24OPENVINO intermediate course 16 Gstreamer构建视频处理流水线
Gstreamer构建视频处理流水线
- 1 说明
- 2 实验目的
- 3 任务内容
- 4 实验原理
- 5 操作步骤
- 6 实际操作
1 说明
本实验所有代码均在ubuntu 18.04 + OpenVINO 2020R3.LTS installed 环境下验证通过,若需要代码移植,请务必检查环境配置是否与本实验环境相同。
2 实验目的
1、了解使用Gstreamer构建视频处理流水线的方法。
2、掌握使用DL-Streamer运行面部检测和分类视频处理流水线的方法。
3 任务内容
1、学习使用Gstreamer构建视频处理流水线的方法。
2、使用DL-Streamer运行面部检测和分类视频处理流水线。
4 实验原理
前面的实验介绍了模型部署的全部流程以及流程中的每一个阶段,本实验重点介绍如何去模拟部署一个完整AI应用的流程。
项目六介绍了完整的视频分析流程,包括创建基于AI的视频分析应用需要的步骤。一般来说,了解AI应用需要做什么后,需要选择正确的系统和可以实施具体操作的硬件,所以用户需要对整个流程进行一个模拟或基准测试。用户可以通过各种方式查看解码密度,比如可以使用Media-SDK,OpenCV或Gstreamer,并且在测试中不断增加通道数,直到每秒帧速率降至用户的最低要求以下。第5课介绍了如何进行基准测试、如何测量推理性能。实验中使用了benchmark App和性能计数器来测量推理性能。但是假设有3个或4个模型并行运行的时候该如何去测量推理性能呢?或者说,如果有一个特殊的视频流该如何处理?如何将所有要素整合起来?如何解决解码10个视频流的解码密度问题?可以对所有视频流进行推理但一定能同时对10个视频流进行解码和推理。也许可以同时对8个视频进行解码和推理,但这需要实验来进一步确认。因此,测量性能的最佳方法是快速构建一个真实流水线,这个流水线应用要看起来尽可能接近用户尝试构建的实际应用。

使用的输入内容最好是将在产品中使用的视频,因为视频中实际操作量的大小会影响进行解码所需要的算力。如果是摄像头或RTSP流,应尽量去模拟真实对象。输出内容也需要符合这样的要求,如果用户需要实时查看输出视频,或者说可能需要存储或上传这一内容时,视频中实际操作量的大小同时会影响进行编码所需要的算力。如果不需要输出,则可以省去成本高昂的编码流程,或者编码为较低的分辨率、较低的帧速率,这些都会降低实际造成的影响。
为了让用户可以模拟整个流程,构建了DL-Streamer,Deep Learning Streamer是一个框架,可以用来构建计算图或流水线。它包含在2020.2以及更高版本的OpenVINO中,并且它还具有开源版本。用户可以将开发的视频分析元素添加至Gstreamer Elements的列表中,这些新元素利用OpenVINO进行检测、分类、识别跟踪、可视化等操作。DL-Streamer具有C++、Python和纯Gstreamer脚本示例。本实验介绍最简单的方法,直接编写简单的Gstreamer流水线代码,并在hands-on中运行代码。
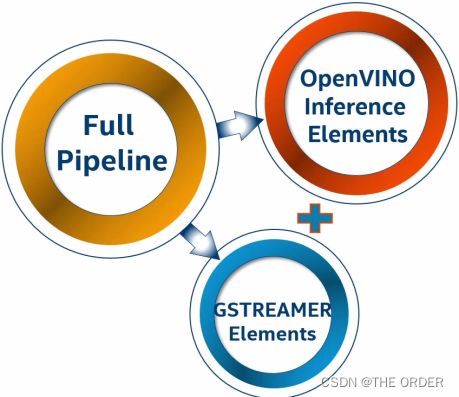
完成这样一个完整的流水线较简单,采用包含前面介绍的所有阶段、或者包含更多阶段的流水线,如下流水线包括2个推理阶段,即推理1和推理2,比如检测模型和分类模型等。

