非局部均值滤波(NL-means)算法的积分图加速原理与C++实现
在上一篇文章中,我们讲解了非局部均值滤波算法的原理,以及使用C++和Opencv来实现了该算法:
非局部均值滤波(NL-means)算法的原理与C++实现
我们知道,非局部均值滤波是非常耗时的,这很影响该算法在实际场景中的应用。所以后来有研究人员提出使用积分图来加速该算法,可提升数倍的速度。本文我们将详细讲解该算法的积分图加速原理,并使用C++与Opencv来将其实现。
积分图的原理我们之前也讲过,此处不再重复:
数字图像处理之积分图
数字图像处理之积分图计算优化
积分图的一种CUDA并行运算
首先,让我们来回顾一下上篇文章中的计算思路:
原图像中的每一个点都是待滤波点,每一个待滤波点对应一个以它为中心的搜索窗口和一个同样以它为中心的邻域块(搜索窗口与邻域块都是矩形区域,只不过搜索窗口的尺寸要大于邻域块)。从而每一个待滤波点的滤波值由搜索窗口内所有点的像素值加权求和得到。搜索窗口中每个点的权重则由该点的邻域块与待滤波点的邻域块的MSE相似度决定。
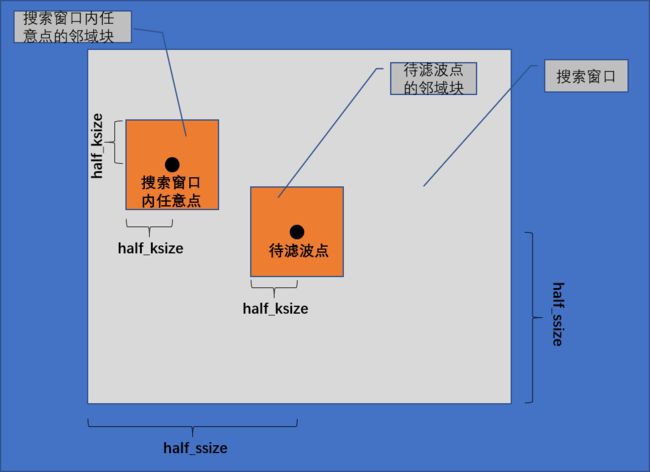
因此,上篇文章使用4层for循环来实现算法,伪代码如下。由此可知,对于当前的一个待滤波点,计算完其对应搜索窗口内所有点的加权和得到其滤波值之后,再开始计算下一个待滤波点的滤波值。
for 原图像的每一行
{
for 原图像的每一列 //在这一层循环确定了一个待滤波点
{
for 搜索窗口的每一行
{
for 搜索窗口的每一列 //在这一层循环确定了当前搜索窗口中的一个点
{
//在这里计算当前搜索窗口中确定的一个点的权重,并计算加权和
}
}
}
}
为了便于使用积分图加速计算,我们把计算顺序改变一下,伪代码如下:
for 搜索窗口的每一行
{
for 搜索窗口的每一列 //在这一层循环确定了所有搜索窗口中相同偏移位置的点
{
for 原图像的每一行
{
for 原图像的每一列 //在这一层循环确定了原图像中的一个待滤波点
{
/*
在这里计算当前确定的待滤波点的对应搜索窗口内的对应偏移
位置点的权重,然后计算该点像素值与权重的乘积,并累加乘积
*/
}
}
}
}
上述伪代码中讲的“所有搜索窗口中相同偏移位置的点”可能有点抽象,我们结合下图来更加详细地说明。如下图所示,点A1、点A2都是待滤波点,点B1为点A1对应搜索窗口内的一个点,点B2为点A2对应搜索窗口内的一个点,如果B1与A1的相对位置,与B2与A2的相对位置一样,那么B1与B2就是这两个搜索窗口中相同偏移位置的点。
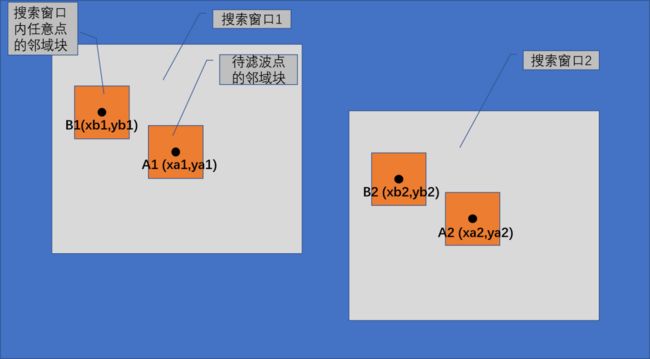
如果从数学角度来描述相对位置一样,那么就是下式:
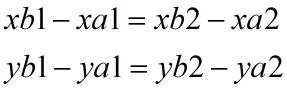
按照改变后的计算顺序,在内两层循环中计算所有待滤波点在各自的搜索窗口中相同偏移位置的点的权重,及该点像素值与权重的乘积,并累加乘积。感觉这样表达还是有点抽象,下面我们再举例子说明。
