Sensor/组织: Uber
Status: Reading
Summary: 非常棒!端到端输出map中间态 一种建图 感知 预测 规划的通用框架
Type: CVPR
Year: 2021
引用量: 20
-
参考与前言
论文链接:
https://openaccess.thecvf.com/content/CVPR2021/papers/Casas_MP3_A_Unified_Model_To_Map_Perceive_Predict_and_Plan_CVPR_2021_paper.pdf
arxiv上链接(CVPR那个链接缺少附录 ):
MP3: A Unified Model to Map, Perceive, Predict and Plan
1. Motivation
HD Map有相当丰富的语义信息比如lanes,crosswalks,traffic lights等等的拓扑和信息。这些信息给 感知和motion forecast任务 提供了很多先验信息。但是
- 人为制作hd map是非常cost的,而且还需要实时去根据道路维护hd map
- 即使是持续维护hd map,在运行过程中也要保证有厘米级的定位
由此本文提出一种端到端方法 去表达map中间态,同时能在定位失效的情况下整个车辆的运行
问题场景
在没有HD Map的场景下进行自动驾驶任务是比较困难的,比如感知就损失了先验信息,比如道路上更多的是车,行人横穿马路的crosswalk位置等。而更重要的是规划模块大部分时候需要一个地图先验进行车道中心线的跟随。如果没有HD Map的话 SDV(自动驾驶车辆)应该能有能力根据场景内容进行High-level command的输出
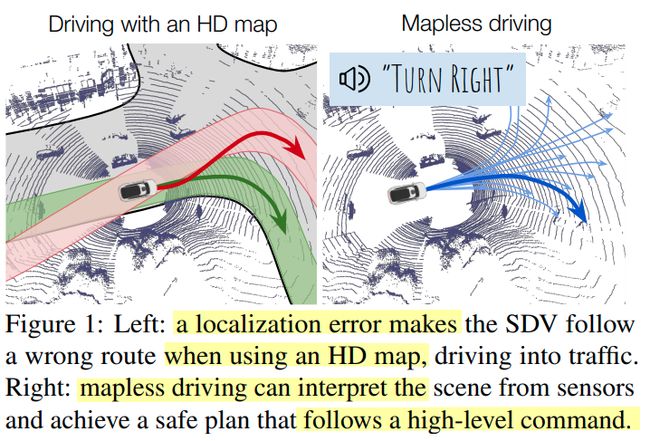
相关工作对于端到端的基本都是直接收到所有传感器数据进入网络输出动作,并没有一种中间表达态,而这一层存在的意义也很重要:
- interpretability 对于自动驾驶系统的可解释性
- 直接的端到端形式 缺乏整体结构和先验知识的有效利用 brittle to distribution shift [44]
论文相关工作部分着重介绍了online mapping, perception, prediction and motion planning各个子模块的工作同时分析他们如何在端到端的下游中起到作用
Contribution
提出了一种 针对端到端任务下的 mapless drivining approach 使得整个过程具有更多可解释性,不会有information loss,而且对于中间态表达的不确定性 也有一定解释。主要方法步骤看下部分和框图基本能理解个大概
发现CV会好像论文介绍后 也可以不总结贡献哎
问题区
-
does not incur any information loss
这点怎么证明?... 怎么说明没有information loss 或是其他方法有 信息损失呢?
2. Method
- 提出了使用probabilistic spatial layers去建模环境内的静态和动态部分,其中
- 静态部分是以规划为中心的online mapping,提取处那些区域可以进行驾驶和相关的交通信息(比如红绿灯 限速等)
- 动态部分主要是其他道路交通参与者,用一个novel occupancy flow来提供随时间 occupancy和 其速度信息。
- 随后走到motion planning模块进行retrieve dynamically feasible trajectories,预测地图上的spatial mask以给出SDV一条能走的路,同时使用online mapping和occupancy flow用来作为计算可解释性的safe planning cost

