Python的一些库和函数
Python的函数在定义的时候是不写参数类型的
def ChangeInt(a): a += 10 return a b = 2 b = ChangeInt(b) print(b)是def ChangeInt(a): 而不是def ChangeInt(a:int)
Python类在定义的时候括号内是父类名,如果没有继承父类就不用写
括号内不是写什么参数
class Animals(): def breathe(self): print('breathing') def move(self): print('moving') def eat(self): print('eating food') class Mammals(Animals): def breastfeed(self): print('feeding young')
reshape() / np.reshape()
X = X. reshape(a,b) 或 reshape((a,b)) 将 X矩阵reshape成a行b列,X原来必须也是a*b的
reshape()与resize()的作用基本相同,只有一点,如果给定的行列维度相等大于原数组,reshape会报错,而resize会copy原数组中的值对新数组进行填充
X = reshape(X.size, 1)
这句话的作用是,给X增添一维维度,如原本X是一维的,即一行,一个行向量,增添一维之后就会变成一列,一个列向量
就像newaxis的作用一样
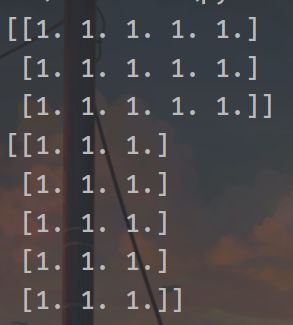
import numpy as np a = np.ones((3,5)) print(a) a = a.reshape(5,3) print(a)
python在程序运行中间打断点交互
import code code.interact(local=locals())
python数据类型间的转换
字符串str与字节byte
b = b"example" # bytes object s = "example" # str object sb = bytes(s, encoding = "utf8") # str to bytes 或者:sb = str.encode(s) # str to bytes bs = str(b, encoding = "utf8") # bytes to str 或者:bs = bytes.decode(b) # bytes to str
Python collections.Counter()用法
什么是collections
collections在python官方文档中的解释是High-performance container datatypes,直接的中文翻译解释高性能容量数据类型。
它总共包含五种数据类型:
其中Counter中文意思是计数器,也就是我们常用于统计的一种数据类型,在使用Counter之后可以让我们的代码更加简单易读。
Counter
先看一个简单的例子:
#统计词频 colors = ['red', 'blue', 'red', 'green', 'blue', 'blue'] result = {} for color in colors: if result.get(color)==None: result[color]=1 else: result[color]+=1 print (result) #{'red': 2, 'blue': 3, 'green': 1}下面我们看用Counter怎么实现:
from collections import Counter colors = ['red', 'blue', 'red', 'green', 'blue', 'blue'] c = Counter(colors) print (dict(c))显然代码更加简单了,也更容易读和维护了。
Counter操作
可以创建一个空的Counter:
cnt = Counter()之后在空的Counter上进行一些操作。
也可以创建的时候传进去一个迭代器(数组,字符串,字典等):c = Counter('gallahad') # 传进字符串 c = Counter({'red': 4, 'blue': 2}) # 传进字典 c = Counter(cats=4, dogs=8) # 传进元组

Python的enumerate()函数
对于一个可迭代/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
enumerate多用于在for循环中得到计数
如果对一个列表,既要遍历索引又要遍历元素时,首先可以这样写:
list1 = ["这", "是", "一个", "测试"] for i in range (len(list1)): print i ,list1[i]上述方法有些累赘,利用enumerate()会更加直接和优美:
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1): print(index, item) >>> 0 这 1 是 2 一个 3 测试enumerate还可以设置下标起始位置
这样下标就是从1开始了,就不是从0了
这就是从2开始


python的排序函数sorted()
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
还可以
myList = ['青海省','内蒙古自治区','西藏自治区','新疆维吾尔自治区','广西壮族自治区'] myList1 = sorted(myList,key = lambda i:len(i),reverse=True) print(myList1)按照首元素排序,首元素相同按照第二个,第二个相同按照第三个
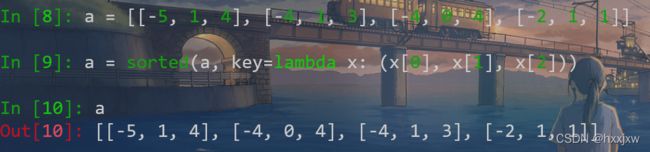
a = [[-5, 1, 4], [-4, 1, 3], [-4, 0, 4], [-2, 1, 1]] a = sorted(a, key=lambda x: (x[0], x[1], x[2]))
注意这里的lamdba只能有一个参数,常规的lamdba可以写成lamdba x,y:x+y这种,这里不行,只能写lamdba x: ...
一句话说:python3中一些接受key的函数中(例如sorted,min,max,heapq.nlargest,itertools.groupby),key仅仅支持一个参数,无法实现两个参数之间的对比。采用cmp_to_key 函数,可以接受两个参数,对两个参数做处理,比如做和做差,转换成一个参数,就可以应用于key关键字了。
from functools import cmp_to_key def cmp(x,y): return 1 if x + y < y + x else -1 a = ['4','42','45'] a = sorted(a, key=cmp_to_key(cmp)) print(a)sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
排序的同时返回下标
np中可以用argsort,pytorch可以用torch,sort, 都可以顺带返回下标
但python没有现成的函数,可以用enumerate这样
nums = [4, 1, 5, 2, 9, 6, 8, 7] sorted_nums = sorted(enumerate(nums), key=lambda x: x[1]) nums = [i[1] for i in sorted_nums] idx = [i[0] for i in sorted_nums] print(nums) print(idx)




lamdba表达式
即匿名函数
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用。
lambda所表示的匿名函数的内容应该是很简单的,如果复杂的话,干脆就重新定义一个函数了,使用lambda就有点过于执拗了。
lambda就是用来定义一个匿名函数的,如果还要给他绑定一个名字的话,就会显得有点画蛇添足,通常是直接使用lambda函数。如下所示:
add = lambda x, y : x+y add(1,2) # 结果为3
np.arange()函数:用于生成一维数组
np.arange(头,尾,步长)
注意头尾是左闭右开的

