机器学习复习
七月的博客还有很多数据结构基础知识,很多面试题,写的非常好,其七月在线app很多课程也很不错。
这只是部分题,后面还有题目。见http://mp.weixin.qq.com/s/C99b32MyrnEVggRAECetUA
本文原文链接:
http://m.blog.csdn.net/v_JULY_v/article/details/78121924
整理:七月在线July、德伟、立娜、孟莹、贾茹等众人。本系列大部分题目来源于公开网络,且注明来源链接。
说明:本系列自2017年9月28日开始,每周持续更新。首发于七月在线实验室公众号上:julyedulab,并同步更新于本博客上。另,可以转载,注明来源链接即可。
———————————————————————————————————————————————————————————————————————————-
前言
July我又回来了。
之前本博客整理过数千道微软等公司的面试题,侧重数据结构、算法、海量数据处理,详见:微软面试100题系列,今17年,近期和团队整理BAT机器学习面试1000题系列,侧重机器学习、深度学习。我们将通过这个系列索引绝大部分机器学习和深度学习的笔试面试题、知识点,它将是一个足够庞大的机器学习和深度学习面试库/知识库,通俗成体系且循序渐进。
- 虽然本系列主要是机器学习、深度学习相关的考题,其他类型的题不多,但不代表应聘机器学习或深度学习的岗位时,公司或面试官就只问这两项,虽说是做数据或AI相关,但基本的语言(比如Python)、编码coding能力(对于开发,编码coding能力怎么强调都不过分,比如最简单的手写快速排序、手写二分查找)、数据结构、算法、计算机体系结构、操作系统、概率统计等等也必须掌握。对于数据结构和算法,一者 重点推荐前面说的微软面试100题系列(后来这个系列整理成了新书《编程之法:面试和算法心得》),二者 多刷leetcode,看1000道题不如实际动手刷100道。
- 本系列会尽量让考察同一个部分(比如同是模型/算法相关的)、同一个方向(比如同是属于最优化的算法)的题整理到一块,为的是让大家做到举一反三、构建完整知识体系,在准备笔试面试的过程中,通过懂一题懂一片。
- 本系列每一道题的答案都会确保逻辑清晰、通俗易懂(当你学习某个知识点感觉学不懂时,十有八九不是你不够聪明,十有八九是你所看的资料不够通俗、不够易懂),如有更好意见,欢迎在评论下共同探讨。
- 关于如何学习机器学习,最推荐机器学习集训营系列。从Python基础、数据分析、爬虫,到数据可视化、spark大数据,最后实战机器学习、深度学习等一应俱全。
BAT机器学习面试1000题系列
- 请简要介绍下SVMSVM,全称是support vector machine,中文名叫支持向量机。SVM是一个面向数据的分类算法,它的目标是为确定一个分类超平面,从而将不同的数据分隔开。
扩展:这里有篇文章详尽介绍了SVM的原理、推导,《支持向量机通俗导论(理解SVM的三层境界)》。此外,这里有个视频也是关于SVM的推导:《纯白板手推SVM》 - 请简要介绍下tensorflow的计算图
@寒小阳:Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。

- 在k-means或kNN,我们常用欧氏距离来计算最近的邻居之间的距离,有时也用曼哈顿距离,请对比下这两种距离的差别。
欧氏距离,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,…,xn) 和 y = (y1,…,yn) 之间的距离为: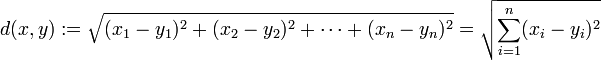
- 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为:
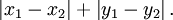 ,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
通俗来讲,想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。而实际驾驶距离就是这个“曼哈顿距离”,这也是曼哈顿距离名称的来源, 同时,曼哈顿距离也称为城市街区距离(City Block distance)。另,关于各种距离的比较参看《从K近邻算法、距离度量谈到KD树、SIFT+BBF算法》。 - 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为:
- 百度2015校招机器学习笔试题
http://www.itmian4.com/thread-7042-1-1.html
- 关于LR@rickjin:把LR从头到脚都给讲一遍。建模,现场数学推导,每种解法的原理,正则化,LR和maxent模型啥关系,lr为啥比线性回归好。有不少会背答案的人,问逻辑细节就糊涂了。原理都会? 那就问工程,并行化怎么做,有几种并行化方式,读过哪些开源的实现。还会,那就准备收了吧,顺便逼问LR模型发展历史。
 另外,这两篇文章可以做下参考:Logistic Regression 的前世今生(理论篇)、机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)。
另外,这两篇文章可以做下参考:Logistic Regression 的前世今生(理论篇)、机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)。 - overfitting怎么解决:
dropout、regularization、batch normalizatin - LR和SVM的联系与区别
@朝阳在望,联系:
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
来源:http://blog.csdn.net/timcompp/article/details/62237986 - 说说你知道的核函数
通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:
- 多项式核
,显然刚才我们举的例子是这里多项式核的一个特例(R = 1,d = 2)。虽然比较麻烦,而且没有必要,不过这个核所对应的映射实际上是可以写出来的,该空间的维度是
 ,其中
,其中  是原始空间的维度。
是原始空间的维度。 - 高斯核
 ,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果
,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
- 线性核
 ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
- 多项式核
- LR与线性回归的区别与联系
@nishizhen:个人感觉逻辑回归和线性回归首先都是广义的线性回归,
其次经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数,
另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,逻辑回归的鲁棒性比线性回归的要好。
@乖乖癞皮狗:逻辑回归的模型本质上是一个线性回归模型,逻辑回归都是以线性回归为理论支持的。但线性回归模型无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。
- 请问(决策树、Random Forest、Booting、Adaboot)GBDT和XGBoost的区别是什么?
关于决策树,这里有篇《决策树算法》。而随机森林Random Forest是一个包含多个决策树的分类器。至于AdaBoost,则是英文”Adaptive Boosting”(自适应增强)的缩写,关于AdaBoost可以看下这篇文章《Adaboost 算法的原理与推导》。GBDT(Gradient Boosting Decision Tree),即梯度上升决策树算法,相当于融合决策树和梯度上升boosting算法。
@Xijun LI:xgboost类似于gbdt的优化版,不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:
1.损失函数是用泰勒展式二项逼近,而不是像gbdt里的就是一阶导数
2.对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性
3.节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
更多详见:https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/ - 为什么xgboost要用泰勒展开,优势在哪里?
@AntZ:xgboost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得二阶倒数形式, 可以在不选定损失函数具体形式的情况下用于算法优化分析.本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了xgboost的适用性。
- xgboost如何寻找最优特征?是又放回还是无放回的呢?
@AntZ:xgboost在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性. xgboost利用梯度优化模型算法, 样本是不放回的(想象一个样本连续重复抽出,梯度来回踏步会不会高兴). 但xgboost支持子采样, 也就是每轮计算可以不使用全部样本。
- 谈谈判别式模型和生成式模型?
判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机 - L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
- L1和L2正则先验分别服从什么分布
@齐同学:面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
-
CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
@许韩,来源:https://zhuanlan.zhihu.com/p/25005808
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。
CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图: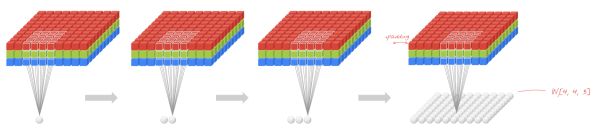
上图中,如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
另,关于CNN,这里有篇文章《 CNN笔记:通俗理解卷积神经网络》。 - 说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2…,请写出最终的决策公式。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例
 ,而实例空间
,而实例空间 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, …, M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):
b. 计算Gm(x)在训练数据集上的分类误差率
由上述式子可知,Gm(x)在训练数据集上的 误差率em就是被Gm(x)误分类样本的权值之和。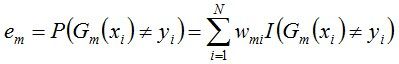 c. 计算Gm(x)的系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
c. 计算Gm(x)的系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。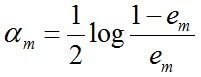
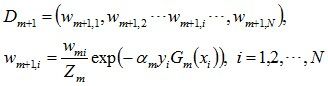
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器
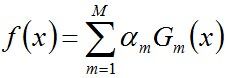
从而得到最终分类器,如下:
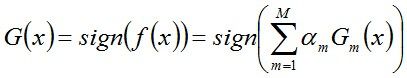
更多请查看此文:《Adaboost 算法的原理与推导》。 -
LSTM结构推导,为什么比RNN好?
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸 -
经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会提示你是不是要输入某一个正确的单词,比如当你在Google中输入“Julw”时,系统会猜测你的意图:是不是要搜索“July”,如下图所示:
这叫做拼写检查。根据谷歌一员工写的文章显示,Google的拼写检查基于贝叶斯方法。请说说的你的理解,具体Google是怎么利用贝叶斯方法,实现”拼写检查”的功能。
用户输入一个单词时,可能拼写正确,也可能拼写错误。如果把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong),那么”拼写检查”要做的事情就是:在发生w的情况下,试图推断出c。换言之:已知w,然后在若干个备选方案中,找出可能性最大的那个c,也就是求
 的最大值。
的最大值。
而根据贝叶斯定理,有:

由于对于所有备选的c来说,对应的都是同一个w,所以它们的P(w)是相同的,因此我们只要最大化

即可。其中:
- P(c)表示某个正确的词的出现”概率”,它可以用”频率”代替。如果我们有一个足够大的文本库,那么这个文本库中每个单词的出现频率,就相当于它的发生概率。某个词的出现频率越高,P(c)就越大。比如在你输入一个错误的词“Julw”时,系统更倾向于去猜测你可能想输入的词是“July”,而不是“Jult”,因为“July”更常见。
- P(w|c)表示在试图拼写c的情况下,出现拼写错误w的概率。为了简化问题,假定两个单词在字形上越接近,就有越可能拼错,P(w|c)就越大。举例来说,相差一个字母的拼法,就比相差两个字母的拼法,发生概率更高。你想拼写单词July,那么错误拼成Julw(相差一个字母)的可能性,就比拼成Jullw高(相差两个字母)。值得一提的是,一般把这种问题称为“编辑距离”,参见博客中的这篇文章。
-
为什么朴素贝叶斯如此“朴素”?
因为它假定所有的特征在数据集中的作用是同样重要和独立的。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。
-
请大致对比下plsa和LDA的区别
- pLSA中,主题分布和词分布确定后,以一定的概率(
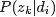 、
、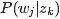 )分别选取具体的主题和词项,生成好文档。而后根据生成好的文档反推其主题分布、词分布时,最终用EM算法(极大似然估计思想)求解出了两个未知但固定的参数的值:
)分别选取具体的主题和词项,生成好文档。而后根据生成好的文档反推其主题分布、词分布时,最终用EM算法(极大似然估计思想)求解出了两个未知但固定的参数的值: (由转换而来)和
(由转换而来)和 (由转换而来)。
(由转换而来)。
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
- 举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示(图截取自沈博PPT上):
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
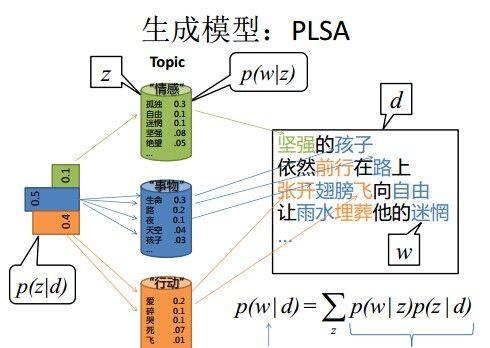
- 但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
- 还是再次举下文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示(图截取自沈博PPT上):
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
 更多请参见:《通俗理解LDA主题模型》。换言之,LDA在pLSA的基础上给这两参数 ( 、
)加了两个先验分布的参数( 贝叶斯化):一个主题分布的先验分布 Dirichlet分布
更多请参见:《通俗理解LDA主题模型》。换言之,LDA在pLSA的基础上给这两参数 ( 、
)加了两个先验分布的参数( 贝叶斯化):一个主题分布的先验分布 Dirichlet分布
 ,和一个词语分布的先验分布 Dirichlet分布
,和一个词语分布的先验分布 Dirichlet分布
 。
综上,LDA真的只是pLSA的贝叶斯版本,文档生成后,两者都要根据文档去推断其主题分布和词语分布,只是用的参数推断方法不同,在pLSA中用极大似然估计的思想去推断两未知的固定参数,而LDA则把这两参数弄成随机变量,且加入dirichlet先验。
。
综上,LDA真的只是pLSA的贝叶斯版本,文档生成后,两者都要根据文档去推断其主题分布和词语分布,只是用的参数推断方法不同,在pLSA中用极大似然估计的思想去推断两未知的固定参数,而LDA则把这两参数弄成随机变量,且加入dirichlet先验。
- pLSA中,主题分布和词分布确定后,以一定的概率(
-
请简要说说EM算法
@tornadomeet,本题解析来源:http://www.cnblogs.com/tornadomeet/p/3395593.html
有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个),EM算法一般分为2步:E步:选取一组参数,求出在该参数下隐含变量的条件概率值;
M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。
重复上面2步直至收敛。
公式如下所示:
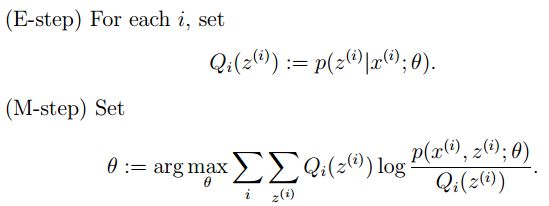
M步公式中下界函数的推导过程:
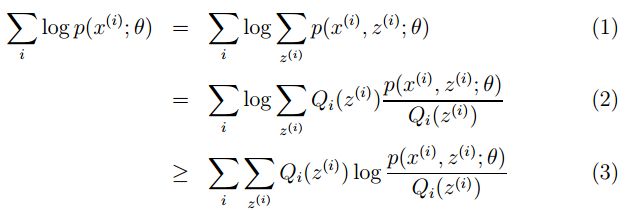
EM算法一个常见的例子就是GMM模型,每个样本都有可能由k个高斯产生,只不过由每个高斯产生的概率不同而已,因此每个样本都有对应的高斯分布(k个中的某一个),此时的隐含变量就是每个样本对应的某个高斯分布。
GMM的E步公式如下(计算每个样本对应每个高斯的概率):
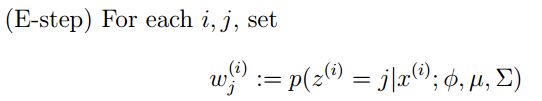
更具体的计算公式为:
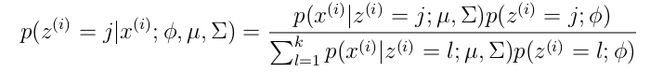
M步公式如下(计算每个高斯的比重,均值,方差这3个参数):

-
KNN中的K如何选取的?
关于什么是KNN,可以查看此文:《从K近邻算法、距离度量谈到KD树、SIFT+BBF算法》。KNN中的K值选取对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用 交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。 -
防止过拟合的方法
过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。
处理方法:- 早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- 数据集扩增:原有数据增加、原有数据加随机噪声、重采样
- 正则化
- 交叉验证
- 特征选择/特征降维
-
机器学习中,为何要经常对数据做归一化
@
zhanlijun,本题解析来源:http://www.cnblogs.com/LBSer/p/4440590.html
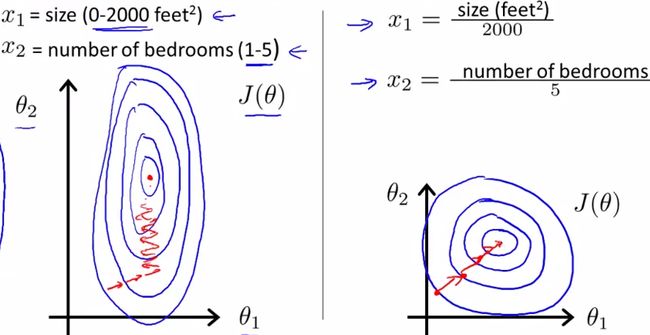
机器学习模型被互联网行业广泛应用,如排序(参见:排序学习实践)、推荐、反作弊、定位(参见:基于朴素贝叶斯的定位算法)等。一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?很多同学并未搞清楚,维基百科给出的解释:1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。下面再简单扩展解释下这两点。
1 归一化为什么能提高梯度下降法求解最优解的速度?
斯坦福机器学习视频做了很好的解释:https://class.coursera.org/ml-003/lecture/21
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2 归一化有可能提高精度
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
3 归一化的类型
1)线性归一化
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
2)标准差标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
3)非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
-
谈谈深度学习中的归一化问题

详情参见此视频:《深度学习中的归一化》。 -
哪些机器学习算法不需要做归一化处理?
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
@管博士:我理解归一化和标准化主要是为了使计算更方便 比如两个变量的量纲不同 可能一个的数值远大于另一个那么他们同时作为变量的时候 可能会造成数值计算的问题,比如说求矩阵的逆可能很不精确 或者梯度下降法的收敛比较困难,还有如果需要计算欧式距离的话可能 量纲也需要调整 所以我估计lr 和 knn 保准话一下应该有好处。至于其他的算法 我也觉得如果变量量纲差距很大的话 先标准化一下会有好处。
@寒小阳:一般我习惯说树形模型,这里说的概率模型可能是差不多的意思。
-
对于树形结构为什么不需要归一化?
答:数值缩放,不影响分裂点位置。因为第一步都是按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。对于线性模型,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,这样运用梯度下降时候,损失等高线是一个椭圆的形状,这样我想迭代到最优点,就需要很多次迭代,但是如果进行了归一化,那么等高线就是圆形的,那么SGD就会往原点迭代,需要的迭代次数较少。
另外,注意树模型是不能进行梯度下降的,因为树模型是阶跃的,阶跃点是不可导的,并且求导没意义,所以树模型(回归树)寻找最优点事通过寻找最优分裂点完成的。
-
数据归一化(或者标准化,注意归一化和标准化不同)的原因
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
要强调:能不归一化最好不归一化,之所以进行数据归一化是因为各维度的量纲不相同。而且需要看情况进行归一化。- 有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。
- 有些模型伸缩有与原来等价,如:LR则不用归一化,但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最坏进行数据归一化。
补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。
-
请简要说说一个完整机器学习项目的流程
@寒小阳、龙心尘
1 抽象成数学问题
明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成本是非常高的。
这里的抽象成数学问题,指的我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,如果划归为其中的某类问题。
2 获取数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
数据要有代表性,否则必然会过拟合。
而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
3 特征预处理与特征选择
良好的数据要能够提取出良好的特征才能真正发挥效力。
特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。
筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
4 训练模型与调优
直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
5 模型诊断
如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。
过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题……
诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
6 模型融合
一般来说,模型融合后都能使得效果有一定提升。而且效果很好。
工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
7 上线运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
故,基于此,七月在线每一期ML算法班都特此增加特征工程、模型调优等相关课。比如,这里有个公开课视频《特征处理与特征选择》。 -
逻辑斯特回归为什么要对特征进行离散化
@严林,本题解析来源:https://www.zhihu.com/question/31989952在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
0. 离散特征的增加和减少都很容易,易于模型的快速迭代;
1. 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
2. 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
3. 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
4. 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
5. 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
6. 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
李沐曾经说过:模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
-
new 和 malloc的区别
@Sommer_Xia,来源:http://blog.csdn.net/shymi1991/article/details/39432775
1. malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
2. 对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
3. 因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
4. C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存
-
hash 冲突及解决办法
@Sommer_Xia,来源:http://blog.csdn.net/shymi1991/article/details/39432775
关键字值不同的元素可能会映象到哈希表的同一地址上就会发生哈希冲突。解决办法:
1)开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
2) 再哈希法:同时构造多个不同的哈希函数。
3)链地址法:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
4)建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。 -
下列哪个不属于CRF模型对于HMM和MEMM模型的优势(B )
A. 特征灵活 B. 速度快 C. 可容纳较多上下文信息 D. 全局最优
首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模.
隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择
最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉
条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
-
什么是熵
从名字上来看,熵给人一种很玄乎,不知道是啥的感觉。其实,熵的定义很简单,即用来表示随机变量的不确定性。之所以给人玄乎的感觉,大概是因为为何要取这样的名字,以及怎么用。
熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。
熵的引入
事实上,熵的英文原文为entropy,最初由德国物理学家鲁道夫·克劳修斯提出,其表达式为:
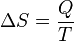
它表示一个系系统在不受外部干扰时,其内部最稳定的状态。后来一中国学者翻译entropy时,考虑到entropy是能量Q跟温度T的商,且跟火有关,便把entropy形象的翻译成“熵”。
我们知道,任何粒子的常态都是随机运动,也就是”无序运动”,如果让粒子呈现”有序化”,必须耗费能量。所以,温度(热能)可以被看作”有序化”的一种度量,而”熵”可以看作是”无序化”的度量。
如果没有外部能量输入,封闭系统趋向越来越混乱(熵越来越大)。比如,如果房间无人打扫,不可能越来越干净(有序化),只可能越来越乱(无序化)。而要让一个系统变得更有序,必须有外部能量的输入。
1948年,香农Claude E. Shannon引入信息(熵),将其定义为离散随机事件的出现概率。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以说,信息熵可以被认为是系统有序化程度的一个度量。更多请查看《最大熵模型中的数学推导》。 -
熵、联合熵、条件熵、相对熵、互信息的定义
为了更好的理解,需要了解的概率必备知识有:- 大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;
- P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示已知随机变量X的情况下随机变量Y的条件概率分布;
- p(X = x)表示随机变量X取某个具体值的概率,简记为p(x);
- p(X = x, Y = y) 表示联合概率,简记为p(x,y),p(Y = y|X = x)表示条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, …, n),则随机变量X的熵定义为:
把最前面的负号放到最后,便成了: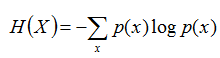
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。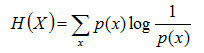
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
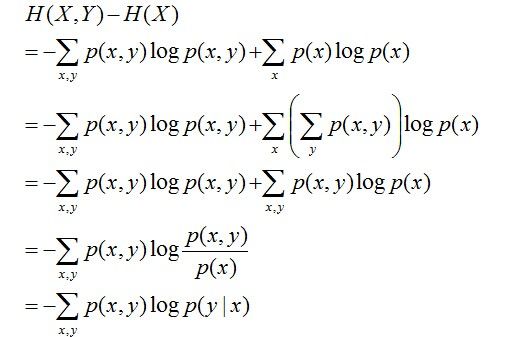
简单解释下上面的推导过程。整个式子共6行,其中
- 第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
- 第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
- 第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
- 第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
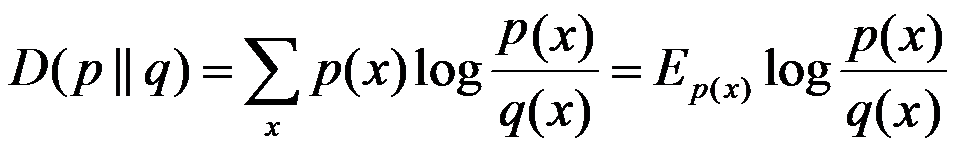
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
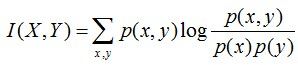
且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。更多请查看《最大熵模型中的数学推导》。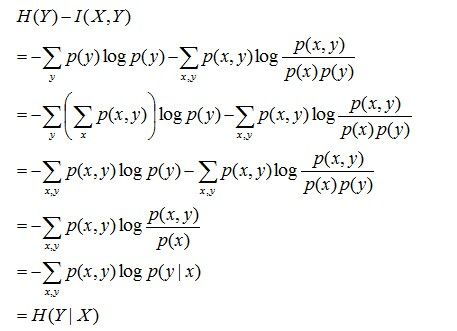
-
什么是最大熵
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵。为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。例如,投掷一个骰子,如果问”每个面朝上的概率分别是多少”,你会说是等概率,即各点出现的概率均为1/6。因为 对这个”一无所知”的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保 留了最大的不确定性,也就是说让熵达到最大。3.1 无偏原则
下面再举个大多数有关最大熵模型的文章中都喜欢举的一个例子。例如,一篇文章中出现了“学习”这个词,那这个词是主语、谓语、还是宾语呢?换言之,已知“学习”可能是动词,也可能是名词,故“学习”可以被标为主语、谓语、宾语、定语等等。- 令x1表示“学习”被标为名词, x2表示“学习”被标为动词。
- 令y1表示“学习”被标为主语, y2表示被标为谓语, y3表示宾语, y4表示定语。
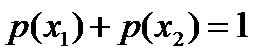 ,
,
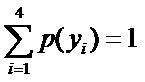 , 则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
, 则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
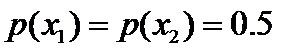
因为没有任何的先验知识,所以这种判断是合理的。如果有了一定的先验知识呢?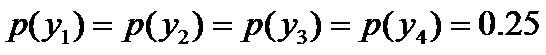
即进一步,若已知:“学习”被标为定语的可能性很小,只有0.05,即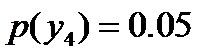 ,剩下的依然根据无偏原则,可得:
,剩下的依然根据无偏原则,可得:
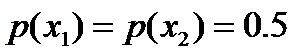
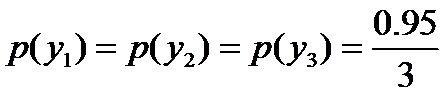 再进一步,当“学习”被标作名词x1的时候,它被标作谓语y2的概率为0.95,即
再进一步,当“学习”被标作名词x1的时候,它被标作谓语y2的概率为0.95,即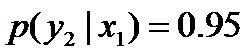 ,此时仍然需要坚持无偏见原则,使得概率分布尽量平均。但怎么样才能得到尽量无偏见的分布?
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。 比如,给定均值和方差,熵最大的分布就变成了正态分布 )。于是,问题便转化为了:计算X和Y的分布,使得H(Y|X)达到最大值,并且满足下述条件:
,此时仍然需要坚持无偏见原则,使得概率分布尽量平均。但怎么样才能得到尽量无偏见的分布?
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。 比如,给定均值和方差,熵最大的分布就变成了正态分布 )。于是,问题便转化为了:计算X和Y的分布,使得H(Y|X)达到最大值,并且满足下述条件: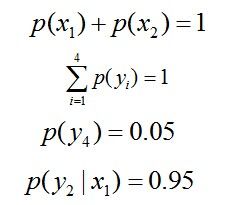
因此,也就引出了最大熵模型的本质,它要解决的问题就是已知X,计算Y的概率,且尽可能让Y的概率最大(实践中,X可能是某单词的上下文信息,Y是该单词翻译成me,I,us、we的各自概率),从而根据已有信息,尽可能最准确的推测未知信息,这就是最大熵模型所要解决的问题。
相当于已知X,计算Y的最大可能的概率,转换成公式,便是要最大化下述式子H(Y|X):