整体框架
- 其中 retrieval-based trajectory sampler是从专家的演示中学习到的一种sampler吗?不是model-based?
2.1 LiDAR
首先对比其他直接输入一帧雷达点云不同之处,这里是exploits a history of LiDAR point clouds 以提取场景此时间下 更丰富的几何和语义特征点
参考[30] 将 \(T_p=10\) 历史LiDAR点弄成BEV 也就是1秒内的所有激光雷达点,然后以 \(a=0.2m/\text{voxel}\) 的分辨率进行voxelized处理,ROI为 \(W=140m\) 前后各70m,\(H=80\),左右各40和 \(Z=10\) 高5m,然后参考[9]将高度和时间作为单独的通道 以避免使用三维卷积 saving memory and 减少计算时间。所以整个 3D tensor是:\(\left(\frac{H}{a}, \frac{W}{a}, \frac{Z}{a} \cdot T_{p}\right)\)
下图橙黄部分为LiDAR对应网络框架,同时结合了[9,52]来进行的提取场景中的几何、语义和motion信息

2.2 Scene Representations
主要是用来给出环境信息的一定先验,并在这层输出可视化,再有问题出现时,有一定的可解释性。同时包含对静态环境的预测=online map,和预测动态障碍物位置和速度=dynamics occupancy field
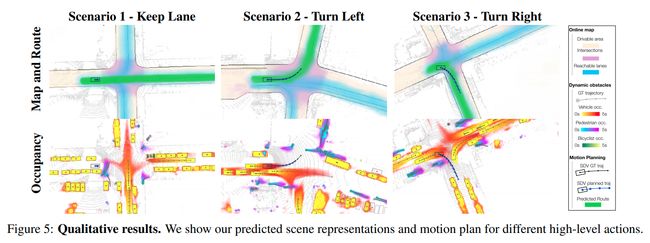
下图三为相关的可视化表达,同时因为传感器感知的局限性,考虑不确定性来评估SDV可能出现的危险也是很重要的;图四为dynamic occupancy field的建立过程

online map:主要包含可行驶区域(drivable area),可到达道路(reachable lanes),交叉路口(intersection);正常情况下 我们希望SDV尽可能接近reachable lanes,也就是道路中心线,交叉路口主要帮助理解红绿灯,停车和让行等标志
dynamic occupancy field:主要是帮助SDV理解其他道路参与者,如图四所示,先进行实际的栅格占据,再根据预测的路径进行flow的添加,BEV 0.4m/pixel 分辨率,包含:初始栅格(Initial occupancy),temporal motion field‘;需要注意的是 对 vehicles, pedestrains and bikes 进行了分类 各自都有自己的occupancy flow
从下部分图八中对应到上面的整体框图,可以看到感知和预测模块的整个网络框架细节部分
概率模型
作用:reason about uncertainty in our online map and dynamic occupancy filed,主要就是解释occupancy flow整个的建立过程
下面为notation与公式细节
- 如图三所示 每个map都是自己的语义通道,定义为\(\mathcal M\)
- 用 \(i\) 表明 spatial index
- drivable area 和 交叉路口 通道分别用 \(\mathcal{M}_{i}^{A} \text { and } \mathcal{M}_{i}^{I}\) Bernoulli random variables 伯努利分布
- 将SDV到车道中心线的距离model as 拉普拉斯算子 \(\mathcal{M}_{i}^{D}\),因为作者发现比Gaussian更准确
- 将SDV到最近车道中心线的方向 表示为 \(\mathcal{M}_{i}^{\theta}\) 用Von Mises 分布 因为范围可以从 -pi到pi
- 前面提到了 会对动态障碍物进行分类 \(\mathcal O^c\) 其中c为class 包含:车辆、行人、骑自行车的人 \(\mathcal O^c_{t,i}\) 为类c下 spatio temporal index t,i 的Bernoulli random variables
- 对每个类别在每个 spatio-temporal location进行建分布:\(\mathcal{K}_{t, i}^{c}\) over K BEV motion vectors \(\left\{\mathcal{V}_{t, i, k}^{c}: k \in 1 \ldots K\right\}\)
终于介绍完了 emmm 接着直接走到公式:在连续时间 t 和 \(t+1\) 时从位置 \(i_1\) 到位置 \(i_2\) 的 对应整体occupancy flow的概率为:
其中 \(p\left(\mathcal{V}_{t, i_{1}, k}^{c}=i_{2}\right)\) 如果位置 \(i_2\) 在连续motion vector附近的4个格的话,使用的是线性插值;否则直接为0 如图四部分,这里是对整体 F occupancy flow,下面为单个格 \(i\) 在时间 \(t+1\) 下 从 t 转过来的所有格 \(j\) 的概率:
如果好奇如何推导的建议查附录,这里就不展开了... 因为看起来问题不大:二项分布 有无 & 连乘得大图
2.3 Motion Planning
这一部分有对不确定性的score加入,然后向整体框图那样 根据所有的来进行选择一个最小的cost。下图为对应细节框架设计

