Linux指令整理(从入门到高级)+Shell语法
一、Linux简介与安装
1.1 计算机的相关概念
1. 什么是计算机
能够接收使用者输入的指令与数据,经由中央处理器的算术与逻辑单元运算处理后,以产生或存储有用的新数据。比如计算器,手机,汽车导航系统,提款机,桌面电脑,手提电脑等。
2. 计算机的硬件组成
计算单元和控制单元(CPU)
输入单元(键盘,鼠标)
输出单元(显示器,打印机)
存储单元(硬盘,u盘,内存条)
3. 操作系统
用来管理计算机硬件和其他软件的计算机程序,没有操作系统的计算机,就是一堆废铁。
常见的PC端操作系统:windows,linux,mac
常见的移动端操作系统:鸿蒙系统(大力支持),ios,Android等
4. 文件系统
用来管理文件(数据)的软件程序。
通常其组织结构都是树形结构
1.2 Linux的简介
1. 简介
- 是一款免费的,开源的类Unix操作系统,支持多用户,多任务,多线程,多cpu
- 支持32位和64位
- Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
- Linux也继承了Unix的文件设计思想,一切皆文件(文件夹也是文件)
- Linux之父是“托瓦斯林纳斯”
2. 版本说明:
Linux由于是开源的,所以有很多公司在Linux内核程序基础上开发了自己的有特别功能的程序(工具),然后,再命令为一个新的版本,因此Linux有众多的版本型号。
总结:严格来讲,Linux操作系统指的是“linux内核+各种软件”.
常见的Linux版本:
Red Hat系列:
其中就有RedHat,CentOS
Debin系列
其中就有Debin,Ubuntu
3. CentOS社区版介绍
CentOS官网:http://www.centos.org/
CentOS搜狐镜像:http://mirrors.sohu.com/centos/
CentOS网易镜像:http://mirrors.163.com/centos/
CentOS阿里镜像:https://mirrors.aliyun.com/centos/
CentOS 是RedHat的社区版本,功能和RedHat基本一样
4. 用途:
Linux企业服务器
嵌入式系统:Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、智能家电等嵌入式系统。
电影娱乐行业:电影后期特效处理。
1.3 VMware的安装
1. VMware的简介
是一款虚拟化工具。可以帮助用户来模拟计算机硬件,比如模拟计算机的内存条,磁盘,cpu,输入和输出设备。然后这些硬件模拟出来后,用户就可以在这个基础上安装OS。
2. vmware的安装
安装vmware16. 双击,点击下一步即可。
注意:如果安装成功,那么在物理机的网络适配器里,应该会多出两个VMware NetWork Adapter。
一个是VMnet1,
一个是VMnet8.
破解:百度上搜VMware16激活码。
注意:如果想要在vmware中安装OS,那么物理机的BIOS必须开启虚拟化支持。
1.4 Linux的安装
1. 第一大步:使用vmware先虚拟化一台硬件机器
文件-->新建虚拟机-->典型-->稍后安装操作系统
-->选择Linux,并选择CentOS 7 64位
--> 虚拟机名称: test01
位置:最好改成其他盘符
--> 磁盘大小: 50G, hadoop之后一定要50G以上
单个文件和多个文件,哪一个都行。
-->自定义硬件
内存:2G
处理器: 1个cpu,2个核
新CD/DVD: 指定要安装的OS的映像文件
删除声卡和打印机, 确定即可 最终完成
---------------------到此为止,硬件模拟完成----------------------
2. 安装OS
开启此虚拟机-->选择install centos......
-->简体中文
-->设置分区:自动或者自定义
自定义: +键
/boot 300M
/swap(磁盘交换空间) 1024M
/ 剩下的全部给根
接受更改
--> 安装
--> 安装期间设置root的密码或者是新用户
超级管理员:root
密码:123123
--> 重新加载
--> 成功启动了,开心的玩吧。
二、Linux的基础命令(重要)
2.1 命令格式的说明
1. 进入命令行界面的提示符解析
[root@localhost ~]#
root位置: 登录用户名
@: 连接符号
localhost位置: 本机的主机名
~位置: 当前的所在位置
#位置: 表示是超级管理员还是普通用户
超级管理员则使用#
普通用户则使用$
eg: 如果登录名为scott,主机名为qianfeng01, 当前位置为/home/soft/tencent/wechat/
那么提示符的样子:
[scott@qianfeng01 wechat]$
2. 命令格式的说明(格式标明时的中括号一般情况下都表示可有可无)
格式如下:
[scott@qianfeng01 wechat]$ command [-option][...] [参数]
eg: ls -la /usr
说明:
- 大部分命令遵从该格式
- 多个选项时,可以一起写
eg: ls –l –a ls –la
- 简化选项与完整选项(注:并非所有选项都可使用完整选项)
eg: ls –all ls –a
2.2 三个最常用的指令
1. pwd : print current work directory三个单词的简写
作用就是以绝对路径的形式显示当前的位置所在
eg:
[root@localhost network-scripts]# pwd
/etc/sysconfig/network-scripts
[root@localhost ~]# pwd
/root
2. ls : list directory contents的简写
作用,就是列出指定目录下的内容(文件,子目录等)
eg: ls 默认列出当前工作空间里的内容
常用的选项:
-l : 列出每个子文件的属性详情
-a : 显示所有的内容,包括隐藏的
-S : 以大小进行降序排序显示, 尽量与-h,-l一起使用
-h: 以方便人类可读的显示效果显示大小的单位,比如k,MB,G
eg: ls -l 显示属性详情, 可以简化写: ll
eg: ls -a 显示所有包括隐藏的内容
eg: ls -l -a 显示所有包括隐藏的内容的属性详情 ,简化写:ll -a 或者ls -la
eg: ls -lhS 显示当前目录下的所有内容,并降序排序
eg: ls -lhS /etc 显示指定目录/etc下的所有内容,并降序排序
3. cd : change directory的简写, 切换工作空间。
注意:是一个特殊指令,特殊在是一个shell内置指令。
cd [target directory]
eg: cd 回家
eg: cd ~ 回家
eg: cd - 回到上一次的位置
eg: cd /etc 切换到/etc下
eg: cd .. 回到上一级目录(父目录)
cd . 表示不动
扩展1:属性详情
【-rw-------】 【1】 【root】 【root】 【1259】 【11月 29 19:03】 【anaconda-ks.cfg】
文件类型+权限 硬链接数 owner group 文件大小 最后一次访问时间 文件名
扩展2:绝对和相对路径
在计算机中,路径有两种写法,分别是绝对路径和相对路径
-- 绝对路径: 从根开始书写的路径。 Linux的根的写法,就是一个斜杠 /
eg: /home/scott/app/tencent/qq/bin/qq.sh
-- 相对路径: 从当前目录下开始书写的路径。
. : 当前目录的表示方式 注意: 书写相对路径时,当前目录可以省略不写
.. : 上一级目录的表示方式
eg: 假如工作空间位于:/home/scott/app/tencent/qq/bin/目录下
问题1: 切换到app目录下
绝对路径的写法: cd /home/scott/app/
相对路径的写法: cd ./../../../
cd ../../../
问题2: 切换到/home/michael/app/目录下
绝对路径的写法: cd /home/michael/app
相对路径的写法: cd ../../../../../michael/app/
小贴士: 如果不涉及移动操作,那么绝对路径书写起来简单。
如果涉及到项目移动,项目部署,则应该使用相对路径
2.3 帮助指令
man指令:
作用:查看指定命令的帮助文档
语法: man 指令
eg: man ls
man pwd
man cd
help指令
作用:查看指定命令的主题信息
语法: help 指令
注意: 不是所有的指令都有主题信息
info指令
作用:用来查看指令命令的详细信息
语法: info 指令
2.4 文件处理指令
2.4.1 touch
作用:用于创建一个空文件
语法: touch filename.....
eg:
[root@localhost etc]# touch file1 file2 file3
[root@localhost etc]# pwd
/etc
[root@localhost etc]# touch ~/file4
[root@localhost etc]# touch ~/{file5,file6}
[root@localhost etc]# ls ~
anaconda-ks.cfg file1 file2 file3 file4 file5 file6
2.4.2 mkdir
作用:用于创一个目录
语法:mkdir [-p] dirname.....
[root@localhost ~]# mkdir dir1
[root@localhost ~]# mkdir ./dir2 ./dir3
[root@localhost ~]# cd /etc
[root@localhost etc]# mkdir ~/{dir4,dir5}
[root@localhost etc]# mkdir ~/dir6/dir66 #会报错,因为dir6不存在,所以不能创建dir66
[root@localhost etc]# mkdir -p ~/dir6/dir66 #表示多层级创建目录
[root@localhost etc]# ls -l ~
总用量 4
-rw-------. 1 root root 1259 11月 29 19:03 anaconda-ks.cfg
drwxr-xr-x. 2 root root 6 11月 29 22:32 dir1
drwxr-xr-x. 2 root root 6 11月 29 22:33 dir2
drwxr-xr-x. 2 root root 6 11月 29 22:33 dir3
drwxr-xr-x. 2 root root 6 11月 29 22:33 dir4
drwxr-xr-x. 2 root root 6 11月 29 22:33 dir5
drwxr-xr-x. 3 root root 19 11月 29 22:34 dir6
-rw-r--r--. 1 root root 0 11月 29 22:28 file1
-rw-r--r--. 1 root root 0 11月 29 22:28 file2
-rw-r--r--. 1 root root 0 11月 29 22:28 file3
-rw-r--r--. 1 root root 0 11月 29 22:29 file4
-rw-r--r--. 1 root root 0 11月 29 22:30 file5
-rw-r--r--. 1 root root 0 11月 29 22:30 file6
[root@localhost etc]# ls ~/dir6
dir66
2.4.3 rm
作用:删除文件或者是目录
语法:rm [-rf] filename .....
eg:
[root@localhost ~]# ls
anaconda-ks.cfg dir1 dir2 dir3 dir4 dir5 dir6 file1 file2 file3 file4 file5 file6
[root@localhost ~]# rm file1
rm:是否删除普通空文件 "file1"?y
[root@localhost ~]# ls
anaconda-ks.cfg dir1 dir2 dir3 dir4 dir5 dir6 file2 file3 file4 file5 file6
[root@localhost ~]# rm dir1
rm: 无法删除"dir1": 是一个目录
[root@localhost ~]# rm -f file2
[root@localhost ~]# ls
anaconda-ks.cfg dir1 dir2 dir3 dir4 dir5 dir6 file3 file4 file5 file6
[root@localhost ~]# rm -r dir1
rm:是否删除目录 "dir1"?y
[root@localhost ~]# ls
anaconda-ks.cfg dir2 dir3 dir4 dir5 dir6 file3 file4 file5 file6
[root@localhost ~]#
总结: 默认情况下,是有询问的删除文件,输入y表示删除,输入n表示不删除
如果想要强制删除文件,添加-f, 但是要慎用。
如果想要删除目录,必须添加-r,表示递归删除。
2.4.4 mv
作用:移动文件或者目录,有更名作用
语法: mv [OPTION]... SOURCE... DIRECTORY
eg:
[root@localhost ~]# ls
anaconda-ks.cfg dir2 dir3 dir4 dir5 dir6 file3 file4 file5 file6
[root@localhost ~]# mv file3 file4 dir2 dir3 # 将file3 file4 dir2 移动到dir3里
[root@localhost ~]# ls
anaconda-ks.cfg dir3 dir4 dir5 dir6 file5 file6
[root@localhost ~]# ls dir3
dir2 file3 file4
[root@localhost ~]# mv file6 dir3/file7 #将file6移动到dir3里并更名为file7
[root@localhost ~]# ls dir3
dir2 file3 file4 file7
[root@localhost ~]#
2.4.5 cp
作用:拷贝文件或者是目录
语法:cp [-r] source....directory
eg:
[root@localhost ~]# rm -rf ./* 删除当前目录下的所有非隐藏文件
[root@localhost ~]# touch file1 file2 file3
[root@localhost ~]# mkdir dir1 dir2 dir3
[root@localhost ~]# ll
总用量 0
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir1
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir2
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir3
-rw-r--r--. 1 root root 0 11月 29 23:04 file1
-rw-r--r--. 1 root root 0 11月 29 23:04 file2
-rw-r--r--. 1 root root 0 11月 29 23:04 file3
[root@localhost ~]# cp file1 dir1 # 拷贝file1到dir1里
[root@localhost ~]# ll
总用量 0
drwxr-xr-x. 2 root root 19 11月 29 23:04 dir1
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir2
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir3
-rw-r--r--. 1 root root 0 11月 29 23:04 file1 #源文件依然存在
-rw-r--r--. 1 root root 0 11月 29 23:04 file2
-rw-r--r--. 1 root root 0 11月 29 23:04 file3
[root@localhost ~]# ls dir1 # 查看dir1里的内容
file1
[root@localhost ~]# echo "helloworld" > file2 #写一些字符串到file2文件里
[root@localhost ~]# ll
总用量 4
drwxr-xr-x. 2 root root 19 11月 29 23:04 dir1
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir2
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir3
-rw-r--r--. 1 root root 0 11月 29 23:04 file1
-rw-r--r--. 1 root root 11 11月 29 23:05 file2
-rw-r--r--. 1 root root 0 11月 29 23:04 file3
[root@localhost ~]# cp file2 dir1/file22 # 复制file2到dir1里同时更名为file22
[root@localhost ~]# ll dir1
总用量 4
-rw-r--r--. 1 root root 0 11月 29 23:04 file1
-rw-r--r--. 1 root root 11 11月 29 23:05 file22
[root@localhost ~]# cp file3 file4 #拷贝并更名
[root@localhost ~]# ll
总用量 4
drwxr-xr-x. 2 root root 33 11月 29 23:05 dir1
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir2
drwxr-xr-x. 2 root root 6 11月 29 23:04 dir3
-rw-r--r--. 1 root root 0 11月 29 23:04 file1
-rw-r--r--. 1 root root 11 11月 29 23:05 file2
-rw-r--r--. 1 root root 0 11月 29 23:04 file3
-rw-r--r--. 1 root root 0 11月 29 23:07 file4
[root@localhost ~]# cp dir2 dir3 # 拷贝目录时, 不带参数-r,会忽略目录
cp: 略过目录"dir2"
[root@localhost ~]# ll dir3
总用量 0
[root@localhost ~]# cp dir1 dir3
cp: 略过目录"dir1"
[root@localhost ~]# ll dir3
总用量 0
[root@localhost ~]# cp -r dir1 dir3 # 如果想要拷贝目录,应该带上-r参数,表示递归拷贝
[root@localhost ~]# ll dir3
总用量 0
drwxr-xr-x. 2 root root 33 11月 29 23:08 dir1
2.4.6 ln
作用:用于创建链接文件
语法: ln [-s] filename newfilename
解析:
linux的链接文件分为两类,
一类是软链接文件: 软链接文件相当于windows的快捷方式
文件和目录都可以有软链接
创建语法: ln -s filename newfilename
一类是硬链接文件: 文件可以有硬链接,目录不能有硬链接
创建语法: ln filename newfilename
总结: 软链接,新开辟了一个文件块和inode
硬链接,就是源文件名的别名

2.4.7 echo
作用: 用于展示一行文件信息
语法: echo 字符串|环境变量名
[root@localhost ~]# echo you are best # 打印一串字符,到控制台
you are best
[root@localhost ~]# echo "you are best"
you are best
[root@localhost ~]# echo $HOME #打印HOME变量的值
/root
[root@localhost ~]# echo $PATH #打印PATH变量的值
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@localhost ~]# echo $HOSTNAME #打印HOSTNAME变量的值
localhost.localdomain
扩展:重定向符号
> : 重定向到某一个位置,会覆盖原有的内容
>>: 重定向到某一个文职,追加到原有内容的后面
[root@localhost ~]# echo "hello world"
hello world
# 将一串字符输入到content.txt文件里, 注意,如果该文件不存在,会直接创建。
[root@localhost ~]# echo "hello world" > content.txt
[root@localhost ~]# ll
总用量 16
-rw-r--r--. 1 root root 12 11月 29 23:43 content.txt
[root@localhost ~]# echo "hello" > content.txt #覆盖
[root@localhost ~]# ll
总用量 16
-rw-r--r--. 1 root root 6 11月 29 23:43 content.txt #变成6个字节
[root@localhost ~]# echo "world" >> content.txt #追加
[root@localhost ~]# ll
总用量 16
-rw-r--r--. 1 root root 12 11月 29 23:44 content.txt #变成12个字节
2.5 文件查看指令
2.5.1 cat
作用: 查看整个文件的内容
语法: cat [-An] filename
解析: -A 显示隐藏的字符
-n 显示行号
2.5.2 more/less
作用: 用于分页查看文件内容
语法: more filename
解析: 默认查看第一页内容
空格键/f键 查看下一页
enter键: 一行一行的滚动
b :往回翻页
q|Q: 退出
less和more用法一样
2.5.3 head
作用: 查看文件的头部信息,默认查看10行
语法: head [-number] filename
解析: 如果想要查看指定行数,添加-数字
2.5.4 tail
作用:查看文件的末尾信息,默认查看10行
语法: tail [-number] filename
解析: 如果想要查看指定行数,添加-数字
2.6 文件查找指令
find
作用:是可以根据指定类型参数,来查找文件系统中的文件或者是目录的
语法: find 搜索位置 条件
eg:
[root@localhost ~]# find /etc -name 'init*' 按照名字查找init开头的文件或目录
/etc/inittab
/etc/sysconfig/init
/etc/sysconfig/network-scripts/init.ipv6-global
/etc/init.d
/etc/rc.d/init.d
/etc/selinux/targeted/active/modules/100/init
/etc/selinux/targeted/contexts/initrc_context
[root@localhost ~]# find /etc -name 'init' 按照名字为init的文件或目录
/etc/sysconfig/init
/etc/selinux/targeted/active/modules/100/init
[root@localhost ~]# find /etc -name 'in??' 按照名字查找in开头并且长度为4的文件或目录
/etc/sysconfig/init
/etc/selinux/targeted/active/modules/100/init
[root@localhost ~]# find /etc -name '?i*' 按照名字查找第二个字符是i的文件或目录
find /etc -type d 查看/etc下的所有目录,包括子目录
d:目录 l:软链接, f:普通文件
find /etc -size -1024
find /etc -size +2K -size -3k 单位: k,M,G等
注意: 默认单位为一个block 一个block相当于512byte
如果想要查询小于100MB的文件, 100*1024KB 100*1024*2block
所以:find /etc -size -204800
find /etc -size +1024 查看大于512KB的文件
grep
作用:用于过滤查询文件内容
语法:grep [-cinv] '搜寻字符串' filename
-c :输出匹配行的个数(是以行为单位,不是以出现次数为单位)
-i :忽略大小写,所以大小写视为相同
-n :显示匹配行及行号
-v :反向选择,显示不包含匹配文本的所有行。
eg:
[root@localhost ~]# grep -i HOST ./profile 忽略大小写的查找host所在的行信息
[root@localhost ~]# grep -ci HOST ./profile 忽略大小写的查找host所在的行的数量
[root@localhost ~]# grep -in HOST ./profile 忽略大小写的查找host所在的行信息以及行号
[root@localhost ~]# grep -v HOST ./profile 查找除了HOST所在的行的其他行的信息
扩展:管道
管道: |
作用: 将前一个命令的结果通过管道交给后一个命令,继续操作
[root@localhost ~]# grep -i HOST ./profile
HOSTNAME=`/usr/bin/hostname 2>/dev/null`
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# 前一个查询的结果交给下一个grep继续过滤
[root@localhost ~]# grep -i HOST ./profile | grep USER
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
which
作用:用来在path变量的值中查找命令的位置
语法: which 命令
whereis
作用:用于查看命令的位置和帮助文件的位置
语法: whereis 命令
2.7 文件(解)压缩指令
gzip/gunzip
作用:压缩指令,将每一个文件进行压缩。一个文件对应一个压缩文件
语法: gzip filename.....
特点:
- 只能压缩文件,
- 并且源文件会消失
- 压缩文件名的后缀.gz
gzip -d 表示解压缩,相当于gunzip的作用
bzip2/bunzip2(需要安装)
作用:压缩指令,将每一个文件进行压缩。一个文件对应一个压缩文件
语法: bzip2 filename.....
特点:
- 只能压缩文件,
- 默认情况下,源文件会消失, 除非带上-k参数,会保留源文件
- 压缩文件名的后缀.bz2
bzip2 -d 表示解压缩,相当于bunzip2的作用
zip
作用:压缩指令,可以将多个文件或者目录压缩到一个压缩文件中。
语法: zip -r compressfilename.zip file1 file2.... dir1 dir2....
特点:
- 保留源文件
- 需要自定义压缩文件名
- 如果有目录要压缩,必须添加-r参数
小贴士:zip是为了兼容windows的压缩工具,而提供的
zip和unzip都需要安装
tar
作用:打包指令,用于将多个文件打成一个包,也就是一个包文件
语法: tar -[cxvf] tarfilename.tar file............
解析: -c :表示打包,即create
-f :用于指定新文件名,必须和新文件名挨着
-x :拆包, 不能和-c共存
-v :显示压缩过程
eg: tar -cvf michael.tar file1 file2 dir1 dir2
tar -xvf michael.tar 拆包
小贴士:
- 打包后的文件大小,是打包前的总和。
- 所以,如果想要压缩包文件,tar指令一般会和压缩(解压缩)指令一起使用。
常用组合: zcvf 中的z 表示gzip
jcvf 中的j 表示bzip2
打包并压缩:tar -[zcvf] arfilename.tar file............
tar -[jcvf] arfilename.tar file............