可以使用一行Gstreamer代码构建与模拟该流水线,如下。

第一步是“输入”,这里的输入是一个视频文件“video1.mp4”,当然也可以把它换成RTSP流或摄像头。

这里的红色感叹号均表示新的流水线阶段。

下一步是解码输入视频。

然后将其转换为下一阶段所需的正确格式,这些操作叫做“预处理”,下面可以进行推理了。

GVA表示Gstreamer Video Analytics,这是执行检测的命令。可以使用JSON文件或在此处的命令行中指定用于检测的所有参数,例如,以下模型用于面部检测,并且提供了xml文件路径。

检测完成后获取检测结果并执行另一次推理。这里使用GVA-Classify进行情感识别,并使用WaterMark命令在原始图像上绘制检测和识别结果。然后重新设置视频的输出格式,叫做“视频后处理”,并且也有可能对结果进行编码。

因此可以通过一行代码定义完整的工作负载,同时可以有许多并行或串行运行的模型。一般来说,可以添加任何原始的GSTREAMER元素,这行的代码用来描述一个视频分析通道。
如果想模拟多个通道,只需复制这行代码。这里定义了2个并行运行的这类流水线。然后在任意OpenVINO机器上运行这个流水线来获得性能测试结果。这不仅可以在本地机器上运行,也可以在AI dev-cloud上的Docker容器中运行。

互联网是获取DL-Streamer所有相关信息的最佳途径,可以在git-hub上看到OpenCV页面和DL-Streamer页面,即以前的GST-VIDEO-ANALYTICS。
可以在此处找到需要的所有信息,支持的硬件和软件,安装指南。
用户不需要安装指南,因为如果安装了OpenVINO,DL-Streamer也会随之安装。还有所有的示例,转到“元素列表”,可以在右侧看到有关使用DL-Streamer的大量信息和元素。
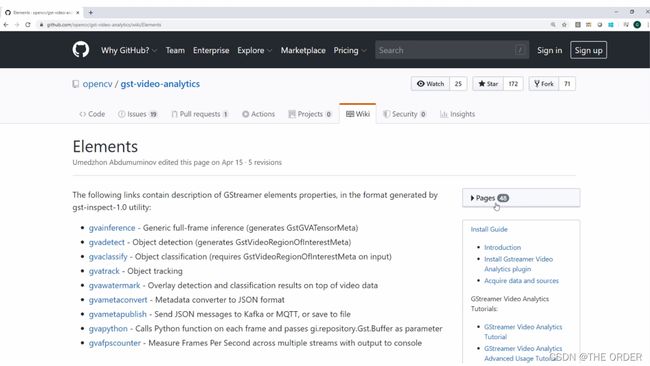
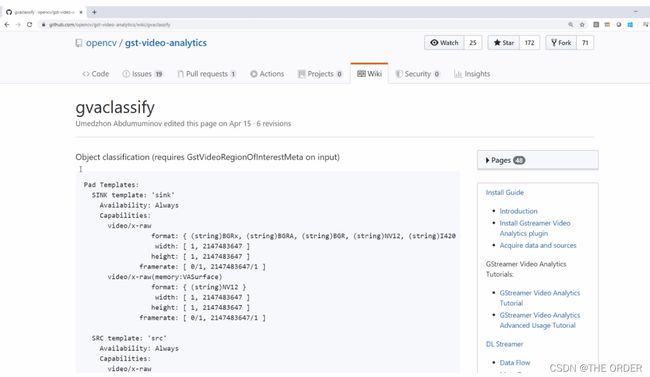
以GVA-Classify为例,在这里可以找到完整的文档,并看到“source”和“sink”,它们基本上是元素的输入和输出,可以看到元素的所有属性、如何添加批次大小、如何加载模型等。一般来说,可以看到在自己的流水线中使用这些元素需要的所有内容。

本实验为面部检测和分类示例,用来了解如何建立并运行流水线。
5 操作步骤
步骤1
登录实验平台,进入实验环境并打开命令行执行终端。
步骤2
执行命令su,输入root用户密码root@openlab,切换到root目录。
步骤3
执行命令cd ~/51openlab/07/exercise-1/,进入exercise-1目录。
步骤4
执行ll命令查看当前目录下的文件。

