前文传送门:抽象编码器MessageToByteEncoder
写buffer队列
之前的小节我们介绍过, writeAndFlush方法其实最终会调用write和flush方法
write方法最终会传递到head节点, 调用HeadContext的write方法:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
这里通过unsafe对象的write方法, 将消息写入到缓存中, 具体的执行逻辑, 我们在这个小节进行剖析
我们跟到AbstractUnsafe的write方法中
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
//负责缓冲写进来的byteBuf
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
safeSetFailure(promise, WRITE_CLOSED_CHANNEL_EXCEPTION);
ReferenceCountUtil.release(msg);
return;
}
int size;
try {
//非堆外内存转化为堆外内存
msg = filterOutboundMessage(msg);
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
//插入写队列
outboundBuffer.addMessage(msg, size, promise);
}
首先看 ChannelOutboundBuffer outboundBuffer = this.outboundBuffer
ChannelOutboundBuffer的功能就是缓存写入的ByteBuf
我们继续看try块中的 msg = filterOutboundMessage(msg)
这步的意义就是将非对外内存转化为堆外内存
filterOutboundMessage方法方法最终会调用AbstractNioByteChannel中的filterOutboundMessage方法:
protected final Object filterOutboundMessage(Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
//是堆外内存, 直接返回
if (buf.isDirect()) {
return msg;
}
return newDirectBuffer(buf);
}
if (msg instanceof FileRegion) {
return msg;
}
throw new UnsupportedOperationException(
"unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES);
}
首先判断msg是否byteBuf对象, 如果是, 判断是否堆外内存, 如果是堆外内存, 则直接返回, 否则, 通过newDirectBuffer(buf)这种方式转化为堆外内存
回到write方法中
outboundBuffer.addMessage(msg, size, promise)将已经转化为堆外内存的msg插入到写队列
我们跟到addMessage方法当中, 这是ChannelOutboundBuffer中的方法:
public void addMessage(Object msg, int size, ChannelPromise promise) {
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
if (tailEntry == null) {
flushedEntry = null;
tailEntry = entry;
} else {
Entry tail = tailEntry;
tail.next = entry;
tailEntry = entry;
}
if (unflushedEntry == null) {
unflushedEntry = entry;
}
incrementPendingOutboundBytes(size, false);
}
首先通过 Entry.newInstance(msg, size, total(msg), promise) 的方式将msg封装成entry
然后通过调整tailEntry, flushedEntry, unflushedEntry三个指针, 完成entry的添加
这三个指针均是ChannelOutboundBuffer的成员变量
flushedEntry指向第一个被flush的entry
unflushedEntry指向第一个未被flush的entry
也就是说, 从flushedEntry到unflushedEntry之间的entry, 都是被已经被flush的entry
tailEntry指向最后一个entry, 也就是从unflushedEntry到tailEntry之间的entry都是没flush的entry
我们回到代码中:
创建了entry之后首先判断尾指针是否为空, 在第一次添加的时候, 均是空, 所以会将flushedEntry设置为null, 并且将尾指针设置为当前创建的entry
最后判断unflushedEntry是否为空, 如果第一次添加这里也是空, 所以这里将unflushedEntry设置为新创建的entry
第一次添加如下图所示
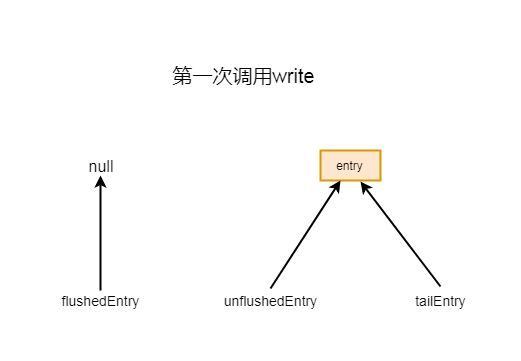
7-3-1
如果不是第一次调用write方法, 则会进入 if (tailEntry == null) 中else块:
Entry tail = tailEntry 这里tail就是当前尾节点
tail.next = entry 代表尾节点的下一个节点指向新创建的entry
tailEntry = entry 将尾节点也指向entry
这样就完成了添加操作, 其实就是将新创建的节点追加到原来尾节点之后
第二次添加 if (unflushedEntry == null) 会返回false, 所以不会进入if块
第二次添加之后指针的指向情况如下图所示:
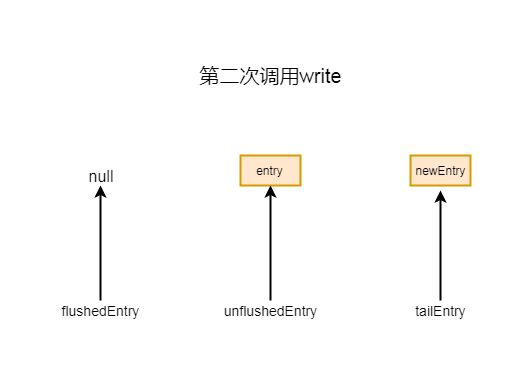
7-3-4
以后每次调用write, 如果没有调用flush的话都会在尾节点之后进行追加
回到代码中, 看这一步incrementPendingOutboundBytes(size, false)
这步时统计当前有多少字节需要被写出, 我们跟到这个方法中:
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
}
//TOTAL_PENDING_SIZE_UPDATER当前缓冲区里面有多少待写的字节
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
//getWriteBufferHighWaterMark() 最高不能超过64k
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
setUnwritable(invokeLater);
}
}
看这一步:
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size)
TOTAL_PENDING_SIZE_UPDATER表示当前缓冲区还有多少待写的字节, addAndGet就是将当前的ByteBuf的长度进行累加, 累加到newWriteBufferSize中
在继续看判断 if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark())
channel.config().getWriteBufferHighWaterMark() 表示写buffer的高水位值, 默认是64k, 也就是说写buffer的最大长度不能超过64k
如果超过了64k, 则会调用setUnwritable(invokeLater)方法设置写状态
我们跟到setUnwritable(invokeLater)方法中
private void setUnwritable(boolean invokeLater) {
for (;;) {
final int oldValue = unwritable;
final int newValue = oldValue | 1;
if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {
if (oldValue == 0 && newValue != 0) {
fireChannelWritabilityChanged(invokeLater);
}
break;
}
}
}
这里通过自旋和cas操作, 传播一个ChannelWritabilityChanged事件, 最终会调用handler的channelWritabilityChanged方法进行处理
以上就是写buffer的相关逻辑,更多关于Netty分布式编码器写buffer队列的资料请关注脚本之家其它相关文章!