接口基础:正则表达式
接口测试的时候,如果想验证response是否正确,就需要提取关键字,拿关键字进行assertequal 断言.
如果不会提取关键字就尴尬了,开发不只是用正则提取需要的文字,他们会拿正则判断输入的字符串是否
符合规则.
下边我的讲解尽量用图描述,你们看着就很清晰了.
学之前大概浏览下表达式的含义,链接如下:
http://tool.oschina.net/uploads/apidocs/jquery/regexp.html
正则表达式 生成图片工具请点击
1.手机号正则
reg: /^1[34578][0-9]{9}$/
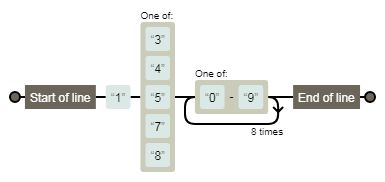
注释:以1开头,第二位为3 4 5 7 9 其中一个,以9位(本身1次加重复8次)0-9数字结尾
看不懂就看表达式的链接。
2.URL分组替换
reg: /http:(//.+.jpg)/

注释: http: 是固定的, 后天的 // 要用 \ 转义下,+ 匹配前面的子表达式一次或多次 , . 也需要转义,
.jpg 是固定的.
大家注意下 图片有group 标签,说明可以用group提取出来的,我们用代码演示下:
import re
URL="https://mp.csdn.net/mdeditor#.jpg"
print(re.search(r'https:(\/\/.+\.jpg)',URL).group(1))
打印结果:
//mp.csdn.net/mdeditor#.jpg
3.日期匹配与分组替换
reg=/^\d{4}[/-]\d{2}[/-]\d{2}$/
图片演示如下:

注释:
^ 是开始位置,$ 结束位置.
\d{4} 四位任意数字,[/-] 匹配 / or -, \d{2} 2位任意数字
验证代码 :
import re
reg="^\d{4}[/-]\d{2}[/-]\d{2}$"
print(re.match(reg,"2014-01-01").group(0))
# group(0)代表是它匹配的自身,group(1) 才是开始取的分组
print(re.match(reg,"20104-01-01"))
打印结果如下:
2014-01-01
None
想要分组必须有 () ,我们加上三个 group 演示下:
改造下这个正则
/^(\d{4})/-/-$/
演示图片如下:

代码改下,取出来 group 的值:
import re
reg="^(\d{4})[/-](\d{2})[/-](\d{2})$"
print(re.match(reg,"2014-01-01").group(0))
print(re.match(reg,"2014-01-01").group(1))
print(re.match(reg,"2014-01-01").group(2))
print(re.match(reg,"2014-01-01").group(3))
打印结果:
2014-01-01
2014
01
01
4.修饰符
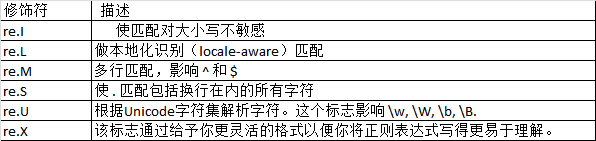
演示 第一个 大小写敏感:
import re
reg=r"[a-z]+"
m=re.findall(reg,"Dog,cAT,MONKY",re.I)
print(m)
打印结果:
['Dog', 'cAT', 'MONKY']
PS 下: 在接口测试时候,用findall(表达式,被赛选的内容,修饰符) 这个方法已经够用,并且返回分组list
便于我们取值.
其他方法自己学不会也可以.
自己要搞清楚加括号和不加括号的区别, 用代码演示下 ;
import re
reg=r"name=.{0,}?$"
m=re.findall(reg,"dog's name=xiaohei",re.I)
print(m)
#打印结果为 ['name=xiaohei']
reg=r"name=(.{0,}?$)"
m=re.findall(reg,"dog's name=xiaohei",re.I)
print(m)
#d打印结果为['xiaohei']
5.量词
reg=/\d?@\d*@\d+@\d{10}@\d{10,20}@\d{10,}@\d{0,10}/
演示图:

注释:结合图片看
\d? 出现0次或者 一次数字,
\d* 出现0次或者多次数字 *等价于{0,}
\d+ 出现一次或多次数字,+等价于{1,}
\d{10} 出现十次
\d{10,20} 最少匹配10次且最多匹配20次
\d{10,} 最少匹配10次
\d{0,10} o次 到10次之间 .
如果懂了上边的基础,在做接口测试够用,如果自己扩展还可以,
贪婪 和懒惰 模式自己查下.
我再这里稍微提示下:
避免贪婪 用 ? .