且满足以下4个约束条件:
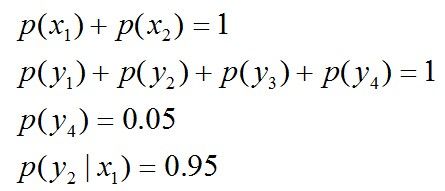
-
简单说下有监督学习和无监督学习的区别
有监督学习:对具有标记的训练样本进行学习,以尽可能对训练样本集外的数据进行分类预测。(LR,SVM,BP,RF,GBDT)
无监督学习:对未标记的样本进行训练学习,比发现这些样本中的结构知识。(KMeans,DL) -
了解正则化么
正则化是针对过拟合而提出的,以为在求解模型最优的是一般优化最小的经验风险,现在在该经验风险上加入模型复杂度这一项(正则化项是模型参数向量的范数),并使用一个rate比率来权衡模型复杂度与以往经验风险的权重,如果模型复杂度越高,结构化的经验风险会越大,现在的目标就变为了结构经验风险的最优化,可以防止模型训练过度复杂,有效的降低过拟合的风险。
奥卡姆剃刀原理,能够很好的解释已知数据并且十分简单才是最好的模型。
-
协方差和相关性有什么区别?
相关性是协方差的标准化格式。协方差本身很难做比较。例如:如果我们计算工资($)和年龄(岁)的协方差,因为这两个变量有不同的度量,所以我们会得到不能做比较的不同的协方差。为了解决这个问题,我们计算相关性来得到一个介于-1和1之间的值,就可以忽略它们各自不同的度量。
-
线性分类器与非线性分类器的区别以及优劣
如果模型是参数的线性函数,并且存在线性分类面,那么就是线性分类器,否则不是。
常见的线性分类器有:LR,贝叶斯分类,单层感知机、线性回归
常见的非线性分类器:决策树、RF、GBDT、多层感知机
SVM两种都有(看线性核还是高斯核)
线性分类器速度快、编程方便,但是可能拟合效果不会很好
非线性分类器编程复杂,但是效果拟合能力强 - 数据的逻辑存储结构(如数组,队列,树等)对于软件开发具有十分重要的影响,试对你所了解的各种存储结构从运行速度、存储效率和适用场合等方面进行简要地分析。
运行速度 存储效率 适用场合 数组 快 高 比较适合进行查找操作,还有像类似于矩阵等的操作 链表 较快 较高 比较适合增删改频繁操作,动态的分配内存 队列 较快 较高 比较适合进行任务类等的调度 栈 一般 较高 比较适合递归类程序的改写 二叉树(树) 较快 一般 一切具有层次关系的问题都可用树来描述 图 一般 一般 除了像最小生成树、最短路径、拓扑排序等经典用途。还被用于像神经网络等人工智能领域等等。 - 什么是分布式数据库?
分布式数据库系统是在集中式数据库系统成熟技术的基础上发展起来的,但不是简单地把集中式数据库分散地实现,它具有自己的性质和特征。集中式数据库系统的许多概念和技术,如数据独立性、数据共享和减少冗余度、并发控制、完整性、安全性和恢复等在分布式数据库系统中都有了不同的、更加丰富的内容。 -
简单说说贝叶斯定理。
在引出贝叶斯定理之前,先学习几个定义:- 条件概率(又称后验概率)就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。

- 联合概率表示两个事件共同发生的概率。A与B的联合概率表示为
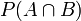 或者
或者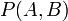 。
。 - 边缘概率(又称先验概率)是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
接着,考虑一个问题:P(A|B)是在B发生的情况下A发生的可能性。
- 首先,事件B发生之前,我们对事件A的发生有一个基本的概率判断,称为A的先验概率,用P(A)表示;
- 其次,事件B发生之后,我们对事件A的发生概率重新评估,称为A的后验概率,用P(A|B)表示;
- 类似的,事件A发生之前,我们对事件B的发生有一个基本的概率判断,称为B的先验概率,用P(B)表示;
- 同样,事件A发生之后,我们对事件B的发生概率重新评估,称为B的后验概率,用P(B|A)表示。
贝叶斯定理便是基于下述贝叶斯公式:
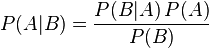
上述公式的推导其实非常简单,就是从条件概率推出。
根据条件概率的定义,在事件B发生的条件下事件A发生的概率是 同样地,在事件A发生的条件下事件B发生的概率
同样地,在事件A发生的条件下事件B发生的概率 整理与合并上述两个方程式,便可以得到:
整理与合并上述两个方程式,便可以得到: 接着,上式两边同除以P(B),若P(B)是非零的,我们便可以得到 贝叶斯定理的公式表达式:
接着,上式两边同除以P(B),若P(B)是非零的,我们便可以得到 贝叶斯定理的公式表达式:
所以,贝叶斯公式可以直接根据条件概率的定义直接推出。即因为P(A,B) = P(A)P(B|A) = P(B)P(A|B),所以P(A|B) = P(A)P(B|A) / P(B)。更多请参见此文:《从贝叶斯方法谈到贝叶斯网络》。
- #include和#include“filename.h”有什么区别?
用 #include 格式来引用标准库的头文件(编译器将从标准库目录开始搜索)。
用 #include “filename.h” 格式来引用非标准库的头文件(编译器将从用户的工作目录开始搜索)。
- 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A)
A. 关联规则发现 B. 聚类
C. 分类 D. 自然语言处理
- 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C)
A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘
- 下面哪种不属于数据预处理的方法? (D)
A变量代换 B离散化 C 聚集 D 估计遗漏值
- 什么是KDD? (A)
A. 数据挖掘与知识发现 B. 领域知识发现
C. 文档知识发现 D. 动态知识发现
- 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B)
A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链
- 建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?(C)
A. 根据内容检索 B. 建模描述
C. 预测建模 D. 寻找模式和规则
- 以下哪种方法不属于特征选择的标准方法: (D)
A嵌入 B 过滤 C 包装 D 抽样
- 请用python编写函数find_string,从文本中搜索并打印内容,要求支持通配符星号和问号。
例子:
>>>find_string(‘hello\nworld\n’,’wor’)
[‘wor’]
>>>find_string(‘hello\nworld\n’,’l*d’)
[‘ld’]
>>>find_string(‘hello\nworld\n’,’o.’)
[‘or’]
答案
def find_string(str,pat):
import re
return re.findall(pat,str,re.I) -
说下红黑树的五个性质
红黑树,一种二叉查找树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。
通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近平衡的。
红黑树,作为一棵二叉查找树,满足二叉查找树的一般性质。下面,来了解下 二叉查找树的一般性质。
二叉查找树,也称有序二叉树(ordered binary tree),或已排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
任意节点的左、右子树也分别为二叉查找树。
没有键值相等的节点(no duplicate nodes)。
因为一棵由n个结点随机构造的二叉查找树的高度为lgn,所以顺理成章,二叉查找树的一般操作的执行时间为O(lgn)。但二叉查找树若退化成了一棵具有n个结点的线性链后,则这些操作最坏情况运行时间为O(n)。
红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。
但它是如何保证一棵n个结点的红黑树的高度始终保持在logn的呢?这就引出了红黑树的5个性质:
每个结点要么是红的要么是黑的。
根结点是黑的。
每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
如果一个结点是红的,那么它的两个儿子都是黑的。
对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。
正是红黑树的这5条性质,使一棵n个结点的红黑树始终保持了logn的高度,从而也就解释了上面所说的“红黑树的查找、插入、删除的时间复杂度最坏为O(log n)”这一结论成立的原因。更多请参见此文:《 教你初步了解红黑树》。 -
简单说下 sigmoid激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下
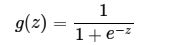
其中z是一个线性组合,比如z可以等于:b +
 *
* +
+ 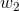 *
* 。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。
。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):

也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)
z = b +
* + *,其中b为偏置项 假定取-30,、都取为20- 如果 = 0 = 0,则z = -30,g(z) = 1/( 1 + e^-z )趋近于0。此外,从上图sigmoid函数的图形上也可以看出,当z=-30的时候,g(z)的值趋近于0
- 如果 = 0 = 1,或 =1 = 0,则z = b + * + * = -30 + 20 = -10,同样,g(z)的值趋近于0
- 如果 = 1 = 1,则z = b + * + * = -30 + 20*1 + 20*1 = 10,此时,g(z)趋近于1。
换言之,只有
和都取1的时候,g(z)→1,判定为正样本;或取0的时候,g(z)→0,判定为负样本,如此达到分类的目的。 - 如果
-
什么是卷积
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做 内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。 OK,举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
OK,举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
分解下上图 对应位置上是数字先相乘后相加
对应位置上是数字先相乘后相加
 =
=
 中间滤波器filter与数据窗口做内积,其具体计算过程则是:4*0 + 0*0 + 0*0 + 0*0 + 0*1 + 0*1 + 0*0 + 0*1 + -4*2 = -8
中间滤波器filter与数据窗口做内积,其具体计算过程则是:4*0 + 0*0 + 0*0 + 0*0 + 0*1 + 0*1 + 0*0 + 0*1 + -4*2 = -8 -
什么是CNN的池化pool层
池化,简言之,即取区域平均或最大,如下图所示(图引自cs231n)

上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。很简单不是?
-
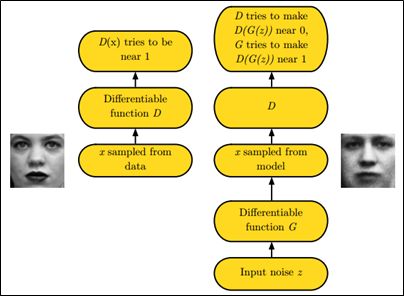
简述下什么是生成对抗网络
GAN之所以是对抗的,是因为GAN的内部是竞争关系,一方叫generator,它的主要工作是生成图片,并且尽量使得其看上去是来自于训练样本的。另一方是discriminator,其目标是判断输入图片是否属于真实训练样本。
更直白的讲,将generator想象成假币制造商,而discriminator是警察。generator目的是尽可能把假币造的跟真的一样,从而能够骗过discriminator,即生成样本并使它看上去好像来自于真实训练样本一样。

如下图中的左右两个场景:
更多请参见此课程:《 生成对抗网络班》。 -
学梵高作画的原理是啥
这里有篇如何做梵高风格画的实验教程《 教你从头到尾利用DL学梵高作画:GTX 1070 cuda 8.0 tensorflow gpu版》,至于其原理请看这个视频: NeuralStyle艺术化图片(学梵高作画背后的原理)。 -
现在有 a 到 z 26 个元素, 编写程序打印 a 到 z 中任取 3 个元素的组合(比如 打印 a b c ,d y z等)
解析参考:http://blog.csdn.net/lvonve/article/details/53320680 -
说说梯度下降法
@LeftNotEasy,本题解析来源:http://www.cnblogs.com/LeftNotEasy/archive/2010/12/05/mathmatic_in_machine_learning_1_regression_and_gradient_descent.html下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。

我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向等等,我们可以做出一个估计函数:

θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:

我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个进行评估的函数称为损失函数(loss function),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以做出下面的一个损失函数:

换言之,我们把对x(i)的估计值与真实值y(i)差的平方和作为损失函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一种完全是数学描述的方法,另外一种就是梯度下降法。
梯度下降法的算法流程如下:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
为了描述的更清楚,给出下面的图:
 这是一个表示参数θ与误差函数J(θ)的关系图,红色的部分是表示J(θ)有着比较高的取值,我们需要的是,能够让J(θ)的值尽量的低,也就是达到深蓝色的部分。θ0,θ1表示θ向量的两个维度。
这是一个表示参数θ与误差函数J(θ)的关系图,红色的部分是表示J(θ)有着比较高的取值,我们需要的是,能够让J(θ)的值尽量的低,也就是达到深蓝色的部分。θ0,θ1表示θ向量的两个维度。在上面提到梯度下降法的第一步是给θ给一个初值,假设随机给的初值是在图上的十字点。
然后我们将θ按照梯度下降的方向进行调整,就会使得J(θ)往更低的方向进行变化,如下图所示,算法的结束将是在θ下降到无法继续下降为止。
 当然,可能梯度下降的最终点并非是全局最小点,即也可能是一个局部最小点,如下图所示:
当然,可能梯度下降的最终点并非是全局最小点,即也可能是一个局部最小点,如下图所示:
上面这张图就是描述的一个局部最小点,这是我们重新选择了一个初始点得到的,看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点。
下面我将用一个例子描述一下梯度减少的过程,对于我们的函数J(θ)求偏导J:

下面是更新的过程,也就是θi会向着梯度最小的方向进行减少。θi表示更新之前的值,-后面的部分表示按梯度方向减少的量,α表示步长,也就是每次按照梯度减少的方向变化多少。
 一个很重要的地方值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管它是局部的还是全局的。
一个很重要的地方值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管它是局部的还是全局的。用更简单的数学语言进行描述步骤2)是这样的:

-
梯度下降法找到的一定是下降最快的方向么?
梯度下降法并不是下降最快的方向,它只是目标函数在当前的点的切平面(当然高维问题不能叫平面)上下降最快的方向。在practical implementation中,牛顿方向(考虑海森矩阵)才一般被认为是下降最快的方向,可以达到superlinear的收敛速度。梯度下降类的算法的收敛速度一般是linear甚至sublinear的(在某些带复杂约束的问题)。by林小溪(https://www.zhihu.com/question/30672734/answer/139689869)。
一般解释梯度下降,会用下山来举例。 假设你现在在山顶处,必须抵达山脚下(也就是山谷最低处)的湖泊。但让人头疼的是,你的双眼被蒙上了无法辨别前进方向。换句话说,你不再能够一眼看出哪条路径是最快的下山路径,如下图(图片来源:http://blog.csdn.net/wemedia/details.html?id=45460):
最好的办法就是走一步算一步,先用脚向四周各个方向都迈出一步,试探一下周围的地势,用脚感觉下哪个方向是下降最大的方向。换言之,每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向(当前最陡峭的位置向下)走一步。就这样,每要走一步都根据上一步所在的位置选择当前最陡峭最快下山的方向走下一步,一步步走下去,一直走到我们感觉已经到了山脚。
当然这样走下去,我们走到的可能并不一定是真正的山脚,而只是走到了某一个局部的山峰低处。换句话说,梯度下降不一定能够找到全局的最优解,也有可能只是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。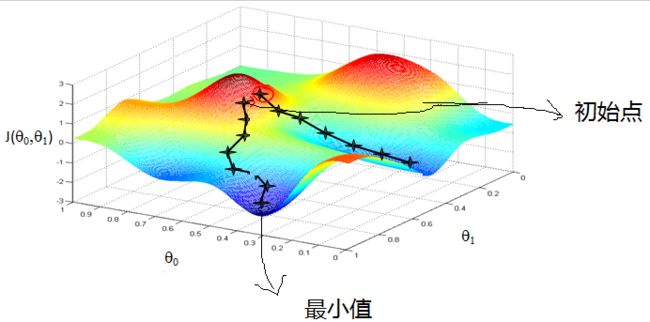
@zbxzc(http://blog.csdn.net/u014568921/article/details/44856915):更进一步,我们来定义输出误差,即对于任意一组权值向量,那它得到的输出和我们预想的输出之间的误差值。定义误差的方法很多,不同的误差计算方法可以得到不同的权值更新法则,这里我们先用这样的定义:
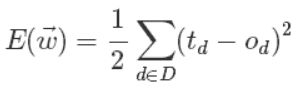
上面公式中D代表了所有的输入实例,或者说是样本,d代表了一个样本实例,od表示感知器的输出,td代表我们预想的输出。
这样,我们的目标就明确了,就是想找到一组权值让这个误差的值最小,显然我们用误差对权值求导将是一个很好的选择,导数的意义是提供了一个方向,沿着这个方向改变权值,将会让总的误差变大,更形象的叫它为梯度。
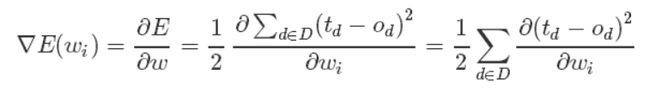
既然梯度确定了E最陡峭的上升的方向,那么梯度下降的训练法则是:

梯度上升和梯度下降其实是一个思想,上式中权值更新的+号改为-号也就是梯度上升了。梯度上升用来求函数的最大值,梯度下降求最小值。
这样每次移动的方向确定了,但每次移动的距离却不知道。这个可以由步长(也称学习率)来确定,记为α。这样权值调整可表示为:

总之,梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是“最速下降法”。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
正因为梯度度下降法在接近最优解的区域收敛速度明显变慢,所以利用梯度下降法求解需要很多次的迭代。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。by@wtq1993,http://blog.csdn.net/wtq1993/article/details/51607040
随机梯度下降
普通的梯度下降算法在更新回归系数时要遍历整个数据集,是一种批处理方法,这样训练数据特别忙庞大时,可能出现如下问题:
1)收敛过程可能非常慢;
2)如果误差曲面上有多个局极小值,那么不能保证这个过程会找到全局最小值。
为了解决上面的问题,实际中我们应用的是梯度下降的一种变体被称为随机梯度下降。
上面公式中的误差是针对于所有训练样本而得到的,而随机梯度下降的思想是根据每个单独的训练样本来更新权值,这样我们上面的梯度公式就变成了:
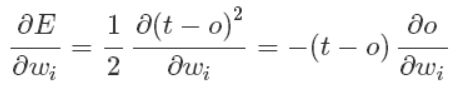
经过推导后,我们就可以得到最终的权值更新的公式:
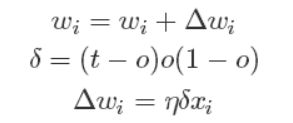
有了上面权重的更新公式后,我们就可以通过输入大量的实例样本,来根据我们预期的结果不断地调整权值,从而最终得到一组权值使得我们的算法能够对一个新的样本输入得到正确的或无限接近的结果。
这里做一个对比
设代价函数为
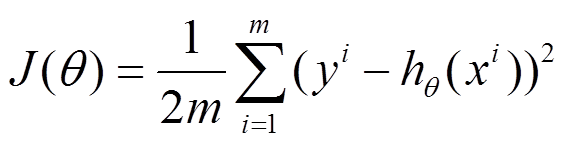
批量梯度下降
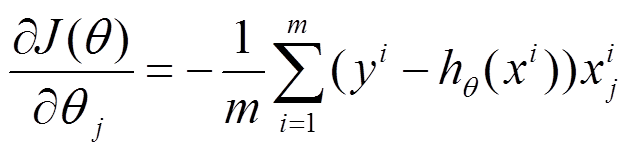
参数更新为:
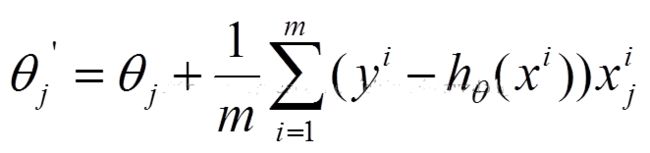
i是样本编号下标,j是样本维数下标,m为样例数目,n为特征数目。所以更新一个θj需要遍历整个样本集
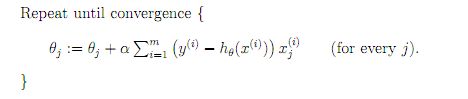
随机梯度下降
参数更新为:
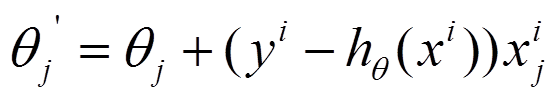
i是样本编号下标,j是样本维数下标,m为样例数目,n为特征数目。所以更新一个θj只需要一个样本就可以。
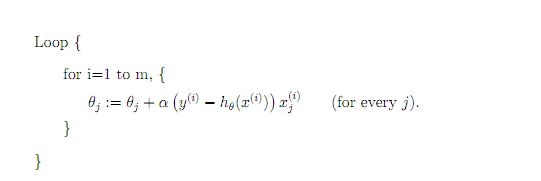
下面两幅图可以很形象的对比各种优化方法(图来源:http://sebastianruder.com/optimizing-gradient-descent/):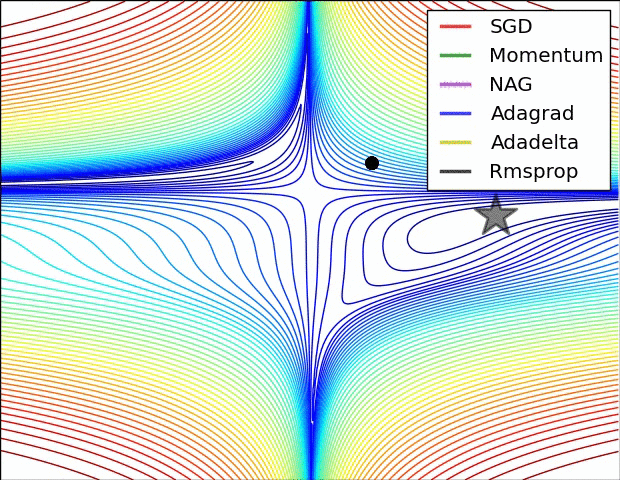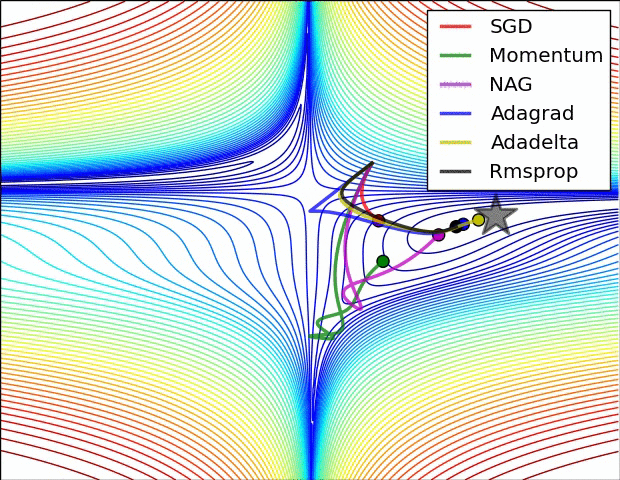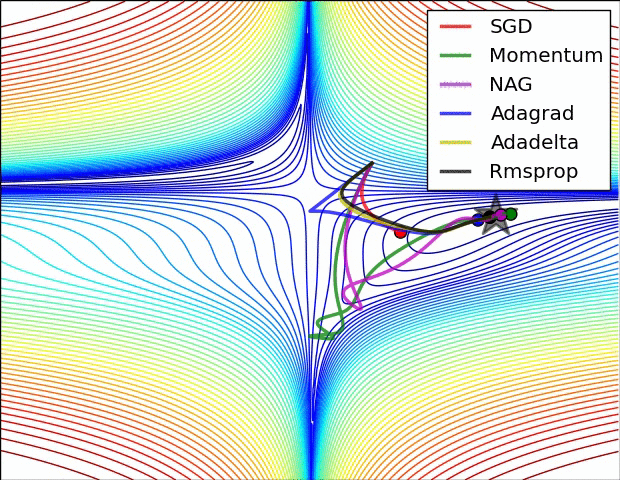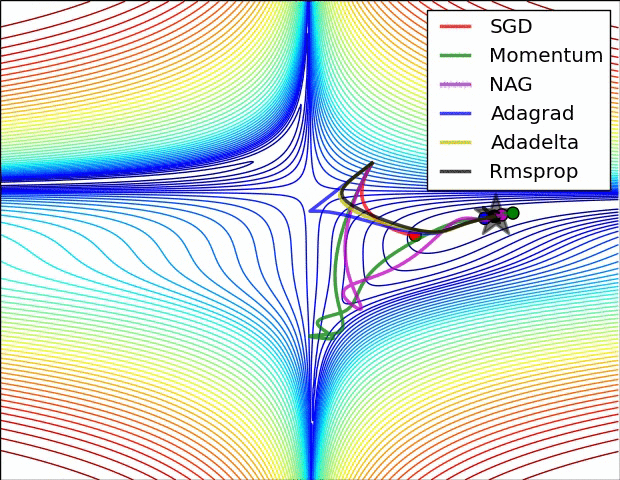
SGD各优化方法在损失曲面上的表现
从上图可以看出, Adagrad、Adadelta与RMSprop在损失曲面上能够立即转移到正确的移动方向上达到快速的收敛。而Momentum 与NAG会导致偏离(off-track)。同时NAG能够在偏离之后快速修正其路线,因为其根据梯度修正来提高响应性。
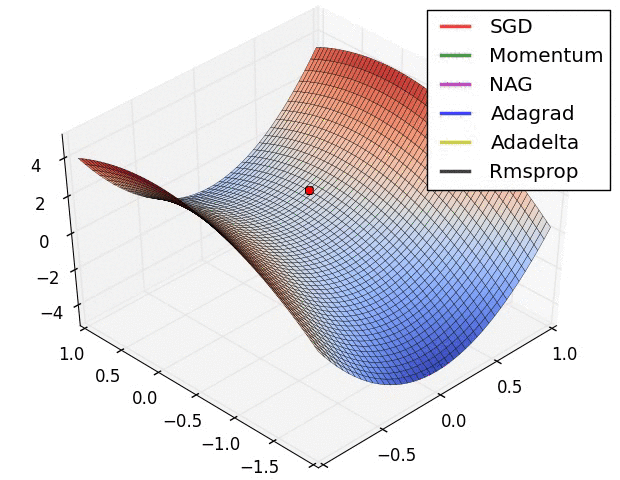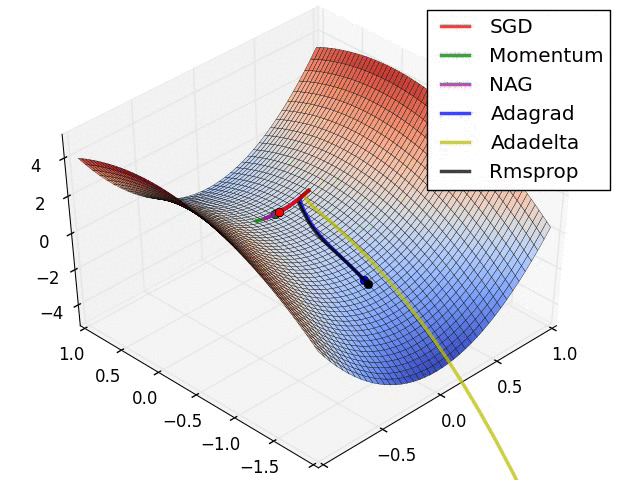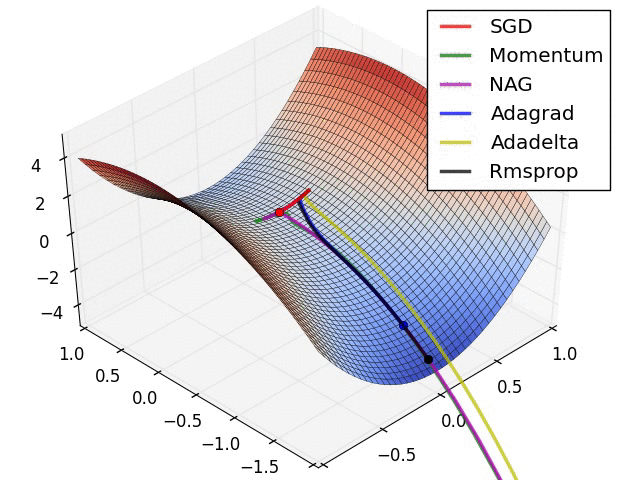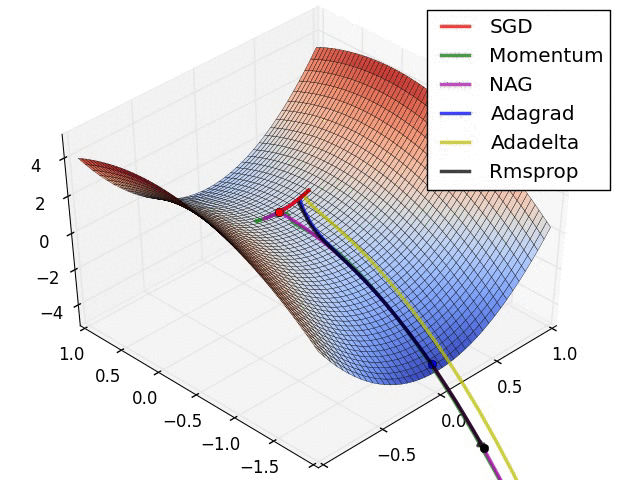
SGD各优化方法在损失曲面鞍点处上的表现
-
牛顿法和梯度下降法有什么不同
@wtq1993,http://blog.csdn.net/wtq1993/article/details/51607040
1)牛顿法(Newton’s method)牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
具体步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ‘ 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f ‘(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
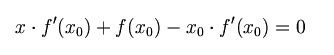
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
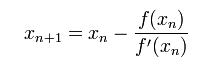
已经证明,如果f ‘ 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ’ (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是”切线法”。牛顿法的搜索路径(二维情况)如下图所示:
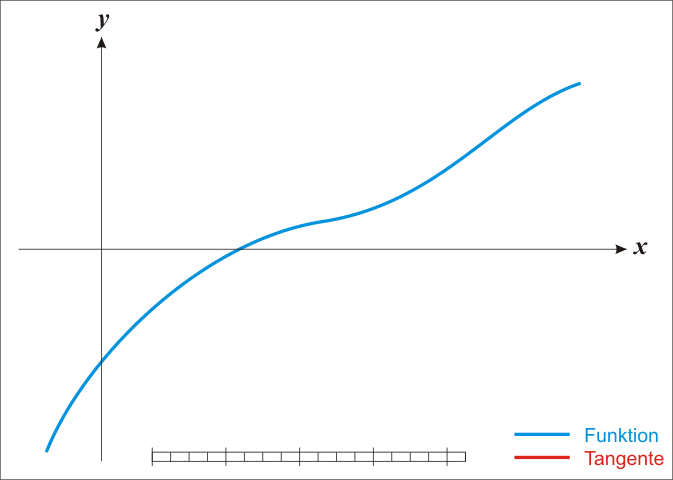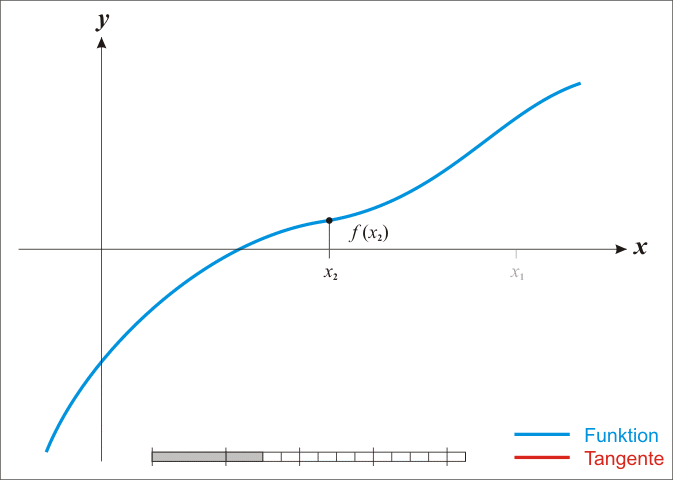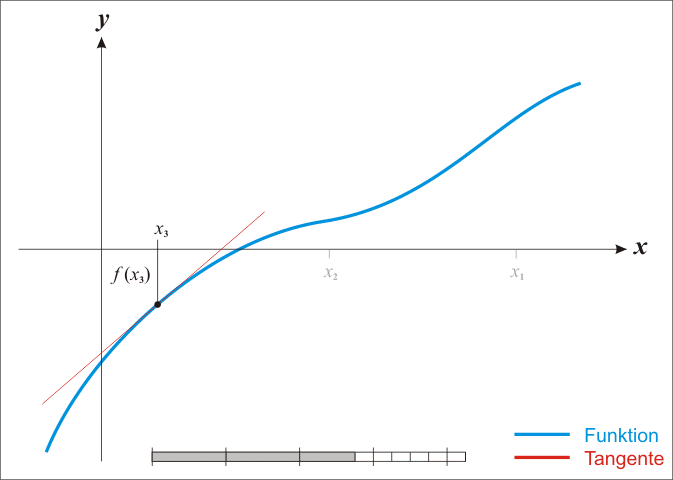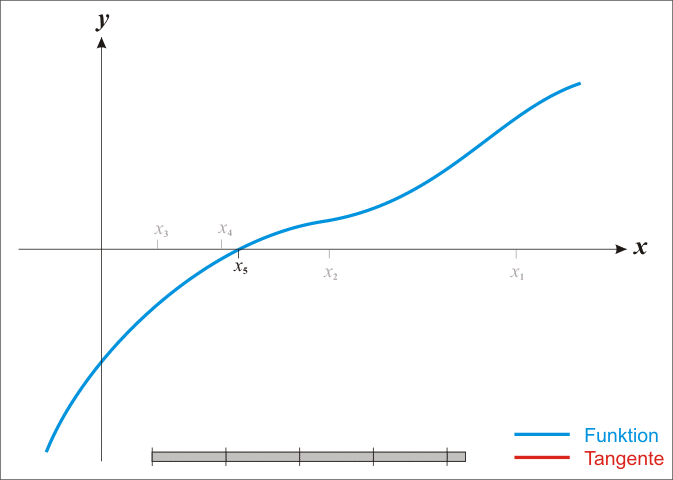
关于牛顿法和梯度下降法的效率对比:
a)从收敛速度上看 ,牛顿法是二阶收敛,梯度下降是一阶收敛,前者牛顿法收敛速度更快。但牛顿法仍然是局部算法,只是在局部上看的更细致,梯度法仅考虑方向,牛顿法不但考虑了方向还兼顾了步子的大小,其对步长的估计使用的是二阶逼近。
b)根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
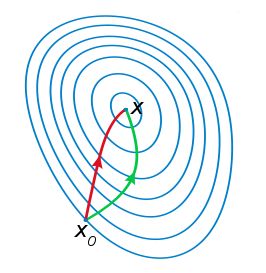
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
-
什么是拟牛顿法(Quasi-Newton Methods)
@wtq1993,http://blog.csdn.net/wtq1993/article/details/51607040
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点: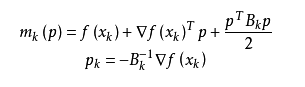 其中我们要求步长ak
其中我们要求步长ak 满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hessian矩阵Bk代替真实的Hessian矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:
满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hessian矩阵Bk代替真实的Hessian矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型: 我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求从而得到
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求从而得到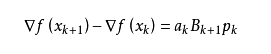
 这个公式被称为割线方程。 常用的拟牛顿法有DFP算法和BFGS算法。
这个公式被称为割线方程。 常用的拟牛顿法有DFP算法和BFGS算法。 -
请说说随机梯度下降法的问题和挑战




那到底如何优化随机梯度法呢?详情请点击:论文公开课第一期:详解梯度下降等各类优化算法(含视频和PPT下载)。 -
说说共轭梯度法
@wtq1993,http://blog.csdn.net/wtq1993/article/details/51607040
共轭梯度法是介于梯度下降法(最速下降法)与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hessian矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有逐步收敛性,稳定性高,而且不需要任何外来参数。下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图: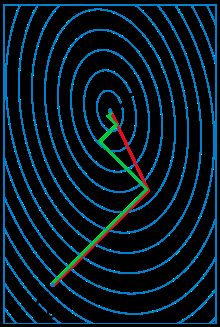 注:绿色为梯度下降法,红色代表共轭梯度法
注:绿色为梯度下降法,红色代表共轭梯度法
-
对所有优化问题来说, 有没有可能找到比現在已知算法更好的算法?
@抽象猴,来源:https://www.zhihu.com/question/41233373/answer/145404190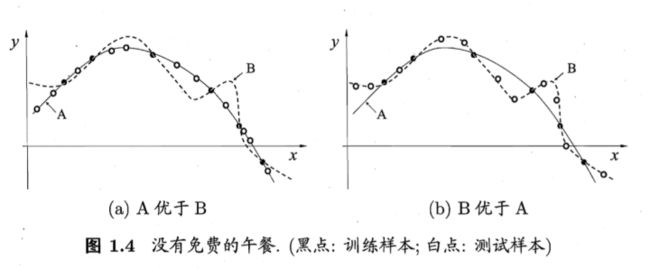
没有免费的午餐定理:
对于训练样本(黑点),不同的算法A/B在不同的测试样本(白点)中有不同的表现,这表示:对于一个学习算法A,若它在某些问题上比学习算法 B更好,则必然存在一些问题,在那里B比A好。
也就是说:对于所有问题,无论学习算法A多聪明,学习算法 B多笨拙,它们的期望性能相同。
但是:没有免费午餐定力假设所有问题出现几率相同,实际应用中,不同的场景,会有不同的问题分布,所以,在优化算法时,针对具体问题进行分析,是算法优化的核心所在。
-
什么最小二乘法?
我们口头中经常说:一般来说,平均来说。如平均来说,不吸烟的健康优于吸烟者,之所以要加“平均”二字,是因为凡事皆有例外,总存在某个特别的人他吸烟但由于经常锻炼所以他的健康状况可能会优于他身边不吸烟的朋友。而最小二乘法的一个最简单的例子便是算术平均。
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。用函数表示为:

使误差「所谓误差,当然是观察值与实际真实值的差量」平方和达到最小以寻求估计值的方法,就叫做最小二乘法,用最小二乘法得到的估计,叫做最小二乘估计。当然,取平方和作为目标函数只是众多可取的方法之一。
最小二乘法的一般形式可表示为:

有效的最小二乘法是勒让德在 1805 年发表的,基本思想就是认为测量中有误差,所以所有方程的累积误差为

我们求解出导致累积误差最小的参数即可:

勒让德在论文中对最小二乘法的优良性做了几点说明:
- 最小二乘使得误差平方和最小,并在各个方程的误差之间建立了一种平衡,从而防止某一个极端误差取得支配地位
- 计算中只要求偏导后求解线性方程组,计算过程明确便捷
- 最小二乘可以导出算术平均值作为估计值
对于最后一点,从统计学的角度来看是很重要的一个性质。推理如下:假设真值为 θ, x1,⋯,xn为n次测量值, 每次测量的误差为ei=xi−θ,按最小二乘法,误差累积为

求解
 使
使 达到最小,正好是算术平均
达到最小,正好是算术平均 。
。由于算术平均是一个历经考验的方法,而以上的推理说明,算术平均是最小二乘的一个特例,所以从另一个角度说明了最小二乘方法的优良性,使我们对最小二乘法更加有信心。
最小二乘法发表之后很快得到了大家的认可接受,并迅速的在数据分析实践中被广泛使用。不过历史上又有人把最小二乘法的发明归功于高斯,这又是怎么一回事呢。高斯在1809年也发表了最小二乘法,并且声称自己已经使用这个方法多年。高斯发明了小行星定位的数学方法,并在数据分析中使用最小二乘方法进行计算,准确的预测了谷神星的位置。
对了,最小二乘法跟SVM有什么联系呢?请参见《支持向量机通俗导论(理解SVM的三层境界)》。 -
看你T恤上印着:人生苦短,我用Python,你可否说说 Python到底是什么样的语言?你可以比较其他技术或者语言来回答你的问题。
@David 9,http://nooverfit.com/wp/15%E4%B8%AA%E9%87%8D%E8%A6%81python%E9%9D%A2%E8%AF%95%E9%A2%98-%E6%B5%8B%E6%B5%8B%E4%BD%A0%E9%80%82%E4%B8%8D%E9%80%82%E5%90%88%E5%81%9Apython%EF%BC%9F/这里是一些关键点:Python是解释型语言。这意味着不像C和其他语言,Python运行前不需要编译。其他解释型语言包括PHP和Ruby。
- Python是动态类型的,这意味着你不需要在声明变量时指定类型。你可以先定义
x=111,然后x=”I’m a string”。 - Python是面向对象语言,所有允许定义类并且可以继承和组合。Python没有访问访问标识如在C++中的
public,private, 这就非常信任程序员的素质,相信每个程序员都是“成人”了~ - 在Python中,函数是一等公民。这就意味着它们可以被赋值,从其他函数返回值,并且传递函数对象。类不是一等公民。
- 写Python代码很快,但是跑起来会比编译型语言慢。幸运的是,Python允许使用C扩展写程序,所以瓶颈可以得到处理。Numpy库就是一个很好例子,因为很多代码不是Python直接写的,所以运行很快。
- Python使用场景很多 – web应用开发、大数据应用、数据科学、人工智能等等。它也经常被看做“胶水”语言,使得不同语言间可以衔接上。
- Python能够简化工作 ,使得程序员能够关心如何重写代码而不是详细看一遍底层实现。
@July:Python目前早已成为AI时代的第一语言,为帮助大家更好的学习Python语言、数据分析、爬虫等相关知识,七月在线特开一系列Python课程,有需要的亲们可以看下,比如《Python数据分析集训营》。 - Python是动态类型的,这意味着你不需要在声明变量时指定类型。你可以先定义
-
Python是如何进行内存管理的?
@Tom_junsong,来源:http://www.cnblogs.com/tom-gao/p/6645859.html
答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
- 的请写出一段Python代码实现删除一个list里面的重复元素
@Tom_junsong,http://www.cnblogs.com/tom-gao/p/6645859.html
答:
1,使用set函数,set(list)
2,使用字典函数,
>>>a=[1,2,4,2,4,5,6,5,7,8,9,0]
>>> b={}
>>>b=b.fromkeys(a)
>>>c=list(b.keys())
>>> c
- 编程用sort进行排序,然后从最后一个元素开始判断
a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
@Tom_junsong,http://www.cnblogs.com/tom-gao/p/6645859.html
a.sort()
last=a[-1]
for i inrange(len(a)-2,-1,-1):
if last==a[i]:
del a[i]
else:last=a[i]
print(a)
- Python里面如何生成随机数?
@Tom_junsong,http://www.cnblogs.com/tom-gao/p/6645859.html
答:random模块
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。更多Python笔试面试题请看:http://python.jobbole.com/85231/
- 说说常见的损失函数
对于给定的输入X,由f(X)给出相应的输出Y,这个输出的预测值f(X)与真实值Y可能一致也可能不一致(要知道,有时损失或误差是不可避免的),用一个损失函数来度量预测错误的程度。损失函数记为L(Y, f(X))。
常用的损失函数有以下几种(基本引用自《统计学习方法》):


如此,SVM有第二种理解,即最优化+损失最小,或如@夏粉_百度所说“可从损失函数和优化算法角度看SVM,boosting,LR等算法,可能会有不同收获”。关于SVM的更多理解请参考:支持向量机通俗导论(理解SVM的三层境界)
-
简单介绍下logistics回归
Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数
 其中x是n维特征向量,函数g就是logistic函数。而
其中x是n维特征向量,函数g就是logistic函数。而 的图像是
的图像是