Trajectory Sampling
一开始看的时候... 我还以为是model-based,细看是从large-dataset学到的采样(不用网络)。
-
从数据集里提取出车辆轨迹,一共150个小时的manual driving data
-
聚类(因为高效)每个轨迹的bin包含当前SDV的速度、加速度和曲率
使用初始 速度、曲率和加速度 对应每个bin size为 2.0 (m/s), 0.02 (1/m), 1.0 (m/s^2),去将轨迹分类成不同的bins;每个bin中的轨迹都会被聚类成3000个sets,然后 closest trajectories to cluster prototype 会被保留
-
再加上速度和曲率放入自行车模型 给一遍 rollout 来生成连续速度和转角的轨迹。

如上网络 输入online map和纵向的距离,然后加上high-level action,\(c=(a,d)\) 其中a包含 keep lane, 左转,右转。这里手动给GPS加了(0,5)的高斯噪音
Scoring Cost
最后所有的东西都到了这一步来输出实际车辆要运行的那条轨迹,也就是cost最低的,一共有三个指标:routing and driving on roads、safety、comfort
Routing and Driving on Roads
有以下几条
-
为鼓励SDV执行high-level command,使用评分函数使得SDV 在 \(\mathcal R\) 中概率较高的区域行驶更远距离的轨迹
\[f_{r}(\tau, \mathcal{R})=-m(\tau) \min _{i \in m(\tau)} \mathcal{R}_{i} \]其中 \(m(\tau)\) 是指 BEV下 SDV选择轨迹 \(\tau\) 所占领的grid cells。用上述 scoring function 可以确保 SDV 保持在路线上,并且仅在路线内移动时才会获得奖励。
-
引入了一个cost-to-go,来应对超出计划范围的预测路线,对于尽头转弯或者车辆高速下比较有用。具体来说,假设 SDV 保持恒定的速度和航向,我们计算所有与 SDV 重叠的 BEV 网格单元 j 的平均值 \(1-R_j\)
-
为确保SDV行驶在道路中心线上,use the predicted reachable lanes distance transform \(\mathcal M^D\) 去对轨迹点进行penalize。
-
同时为了考虑 \(\mathcal M^D\) 和 \(\mathcal M^\theta\) 上的不确定性,使用 cost function: product of SDV velocity and standard deviation of gird cells,即 \(\mathcal M^D\) 和 \(\mathcal M^\theta\) 下 SDV 所占领的那些格
\[f_{d}\left(\mathbf{x}, \mathcal{M}^{\theta}, \mathcal{M}^{D}\right)=\sum_{i \in m(\mathbf{x})} \mathbf{x}_{v}\left(\sigma_{i}^{D}+\frac{1}{k_{i}^{\theta}}\right) \]其中 \(k_i^\theta\) is the concentration parameter of the von Mises distribution representing lane direction
-
使用一个penalize 约束SDV在道路上,不去碰撞边缘
\[f_{a}(\mathbf{x}, \mathcal{M})=\max _{i \in m(\mathbf{x})}\left[1-P\left(\mathcal{M}_{i}^{A}\right)\right] \] -
再加一个交叉路口的红绿灯cost,之间使用predicted junction probability map \(\mathcal M^J\) 对闯红灯的行为进行惩罚
Safety
即对SDV overlaps occupied regions进行惩罚,对于那些没有重合的 但是距离障碍物太近的轨迹点 \(\mathbf x\),根据距离和SDV现在的速度进行刹车计算来measure the violation of safety distance,对于comfrotable deceleration的状态为 \(\mathbf x_t\)
其中 \(m(\mathbf{x}_{t})\) 表示BEV grid-cells,对应 \(c\) 为语义的class that overlap 在状态 \(\mathbf x_t\) 下的SDV多边形
Comfort
对jerk, 横向加速度,曲率和曲率变化率进行comfortable driving的定义
问题区
-
原文中 safety和comfort 好像没有很多解释 emm
附录有部分公式
-
而且 对于中心线上的 附录使用的direction进行的约束,但是正文是距离?
\[f_{d}(\mathbf{x}, \mathcal{M})=\underset{i \in m(\mathbf{x})}{\mathbb{E}}\left|\mathcal{M}_{i}^{\theta}-\mathbf{x}_{\theta}\right| \]
2.4 Training Loss
像GRI和MaRLn一样 是两个阶段的loss回馈,这样训练整个任务的效果会好很多
第一阶段: Multi-task 多任务学习下的 loss
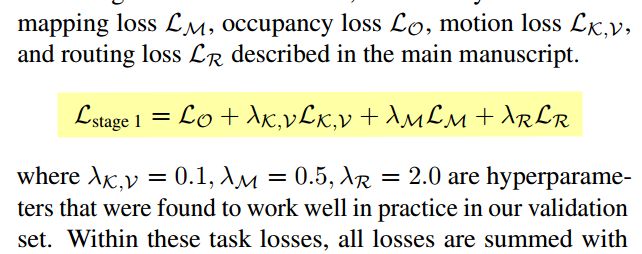
第二阶段: Trajectory Scoring的

