CNN做时间序列预测_使用PyTorch进行LSTM时间序列预测
LSTM预测航班
搬运自:LSTM,感谢原作者Usman Malik 。
(顺便种草一个软件:神经网络结构绘图软件https://github.com/alexlenail/NN-SVG)
本节将介绍另一种常用的门控循环神经网络:长短期记忆(long short-term memory,LSTM)。它 比门控循环单元的结构稍微复杂一点。
1.1、数据集和问题定义
import 让我们打印Seaborn库内置的所有数据集的列表:
[让我们将数据集加载到我们的应用程序中
flight_data 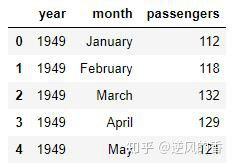
该数据集有三列:year,month,和passengers。该passengers列包含指定月份旅行旅客的总数。让我们绘制数据集的形状:
flight_data可以看到数据集中有144行和3列,这意味着数据集包含12年的乘客旅行记录。
任务是根据前132个月来预测最近12个月内旅行的乘客人数。请记住,我们有144个月的记录,这意味着前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最近12个月的值进行评估。
让我们绘制每月乘客的出行频率。
接下来的脚本绘制了每月乘客人数的频率:
fig_size 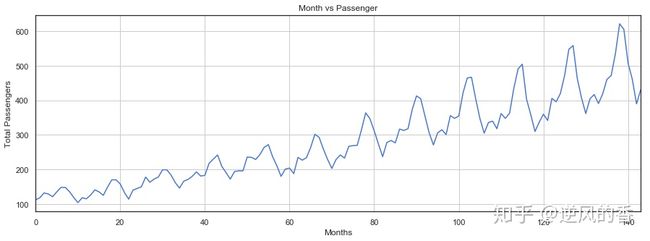
输出显示,多年来,乘飞机旅行的平均乘客人数有所增加。一年内旅行的乘客数量波动,这是有道理的,因为在暑假或寒假期间,旅行的乘客数量与一年中的其他部分相比有所增加。
1.2、数据预处理
数据集中的列类型为object,如以下代码所示:
flight_data第一步是将passengers列的类型更改为float。
all_data 接下来,我们将数据集分为训练集和测试集。LSTM算法将在训练集上进行训练。然后将使用该模型对测试集进行预测。将预测结果与测试集中的实际值进行比较,以评估训练后模型的性能。
前132条记录将用于训练模型,后12条记录将用作测试集。以下脚本将数据分为训练集和测试集。
test_data_size 我们的数据集目前尚未规范化。最初几年的乘客总数远少于后来几年的乘客总数。标准化数据以进行时间序列预测非常重要。以在一定范围内的最小值和最大值之间对数据进行规范化。我们将使用模块中的MinMaxScaler类sklearn.preprocessing来扩展数据。
以下代码 分别将最大值和最小值分别为-1和1归一化。
from 您可以看到数据集值现在在-1和1之间。
在此重要的是要提到数据标准化仅应用于训练数据,而不应用于测试数据。如果对测试数据进行归一化处理,则某些信息可能会从训练集中 到测试集中。
下一步是将我们的数据集转换为张量,因为PyTorch模型是使用张量训练的。要将数据集转换为张量,我们可以简单地将数据集传递给FloatTensor对象的构造函数,如下所示
train_data_normalized 最后的预处理步骤是将我们的训练数据转换为序列和相应的标签。
您可以使用任何序列长度,这取决于领域知识。但是,在我们的数据集中,使用12的序列长度很方便,因为我们有月度数据,一年中有12个月。如果我们有每日数据,则更好的序列长度应该是365,即一年中的天数。因此,我们将训练的输入序列长度设置为12。
接下来,我们将定义一个名为的函数create_inout_sequences。该函数将接受原始输入数据,并将返回一个元组列表。在每个元组中,第一个元素将包含与12个月内旅行的乘客数量相对应的12个项目的列表,第二个元组元素将包含一个项目,即在12 + 1个月内的乘客数量。
train_window 执行以下脚本以创建序列和相应的标签进行训练:
train_inout_seq 如果打印train_inout_seq列表的长度,您将看到它包含120个项目。这是因为尽管训练集包含132个元素,但是序列长度为12,这意味着第一个序列由前12个项目组成,第13个项目是第一个序列的标签。同样,第二个序列从第二个项目开始,到第13个项目结束,而第14个项目是第二个序列的标签,依此类推。
现在让我们输出train_inout_seq列表的前5个项目:
train_inout_seq您会看到每个项目都是一个元组,其中第一个元素由序列的12个项目组成,第二个元组元素包含相应的标签。
1.3、创建LSTM模型
让我总结一下以上代码中发生的事情。LSTM该类的构造函数接受三个参数:
input_size:对应于输入中的要素数量。尽管我们的序列长度为12,但每个月我们只有1个值,即乘客总数,因此输入大小为1。 hidden_layer_size:指定隐藏层的数量以及每层中神经元的数量。我们将有一层100个神经元。 output_size:输出中的项目数,由于我们要预测未来1个月的乘客人数,因此输出大小为1。 接下来,在构造函数中,我们创建变量hidden_layer_size,lstm,linear,和hidden_cell。LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。该hidden_cell变量包含先前的隐藏状态和单元状态。的lstm和linear层变量用于创建LSTM和线性层。
在forward方法内部,将input_seq作为参数传递,该参数首先传递给lstm图层。lstm层的输出是当前时间步的隐藏状态和单元状态,以及输出。lstm图层的输出将传递到该linear图层。预计的乘客人数存储在predictions列表的最后一项中,并返回到调用函数。
下一步是创建LSTM()类的对象,定义损失函数和优化器。由于我们正在解决分类问题,
让我们输出模型:
class 1.4、训练模型
epochs 1.5、做出预测
现在我们的模型已经训练完毕,我们可以开始进行预测了。
fut_pred 您可以将上述值与train_data_normalized数据列表的最后12个值进行比较。
该test_inputs项目将包含12个项目。在for循环内,这12个项目将用于对测试集中的第一个项目进行预测,即项目编号133。然后将预测值附加到test_inputs列表中。在第二次迭代中,最后12个项目将再次用作输入,并将进行新的预测,然后将其test_inputs再次添加到列表中。for由于测试集中有12个元素,因此该循环将执行12次。在循环末尾,test_inputs列表将包含24个项目。最后12个项目将是测试集的预测值。
以下脚本用于进行预测:
如果输出test_inputs列表的长度,您将看到它包含24个项目。可以按以下方式打印最后12个预测项目:
model由于我们对训练数据集进行了标准化,因此预测值也进行了标准化。我们需要将归一化的预测值转换为实际的预测值。
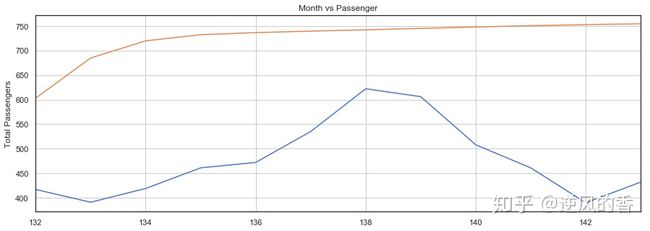
actual_predictions 现在让我们针对实际值绘制预测值。看下面的代码:
x 在上面的脚本中,我们创建一个列表,其中包含最近12个月的数值。第一个月的索引值为0,因此最后一个月的索引值为143。
在下面的脚本中,我们将绘制144个月的乘客总数以及最近12个月的预计乘客数量。
plt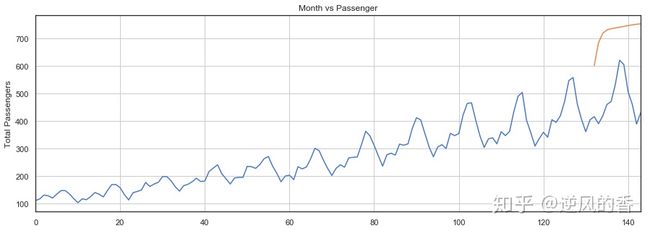
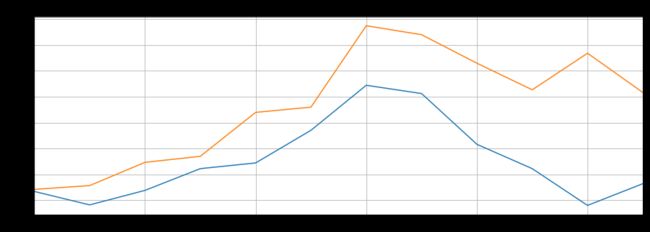
我们的LSTM所做的预测用橙色线表示。您可以看到我们的算法不太准确,但是它仍然能够捕获最近12个月内旅行的乘客总数的上升趋势以及偶尔的波动。您可以尝试在LSTM层中使用更多的时期和更多的神经元,以查看是否可以获得更好的性能。
为了更好地查看输出,我们可以绘制最近12个月的实际和预测乘客数量,如下所示:
plt