可以看到,将无穷映射到了(0,1)。而假设函数就是特征属于y=1的概率。
从而,当我们要判别一个新来的特征属于哪个类时,只需求
 即可,若大于0.5就是y=1的类,反之属于y=0类。
即可,若大于0.5就是y=1的类,反之属于y=0类。此外,
只和 有关,
有关, >0,那么
>0,那么 ,而g(z)只是用来映射,真实的类别决定权还是在于
,而g(z)只是用来映射,真实的类别决定权还是在于 。再者,当
。再者,当 时,
时, =1,反之
=1,反之 =0。如果我们只从
=0。如果我们只从 出发,希望模型达到的目标就是让训练数据中y=1的特征
出发,希望模型达到的目标就是让训练数据中y=1的特征 ,而是y=0的特征
,而是y=0的特征 。Logistic回归就是要学习得到
。Logistic回归就是要学习得到 ,使得正例的特征远大于0,负例的特征远小于0,而且要在全部训练实例上达到这个目标。
,使得正例的特征远大于0,负例的特征远小于0,而且要在全部训练实例上达到这个目标。接下来,尝试把logistic回归做个变形。首先,将使用的结果标签y = 0和y = 1替换为y = -1,y = 1,然后将
 (
( )中的
)中的 替换为b,最后将后面的
替换为b,最后将后面的 替换为(即
替换为(即 )。如此,则有了
)。如此,则有了 。也就是说除了y由y=0变为y=-1外,线性分类函数跟logistic回归的形式化表示
。也就是说除了y由y=0变为y=-1外,线性分类函数跟logistic回归的形式化表示 没区别。
没区别。进一步,可以将假设函数
 中的g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
中的g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
- 看你是搞视觉的,熟悉哪些CV框架,顺带聊聊CV最近五年的发展史如何?
原英文:adeshpande3.github.io
作者:Adit Deshpande,UCLA CS研究生
译者:新智元闻菲、胡祥杰
译文链接:https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651986617&idx=1&sn=fddebd0f2968d66b7f424d6a435c84af&scene=0#wechat_redirect的
本段结构如下:AlexNet(2012年)
ZF Net(2013年)
VGG Net(2014年)
GoogLeNet (2015年)
微软 ResNet (2015年)
区域 CNN(R-CNN - 2013年,Fast R-CNN - 2015年,Faster R-CNN - 2015年)
生成对抗网络(2014年)
生成图像描述(2014年)
空间转化器网络(2015年)
AlexNet(2012年)
一切都从这里开始(尽管有些人会说是Yann LeCun 1998年发表的那篇论文才真正开启了一个时代)。这篇论文,题目叫做“ImageNet Classification with Deep Convolutional Networks”,迄今被引用6184次,被业内普遍视为行业最重要的论文之一。Alex Krizhevsky、Ilya Sutskever和 Geoffrey Hinton创造了一个“大型的深度卷积神经网络”,赢得了2012 ILSVRC(2012年ImageNet 大规模视觉识别挑战赛)。稍微介绍一下,这个比赛被誉为计算机视觉的年度奥林匹克竞赛,全世界的团队相聚一堂,看看是哪家的视觉模型表现最为出色。2012年是CNN首次实现Top 5误差率15.4%的一年(Top 5误差率是指给定一张图像,其标签不在模型认为最有可能的5个结果中的几率),当时的次优项误差率为26.2%。这个表现不用说震惊了整个计算机视觉界。可以说,是自那时起,CNN才成了家喻户晓的名字。
论文中,作者讨论了网络的架构(名为AlexNet)。相比现代架构,他们使用了一种相对简单的布局,整个网络由5层卷积层组成,最大池化层、退出层(dropout layer)和3层全卷积层。网络能够对1000种潜在类别进行分类。
AlexNet 架构:看上去有些奇怪,因为使用了两台GPU训练,因而有两股“流”。使用两台GPU训练的原因是计算量太大,只能拆开来。
要点
使用ImageNet数据训练网络,ImageNet数据库含有1500多万个带标记的图像,超过2.2万个类别。
使用ReLU代替传统正切函数引入非线性(ReLU比传统正切函数快几倍,缩短训练时间)。
使用了图像转化(image translation)、水平反射(horizontal reflection)和补丁提取(patch extraction)这些数据增强技术。
用dropout层应对训练数据过拟合的问题。
使用批处理随机梯度下降训练模型,注明动量衰减值和权重衰减值。
使用两台GTX 580 GPU,训练了5到6天
为什么重要?
Krizhevsky、Sutskever 和 Hinton 2012年开发的这个神经网络,是CNN在计算机视觉领域的一大亮相。这是史上第一次有模型在ImageNet 数据库表现这么好,ImageNet 数据库难度是出了名的。论文中提出的方法,比如数据增强和dropout,现在也在使用,这篇论文真正展示了CNN的优点,并且以破纪录的比赛成绩实打实地做支撑。
ZF Net(2013年)
2012年AlexNet出尽了风头,ILSVRC 2013就有一大批CNN模型冒了出来。2013年的冠军是纽约大学Matthew Zeiler 和 Rob Fergus设计的网络 ZF Net,错误率 11.2%。ZF Net模型更像是AlexNet架构的微调优化版,但还是提出了有关优化性能的一些关键想法。还有一个原因,这篇论文写得非常好,论文作者花了大量时间阐释有关卷积神经网络的直观概念,展示了将滤波器和权重可视化的正确方法。
在这篇题为“Visualizing and Understanding Convolutional Neural Networks”的论文中,Zeiler和Fergus从大数据和GPU计算力让人们重拾对CNN的兴趣讲起,讨论了研究人员对模型内在机制知之甚少,一针见血地指出“发展更好的模型实际上是不断试错的过程”。虽然我们现在要比3年前知道得多一些了,但论文所提出的问题至今仍然存在!这篇论文的主要贡献在于提出了一个比AlexNet稍微好一些的模型并给出了细节,还提供了一些制作可视化特征图值得借鉴的方法。
要点
除了一些小的修改,整体架构非常类似AlexNet。
AlexNet训练用了1500万张图片,而ZFNet只用了130万张。
AlexNet在第一层中使用了大小为11×11的滤波器,而ZF使用的滤波器大小为7x7,整体处理速度也有所减慢。做此修改的原因是,对于输入数据来说,第一层卷积层有助于保留大量的原始象素信息。11×11的滤波器漏掉了大量相关信息,特别是因为这是第一层卷积层。
随着网络增大,使用的滤波器数量增多。
利用ReLU的激活函数,将交叉熵代价函数作为误差函数,使用批处理随机梯度下降进行训练。
使用一台GTX 580 GPU训练了12天。
开发可视化技术“解卷积网络”(Deconvolutional Network),有助于检查不同的特征激活和其对输入空间关系。名字之所以称为“deconvnet”,是因为它将特征映射到像素(与卷积层恰好相反)。
DeConvNet
DeConvNet工作的基本原理是,每层训练过的CNN后面都连一层“deconvet”,它会提供一条返回图像像素的路径。输入图像进入CNN之后,每一层都计算激活。然而向前传递。现在,假设我们想知道第4层卷积层某个特征的激活值,我们将保存这个特征图的激活值,并将这一层的其他激活值设为0,再将这张特征图作为输入送入deconvnet。Deconvnet与原来的CNN拥有同样的滤波器。输入经过一系列unpool(maxpooling倒过来),修正,对前一层进行过滤操作,直到输入空间满。
这一过程背后的逻辑在于,我们想要知道是激活某个特征图的是什么结构。下面来看第一层和第二层的可视化。
ConvNet的第一层永远是低层特征检测器,在这里就是对简单的边缘、颜色进行检测。第二层就有比较圆滑的特征了。再来看第三、第四和第五层。
这些层展示出了更多的高级特征,比如狗的脸和鲜花。值得一提的是,在第一层卷积层后面,我们通常会跟一个池化层将图像缩小(比如将 32x32x32 变为16x16x3)。这样做的效果是加宽了第二层看原始图像的视野。更详细的内容可以阅读论文。
为什么重要?
ZF Net不仅是2013年比赛的冠军,还对CNN的运作机制提供了极好的直观信息,展示了更多提升性能的方法。论文所描述的可视化方法不仅有助于弄清CNN的内在机理,也为优化网络架构提供了有用的信息。Deconv可视化方法和 occlusion 实验也让这篇论文成了我个人的最爱。
VGG Net(2015年)
简单、有深度,这就是2014年错误率7.3%的模型VGG Net(不是ILSVRC 2014冠军)。牛津大学的Karen Simonyan 和 Andrew Zisserman Main Points创造了一个19层的CNN,严格使用3x3的过滤器(stride =1,pad= 1)和2x2 maxpooling层(stride =2)。简单吧?
要点
这里使用3x3的滤波器和AlexNet在第一层使用11x11的滤波器和ZF Net 7x7的滤波器作用完全不同。作者认为两个3x3的卷积层组合可以实现5x5的有效感受野。这就在保持滤波器尺寸较小的同时模拟了大型滤波器,减少了参数。此外,有两个卷积层就能够使用两层ReLU。
3卷积层具有7x7的有效感受野。
每个maxpool层后滤波器的数量增加一倍。进一步加强了缩小空间尺寸,但保持深度增长的想法。
图像分类和定位任务都运作良好。
使用Caffe工具包建模。
训练中使用scale jittering的数据增强技术。
每层卷积层后使用ReLU层和批处理梯度下降训练。
使用4台英伟达Titan Black GPU训练了两到三周。
为什么重要?
在我看来,VGG Net是最重要的模型之一,因为它再次强调CNN必须够深,视觉数据的层次化表示才有用。深的同时结构简单。
GoogLeNet(2015年)
理解了我们刚才所说的神经网络架构中的简化的概念了吗?通过推出 Inception 模型,谷歌从某种程度上把这一概念抛了出来。GoogLeNet是一个22层的卷积神经网络,在2014年的ILSVRC2014上凭借6.7%的错误率进入Top 5。据我所知,这是第一个真正不使用通用方法的卷积神经网络架构,传统的卷积神经网络的方法是简单堆叠卷积层,然后把各层以序列结构堆积起来。论文的作者也强调,这种新的模型重点考虑了内存和能量消耗。这一点很重要,我自己也会经常忽略:把所有的层都堆叠、增加大量的滤波器,在计算和内存上消耗很大,过拟合的风险也会增加。
换一种方式看 GoogLeNet:
Inception 模型
第一次看到GoogLeNet的构造时,我们立刻注意到,并不是所有的事情都是按照顺序进行的,这与此前看到的架构不一样。我们有一些网络,能同时并行发生反应。
这个盒子被称为 Inception 模型。可以近距离地看看它的构成。
底部的绿色盒子是我们的输入层,顶部的是输出层(把这张图片向右旋转90度,你会看到跟展示了整个网络的那张图片相对应的模型)。基本上,在一个传统的卷积网络中的每一层中,你必须选择操作池还是卷积操作(还要选择滤波器的大小)。Inception 模型能让你做到的就是并行地执行所有的操作。事实上,这就是作者构想出来的最“初始”的想法。
现在,来看看它为什么起作用。它会导向许多不同的结果,我们会最后会在输出层体积上获得极端大的深度通道。作者处理这个问题的方法是,在3X3和5X5层前,各自增加一个1X1的卷积操作。1X1的卷积(或者网络层中的网络),提供了一个减少维度的方法。比如,我们假设你拥有一个输入层,体积是100x100x60(这并不定是图像的三个维度,只是网络中每一层的输入)。增加20个1X1的卷积滤波器,会让你把输入的体积减小到100X100X20。这意味着,3X3层和5X5层不需要处理输入层那么大的体积。这可以被认为是“池特征”(pooling of feature),因为我们正在减少体积的高度,这和使用常用的最大池化层(maxpooling layers)减少宽度和长度类似。另一个需要注意的是,这些1X1的卷积层后面跟着的是ReLU 单元,这肯定不会有害。
你也许会问,“这个架构有什么用?”这么说吧,这个模型由一个网络层中的网络、一个中等大小的过滤卷积、一个大型的过滤卷积、一个操作池(pooling operation)组成。网络卷积层中的网络能够提取输入体积中的每一个细节中的信息,同时 5x5 的滤波器也能够覆盖大部分接受层的的输入,进而能提起其中的信息。你也可以进行一个池操作,以减少空间大小,降低过度拟合。在这些层之上,你在每一个卷积层后都有一个ReLU,这能改进网络的非线性特征。基本上,网络在执行这些基本的功能时,还能同时考虑计算的能力。这篇论文还提供了更高级别的推理,包括的主题有稀疏和紧密联结(见论文第三和第四节)。
要点
整个架构中使用了9个Inception 模型,总共超过100层。这已经很深了……没有使用完全连接的层。他们使用一个平均池代替,从 7x7x1024 的体积降到了 1x1x1024,这节省了大量的参数。比AlexNet的参数少了12X在测试中,相同图像的多个剪裁建立,然后填到网络中,计算softmax probabilities的均值,然后我们可以获得最后的解决方案。在感知模型中,使用了R-CNN中的概念。Inception有一些升级的版本(版本6和7),“少数高端的GPU”一周内就能完成训练。
为什么重要?
GoogLeNet 是第一个引入了“CNN 各层不需要一直都按顺序堆叠”这一概念的模型。用Inception模型,作者展示了一个具有创造性的层次机构,能带来性能和计算效率的提升。这篇论文确实为接下来几年可能会见到的令人惊叹的架构打下了基础。
微软 ResNet(2015年)
想象一个深度CNN架构,再深、再深、再深,估计都还没有 ILSVRC 2015 冠军,微软的152层ResNet架构深。除了在层数上面创纪录,ResNet 的错误率也低得惊人,达到了3.6%,人类都大约在5%~10%的水平。
为什么重要?
只有3.6%的误差率,这应该足以说服你。ResNet模型是目前最好的CNN架构,而且是残差学习理念的一大创新。从2012年起,错误率逐年下降,我怀疑到ILSVRC2016,是否还会一直下降。我相信,我们现在堆放更多层将不会实现性能的大幅提升。我们必须要创造新的架构。
区域 CNN:R-CNN(2013年)、Fast R-CNN(2015年)、Faster R-CNN(2015年)
一些人可能会认为,R-CNN的出现比此前任何关于新的网络架构的论文都有影响力。第一篇关于R-CNN的论文被引用了超过1600次。Ross Girshick 和他在UC Berkeley 的团队在机器视觉上取得了最有影响力的进步。正如他们的文章所写, Fast R-CNN 和 Faster R-CNN能够让模型变得更快,更好地适应现代的物体识别任务。
R-CNN的目标是解决物体识别的难题。在获得特定的一张图像后, 我们希望能够绘制图像中所有物体的边缘。这一过程可以分为两个组成部分,一个是区域建议,另一个是分类。
论文的作者强调,任何分类不可知区域的建议方法都应该适用。Selective Search专用于RCNN。Selective Search 的作用是聚合2000个不同的区域,这些区域有最高的可能性会包含一个物体。在我们设计出一系列的区域建议之后,这些建议被汇合到一个图像大小的区域,能被填入到经过训练的CNN(论文中的例子是AlexNet),能为每一个区域提取出一个对应的特征。这个向量随后被用于作为一个线性SVM的输入,SVM经过了每一种类型和输出分类训练。向量还可以被填入到一个有边界的回归区域,获得最精准的一致性。
非极值压抑后被用于压制边界区域,这些区域相互之间有很大的重复。
Fast R-CNN
原始模型得到了改进,主要有三个原因:训练需要多个步骤,这在计算上成本过高,而且速度很慢。Fast R-CNN通过从根本上在不同的建议中分析卷积层的计算,同时打乱生成区域建议的顺利以及运行CNN,能够快速地解决问题。
Faster R-CNN
Faster R-CNN的工作是克服R-CNN和 Fast R-CNN所展示出来的,在训练管道上的复杂性。作者 在最后一个卷积层上引入了一个区域建议网络(RPN)。这一网络能够只看最后一层的特征就产出区域建议。从这一层面上来说,相同的R-CNN管道可用。
为什么重要?
能够识别出一张图像中的某一个物体是一方面,但是,能够识别物体的精确位置对于计算机知识来说是一个巨大的飞跃。更快的R-CNN已经成为今天标准的物体识别程序。
生成对抗网络(2015年)
按照Yann LeCun的说法,生成对抗网络可能就是深度学习下一个大突破。假设有两个模型,一个生成模型,一个判别模型。判别模型的任务是决定某幅图像是真实的(来自数据库),还是机器生成的,而生成模型的任务则是生成能够骗过判别模型的图像。这两个模型彼此就形成了“对抗”,发展下去最终会达到一个平衡,生成器生成的图像与真实的图像没有区别,判别器无法区分两者。
左边一栏是数据库里的图像,也即真实的图像,右边一栏是机器生成的图像,虽然肉眼看上去基本一样,但在CNN看起来却十分不同。
为什么重要?
听上去很简单,然而这是只有在理解了“数据内在表征”之后才能建立的模型,你能够训练网络理解真实图像和机器生成的图像之间的区别。因此,这个模型也可以被用于CNN中做特征提取。此外,你还能用生成对抗模型制作以假乱真的图片。
生成图像描述(2014年)
把CNN和RNN结合在一起会发生什么?Andrej Karpathy 和李飞飞写的这篇论文探讨了结合CNN和双向RNN生成不同图像区域的自然语言描述问题。简单说,这个模型能够接收一张图片,然后输出
很神奇吧。传统CNN,训练数据中每幅图像都有单一的一个标记。这篇论文描述的模型则是每幅图像都带有一句话(或图说)。这种标记被称为弱标记,使用这种训练数据,一个深度神经网络“推断句子中的部分与其描述的区域之间的潜在对齐(latent alignment)”,另一个神经网络将图像作为输入,生成文本的描述。
为什么重要?
使用看似不相关的RNN和CNN模型创造了一个十分有用的应用,将计算机视觉和自然语言处理结合在一起。这篇论文为如何建模处理跨领域任务提供了全新的思路。
空间转换器网络(2015年)
最后,让我们来看该领域最近的一篇论文。本文是谷歌DeepMind的一个团队在一年前写的。这篇论文的主要贡献是介绍了空间变换器(Spatial Transformer)模块。基本思路是,这个模块会转变输入图像,使随后的层可以更轻松地进行分类。作者试图在图像到达特定层前改变图像,而不是更改主CNN架构本身。该模块希望纠正两件事:姿势标准化(场景中物体倾斜或缩放)和空间注意力(在密集的图像中将注意力集中到正确的物体)。对于传统的CNN,如果你想使你的模型对于不同规格和旋转的图像都保持不变,那你需要大量的训练样本来使模型学习。让我们来看看这个模块是如何帮助解决这一问题。
传统CNN模型中,处理空间不变性的是maxpooling层。其原因是,一旦我们知道某个特定特性还是起始输入量(有高激活值),它的确切位置就没有它对其他特性的相对位置重要,其他功能一样重要。这个新的空间变换器是动态的,它会对每个输入图像产生不同的行为(不同的扭曲/变形)。这不仅仅是像传统 maxpool 那样简单和预定义。让我们来看看这个模块是如何工作的。该模块包括:
一个本地化网络,会吸收输入量,并输出应施加的空间变换的参数。参数可以是6维仿射变换。
采样网格,这是由卷曲规则网格和定位网络中创建的仿射变换(theta)共同产生的。
一个采样器,其目的是执行输入功能图的翘曲。
该模块可以放入CNN的任何地方中,可以帮助网络学习如何以在训练过程中最大限度地减少成本函数的方式来变换特征图。
为什么重要?
CNN的改进不一定要到通过网络架构的大改变来实现。我们不需要创建下一个ResNet或者 Inception 模型。本文实现了对输入图像进行仿射变换的简单的想法,以使模型对平移,缩放和旋转保持不变。更多请查看《CNN十篇经典论文》。
-
深度学习在视觉领域有何前沿进展
@元峰,本题解析来源:https://zhuanlan.zhihu.com/p/24699780
引言
在今年的神经网络顶级会议NIPS2016上,深度学习三大牛之一的Yann Lecun教授给出了一个关于机器学习中的有监督学习、无监督学习和增强学习的一个有趣的比喻,他说:如果把智能(Intelligence)比作一个蛋糕,那么无监督学习就是蛋糕本体,增强学习是蛋糕上的樱桃,那么监督学习,仅仅能算作蛋糕上的糖霜(图1)。

图1. Yann LeCun 对监督学习,增强学习和无监督学习的价值的形象比喻
1. 深度有监督学习在计算机视觉领域的进展
1.1 图像分类(Image Classification)
自从Alex和他的导师Hinton(深度学习鼻祖)在2012年的ImageNet大规模图像识别竞赛(ILSVRC2012)中以超过第二名10个百分点的成绩(83.6%的Top5精度)碾压第二名(74.2%,使用传统的计算机视觉方法)后,深度学习真正开始火热,卷积神经网络(CNN)开始成为家喻户晓的名字,从12年的AlexNet(83.6%),到2013年ImageNet 大规模图像识别竞赛冠军的88.8%,再到2014年VGG的92.7%和同年的GoogLeNet的93.3%,终于,到了2015年,在1000类的图像识别中,微软提出的残差网(ResNet)以96.43%的Top5正确率,达到了超过人类的水平(人类的正确率也只有94.9%).
Top5精度是指在给出一张图片,模型给出5个最有可能的标签,只要在预测的5个结果中包含正确标签,即为正确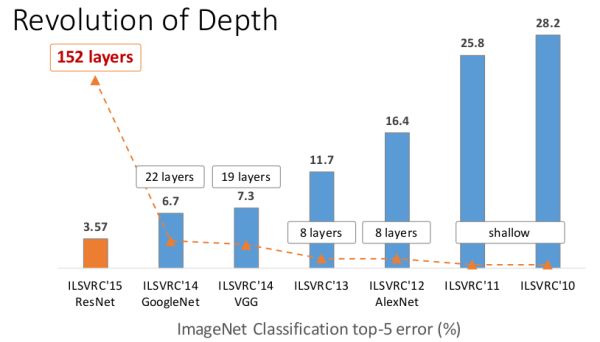
图2. 2010-2015年ILSVRC竞赛图像识别错误率演进趋势
1.2 图像检测(Image Dection)
伴随着图像分类任务,还有另外一个更加有挑战的任务–图像检测,图像检测是指在分类图像的同时把物体用矩形框给圈起来。从14年到16年,先后涌现出R-CNN,Fast R-CNN, Faster R-CNN, YOLO, SSD等知名框架,其检测平均精度(mAP),在计算机视觉一个知名数据集上PASCAL VOC上的检测平均精度(mAP),也从R-CNN的53.3%,到Fast RCNN的68.4%,再到Faster R-CNN的75.9%,最新实验显示,Faster RCNN结合残差网(Resnet-101),其检测精度可以达到83.8%。深度学习检测速度也越来越快,从最初的RCNN模型,处理一张图片要用2秒多,到Faster RCNN的198毫秒/张,再到YOLO的155帧/秒(其缺陷是精度较低,只有52.7%),最后出来了精度和速度都较高的SSD,精度75.1%,速度23帧/秒。

图3. 图像检测示例
1.3 图像分割(Semantic Segmentation)
图像分割也是一项有意思的研究领域,它的目的是把图像中各种不同物体给用不同颜色分割出来,如下图所示,其平均精度(mIoU,即预测区域和实际区域交集除以预测区域和实际区域的并集),也从最开始的FCN模型(图像语义分割全连接网络,该论文获得计算机视觉顶会CVPR2015的最佳论文的)的62.2%,到DeepLab框架的72.7%,再到牛津大学的CRF as RNN的74.7%。该领域是一个仍在进展的领域,仍旧有很大的进步空间。
 图4. 图像分割的例子
图4. 图像分割的例子
1.4 图像标注–看图说话(Image Captioning)
图像标注是一项引人注目的研究领域,它的研究目的是给出一张图片,你给我用一段文字描述它,如图中所示,图片中第一个图,程序自动给出的描述是“一个人在尘土飞扬的土路上骑摩托车”,第二个图片是“两只狗在草地上玩耍”。由于该研究巨大的商业价值(例如图片搜索),近几年,工业界的百度,谷歌和微软 以及学术界的加大伯克利,深度学习研究重地多伦多大学都在做相应的研究。

图5.图像标注,根据图片生成描述文字
1.5 图像生成–文字转图像(Image Generator)
图片标注任务本来是一个半圆,既然我们可以从图片产生描述文字,那么我们也能从文字来生成图片。如图6所示,第一列“一架大客机在蓝天飞翔”,模型自动根据文字生成了16张图片,第三列比较有意思,“一群大象在干燥草地行走”(这个有点违背常识,因为大象一般在雨林,不会在干燥草地上行走),模型也相应的生成了对应图片,虽然生成的质量还不算太好,但也已经中规中矩。

图6.根据文字生成图片
2.强化学习(Reinforcement Learning)
在监督学习任务中,我们都是给定样本一个固定标签,然后去训练模型,可是,在真实环境中,我们很难给出所有样本的标签,这时候,强化学习就派上了用场。简单来说,我们给定一些奖励或惩罚,强化学习就是让模型自己去试错,模型自己去优化怎么才能得到更多的分数。2016年大火的AlphaGo就是利用了强化学习去训练,它在不断的自我试错和博弈中掌握了最优的策略。利用强化学习去玩flyppy bird,已经能够玩到几万分了。
 图7. 强化学习玩flappy bird
图7. 强化学习玩flappy bird谷歌DeepMind发表的使用增强学习来玩Atari游戏,其中一个经典的游戏是打砖块(breakout),DeepMind提出的模型仅仅使用像素作为输入,没有任何其他先验知识,换句话说,模型并不认识球是什么,它玩的是什么,令人惊讶的是,在经过240分钟的训练后,它不光学会了正确的接球,击打砖块,它甚至学会了持续击打同一个位置,游戏就胜利的越快(它的奖励也越高)。视频链接:Youtbe(需),优酷
图8.使用深度增强学习来玩Atari Breakout强化学习在机器人领域和自动驾驶领域有极大的应用价值,当前arxiv上基本上每隔几天就会有相应的论文出现。机器人去学习试错来学习最优的表现,这或许是人工智能进化的最优途径,估计也是通向强人工智能的必经之路。
3深度无监督学习(Deep Unsupervised Learning)–预测学习
相比有限的监督学习数据,自然界有无穷无尽的未标注数据。试想,如果人工智能可以从庞大的自然界自动去学习,那岂不是开启了一个新纪元?当前,最有前景的研究领域或许应属无监督学习,这也正是Yann Lecun教授把无监督学习比喻成人工智能大蛋糕的原因吧。
深度学习牛人Ian Goodfellow在2014年提出生成对抗网络后,该领域越来越火,成为16年研究最火热的一个领域之一。大牛Yann LeCun曾说:“对抗网络是切片面包发明以来最令人激动的事情。”这句话足以说明生成对抗网络有多重要。
生成对抗网络的一个简单解释如下:假设有两个模型,一个是生成模型(Generative Model,下文简写为G),一个是判别模型(Discriminative Model,下文简写为D),判别模型(D)的任务就是判断一个实例是真实的还是由模型生成的,生成模型(G)的任务是生成一个实例来骗过判别模型(D),两个模型互相对抗,发展下去就会达到一个平衡,生成模型生成的实例与真实的没有区别,判别模型无法区分自然的还是模型生成的。以赝品商人为例,赝品商人(生成模型)制作出假的毕加索画作来欺骗行家(判别模型D),赝品商人一直提升他的高仿水平来区分行家,行家也一直学习真的假的毕加索画作来提升自己的辨识能力,两个人一直博弈,最后赝品商人高仿的毕加索画作达到了以假乱真的水平,行家最后也很难区分正品和赝品了。下图是Goodfellow在发表生成对抗网络论文中的一些生成图片,可以看出,模型生成的模型与真实的还是有大差别,但这是14年的论文了,16年这个领域进展非常快,相继出现了条件生成对抗网络(Conditional Generative Adversarial Nets)和信息生成对抗网络(InfoGAN),深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network, DCGAN),更重要的是,当前生成对抗网络把触角伸到了视频预测领域,众所周知,人类主要是靠视频序列来理解自然界的,图片只占非常小的一部分,当人工智能学会理解视频后,它也真正开始显现出威力了。这里推荐一篇2017年初Ian GoodFellow结合他在NIPS2016的演讲写出的综述性论文NIPS 2016 Tutorial: Generative Adversarial Networks