步骤5
执行如下命令输出实验路径。
# export lab_dir=~/51openlab/07/exercise-1/
# export MODELS_PATH=~/51openlab/07/exercise-1/models/
说明:确保MODELS_PATH这个环境变量定向到模型的目录中。
步骤6
执行如下命令,初始化OpenVINO环境。
# source /opt/intel/openvino/bin/setupvars.sh
![]()
步骤7
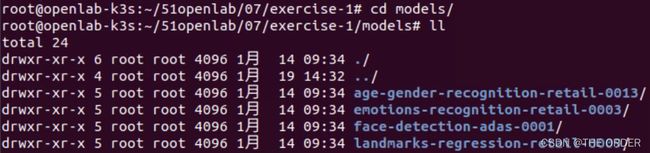
执行如下命令进入models目录并查看来自model-zoo的4个模型。
# cd models
# ll
# cd age-gender-recognition-retail-0013
# ll
# cd FP16
# ll
本实验将使用这些模型,每个模型都有几个版本:FP16、FP32、或者整型格式。
步骤8
执行如下命令进入model_proc目录并查看模型的JSON文件。
# cd ../../../model_proc
# ll
# vi age-gender-recognition-retail-0013.json
查看模型描述:

“model_proc”目录中包含如何使用模型的指令、第一层和最后一层的信息、格式等内容。
步骤9
执行命令如下命令显示需要输入的原始视频文件。
# cd ..
# gst-play-1.0 faces.mp4

步骤10
执行命令vi face_detection_and_classification-file.sh查看代码。
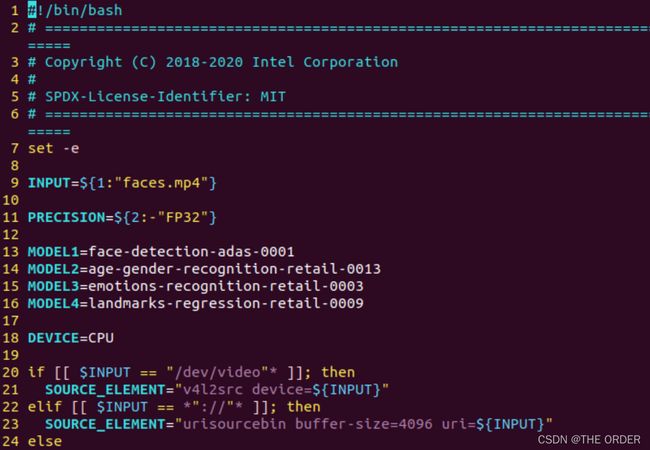

可以看到本实验正在使用的模型名称,待使用的设备是CPU。
该代码为IR文件和JSON文件指定正确的路径。PIPELINE是流水线,采用源元素,即视频输入,对其进行解码和转换。第66行执行检测,然后执行3种不同的分类,最后输出视频文件。
步骤11
执行如下命令运行代码,并查看输出的视频文件。
# bash face_detection_and_classification-file.sh
# ll
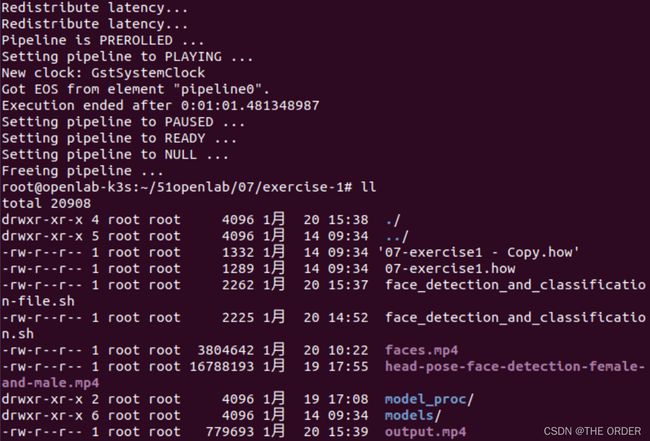
可以看到output.mp4是输出文件。
步骤12
执行命令gst-play-1.0 output.mp4检查实验结果视频。

可以看到面部检测正在运行,年龄、性别和情感等信息都显示到屏幕上,甚至可以看到脸上的5个点,称之为“特征”。
请继续去完成第二个实验,任务二将运行另外一个demo,进行目标检测和物体跟踪。
6 实际操作

执行.sh文件完成