Paper Information
论文标题:Contrastive Multi-View Representation Learning on Graphs
论文作者:Kaveh Hassani 、Amir Hosein Khasahmadi
论文来源:2020, ICML
论文地址:download
论文代码:download
Abstract
介绍了一种自监督的方法,通过对比图的结构视图来学习节点和图级别的表示。与视觉表示学习不同,对于图上的对比学习,将视图的数量增加到两个以上或对比多尺度编码并不能提高性能。但是通过对比来自一阶邻居和图扩散的编码能够达到最好的性能。论文在 8 个节点分类和图分类数据集的自监督学习中达到了 SOTA 性能。
1 Introduction
GNNs 面临的问提:GNNs 依赖于标签来学习丰富的表示,像视频、图像、文本和音频等形式,使用标注数据代价昂贵。为解决这一问题,非监督方法应运而生,如基于重构的方法和对比方法与 GNNs 结合,允许它们在不依赖监督数据的情况下学习表示。最近的研究通过最大化节点和图表示之间的互信息(MI)来进行对比学习,在节点分类和图分类任务上取得了最先进的成果。
最近在多视图视觉表示学习(multi-view visual representation learning)上,将数据增强的组合用于生成同一图像的多个视图用于对比学习,已经在图像分类基准上取得了超过监督基线的最先进的结果。然而,目前还不清楚如何将这些技术应用到以图表示数据上。
为了解决这个问题,作者引入了一种自监督的方法来训练图编码器,通过最大化从不同图的结构视图编码的表示之间的 $\text{MI}$。
为了进一步改进在节点和图分类任务上的对比表示学习,我们系统地研究了我们的框架的主要组成部分,并令人惊讶地表明,与视觉对比学习不同:
-
- 增加了视图的数量(即 Augmentation ),超过两个视图并不能提高性能,而通过对比来自一阶邻居的编码和一般的图扩散,可以获得最好的性能;
- 通过对比视图间节点和图编码在节点分类和链接预测取得的结果比对比图之间编码效果更好;
- 与可微池(DiffPool)等分层图池方法相比,一个简单的图 Readout 在这两个任务上都取得了更好的性能;
- 应用正则化(除了早期停止)或归一化层对性能有负面影响;
利用这些发现,我们在线性评估协议下的8个节点中的8个和图分类基准上实现了新的最新的自监督学习。
2 Related Work
相关工作讲废话的一篇,可以略过。
2.1 Unsupervised Representation Learning on Graphs
Random walks
通过跨节点进行随机游走并使用语言模型学习节点表示,将图展平为序列表示。它们以牺牲结构信息为代价,过度强调邻近信息。此外,它们仅限于 transductive,不使用节点特征。
Graph kernels
将图分解为子结构,并使用核函数来度量它们之间的图的相似性。然而,需要设计如何衡量子结构之间相似度量。
Graph autoencoders (GAE)
训练通过预测一阶邻居来加强图中节点的拓扑连接性,GAEs 过分强调近邻信息。
Contrastive methods
2.2 Graph Diffusion Networks
图扩散网络(GDN)协调了空间信息传递和广义图扩散,其中扩散作为去噪滤波器允许消息通过高阶邻域。根据扩散阶段的不同,GDNs 可以分为早期和晚期融合模型。早期融合模型使用图扩散来决定邻居,例如,图扩散卷积(GDC)用稀疏的扩散矩阵代替图卷积中的邻接矩阵。晚期融合模型将节点特征投射到一个潜在空间,然后传播基于扩散的学习表示。
2.3. Learning by Mutual Information Maximization
InfoMax 原理鼓励编码器学习能够最大化输入和已学习表示之间互信息的表示。
3 Method
作者提出最大化一个视图的节点表示与另一个视图的图表示之间的互信息。框架如下:
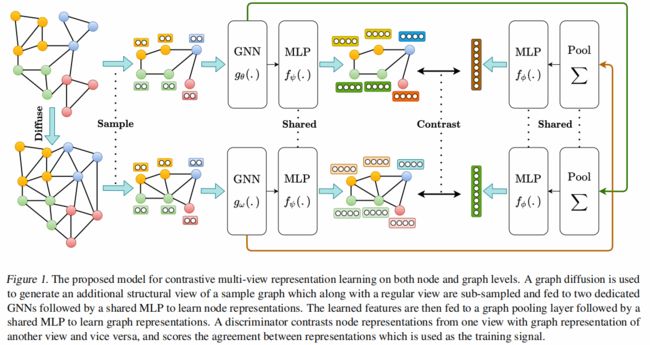
框架由以下组件组成:
-
- 增广机制:将样本图转换为同一图的相关视图。只对图结构进行增广,而不对初始节点特征进行增广。接下来是一个采样器,从两个视图对相同的节点进行子采样,也就是类似于在视觉域裁剪;
- 两个专用的 GNN :即图编码器,每个视图一个,后面接一个共享的 MLP 用来以学习两个视图的节点表示;
- 图池化层:即读出函数,后面接了共享的MLP,即投影头,以学习两种视图的图表示;
- 判别器:将一个视图的节点表示与另一个视图的图表示进行对比,并对它们之间的一致性进行评分;
3.1 Augmentations
图上数据增强考虑两个方面:
-
- 特征空间方面:对初始节点特征进行操作,例如,遮蔽(masking)或添加高斯噪声(Gaussian noise);
- 结构空间方面:破坏图结构,通过添加或删除边、子采样,或使用最短距离或扩散矩阵生成全局视图。作者选择生成一个全局视图,然后再进行子采样。
实验表明,在大多数情况下,最好的结果是通过将邻接矩阵转化为扩散矩阵,并将这两个矩阵视为同一图的结构的两个一致视图。因为邻接矩阵和扩散矩阵分别提供了图结构的局部和全局视图,从这两种视图中学习到的表示之间最大限度的一致性鼓励模型同时编码丰富的局部和全局信息。
扩散过程
扩散过程采用 快速逼近和稀疏化方法:
$\mathbf{S}=\sum\limits _{k=0}^{\infty} \Theta_{k} \mathbf{T}^{k} \in \mathbb{R}^{n \times n}\quad \quad\quad(1)$
其中:
-
- $\mathbf{T} \in \mathbb{R}^{n \times n} $ 是生成的转移矩阵;
- $ \Theta$ 是权重系数,决定了全局和局部信息的比重;
- $\sum\limits _{k=0}^{\infty} \theta_{k}=1, \theta_{k} \in[0,1] $
- $\lambda_{i} \in[0,1] $ 是矩阵 $\mathbf{T} $ 的特征值,保证收敛性。
给定一个邻接矩阵 $\mathbf{A} \in \mathbb{R}^{n \times n}$ 和一个度矩阵 $\mathbf{D} \in \mathbb{R}^{n \times n}$,广义图扩散的两个实例:Personalized PageRank (PPR) 和 heat kernel,定义为:
$\mathbf{T}=\mathbf{A} \mathbf{D}^{-1}$
$\theta_{k}=\alpha(1-\alpha)^{k}$
$\theta_{k}=e^{-t} t^{k} / k !$
其中:$\alpha$ 表示随机游走的传送概率, $t$ 是扩散时间。
heat 和 PPR 扩散的封闭解分别如下所示:
$\mathbf{S}^{\text {heat }}=\exp \left(t \mathbf{A} \mathbf{D}^{-1}-t\right) \quad\quad\quad\quad(2)$
$\mathbf{S}^{\mathrm{PPR}}=\alpha\left(\mathbf{I}_{n}-(1-\alpha) \mathbf{D}^{-1 / 2} \mathbf{A} \mathbf{D}^{-1 / 2}\right)^{-1}\quad\quad\quad\quad(3)$
子采样
从一个视图中随机抽样节点及其边,并从另一个视图中选择一样的的节点和边。
3.2 Encoders
作者为每个视图使用一个专用的图编码器(本文采用GCN编码器),分别是 $g_{\theta}(.), g_{\omega}(.): \mathbb{R}^{n \times d_{x}} \times \mathbb{R}^{n \times n} \longmapsto\mathbb{R}^{n \times d_{h}}$。
作者将邻接矩阵和扩散矩阵作为两个结构一致的视图,用于学习每个视图的节点表示,将 GCN 层分别定义为:
$\sigma(\tilde{\mathbf{A}} \mathbf{X} \Theta)$
$\sigma(\mathbf{S} \mathbf{X} \Theta)$
其中
-
- $\tilde{\mathbf{A}}=\hat{\mathbf{D}}^{-1 / 2} \hat{\mathbf{A}} \hat{\mathbf{D}}^{-1 / 2} \in \mathbb{R}^{n \times n}$;
- $\mathbf{S} \in \mathbb{R}^{n \times n}$ 是扩散矩阵;
- $\mathbf{X} \in \mathbb{R}^{n \times d_{x}}$ 是特征矩阵;
- $\Theta \in \mathbb{R}^{d_{x} \times d_{h}}$ 是网络参数矩阵;
- $\sigma$ 是非线性映射 ReLU (PReLU) ;
学习到的表示被喂入到共享的 MLP 映射头(2层+使用 PReLU 激活函数):$f_{\psi}(.): \mathbb{R}^{n \times d_{h}} \longmapsto \mathbb{R}^{n \times d_{h}}$,最后生成各自对应的节点表示 $\mathbf{H}^{\alpha}, \mathbf{H}^{\beta} \in \mathbb{R}^{n \times d_{h}}$ 。

为得到图级别的表示,Readout ($\mathcal{P}(.): \mathbb{R}^{n \times d_{h}} \longmapsto \mathbb{R}^{d_{h}}$)函数拼接每个 GCN 层的节点表示的总和,然后将其送入全职共享的 $2$ 层前馈网络,使获得的图表示与节点表示的维数大小一致:
$\vec{h}_{g}=\sigma\left(\|_{l=1}^{L}\left[\sum\limits _{i=1}^{n} \vec{h}_{i}^{(l)}\right] \mathbf{W}\right) \in \mathbb{R}^{d_{h}}\quad\quad\quad\quad(4)$
其中:
-
- $\vec{h}_{i}^{(l)}$ 节点 $\text{i}$ 第 $\text{l}$ 层的潜在表示;
- $\|$ 是拼接操作;
- $\text{L}$ 代表 $\mathrm{GCN}$ 的层数;
- $\mathbf{W} \in \mathbb{R}^{\left(L \times d_{h}\right) \times d_{h}}$ 是网络权值矩阵;
- $\sigma$ 是 PReLU 非线性映射;
最后得到图表示 $\vec{h}_{g}^{\alpha}, \vec{h}_{g}^{\beta} \in \mathbb{R}^{d_{h}}$ 。推断时,通过加和聚合每个视图的表示(节点级和图级) : $\vec{h}=\vec{h}_{g}^{\alpha}+\vec{h}_{g}^{\beta} \in \mathbb{R}^{n} $、$\mathbf{H}=\mathbf{H}^{\alpha}+\mathbf{H}^{\beta} \in \mathbb{R}^{n \times d_{h}} $ ,作为节点和图的表示应用在下游任务上。
3.3 Training
最后一步,训练。我们将一个视图的节点表示与另一个视图的图表示进行对比,另一组也是这样。利用 deep infomax 的方法,最大化两个视图之间的互信息。互信息MI可以看作一个鉴别器模型,对节点表示和图表示之间的一致性进行评分。以上就是正样本的学习过程。在对比学习中,负样本的选取也是极为重要的。我们通过随机特征值换的方法,打乱节点的特征矩阵来生成负样本,完成对比学习。
$\underset{\theta, \omega, \phi, \psi}{\text{max}}\frac{1}{|\mathcal{G}|} \sum\limits _{g \in \mathcal{G}}\left[\frac{1}{|g|} \sum\limits _{i=1}^{|g|}\left[\mathbf{M I}\left(\vec{h}_{i}^{\alpha}, \vec{h}_{g}^{\beta}\right)+\operatorname{MI}\left(\vec{h}_{i}^{\beta}, \vec{h}_{g}^{\alpha}\right)\right]\right]\quad\quad\quad\quad(5)$
其中:
-
- $\theta$,$\omega$,$\phi$,$\psi$ 是图编码器和映射头的参数;
- $|\mathcal{G}|$ 是图的数目;
- $|g| $ 是节点的数目;
- $\vec{h}_{i}^{\alpha}, \vec{h}_{g}^{\beta}$ 是节点 $ i$ 和图 $g$ 在 $\alpha$, $\beta $ 视角下的表示。
互信息作为为判别器
$\mathcal{D}(., .): \mathbb{R}^{d_{h}} \times \mathbb{R}^{d_{h}} \longmapsto \mathbb{R}$ ,简单地将判别器实现为两个表示之间的点积: $\mathcal{D}\left(\vec{h}_{n}, \vec{h}_{g}\right)=\vec{h}_{n} \cdot \vec{h}_{g}^{T} $
当判别器和投影头被整合到双线性层时,节点分类数据集略有改善。为了确定 MI 估计器,研究了四个互信息估计器,并为每个数据集选择了最好的一个。从联合分布 $x_{p} \sim p\left(\left[\mathbf{X}, \tau_{\alpha}(\mathbf{A})\right],\left[\mathbf{X}, \tau_{\beta}(\mathbf{A})\right]\right)$ 中提供正样本,从边际乘积中 $x_{n} \sim p\left(\left[\mathbf{X}, \tau_{\alpha}(\mathbf{A})\right],\left[\mathbf{X}, \tau_{\beta}(\mathbf{A})\right]\right)$ 提供负样本。利用小批量随机梯度下降法对模型参数进行优化。假设一组训练图化。假设一组训练图 $\mathcal{G}$,采样图 $g=(\mathbf{A}, \mathbf{X}) \in \mathcal{G}$,视图表示学习算法总结如下:

4 Experimental Results
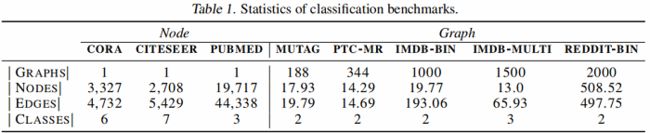
4.1 Benchmarks
4.2 Comparison with State-of-the-Art
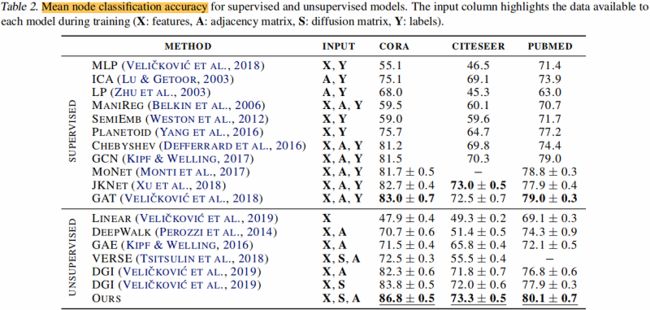
在线性评估协议下评估节点分类
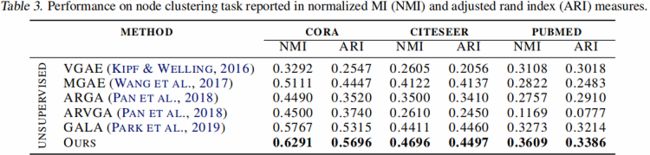
评价聚类算法下的节点分类
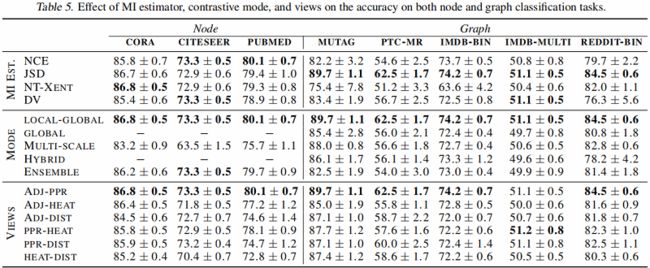
在线性评价协议下评估图分类

不同对比模式的效果
论文考虑了五种对比模式:
-
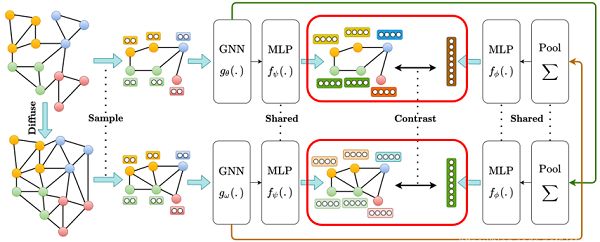
- local-global:对比一个视角的节点编码与另一个视角的图编码;
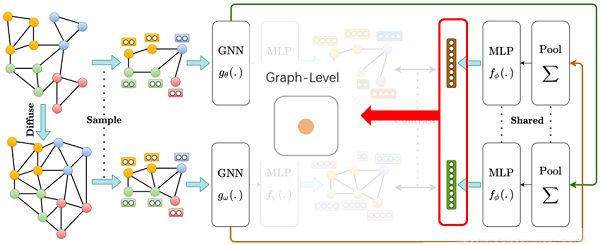
- global-global:对比不同视角的图编码;
- multi-scale:对比来自一个视图的图编码与来自另一个视图的中间编码;使用 DiffPool 层计算中间编码;
- hybrid:使用 local-global 和 global-global 模式;
- ensemble modes:对所有视图,从相同视图对比节点和图编码。
参考论文