图9 生成对抗网络生成的一些图片,最后边一列是与训练集中图片最相近的生产图片
3.1条件生成对抗网络(Conditional Generative Adversarial Nets,CGAN)
生成对抗网络一般是根据随机噪声来生成特定类型的图像等实例,条件生成对抗网络则是根据一定的输入来限定输出,例如根据几个描述名词来生成特定的实例,这有点类似1.5节介绍的由文字生成图像,下图是Conditioanal Generative Adversarial Nets论文中的一张图片,根据特定的名词描述来生成图片。(注意:左边的一列图片的描述文字是训练集中不存在的,也就是说是模型根据没有见过的描述来生成的图片,右边的一列图片的描述是训练集中存在的)

图10. 根据文字来生成图片条件生成对抗网络的另一篇有意思的论文是图像到图像的翻译,该论文提出的模型能够根据一张输入图片,然后给出模型生成的图片,下图是论文中的一张图,其中左上角第一对非常有意思,模型输入图像分割的结果,给出了生成的真实场景的结果,这类似于图像分割的反向工程。
 图11. 根据特定输入来生成一些有意思的输出图片生成对抗网络也用在了图像超分辨率上,2016年有人提出 SRGAN模型,它把原高清图下采样后,试图用生成对抗网络模型来还原图片来生成更为自然的,更逼近原图像的图像。下图中最右边是原图,把他降采样后采用三次差值(Bicubic Interpolation)得到的图像比较模糊,采用残差网络的版本(SRResNet)已经干净了很多,我们可以看到SRGAN生成的图片更为真实一些。
图11. 根据特定输入来生成一些有意思的输出图片生成对抗网络也用在了图像超分辨率上,2016年有人提出 SRGAN模型,它把原高清图下采样后,试图用生成对抗网络模型来还原图片来生成更为自然的,更逼近原图像的图像。下图中最右边是原图,把他降采样后采用三次差值(Bicubic Interpolation)得到的图像比较模糊,采用残差网络的版本(SRResNet)已经干净了很多,我们可以看到SRGAN生成的图片更为真实一些。
图12.生成对抗网络做超分辨率的例子,最右边是原始图像
生成对抗网络的另一篇有影响力的论文是深度卷积生成对抗网络DCGAN,作者把卷积神经网络和生成对抗网络结合起来,作者指出该框架可以很好的学习事物的特征,论文在图像生成和图像操作上给出了很有意思的结果,例如图13,带眼睛的男人-不戴眼镜的男人+不带眼睛的女人=带眼睛的女人,该模型给出了图片的类似向量化操作。
 图13. DCGAN论文中的例图生成对抗网络的发展是在是太火爆,一篇文章难以罗列完全,对此感兴趣的朋友们可以自己在网络搜素相关论文来研究
图13. DCGAN论文中的例图生成对抗网络的发展是在是太火爆,一篇文章难以罗列完全,对此感兴趣的朋友们可以自己在网络搜素相关论文来研究
openAI的一篇描述生成对抗网络的博客非常棒,因为Ian Goodfellow就在OpenAI工作,所以这篇博客的质量还是相当有保障的。链接为: Open AI 生成对抗网络博客3.2 视频预测
该方向是笔者自己最感兴趣的方向,Yann LeCun也提出,“用预测学习来替代无监督学习”,预测学习通过观察和理解这个世界是如何运作的,然后对世界的变化做出预测,机器学会了感知世界的变化,然后对世界的状态进行了推断。
今年的NIPS上,MIT的学者Vondrick等人发表了一篇名为Generating Videos with Scene Dynamics的论文,该论文提出了基于一幅静态的图片,模型自动推测接下来的场景,例如给出一张人站在沙滩的图片,模型自动给出一段接下来的海浪涌动的小视频。该模型是以无监督的方式,在大量的视频上训练而来的。该模型表明它可以自动学习到视频中有用的特征。下图是作者的官方主页上给出的图,是动态图,如果无法正常查看,请转入官方网站
视频生成例子,下图的视频是模型自动生成的,我们可以看到图片不太完美,但已经能相当好的表示一个场景了。

 图14. 随机生成的视频,沙滩上波涛涌动,火车奔驰的场景条件视频生成,下图是输入一张静态图,模型自动推演出一段小视频。
图14. 随机生成的视频,沙滩上波涛涌动,火车奔驰的场景条件视频生成,下图是输入一张静态图,模型自动推演出一段小视频。

 图15.根据一张草地静态图,模型自动推测人的移动场景,该图为动图,如果无法查看, 请访问
图15.根据一张草地静态图,模型自动推测人的移动场景,该图为动图,如果无法查看, 请访问
 图16.给出一张铁道图,模型自动推测火车跑过的样子,该图为动图,如果无法查看, 请访问MIT的CSAIL实验室也放出了一篇博客,题目是 《教会机器去预测未来》,该模型在youtube视频和电视剧上(例如 The Office和《绝望主妇》)训练,训练好以后,如果你给该模型一个亲吻之前的图片,该模型能自动推测出加下来拥抱亲吻的动作,具体的例子见下图。
图16.给出一张铁道图,模型自动推测火车跑过的样子,该图为动图,如果无法查看, 请访问MIT的CSAIL实验室也放出了一篇博客,题目是 《教会机器去预测未来》,该模型在youtube视频和电视剧上(例如 The Office和《绝望主妇》)训练,训练好以后,如果你给该模型一个亲吻之前的图片,该模型能自动推测出加下来拥抱亲吻的动作,具体的例子见下图。
 图17. 给出一张静态图,模型自动推测接下来的动作哈佛大学的Lotter等人提出了 PredNet,该模型也是在 KITTI数据集上训练,然后该模型就可以根据前面的视频,预测行车记录仪接下来几帧的图像,模型是用长短期记忆神经网络(LSTM)训练得到的。具体例子见下图,给出行车记录仪前几张的图片,自动预测接下来的五帧场景,模型输入几帧图像后,预测接下来的5帧,由图可知,越往后,模型预测的越是模糊 ,但模型已经可以给出有参加价值的预测结果了。图片是动图,如果无法正常查看,请访问论文 作者的博客
图17. 给出一张静态图,模型自动推测接下来的动作哈佛大学的Lotter等人提出了 PredNet,该模型也是在 KITTI数据集上训练,然后该模型就可以根据前面的视频,预测行车记录仪接下来几帧的图像,模型是用长短期记忆神经网络(LSTM)训练得到的。具体例子见下图,给出行车记录仪前几张的图片,自动预测接下来的五帧场景,模型输入几帧图像后,预测接下来的5帧,由图可知,越往后,模型预测的越是模糊 ,但模型已经可以给出有参加价值的预测结果了。图片是动图,如果无法正常查看,请访问论文 作者的博客
图18. 给出行车记录仪前几张的图片,自动预测接下来的五帧场景,该图为动图,如果无法查看,请访问
4 总结
生成对抗网络,无监督学习视频预测的论文实在是太多,本人精力实在有限,对此感兴趣的读者可以每天刷一下arxiv的计算机视觉版块的计算机视觉和模型识别,神经网络和进化计算和人工智能等相应版块,基本上每天都有这方面新论文出现。图像检测和分割,增强学习,生成对抗网络,预测学习都是人工智能发展火热的方向,希望对深度学习感兴趣的我们在这方面能做出来点成果。谢谢朋友们的阅读,对深度无监督学习感兴趣的朋友,欢迎一起学习交流,请私信我。
5 参考文献
在写本文的过程中,我尽量把论文网址以链接的形式附着在正文中.本文参考的大部分博客和论文整理如下,方便大家和自己以后研究查看。
参考博客
- 【NIPS 主旨演讲】Yann LeCun:用预测学习替代无监督学习
- 计算机视觉和 CNN 发展十一座里程碑
- Generative Models
- Generating Videos with Scene Dynamics
- Teaching machines to predict the future
-
参考论文
- Resnet模型,图像分类,超过人类的计算机识别水平。Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
- 图像检测 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 图像分割Conditional Random Fields as Recurrent Neural Networks
- 图像标注,看图说话 Show and Tell: A Neural Image Caption Generator
- 文字生成图像Generative Adversarial Text to Image Synthesis
- 强化学习玩flyppy bird Using Deep Q-Network to Learn How To Play Flappy Bird
- 强化学习玩Atari游戏 Playing Atari with Deep Reinforcement Learning
- 生成对抗网络 Generative Adversarial Networks
- 条件生成对抗网络Conditional Generative Adversarial Nets
- 生成对抗网络做图像超分辨率Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- 深度卷积生成对抗网络Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- 由图片推演视频Generating Videos with Scene Dynamics
- 视频预测和无监督学习Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
-
HashMap与HashTable区别
点评 :HashMap基于Hashtable实现,不同之处在于HashMap是非同步的,并且允许null,即null value和null key,Hashtable则不允许null,详见: http://oznyang.iteye.com/blog/30690 。此外,记住一点:hashmap/hashset等凡是带有hash字眼的均基于hashtable实现,没带hash字眼的如set/map均是基于红黑树实现,前者无序,后者有序,详见此文第一部分:《教你如何迅速秒杀掉:99%的海量数据处理面试题》 。
不过,估计还是直接来图更形象点,故直接上图(图片来源:July9月28日在上海交大面试&算法讲座的PPT http://vdisk.weibo.com/s/zrFL6OXKg_1me ):

-
在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是( )
A 将负样本重复10次,生成10w样本量,打乱顺序参与分类
B 直接进行分类,可以最大限度利用数据
C 从10w正样本中随机抽取1w参与分类
D 将负样本每个权重设置为10,正样本权重为1,参与训练过程
@管博士:准确的说,其实选项中的这些方法各有优缺点,需要具体问题具体分析,有篇文章对各种方法的优缺点进行了分析,讲的不错 感兴趣的同学可以参考一下:https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/。 -
以下第69题~第83题来自:http://blog.csdn.net/u011204487
深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为
m∗n,n∗p,p∗q,且m
A.(AB)C
B.AC(B)
C.A(BC)
D.所以效率都相同
正确答案:A
@BlackEyes_SGC: m*n*pNave Bayes是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:()
A.各类别的先验概率P(C)是相等的
B.以0为均值,sqr(2)/2为标准差的正态分布
C.特征变量X的各个维度是类别条件独立随机变量
D.P(X|C)是高斯分布
正确答案:C
@BlackEyes_SGC:朴素贝叶斯的条件就是每个变量相互独立。关于支持向量机SVM,下列说法错误的是()
A.L2正则项,作用是最大化分类间隔,使得分类器拥有更强的泛化能力
B.Hinge 损失函数,作用是最小化经验分类错误
C.分类间隔为1/||w||,||w||代表向量的模
D.当参数C越小时,分类间隔越大,分类错误越多,趋于欠学习
正确答案:C
@BlackEyes_SGC:
A正确。考虑加入正则化项的原因:想象一个完美的数据集,y>1是正类,y<-1是负类,决策面y=0,加入一个y=-30的正类噪声样本,那么决策面将会变“歪”很多,分类间隔变小,泛化能力减小。加入正则项之后,对噪声样本的容错能力增强,前面提到的例子里面,决策面就会没那么“歪”了,使得分类间隔变大,提高了泛化能力。
B正确。
C错误。间隔应该是2/||w||才对,后半句应该没错,向量的模通常指的就是其二范数。
D正确。考虑软间隔的时候,C对优化问题的影响就在于把a的范围从[0,+inf]限制到了[0,C]。C越小,那么a就会越小,目标函数拉格朗日函数导数为0可以求出w=求和ai∗yi∗xi,a变小使得w变小,因此间隔2/||w||变大在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
A.EM算法
B.维特比算法
C.前向后向算法
D.极大似然估计
正确答案:D
@BlackEyes_SGC:
EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计
前向后向算法:用来算概率
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数
注意的是在给定观测序列和对应的状态序列估计模型参数,可以利用极大似然发估计。如果给定观测序列,没有对应的状态序列,才用EM,将状态序列看不不可测的隐数据。假定某同学使用Naive Bayesian(NB)分类模型时,不小心将训练数据的两个维度搞重复了,那么关于NB的说法中正确的是:
A.这个被重复的特征在模型中的决定作用会被加强
B.模型效果相比无重复特征的情况下精确度会降低
C.如果所有特征都被重复一遍,得到的模型预测结果相对于不重复的情况下的模型预测结果一样。
D.当两列特征高度相关时,无法用两列特征相同时所得到的结论来分析问题
E.NB可以用来做最小二乘回归
F.以上说法都不正确
正确答案:BD
@BlackEyes_SGC:NB的核心在于它假设向量的所有分量之间是独立的。在贝叶斯理论系统中,都有一个重要的条件独立性假设:假设所有特征之间相互独立,这样才能将联合概率拆分- 以下哪些方法不可以直接来对文本分类?
A、Kmeans
B、决策树
C、支持向量机
D、KNN正确答案: A分类不同于聚类。
@BlackEyes_SGC:A:Kmeans是聚类方法,典型的无监督学习方法。分类是监督学习方法,BCD都是常见的分类方法。
- 已知一组数据的协方差矩阵P,下面关于主分量说法错误的是()
A、主分量分析的最佳准则是对一组数据进行按一组正交基分解, 在只取相同数量分量的条件下,以均方误差计算截尾误差最小
B、在经主分量分解后,协方差矩阵成为对角矩阵
C、主分量分析就是K-L变换
D、主分量是通过求协方差矩阵的特征值得到
正确答案: C
@BlackEyes_SGC:K-L变换与PCA变换是不同的概念,PCA的变换矩阵是协方差矩阵,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内离散度矩阵等等)。当K-L变换矩阵为协方差矩阵时,等同于PCA。
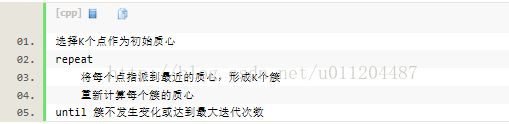
kmeans的复杂度
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数- 关于logit 回归和SVM 不正确的是(A)
A. Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。A错误
B. Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确
C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化。
D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。
@BlackEyes_SGC:Logit回归目标函数是最小化后验概率,Logit回归可以用于预测事件发生概率的大小,SVM目标是结构风险最小化,SVM可以有效避免模型过拟合。
- 输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为:
95
96
97
98
99
100
正确答案:C
@BlackEyes_SGC:计算尺寸不被整除只在GoogLeNet中遇到过。卷积向下取整,池化向上取整。
本题 (200-5+2*1)/2+1 为99.5,取99
(99-3)/1+1 为97
(97-3+2*1)/1+1 为97
研究过网络的话看到stride为1的时候,当kernel为 3 padding为1或者kernel为5 padding为2 一看就是卷积前后尺寸不变。
计算GoogLeNet全过程的尺寸也一样。
- 影响聚类算法结果的主要因素有(B、C、D )。
A.已知类别的样本质量;
B.分类准则;
C.特征选取;
D.模式相似性测度- 模式识别中,马式距离较之于欧式距离的优点是(C、D)。
A.平移不变性;
B.旋转不变性;
C尺度不变性;
D.考虑了模式的分布- 影响基本K-均值算法的主要因素有(ABD)。
A.样本输入顺序;
B.模式相似性测度;
C.聚类准则;
D.初始类中心的选取- 在统计模式分类问题中,当先验概率未知时,可以使用(BD)。
A. 最小损失准则;
B. 最小最大损失准则;
C. 最小误判概率准则;
D. N-P判决- 如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(BC)。
A. 已知类别样本质量;
B. 分类准则;
C. 特征选取;
D. 量纲- 欧式距离具有(A B );马式距离具有(A B C D )。
A. 平移不变性;
B. 旋转不变性;
C. 尺度缩放不变性;
D. 不受量纲影响的特性
- 你有哪些deep learning(rnn、cnn)调参的经验?
https://www.zhihu.com/question/41631631
- 简单说说RNN的原理
我们升学到高三准备高考时,此时的知识是由高二及高二之前所学的知识加上高三所学的知识合成得来,即我们的知识是由前序铺垫,是有记忆的,好比当电影字幕上出现:“我是”时,你会很自然的联想到:“我是中国人”。
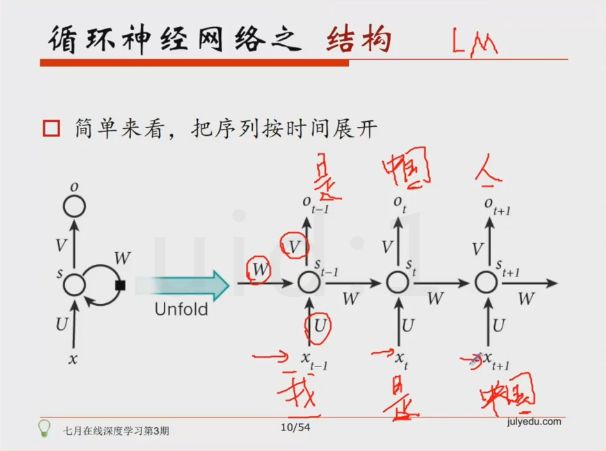
关于RNN,这里有课程详细讲RNN,包括RNN条件生成、attention,以及LSTM等等均有细致讲解:深度学习 [同品类最牛,培养DL工程师]。
- 什么是RNN?
@一只鸟的天空,本题解析来源:http://blog.csdn.net/heyongluoyao8/article/details/48636251
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:
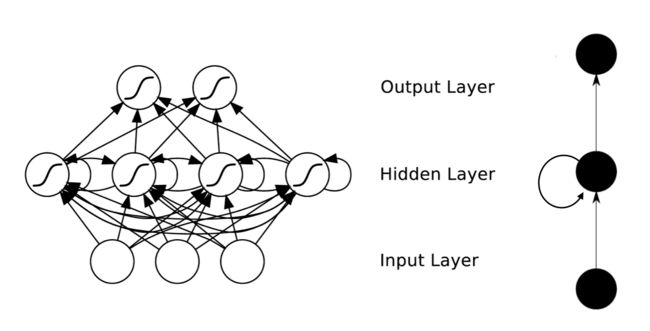
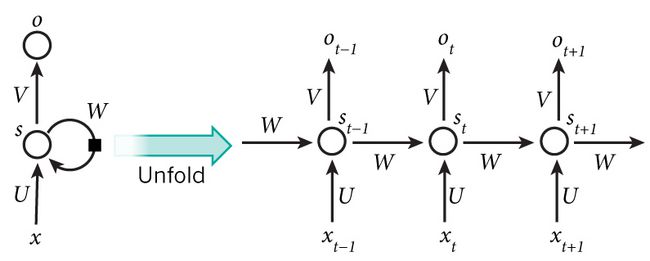
From Nature
RNNs包含输入单元(Input units),输入集标记为{x0,x1,...,xt,xt+1,...},而输出单元(Output units)的输出集则被标记为{y0,y1,...,yt,yt+1.,..}。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,...,st,st+1,...},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
上图将循环神经网络进行展开成一个全神经网络。例如,对一个包含5个单词的语句,那么展开的网络便是一个五层的神经网络,每一层代表一个单词。对于该网络的计算过程如下:- xt表示第t,t=1,2,3…步(step)的输入。比如,x1为第二个词的one-hot向量(根据上图,x0为第一个词);
- st为隐藏层的第t步的状态,它是网络的记忆单元。 st根据当前输入层的输出与上一步隐藏层的状态进行计算。st=f(Uxt+Wst−1),其中f一般是非线性的激活函数,如tanh或ReLU,在计算s0时,即第一个单词的隐藏层状态,需要用到s−1,但是其并不存在,在实现中一般置为0向量;
- ot是第t步的输出,如下个单词的向量表示,ot=softmax(Vst).
更多请看此文:循环神经网络(RNN, Recurrent Neural Networks)介绍。
RNN是怎么从单层网络一步一步构造的的
@何之源,本题解析来源:https://zhuanlan.zhihu.com/p/28054589
一、从单层网络谈起
在学习RNN之前,首先要了解一下最基本的单层网络,它的结构如图:
输入是x,经过变换Wx+b和激活函数f得到输出y。相信大家对这个已经非常熟悉了。
二、经典的RNN结构(N vs N)
在实际应用中,我们还会遇到很多序列形的数据:

如:
- 自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推。
- 语音处理。此时,x1、x2、x3……是每帧的声音信号。
- 时间序列问题。例如每天的股票价格等等。
序列形的数据就不太好用原始的神经网络处理了。为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。先从h1的计算开始看:

图示中记号的含义是:
- 圆圈或方块表示的是向量。
- 一个箭头就表示对该向量做一次变换。如上图中h0和x1分别有一个箭头连接,就表示对h0和x1各做了一次变换。
在很多论文中也会出现类似的记号,初学的时候很容易搞乱,但只要把握住以上两点,就可以比较轻松地理解图示背后的含义。
h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。