np.zeros() 生成全0矩阵
zeros的参数n,m表示的是维度
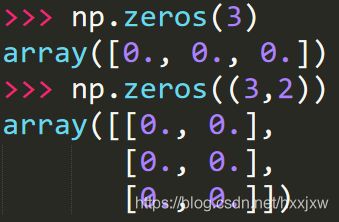
np.zeros(n) 或 np.zeros([n])
np.zeros((n,n)) 注意2层括号不能省
默认填充类型为float64
np.zeros((3,2), dtype=int)

astype numpy数据类型转换
img = img.astype(np.float32)
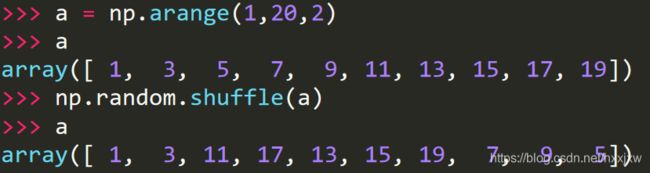
python的shuffle()函数
shuffle() 方法将序列的所有元素随机排序
python的pillow库
pillow是Python平台上图像处理标准库,功能强大,使用简单。之前是PIL(Python Imaging Library),但默认仅支持到Python2.7,如果要支持Python3.x版本,必须使用兼容PIL的新版本–Pillow,Pillow中加入了相比于PIL更多的新特性。
pillow和opencv都是图像处理库,但是不是一个量级的。可以说pillow是小渔船,而opencv是航母。但有部分功能是重合的
python的 ImageFont 模块的 truetype() 函数
from PIL import ImageFont
ImageFont.truetype(filename , wordsize)
加载一个TrueType或者OpenType字体文件,并且创建一个字体对象。
通常为ttf文件,还有少数ttc文件
ttc文件是几种ttf文件的集合,比如simsun.ttc是“宋体、新宋体、宋体-PUA”三种字体的集合,可以通过在truetype中增加index参量实现对集合内字体的调用
Python的random()函数
random.random() 方法返回随机生成的一个实数,它在[0,1)范围内。
import random a = random.random()如果想要生成[0,n)范围内的随机实数
import random a = random.random()*nnp.random.random()
生成[0,1)范围的浮点数,可以指定size
x = np.random.random((2,3))
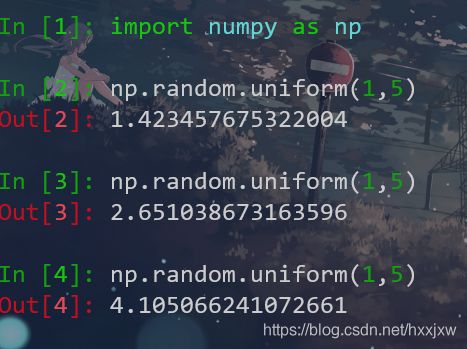
np.random.uniform()
random.uniform(x, y) 方法将随机生成一个实数,它在 [x,y] 范围内。
产生整数
random.randint()
import random #随机产生0-24之间的整数,包括0和24 i = random.randint(0,24)np.random.randint()
产生某个范围内的整数,可以指定size
x = np.random.randint(0,24,(2,3))
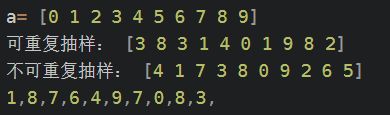
np.random.choice()
从数组中随机抽取元素
np.random.choice(a, size=10) 从a中抽10个元素
import numpy as np a = np.arange(10) print('a=', a) print('可重复抽样:', np.random.choice(a, size=10)) #即有放回 print('不可重复抽样:', np.random.choice(a, size=10, replace=False)) #即无放回 # 注意,下面的方式,产生的样本还可以是重复的,因为replace=False只能配合size参数在一次抽样中发挥作用,下面这种属于多次抽样 for i in range(10): print(np.random.choice(a, replace=False), end=',')
replace默认是True
a也可以是一个数值, 如np.random.choice(10,5) 就表示从(0,10)中取5个值
random.choice() / random.choices()
随机选取序列中的一个或多个元素
random.choices, 用k指定选择个数,默认是1
可能会有重复
random.sample() 随即从序列选取多个元素(不重复)
随机种子
random.seed()
random.seed(2)





设置随机数种子
包括numpy和torch的,使实验结果可复现
def setup_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) np.random.seed(seed) random.seed(seed) torch.backends.cudnn.deterministic = True # 设置随机数种子 setup_seed(20)
np.random.binomial() 二项式分布函数
numpy.random.binomial(n,p,size=None)
参数n:一次试验的样本数n
参数p:事件发生的概率p
test = np.random.binomial(1, 0.5, 10) print(test)
Python的json库
import json
json.dumps()
将 Python 对象编码成 JSON 字符串
json.loads()将已编码的 JSON 字符串解码为 Python 对象
Python的time库
import time
time.localtime() 得到当下的时间
time.asctime(t) 接受时间元组并返回一个可读的形式为
import time t = time.localtime() print(t) print(time.asctime(t))
time.strftime()
Python time strftime() 函数接收以时间元组(某些表示时间的符号),并返回以可读字符串表示的当地时间,格式由参数format决定。
python中时间日期格式化符号:
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %X 本地相应的时间表示
- ...
例2