更多详情见arxiv上的论文主页附录
3. 实验
直接摘取了论文里的表格和图,从数字看来这个效果提升很大啊,成功率直接飙升
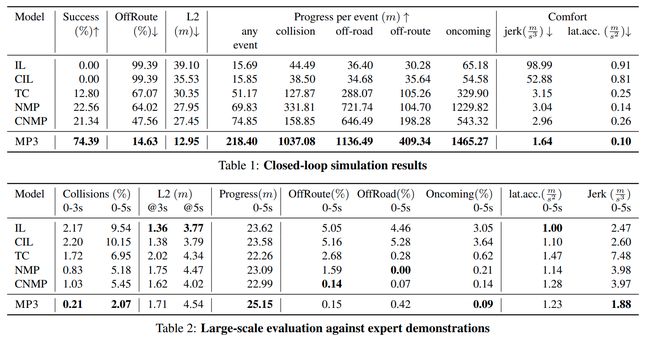
在附录里,做了很多个消融实验,这个工作量也挺大的,可惜没开 hhh 附录里也做了将HD Map加到Motion plan的地方进行的对比
4. Conclusion
也直接摘取了 和前面方法总结基本一致,可以看看:

整体来说 这篇工作虽然没有开源,但是很完整,可以说非常完整。从方法设计,到为什么要提出一个模块部分,motivation非常好。整篇文章讲的也很好,算是近期看过的第一名了
碎碎念
这个... 工作好棒啊,看到过程 特别是occupancy flow那个处理 很聪明,妙啊.. 甚至整条方法链感觉比LAV更完善一点,虽然这个不开源,公司做的嘛.. 向来都是不开源,而且数据集好像也没引用 是自己的数据集,所以不如LAV 开源的这种 直接对着代码 更爽点。不过有一点是 MP3 本文的方法讲的很仔细,包括附录的网络图和一些参数,仔细到 大佬们 应该能照着复现。感谢杰哥组会指出这篇 hhh 漏网之鱼
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh