【YOLOX训练部署】YOLOX 使用OpenVINO 推理自己训练的模型
YOLOX训练自己的VOC数据集
【YOLOX训练部署】YOLOX训练自己的VOC数据集_乐亦亦乐的博客-CSDN博客YOLOX 环境安装与训练自己标注的VOC数据集;https://blog.csdn.net/qq_41251963/article/details/122262738将自己训练的YOLOX权重转化成ONNX 并进行推理
【YOLOX训练部署】将自己训练的YOLOX权重转化成ONNX 并进行推理_乐亦亦乐的博客-CSDN博客使用YOLOX 训练自己的VOC数据集;保存训练模型;将训练模型转化成ONNX格式,并进行推理!https://blog.csdn.net/qq_41251963/article/details/122265224
YOLOX ONNX 使用GPU进行推理
【YOLOX训练部署】YOLOX ONNX 使用GPU进行推理_乐亦亦乐的博客-CSDN博客YOLOX训练自己的VOC数据集【YOLOX训练部署】YOLOX训练自己的VOC数据集_乐亦亦乐的博客-CSDN博客将自己训练的YOLOX权重转化成ONNX 并进行推理【YOLOX训练部署】将自己训练的YOLOX权重转化成ONNX 并进行推理_乐亦亦乐的博客-CSDN博客ONNX 在 CPU 上推理速度较慢,对比GPU效果,使用GPU对onnx进行推理。具体操作:首先卸载onnxruntime,并安装onnxruntime-gpupip uninstall onnxruntimehttps://blog.csdn.net/qq_41251963/article/details/122265641
【OpenVINO】 Ubuntu18.04 环境下载安装
【OpenVINO】 Ubuntu18.04 环境下载安装_乐亦亦乐的博客-CSDN博客OpenVINO官方中文文档:OpenVINO™ 工具套件概述 - OpenVINO™ 工具套件https://docs.openvino.ai/cn/latest/index.htmlOpenVINO下载地址:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit-download.htmlhttps://www.intel.com/content/www/us/en/developer/tools/op..https://blog.csdn.net/qq_41251963/article/details/122267274
首先参考OpenVINO 安装,安装OpenVINO!
找到安装目录下:
/home/liqiang/intel/openvino_2021/python/python3.7
将此文件夹下的文件复制到Python 虚拟环境中,也就是下面的路径:
/home/liqiang/anaconda3/envs/YOLOX/lib/python3.7/site-packages
这样就可以找到openvino的库了。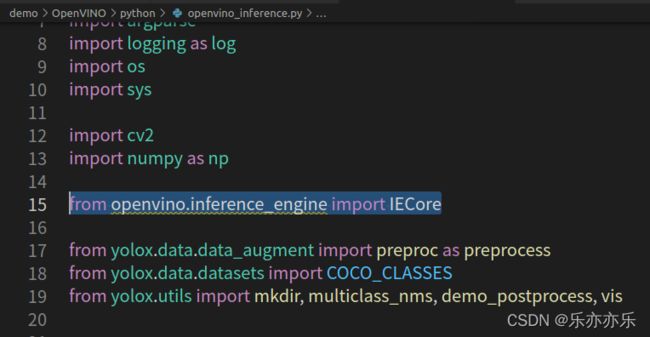
模型转化,首选将训练好的模型转换成ONNX模型;可参考博客:
【YOLOX训练部署】将自己训练的YOLOX权重转化成ONNX 并进行推理_乐亦亦乐的博客-CSDN博客使用YOLOX 训练自己的VOC数据集;保存训练模型;将训练模型转化成ONNX格式,并进行推理!https://blog.csdn.net/qq_41251963/article/details/122265224但注意:Note that you should set --opset to 10
本文模型转化例子:
python tools/export_onnx.py --output-name my_yolox_s.onnx -f exps/example/yolox_voc/yolox_voc_s.py -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth -o 10
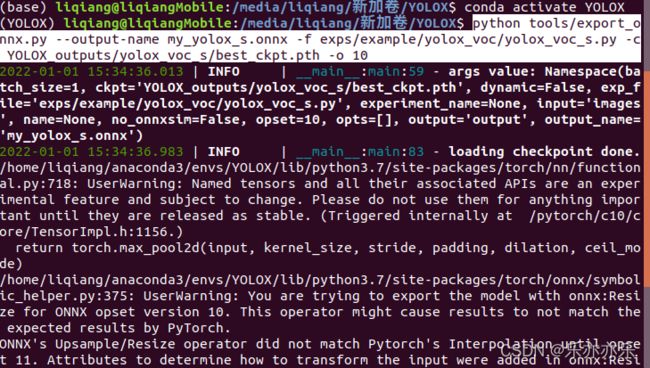
ONNX 模型转化成功!接下来将ONNX模型转换成OpenVINO模型!
进入OpenVINO 安装目录,进入模型转化-路径:/home/liqiang/intel/openvino_2021/deployment_tools/model_optimizer
python3 mo.py --input_model--input_shape [--data_type FP16]
命令
python3 mo.py --input_model /media/liqiang/新加卷/YOLOX/my_yolox_s.onnx --input_shape [1,3,640,640] --data_type FP16 --output_dir /media/liqiang/新加卷/YOLOX/openvINO
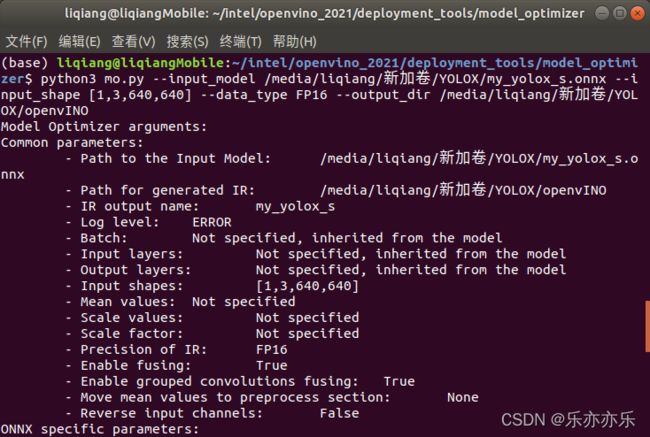
OpenVINO 模型转化完成!!!
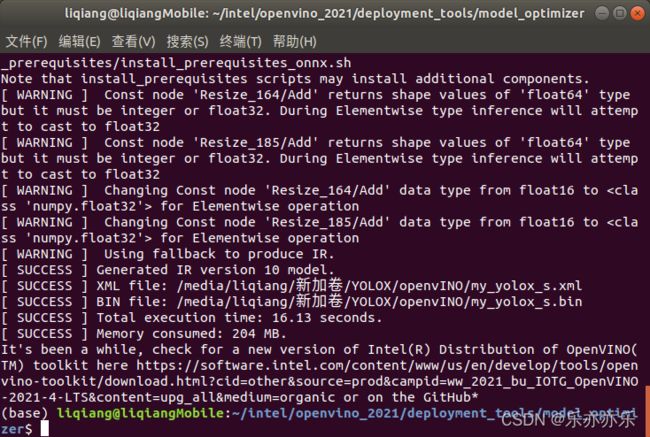
运行Demo进行推理:
修改代码:YOLOX/demo/OpenVINO/python/openvino_inference.py
1)导入VOC_CLASSES
 2) VOC_CLASSES
2) VOC_CLASSES 
python openvino_inference.py -m-i -o -s -d
运行:
python openvino_inference.py -m /media/liqiang/新加卷/YOLOX/openvINO/my_yolox_s.xml -i /media/liqiang/新加卷/YOLOX/assets/8_169.jpg -o /media/liqiang/新加卷/YOLOX
运行成功!!! 
视频推理代码:openvino_inference_video.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Copyright (C) 2018-2021 Intel Corporation
# SPDX-License-Identifier: Apache-2.0
# Copyright (c) Megvii, Inc. and its affiliates.
import argparse
import logging as log
import os
import sys
import cv2
import numpy as np
from openvino.inference_engine import IECore
from yolox.data.data_augment import preproc as preprocess
# from yolox.data.datasets import COCO_CLASSES
from yolox.data.datasets import VOC_CLASSES
from yolox.utils import mkdir, multiclass_nms, demo_postprocess, vis
def parse_args() -> argparse.Namespace:
"""Parse and return command line arguments"""
parser = argparse.ArgumentParser(add_help=False)
args = parser.add_argument_group('Options')
args.add_argument(
'-h',
'--help',
action='help',
help='Show this help message and exit.')
args.add_argument(
'-m',
'--model',
required=True,
type=str,
help='Required. Path to an .xml or .onnx file with a trained model.')
args.add_argument(
'-i',
'--input',
required=True,
type=str,
help='Required. Path to an image file.')
args.add_argument(
'-o',
'--output_dir',
type=str,
default='demo_output',
help='Path to your output dir.')
args.add_argument(
'-s',
'--score_thr',
type=float,
default=0.3,
help="Score threshould to visualize the result.")
args.add_argument(
'-d',
'--device',
default='CPU',
type=str,
help='Optional. Specify the target device to infer on; CPU, GPU, \
MYRIAD, HDDL or HETERO: is acceptable. The sample will look \
for a suitable plugin for device specified. Default value \
is CPU.')
args.add_argument(
'--labels',
default=None,
type=str,
help='Option:al. Path to a labels mapping file.')
args.add_argument(
'-nt',
'--number_top',
default=10,
type=int,
help='Optional. Number of top results.')
return parser.parse_args()
def main():
log.basicConfig(format='[ %(levelname)s ] %(message)s', level=log.INFO, stream=sys.stdout)
args = parse_args()
# ---------------------------Step 1. Initialize inference engine core--------------------------------------------------
log.info('Creating Inference Engine')
ie = IECore()
# ---------------------------Step 2. Read a model in OpenVINO Intermediate Representation or ONNX format---------------
log.info(f'Reading the network: {args.model}')
# (.xml and .bin files) or (.onnx file)
net = ie.read_network(model=args.model)
if len(net.input_info) != 1:
log.error('Sample supports only single input topologies')
return -1
if len(net.outputs) != 1:
log.error('Sample supports only single output topologies')
return -1
# ---------------------------Step 3. Configure input & output----------------------------------------------------------
log.info('Configuring input and output blobs')
# Get names of input and output blobs
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))
# Set input and output precision manually
net.input_info[input_blob].precision = 'FP32'
net.outputs[out_blob].precision = 'FP16'
# Get a number of classes recognized by a model
num_of_classes = max(net.outputs[out_blob].shape)
# ---------------------------Step 4. Loading model to the device-------------------------------------------------------
log.info('Loading the model to the plugin')
exec_net = ie.load_network(network=net, device_name=args.device)
# ---------------------------Step 5. Create infer request--------------------------------------------------------------
# load_network() method of the IECore class with a specified number of requests (default 1) returns an ExecutableNetwork
# instance which stores infer requests. So you already created Infer requests in the previous step.
# ---------------------------Step 6. Prepare input---------------------------------------------------------------------
cap = cv2.VideoCapture(args.input)
while True:
ret, origin_img = cap.read()
_, _, h, w = net.input_info[input_blob].input_data.shape
image, ratio = preprocess(origin_img, (h, w))
# ---------------------------Step 7. Do inference----------------------------------------------------------------------
log.info('Starting inference in synchronous mode')
res = exec_net.infer(inputs={input_blob: image})
# ---------------------------Step 8. Process output--------------------------------------------------------------------
res = res[out_blob]
predictions = demo_postprocess(res, (h, w), p6=False)[0]
boxes = predictions[:, :4]
scores = predictions[:, 4, None] * predictions[:, 5:]
boxes_xyxy = np.ones_like(boxes)
boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2]/2.
boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3]/2.
boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2]/2.
boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3]/2.
boxes_xyxy /= ratio
dets = multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1)
if dets is not None:
final_boxes = dets[:, :4]
final_scores, final_cls_inds = dets[:, 4], dets[:, 5]
origin_img = vis(origin_img, final_boxes, final_scores, final_cls_inds,
conf=args.score_thr, class_names=VOC_CLASSES)
cv2.imshow("result", origin_img)
c = cv2.waitKey(1)
if c == 27:
break
# mkdir(args.output_dir)
# output_path = os.path.join(args.output_dir, args.input.split("/")[-1])
# cv2.imwrite(output_path, origin_img)
if __name__ == '__main__':
sys.exit(main())
运行:
python openvino_inference_video.py -m /media/liqiang/新加卷/YOLOX/openvINO/my_yolox_s.xml -i 4.mp4 -o /media/liqiang/新加卷/YOLOX