依次计算剩下来的(使用相同的参数U、W、b):
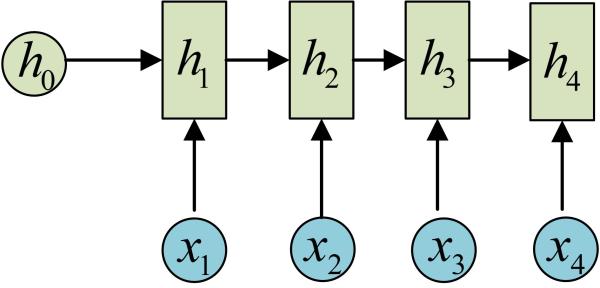
我们这里为了方便起见,只画出序列长度为4的情况,实际上,这个计算过程可以无限地持续下去。
我们目前的RNN还没有输出,得到输出值的方法就是直接通过h进行计算:
正如之前所说,一个箭头就表示对对应的向量做一次类似于f(Wx+b)的变换,这里的这个箭头就表示对h1进行一次变换,得到输出y1。
剩下的输出类似进行(使用和y1同样的参数V和c):
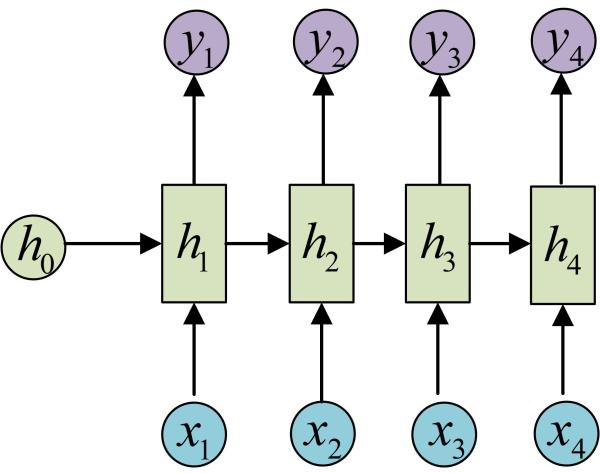
OK!大功告成!这就是最经典的RNN结构,我们像搭积木一样把它搭好了。它的输入是x1, x2, …..xn,输出为y1, y2, …yn,也就是说,输入和输出序列必须要是等长的。
由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:
- 计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
- 输入为字符,输出为下一个字符的概率。这就是著名的Char RNN(详细介绍请参考:The Unreasonable Effectiveness of Recurrent Neural Networks,Char RNN可以用来生成文章、诗歌,甚至是代码。此篇博客里有自动生成歌词的实验教程《基于torch学汪峰写歌词、聊天机器人、图像着色/生成、看图说话、字幕生成》)。
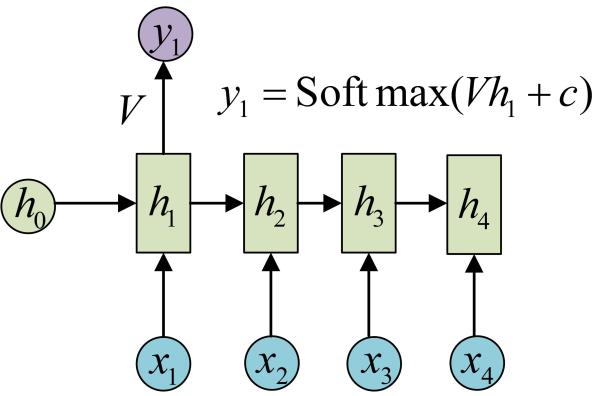
三、N VS 1
有的时候,我们要处理的问题输入是一个序列,输出是一个单独的值而不是序列,应该怎样建模呢?实际上,我们只在最后一个h上进行输出变换就可以了:
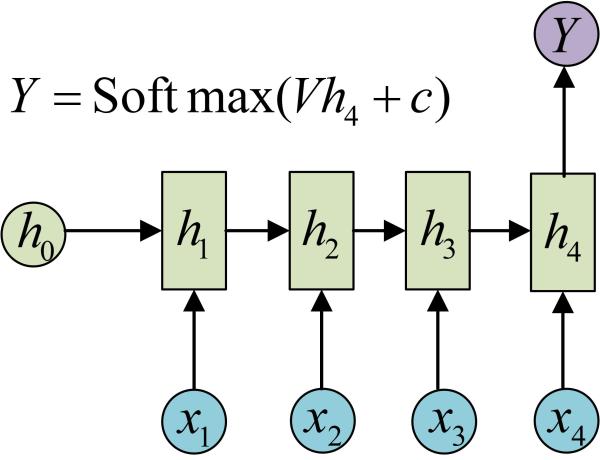
这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
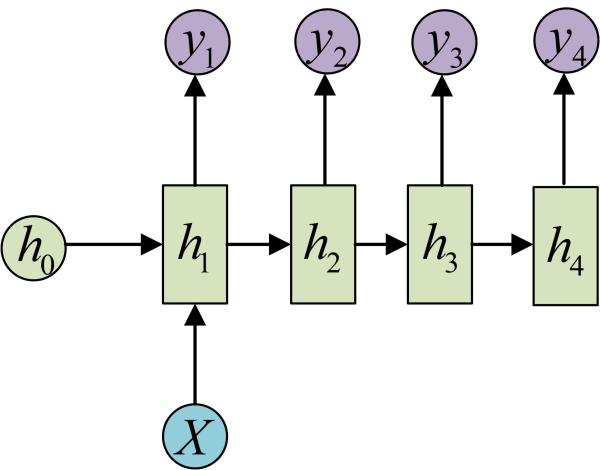
四、1 VS N
输入不是序列而输出为序列的情况怎么处理?我们可以只在序列开始进行输入计算:
还有一种结构是把输入信息X作为每个阶段的输入:
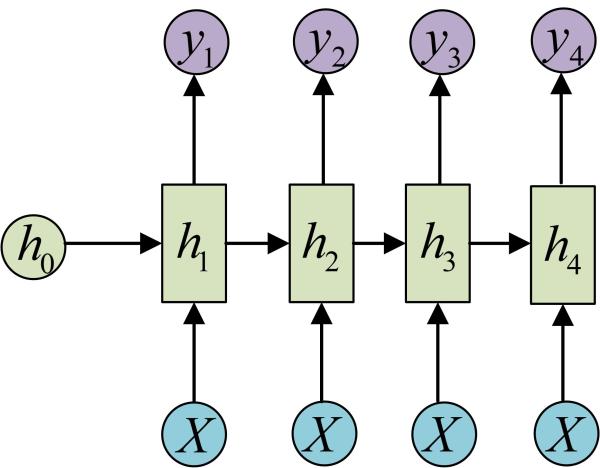
下图省略了一些X的圆圈,是一个等价表示:
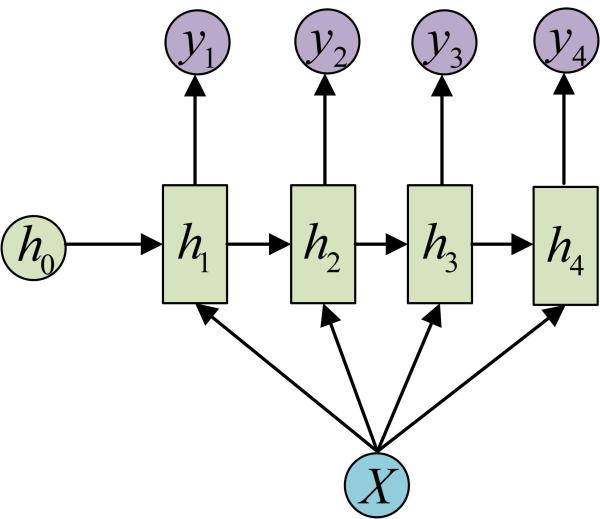
这种1 VS N的结构可以处理的问题有:
- 从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子
- 从类别生成语音或音乐等
五、N vs M
下面我们来介绍RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
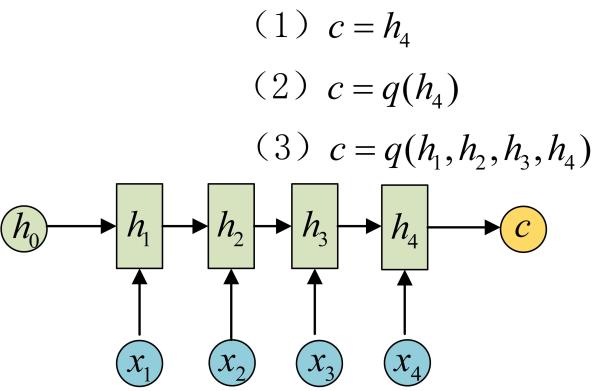
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
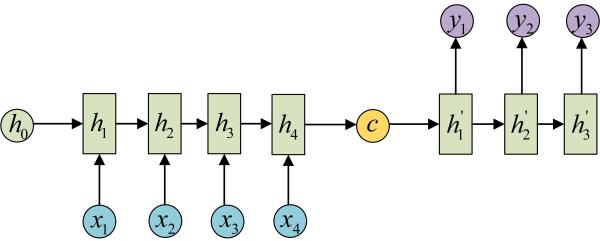
还有一种做法是将c当做每一步的输入:
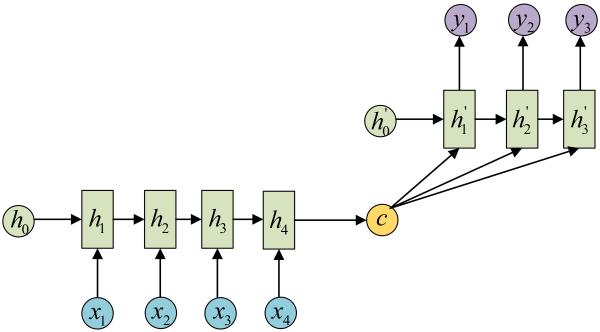
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
- 文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
- 阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别。输入是语音信号序列,输出是文字序列。
- RNN中只能采用tanh而不是ReLu作为激活函数么?
解析详见:https://www.zhihu.com/question/61265076
- 深度学习(CNN RNN Attention)解决大规模文本分类问题
https://zhuanlan.zhihu.com/p/25928551
- 如何解决RNN梯度爆炸和弥散的问题?的
本题解析来源:深度学习与自然语言处理(7)_斯坦福cs224d 语言模型,RNN,LSTM与GRU为了解决梯度爆炸问题,Thomas Mikolov首先提出了一个简单的启发性的解决方案,就是当梯度大于一定阈值的的时候,将它截断为一个较小的数。具体如算法1所述:
算法:当梯度爆炸时截断梯度(伪代码)
g^←∂E∂W
if ∥g^∥≥threshold then
g^←threashold∥∥g^∥∥g^
下图可视化了梯度截断的效果。它展示了一个小的rnn(其中W为权值矩阵,b为bias项)的决策面。这个模型是一个一小段时间的rnn单元组成;实心箭头表明每步梯度下降的训练过程。当梯度下降过程中,模型的目标函数取得了较高的误差时,梯度将被送到远离决策面的位置。截断模型产生了一个虚线,它将误差梯度拉回到离原始梯度接近的位置。
梯度爆炸,梯度截断可视化
为了解决梯度弥散的问题,我们介绍了两种方法。第一种方法是将随机初始化W(hh)改为一个有关联的矩阵初始化。第二种方法是使用ReLU(Rectified Linear Units)代替sigmoid函数。ReLU的导数不是0就是1.因此,神经元的梯度将始终为1,而不会当梯度传播了一定时间之后变小。
- 如何理解LSTM网络
@Not_GOD,本题解析来源:http://www.jianshu.com/p/9dc9f41f0b29/Recurrent Neural Networks
人类并不是每时每刻都从一片空白的大脑开始他们的思考。在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。
传统的神经网络并不能做到这点,看起来也像是一种巨大的弊端。例如,假设你希望对电影中的每个时间点的时间类型进行分类。传统的神经网络应该很难来处理这个问题——使用电影中先前的事件推断后续的事件。
RNN 解决了这个问题。RNN 是包含循环的网络,允许信息的持久化。
RNN 包含循环在上面的示例图中,神经网络的模块,A,正在读取某个输入 x_i,并输出一个值 h_i。循环可以使得信息可以从当前步传递到下一步。
这些循环使得 RNN 看起来非常神秘。然而,如果你仔细想想,这样也不比一个正常的神经网络难于理解。RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开: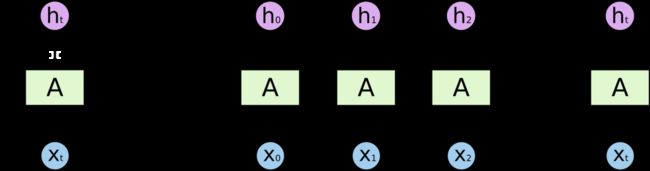
展开的 RNN
链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
并且 RNN 也已经被人们应用了!在过去几年中,应用 RNN 在语音识别,语言建模,翻译,图片描述等问题上已经取得一定成功,并且这个列表还在增长。我建议大家参考 Andrej Karpathy 的博客文章—— The Unreasonable Effectiveness of Recurrent Neural Networks 来看看更丰富有趣的 RNN 的成功应用。
而这些成功应用的关键之处就是 LSTM 的使用,这是一种特别的 RNN,比标准的 RNN 在很多的任务上都表现得更好。几乎所有的令人振奋的关于 RNN 的结果都是通过 LSTM 达到的。这篇博文也会就 LSTM 进行展开。长期依赖(Long-Term Dependencies)问题
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。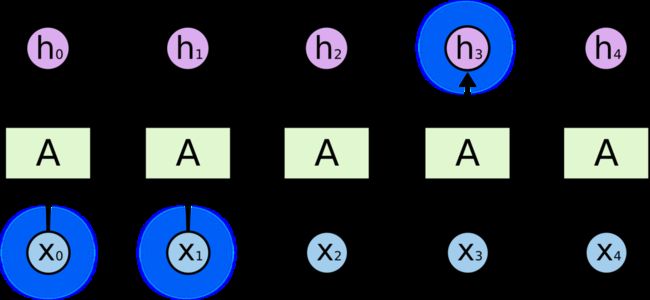
不太长的相关信息和位置间隔但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。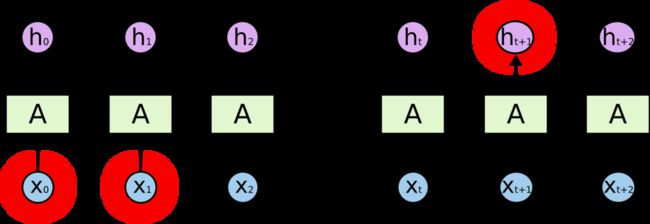
相当长的相关信息和位置间隔在理论上,RNN 绝对可以处理这样的 长期依赖 问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN 肯定不能够成功学习到这些知识。Bengio, et al. (1994)等人对该问题进行了深入的研究,他们发现一些使训练 RNN 变得非常困难的相当根本的原因。
然而,幸运的是,LSTM 并没有这个问题!LSTM 网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。如@寒小阳所说:LSTM和基线RNN并没有特别大的结构不同,但是它们用了不同的函数来计算隐状态。LSTM的“记忆”我们叫做细胞/cells,你可以直接把它们想做黑盒,这个黑盒的输入为前状态ht−1和当前输入xt。这些“细胞”会决定哪些之前的信息和状态需要保留/记住,而哪些要被抹去。实际的应用中发现,这种方式可以有效地保存很长时间之前的关联信息。
LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。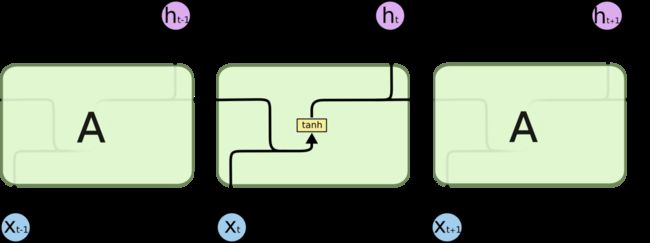
标准 RNN 中的重复模块包含单一的层
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。

LSTM 中的重复模块包含四个交互的层
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。

LSTM 中的图标
在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
LSTM 的核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。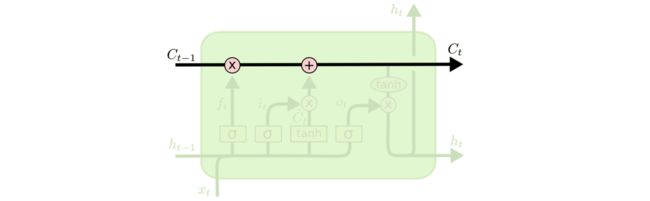
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
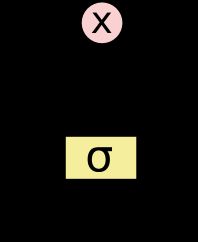
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解 LSTM
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取
h_{t-1}和x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态C_{t-1}中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。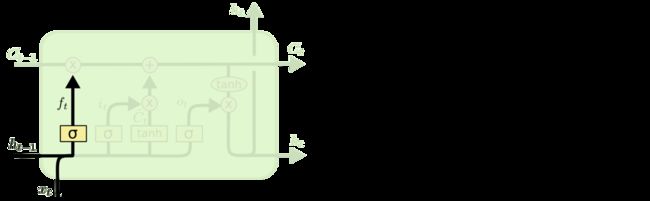
决定丢弃信息
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,\tilde{C}_t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。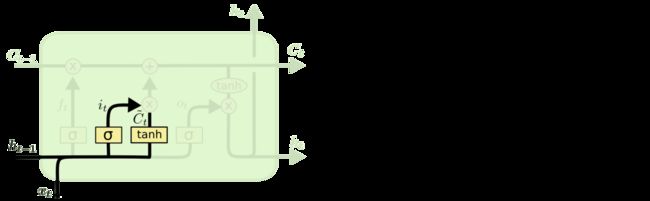
确定更新的信息现在是更新旧细胞状态的时间了,
C_{t-1}更新为C_t。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与f_t相乘,丢弃掉我们确定需要丢弃的信息。接着加上i_t * \tilde{C}_t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。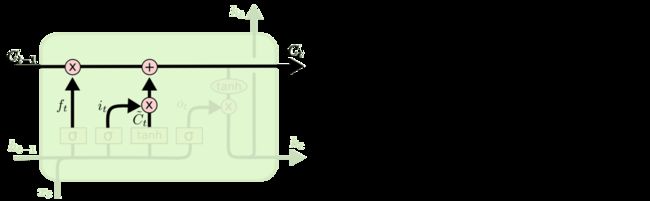
更新细胞状态最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。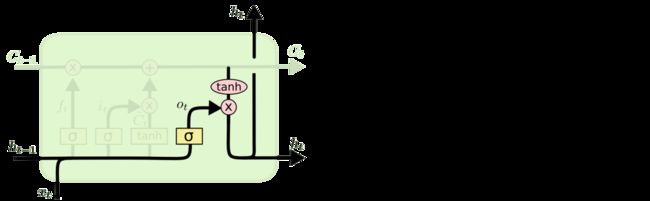
输出信息LSTM 的变体
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。差异非常小,但是也值得拿出来讲一下。
其中一个流形的 LSTM 变体,就是由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。是说,我们让 门层 也会接受细胞状态的输入。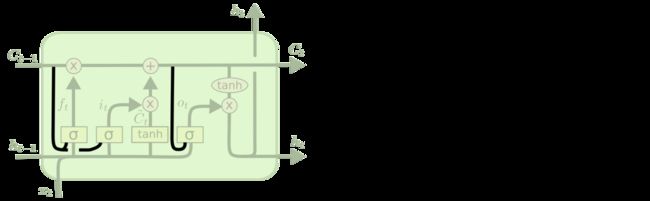
peephole 连接上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
另一个变体是通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。我们仅仅会当我们将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态 。
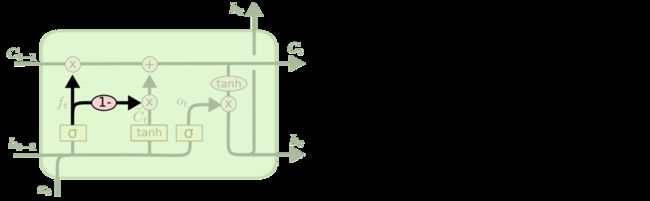
coupled 忘记门和输入门
另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
GRU
这里只是部分流行的 LSTM 变体。当然还有很多其他的,如 Yao, et al. (2015) 提出的 Depth Gated RNN。还有用一些完全不同的观点来解决长期依赖的问题,如 Koutnik, et al. (2014) 提出的 Clockwork RNN。
要问哪个变体是最好的?其中的差异性真的重要吗? Greff, et al. (2015) 给出了流行变体的比较,结论是他们基本上是一样的。 Jozefowicz, et al. (2015) 则在超过 1 万种 RNN 架构上进行了测试,发现一些架构在某些任务上也取得了比 LSTM 更好的结果。
Jozefowicz等人论文截图结论
刚开始,我提到通过 RNN 得到重要的结果。本质上所有这些都可以使用 LSTM 完成。对于大多数任务确实展示了更好的性能!
由于 LSTM 一般是通过一系列的方程表示的,使得 LSTM 有一点令人费解。然而本文中一步一步地解释让这种困惑消除了不少。
LSTM 是我们在 RNN 中获得的重要成功。很自然地,我们也会考虑:哪里会有更加重大的突破呢?在研究人员间普遍的观点是:“Yes! 下一步已经有了——那就是注意力!” 这个想法是让 RNN 的每一步都从更加大的信息集中挑选信息。例如,如果你使用 RNN 来产生一个图片的描述,可能会选择图片的一个部分,根据这部分信息来产生输出的词。实际上,Xu, et al.(2015)已经这么做了——如果你希望深入探索注意力可能这就是一个有趣的起点!还有一些使用注意力的相当振奋人心的研究成果,看起来有更多的东西亟待探索……
注意力也不是 RNN 研究领域中唯一的发展方向。例如,Kalchbrenner, et al. (2015) 提出的 Grid LSTM 看起来也是很有前途。使用生成模型的 RNN,诸如Gregor, et al. (2015) Chung, et al. (2015) 和 Bayer & Osendorfer (2015) 提出的模型同样很有趣。在过去几年中,RNN 的研究已经相当的燃,而研究成果当然也会更加丰富!
再次说明下,本题解析基本取自Not_GOD翻译Christopher Olah 博文的《理解LSTM网络》,致谢。RNN、LSTM、GRU区别
@我愛大泡泡,本题解析来源:http://blog.csdn.net/woaidapaopao/article/details/77806273- RNN引入了循环的概念,但是在实际过程中却出现了初始信息随时间消失的问题,即长期依赖(Long-Term Dependencies)问题,所以引入了LSTM。
- LSTM:因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸的变化是关键,下图非常明确适合记忆:
- GRU是LSTM的变体,将忘记门和输入们合成了一个单一的更新门。
当机器学习性能遭遇瓶颈时,你会如何优化的
可以从这4个方面进行尝试:、基于数据、借助算法、用算法调参、借助模型融合。当然能谈多细多深入就看你的经验心得了。这里有一份参考清单:机器学习性能改善备忘单。如何提高深度学习的性能
http://blog.csdn.net/han_xiaoyang/article/details/52654879做过什么样的机器学习项目?比如如何从零构建一个推荐系统
这里有一个推荐系统的公开课《推荐系统》,另,再推荐一个课程:机器学习项目班 [10次纯项目讲解,100%纯实战]。什麽样的资料集不适合用深度学习?
@抽象猴,来源:https://www.zhihu.com/question/41233373- 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
- 数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
- 广义线性模型是怎被应用在深度学习中?
@许韩,来源:https://www.zhihu.com/question/41233373/answer/145404190
A Statistical View of Deep Learning (I): Recursive GLMs
深度学习从统计学角度,可以看做递归的广义线性模型。
广义线性模型相对于经典的线性模型(y=wx+b),核心在于引入了连接函数g(.),形式变为:y=g−1(wx+b)。
深度学习时递归的广义线性模型,神经元的激活函数,即为广义线性模型的链接函数。逻辑回归(广义线性模型的一种)的Logistic函数即为神经元激活函数中的Sigmoid函数,很多类似的方法在统计学和神经网络中的名称不一样,容易引起初学者(这里主要指我)的困惑。下图是一个对照表
- 准备机器学习面试应该了解哪些理论知识
@穆文,来源:https://www.zhihu.com/question/62482926

看下来,这些问题的答案基本都在本BAT机器学习面试1000题系列里了。标准化与归一化的区别
简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。规则为l2的归一化公式如下:
特征向量的缺失值处理
1. 缺失值较多.直接将该特征舍弃掉,否则可能反倒会带入较大的noise,对结果造成不良影响。
2. 缺失值较少,其余的特征缺失值都在10%以内,我们可以采取很多的方式来处理:
1) 把NaN直接作为一个特征,假设用0表示;
2) 用均值填充;
3) 用随机森林等算法预测填充随机森林如何处理缺失值
方法一(na.roughfix)简单粗暴,对于训练集,同一个class下的数据,如果是分类变量缺失,用众数补上,如果是连续型变量缺失,用中位数补。
方法二(rfImpute)这个方法计算量大,至于比方法一好坏?不好判断。先用na.roughfix补上缺失值,然后构建森林并计算proximity matrix,再回头看缺失值,如果是分类变量,则用没有缺失的观测实例的proximity中的权重进行投票。如果是连续型变量,则用proximity矩阵进行加权平均的方法补缺失值。然后迭代4-6次,这个补缺失值的思想和KNN有些类似12。随机森林如何评估特征重要性
衡量变量重要性的方法有两种,Decrease GINI 和 Decrease Accuracy:
1) Decrease GINI: 对于回归问题,直接使用argmax(VarVarLeftVarRight)作为评判标准,即当前节点训练集的方差Var减去左节点的方差VarLeft和右节点的方差VarRight。
2) Decrease Accuracy:对于一棵树Tb(x),我们用OOB样本可以得到测试误差1;然后随机改变OOB样本的第j列:保持其他列不变,对第j列进行随机的上下置换,得到误差2。至此,我们可以用误差1-误差2来刻画变量j的重要性。基本思想就是,如果一个变量j足够重要,那么改变它会极大的增加测试误差;反之,如果改变它测试误差没有增大,则说明该变量不是那么的重要。优化Kmeans
使用kd树或者ball tree
将所有的观测实例构建成一颗kd树,之前每个聚类中心都是需要和每个观测点做依次距离计算,现在这些聚类中心根据kd树只需要计算附近的一个局部区域即可KMeans初始类簇中心点的选取
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。
1. 从输入的数据点集合中随机选择一个点作为第一个聚类中心
2. 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3. 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4. 重复2和3直到k个聚类中心被选出来
5. 利用这k个初始的聚类中心来运行标准的k-means算法解释对偶的概念
一个优化问题可以从两个角度进行考察,一个是primal 问题,一个是dual 问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM中就是将primal问题转换为dual问题进行求解,从而进一步引入核函数的思想。如何进行特征选择?
特征选择是一个重要的数据预处理过程,主要有两个原因:一是减少特征数量、降维,使模型泛化能力更强,减少过拟合;二是增强对特征和特征值之间的理解
常见的特征选择方式:
1. 去除方差较小的特征
2. 正则化。1正则化能够生成稀疏的模型。L2正则化的表现更加稳定,由于有用的特征往往对应系数非零。
3. 随机森林,对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。一般不需要feature engineering、调参等繁琐的步骤。它的两个主要问题,1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。
4. 稳定性选择。是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。数据预处理
1. 缺失值,填充缺失值fillna:
i. 离散:None,
ii. 连续:均值。
iii. 缺失值太多,则直接去除该列
2. 连续值:离散化。有的模型(如决策树)需要离散值
3. 对定量特征二值化。核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。如图像操作
4. 皮尔逊相关系数,去除高度相关的列简单说说特征工程
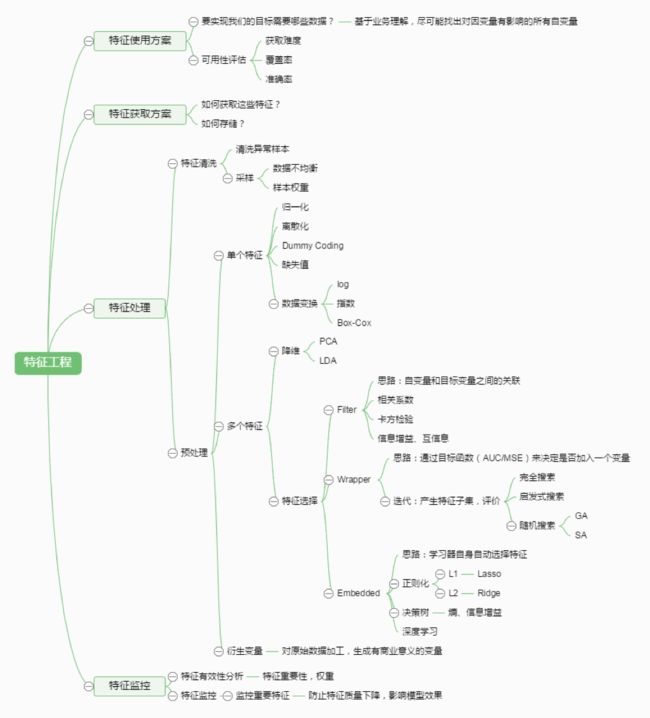
上图来源:http://www.julyedu.com/video/play/18你知道有哪些数据处理和特征工程的处理?
更多请查看此课程《 机器学习工程师 第八期 [六大阶段、层层深入]》第7次课 特征工程。- 请对比下Sigmoid、Tanh、ReLu这三个激活函数
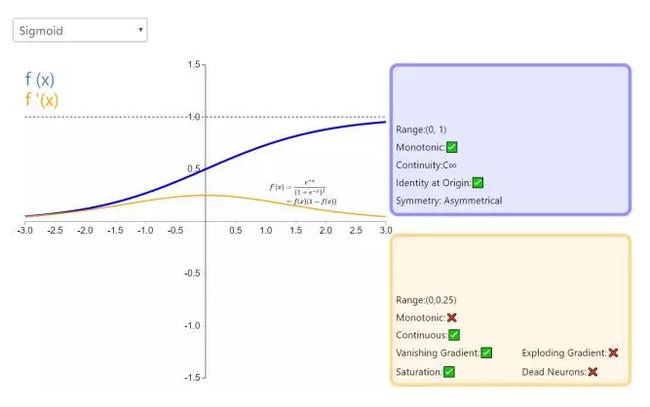
sigmoid函数又称logistic函数,应用在Logistic回归中。logistic回归的目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数
其中x是n维特征向量,函数g就是logistic函数。而的图像是
可以看到,将无穷映射到了(0,1)。而假设函数就是特征属于y=1的概率。
从而,当我们要判别一个新来的特征属于哪个类时,只需求
即可,若大于0.5就是y=1的类,反之属于y=0类。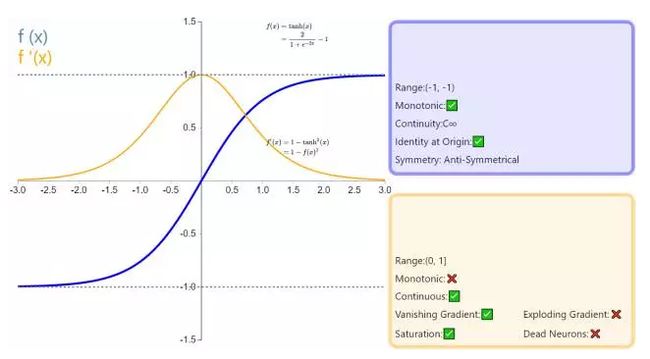
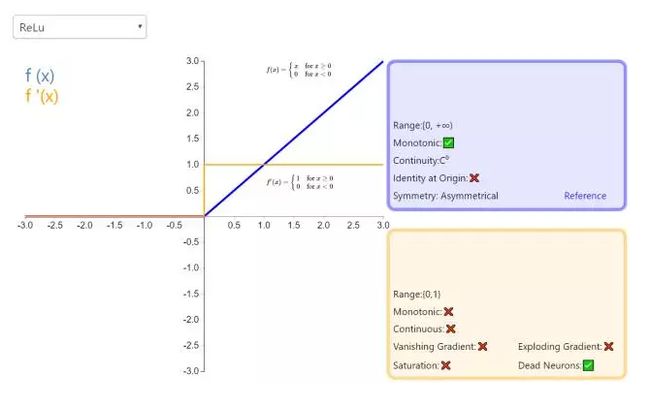
更多详见:https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ
- Sigmoid、Tanh、ReLu这三个激活函数有什么缺点或不足,有没改进的激活函数
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273- 怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感
https://www.zhihu.com/question/58230411
- 为什么引入非线性激励函数?
@Begin Again,来源:https://www.zhihu.com/question/29021768
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)。
请问人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
@Begin Again,来源:https://www.zhihu.com/question/29021768
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。 多加一句,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[2] He, Kaiming, et al. “Identity Mappings in Deep Residual Networks.” arXiv preprint arXiv:1603.05027 (2016).为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数?
为什么不是选择统一一种sigmoid或者tanh,而是混合使用呢?这样的目的是什么?
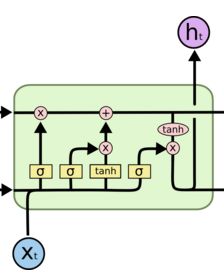
本题解析来源:https://www.zhihu.com/question/46197687
@beanfrog:二者目的不一样
sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。
tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
@hhhh:另可参见A Critical Review of Recurrent Neural Networks for Sequence Learning的section4.1,说了那两个tanh都可以替换成别的。衡量分类器的好坏
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
这里首先要知道TP、FN(真的判成假的)、FP(假的判成真)、TN四种(可以画一个表格)。
几种常用的指标:- 精度precision = TP/(TP+FP) = TP/~P (~p为预测为真的数量)
- 召回率 recall = TP/(TP+FN) = TP/ P
- F1值: 2/F1 = 1/recall + 1/precision
- ROC曲线:ROC空间是一个以伪阳性率(FPR,false positive rate)为X轴,真阳性率(TPR, true positive rate)为Y轴的二维坐标系所代表的平面。其中真阳率TPR = TP / P = recall, 伪阳率FPR = FP / N
机器学习和统计里面的auc的物理意义是啥
https://www.zhihu.com/question/39840928
观察增益gain, alpha和gamma越大,增益越小?
@AntZ:xgboost寻找分割点的标准是最大化gain. 考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中计算Gain按最大值找出最佳的分割点。它的计算公式分为四项, 可以由正则化项参数调整(lamda为叶子权重平方和的系数, gama为叶子数量):
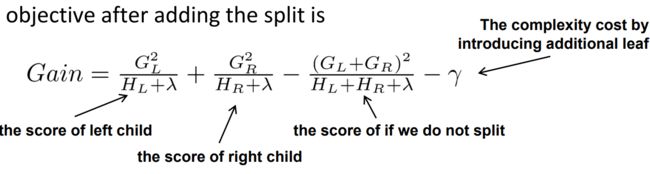
第一项是假设分割的左孩子的权重分数, 第二项为右孩子, 第三项为不分割总体分数, 最后一项为引入一个节点的复杂度损失
由公式可知, gama越大gain越小, lamda越大, gain可能小也可能大.
原问题是alpha而不是lambda, 这里paper上没有提到, xgboost实现上有这个参数. 上面是我从paper上理解的答案,下面是搜索到的:
https://zhidao.baidu.com/question/2121727290086699747.html?fr=iks&word=xgboost+lamda&ie=gbk
lambda[默认1]权重的L2正则化项。(和Ridge regression类似)。 这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。11、alpha[默认1]权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
gamma[默认0]在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。
- 什麽造成梯度消失问题? 推导一下
@许韩,来源:https://www.zhihu.com/question/41233373/answer/145404190-
- Yes you should understand backdrop-Andrej Karpathy
- How does the ReLu solve the vanishing gradient problem?
- 神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
- 梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0,造成学习停止。
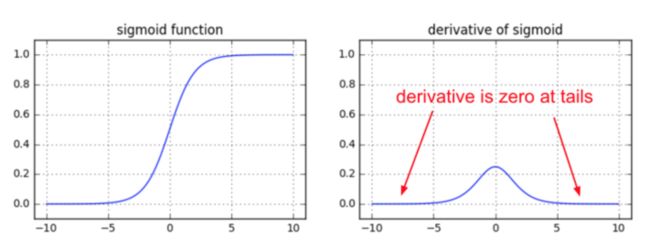
- Yes you should understand backdrop-Andrej Karpathy
- 什么是梯度消失和梯度爆炸?
@寒小阳,反向传播中链式法则带来的连乘,如果有数很小趋于0,结果就会特别小(梯度消失);如果数都比较大,可能结果会很大(梯度爆炸)。
@单车,下段来源:https://zhuanlan.zhihu.com/p/25631496
层数比较多的神经网络模型在训练时也是会出现一些问题的,其中就包括梯度消失问题(gradient vanishing problem)和梯度爆炸问题(gradient exploding problem)。梯度消失问题和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。例如,对于下图所示的含有3个隐藏层的神经网络,梯度消失问题发生时,接近于输出层的hidden layer 3等的权值更新相对正常,但前面的hidden layer 1的权值更新会变得很慢,导致前面的层权值几乎不变,仍接近于初始化的权值,这就导致hidden layer 1相当于只是一个映射层,对所有的输入做了一个同一映射,这是此深层网络的学习就等价于只有后几层的浅层网络的学习了。
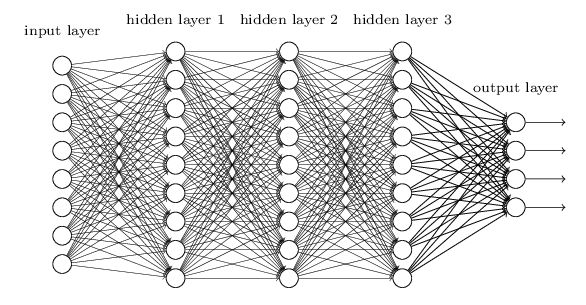
而这种问题为何会产生呢?以下图的反向传播为例(假设每一层只有一个神经元且对于每一层,其中为sigmoid函数)
可以推导出
而sigmoid的导数如下图
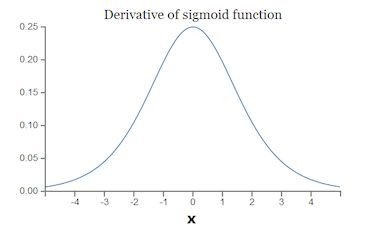
可见,的最大值为,而我们初始化的网络权值通常都小于1,因此,因此对于上面的链式求导,层数越多,求导结果越小,因而导致梯度消失的情况出现。
这样,梯度爆炸问题的出现原因就显而易见了,即1” style=”border:none; vertical-align:middle; outline:none; max-width:100%; max-height:100%; overflow:hidden; display:inline-block; margin:0px 3px”>,也就是比较大的情况。但对于使用sigmoid激活函数来说,这种情况比较少。因为的大小也与有关(),除非该层的输入值在一直一个比较小的范围内。
其实梯度爆炸和梯度消失问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑用ReLU激活函数取代sigmoid激活函数。另外,LSTM的结构设计也可以改善RNN中的梯度消失问题。
如何解决梯度消失和梯度膨胀
(1)梯度消失:
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0
可以采用ReLU激活函数有效的解决梯度消失的情况
(2)梯度膨胀
根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都大于1的话,在经过足够多层传播之后,误差对输入层的偏导会趋于无穷大
可以通过激活函数来解决推导下反向传播Backpropagation
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273反向传播是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式法则对参数进行一层一层的求导。这里重点强调:要将参数进行随机初始化而不是全部置0,否则所有隐层的数值都会与输入相关,这称为对称失效。
大致过程是:-
首先前向传导计算出所有节点的激活值和输出值,
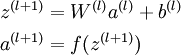
-
计算整体损失函数:

- 然后针对第L层的每个节点计算出残差(这里是因为UFLDL中说的是残差,本质就是整体损失函数对每一层激活值Z的导数),所以要对W求导只要再乘上激活函数对W的导数即可
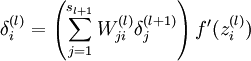

、SVD和PCA
PCA的理念是使得数据投影后的方差最大,找到这样一个投影向量,满足方差最大的条件即可。而经过了去除均值的操作之后,就可以用SVD分解来求解这样一个投影向量,选择特征值最大的方向。
数据不平衡问题
这主要是由于数据分布不平衡造成的。解决方法如下:
- 采样,对小样本加噪声采样,对大样本进行下采样
- 进行特殊的加权,如在Adaboost中或者SVM中
- 采用对不平衡数据集不敏感的算法
- 改变评价标准:用AUC/ROC来进行评价
- 采用Bagging/Boosting/ensemble等方法
- 考虑数据的先验分布
简述神经网络的发展
MP模型+sgn—->单层感知机(只能线性)+sgn— Minsky 低谷 —>多层感知机+BP+sigmoid—- (低谷) —>深度学习+pre-training+ReLU/sigmoid
深度学习常用方法
@SmallisBig,来源:http://blog.csdn.net/u010496169/article/details/73550487
全连接DNN(相邻层相互连接、层内无连接):
AutoEncoder(尽可能还原输入)、Sparse Coding(在AE上加入L1规范)、RBM(解决概率问题)—–>特征探测器——>栈式叠加 贪心训练
RBM—->DBN
解决全连接DNN的全连接问题—–>CNN
解决全连接DNN的无法对时间序列上变化进行建模的问题—–>RNN—解决时间轴上的梯度消失问题——->LSTM
神经网络模型(Neural Network)因受人类大脑的启发而得名。

神经网络由许多神经元(Neuron)组成,每个神经元接受一个输入,对输入进行处理后给出一个输出,如下图所示。请问下列关于神经元的描述中,哪一项是正确的?

-
每个神经元只有一个输入和一个输出
-
每个神经元有多个输入和一个输出
-
每个神经元有一个输入和多个输出
-
每个神经元有多个输入和多个输出
-
上述都正确
答案:(E)
每个神经元可以有一个或多个输入,和一个或多个输出。
下图是一个神经元的数学表示
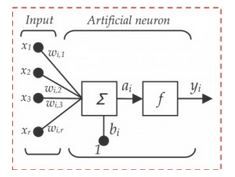
这些组成部分分别表示为:
- x1, x2,…, xN:表示神经元的输入。可以是输入层的实际观测值,也可以是某一个隐藏层(Hidden Layer)的中间值
- w1, w2,…,wN:表示每一个输入的权重
- bi:表示偏差单元/偏移量(bias unit)。作为常数项加到激活函数的输入当中,类似截距(Intercept)
- a:作为神经元的激励函数(Activation),可以表示为
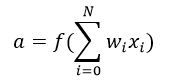
- y:神经元输出
考虑上述标注,线性等式(y = mx + c)可以被认为是属于神经元吗:
A. 是
B. 否
答案:(A)
一个不包含非线性的神经元可以看作是线性回归函数(Linear Regression Function)。
在一个神经网络中,知道每一个神经元的权重和偏差是最重要的一步。如果知道了神经元准确的权重和偏差,便可以近似任何函数,但怎么获知每个神经的权重和偏移呢?
A 搜索每个可能的权重和偏差组合,直到得到最佳值
B 赋予一个初始值,然后检查跟最佳值的差值,不断迭代调整权重
C 随机赋值,听天由命
D 以上都不正确的
答案:(C)
选项C是对梯度下降的描述。
梯度下降算法的正确步骤是什么?
-
计算预测值和真实值之间的误差
-
重复迭代,直至得到网络权重的最佳值
-
把输入传入网络,得到输出值
-
用随机值初始化权重和偏差
-
对每一个产生误差的神经元,调整相应的(权重)值以减小误差
A. 1, 2, 3, 4, 5
B. 5, 4, 3, 2, 1
C. 3, 2, 1, 5, 4
D. 4, 3, 1, 5, 2
答案:(D)
已知:
- 大脑是有很多个叫做神经元的东西构成,神经网络是对大脑的简单的数学表达。
- 每一个神经元都有输入、处理函数和输出。
- 神经元组合起来形成了网络,可以拟合任何函数。
- 为了得到最佳的神经网络,我们用梯度下降方法不断更新模型
给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
A 加入更多层,使神经网络的深度增加
B 有维度更高的数据
C 当这是一个图形识别的问题时
D 以上都不正确
答案:(A)
更多层意味着网络更深。没有严格的定义多少层的模型才叫深度模型,目前如果有超过2层的隐层,那么也可以及叫做深度模型。
卷积神经网络可以对一个输入进行多种变换(旋转、平移、缩放),这个表述正确吗?
正确
错误
答案:(B)
把数据传入神经网络之前需要做一系列数据预处理(也就是旋转、平移、缩放)工作,神经网络本身不能完成这些变换。
下面哪项操作能实现跟神经网络中Dropout的类似效果?
A Boosting
B Bagging
C Stacking
D Mapping
Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
下列哪一项在神经网络中引入了非线性?
-
随机梯度下降
-
修正线性单元(ReLU)
-
卷积函数
-
以上都不正确
答案:(B)
修正线性单元是非线性的激活函数。
在训练神经网络时,损失函数(loss)在最初的几个epochs时没有下降,可能的原因是?(D)D 以上都有可能
A 学习率(learning rate)太低
B 正则参数太高
C 陷入局部最小值
下列哪项关于模型能力(model capacity)的描述是正确的?(指神经网络模型能拟合复杂函数的能力)
-
隐藏层层数增加,模型能力增加
-
Dropout的比例增加,模型能力增加
-
学习率增加,模型能力增加
-
都不正确
答案:(A)
如果增加多层感知机(Multilayer Perceptron)的隐藏层层数,分类误差便会减小。这种陈述正确还是错误?
-
正确
-
错误
答案:(B)
并不总是正确。过拟合可能会导致错误增加。
构建一个神经网络,将前一层的输出和它自身作为输入。
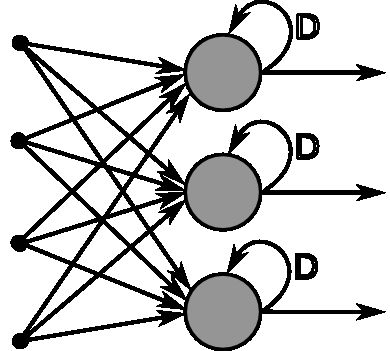
下列哪一种架构有反馈连接?
-
循环神经网络
-
卷积神经网络
-
限制玻尔兹曼机
-
都不是
答案:(A)
在感知机中(Perceptron)的任务顺序是什么?
随机初始化感知机的权重
去到数据集的下一批(batch)
如果预测值和输出不一致,则调整权重
对一个输入样本,计算输出值
A. 1, 2, 3, 4
B. 4, 3, 2, 1
C. 3, 1, 2, 4
D. 1, 4, 3, 2
答案:(D)
假设你需要调整参数来最小化代价函数(cost function),可以使用下列哪项技术?
A. 穷举搜索
B. 随机搜索
C. Bayesian优化
D. 以上任意一种
答案:(D)
在下面哪种情况下,一阶梯度下降不一定正确工作(可能会卡住)?
D. 以上都不正确
答案:(B)
这是鞍点(Saddle Point)的梯度下降的经典例子。另,本题来源于:https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/。
下图显示了训练过的3层卷积神经网络准确度,与参数数量(特征核的数量)的关系。。
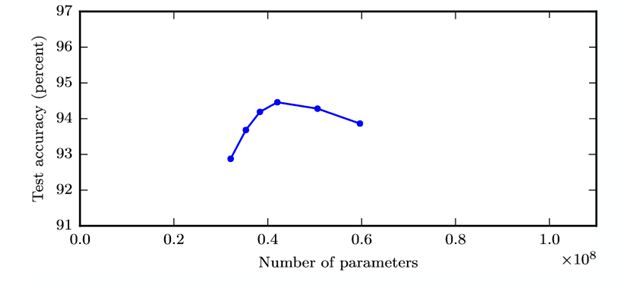
从图中趋势可见,如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么?
-
即使增加卷积核的数量,只有少部分的核会被用作预测
-
当卷积核数量增加时,神经网络的预测能力(Power)会降低
-
当卷积核数量增加时,它们之间的相关性增加(correlate),导致过拟合
-
以上都不正确
答案:(C)
如C选项指出的那样,可能的原因是核之间的相关性。
假设我们有一个如下图所示的隐藏层。隐藏层在这个网络中起到了一定的降纬作用。假如现在我们用另一种维度下降的方法,比如说主成分分析法(PCA)来替代这个隐藏层。
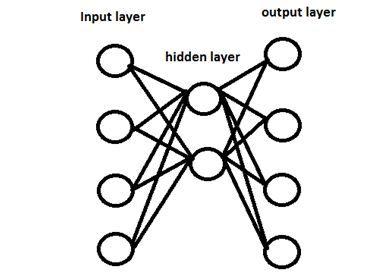
那么,这两者的输出效果是一样的吗?
A.是
B.否
答案:(B)
因为PCA用于相关特征而隐层用于有预测能力的特征
神经网络能组成函数(y=1/x)吗?
A.是
B.否
答案:(A)
选项A是正确的,因为激活函数可以是互反函数
下列哪个神经网络结构会发生权重共享?
A.卷积神经网络
B.循环神经网络
C.全连接神经网络
D.选项A和B
答案:(D)
批规范化(Batch Normalization)的好处都有啥?
A.在将所有的输入传递到下一层之前对其进行归一化(更改)
B.它将权重的归一化平均值和标准差
C.它是一种非常有效的反向传播(BP)方法
D.这些均不是
答案:(A)
在一个神经网络中,下面哪种方法可以用来处理过拟合?(D)
A Dropout
B 分批归一化(Batch Normalization)
C 正则化(regularization)
D 都可以
如果我们用了一个过大的学习速率会发生什么?
A 神经网络会收敛
B 不好说
C 都不对
D 神经网络不会收敛下图所示的网络用于训练识别字符H和T,如下所示:
网络的输出是什么?
D.可能是A或B,取决于神经网络的权重设置
答案:(D)
不知道神经网络的权重和偏差是什么,则无法判定它将会给出什么样的输出。假设我们已经在ImageNet数据集(物体识别)上训练好了一个卷积神经网络。然后给这张卷积神经网络输入一张全白的图片。对于这个输入的输出结果为任何种类的物体的可能性都是一样的,对吗?
A 对的
B 不知道
C 看情况
D 不对
答案:D,各个神经元的反应是不一样的
当在卷积神经网络中加入池化层(pooling layer)时,变换的不变性会被保留,是吗?
A 不知道
B 看情况
C 是
D 否
答案:(C)
使用池化时会导致出现不变性。
当数据过大以至于无法在RAM中同时处理时,哪种梯度下降方法更加有效?(A)
A 随机梯度下降法(Stochastic Gradient Descent)
B 不知道
C 整批梯度下降法(Full Batch Gradient Descent)
D 都不是
下图是一个利用sigmoid函数作为激活函数的含四个隐藏层的神经网络训练的梯度下降图。这个神经网络遇到了梯度消失的问题。由于反向传播算法进入起始层,学习能力降低,这就是梯度消失。下面哪个叙述是正确的?(A)
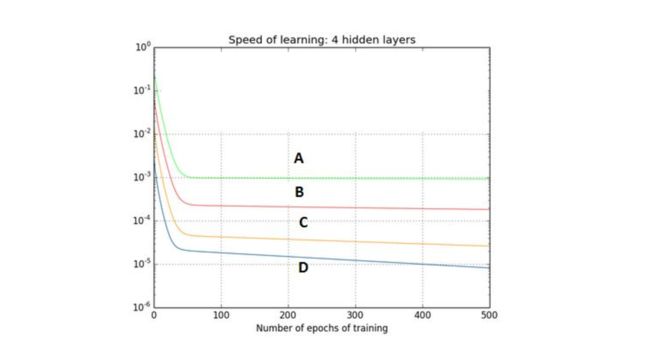
第一隐藏层对应D,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应A
第一隐藏层对应A,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应D
第一隐藏层对应A,第二隐藏层对应B,第三隐藏层对应C,第四隐藏层对应D
第一隐藏层对应B,第二隐藏层对应D,第三隐藏层对应C,第四隐藏层对应A对于一个分类任务,如果开始时神经网络的权重不是随机赋值的,二是都设成0,下面哪个叙述是正确的?(C)
A 其他选项都不对
B 没啥问题,神经网络会正常开始训练
C 神经网络可以训练,但是所有的神经元最后都会变成识别同样的东西
D 神经网络不会开始训练,因为没有梯度改变
下图显示,当开始训练时,误差一直很高,这是因为神经网络在往全局最小值前进之前一直被卡在局部最小值里。为了避免这种情况,我们可以采取下面哪种策略?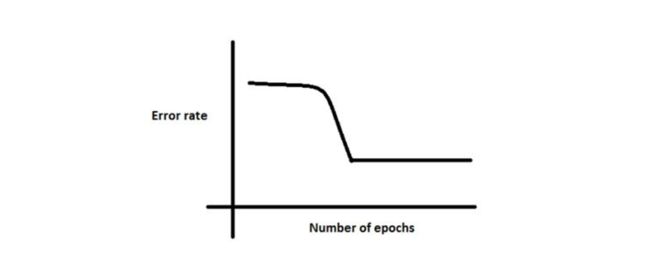
A 改变学习速率,比如一开始的几个训练周期不断更改学习速率
B 一开始将学习速率减小10倍,然后用动量项(momentum)
C 增加参数数目,这样神经网络就不会卡在局部最优处
D 其他都不对
答案:(A)
选项A可以将陷于局部最小值的神经网络提取出来。对于一个图像识别问题(在一张照片里找出一只猫),下面哪种神经网络可以更好地解决这个问题?(D)
A 循环神经网络
B 感知机
C 多层感知机
D 卷积神经网络
卷积神经网络将更好地适用于图像相关问题,因为考虑到图像附近位置变化的固有性质。
假设在训练中我们突然遇到了一个问题,在几次循环之后,误差瞬间降低
你认为数据有问题,于是你画出了数据并且发现也许是数据的偏度过大造成了这个问题。
你打算怎么做来处理这个问题?
A 对数据作归一化
B 对数据取对数变化
C 都不对
D 对数据作主成分分析(PCA)和归一化
答案:(D)
首先您将相关的数据去掉,然后将其置零。下面那个决策边界是神经网络生成的?(E)
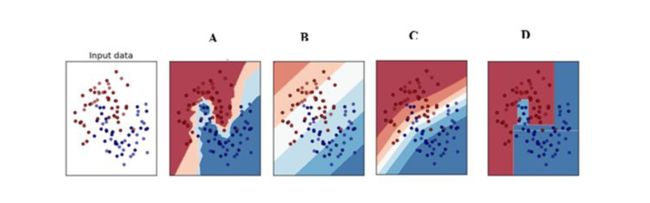
A A
B D
C C
D B
E 以上都有在下图中,我们可以观察到误差出现了许多小的”涨落”。这种情况我们应该担心吗?

A 需要,这也许意味着神经网络的学习速率存在问题
B 不需要,只要在训练集和交叉验证集上有累积的下降就可以了
C 不知道
D 不好说
答案:(B)
选项B是正确的,为了减少这些“起伏”,可以尝试增加批尺寸(batch size)。在选择神经网络的深度时,下面那些参数需要考虑?
1 神经网络的类型(如MLP,CNN)
2 输入数据
3 计算能力(硬件和软件能力决定)
4 学习速率
5 映射的输出函数
A 1,2,4,5
B 2,3,4,5
C 都需要考虑
D 1,3,4,5
答案:(C)
所有上述因素对于选择神经网络模型的深度都是重要的。
考虑某个具体问题时,你可能只有少量数据来解决这个问题。不过幸运的是你有一个类似问题已经预先训练好的神经网络。可以用下面哪种方法来利用这个预先训练好的网络?(C)
A 把除了最后一层外所有的层都冻住,重新训练最后一层
B 对新数据重新训练整个模型
C 只对最后几层进行调参(fine tune)
D 对每一层模型进行评估,选择其中的少数来用
增加卷积核的大小对于改进卷积神经网络的效果是必要的吗?(C)
A 没听说过
B 是
C 否
D 不知道
答案:C,增加核函数的大小不一定会提高性能。这个问题在很大程度上取决于数据集。请简述神经网络的发展史@SIY.Z。本题解析来源:https://zhuanlan.zhihu.com/p/29435406
sigmoid会饱和,造成梯度消失。于是有了ReLU。
ReLU负半轴是死区,造成梯度变0。于是有了LeakyReLU,PReLU。
强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
太深了,梯度传不下去,于是有了highway。
干脆连highway的参数都不要,直接变残差,于是有了ResNet。
强行稳定参数的均值和方差,于是有了BatchNorm。
在梯度流中增加噪声,于是有了 Dropout。
RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。
LSTM简化一下,有了GRU。
GAN的JS散度有问题,会导致梯度消失或无效,于是有了WGAN。
WGAN对梯度的clip有问题,于是有了WGAN-GP。
说说spark的性能调优
https://tech.meituan.com/spark-tuning-basic.html
https://tech.meituan.com/spark-tuning-pro.html常见的分类算法有哪些?
SVM、神经网络、随机森林、逻辑回归、KNN、贝叶斯
常见的监督学习算法有哪些?
感知机、svm、人工神经网络、决策树、逻辑回归
在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题()
A. 增加训练集量
B. 减少神经网络隐藏层节点数
C. 删除稀疏的特征
D. SVM算法中使用高斯核/RBF核代替线性核
正确答案:D
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
一般情况下,越复杂的系统,过拟合的可能性就越高,一般模型相对简单的话泛化能力会更好一点。
B.一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向, svm高斯核函数比线性核函数模型更复杂,容易过拟合
D.径向基(RBF)核函数/高斯核函数的说明,这个核函数可以将原始空间映射到无穷维空间。对于参数 ,如果选的很大,高次特征上的权重实际上衰减得非常快,实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调整参数 ,高斯核实际上具有相当高的灵活性,也是 使用最广泛的核函数 之一。下列时间序列模型中,哪一个模型可以较好地拟合波动性的分析和预测
A.AR模型
B.MA模型
C.ARMA模型
D.GARCH模型
正确答案:D
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点),所以其本质类似于插值。
MA模型(moving average model)滑动平均模型,其中使用趋势移动平均法建立直线趋势的预测模型。
ARMA模型(auto regressive moving average model)自回归滑动平均模型,模型参量法高分辨率谱分析方法之一。这种方法是研究平稳随机过程有理谱的典型方法。它比AR模型法与MA模型法有较精确的谱估计及较优良的谱分辨率性能,但其参数估算比较繁琐。
GARCH模型称为广义ARCH模型,是ARCH模型的拓展,由Bollerslev(1986)发展起来的。它是ARCH模型的推广。GARCH(p,0)模型,相当于ARCH(p)模型。GARCH模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
以下()属于线性分类器最佳准则?
A.感知准则函数
B.贝叶斯分类
C.支持向量机
D.Fisher准则
正确答案:ACD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
线性分类器有三大类:感知器准则函数、SVM、Fisher准则,而贝叶斯分类器不是线性分类器。
感知准则函数 :准则函数以使错分类样本到分界面距离之和最小为原则。其优点是通过错分类样本提供的信息对分类器函数进行修正,这种准则是人工神经元网络多层感知器的基础。
支持向量机 :基本思想是在两类线性可分条件下,所设计的分类器界面使两类之间的间隔为最大,它的基本出发点是使期望泛化风险尽可能小。(使用核函数可解决非线性问题)
Fisher 准则 :更广泛的称呼是线性判别分析(LDA),将所有样本投影到一条远点出发的直线,使得同类样本距离尽可能小,不同类样本距离尽可能大,具体为最大化“广义瑞利商”。
根据两类样本一般类内密集,类间分离的特点,寻找线性分类器最佳的法线向量方向,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。这种度量通过类内离散矩阵 Sw 和类间离散矩阵 Sb 实现。
基于二次准则函数的H-K算法较之于感知器算法的优点是()?
A.计算量小
B.可以判别问题是否线性可分
C.其解完全适用于非线性可分的情况
D.其解的适应性更好
正确答案:BD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
HK算法思想很朴实,就是在最小均方误差准则下求得权矢量.
他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况,对于线性可分的情况,给出最优权矢量,对于非线性可分得情况,能够判别出来,以退出迭代过程.
以下说法中正确的是()
A.SVM对噪声(如来自其他分布的噪声样本)鲁棒
B.在AdaBoost算法中,所有被分错的样本的权重更新比例相同
C.Boosting和Bagging都是组合多个分类器投票的方法,二者都是根据单个分类器的正确率决定其权重
D.给定n个数据点,如果其中一半用于训练,一般用于测试,则训练误差和测试误差之间的差别会随着n的增加而减少
正确答案:BD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
A、SVM对噪声(如来自其他分布的噪声样本)鲁棒
SVM本身对噪声具有一定的鲁棒性,但实验证明,是当噪声率低于一定水平的噪声对SVM没有太大影响,但随着噪声率的不断增加,分类器的识别率会降低。
B、在AdaBoost算法中所有被分错的样本的权重更新比例相同
AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被凸显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。以此类推,将所有的弱分类器重叠加起来,得到强分类器。
C、Boost和Bagging都是组合多个分类器投票的方法,二者均是根据单个分类器的正确率决定其权重。
Bagging与Boosting的区别:
取样方式不同。
Bagging采用均匀取样,而Boosting根据错误率取样。
Bagging的各个预测函数没有权重,而Boosting是有权重的。
Bagging的各个预测函数可以并行生成,而Boosing的各个预测函数只能顺序生成。
输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为:
A. 95
B. 96
C. 97
D. 98
E. 99
F. 100
正确答案:C
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
首先我们应该知道卷积或者池化后大小的计算公式:
outputw=⌊imagew+2padding−kernelsizestride⌋+1
outputh=⌊imageh+2padding−kernelsizestride⌋+1其中,padding指的是向外扩展的边缘大小,而stride则是步长,即每次移动的长度。
这样一来就容易多了,首先长宽一般大,所以我们只需要计算一个维度即可,这样,经过第一次卷积后的大小为:
200+2−52+1=99
经过第一次池化后的大小为:
99+0−31+1=97
经过第二次卷积后的大小为:
97+2−31+1=97最终的结果为97。
- 在spss的基础分析模块中,作用是“以行列表的形式揭示数据之间的关系”的是( )
A. 数据描述
B. 相关
C. 交叉表
D. 多重相应
正确答案:C
- 一监狱人脸识别准入系统用来识别待进入人员的身份,此系统一共包括识别4种不同的人员:狱警,小偷,送餐员,其他。下面哪种学习方法最适合此种应用需求:()。
A. 二分类问题
B. 多分类问题
C. 层次聚类问题
D. k-中心点聚类问题
E. 回归问题
F. 结构分析问题
正确答案:B
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
二分类:每个分类器只能把样本分为两类。监狱里的样本分别为狱警、小偷、送餐员、其他。二分类肯 定行不通。瓦普尼克95年提出来基础的支持向量机就是个二分类的分类器,这个分类器学习过 程就是解一个基于正负二分类推导而来的一个最优规划问题(对偶问题),要解决多分类问题 就要用决策树把二分类的分类器级联,VC维的概念就是说的这事的复杂度。
层次聚类: 创建一个层次等级以分解给定的数据集。监狱里的对象分别是狱警、小偷、送餐员、或者其 他,他们等级应该是平等的,所以不行。此方法分为自上而下(分解)和自下而上(合并)两种操作方式。
K-中心点聚类:挑选实际对象来代表簇,每个簇使用一个代表对象。它是围绕中心点划分的一种规则,所以这里并不合适。
回归分析:处理变量之间具有相关性的一种统计方法,这里的狱警、小偷、送餐员、其他之间并没有什 么直接关系。
结构分析: 结构分析法是在统计分组的基础上,计算各组成部分所占比重,进而分析某一总体现象的内部结构特征、总体的性质、总体内部结构依时间推移而表现出的变化规律性的统计方法。结构分析法的基本表现形式,就是计算结构指标。这里也行不通。
多分类问题: 针对不同的属性训练几个不同的弱分类器,然后将它们集成为一个强分类器。这里狱警、 小偷、送餐员 以及他某某,分别根据他们的特点设定依据,然后进行区分识别。
- 关于 logit 回归和 SVM 不正确的是()
A.Logit回归目标函数是最小化后验概率
B. Logit回归可以用于预测事件发生概率的大小
C. SVM目标是结构风险最小化
D.SVM可以有效避免模型过拟合
正确答案: A
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
A. Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。而最小化后验概率是朴素贝叶斯算法要做的。A错误
B. Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确
C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化。
D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。
- 有两个样本点,第一个点为正样本,它的特征向量是(0,-1);第二个点为负样本,它的特征向量是(2,3),从这两个样本点组成的训练集构建一个线性SVM分类器的分类面方程是()
A. 2x+y=4
B. x+2y=5
C. x+2y=3
D. 2x-y=0
正确答案:C
解析:这道题简化了,对于两个点来说,最大间隔就是垂直平分线,因此求出垂直平分线即可。
- 下面有关分类算法的准确率,召回率,F1 值的描述,错误的是?
A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B.召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
C.正确率、召回率和 F 值取值都在0和1之间,数值越接近0,查准率或查全率就越高
D.为了解决准确率和召回率冲突问题,引入了F1分数
正确答案:C
解析:
对于二类分类问题常用的评价指标是精准度(precision)与召回率(recall)。通常以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记作:
TP——将正类预测为正类数
FN——将正类预测为负类数
FP——将负类预测为正类数
TN——将负类预测为负类数
由此:
精准率定义为:P = TP / (TP + FP)
召回率定义为:R = TP / (TP + FN)
F1值定义为: F1 = 2 P R / (P + R)
精准率和召回率和F1取值都在0和1之间,精准率和召回率高,F1值也会高,不存在数值越接近0越高的说法,应该是数值越接近1越高。
- 以下几种模型方法属于判别式模型(Discriminative Model)的有()
1)混合高斯模型
2)条件随机场模型
3)区分度训练
4)隐马尔科夫模型
A.2,3
B.3,4
C.1,4
D.1,2
正确答案:A
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
常见的判别式模型有:
Logistic regression(logistical 回归)
Linear discriminant analysis(线性判别分析)
Supportvector machines(支持向量机)
Boosting(集成学习)
Conditional random fields(条件随机场)
Linear regression(线性回归)
Neural networks(神经网络)
常见的生成式模型有:
Gaussian mixture model and othertypes of mixture model(高斯混合及其他类型混合模型)
Hidden Markov model(隐马尔可夫)
NaiveBayes(朴素贝叶斯)
AODE(平均单依赖估计)
Latent Dirichlet allocation(LDA主题模型)
Restricted Boltzmann Machine(限制波兹曼机)
生成式模型是根据概率乘出结果,而判别式模型是给出输入,计算出结果。
- SPSS中,数据整理的功能主要集中在( )等菜单中
A.数据
B.直销
C.分析
D.转换
正确答案:AD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
解析:对数据的整理主要在数据和转换功能菜单中。
深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m<n<p<q,以下计算顺序效率最高的是()
A.(AB)CB.AC(B)
C.A(BC)
D.所以效率都相同
正确答案:A
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
首先,根据简单的矩阵知识,因为 A*B , A 的列数必须和 B 的行数相等。因此,可以排除 B 选项,
然后,再看 A 、 C 选项。在 A 选项中,m∗n 的矩阵 A 和n∗p的矩阵 B 的乘积,得到 m∗p的矩阵 A*B ,而 A∗B的每个元素需要 n 次乘法和 n-1 次加法,忽略加法,共需要 m∗n∗p次乘法运算。同样情况分析 A*B 之后再乘以 C 时的情况,共需要 m∗p∗q次乘法运算。因此, A 选项 (AB)C 需要的乘法次数是 m∗n∗p+m∗p∗q 。同理分析, C 选项 A (BC) 需要的乘法次数是 n∗p∗q+m∗n∗q。
由于m∗n∗p<m∗n∗q,m∗p∗q<n∗p∗q,显然 A 运算次数更少,故选 A 。Nave Bayes是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:()
A.各类别的先验概率P(C)是相等的B.以0为均值,sqr(2)/2为标准差的正态分布
C.特征变量X的各个维度是类别条件独立随机变量
D.P(X|C)是高斯分布
正确答案:C
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
朴素贝叶斯的条件就是每个变量相互独立。
关于支持向量机SVM,下列说法错误的是()
A.L2正则项,作用是最大化分类间隔,使得分类器拥有更强的泛化能力B.Hinge 损失函数,作用是最小化经验分类错误
C.分类间隔为1/||w||,||w||代表向量的模
D.当参数C越小时,分类间隔越大,分类错误越多,趋于欠学习
正确答案:C
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
A正确。考虑加入正则化项的原因:想象一个完美的数据集,y>1是正类,y<-1是负类,决策面y=0,加入一个y=-30的正类噪声样本,那么决策面将会变“歪”很多,分类间隔变小,泛化能力减小。加入正则项之后,对噪声样本的容错能力增强,前面提到的例子里面,决策面就会没那么“歪”了,使得分类间隔变大,提高了泛化能力。
B正确。
C错误。间隔应该是2/||w||才对,后半句应该没错,向量的模通常指的就是其二范数。
D正确。考虑软间隔的时候,C对优化问题的影响就在于把a的范围从[0,+inf]限制到了[0,C]。C越小,那么a就会越小,目标函数拉格朗日函数导数为0可以求出w=求和ai∗yi∗xi,a变小使得w变小,因此间隔2/||w||变大
- 在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
A.EM算法
B.维特比算法
C.前向后向算法
D.极大似然估计
正确答案:D
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计
前向后向算法:用来算概率
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数
注意的是在给定观测序列和对应的状态序列估计模型参数,可以利用极大似然发估计。如果给定观测序列,没有对应的状态序列,才用EM,将状态序列看不不可测的隐数据。- 假定某同学使用Naive Bayesian(NB)分类模型时,不小心将训练数据的两个维度搞重复了,那么关于NB的说法中正确的是:
A.这个被重复的特征在模型中的决定作用会被加强
B.模型效果相比无重复特征的情况下精确度会降低
C.如果所有特征都被重复一遍,得到的模型预测结果相对于不重复的情况下的模型预测结果一样。
D.当两列特征高度相关时,无法用两列特征相同时所得到的结论来分析问题
E.NB可以用来做最小二乘回归
F.以上说法都不正确
正确答案:BD
L1与L2范数
在Logistic Regression 中,如果同时加入L1和L2范数,会产生什么效果()
A.可以做特征选择,并在一定程度上防止过拟合
B.能解决维度灾难问题
C.能加快计算速度
D.可以获得更准确的结果
正确答案:A
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
L1范数具有系数解的特性,但是要注意的是,L1没有选到的特征不代表不重要,原因是两个高相关性的特征可能只保留一个。如果需要确定哪个特征重要,再通过交叉验证。在代价函数后面加上正则项,L1即是Losso回归,L2是岭回归。L1范数是指向量中各个元素绝对值之和,用于特征选择。L2范数 是指向量各元素的平方和然后求平方根,用于 防止过拟合,提升模型的泛化能力。因此选择A。
对于机器学习中的范数规则化,也就是L0,L1,L2范数的详细解答,请参阅《范数规则化》。
- 正则化
机器学习中L1正则化和L2正则化的区别是?
A.使用L1可以得到稀疏的权值
B.使用L1可以得到平滑的权值
C.使用L2可以得到稀疏的权值
D.使用L2可以得到平滑的权值
正确答案:AD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
L1正则化偏向于稀疏,它会自动进行特征选择,去掉一些没用的特征,也就是将这些特征对应的权重置为0.
L2主要功能是为了防止过拟合,当要求参数越小时,说明模型越简单,而模型越简单则,越趋向于平滑,从而防止过拟合。
L1正则化/Lasso
L1正则化将系数w的l1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变成0。因此L1正则化往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化成为一种很好的特征选择方法。
L2正则化/Ridge regression
L2正则化将系数向量的L2范数添加到了损失函数中。由于L2惩罚项中系数是二次方的,这使得L2和L1有着诸多差异,最明显的一点就是,L2正则化会让系数的取值变得平均。对于关联特征,这意味着他们能够获得更相近的对应系数。还是以Y=X1+X2为例,假设X1和X2具有很强的关联,如果用L1正则化,不论学到的模型是Y=X1+X2还是Y=2X1,惩罚都是一样的,都是2alpha。但是对于L2来说,第一个模型的惩罚项是2alpha,但第二个模型的是4*alpha。可以看出,系数之和为常数时,各系数相等时惩罚是最小的,所以才有了L2会让各个系数趋于相同的特点。
可以看出,L2正则化对于特征选择来说一种稳定的模型,不像L1正则化那样,系数会因为细微的数据变化而波动。所以L2正则化和L1正则化提供的价值是不同的,L2正则化对于特征理解来说更加有用:表示能力强的特征对应的系数是非零。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
具体的,可以参阅《机器学习之特征选择》与《机器学习范数正则化》。- 势函数法
位势函数法的积累势函数K(x)的作用相当于Bayes判决中的()
A.后验概率
B.先验概率
C.类概率密度
D.类概率密度与先验概率的乘积
正确答案:AD
@刘炫320,本题题目及解析来源:http://blog.csdn.net/column/details/16442.html
事实上,AD说的是一回事。
具体的,势函数详解请看——《势函数法》。- 隐马尔可夫
隐马尔可夫模型三个基本问题以及相应的算法说法正确的是( )
A.评估—前向后向算法
B.解码—维特比算法
C.学习—Baum-Welch算法
D.学习—前向后向算法
正确答案:ABC
解析:评估问题,可以使用前向算法、后向算法、前向后向算法。