timeit 计时器
通常在一段程序的前后都用上time.time(),然后进行相减就可以得到一段程序的运行时间,不过python提供了更强大的计时库:timeit
默认次数是10000次
#导入timeit.timeit from timeit import timeit #看执行1000000次x=1的时间: timeit('x=1') #看x=1的执行时间,执行1次(number可以省略,默认值为1000000): timeit('x=1', number=1) #看一个列表生成器的执行时间,执行1次: timeit('[i for i in range(10000)]', number=1) #看一个列表生成器的执行时间,执行10000次: timeit('[i for i in range(100) if i%2==0]', number=10000)测试一个函数的执行时间
此程序测试函数运行1000次的执行时间
from timeit import timeit def compute(): s = 0 for i in range(1000): s += i print(s) # timeit(函数名_字符串,运行环境_字符串,number=运行次数) t = timeit('compute()', 'from __main__ import compute', number=1000) print(t)
repeat
由于电脑永远都有其他程序也在占用着资源,你的程序不可能最高效的执行。所以一般都会进行多次试验,取最少的执行时间为真正的执行时间。
from timeit import repeat def func(): s = 0 for i in range(1000): s += i #repeat和timeit用法相似,多了一个repeat参数,表示重复测试的次数(可以不写,默认值为3.),返回值为一个时间的列表。 t = repeat('func()', 'from __main__ import func', number=100, repeat=5) print(t) print(min(t))
Python格式化字符串f-string
f-string,亦称为格式化字符串常量(formatted string literals),是Python3.6新引入的一种字符串格式化方法。注意只能在3.6及以上用
f-string在形式上是以
f或F修饰符引领的字符串(f'xxx'或F'xxx'),以大括号{}标明被替换的字段;f-string在本质上并不是字符串常量,而是一个在运行时运算求值的表达式
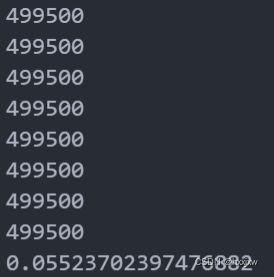
#简单替换 >>> name = 'Eric' >>> f'Hello, my name is {name}' 'Hello, my name is Eric' >>> number = 7 >>> f'My lucky number is {number}' 'My lucky number is 7' #表达式求值与函数调用 >>> f'A total number of {24 * 8 + 4}' 'A total number of 196' >>> name = 'ERIC' >>> f'My name is {name.lower()}' 'My name is eric'f-string保留小数
可以有3种格式
指定宽度
指定宽度,和保留小数点后几位
也可以不指定宽度,直接指定小数点后几位



Python格式化函数 | format()
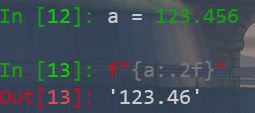
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
这个索引的功能很强,可以重复用某个值

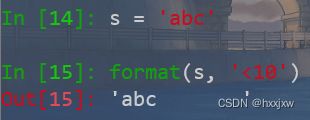
字符串左、右、居中对齐
用 format()函数
左对齐,长度为10
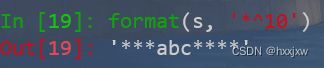
format(s, '<10')
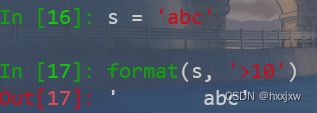
右对齐,长度为10
format(s, '>10')
居中对齐,长度为10
format(s, '^10')
居中对齐,长度为10,空余部分用*填充
format(s, '*^10')
不一定非要字符串,也可以是数字


hasattr() 函数
用于判断对象是否包含对应的属性。
hasattr(object, name)判断object对象中是否有name属性
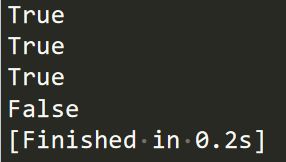
class Coordinate: x = 10 y = -5 z = 0 point1 = Coordinate() print(hasattr(point1, 'x')) print(hasattr(point1, 'y')) print(hasattr(point1, 'z')) print(hasattr(point1, 'no')) # 没有该属性
getattr()
用于返回一个对象属性值。
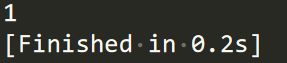
class A(object): bar = 1 a = A() print(getattr(a, 'bar')) # 获取属性 bar 值
setattr()
设置属性值,该属性不一定是存在的。
>>>class A(object): ... bar = 1 ... >>> a = A() >>> getattr(a, 'bar') # 获取属性 bar 值 1 >>> setattr(a, 'bar', 5) # 设置属性 bar 值 >>> a.bar 5如果属性不存在会创建一个新的对象属性,并对属性赋值:
>>>class A(): ... name = "runoob" ... >>> a = A() >>> setattr(a, "age", 28) >>> print(a.age) 28 >>>
glob库
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。跟使用windows下的文件搜索差不多
import glob #获取指定目录下的所有图片 print (glob.glob(r"/home/qiaoyunhao/*/*.png"),"\n")#加上r让字符串不转义 #获取上级目录的所有.py文件 print (glob.glob(r'../*.py')) #相对路径
os.path.join()
路径拼接,把几个路径拼起来,中间加上"/"
import os
Path1 = 'home'
Path2 = 'develop'
Path3 = 'code'Path10 = Path1 + Path2 + Path3
Path20 = os.path.join(Path1,Path2,Path3)
print ('Path10 = ',Path10)
print ('Path20 = ',Path20)输出
Path10 = homedevelopcode
Path20 = home\develop\code
''.join 合并字符串
join就是连接字符生成新的字符串
str = "-"; seq = ("a", "b", "c"); # 字符串序列 print str.join( seq );输出: a-b-c
所以如果是''.join
那就是字符之间的无缝连接
seq = ("a", "b", "c") # 字符串序列 print(''.join(seq))
join 与 +
join 与 + 都是连接字符串,运算结果一样。
但是连接字符串数组的时候,join的运算效率高于 +
当使用“+”连接字符串的时候,每执行一次“+”操作都会申请一块新的内存,然后复制上一个“+”操作的结果和本次操作的有操作符到这块内存空间中,所以用“+”连接字符串的时候会涉及内存申请和复制;join在连接字符串的时候,首先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去。在用"+"连接字符串时,结果会生成新的对象,而用join时只是将原列表中的元素拼接起来,因此在连接字符串数组的时候会考虑优先使用join。
assert
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
loc和iloc 提取行/列数据
loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
1. 利用loc、iloc提取行数据
import numpy as np import pandas as pd #创建一个Dataframe data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD')) In[1]: data Out[1]: A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 d 12 13 14 15 #取索引为'a'的行 In[2]: data.loc['a'] Out[2]: A 0 B 1 C 2 D 3 #取第一行数据,索引为'a'的行就是第一行,所以结果相同 In[3]: data.iloc[0] Out[3]: A 0 B 1 C 2 D 32. 利用loc、iloc提取列数据
In[4]:data.loc[:,['A']] #取'A'列所有行,多取几列格式为 data.loc[:,['A','B']] Out[4]: A a 0 b 4 c 8 d 12 In[5]:data.iloc[:,[0]] #取第0列所有行,多取几列格式为 data.iloc[:,[0,1]] Out[5]: A a 0 b 4 c 8 d 12
np.meshgrid()
numpy.meshgrid()的作用是生成网格点坐标矩阵
#coding:utf-8 import numpy as np # 坐标向量 a = np.array([1,2,3]) # 坐标向量 b = np.array([7,8]) # 从坐标向量中返回坐标矩阵 # 返回list,有两个元素,第一个元素是X轴的取值,第二个元素是Y轴的取值 res = np.meshgrid(a,b) #返回结果: [array([ [1,2,3] [1,2,3] ]), array([ [7,7,7] [8,8,8] ])]
numpy.meshgrid()理解_lllxxq141592654的博客-CSDN博客

np.ravel()
ravel的意思是散开,解开
将矩阵向量化,将多维数组降为一维
np.ravel(x)也可以写作x.ravel()