比如,待滤波点为A1、A2、A3、A4、A5......
A1、A2、A3、A4、A5......对应搜索窗口中所有相同偏移位置点为:
相同偏移位置1:B1、B2、B3、B4、B5......
相同偏移位置2:C1、C2、C3、C4、C5......
相同偏移位置3:D1、D2、D3、D4、D5......
.
.
.
其中B1、C1、D1......组成A1对应的搜索窗口内的所有点。B2、C2、D2......组成A2对应的搜索窗口内的所有点。B3、C3、D3......组成A3对应的搜索窗口内的所有点......
在上篇文章中我们先计算B1、C1、D1......的权重:
WB1、WC1、WD1......
以及像素值与权重的乘积:
IB1*WB1、IC1*WC1、ID1*WD1......
并将乘积与权重分别累加,得到点A1的滤波值:
sumw1 = WB1+WB2+WB3+......
A1的滤波值=(IB1*WB1+IC1*WC1+ID1*WD1+......)/sumw1
改变顺序之后,我们先计算B1、B2、B3、B4、B5......的权重得到WB1、WB2、WB3、WB4、WB5......,以及像素值与权重的乘积IB1*WB1、IB2*WB2、IB3*WB3、IB4*WB4、IB5*WB5......,然后将乘积和权重分别累加到一个变量:
sum1 = sum1+IB1*WB1
w_sum1 = w_sum1+WB1
sum2 = sum2+IB2*WB2
w_sum2 = w_sum2+WB2
sum3 = sum3+IB3*WB3
w_sum3 = w_sum3+WB3
sum4 = sum4+IB4*WB4
w_sum4 = w_sum4+WB4
sum5 = sum5+IB5*WB5
w_sum5 = w_sum5+WB5
.
.
.
接着计算C1、C2、C3、C4、C5......的权重得到WC1、WC2、WC3、WC4、WC5......,以及像素值与权重的乘积IC1*WC1、IC2*WC2、IC3*WC3、IC4*WC4、IC5*WC5......,然后将乘积和权重分别累加到一个变量:
sum1 = sum1+IC1*WC1
w_sum1 = w_sum1+WC1
sum2 = sum2+IC2*WC2
w_sum2 = w_sum2+WC2
sum3 = sum3+IC3*WC3
w_sum3 = w_sum3+WC3
sum4 = sum4+IC4*WC4
w_sum4 = w_sum4+WC4
sum5 = sum5+IC5*WC5
w_sum5 = w_sum5+WC5
.
.
.
同理计算D1、D2、D3、D4、D5......,以及所有相同偏移位置的系列点。最后计算完所有偏移位置的点之后,再计算:
A1的滤波值=sum1/w_sum1
A2的滤波值=sum2/w_sum2
A3的滤波值=sum3/w_sum3
A4的滤波值=sum4/w_sum4
A5的滤波值=sum5/w_sum5
.
.
.
非局部均值滤波的主要耗时点在于频繁计算邻域块的MSE相似度。讲完计算顺序,接下来我们讲怎么使用积分图来加速计算邻域块的MSE相似度。由积分图的原理可知,计算矩形窗口内所有点的像素值和时,可以使用积分图来加速计算。根据两个邻域块的MSE计算公式,我们可以构造一个图像,并计算该图像的积分图,然后使用该积分图来快速计算邻域块的MSE。
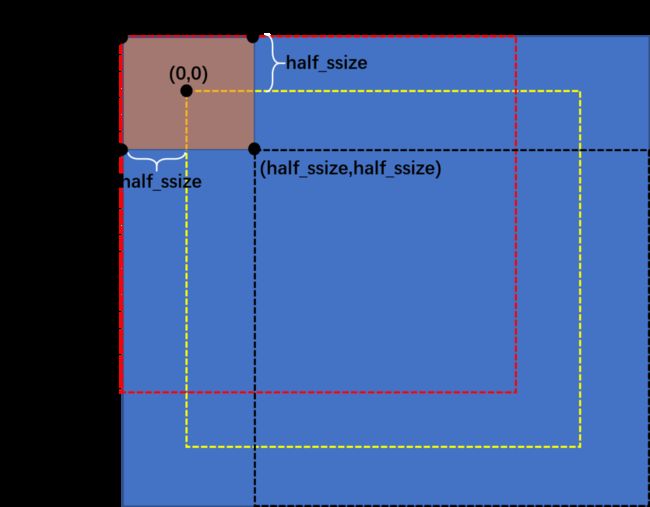
首先在边缘扩充之后的图像中取图像A,相当于上、下、左、右各裁剪half_ssize行、half_ssize行、half_ssize列、half_ssize列得到(也相当于把上图中黄色虚线框内区域抠出来作为图像A)。然后根据搜索窗口内当前计算点与当前待滤波点的位置偏移(x_offset,y_offset)(-half_ssize≤x_offset≤half_ssize,-half_ssize≤y_offset≤half_ssize),获取与图像A的行、列均相同的图像B,比如偏移量为(-half_ssize,-half_ssize),那么图像B为上图中红色虚线框内区域抠出来的图像,又比如偏移量为(half_ssize,half_ssize),那么图像B为上图中黑色虚线框内区域抠出来的图像。
得到图像A与图像B之后,计算两图像的差值图C(也即相同坐标点的像素差值):
C = A - B
接着,计算图C的平方图(也即对每一个坐标点的像素值计算平方):
D = C * C
然后,计算图D的积分图,即为位置偏移(x_offset,y_offset)的积分图。那么在不同搜索窗口内,所有相对于待滤波点的偏移位置为(x_offset,y_offset)的点,其与待滤波点的邻域块相似度均可以使用这个积分图来计算。一个搜索窗口内有(2*half_ssize+1)*(2*half_ssize+1)个点,也即有(2*half_ssize+1)*(2*half_ssize+1)个相对于其中心点的偏移位置,因此我们需要计算(2*half_ssize+1)*(2*half_ssize+1)张积分图(所有搜索窗口中相同偏移位置的点是共用一张积分图的)。
最后,得到积分图之后,就可以根据当前待滤波点在积分图上对应的位置取得其邻域块区域,快速计算邻域块区域内所有点的像素值平均值,即为MSE相似度:
假设待滤波点在原始图像中坐标为A(x,y),那么该点在积分图中坐标为A(x+half_ksize,y+half_ksize),从而在积分图中得到以点A为中心的邻域块,其4个顶点坐标分别为P1(x,y),P2(x+half_ksize,y-half_ksize),P3(x-half_ksize,y+half_ksize),P4(x+half_ksize,y+half_ksize)。

邻域块的尺寸是确定的:(2*half_ksize+1)*(2*half_ksize+1),最后可以根据积分图上点P1、P2、P3、P4的像素值IP1、IP2、IP3、IP4以及邻域块尺寸,计算得到点A、与点A坐标偏移为(x_offset,y_offset)的搜索窗口内点的邻域块相似度:
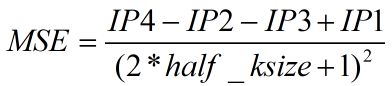
讲完原理之后,下面上代码。
1. 计算积分图代码
void integralImgSqDiff(Mat src, Mat &dst, int Ds, int t1, int t2, int m1, int n1)
{
//计算图像A与图像B的差值图C
Mat Dist2 = src(Range(Ds, src.rows - Ds), Range(Ds, src.cols - Ds)) - src(Range(Ds + t1, src.rows - Ds + t1), Range(Ds + t2, src.cols - Ds + t2));
float *Dist2_data;
for (int i = 0; i < m1; i++)
{
Dist2_data = Dist2.ptr(i);
for (int j = 0; j < n1; j++)
{
Dist2_data[j] *= Dist2_data[j]; //计算图像C的平方图D
}
}
integral(Dist2, dst, CV_32F); //计算图像D的积分图
}
2. 快速NL-means算法主体函数代码
void fastNLmeans(Mat src, Mat &dst, int ds, int Ds, float h)
{
Mat src_tmp;
src.convertTo(src_tmp, CV_32F);
int m = src_tmp.rows;
int n = src_tmp.cols;
int boardSize = Ds + ds + 1;
Mat src_board;
copyMakeBorder(src_tmp, src_board, boardSize, boardSize, boardSize, boardSize, BORDER_REFLECT);
Mat average(m, n, CV_32FC1, 0.0);
Mat sweight(m, n, CV_32FC1, 0.0);
float h2 = h*h;
int d2 = (2 * ds + 1)*(2 * ds + 1);
int m1 = src_board.rows - 2 * Ds; //行
int n1 = src_board.cols - 2 * Ds; //列
Mat St(m1, n1, CV_32FC1, 0.0);
for (int t1 = -Ds; t1 <= Ds; t1++)
{
int Dst1 = Ds + t1;
for (int t2 = -Ds; t2 <= Ds; t2++)
{
int Dst2 = Ds + t2;
integralImgSqDiff(src_board, St, Ds, t1, t2, m1, n1);
for (int i = 0; i < m; i++)
{
float *sweight_p = sweight.ptr(i);
float *average_p = average.ptr(i);
float *v_p = src_board.ptr(i + Ds + t1 + ds);
int i1 = i + ds + 1; //row
float *St_p1 = St.ptr(i1 + ds);
float *St_p2 = St.ptr(i1 - ds - 1);
for (int j = 0; j < n; j++)
{
int j1 = j + ds + 1; //col
float Dist2 = (St_p1[j1 + ds] + St_p2[j1 - ds - 1]) - (St_p1[j1 - ds - 1] + St_p2[j1 + ds]);
Dist2 /= (-d2*h2);
float w = fast_exp(Dist2);
sweight_p[j] += w;
average_p[j] += w * v_p[j + Ds + t2 + ds];
}
}
}
}
average = average / sweight;
average.convertTo(dst, CV_8U);
}
运行上述代码同样对496*472的Lena图像去噪,结果如下图所示,耗时由原来的20秒左右减少为1.6秒左右,所以加速效果还是非常显著的。

噪声图像

快速NL-means算法去噪图像
使用积分图加速之后,计算耗时减少了好多,不过还是秒级的。然而在实时应用场合中通常要求毫秒级的耗时,因此加速得还不够,下篇文章中我们将介绍在积分图加速得基础上,使用CUDA进一步加速优化该算法,敬请期待~
本人微信公众号如下,不定期更新精彩内容,欢迎扫码关注:
