全网目前最全python例子(附源码)八、Python实战
Python实战
1 环境搭建
区分几个小白容易混淆的概念:pycharm,python解释器,conda安装,pip安装,总结来说:
pycharm是python开发的集成开发环境(Integrated Development Environment,简称IDE),它本身无法执行Python代码python解释器才是真正执行代码的工具,pycharm里可设置Python解释器,一般去python官网下载python3.7或python3.8版本;如果安装过anaconda,它里面必然也包括一个某版本的Python解释器;pycharm配置python解释器选择哪一个都可以。anaconda是python常用包的合集,并提供给我们使用
conda命令非常方便的安装各种Python包。conda安装:我们安装过anaconda软件后,就能够使用conda命令下载anaconda源里(比如中科大镜像源)的包pip安装:类似于conda安装的python安装包的方法
修改镜像源
在使用安装conda 安装某些包会出现慢或安装失败问题,最有效方法是修改镜像源为国内镜像源。之前都选用清华镜像源,但是2019年后已停止服务。推荐选用中科大镜像源。
先查看已经安装过的镜像源,cmd窗口执行命令:
conda config --show
复制代码查看配置项channels,如果显示带有tsinghua,则说明已安装过清华镜像。
channels:
- https://mirrors.tuna.tsinghua.edu.cn/tensorflow/linux/cpu/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
复制代码下一步,使用conda config --remove channels url地址删除清华镜像,如下命令删除第一个。然后,依次删除所有镜像源
conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/tensorflow/linux/cpu/
复制代码添加目前可用的中科大镜像源:
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
复制代码并设置搜索时显示通道地址:
conda config --set show_channel_urls yes
复制代码确认是否安装镜像源成功,执行conda config --show,找到channels值为如下:
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- defaults
复制代码Done~
2 自动群发邮件
Python自动群发邮件
import smtplib
from email import (header)
from email.mime import (text, application, multipart)
import time
def sender_mail():
smt_p = smtplib.SMTP()
smt_p.connect(host='smtp.qq.com', port=25)
sender, password = '[email protected]', "**************"
smt_p.login(sender, password)
receiver_addresses, count_num = [
'[email protected]', '[email protected]'], 1
for email_address in receiver_addresses:
try:
msg = multipart.MIMEMultipart()
msg['From'] = "zhenguo"
msg['To'] = email_address
msg['subject'] = header.Header('这是邮件主题通知', 'utf-8')
msg.attach(text.MIMEText(
'这是一封测试邮件,请勿回复本邮件~', 'plain', 'utf-8'))
smt_p.sendmail(sender, email_address, msg.as_string())
time.sleep(10)
print('第%d次发送给%s' % (count_num, email_address))
count_num = count_num + 1
except Exception as e:
print('第%d次给%s发送邮件异常' % (count_num, email_address))
continue
smt_p.quit()
sender_mail()
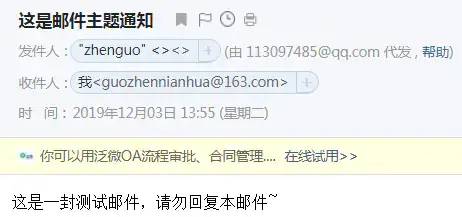
复制代码注意:发送邮箱是qq邮箱,所以要在qq邮箱中设置开启SMTP服务,设置完成时会生成一个授权码,将这个授权码赋值给文中的password变量。
发送后的截图:
3 二分搜索
二分搜索是程序员必备的算法,无论什么场合,都要非常熟练地写出来。
小例子描述:在有序数组arr中,指定区间[left,right]范围内,查找元素x如果不存在,返回-1
二分搜索binarySearch实现的主逻辑
def binarySearch(arr, left, right, x):
while left <= right:
mid = int(left + (right - left) / 2); # 找到中间位置。求中点写成(left+right)/2更容易溢出,所以不建议这样写
# 检查x是否出现在位置mid
if arr[mid] == x:
print('found %d 在索引位置%d 处' %(x,mid))
return mid
# 假如x更大,则不可能出现在左半部分
elif arr[mid] < x:
left = mid + 1 #搜索区间变为[mid+1,right]
print('区间缩小为[%d,%d]' %(mid+1,right))
# 同理,假如x更小,则不可能出现在右半部分
elif x在Ipython交互界面中,调用binarySearch的小Demo:
In [8]: binarySearch([4,5,6,7,10,20,100],0,6,5)
区间缩小为[0,2]
found 5 at 1
Out[8]: 1
In [9]: binarySearch([4,5,6,7,10,20,100],0,6,4)
区间缩小为[0,2]
区间缩小为[0,0]
found 4 at 0
Out[9]: 0
In [10]: binarySearch([4,5,6,7,10,20,100],0,6,20)
区间缩小为[4,6]
found 20 at 5
Out[10]: 5
In [11]: binarySearch([4,5,6,7,10,20,100],0,6,100)
区间缩小为[4,6]
区间缩小为[6,6]
found 100 at 6
Out[11]: 6
复制代码4 爬取天气数据并解析温度值
爬取天气数据并解析温度值
素材来自朋友袁绍,感谢!
爬取的html 结构

import requests
from lxml import etree
import pandas as pd
import re
url = 'http://www.weather.com.cn/weather1d/101010100.shtml#input'
with requests.get(url) as res:
content = res.content
html = etree.HTML(content)
复制代码通过lxml模块提取值
lxml比beautifulsoup解析在某些场合更高效
location = html.xpath('//*[@id="around"]//a[@target="_blank"]/span/text()')
temperature = html.xpath('//*[@id="around"]/div/ul/li/a/i/text()')
复制代码结果:
['香河', '涿州', '唐山', '沧州', '天津', '廊坊', '太原', '石家庄', '涿鹿', '张家口', '保定', '三河', '北京孔庙', '北京国子监', '中国地质博物馆', '月坛公
园', '明城墙遗址公园', '北京市规划展览馆', '什刹海', '南锣鼓巷', '天坛公园', '北海公园', '景山公园', '北京海洋馆']
['11/-5°C', '14/-5°C', '12/-6°C', '12/-5°C', '11/-1°C', '11/-5°C', '8/-7°C', '13/-2°C', '8/-6°C', '5/-9°C', '14/-6°C', '11/-4°C', '13/-3°C'
, '13/-3°C', '12/-3°C', '12/-3°C', '13/-3°C', '12/-2°C', '12/-3°C', '13/-3°C', '12/-2°C', '12/-2°C', '12/-2°C', '12/-3°C']
复制代码构造DataFrame对象
df = pd.DataFrame({'location':location, 'temperature':temperature})
print('温度列')
print(df['temperature'])
复制代码正则解析温度值
df['high'] = df['temperature'].apply(lambda x: int(re.match('(-?[0-9]*?)/-?[0-9]*?°C', x).group(1) ) )
df['low'] = df['temperature'].apply(lambda x: int(re.match('-?[0-9]*?/(-?[0-9]*?)°C', x).group(1) ) )
print(df)
复制代码详细说明子字符创捕获
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(group)。比如:^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码
m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
print(m.group(0))
print(m.group(1))
print(m.group(2))
# 010-12345
# 010
# 12345
复制代码如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
最终结果
Name: temperature, dtype: object
location temperature high low
0 香河 11/-5°C 11 -5
1 涿州 14/-5°C 14 -5
2 唐山 12/-6°C 12 -6
3 沧州 12/-5°C 12 -5
4 天津 11/-1°C 11 -1
5 廊坊 11/-5°C 11 -5
6 太原 8/-7°C 8 -7
7 石家庄 13/-2°C 13 -2
8 涿鹿 8/-6°C 8 -6
9 张家口 5/-9°C 5 -9
10 保定 14/-6°C 14 -6
11 三河 11/-4°C 11 -4
12 北京孔庙 13/-3°C 13 -3
13 北京国子监 13/-3°C 13 -3
14 中国地质博物馆 12/-3°C 12 -3
15 月坛公园 12/-3°C 12 -3
16 明城墙遗址公园 13/-3°C 13 -3
17 北京市规划展览馆 12/-2°C 12 -2
18 什刹海 12/-3°C 12 -3
19 南锣鼓巷 13/-3°C 13 -3
20 天坛公园 12/-2°C 12 -2
21 北海公园 12/-2°C 12 -2
22 景山公园 12/-2°C 12 -2
23 北京海洋馆 12/-3°C 12 -3