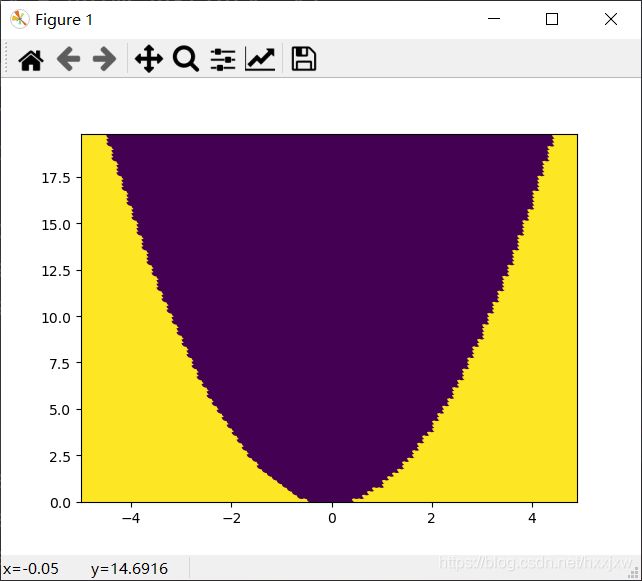
plt.contourf()
plt.contourf用来画出不同分类的边界线
z是用来标记不同种类点的
import numpy as np import matplotlib.pyplot as plt #生成数据点 x = np.arange(-5, 5, 0.1) y = np.arange(0, 20, 0.2) xx, yy = np.meshgrid(x, y) #对不同类进行标记 z = np.square(xx) - yy > 0 print(z) #绘图 plt.contourf(xx, yy, z, cmap="cool") plt.scatter(xx, yy, c=z) plt.show()
还有一个可选的参数alpha,表示混合值,介于0(透明)和1(不透明)之间。
isinstance()
isinstance() 函数来判断一个对象是否是某种类型

copy()
copy()是浅复制,浅拷贝。对应于deepcopy的深拷贝
我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
>>> import copy >>> origin = [1, 2, [3, 4]] #origin 里边有三个元素:1, 2,[3, 4] >>> cop1 = copy.copy(origin) >>> cop2 = copy.deepcopy(origin) >>> cop1 == cop2 True >>> cop1 is cop2 False #cop1 和 cop2 看上去相同,但已不再是同一个object >>> origin[2][0] = "hey!" >>> origin [1, 2, ['hey!', 4]] >>> cop1 [1, 2, ['hey!', 4]] >>> cop2 [1, 2, [3, 4]] #把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2

deepcopy()
在oop编程中遇到的。
对于一个对象来说,例如gameState(), 如果我们要复制它, newgame = gameState
那么这只是一个指针的复制,即修改newgame会等于修改,gameState
而如果用deepcopy的话,就是纯复制了
cop2 = copy.deepcopy(origin)copy仅拷贝对象本身,而不对中的子对象进行拷贝,故对子对象进行修改也会随着修改。
deepcopy是真正意义上的复制,即从新开辟一片空间。我们经常说的复制实际上就是deepcopy.
math.hypot
hypot() 返回欧几里德范数 sqrt(x*x + y*y)
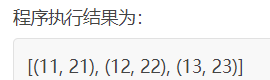
zip函数
zip() 函数是 Python 内置函数之一,它可以将多个序列(列表、元组、字典、集合、字符串以及 range() 区间构成的列表)“压缩”成一个 zip 对象
my_list = [11,12,13] my_tuple = (21,22,23) print([x for x in zip(my_list,my_tuple)])
np.where()
np.where(condition, x, y)
满足条件(condition),输出x,不满足输出y。
import pandas as pd import numpy as np df = pd.read_csv('iris.data',header=None) y = df.iloc[0:100, 4] #取0-100行,第4列 print(y) y = np.where(y == 'Iris-setosa', -1, 1) print(y)

np.dot() 矩阵相乘(点乘)
dot函数为numpy库下的一个函数,主要用于矩阵的乘法运算,其中包括:向量内积、多维矩阵乘法和矩阵与向量的乘法
就是矩阵相乘(点乘)
machine learning中计算y=wx+b的wx相乘就用dot()来算
def net_input(self, X): return np.dot(X, self.w_[1:]) + self.w_[0]
np.random.RandomState()
随机数生成器
注意生成器,生成器生成之后再用生成器去生成随机数
from numpy.random import RandomState rdm = RandomState(1) a = rdm.uniform(1,2,(3,4)) print(a)

