CVPR2021 | 实现图像的“无限放大”,超详细局部隐式图像函数(LIIF)解读
作者‖ flow
编辑‖ 3D视觉开发者社区
论文链接https://openaccess.thecvf.com/content/CVPR2021/papers/Chen_Learning_Continuous_Image_Representation_With_Local_Implicit_Image_Function_CVPR_2021_paper.pdf
代码链接: https://yinboc.github.io/liif/
一、概述
LIIF在离散2D与连续2D之间构建了桥梁,进而对图像进行分辨率调整,实现所谓的“无限放大”。通过局部的隐式图像函数对连续的图像进行表达。所谓的局部隐式表达(local implicit image Function, LIF),指函数以图像坐标以及坐标周围的二维特征作为输入,以某给定坐标处的RGB数值作为输出。由于坐标是连续的值,因此LIIF可以以任意分辨率进行表示。为了生成影像的连续表达,我们通过一个用于超分的自监督任务训练得到一个编码器。学得的连续表达就可以以任意分辨率进行超分,超分的分辨率甚至可以高达30x。换句话说,LIIF搭建了2D离散值和连续表达之间的桥梁,因此,它天然的支持GT的尺寸不一样的情况。
二、局部隐式图像函数(Local Implicit Image Function, 简称LIIF)
在LILF的表达中,将每一个连续的图像 I ( i ) I^{(i)} I(i)都会被表达成2D的特征图 M ( i ) ∈ R H ∗ W ∗ D M^{(i)} \in \mathbb{R}^{H*W*D} M(i)∈RH∗W∗D。解码的函数 f θ f_{\theta} fθ将被所有的影像共用,其参数 θ \theta θ由MLP获得,数学表达为:
s = f θ ( z , x ) s = f_\theta(z,x) s=fθ(z,x)
其中, z z z是一个向量,可以理解为隐藏的特征编码, x ∈ X x \in \mathcal{X} x∈X是在连续影像坐标域上的一个2D的坐标, s ∈ S s \in \mathcal{S} s∈S是预测的值,比如说RGB图上的颜色值。
MLP的python代码为:
@register('mlp') class MLP(nn.Module): def __init__(self, in_dim, out_dim, hidden_list): super().__init__() layers = [] lastv = in_dim for hidden in hidden_list: layers.append(nn.Linear(lastv, hidden)) layers.append(nn.ReLU()) lastv = hidden layers.append(nn.Linear(lastv, out_dim)) self.layers = nn.Sequential(*layers) def forward(self, x): shape = x.shape[:-1] x = self.layers(x.view(-1, x.shape[-1])) return x.view(*shape, -1)
不妨假设 x x x在二维空间上两个维度的范围分别为: [ 0 , 2 H ] [0,2H] [0,2H]以及 [ 0 , 2 W ] [0,2W] [0,2W],且称 M ( i ) M^{(i)} M(i)为潜在编码,其将均匀地分布在连续的影像域中,如下图中的蓝圈所示:
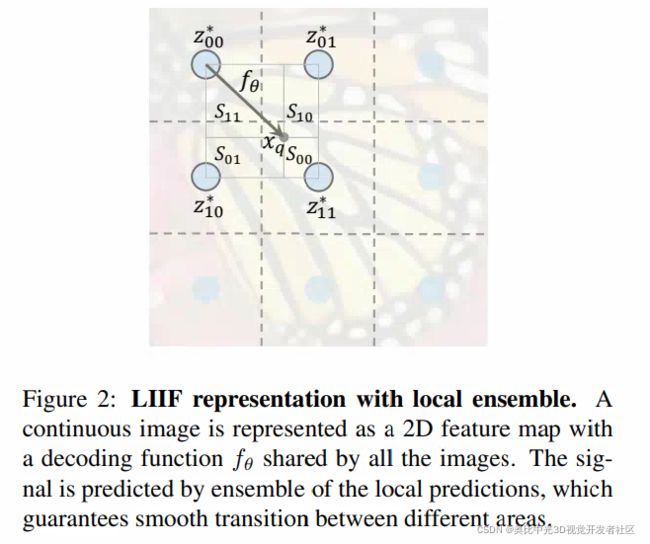
对于平均分布的潜在编码 M ( i ) M^{(i)} M(i)而言,我们为每一个篮圈都分配一个2D坐标。
对于连续的影像 I ( i ) I^{(i)} I(i),在某个坐标位置 x q x_q xq的RGB值被定义为:
I ( i ) ( x q ) = f θ ( z ∗ , x q − v ∗ ) I^{(i)}(x_q) = f_{\theta}(z*,x_q - v*) I(i)(xq)=fθ(z∗,xq−v∗)
其中, z ∗ z* z∗是在欧几里得意义上与坐标 x q x_q xq最近的潜在编码, v ∗ v* v∗是潜在编码 z ∗ z^* z∗在影像域上的坐标。以Fig 2为例,设 z 11 ∗ z_{11}^{*} z11∗就是 x q x_q xq的潜在编码,而 v ∗ v^{*} v∗就是 z 11 ∗ z_{11}^{*} z11∗的坐标。
综上,有一个被所有影像共享的函数 f θ f_{\theta} fθ,图像的连续表达形式是 M ( i ) ∈ R H ∗ W ∗ D M^{(i)} \in \mathbb{R}^{H * W *D} M(i)∈RH∗W∗D,其被视作 H ∗ W H * W H∗W大小的潜在编码。在 M ( i ) M^{(i)} M(i)中的潜在编码,表示了连续图像的局部特征,其将为该局部块的所有连续坐标的输出负责。
1、Feature unfolding
为了丰富 M ( i ) M^{(i)} M(i)中的每一个潜在编码的信息丰富程度,我们将 M ( i ) M^{(i)} M(i)扩展为 M ^ ( i ) \hat{M}^{(i)} M^(i)。
在 M ^ ( i ) \hat{M}^{(i)} M^(i)中,每一个潜在编码都变成了原本 M i M^{i} Mi中的 3 ∗ 3 3 * 3 3∗3相邻的潜在编码的concat。公式表达为:
M ^ j k ( i ) = Concat ( { M j + l , k + m ( i ) } l , m ∈ { − 1 , 0 , 1 } ) \hat{M}_{j k}^{(i)}=\operatorname{Concat}\left(\left\{M_{j+l, k+m}^{(i)}\right\}_{l, m \in\{-1,0,1\}}\right) M^jk(i)=Concat({Mj+l,k+m(i)}l,m∈{−1,0,1})
对于 M ( i ) M^{(i)} M(i)中超出边界的部分直接补0。在做完Feature unfolding后,之后的所有计算都由 M ^ ( i ) \hat{M}^{(i)} M^(i)来进行。简单来说,后续所有需要 M ( i ) M^{(i)} M(i)的部分,都替换成 M ^ ( i ) \hat{M}^{(i)} M^(i)。
2、局部ensemble
对于该式来说,
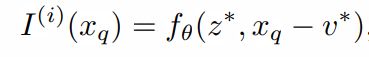
有一个巨大的问题就是预测是不连续的。具体来说,由于在 x q x_q xq区域的预测是通过查询其最近的潜在编码 z ∗ z^* z∗来得到的,也就是说,随着 x q x_q xq在2D域上的移动, z ∗ z^{*} z∗会突然的变化,比如说在Fig 2中,当 x q x_q xq跨越虚线的时候就会出现这种情况。只要 f θ f_{\theta} fθ没有非常完美,对于每一次跨越虚线的情况,都会产生目视效果上的不连续感。
为了解决这样的问题,将上式改写为:
I ( i ) ( x q ) = ∑ t ∈ { 00 , 01 , 10 , 11 } S t S ⋅ f θ ( z t ∗ , x q − v t ∗ ) I^{(i)}\left(x_{q}\right)=\sum_{t \in\{00,01,10,11\}} \frac{S_{t}}{S} \cdot f_{\theta}\left(z_{t}^{*}, x_{q}-v_{t}^{*}\right) I(i)(xq)=t∈{00,01,10,11}∑SSt⋅fθ(zt∗,xq−vt∗)
其中, z t ∗ z_t^{*} zt∗表示左上、右上、左下、右下四个位置的潜在编码, v t ∗ v_t^{*} vt∗是 z t ∗ z_t^{*} zt∗的坐标, S t S_t St表示 x q x_q xq和 v t ′ ∗ v_{t'}^{*} vt′∗之间的矩阵,而 t ′ t' t′与 t t t呈对角关系。
我们事先已经认为潜在特征将在边界外被镜像地填充,因此,上式对于边界附近的坐标也是适用的。
直观上讲,这样做的目的是使得由局部潜在编码所表示的局部片段能够和其周围的局部片段有所重合,进而使得每一个坐标处都有四个独立的潜在编码对其进行独立的预测,且这四个独立预测的结果将进行加权,即为最终的预测结果。
这样就可以在 z ∗ z^{*} z∗进行变换的时候实现平滑过渡。
3、Cell decoding
在实践中,我们希望LILF能够以任意分辨率进行表达。假设我们已经给定了想要的分辨率,那么一种直观的方法就是直接通过 I ( i ) ( x ) I^{(i)}(x) I(i)(x)的方式来查询像素中心的RGB值。尽管这样的做法已经可以工作的很好了,但是并不是最优的,因为对于某一个查询像素的RGB值和它的size是无关的,而在其分辨率的像素范围内的其他信息却都被丢掉了(除了中心位置)。
为了解决这个问题,文章提出了“cell decoding”,示意图如下所示:

且将 s = f θ ( z , x ) s=f_{\theta}(z, x) s=fθ(z,x)改写为:
s = f cell ( z , [ x , c ] ) s=f_{\text {cell }}(z,[x, c]) s=fcell (z,[x,c])
其中, c = [ c h , c w ] c = [c_h,c_w] c=[ch,cw]包含了指定像素的高与宽, [ x , c ] [x,c] [x,c]则表示 x x x与 c c c的concat。
在进行连续表达的时候,实验会证明,额外给定一个 c c c的输入是有所裨益的。
三、学习连续的图像表达
学习连续的图像表达的流程示意图为:

具体地,在该任务中,训练集为一系列的影像,目标是为一个网络没见过的图片生成连续的表达。
通常的思想是首先训练一个编码器 E φ E_{\varphi} Eφ,该编码器将影像映射为一个2D的特征图,该2D特征图与LIIF的表达是一致的。而 f θ f_{\theta} fθ对于所有的影像来说,是共享的函数。
自然,我们希望LIIF不仅仅能够很好地表达输入,更重要的是能够形成一个连续的表达,希望其能够在高分辨率下也能够保证高保真,因此,文章设计了超分的自监督任务。
现在,我们对Fig 4中的流程进行详细的描述,对于一张训练图像来说,首先对其进行随机尺度的下采样,作为网络的输入。而GT的获取则是通过将训练影像表示为像素样本 x h r 、 s h r x_{hr}、s_{hr} xhr、shr,其中 x h r x_{hr} xhr是像素在影像域的中心坐标, s h r s_{hr} shr则为对应的RGB值。编码器 E φ E_{\varphi} Eφ将输入的图像映射为一个2D的特征图,该2D特征图将被作为LIIF中的隐含编码。而坐标 x h r x_{hr} xhr则被用于查询 L I I F LIIF LIIF表达中的值, f θ f_{\theta} fθ则用于输出对应坐标的RGB值。不妨设 s p r e d s_{pred} spred为预测的RGB值,训练损失(在实验中使用了L1损失)在 s p r e d s_{pred} spred与GT s h r s_{hr} shr之间进行计算。此外,在进行cell decoding的操作时,我们将 x x x替换为 [ x , c ] [x,c] [x,c]。
四、实验
1、学习连续影像表达
设定
使用DIV2K数据集进行实验。其中包含了1k张2k分辨率的图片,并提供了下采样2倍、3倍、四倍的低分辨率对应图(由MATLAB中的resize函数生成,默认为bicubic插值方式生成)。使用DIV2K数据中的800张影像进行训练。在测试阶段,报告了在DIV2K验证集上的100张影像以及在Set5、Set14、B100、Urban100上的结果。
实验目标是为像素表达的图像生成连续的表示,所谓的连续,则表示着能够在高保真度的前提下,以任意分辨率对图像进行表达。因此,为了能够定量地对连续性进行评估,实验对训练集分布内与训练集分布外的尺寸都进行了测试与评估。
特别地,在训练时,上采样倍数在1倍到4倍之间,在测试时,上采样倍数则在6倍到30倍之间。这样做的目的就是,更为严谨地测试是否真正的学到了连续表达,是否真的能够在任意分辨率上进行表达。
实现细节
在编码输入中,使用48*48大小的图片块作为编码器的输入。不妨设 B B B为batchsize,首先采样了B个随机尺度 r 1 ∼ B r_{1 \sim B} r1∼B (均匀分布 μ ( 1 , 4 ) \mu(1,4) μ(1,4)),然后从训练数据中裁剪了 B B B个大小为 { 48 r i ∗ 48 r i } \{48r_i * 48r_i\} {48ri∗48ri} i = 1 B _{i=1}^B i=1B的图像块。而 48 ∗ 48 48 * 48 48∗48大小的输入则是对应倍数下采样的图像块。
对于GT来说,需要将影像转为像素级的样本,即坐标与RGB值的一对一对输入,那么,对于每一个patch来说,则会采样 4 8 2 48^2 482个像素的样本。
将影像转变为coord-RGB pairs的实现代码为:
def make_coord(shape, ranges=None, flatten=True): """ Make coordinates at grid centers. """ coord_seqs = [] for i, n in enumerate(shape): if ranges is None: v0, v1 = -1, 1 else: v0, v1 = ranges[i] r = (v1 - v0) / (2 * n) seq = v0 + r + (2 * r) * torch.arange(n).float() coord_seqs.append(seq) ret = torch.stack(torch.meshgrid(*coord_seqs), dim=-1) if flatten: ret = ret.view(-1, ret.shape[-1]) return ret def to_pixel_samples(img): """ Convert the image to coord-RGB pairs. img: Tensor, (3, H, W) """ coord = make_coord(img.shape[-2:]) rgb = img.view(3, -1).permute(1, 0) return coord, rgb
方法可以结合不同的编码器。在本实验中,使用EDSR-baseline或者RDN作为编码器 E ψ E_{\psi} Eψ,编码的特征大小与输入的影像大小一致。
损失函数使用L1损失。
在训练过程中,使用Pytorch中的bicubic重采样方法来得到连续的降采样。
对于在验证过程中上采样倍数为2、3、4的情况,使用DIV2K数据集中的低分影像作为输入。对于在验证过程中上采样倍数为6-30的情况,则首先对GT进行裁剪(使得大小正好能够被倍数整除),然后再通过bicubic重采样的方式得到低分输入。
此外,使用的优化器为Adam,初始学习率为1e-4,模型训练的batchsize大小为16,训练轮数为1000轮,学习衰减率为0.5(每两百轮进行一次衰减)。
MetaSR的实验设定和LIIF一致,仅仅在其meta解码器的部分与LIIF不同。
定量结果
在表一和表二中,展示了LIIF方法与其他SOTA的对比结果。具体地,EDSR-baseline和RDN的超分倍数只能限制在训练的上采样倍数内,而不能用于其他未见过的上采样倍数。
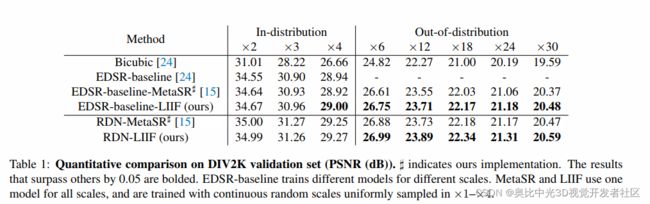
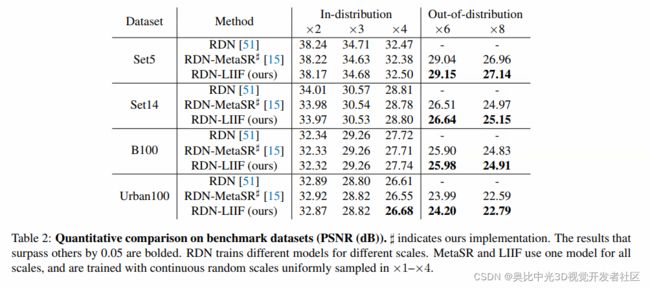
表中可见,上采样倍数越大,隐式神经表达的优势越大。
定性结果
在图5中给出了一个定性比较:

图中,1-SIREN表示独立地对测试图像进行SIREN神经隐式表达的拟合,也就是说,一个神经网络对一张影像,不使用影像编码器。MetaSR和LIIF均使用1倍到4倍的上采样倍数进行训练,使用30倍的上采样倍数进行测试。目视结果可见,LIIF显然比其他方法效果要好。
2、消融实验
在cell decoding中,将查询像素的形状与 f θ f_{\theta} fθ的输入建立关系。直觉上来看,其告诉 f θ f_{\theta} fθ要对局部的信息进行一个整合,然后再输出合适的RGB值。在表3中,对比了LIIF以及LIIF(-c),表中结果可见,使用cell decoding的技巧可以提升2倍、3倍、4倍上采样时的效果,然而,随着上采样尺度逐渐变得更大,似乎cell decoding会在一定程度上损害PSNR的数值。或许,这表示学到的cell无法泛化到训练过程中没见过的倍数上。

在定性上的cell decoding分析,可见下图:

而其他的消融部件也在表三中进行了体现。在此不赘述。
3、学习不同尺寸的GT: image-to-image
我们现在不妨假定有一个模型可以生成固定尺寸的特征图,我们不需要对尺寸不同的GT进行重采样。这是因为,LIIF可以自然地搭建出固定尺寸的特征图和不同尺寸的GT之间的桥梁。
接下来将以一个image-to-image的实验作为示例进行介绍。
设定
使用CelebAHQ数据集,其中包含了30000张高分辨的面部图片。将其中的25000张作为训练集,5000张作为测试集。
任务是学习一个从低分辨率( L ∗ L L * L L∗L)的面部图像到高分辨率 H ∗ H H * H H∗H的映射。然而,在训练数据集中的影像分辨率均匀地分布在 L ∗ L L * L L∗L与 H ∗ H H * H H∗H之间,且对于每一张训练图像,都有其对应的降采样的低分辨率的 L ∗ L L * L L∗L大小的输入。
这个任务虽然也是超分任务,但是与前面的超分任务并不一样。
在前面的超分任务中,假定场景包含了自然场景,训练可以基于patch进行。而对于特定的上采样倍数,超分的输入与输出是固定的。然而,在本任务中,期望模型直接以 L ∗ L L * L L∗L作为输入,而不是patch的输入。
方法及结果
比较两种端到端的方法,第一种被认为是“上采样”模块,其GT使用bicubic重采样的方法 resize至 H ∗ H H * H H∗H大小,第二种方法则是使用LILF的表达,GT不必要对GT进行重采样。
表四则为比较结果:

五、结论
在本文中,提出了用于连续图像表示的局部隐式图像函数(LIIF)。
在LIIF表示中,每个图像表示为一个二维特征图,所有图像共享一个解码函数。具体地,基于输入坐标和相邻特征向量输出RGB值。
多个超分任务的实验结果表明,在保持高保真度的前提下,该方法可以获得比其他上采样模块更高的泛化精度,尤其是在更高的采样倍数情况下,这进一步地证明了LIIF表示确实在二维离散和连续表示之间搭建了一座桥梁。
参考文献
RDN: Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018.
RDN-MetaSR: Xuecai Hu, Haoyuan Mu, Xiangyu Zhang, Zilei Wang, Tieniu Tan, and Jian Sun. Meta-sr: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1575–1584, 2019.
Up-sampling modules/Bicubic: Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 136–144, 2017.
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号3D视觉开发者社区,获取更多干货知识哦。