np.random.normal(loc=0.0, scale=1.0, size=None)
生成高斯分布的概率密度随机数
loc:float 此概率分布的均值(对应着整个分布的中心centre) scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高) size:int or tuple of ints 输出的shape,默认为None,只输出一个值nd1 = np.random.normal(loc=1,scale=2,size=2) #array([-0.46982446, -1.28956852]) nd1 = np.random.normal(loc=1,scale=2,size=[3,3,4,5]) #nd1的shape就是(3,3,4,5)
np.random.permutation()
随机排列一个序列,或者数组
np.random.permutation(10) 输出: array([1, 7, 4, 3, 0, 9, 2, 5, 8, 6])np.random.permutation([1, 4, 9, 12, 15]) 输出: array([15, 1, 9, 4, 12])
np.random.randn()
a = np.random.randn()
则返回一个随机浮点数
返回一个或一组样本,具有标准正态分布(以0为均值、以1为标准差)
np.bincount()
该函数用于统计一个非负的list或array中元素的出现次数
import numpy as np x = np.array([0, 1, 1, 10]) # bincount()内可以是numpy,也可以是list,注意里面的数必须是非负数,否则报错 # 如果里面有n个数,则输出一个长度为n+1的numpy,第i个索引对应的数即i出现的次数 print(np.bincount(x)) print(np.bincount([0, 1, 1, 3, 2, 1, 5])) # [1 2 0 0 0 0 0 0 0 0 1] # [1 3 1 1 0 1]如下与argmax()结合使用可用于投票
y_pred['label'] = y_pred.apply(lambda x:np.argmax(np.bincount(x)), axis=1)
StandardScaler()
sklearn的类
from sklearn.preprocessing import StandardScaler
作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本
#use StandardScalar class to do standardization(feature scaling) sc = StandardScaler() #get mean and std of dataset sc.fit(X_train) #different from models'fit X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test)
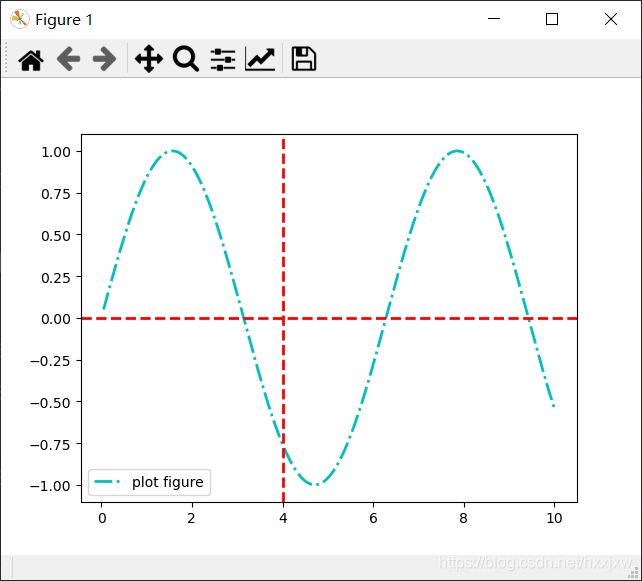
plt.axhline()
绘制平行于x轴的水平参考线
plt.axhline(y=0.0, c="r", ls="--", lw=2)
y:水平参考线的出发点
c:参考线的线条颜色
ls:参考线的线条风格
lw:参考线的线条宽度
import matplotlib.pyplot as plt import numpy as np x = np.linspace(0.05, 10, 1000) y = np.sin(x) plt.plot(x, y, ls="-.", lw=2, c="c", label="plot figure") plt.legend() plt.axhline(y=0.0, c="r", ls="--", lw=2) plt.axvline(x=4.0, c="r", ls="--", lw=2) plt.show()
plt.xlim() / plt.ylim()
设置x轴的数值显示范围
plt.xlim(xmin, xmax)
xmin:x轴上的最小值
xmax:x轴上的最大值
np.clip()
np.clip是一个截取函数,该函数的作用是将数组a中的所有数限定到范围a_min和a_max中
np.clip(x,x_min,x_max)
所有比a_min小的数都会强制变为a_min,所有比a_max大的数都会强制变为a_max
import numpy as np # 一维矩阵 x= np.arange(12) print(x) print(np.clip(x,3,8))

np.vstack 按垂直方向(行顺序)堆叠数组构成一个新的数组
np.hstack:按水平方向(列顺序)堆叠数组构成一个新的数组
In[11]: a = np.array([[1,2,3]]) a.shape Out[11]: (1, 3) In [12]: b = np.array([[4,5,6]]) b.shape Out[12]: (1, 3) In [16]: c = np.hstack((a,b)) # 将两个(1,3)形状的数组按水平方向叠加 print(c) c.shape # 输出形状为(1,6) [[1 2 3 4 5 6]] Out[16]: (1, 6) In [17]: a = np.array([[1],[2],[3]]) a.shape Out[17]: (3, 1) In [18]: b = np.array([[4],[5],[6]]) b.shape Out[18]: (3, 1) In [19]: c = np.hstack((a,b)) 将两个(3,1)形状的数组按水平方向叠加 print(c) c.shape # 输出形状为(3,2) [[1 4] [2 5] [3 6]] Out[19]: (3, 2)In[3]: import numpy as np In[4]: a = np.array([[1,2,3]]) a.shape Out[4]: (1, 3) In [5]: b = np.array([[4,5,6]]) b.shape Out[5]: (1, 3) In [6]: c = np.vstack((a,b)) # 将两个(1,3)形状的数组按垂直方向叠加 print(c) c.shape # 输出形状为(2,3) [[1 2 3] [4 5 6]] Out[6]: (2, 3) In [7]: a = np.array([[1],[2],[3]]) a.shape Out[7]: (3, 1) In [9]: b = np.array([[4],[5],[6]]) b.shape Out[9]: (3, 1) In [10]: c = np.vstack((a,b)) # 将两个(3,1)形状的数组按垂直方向叠加 print(c) c.shape # 输出形状为(6,1) [[1] [2] [3] [4] [5] [6]] Out[10]: (6, 1)
np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。
import numpy as np X = 2 * np.random.rand(100, 1) X_b = np.c_[np.ones((100, 1)), X] # add x0 = 1 to each instance print(X) print(X_b)
np.random.random_sample(n)
随机生成n个(0,1)范围的浮点数
import numpy as np print(np.random.random_sample(10))

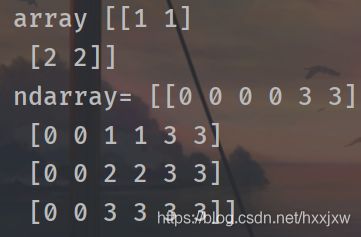
np.pad()
对一维数组的填充
np.pad()常用与深度学习中的数据预处理,可以将numpy数组按指定的方法填充成指定的形状。
import numpy as np array = np.array([[1, 1],[2,2]]) """ ((1,1),(2,2))表示在二维数组array第一维(此处便是行)前面填充1行,最后面填充1行; 在二维数组array第二维(此处便是列)前面填充2列,最后面填充2列 constant_values=(0,3) 表示第一维填充0,第二维填充3 """ ndarray=np.pad(array,((1,1),(2,2)),'constant', constant_values=(0,3)) print("array",array) print("ndarray=",ndarray)
注意这里的constant_values=(0,3) 是广播机制,即对于第一维也是前面填0,后面填3,
第二维也是前面填0后面填3
如果想不一样的话
constant_values=((0,3),(2,5))
np.newaxis
np.newaxis的作用就是在一个位置增加一个一维
import numpy as np x1 = np.array([1, 2, 3, 4, 5]) # the shape of x1 is (5,) x1_new = x1[:, np.newaxis] # now, the shape of x1_new is (5, 1) # array([[1], # [2], # [3], # [4], # [5]]) x2_new = x1_new[:, np.newaxis] # (5,1,1) # [[[1]] # # [[2]] # # [[3]] # # [[4]] # # [[5]]] x1_new = x1[np.newaxis,:] # now, the shape of x1_new is (1, 5) # array([[1, 2, 3, 4, 5]])
divmod()
python divmod() 函数把除数和余数运算结果结合起来
divmod(a,b) = (a // b, a % b)
列表list *取元素值(星)
*就是取出list中的元素的值
list = [1,2,3,4] print(*list) print(list)

dataset.__getitem__()
取出对应下标的data
即
img, target = dataset.__getitem__(1000) 和这句话的功能是一样的 img, target = dataset[1000]
np.column_stack & np.row_stack
np.column_stack 将2个矩阵按列合并
np.row_stack 将2个矩阵按行合并
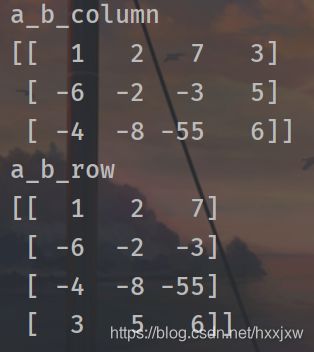
import numpy as np a = [[1, 2, 7], [-6, -2, -3], [-4, -8, -55] ] b = [3, 5, 6] a = np.array(a) b = np.array(b) a_b_column = np.column_stack((a, b)) # 左右根据列拼接 a_b_row = np.row_stack((a, b)) # 上下按照行拼接 print('a_b_column') print(a_b_column) print('a_b_row') print(a_b_row)
np.transpose()
(326, 474, 3)变为(3, 326, 474)
img = np.transpose(img, (2,0,1))
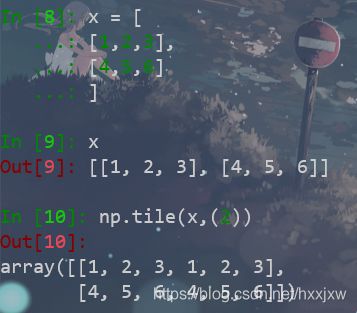
np.tile() 将数组沿各个方向复制
tile有平铺的意思
np.tile(a,(2))将函数沿着X轴扩大一倍(变为两倍)。如果扩大倍数只有一个,默认为X轴
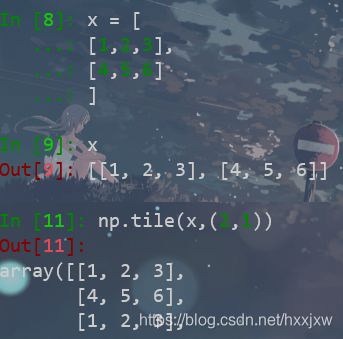
np.tile(a,(2,1))第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数
sys._getframe().f_code.co_name
获取当前函数的 函数名
import sys class test_class(): def hello(self): print(sys._getframe().f_code.co_name) if __name__ == '__main__': t = test_class() t.hello()
nltk.word_tokenize()
输入一个句子,将句子拆分成单词,输出句子中各个单词组成的list(包括标点符号)

os.symlink()
创建一个软链接
list按字符长度从大到小排序
myList = ['青海省','内蒙古自治区','西藏自治区','新疆维吾尔自治区','广西壮族自治区'] myList.sort(key = lambda i:len(i),reverse=True) print(myList)
获得指定长度字符串, 不够开头补零 zfill
str(num).zfill(7)得到7位长度的字符串
对列表lsit去重
通过set
orgList = [1,0,3,7,7,5] #list()方法是把字符串str或元组转成数组 formatList = list(set(orgList)) print (formatList)
np.full
整个数组填充(不是对角线)
np.full((3, 2), 5)生成一个(3,2)维的数组,填充成5

np.concatenate()
和torch.cat一样,在某一维拼接起来
没有np.concat()
np.concatenate((x,y), axis=0)axis就是dim
np.mean()
求平均值
np.mean(list_)
计算log
import math x = math.log(x)
Softmax
只有tensor有nn.Softmax()
numpy中没有算softmax的函数,要自己写
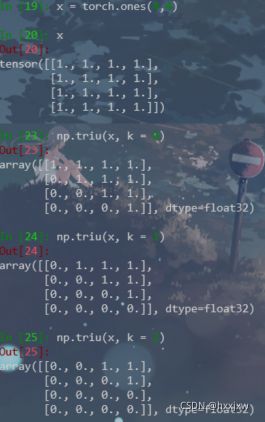
np.triu()
np.triu(a, k)取矩阵a的上三角数据,但这个三角的斜线位置由k的值确定
filter() 过滤器
filter()属于内置函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
def is_odd(n): return n % 2 == 1 tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) newlist = list(tmplist) print(newlist)
将列表中的每个元素根据is_odd函数判断True/False, 将得到Trye的元素过滤出来
用lambda函数的例子
dict_a = [{'name': 'python', 'points': 10}, {'name': 'java', 'points': 8}] test_filter = filter(lambda x : x['name'] == 'python', dict_a) print(list(test_filter))


浮点数保留几位小数
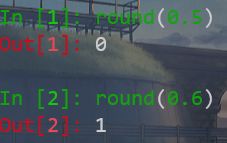
round(x,3)
对浮点数x保留3位小数
注意,round不是四舍五入,而是HALF EVEN(也叫银行家舍入),即<=0.5是0,>0.5是1
浮点数转整数
①int()
int(x)直接舍弃小数部分
②
floor() 向下取整 效果等同于int()
ceil()向上取整
如果想要四舍五入
int(x+0.5)

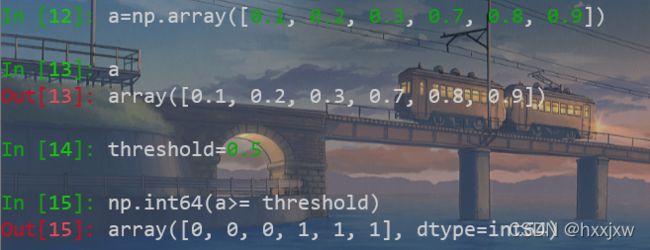
numpy array 中大于某个值的所有元素置0
# 矩阵a中大于Threshold(阈值)的部分置0 a[a > Threshold] = 0 # 矩阵a中小鱼Threshold(阈值)的部分置0 a[a < Threshold] = 0根据阈值threshold将某向量转换为所有元素为0或者1的二进制向量
通常用于将sigmoid的输出结果(概率)转化为预测标签。
例如大于0.5的元素转换为1,否则转换为0.
整数类别转one hot编码
y=np.array([0,5,3,2,4,6]) num_classes = 7 np.eye(num_classes)[y]

获取list特定元素下标 list.index()
如果有多个,index()只是找到第一个

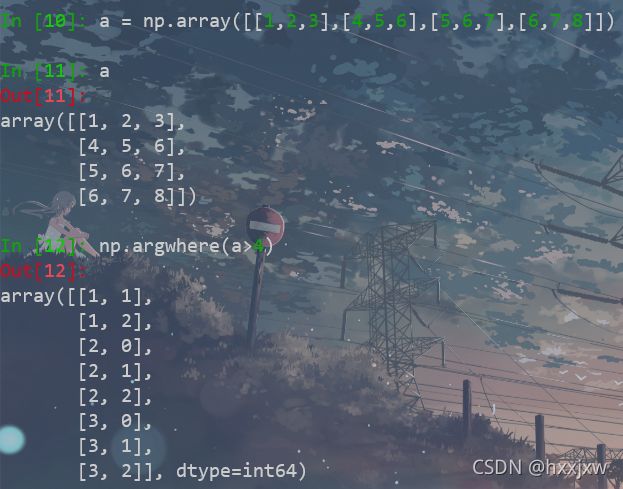
np.argwhere() 查找某个指定元素的索引
import torch import numpy as np a = np.array([[1,2,3],[4,5,6],[5,6,7],[6,7,8]]) index = np.argwhere( a>4 ) print(index)
获得h,w
例如是一个tensor,size是[b,c,h,w]
h,w = x.shape[2:]

eval() 字符串表达式求值

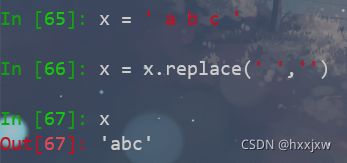
去掉字符串中的某些值
replace()方法,可以去除全部空格
replace同时可以替换
strip()方法,只能去除字符串开头或者结尾的空格

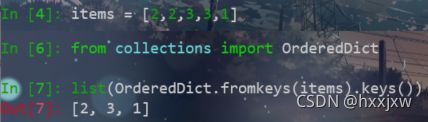
求掉list中的重复元素
①用set
但这会破坏顺序
list(set(items))
②用collections.OrderedDict
keep order
from collections import OrderedDict list(OrderedDict.fromkeys(items).keys())

** 解包
**在python中是解包操作
a = {'ross':'123456', 'xiaoming':'abc123'} b = {'lilei':'111111', 'zhangsan':'1234567'} c = {} for k in a: c[k] = a[k] for k in b: c[k] = b[k] print(c)
可以等价于
a = {'ross':'123456', 'xiaoming':'abc123'} b = {'lilei':'111111', 'zhangsan':'1234567'} c = {**a, **b} print(c)这里的**a和**b相当于将字典a和b的内容直接填写到了这里

统计list元素出现的次数 collections.Counter()
collections.Counter(x)得到的是一个counter对象

拆分含有多种分隔符的字符串 re.split()
re是正则表达式的库
但是比字符串的split会慢一些
re.split('[;,|\t]+',s)

itertools.islice 迭代
itertools.islice(iterable, start, stop[, step])
可以返回从迭代器中的start位置到stop位置的元素。如果stop为None,则一直迭代到最后位置。
当有些迭代器不支持索引查找时,就可以用它来做
例如我想通过序号查找运动员,但是OrderedDict不支持这种操作
那么我就可以



itertools.chain()连接多个迭代对象
如果都是list可以用+,但是不同的对象的话用itertools.chain连接

列表extend()
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值
即如果列表A有5个值,列表B有3个值,想把B的三个值都append到列表A中,如果一个个追加太麻烦,直接一个A.extend(B)就可以了

np.cumsum() 计算某一维度的累加和
np.cumsum(a,axis=0)

np.delete() 删除numpy array特定位置index的元素

np.argsort() 将数组排序后返回排序后的下标
注意返回的只是下标
所以取数组x的最小值可以写成:
x[x.argsort()[0]]数组x的最大值,写成
x[x.argsort()[-1]]或者用argmin()和argmax()函数
也可以适用于

判断字母/数字 isdigit() isalpha()
x.isdigit() x.isalpha()


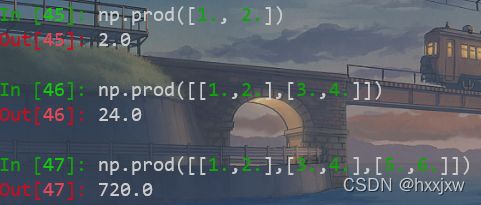
np.prod() 计算所有元素的乘积
对于有多个维度的数组可以指定轴
如果没有指定那就是所有元素全部相乘
指定axis
指定计算行的乘积
选择特定的元素相乘
可以设定一个初始值,与输入数组中的元相乘



np类型转换
查看数据类型
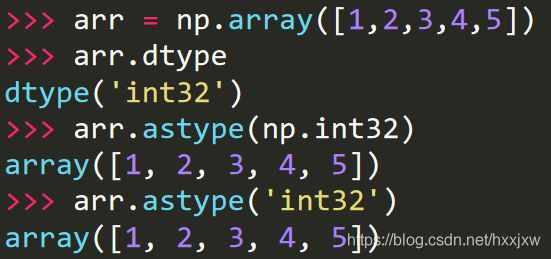
x.dtype转换数据类型
image = image.astype(np.float32)
np.pad() 填充/补零
和torch.pad()稍有不同
如果是想在两个维度上填充的话
np.pad(A,((3,2),(2,3)),'constant',constant_values = (-2,2)) #填充值,前面填充改为-2,后面填充改为2填充时,从前面轴,往后面轴依次填充。
0轴和1轴分别填充不同的值,先填充0轴,后填充1轴,存在1轴填充覆盖0轴填充的情形
例如A.shape是[128,256] 即第一个(3,2)是在128维度上,第二个(2,3)是在256维度上
(3,2)表示在A的第[0]轴填充(二维数组中,0轴表示行),即在0轴前面填充3个宽度的0,比如数组A中的95,96两个元素前面各填充了3个0;在后面填充2个0,比如数组A中的97,98两个元素后面各填充了2个0
(2,3)表示在A的第[1]轴填充(二维数组中,1轴表示列),即在1轴前面填充2个宽度的0,后面填充3个宽度的0
input 获取用户输入
x都是str类型

np.fromfile()
根据文本或二进制文件中的数据构造一个数组。
一种读取具有已知数据类型的二进制数据以及解析简单格式化的文本文件的高效方法。使用tofile方法写入的数据可以使用此函数读取。
- 函数:
np.fromfile(frame,dtype=float,count=-1,sep='')frame:文件、字符串。dtype:读取的数据类型。count:读入元素个数,-1表示读入整个文件。sep:数据分割字符串,如果是空串,写入文件为二进制。
find() 检测字符串中是否包含子字符串 str
和in的作用一样
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
str.find(str, beg=0, end=len(string))
可以s.find(a,10), 但是s.find(a, beg=10)或s.find(a, start=10)就报错,很奇怪

chr()和ord()
chr()和ord()是一对对应的函数
- ord(char)返回ascll数值
- chr(ascii数值)返回char

np.linalg 线性代数模块
numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。
求逆矩阵
np.mat()
np.linalg.inv()
注:矩阵必须是方阵且可逆,否则会抛出LinAlgError异常。
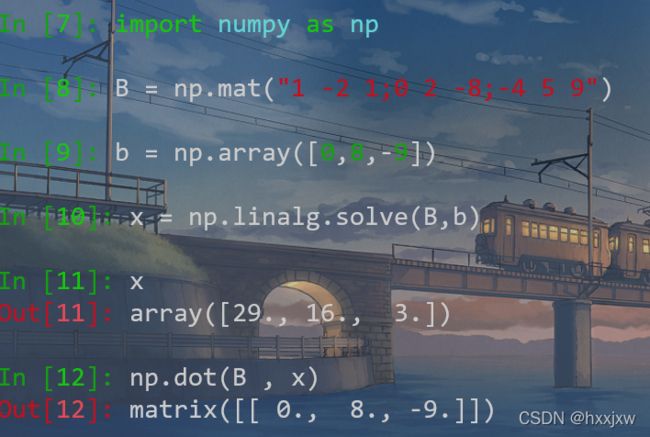
求解线性方程组
np.linalg.solve()
np.linalg中的函数solve可以求解形如 Ax = b 的线性方程组,其中 A 为矩阵,b 为一维或二维的数组,x 是未知变量
特征值和特征向量
特征值(eigenvalue)即方程 Ax = ax 的根,是一个标量。其中,A 是一个二维矩阵,x 是一个一维向量。特征向量(eigenvector)是关于特征值的向量
np.linalg模块中,eigvals函数可以计算矩阵的特征值,而eig函数可以返回一个包含特征值和对应的特征向量的元组
import numpy as np # 创建一个矩阵 C = np.mat("3 -2;1 0") # 调用eigvals函数求解特征值 c0 = np.linalg.eigvals(C) print (c0) # [ 2. 1.] # 使用eig函数求解特征值和特征向量 (该函数将返回一个元组,按列排放着特征值和对应的特征向量,其中第一列为特征值,第二列为特征向量) c1,c2 = np.linalg.eig(C) print (c1) # [ 2. 1.] print (c2) #[[ 0.89442719 0.70710678] # [ 0.4472136 0.70710678]] # 使用dot函数验证求得的解是否正确 for i in range(len(c1)): print ("left:",np.dot(C,c2[:,i])) print ("right:",c1[i] * c2[:,i]) #left: [[ 1.78885438] # [ 0.89442719]] #right: [[ 1.78885438] # [ 0.89442719]] #left: [[ 0.70710678] # [ 0.70710678]] #right: [[ 0.70710678] # [ 0.70710678]]奇异值分解SVD
# SVD(Singular Value Decomposition,奇异值分解)是一种因子分解运算,将一个矩阵分解为3个矩阵的乘积
# numpy.linalg模块中的svd函数可以对矩阵进行奇异值分解。该函数返回3个矩阵——U、Sigma和V,其中U和V是正交矩阵,Sigma包含输入矩阵的奇异值。import numpy as np # 分解矩阵 D = np.mat("4 11 14;8 7 -2") # 使用svd函数分解矩阵 U,Sigma,V = np.linalg.svd(D,full_matrices=False) print ("U:",U) #U: [[-0.9486833 -0.31622777] # [-0.31622777 0.9486833 ]] print ("Sigma:",Sigma) #Sigma: [ 18.97366596 9.48683298] print ("V",V) #V [[-0.33333333 -0.66666667 -0.66666667] # [ 0.66666667 0.33333333 -0.66666667]] # 结果包含等式中左右两端的两个正交矩阵U和V,以及中间的奇异值矩阵Sigma # 使用diag函数生成完整的奇异值矩阵。将分解出的3个矩阵相乘 print (U * np.diag(Sigma) * V) #[[ 4. 11. 14.] # [ 8. 7. -2.]]

产生某个size的布尔矩阵
B = np.full((4,4), True, dtype = bool)
np.prod() 计算所有元素的乘积
对于有多个维度的数组可以指定轴,如axis=1指定计算每一行的乘积

np.roll
np.roll(a, shift, axis=None)将a,沿着axis的方向,滚动shift长度

np.logical_and() 逐元素进行逻辑运算