解压缩并拆包:tar -[zxvf] arfilename.tar
tar -[jxvf] arfilename.tar
2.8 时间指令date
作用:查看或者设置时间
reg:
date 查看系统当前时间
以自定义的方式显示系统时间: date +'%Y-%m-%d %H:%M:%S'
注意:+与字符串之间不能有空格,与date之间要有空格
设置时间
eg: date -s "2015-5-8 19:48:00"
同步到bios,重启之后才能继续生效
eg: hwclock -w
作用:查看时间或者修改时间
]$ date "+%Y-%m-%d %H:%M:%S" 更改输出样式
]$ date -s "2019-08-05 11:25:00" 设置时间
]$ date -d "10 days ago" "+%Y-%m-%d %H:%M:%S" 获取10天前的时间
]$ dt=`date -d "10 days ago" "+%Y-%m-%d %H:%M:%S"`
]$ echo $dt
2.9 系统关机指令
1. 重启指令
reboot
init 6
2. 关机指令:
shutdown -h now 立即关机
shutdown -h 20:30 定时关机
poweroff
half
init 0
2.10 linux的快捷键和basename以及dirname
ctrl+c 终止前台程序
ctrl+z 将前台程序挂起, fg指令是用于将挂起程序调度到前台运行
ctrl+l 清屏,相当于clear
ctrl + a 回到命令行的最前端
ctrl + e 回到命令行的最后面
ctrl + w 删除光标前的一个单词
ctrl + k 删除光标后的所有单词
basename /root/profile 用于显示整个路径中的最后一个名字 结果:profile
dirname /etc/dir1/profile 显示最后一个名字之前的整个路径 结果:/etc/dir1
tab键: 自动补全键
按1次的效果: 补全到相同的字符的最后一位。
按2次的效果: 显示所有符合该字符串开头的文件或者文件夹,或者是命令
2.11 磁盘相关命令
2.11.1 du
作用:用于查看文件或目录的大小(磁盘使用空间)
语法:du [-ahs] [文件名|目录]
解析:
-a 显示子文件的大小
-h 以易读的方式显示 KB,MB,GB等
-s summarize 统计总占有量
说明: -s和-a不能同时使用
2.11.2 df
作用:用于查看Linux文件系统的状态信息,显示各个分区的容量、已使用量、未使用量及挂载点等信息以及剩余空间
语法:df \[-hkam] [挂载点]
-h(human-readable)根据磁盘空间和使用情况 以易读的方式显示 KB,MB,GB等
-k 以KB 为单位显示各分区的信息,默认
-m 以MB为单位显示信息
-a 显示所有分区包括大小为0 的分区
2.11.3 free
作用:显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
相当于windows的任务管理器里的性能查看
语法: free [-kmg]
选项:
-k: 以KB为单位显示,默认就是以KB为单位显示
-m: 以MB为单位显示
-g: 以GB为单位显示
清理缓存命令:
echo 1 > /proc/sys/vm/drop_caches
三、Linux的高阶指令(重要)
3.1 vi/vim编辑器及其相关指令
3.1.1 为什么要学习VI/VIM
1、所有的类Unix系统,都自带vi 文本编辑器
2、很多应用程序的编辑界面都会主动呼唤 vi编辑器
3、vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计;
4、操作简单,编辑速度快。
5、VIM是VI的升级版
vi编辑器就是和windows的记事本,某些本文编辑工具(notepad++,editplus,sublim text)一样
3.1.2 模式介绍
命令模式(一般模式)
用户对一个文件启动 Vim/Vi,便进入了命令模式(也称为一般模式)。此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。在此模式下,可以通过命令对文件内容进行删除,复制,粘贴等行为,可以理解为快捷键操作
插入模式(编辑模式)
在命令模式下,输入i, I, o, O, a, A, r, R等任意命令,便会立即进入插入模式(也称之编辑模式),在这个模式下,我们才可以对文件进行详细的编辑,比如使用退格键,删除键,回车键等各式各样的文本编辑了。按【ESC】键回到命令模式
底行命令模式
在命令模式下,输入字符【:?/】三个中的任意一个,就会来到底线命令模式下。在这个模式下,我们可以完成搜索、读取、存档、离开Vim/Vi等很多行为。按【ESC】键回到命令模式
参考下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7aP5XtF-1648392185126)(ClassNotes.assets/20181221085159118.png)]
3.1.3 常用命令(一般模式下使用)
H:移动到当前屏幕的最上一行的行首
M:移动到当前屏幕的中间一行的行首
L: 移动到当前屏幕的最下一行的行首
gg:移动到这个文件的第一行,相当于1G (常用)
G:移动到这个文件的最后一行(常用)
NG: 移动这个文件的第N行
x, X:在一行字符中,x表示向后删除一个字符(相当于del键),X为向前删除一个字符(相当于退格键) (常用)
nx:n为数字,连续向后删除n个字符。
dd:刪除游标所在的那一行(常用,也是剪切)
ndd:n为数字。删除游标所在的向下n行(常用)
d1G:刪除游标所在到第一行的所有行数据
dG:刪除游标所在到最后一行的所有行数据
yy,Y:复制游标所在的那一行数据(常用)
nyy,nY:n 为数字。复制游标所在的向下n行(常用)
p, P:p表示将复制的数据粘贴到游标所在行的下一行,P表示将复制的数据粘贴到游标所在行的上一行 (常用)
u:撤销前一个动作。(常用)
3.1.4 如何进入插入模式
i/I
- i 光标所在处前开始插入
- I 光标所在行行首开始插入
a/A
- a 光标所在处后开始插入
- A 光标所在行行尾开始插入
o/O
o 光标所在行的下一行开始输入
O 光标所在行的上一行开始输入
3.1.5 底行命令模式
退出操作:
:q 不保存退出, 前提是什么都没干。才会成功
:q! 强制退出,不保存
:qw 保存并退出
:qw! 强制保存并退出
其他的底层命令操作:
:set nu 显示行号
:set nonu 取消行号显示
3.2 Linux的网络配置
3.2.1 网络的相关概念
1. 外网:IP是唯一性,不能重复。范围:0.0.0.0~255.255.255.255
2. 内网:通过路由器或者交换器设备,来重新设置IP地址。
不同的内网的ip可以相同。内网A的某一台主机通过自己的网卡与自己的路由器A通信,然后路由器A通过网络中心
与路由器B通信,路由器B再与内网中的某一台机器的网卡通信。
3. IP: ip地址是确定一台机器的唯一标识符
4. NETMASK(子网掩码):与ip连用,用于确定网络段位
192.168.1.x 范围:1-254
255.255.0.0
子网掩码有1的位置对应ip的部分就是网络段位。0对应的位置就是内网中主机的位置。
5. GATEWAY:网关,用于与连接外网的机器设备通信(路由器)换句话说,网关就是路由器的IP
6. DNS:域名解析服务器
119.75.217.109 www.baidu.com
IP: IP是电脑在网络中的唯一标识符,IP的段位和号码。 段位和路由器一致,后面的号码决定该内网中可以有多少台电脑,但是初始的几个值以及最后的几个值是预用的,普通设备不能使用。
路由器:路由器里的DHCP服务器的作用,是用来给设备分配动态IP
DNS: IP的另外一个好记的名字映射的解析器
3.2.2 Linux的网络配置几种模式
1)桥接模式
该模式下的虚拟机的IP与物理机的IP是同一个段位(换句话说,内网中的机器个数=物理机个数+虚拟机个数)

2)NAT模式
使用的虚拟网卡是NetWork Adapter VMnet8,该虚拟网卡的作用是虚拟机与物理机通信。虚拟机的ip是由此虚拟交换机中的虚拟机DHCP服务器分配。能联网,可以与连接此虚拟交换机内的所有虚拟机进行通信。外网不能直接与此虚拟机通信
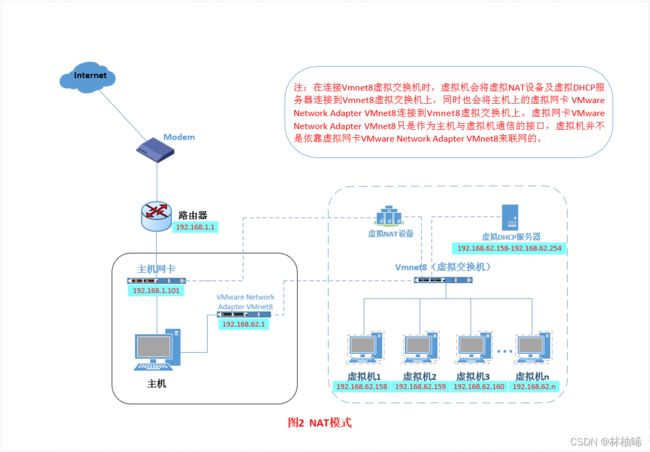
3)仅主机模式(忽略不讲)
作用就是虚拟机和物理机之间进行通信
3.2.3 桥接模式下的静态IP的网络配置
步骤1)修改该虚拟机的连接方式为桥接模式
步骤2)修改配置文件 (/etc/sysconfig/network-scripts/ifcfg-ens33)
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static #三个值dhcp,static,none可选, dhcp表示动态分配,其他两个为静态
NAME=ens33
DEVICE=ens33
ONBOOT=yes #开机后是否自动联网,yes为自动,no为手动
IPADDR=10.20.152.200
NETMASK=255.255.255.0
GATEWAY=10.20.152.1 # 这个单词特别容易写错
DNS1=10.20.152.1
DNS2=8.8.8.8
DNS3=114.114.114.114
步骤3)重启网络服务项
[root@localhost ~]# systemctl restart network
步骤4)查看ip地址
[root@localhost ~]# ip addr
步骤5)校验网络是否畅通
1. 与外网是否通畅:ping www.baidu.com
向百度服务器发送一个连接请求,如果连接成功,百度服务器就会向本机发送64个字节
2. 与物理机是否通畅:
-- 虚拟机ping物理机 ping 物理机的ip
-- 物理机ping虚拟机 ping 虚拟机的ip
3.2.4 NAT模式下的静态IP的网络配置
步骤1)修改虚拟机的连接模式为NAT模式
步骤2)查看并修改VMNet8的虚拟信息
vmware的编辑菜单-->虚拟网络编辑器-->更改设置-->选中VMnet8,修改子网IP段位为192.168.10.0
-->点击应用-->点击NAT设置,查看相关信息,比如
子网IP、子网掩码、网关
步骤3)修改配置文件
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static #三个值dhcp,static,none可选, dhcp表示动态分配,其他两个为静态
NAME=ens33
DEVICE=ens33
ONBOOT=yes #开机后是否自动联网,yes为自动,no为手动
IPADDR=192.168.10.101
NETMASK=255.255.255.0
GATEWAY=192.168.10.2 # 这个单词特别容易写错
DNS1=192.168.10.2
DNS2=8.8.8.8
DNS3=114.114.114.114
步骤4)重启网络服务项
[root@localhost ~]# systemctl restart network
步骤5)查看ip地址
[root@localhost ~]# ip addr
步骤6)校验网络是否畅通
1. 与外网是否通畅:ping www.baidu.com
向百度服务器发送一个连接请求,如果连接成功,百度服务器就会向本机发送64个字节
2. 与物理机是否通畅:
-- 虚拟机ping物理机 ping 物理机的ip
-- 物理机ping虚拟机 ping 虚拟机的ip
3.3 远程连接工具的应用
因为Linux系统通常用于服务器,没有桌面环境,只有DOS界面,而且有的时候,服务器上的软件坏掉了,或者由于权限问题,不能直接操作服务器。而是通过远程进行操作,比如管理员授权普通员工连接服务器,或者管理员自己在家,用家里的电脑连接公司的服务器,进行作业,更加方便。所以,市面上提供很多中可以远程连接服务器的软件工具。比如Xshell、FinallShell、CRT、putty、MobaXterm等
这里选择使用MobaXterm这款工具,版本随意:MobaXterm_Installer_v10.9.zip. 双击安装即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dq8q3TGV-1648392185128)(ClassNotes.assets/image-20211130144050456.png)]
小贴士:setting里可以设置主题,点击右键即粘贴等
3.4 其他网络设置
3.4.1 防火墙的关闭
systemctl status firewalld #查看防火墙的状态
systemctl stop firewalld #临时关闭防火墙
systemctl start firewalld #临时开启防火墙
systemctl disabled firewalld #设置开机不自动启动防火墙
systemctl enable firewalld #设置开机自动启动防火墙
小贴士: 集群中的linux,通常都是关闭防火墙的
3.4.2 NetworkManager的关闭
systemctl status NetworkManager
systemctl stop firewalld
systemctl start firewalld
systemctl disabled firewalld
systemctl enable firewalld
小贴士: 集群中的linux,通常都是关闭NetworkManager的
3.4.3 netstat指令
注意:该指令在net-tools安装包内,需要安装。yum -y install net-tools
英文:network statistics 命令路径:/bin/netstat 执行权限:所有用户
作用:主要用于检测主机的网络配置和状况
-a (all)显示所有连接和监听端口
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 使用数字方式显示地址和端口号
-p 显示socket的PID和进程的名字
-l (listening)显示监控中的服务器的socket
案例演示:
eg: netstat -tlnu 查看本机监听(正在使用的)的端口
eg: netstat -nltp 查看本机监听(正在使用的)的端口以及PID和Name信息
eg: netstat -ntlp | grep tcp6 查看某一个程序的端口信息
eg: netstat -atnp | grep 25 查看端口
3.4.4 主机名和映射文件的修改
1)主机名的修改
方式1:直接修改配置文件/etc/hostname
[root@localhost ~]# vi /etc/hostname
方式2: 使用hostnamectl指令
[root@localhost ~]# hostnamectl set-hostname qianfeng01
主机名的查看
[root@localhost ~]# hostname
如果想要更新当前会话的主机名,要么重启,要么进入子程序(直接bash指令)
2)映射文件的修改
域名映射文件的位置/etc/hosts
[root@qianfeng01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.101 qianfeng01 qianfeng001
192.168.10.102 qianfeng02
192.168.10.103 qianfeng03
192.168.10.104 qianfeng04
192.168.10.105 qianfeng05
注意:先写ip,在写域名字符串
ping指令,会先访问/etc/hosts文件,如果找到了ping后面的域名,则使用域名对应的ip地址,向ip地址所在的机器发送请求
3.5 常用的进程管理命令
3.5.1 ps
作用:查看系统中的进程信息
语法:ps [-auxle]
常用选项
a:显示所有用户的进程
u:显示用户名和启动时间
x:显示没有控制终端的进程
e:显示所有进程,包括没有控制终端的进程
l:长格式显示
eg:
ps -aux
ps -aux | grep java
3.5.2 pstree(需要安装:yum -y install psmisc)
作用:查看当前进程树
语法:pstree [选项]
-p 显示进程PID
-u 显示进程的所属用户
eg: pstree -p
3.5.3 kill
作用:杀死进程
语法: kill -9 pid.....
eg: kill -9 1514 1548
3.5.3 nohup
作用: 将前台进程设置成后台进程, 需要配合&符号,才可以解放当前窗口
eg: nohup ping www.baidu.com > ping.txt &
3.6 用户与用户组的相关命令
3.6.1 简介
要登入Linux系统,一定要有账号和密码才行,否则怎么登入,您说是吧。我们还知道Linux系统是一个多用户的操作系统;那么,不同的用户应该拥有不同的权限才行吧?否则,有什么意义呢。
Linux系统用user和group两个概念来进行一部分权限的限定。当然,这些权限的管理工作,还是超级管理员root来做的。
注意:因为整个系统的管理工作都是root,所以使用root用户时,要谨慎,能不用时,就尽量不用。
user,是登入Linux系统的账号,其实这个账号只是为了方便人们记忆而已,每一个账号都对应一个唯一的UID数字标识符,这个对应关系存储在/etc/passwd文件当中。所以,我们在登入的时候,Linux其实使用的是UID来辨识是否存在此用户的。
group,由于多用户概念的引用,Linux为了方便管理用户,又引用了用户组的概念。Linux系统可以有多个用户组,每个用户组也都有自己的GID数字唯一标识符。
1.用户和用户组的关系
- 一个用户可以属于多个用户组(主用户组和附加用户组)
- 一个用户组下可以有多个用户
2. 举个现实生活中的例子
用户A、B、C是公司开发部门项目组M的成员,正在开发一个JAVA项目
用户D、E、F是公司开发部门项目组N的成员,正在开发一个C语言项目
项目组N由于要赶时间完成开发,向项目组M借用了一个用户A(A牛掰,会java,还会c)
因此牛掰的A每天的上午要在项目组M中开发JAVA项目,下午要在项目组N中开发c项目。晚上......加班吧
3.6.2 User的管理(/etc/passwd,/etc/shadow)
1)useradd
语法格式:useradd [选项] [用户名]
常用选项:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户ID号 指定用户的UID
eg:
[root@qianfeng01 home]# useradd -c 'this is a new user' -g 0 -G 1 -u 1001 -s /bin/bash michael
[root@qianfeng01 home]# useradd -d /home/scott1 -c 'this is a new user' -g 0 -G 1 -u 1002 -s /bin/bash scott
小贴士: 普通用户的家的位置和名字 /home/用户名/
2)passwd
语法格式:passwd [选项] [用户名]
常用选项:
-l 锁定口令,即禁用账号。
-u 口令解锁。
-d 使账号无口令。
-f 强迫用户下次登录时修改口令。
eg: passwd michael
注意:用户账号刚创建时没有口令,账号被系统锁定,无法使用。只有我们为账户指定口令后,此账户才可以使用。设定口令的命令为passwd,超级用户可以为自己和普通用户设定口令,普通用户只能修改自己的口令。
3)su
语法:su [用户名]
作用:切换用户账户
eg:
su michael 切换成michael身份
su 切换成root身份
su root 切换成root身份
4)usermod
语法格式:usermod [选项] [用户名]
常用的选项与useradd命令中的选项一样,有-c, -d, -m, -g, -G, -s, -u等,用这些参数为用户指定新值。
另外,可以使用 -l 选项 来修改用户名(建议:如果修改用户名,最好也一起把主目录也一起修改了)。
格式如下: 如果修改用户名,最好带上-m参数,同时修改主目录
usermod -l newName -d /home/newName -m oldName
案例1:# usermod -s /bin/ksh -d /home/ls –g adm lisi
此命令将用户lisi的登录Shell修改为ksh,主目录改为/home/ls,用户组改为adm
案例2:
usermod -m michael -l michael1 -d /home/michael1
5)userdel
系统管理员可以将用户账户从系统中删除。在做删除操作时,/etc/passwd,/etc/shadow,/etc/group等相关系统文件中的该用户记录会同时删除。有的时候,可能还需要删除该用户相关的主目录。
语法格式:userdel [选项] [用户名]
常用的选项是 -r,它的作用是把用户的主目录一起删除。
如果没有添加-r. 可以使用useradd -g 指定原组 -u 指定原uid值 用户名, 添加回来,再次删除
3.6.3 Group的管理(/etc/group)
Linux将系统内的多个用户规划到不同的用户组中,这样系统就可以通过管理用户组来统一管理多个用户了。默认情况下,系统在创建用户时,会同时创建一个与它同名的用户组,然后将此用户划分到这个用户组中。
用户组的单独管理,其实就是对/etc/group系统文件的管理,涉及到的操作有:添加,删除和修改。
1)groupadd
语法格式如下:groupadd [选项] [用户组]
常用选项有:
-g 指定新用户组的组标识号(gid)。
-o 一般与-g选项同时使用,表示新用户组的gid可以与系统已有用户组的gid相同。
实例1:# groupadd grp1
//在系统中添加一个新组grp1,新组的gid是在当前已有的最大组标识号的基础上自动+1。
实例2:# groupadd -g 600 grp2
//在系统中添加了一个新组grp2,同时指定新组的组标识号是600。
2)groupmod
语法格式:groupmod [选项] [用户组]
常用的选项有:
-g 为用户组指定新的组标识号。
-o 与-g选项同时使用,用户组的新gid可以与系统已有用户组的gid相同。
-n 将用户组的名字改为新名字
实例1: # groupmod -g 601 grp1
// 将用户组grp1的组标识号修改为601。
实例2: # groupmod –g 10000 -n grp2 grp1
// 将用户组grp1的标识号改为10000,同时将组名修改为grp2。
3)groupdel
语法格式:groupdel [用户组]
案例1:# groupdel grp1
//从系统中删除用户组grp1。
3.7 文件权限命令
3.7.1 Linux系统相对安全的原因
总有人问,Linux系统为什么比windows系统相对安全呢?我们可以总结如下:
1. 使用Linux系统的人数少,尤其在国内,很少有人关注Linux。
2. 因为Linux开源,任何的系统漏洞都会被民间高手,或者是官方人员很快的发现。从漏洞的发现到补丁的放出,时间相当短,没有时间给病毒或者黑客作乱的机会。
3. 然后就是linux的权限管理,linux的权限管理很严格。病毒或者黑客想修改系统文件或者系统日志,除非有管理员密码。所以就算中了病毒,病毒的危害也非常的小,重要的系统文件都不会被破坏。所以发现了病毒稍做处理就搞定了。
4. 还有就是linux系统的程序管理。linux安装程序,基本都是利用程序管理软件,比如ubuntu、debian下的软件中心、centos,fedora和红帽的yum。linux系统安装程序基本上都是用软件管理程序,从程序开发者官网上或者是相应的发行版社区直接下载安装。不会有被恶意篡改的软件被安装到使用者的电脑上。
5. 参考我的博客:https://blog.csdn.net/Michael__One/article/details/85006165
3.7.2 文件权限的种类
| 文件权限 | 代表字符 | 数字表示 | 对文件的含义 | 对目录的含义 |
|---|---|---|---|---|
| 读(read) | r | 4 | 可以查看文件的内容 | 可以列出目录的内容 |
| 写(write) | w | 2 | 可以修改文件的内容 | 可以在目录内创建、删除文件 |
| 执行(execute) | x | 1 | 可以执行文件 | 可以进入目录 |
3.7.3 文件属性解析
[root@qianfeng01 ~]# ls -l
-rw-r--r-- 1 root root 302 8月27 9:24 namelist
【 1 】 【2】 【3】 【4】 【5】 【6】 【7】
解析:
第一列:由10个字符组成。第一个字符表示文件类型,第2~10个字符表示权限
权限由9个字符构成: 前三个字符表示owner拥有的权限
中间三个字符表示group下的所有成员拥有的权限
后三个字符表示other的权限
第二列:文件的硬链接数
第三列:owner的名称
第四列:group的名称
第五列:文件大小
第六列:该文件的最后一次访问时间
第七列:该文件名
3.7.4 文件权限的针对者
从文件属性的第一列的解析来看,文件的权限是针对于三种不同用户来设定的
- 拥有者,即文件的owner
- 用户组,即文件的所属组
- 其他人,即除了上述两种情况的其他情况,称为others
3.7.5 文件的权限的修改(chmod指令)
语法1:chmod [ugoa][+-=][rwx] [filename] 该指令只能是root和owner自己使用
解析:
u: 表示owner,即第2~4个字符
g: 表示group,即第5~7个字符
o: 表示other,即第8~10个字符
a: 表示all, 即所有人
+: 表示在原有的权限上添加新权限
-: 表示在原有的权限上撤销权限
=: 覆盖原有的权限,授予新权限
语法2:chmod [421] [filename]
解析:第二个参数中的三个数字分别表示owner,group,other的权限
即每个数字表示某一个身份的权限之和。
案例1:赋予文件file1所属组写权限
chmod g+w file1
案例2:取消所有者,用户组,其他人三个部分对file1的写权限
chmod ugo-w file1
案例3:设定目录dir1为所有用户具有全部权限
chmod 777 dir1
案例4:chmod 763 file1
7表示拥有者的权限是可读可写可执行
6表示所属组的权限是可读可写
3表示其他人的权限是可写可执行
扩展:
文件和目录创建后有默认权限:
root身份创建的:
文件:644
目录:755
普通用户创建的:
文件:664
目录:775
赋值权限问题:
针对于文件而言:权限可以任意chmod,但是在应用时,会涉及到权限够不够的问题
如果文件有执行权限,则必须给读权限。
合理性问题:如果文件有写权限,应该给读权限
针对于目录而言:权限可以任意chmod,但是在应用时,会涉及到权限够不够的问题
如果有r权限,应该赋予x权限
如果有w权限,应该赋予x权限
3.7.6 文件所属组的修改(chgrp指令)
格式:chgrp [-R] [newGroup] filename 该指令只能是root用户使用
功能描述:改变文件或目录的所属组
案例1: 改变文件file1的所属组为adm
chgrp dam file1
案例2:修改目录dir1及其子目录和文件的用户组为michael
chgrp -R michael dir1
3.7.7 文件拥有者的修改(chown指令)
格式1:chown [-R] [newOwner] filename 该指令只能是root用户使用
参数: -R 表示递归修改拥有者
案例1:改变文件file1的所有者为nobody
chown nobody file1
案例2:修改目录dir1及其子目录和文件的拥有者为michael.
chown -R michael: dir1
格式2:chown newOwner:newGroup filename #可以有chgrp的功能
案例3:将install.log的拥有者与群组改为root
chown root:root install.log
案例4:修改目录dir1的用户组为root
chown .root dir1
3.8 sudo指令的应用
3.8.1 sudo简介
有的时候,在操作和管理Linux时,我们需要切换成root身份才能进行,比如修改权限等。su可以用于切换成root账号,但是需要使用root账号的密码(管理员把自己的密码给普通用户 不合适吧)。
sudo,则是root给普通用户的一个特殊指令,普通用户不用再特意切换成root身份,就可以使用root才能使用的一些指令。仅仅需要普通用户自己的密码即可(通过配置,甚至可以不用密码)
当然,普通用户拥有sudo的使用权,必须是管理员root事先通过审核,才能开放给普通用户的。(即,除非是信任用户,否则一般用户默认是不能操作sudo的)
3.8.2 sudo的配置
sudo的配置,其实就是修改/etc/sudoers文件里的信息
参考下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1aMnuJhA-1648392185128)(ClassNotes.assets/20190927192440.jpg)]
通过上图,可以看到,sudoers文件的权限即使是root,也是只有一个读权限。
3.8.2.1 修改该文件的方式
方式1:root用户直接vi /etc/sudoers 然后强制保存
方式2:直接输入牛掰哄哄的visudo
3.8.2.2 具体修改:我选择了牛掰哄哄的visudo
[root@qianfeng01 ~]# visudo
进入后,找到第100行和110行。
- 在100行的 root ALL=(ALL) ALL下面填写 ---配置这个,就可以使用sudo了。
scott ALL=(ALL) ALL
- 在110行的 #%whell ALL=(ALL) NOPASSWD:ALL下面填写 --配置这个,就可以不用再输入密码了
scott ALL=(ALL) NOPASSWD:ALL
-解析: scott ALL=(ALL) ALL
第一列:使用sudo的账号
第二列:客户端计算机主机名
第三列:可切换的身份
第四列:可使用的指令,注意使用具体指令时需要使用绝对路径,多个指令用逗号分开
参考下图:

四、软件管理机制
4.1 Linux软件管理介绍
有一个很好的软件生态圈支持,才是一个优秀、值得广泛使用的操作系统平台。比如PC端的window操作系统、mac操作系统,手机端的IOS系统,Android系统等。在这些操作系统上安装软件,方便的不能再方便了。都有类似的一键安装,方便用户进行操作。
当然,windows上的软件,五花八门,没有统一的妥善管理,漏洞就多。而手机端的操作系统,都有自己的应用商店来统一管理软件,通过审核的才会放入应用商店,相对来说,比较安全
当然,大名鼎鼎的Linux操作系统,也有自己的软件生态,也有自己的软件管理方式。
目前在Linux操作系统上,软件管理方式最常见的有两种,分别是:
- RPM
这个机制最早是由Red Hat这家公司开发出来的,后来实在很好用,因此很多distributions就使用这个机制来作为软件安装的管理方式。包括Fedora、CentOS、SuSE等知名的开发商。
- DPKG
这个机制最早是由Debian Linux社群所开发出来, 通过dpkg的机制,Debian提供的软件就能够简单的安装起来,同时还能提供安装后的软件信息,非常不错。只要是衍生自Debian的其他Lunix distributions大多使用了dpkg这个机制来管理软件的,包括B2D,ubuntu等。
注意了,注意了,注意了
不论rpm,还是dpkg,这些机制在安装软件时,或多或少都会碰到软体依赖的问题,比如软件A的安装依赖于软件B和C,而B的安装依赖于软件D和E,这些依赖信息,软件开发商都已经在每一个软件中提供了一个文档并记录在内,安装时,会进行检查平台上是否存在依赖的软件环境。如果存在,可以安装成功,如果不存在,那么就会进行友好提示,并终止安装。那该如何解决这样的依赖问题呢?
- 第一种方式:我们人工的一步一步的检测和安装所依赖的软件,直到依赖环境都存在。
- 第二种方式:就是使用一种自动管理机制,先获取依赖关系做成列表,查看平台是否已经存在所需要的环境,如果不存在,自动管理机制通过依赖关系,来获取所需要的软件,进行顺序安装,从而解决这样的问题。
针对于自动管理机制的思想,目前Linux系统开发商都有提供了这样的【在线升级】机制,并提供了相应的软件仓库,只要有网络,你就可以安装开发商提供的任何软件。dpkg管理机制提供了APT在线升级机制,RPM则依开发商的不同,有Red hat系统的yum,SuSE系统的Yast Online Update(YOU)等
| distributions代表 | 软件管理机制 | 使用指令 | 在线升级机制(指令) |
|---|---|---|---|
| Red Had/Fedora | RPM | rpm,rpmbuild | YUM(yum) |
| Debian /Ubuntu | DPKG | dpkg | APT(apt-get) |
4.2 二进制安装
4.2.1 简介
这样的软件包是已经将软件源码在不同的平台上进行事先编译,经过压缩打包的文件。 每一个安装包都有自己的平台。换一个不同的平台环境,失效。比较常用,优点:简单方便。 缺点:缺乏灵活性
二进制软件包提供了很多类型的打包方式,最常见的就是我们RPM格式的包,还有以“*.tar.gz、*.tgz、*.bz2“等形式的二进制软件包,最后还有一个就是提供安装程序进行安装的二进制软件包。下面演示jdk的安装
4.2.2 案例演示:JDK的安装
步骤1)上传jdk的二进制安装包 jdk-8u221-linux-x64.tar.gz,比如上传到/root/下
步骤2)解压jdk安装包
[root@qianfeng01 ~]# tar -zxvf ./jdk-8u221-linux-x64.tar.gz -C /usr/local
步骤3)切换到/usr/local下并更名
[root@qianfeng01 ~]# cd /usr/local
[root@qianfeng01 local]# mv jdk1.8.0_221/ jdk
步骤4)配置环境变量
环境变量的配置有三个位置可选,分别是以下三个位置
/etc/profile :系统级别的环境变量配置文件 所有用户都可以使用
~/.bash_profile :用户级别的环境变量配置文件 只对于一个用户好使
~/.bashrc :用户级别的环境变量配置文件 只对于一个用户好使
注意:真实环境中,我们应该选择用户级别的环境变量,这样的好处是,即使配错了,我们可以使用root账号来帮助修改。如果是系统级别的,配错了的话,root账号也不好使了,得另想办法,麻烦死了。
但是在学习期间,避免麻烦,直接配置系统级别的环境变量即可。
[root@qianfeng01 ~]#vim /etc/profile
........省略...................
# JDK environment
JAVA_HOME=/usr/local/jdk
PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
小贴士:原有的PATH值拼在新值的后面
步骤5)让环境变量生效(刷新环境变量)
[root@qianfeng01 ~]# source /etc/profile
步骤6)验证是否生效
[root@qianfeng01 ~]# java -version
[root@qianfeng01 ~]# javac
扩展:二进制软件包的安装还有执行程序式的安装,只需要运行安装指令后,跟着提示进行下一步下一步的操作即可。类似于windows平台上的软件安装界面。
4.3 rpm机制安装
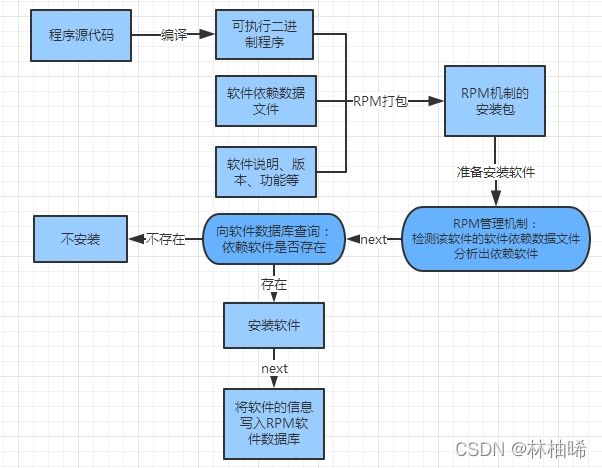
4.3.1 rpm安装原理
1. 下载好的rpm软件包里包含了软件程序,依赖关系文件,版本信息文件
2. 当启动安装操作时,会先根据依赖关系文件查找该平台上是否已经安装好了依赖的软件
3. 如果依赖的软件没有提前安装,则终止该软件的安装
4. 如果依赖的软件已经提前安装,则继续安装,直到成功。
参考下图:
注意:应用程序在使用rpm方式安装时,而该程序的核心文件会默认放置在下面的目录中
| 目录 | 说明 |
|---|---|
| /etc | 一些配置文档存储的目录,例如 /etc/ssh |
| /usr/bin | 一些可执行文件的目录 |
| /usr/lib | 一些程式使用的动态函数库 |
| /usr/share/doc | 一些基本的程序使用手册和说明文档 |
| /usr/share/man | 一些 man page 文档 |
| /var/lib/rpm | 程序相关的资讯信息,即资料库 |
注意:这里说明一下资料库,以后如果对软件升级,版本的比较信息就来源于这里,还有,我们可能会经常查询系统已经安装的程序,也是从这里进行查询的。
4.3.2 rpm指令的常用选项
1)查询选项
]# rpm -qa <==查询系统内已安裝程序
]# rpm -q【licdR】 【已安装的程序名】 <==查询系统内某个已安裝程序的信息
选项参数:
-q :用于查询指定的程序是否已经安装
-qa :列出所有已经安装在Linux系统下的程序名称
-qi :列出该程序的详细信息 ,如版本号,发行时间,安装时间等
-ql :列出该程序所有的文档与目录
-qc :列出该程序的所有配置文件 (通常是指在 /etc/ 底下的文件)
-qd :列出该程序的所有說明文档 (指与 man 有关的文件)
-qR :列出与该程序有关的依赖软件所含的文件 (Required 的意思)
-qf :找出指定文件属于哪一个已经安装的程序
案例测试:用python来测试
[root@qianfeng01 ~]# rpm -qa python
2)安装和卸载选项
基本语法:rpm [-ivh] 软件包名
-i :安装的含义
-v :安装过程中显示详情
-h :以进度条的形式显示安装进度
-e :卸载参数
--nodeps :安装或卸载软件时,有依赖关系时,可以进行强制安装或卸载。有一定的危险性,安装后可以能造成软件无法正常使用!
4.3.3 案例演示:rpm安装mysql
步骤1)上传mysql相关的软件包,比如上传到/root下
mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
步骤2)拆包
[root@qianfeng01 ~]# tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
[root@qianfeng01 ~]# ll
mysql-community-client-5.7.28-1.el7.x86_64.rpm
mysql-community-common-5.7.28-1.el7.x86_64.rpm
mysql-community-devel-5.7.28-1.el7.x86_64.rpm
mysql-community-embedded-5.7.28-1.el7.x86_64.rpm
mysql-community-embedded-compat-5.7.28-1.el7.x86_64.rpm
mysql-community-embedded-devel-5.7.28-1.el7.x86_64.rpm
mysql-community-libs-5.7.28-1.el7.x86_64.rpm
mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
mysql-community-server-5.7.28-1.el7.x86_64.rpm
mysql-community-test-5.7.28-1.el7.x86_64.rpm
小贴士: 其实我们是想安装mysql-community-server-5.7.28-1.el7.x86_64.rpm
步骤3)安装mysql
1. 先检查是否安装了mariadb, 如果已经安装,就卸载掉
[root@qianfeng01 ~]# rpm -qa | grep mariadb
mariadb-libs-5.5.64-1.el7.x86_64
[root@qianfeng01 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
2. 安装mysql-common
[root@qianfeng01 ~]# rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
3. 安装mysql-lib
[root@qianfeng01 ~]# rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
4. 安装mysql-client
[root@qianfeng01 ~]# rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
5. 安装mysql-server
[root@qianfeng01 ~]# rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
--------------------------到此为止,rpm安装完毕 -----------------------
mysql在linux中的服务项叫mysqld
6. 启动mysql的服务项mysqld
[root@qianfeng01 ~]# systemctl start mysqld
[root@qianfeng01 ~]# systemctl status mysqld 并查看
7. 查看mysql提供的默认密码,并复制, 注意,如果服务项启动失败,则不会产生mysqld.log文件
[root@qianfeng01 ~]# cat /var/log/mysqld.log | grep password
8. 登录mysql,并修改密码
[root@qianfeng01 ~]# mysql -uroot -p'9Pe%mQVcs-#<' 回车即可
.... 进入后,修改密码
mysql> alter user root@'localhost' identified by '@Mmforu45';
9. 如果想要远程连接该机器上的mysql server, 那么mysql server需要进行远程授权
mysql> grant all privileges on *.* to root@'%' identified by '@Mmforu45';
然后可以在windows启动navicat 远程连接linux上的mysql了。
4.4 yum在线安装机制
4.4.1 yum安装原理介绍
在使用rpm机制的时候,我们最闹心的地方,可能就是软件依赖问题了。而YUM机制恰恰帮助我们解决了这一问题。YUM,是Yellow dog Updater, Modified 的简称。YUM会通过分析rpm软件包内的预设参数,制定软件依赖的解决方法,然后自动处理软件依赖的问题。这样,在安装、升级或者是卸载时,用户就不必头疼这个依赖问题了。
图示YUM在线升级得原理和过程:
YUM服务器:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TdWzqEmC-1648392185130)(ClassNotes.assets/20181226150200643.png)]
YUM客户端
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IDwTSUac-1648392185131)(ClassNotes.assets/20181226150200663.png)]
安装流程
文字整理:
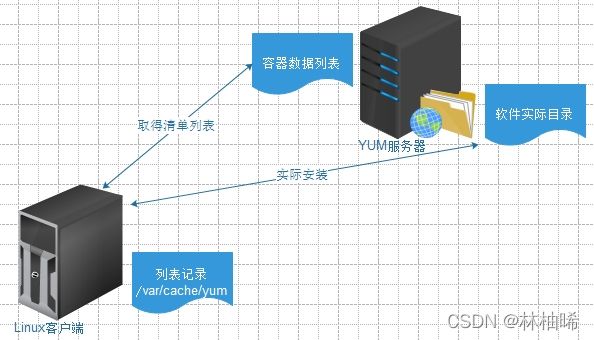
yum服务器: 存储了大量的现成的软件,并且维护着这些软件之间的依赖关系列表
安装流程: 机器在执行yum安装指令准备安装软件A时,会先向yum服务器发送请求,获取软件A的依赖关系列表,下载到本地,与本地的资料库做比较,如果本地的资料库缺少依赖关系中的某些软件,就会从yum服务器上获取所缺的依赖软件以及软件A,然后按照依赖顺序,开始安装。
yum服务器的地址存储在/etc/yum.repo.d/CentOS-Base.repo文件中
小贴士:yum在线安装底层应用的还是RPM机制安装,只不过帮助管理依赖软件的安装而已
4.4.2 YUM常用的查询功能
]# yum list all <==列出yum源仓库里面的所有可用的安装包
]# yum list installed <==列出所有已经安装的安装包
]# yum list available <==列出没有安装的安装包 ####安装软件
]# yum info [appName] <==查看软件的信息
]# yum search [keywords] <==根据关键字查找到相关安装包软件的信息
]# yum whatprovides [fileName] <==查找包含指定文件的相关安装包
4.4.3 YUM的安装/卸载功能
语法:yum [install | update| reinstall | remove ] [软件名称]
]# yum install appname <==安装指定的软件
]# yum reinstall appname <==重新安装指定的软件
]# yum update [appname] <==升级指定软件,不指定软件时,升级整个系统的软件
]# yum remove appname <==卸装指定的软件
4.4.4 案例演示:
以前安装过的:
yum -y install vim
yum -y install bzip2
yum -y install net-tools
现在:本地时间可能不准,那就需要和网络上的时间进行同步,那么可以使用ntpdate -u ntp1.aliyun.com进行同步。但是ntpdate指令不存在,需要安装。
yum -y install ntp
说明: ntp这款软件依赖于ntpdate和autogen, yum都会帮助提前下载并安装。
4.5 源码安装
由于linux操作系统开放源代码,因而在其上安装的软件大部分也都是开源软件,例如apache、tomcat、php等软件。开源软件基本都提供源码下载,源码安装的方式;
4.5.1 源码安装的优缺点
1)优点
1.用户可以自己定制软件功能,安装需要的模块,不需要的功能可以不用安装。
2.用户还可以自己选择安装路径,方便管理。
3.卸载软件也很方便,只需删除对应的安装目录即可。
4.能最大程度和服务器平台融合,效率稍微比其他方式高。
5.没有windows所谓的注册表之说。
2)缺点
1.安装较为繁琐,需要自己配置
2.安装较为耗时,需要自己编译源码
3.安装较为容易出错,出错也难以解决
4.5.2 案例演示:安装Nginx
1) 下载源码包,并解压到你喜欢的位置
[root@qianfeng01 ~]# tar -zxvf nginx-1.8.0.tar.gz -C /usr/local
2)进入该软件的家里
[root@qianfeng01 ~]# cd /usr/local/nginx-1.8.0
3)执行配置信息
注意:需要c语言环境提前安装好
[root@qianfeng01 ~]# yum -y install gcc-c++
[root@qianfeng01 ~]# yum install -y pcre pcre-devel
[root@qianfeng01 ~]# yum install -y zlib zlib-devel
[root@qianfeng01 ~]# yum install -y openssl openssl-devel
安装好环境后,在配置nginx的属性信息
[root@qianfeng01 nginx-1.8.0]# ./configure \
--prefix=/usr/local/nginx-1.8.0 \
--pid-path=/usr/local/nginx-1.8.0/tmp/nginx.pid
4)在家里执行编译指令
[root@qianfeng01 nginx-1.8.0]# make
5)在家里执行安装指令
[root@qianfeng01 nginx-1.8.0]# make install
如果出现了bin或者sbin目录,则表示安装成功。
6)清空缓存
[root@qianfeng01 nginx-1.8.0]# make clean
五、Linux的其他常用操作
5.1 虚拟机的克隆
步骤1)先克隆机器
先关掉要克隆的机器,然后
右键点击机器名称--->管理-->克隆-->虚拟机的当前状态-->创建完整克隆-->虚拟机名称--完成
步骤2)修改IP和主机名以及映射文件,然后重启
[root@qianfeng01 ~]# hostnamectl set-hostname qianfeng02
[root@qianfeng01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@qianfeng01 ~]# vim /etc/hosts
[root@qianfeng01 ~]# reboot
步骤3)测试是否可以通信
[root@qianfeng01 ~]# ping qianfeng02
[root@qianfeng02 ~]# ping qianfeng01
5.2 SCP指令
作用:用于远程拷贝文件
语法: scp [-r] filename.... 远程用户名@远程机器IP:pathname
案例演示:
[root@qianfeng01 ~]# echo "gaoyuanyuan is my friend" > nvshen.txt
eg1:将nvshen.txt文件以michael的身份拷贝到qianfeng02机器上的家里
[root@qianfeng01 ~]# scp nvshen.txt michael@qianfeng02:/home/michael/
eg2: 将nvshen.txt文件以root身份拷贝到qianfeng02机器上的家里
[root@qianfeng01 ~]# scp nvshen.txt root@qianfeng02:~/
eg3: 因为qianfeng02的root用户和当前机器的用户都是root。因此可以简写
[root@qianfeng01 ~]# scp nvshen.txt qianfeng02:~/
eg4: 如果拷贝的位置和当前位置一致,可以使用$PWD
[root@qianfeng01 ~]# scp nvshen.txt qianfeng02:$PWD
5.3 免密登录认证(重要)
5.3.1 准备工作
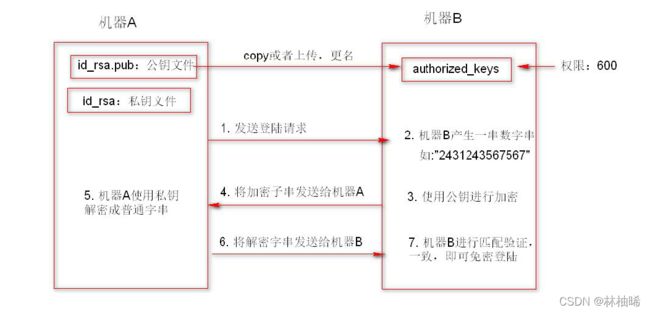
假如机器A想要免密登录机器B,那么需要提前在机器A上生成一对秘钥文件:公钥和私钥文件。而且机器A的公钥文件里的公钥信息还需要拷贝到机器B的连接用户的主目录下的隐藏目录.ssh/下的authoried_keys里
- 先在机器A上生成秘钥
[root@qianfeng01 ~]# ssh-keygen -t rsa 一路回车下去
说明:最后会在当前用户的家里的.ssh隐藏目录下产生两个文件
id_rsa: 私钥文件
id_rsa.pub : 公钥文件
2、将机器A的公钥信息,拷贝到机器B的相关用户的家里的隐藏目录.ssh下的authoried_keys里
注意:先确认机器B里是否有.ssh目录,如果没有需要提前创建
在机器B上,执行 ssh localhost, 就会产生.ssh目录
[root@qianfeng01 .ssh]# scp id_rsa.pub qianfeng02:~/.ssh/authoried_keys
5.3.2 免密登录认证的原理流程
认证原理(步骤):参考图中的1,2,3,4,5,6,7
5.3.3 准备工作的简化方式
1. 生成秘钥
[root@qianfeng01 ~]# ssh-keygen -t rsa 一路回车下去
2. 将公钥拷贝到远程机器上
[root@qianfeng01 ~]# ssh-copy-id -i qianfeng02
ssh-copy-id的作用:将公钥文件拷贝到远程机器的.ssh隐藏目录下,并更名成authorized_keys文件
问题:集群可能有多台机器,都要进行免密登录认证,如果每个机器都有自己的一套秘钥,拷贝赋值非常麻烦,所以这些机器可以用同一套秘钥。
1. 生成秘钥
[root@qianfeng01 ~]# ssh-keygen -t rsa 一路回车下去
2. 对自己进行免密登录认证
[root@qianfeng01 ~]# ssh-copy-id -i qianfeng01
3. 其他机器如果想要这一套钥匙,则需要拷贝id_rsa,id_rsa.pub,authorized_keys到相应的目录下
[root@qianfeng01 ~]# scp ~/.ssh/{id*,authorized_keys} qianfeng02:~/.ssh/
5.4 定时器crontab(熟悉)
5.4.1 crontab的简介
- 在Linux中,周期性的执行任务一般由cron这个守护进程来处理,它是一个linux下 的定时任务执行工具,可以在无需人工干预的情况下运行作业。
[ps -ef|grep cron]
- cron读取一个或多个配置文件,这些配置文件中包含了命令行及其调用时间。
- cron的配置文件称为“crontab”,是“cron table”的简写。
5.4.2 cron服务
systemctl start crond //临时启动服务
systemctl stop crond //临时关闭服务
systemctl restart crond //重启服务
systemctl disable crond //禁用启动项
systemctl enable crond //启动开启启动项
systemctl stutas crond //查看服务状态
5.4.3 cron的配置文件位置:
1. /var/spool/cron/
2. 说明这个目录下存放的是每个用户包括root的crontab任务,每个任务以创建者的名字命名,比如tom建的crontab任务对应的文件就是/var/spool/cron/tom。一般一个用户最多只有一个crontab文件。
5.4.4 crontab命令格式
作用:用于生成cron进程所需要的crontab文件
格式:crontab [-u username] -e
-u:用于指定其他用户的定时任务设置
5.4.5 查看定时器的格式
[root@qianfeng01 cron]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7)OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
即:
格式如下:
* * * * * user-name command to be executed
共有六部分组成,分别表示:
分 时 日 月 星期 要运行的命令
解析:
minute: 一小时中的哪一分钟 [0~59]
hour: 一天中的哪个小时 [0~23]
day: 一月中的哪一天 [1~31]
month: 一年中的哪一月 [1~12]
week: 一周中的哪一天 [0~6] 0表示星期天
commands: 执行的命令
书写注意事项
1.全都不能为空,必须填入,不知道的值使用通配符*表示任何时间
2.每个时间字段都可以指定多个值,不连续的值用,间隔,连续的值用-间隔。
3.命令应该给出绝对路径
4.用户必须具有运行所对应的命令或程序的权限
5. */num 表示频率
5.4.6 常用案例演示
1. 每天早上6点
0 6 * * * echo "Good morning." >> /tmp/test.txt
//注意 如果不进行追加 ,从屏幕上看不到任何输出,因为cron把任何输出都email到root的信箱了。
2. 每两个小时
0 */2 * * * echo "Have a break now." >> /tmp/test.txt
3. 晚上11点到早上8点之间每两个小时和早上八点
0 23-7/2,8 * * * echo "Have a good dream" >> /tmp/test.txt
4. 周一到周五下午,5点半提醒学生15分钟后关机
30 17 * * 1-5 /usr/bin/wall < /etc/issue
45 17 * * 1-5 /sbin/shutdown -h now
5. 学校的计划任务, 12点到14点,每两分钟,检查apache服务是否启动
*/2 12-14 * 3-6,9-12 1-5
6. 每月1、10、22日的4:45运行/apps/bin目录下的backup.sh
45 4 1,10,22 * * /apps/bin/backup.sh
7. 每周六、周日的 1 : 10运行一个find命令
10 1 * * 6,0 /bin/find -name "core" -exec rm {} \;
8. 在每天 18:00至23 :00之间每隔30分钟运行/apps/bin目录下的dbcheck.sh
0,30 18-23 * * * /apps/bin/dbcheck.sh
9.每星期六的 11:00 pm运行/apps/bin目录下的qtrend.sh
0 23 * * 6 /apps/bin/qtrend.sh
5.5 时间同步服务器的搭建
5.5.1 时间同步
在生产环境中的集群里,每台机器都有自己的时间,有的时候机器可能宕机,恢复后,时间不准确,也就是和其他机器时间不一致(不同步)。有些在集群上运行的作业对整个集群上所有机器的时间是有要求的,比如hbase集群要求所有机器的时间差不能超出30s。因此需要同步时间
5.5.2 如何同步时间
使用ntpdate指令进行同步时间,前提是只能同步时间服务器的时间。
用法: ntpdate -u timeserver
ntpdate -u ntp1.aliyun.com
网络上的常用时间服务器:
阿里云时间服务器:ntp1.aliyun.com
微软时间服务器:time.windows.com
如果ntpdate命令不存在,需要安装ntpdate.x86_64
[root@qianfeng01 ~]# yum -y install ntpdate.x86_64
如果生产环境中的集群没有连接外网,那么则需要搭建一个局域网的时间服务器
5.5.3 搭建局域网时间服务器
1. 选择集群中的某一台机器qianfeng01作为时间服务器
2. 保证这台服务器安装了ntp.x86_64。
[root@qianfeng01 ~]# yum list installed | grep ntp 查询
[root@qianfeng01 ~]# yum -y install ntp.x86_64
3. 保证ntpd 服务运行......(开机自启动)
[root@qianfeng01 ~]# systemctl start ntpd
[root@qianfeng01 ~]# systemctl enable ntpd
[root@qianfeng01 ~]# systemctl status ntpd
4. 配置相应文件:vi /etc/ntp.conf
......省略....
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap 添加集群中的网络段位
server 127.127.1.0 -qianfeng01作为服务器
注意:
-- 需要重启机器,或者重启服务
-- 服务器的防火墙要关闭
5. 其他机器要保证安装ntpdate.x86_64
6. 在其他机器上进行测试,是否可以同步
ntpdate -u qianfeng01
7. 其他机器要使用root定义定时器
*/1 * * * * /usr/sbin/ntpdate -u qianfeng01
5.6 YUM源的更换
本地的yum信息在/etc/yum.repo.d/下。
[root@qianfeng01 ~]# cd /etc/yum.repos.d/
[root@qianfeng01 yum.repos.d]# ll
总用量 32
-rw-r--r--. 1 root root 1664 9月 5 2019 CentOS-Base.repo
-rw-r--r--. 1 root root 1309 9月 5 2019 CentOS-CR.repo
-rw-r--r--. 1 root root 649 9月 5 2019 CentOS-Debuginfo.repo
-rw-r--r--. 1 root root 314 9月 5 2019 CentOS-fasttrack.repo
-rw-r--r--. 1 root root 630 9月 5 2019 CentOS-Media.repo
-rw-r--r--. 1 root root 1331 9月 5 2019 CentOS-Sources.repo
-rw-r--r--. 1 root root 6639 9月 5 2019 CentOS-Vault.repo
5.6.1 网络yum源的更换
由于CentOS系统默认的网络YUM源的地址是国外的,网速相对较慢,因此可以更换成国内的YUM源,比如阿里云、网易的等
这里选择更换成阿里云的yum源
步骤1)确保wget指令或者使curl指令存在
如果不在,就安装以下
yum -y install wget* curl*
步骤2)备份原有的yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
步骤3)下载新的 CentOS-Base.repo 到 /etc/yum.repos.d/
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
或者是:
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
步骤4)清理原有的缓存
yum clean all
步骤5)重新构建缓存
yum makecache
5.6.2 本地yum源的搭建
1.确保虚拟机连接了DVD.iso影像文件,开机后,此文件位于/dev/cdrom
2.创建挂载目录/mnt/dvd
[root@scott ~]# mkdir /mnt/dvd
3.将映像文件挂载到/mnt/dvd下, 软件都在Packages目录下
[root@scott ~]# cd /mnt/dvd
[root@scott dvd]# mount -t iso9660 /dev/cdrom -o loop /mnt/dvd
[root@scott dvd]# ll
-t:用来指定文件类型, 光盘的类型是:iso9660
-o: 用来指定挂载方式, loop 用来把一个文件当成硬盘分区挂接上系统
4.将原有的yum源设置为失效状态(修改后缀即可)
[root@scott Packages]# cd /etc/yum.repos.d/
[root@scott yum.repos.d]# rename .repo .repo.bak ./*.repo
解析:rename [要修改的扩展名] [修改后的扩展名] [源文件]
5.创建local.repo文件,配置本地yum源信息
[root@scott yum.repos.d]# vi local.repo
[local] <--- 资源库的唯一标识
name=local <--- 资源库的名字
baseurl=file:///mnt/dvd <-----------指向本地路径
gpgcheck=0 <-----------0表示禁止校验,1表示开启校验
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 <--- CentOS yum源的秘钥文件
enabled=1 <-----------0表示禁用本资源库,1表示开启本资源库
6.清空yum源缓存
[root@scott yum.repos.d]# yum clean all
7.查询yum源软件列表
[root@scott yum.repos.d]# yum list all
注意:重启机器后,需要重写挂载,也就是重新执行mount指令。
5.6.3 局域网yum源的搭建
步骤1)选择局域网内的一台机器作为YUM源服务器,安装HTTP服务进程
[root@qianfeng01 ~]# systemctl status httpd
[root@scott yum.repos.d]# yum -y install httpd.x86_64
步骤2)启动httpd服务项
[root@qianfeng01 ~]# systemctl start httpd
[root@qianfeng01 ~]# systemctl enable httpd
[root@qianfeng01 ~]# systemctl status httpd
步骤3)配置HTTP服务管理YUM源目录
# HTTP服务进程管理的目录是/var/www/html
#在管理目录下,创建软连接,指向YUM源目录
]# ln -s /mnt/dvd /var/www/html/repo <===都是用绝对路径,保没错
步骤4)其他机器只需要把自己本地YUM源的路径指向局域网YUM源地址即可
[root@qianfeng02 yum.repos.d]# rename .repo .repo.bak ./*.repo
[root@qianfeng02 yum.repos.d]# vi local.repo #编辑文件,后缀必须是.repo
[local] <===YUM源仓库名
name=localrepo <===昵称
baseurl=http://局域网IP/repo <===局域网YUM仓库位置
enabled=1 <===1 表示启用,0表示禁用
gpgcheck=1 <===1 表示 校验
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 <===校验钥匙
六、Linux的Shell脚本编程(重要)
6.1 shell的简介
shell其实指的是shell环境,是软件和OS之间的通信接口(软件的执行操作可以被shell翻译成OS识别的指令,从而进行调度硬件进行工作)。shell相对于os是独立的接口,linux上有多种shell接口,比如/bin/sh,/bin/bash,/usr/bin/sh,/usr/bin/bash,用户可以选择任意一个作为环境接口与OS进行通信调度。
参考图片
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vQ4DiYDL-1648392185133)(ClassNotes.assets/1586261642060.png)]
查看系统中有哪些shell可以使用
[root@qianfeng01 ~]# cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
查看当前Linux正在使用的shell环境
[root@qianfeng01 ~]# echo $SHELL
/bin/bash
shell环境(shell命令解释器)有很多功能:比如
1、命令记忆功能
2、命令和文件名补全功能
3、命令别名设置功能
4、作业控制、前台、后台切换功能
5、通配符功能
6、编程语言功能
在公司或者生产环境中所说shell脚本指的就是shell的其中一个强大功能而已。即它支持多种编程语言里常见的特征,比如分支和循环结构,函数,变量和数组等这些编程语法。并且一旦掌握后它将成为你的得力工具。只要能在提示符界面上输入的命令都能放到一个可执行的shell程序里,这意味着用shell语言能简单地重复执行某一任务。
6.2 shell脚本的编程规范
1)shell脚本文件编写的规范
1. 文件名的扩展名是*.sh
2. 文件里的第一行是用来指定使用哪一种shell环境来解析本文件
eg:
#!/bin/bash <---必须#!开头 shell环境写绝对路径
3. 空行会被忽略
4. #用来注释, 必须在行首
5. 命令 选项 参数之间如果有多个空格,会被解析成一个空格
6. tab键形成的空白,也被解析成一个空格。
2)如何运行脚本文件
方式1: 使用bash或sh指令 调度脚本文件
[root@qianfeng01 ~]# bash test1.sh
[root@qianfeng01 ~]# sh test1.sh
方式2:直接写脚本文件的绝对路径或者是相对路径,相对路径时必须添加./ 该文件必须有rx权限
[root@qianfeng01 ~]# /root/test1.sh
[root@qianfeng01 ~]# ./test1.sh
方式3:当脚本用于rw权限后,可以借助PATH环境变量里的一个路径来使用
[root@qianfeng01 ~]# mkdir ~/bin
[root@qianfeng01 ~]# mv ./test1.sh ~/bin
[root@qianfeng01 ~]# test1.sh <------会被当成命令直接使用
因为Linux会为每一个登录用户在PATH环境变量中维护一个~/bin目录,实际上该目录不存在,属于提前维护的。
6.3 shell脚本的变量
6.3.1 变量的应用规范
1)命名规范
- 由字母,数字,_组成,但是数字不能作为开头字符
- 字母习惯使用大写。
- 中间不能有空格。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)
2)使用规范
- 直接定义变量名称,没有类型需要强调(类似于数学中:x=1,y=2,z=x+y)
- 赋值时,"="前后不能有空格
- 命令的执行结果赋值给变量时,使用反单引号 如:TIME=`date`
- 调用变量时,必须使用$ 格式: $变量名 或 ${变量名}
小贴士: 反单引号也可以使用$() 比如 `date` 也可以写成 $(date)
6.3.2 变量的分类
shell脚本中的变量可以分局部变量、环境变量、位置变量、特殊意义的变量。
/etc/profile
1)局部变量
定义的变量只能在当前程序中使用,不能在其他程序中使用,如子程序
[root@qianfeng01 ~]# NAME=GAOYUANYUAN # 在当前shell程序中定义一个NAME变量
[root@qianfeng01 ~]# echo $NAME
GAOYUANYUAN
[root@qianfeng01 ~]# bash # 进入子程序(也就是另起一个shell程序)
[root@qianfeng01 ~]# echo $NAME # 子程序中NAME是没有值的,也就是未定义
[root@qianfeng01 ~]# exit # 退出子程序
exit
[root@qianfeng01 ~]# echo $NAME
GAOYUANYUAN
[root@qianfeng01 ~]# vim ./bin/test1.sh
#!/bin/bash
NAME=zhangjingchu
city=shenzhen
echo $NAME $city #打印变量的值
NAME=CANGLAOSHI #变量重新赋值
CITY=GUANGZHOU #新变量CITY,
echo $NAME $city $CITY # 证明变量名是区分大小写的
只读变量和删除变量
[root@qianfeng01 ~]# NAME='zhaoyouting'
[root@qianfeng01 ~]# echo $NAME
zhaoyouting
[root@qianfeng01 ~]# readonly NAME #设置成只读变量
[root@qianfeng01 ~]# echo $NAME
zhaoyouting
[root@qianfeng01 ~]# NAME='JIAJINGWEN' #只读变量不能被再次赋值
bash: NAME: 只读变量
[root@qianfeng01 ~]# address='changchun'
[root@qianfeng01 ~]# echo $address
changchun
[root@qianfeng01 ~]# unset address #删除变量
[root@qianfeng01 ~]# echo $address
[root@qianfeng01 ~]# unset NAME #只读变量不能被删除
bash: unset: NAME: 无法反设定: 只读 variable
2)环境变量
当前程序中定义的变量,其他程序中也可以使用,我们就称之为环境变量
[root@qianfeng01 ~]# export name='canglaoshi' # 定义局部变量,并导出成环境变量
[root@qianfeng01 ~]# bash #进入子程序
[root@qianfeng01 ~]# echo $name # 打印变量,发现有值。
canglaoshi
[root@qianfeng01 ~]# address='beijing' #定义局部变量
[root@qianfeng01 ~]# export address #将局部变量导出成环境变量
[root@qianfeng01 ~]# bash #进入子程序
[root@qianfeng01 ~]# echo $address # 打印变量,发现有值。
beijing
如何检查系统的环境变量
[root@qianfeng01 ~]# export
或
[root@qianfeng01 ~]# env
3)位置变量
linux系统为命令行提供了特殊的位置变量$num ,num是从0开始的连续自然数。
[root@qianfeng01 ~]# vim bin/test2.sh
#!/bin/bash
echo $0
echo $1
echo $2
echo $4
[root@qianfeng01 ~]# chmod 700 bin/test2.sh
测试脚本
[root@qianfeng01 ~]# test2.sh gaoyuanyuan 贾静雯 苏有朋 李小冉
/root/bin/test2.sh
gaoyuanyuan
贾静雯
李小冉
注意: $0 指的是命令,$1开始的值称之为位置参数
$10会被解析成$1和0的无缝拼接,因此想要表达10位置的参数,需要将数字使用大括号括起来${10}
.........$11-->${11}
4)特殊意义的变量
$* : 将命令行上的所有位置参数当成一个字符串整体看待,即以"$1 $2 … $n"的形式输出所有参数
$@ : 将命令行上的所有位置参数区分看待,即每一个参数都是一个字符串
$# : 位置参数的个数
$? : 上一个命令执行的结果。0表示成功,其他值表示失败,值的范围为0~255
$$ : 当前进程的PID值
$! : 后台进程的最后一个进程的PID
测试:
[root@qianfeng01 ~]# vim bin/test3.sh
#!/bin/bash
echo '$0的值:'$0
echo "第一个位置参数:"$1
echo '$*的值:'$*
echo '$@的值:'$@
echo '$#的值(参数个数):'$#
echo '$?的值:'$?
echo '$$的值(当前进程PID):'$$
echo '$!的值(后台进程最后一个进程的PID):'$!
[root@qianfeng01 ~]# chmod 700 bin/test3.sh
[root@qianfeng01 ~]# test3.sh 1 2 3 4 5 6 7 8 9
$0的值:/root/bin/test3.sh
第一个位置参数:1
$*的值:1 2 3 4 5 6 7 8 9
$@的值:1 2 3 4 5 6 7 8 9
$#的值(参数个数):9
$?的值:0
$$的值(当前进程PID):3306
$!的值(后台进程最后一个进程的PID):
6.4 三个常用的指令
6.4.1 read指令
在这之前,变量的值都是直接被指定的。而read命令,可以让变量接收键盘录入的数据。这就好比Java语言的Scanner类型,可以开启键盘录入功能。read功能常用与shell script中。
格式: read [选项] variable
选项解析:
-p:用于指定提示信息
-n:规定录入字符串长度,达到此长度,自动结束
-t :对录入进行时间限制,单位是秒
-s:隐藏输入的数据
案例演示
[root@qianfeng01 ~]# read -p "请输入用户名:" user
请输入用户名:gaoyuanyuan
[root@qianfeng01 ~]# echo $user
gaoyuanyuan
[root@qianfeng01 ~]# read -p "请输入用户名:" -n 8 user #达到8个长度,自动结束
请输入用户名:gaoyuany
[root@qianfeng01 ~]# echo $user
gaoyuany
[root@qianfeng01 ~]# read -p "请输入用户名:" -n 8 -t 5 user #超过5秒自动结束,但是变量没有值
请输入用户名:aaa
[root@qianfeng01 ~]# echo $user
[root@qianfeng01 ~]# read -p "请输入密码:" -n 8 -s password
请输入密码: <---- 不显示输入的内容
[root@qianfeng01 ~]# echo $password
123123
6.4.2 expr指令
这个命令可以对整数表达式进行运算。注意,运算符前后必须要有空格符
[root@qianfeng01 ~]# expr 1 + 2
3
[root@qianfeng01 ~]# result=`expr 1 + 2`
[root@qianfeng01 ~]# echo $result
3
[root@qianfeng01 ~]# result=$(expr 1 + 2)
[root@qianfeng01 ~]# echo $result
3
[root@qianfeng01 ~]# expr 1 + `expr 2 + 3` # 嵌套一层expr
6
[root@qianfeng01 ~]# expr 2 \* 3 # 乘法运算,*需要转义字符
6
[root@qianfeng01 ~]# n=3
[root@qianfeng01 ~]# m=2
[root@qianfeng01 ~]# result=`expr 1 + \`expr $n + $m\`` #反单引号里的反单引号需要转义
[root@qianfeng01 ~]# echo $result
6
6.4.3 test指令
-
通常test命令不单独使用,而是与if语句连用,或者是放在循环结构中。
-
判断符号[]
除了好用的test外,我们还可以使用中括号来进行检测条件是否成立。举例说明
[ -r filename ] : 检测filename是否有可读权限 [ -f filename -a -r filename ] : 检测filename是不是普通文件并且有可读权限
6.5 shell的字符串类型
6.5.1 字符串的基本用法
- 字符串不能单独,必须要配合变量。
- 字符串可以使用单引号,也可以使用双引号,也可以不用引号
- 单引号内的任何字符没有任何意义,都会原样输出, echo 'hello $name world'
- 单引号内使用变量是无效的,单引号内不能出现单引号
- 双引号内可以使用变量 echo "hello $name world"
- 双引号内可以使用转义字符 echo -e "hello\\nworld"
- 在字符串拼接操作时,我们可以进行无缝拼接,或者是在双引号里使用变量
echo "第一个位置参数是"$1
echo "第一个位置参数是$1"
6.5.2 字符串的长度
可以使用
${#variable}
或者
expr length "${variable}"。
如果给其他变量赋值,注意expr 应该使用反单引号或者$()
直接看案例:
[root@qianfeng01 ~]# name=gaoyuanyuan
[root@qianfeng01 ~]# echo ${#name}
11
[root@qianfeng01 ~]# expr length ${name}
11
[root@qianfeng01 ~]# expr length "${name}"
11
[root@qianfeng01 ~]# len=`expr length ${name}`
[root@qianfeng01 ~]# echo $len
11
6.5.3 子字符串的截取
字符串的下标从0开始。而截取有如下写法:
${variable:startIndex} : 从startIndex下标开始,截取到最后
${variable:startIndex:length} : 从startIndex下标开始,截取length个长度
${variable:0-num} : 倒数第num个开始,截取到最后
${variable:0-num:length} : 倒数第num个开始,截取length个长度
测试:
[root@qianfeng01 ~]# vim bin/test4.sh
#!/bin/bash
url="http://www.baidu.com"
substr=${url:4}
echo $substr
substr=${url:4:4}
echo $substr
substr=${url:0-4}
echo $substr
substr=${url:0-6:4}
echo $substr
[root@qianfeng01 ~]# bash bin/test4.sh
://www.baidu.com
://w
.com
du.c
6.6 shell的数组类型
6.6.1 Array的使用规则
- 在/bin/bash这个shell中,只有一维数组的概念,并且不限定数组的长度。
- 数组的元素下标是从0开始的,
- 获取数组的元素要使用下标
- 下标使用不当,会报错
6.6.2 Array的定义
定义格式: variable=(值1 值2 … 值n)
注意:元素之间除了使用空格作为分隔符,还可以使用换行符。
或者
name[0]=值1
name[1]=值2
…
name[n]=值n
6.6.3 读取数组
${variable[index]}: 读取index索引上的元素
${variable[*]}或者${variable[@]}:读取所有元素
${#variable[*]}或者${#variable[@]} : 读取数组的长度
案例演示1:
[michael@master ~]$ vim bin/test5.sh
#!/bin/bash
name=(gaoyuanyuan liuyifei zhangjunning)
address=(changchun #分隔符为换行
beijing
shanghai
shenzhen)
hobby[0]='eat'
hobby[1]='sleep'
hobby[3]='play'
echo ${name[0]}
echo ${address[*]}
echo ${address[@]}
echo ${#address[*]}
echo ${#hobby[@]}
[michael@master ~]$ bash bin/test5.sh
gaoyuanyuan
changchun beijing shanghai shenzhen
changchun beijing shanghai shenzhen
4
3
案例演示2:下标的应用
[root@qianfeng01 ~]# names=(1 2 3) #定义三个长度的数组
[root@qianfeng01 ~]# echo ${names[0]}
1
[root@qianfeng01 ~]# echo ${names[1]}
2
[root@qianfeng01 ~]# echo ${names[2]}
3
[root@qianfeng01 ~]# echo ${names[3]} #打印第四个元素,数组中没有第四个,不会报错
[root@qianfeng01 ~]# echo ${names[-1]} #打印数组中的倒数第一个元素
3
[root@qianfeng01 ~]# echo ${names[-2]}
2
[root@qianfeng01 ~]# echo ${names[-3]}
1
[root@qianfeng01 ~]# echo ${names[-4]} # 打印数组中的倒数第四个元素,不存在,则报错
bash: names: 坏的数组下标
6.7 shell的分支结构
6.7.1 if分支
1)一条分支的写法:
if [ 条件 ] ;then
执行逻辑
fi
2)带else的写法
if [ 条件 ] ;then
执行逻辑
else
执行逻辑
fi
3)多分支的写法
if [ 条件 ] ;then
执行逻辑
elif [ 条件 ];then
执行逻辑
else
执行逻辑
fi
注意:条件后面应该有一个分号 将 条件和then关键字隔开。如果不想加分号,then需要换行书写。
案例演示:
[root@qianfeng01 ~]# vim bin/test6.sh
#!/bin/bash
m=10
n=20
if [ $m -lt $n ]
then
echo "m>n"
fi
read -p '请给x赋一个整数:' x
read -p '请给y赋一个整数:' y
if [ $x -gt $y ];then
echo "x>y"
else
echo "x
fi
echo '-----------------[] 换成 (()) 可以使用 大于号,小于号等----------------'
# 如果想要在条件中使用>,<这类的符号,可以将条件外的中括号换成双层小括号, $也可以省略不写
read -p '请给a赋一个整数:' a
read -p '请给b赋一个整数:' b
if (( a >= b ));then
echo "a>=b"
else
echo "a
fi
echo '-----------------多分支的测试----------------'
read -p '请给c赋一个整数:' c
read -p '请给d赋一个整数:' d
if [ $c -gt $d ];then
echo "c>d"
elif [ $c -eq $d ];then
echo "c=d"
else
echo "c
fi
测试:
[root@qianfeng01 bin]# bash test6.sh
m>n
请给x赋一个整数:10
请给y赋一个整数:20
x<y
-----------------[] 换成 (()) 可以使用 大于号,小于号等----------------
请给a赋一个整数:4
请给b赋一个整数:5
a<b
-----------------多分支的测试----------------
请给c赋一个整数:2
请给d赋一个整数:2
c=d
6.7.2 case分支
也可以利用case…in语句,进行匹配,选择匹配成功的那块进行作业,语法如下
case ... in
value1)
执行逻辑
;;
value2)
执行逻辑
;;
value3)
执行逻辑
;;
.......
valueN)
执行逻辑
;;
esac
案例演示:
[root@qianfeng01 ~]# vim bin/test7.sh
#!/bin/bash
case $1 in
start)
echo "这是要启动一个服务项"
;;
status)
echo "查看服务项的状态"
;;
stop)
echo "临时停止一个服务项"
;;
*)
echo "您输入了其他不存在的选项"
;;
esac
小贴士: 最后一个分支匹配,用通配符*,表示不满足之前的所有分支,相当于default分支。
测试:
[root@qianfeng01 bin]# bash test7.sh start
这是要启动一个服务项
[root@qianfeng01 bin]# bash test7.sh stop
临时停止一个服务项
[root@qianfeng01 bin]# bash test7.sh enable
[root@qianfeng01 bin]# vim test7.sh
[root@qianfeng01 bin]# bash test7.sh enable
您输入了其他不存在的选项
[root@qianfeng01 bin]# bash test7.sh 1
您输入了其他不存在的选项
6.8 shell的循环结构
6.8.1 while循环结构
语法如下: 当条件成立时,继续执行循环内容
while [ 条件表达式 ]
do
#作业内容
done
案例演示:
#!/bin/bash
echo "---------打印10次hello shell-----------"
count=0
while [ $count -lt 10 ]
do
echo "hello shell"
#count=`expr $count + 1`
#count=$(expr $count + 1)
#count=$[ $count + 1 ]
#count=$[count+1]
let count++
done
echo "-----------计算1~100以内的所有的奇数之和-----------------------"
num=1
sum=0
while [ $num -lt 100 ]
do
if [ $[$num % 2] -ne 0 ];then
sum=$[sum+num]
fi
let num++
done
echo "奇数和为:"$sum
测试:
[root@qianfeng01 bin]# bash test8.sh
---------打印10次hello shell-----------
hello shell
hello shell
hello shell
hello shell
hello shell
hello shell
hello shell
hello shell
hello shell
hello shell
-----------计算1~100以内的所有的奇数之和-----------------------
奇数和为:2500
6.8.2 until循环结构
until循环结构:当条件成立时,就终止循环,条件不成立时,就一直循环下去。
until [ 条件表达式 ]
do
#作业内容
done
练习:
[root@qianfeng01 ~]# vim bin/test9.sh
#!/bin/bash
read -p "请输入密码:" password
count=0
until [ $password == "123456" ]
do
if [ $count -eq 4 ]; then
echo "密码错误超过5次,自动退出"
break
fi
let count++
read -p "请重新输入密码:" password
done
echo "--------over---------"
测试:
[root@qianfeng01 bin]# bash test9.sh
请输入密码:111
请重新输入密码:1111
请重新输入密码:111
请重新输入密码:111
请重新输入密码:123456
--------over---------
6.8.3 for循环结构
语法:
for 变量 in 列表
do
执行逻辑
done
列表的表示方式:
方式1: 使用空格隔开的一堆数据,比如
monday tuesday wenseday thursday friday saturday sunday
方式2: 命令的返回结果为多行或多列的情况
ls ~
方式3: 使用命令seq返回列表,语法:seq n1 n2 表示产生一个从n1到n2的自然数列表
也可以使用{n1..n2}的这种写法
方式4: cut指令的用法: cut -d '分隔符' -fn filename
用来切分文件中的每一行的数据,使用分隔符切分,-fn中的n是获取第n列的意思
案例演示:
[root@qianfeng01 bin]# vim ~/bin/test10.sh
#!/bin/bash
sum=0
for num in 1 2 3 4 5 6 7 8
do
sum=$[ sum + num]
done
echo "sum的值为$sum"
echo "----------命令产生的列表---------"
for filename in $(ls /)
do
echo "文件名:"$filename
done
for num in $(seq 1 10)
do
echo "num的值为:$num"
done
for column in $(cut -d ":" -f1 /etc/passwd)
do
echo $column >> /root/bin/result.txt
done
echo "--------seq命令的一种简化方式列表------------"
for num in {1..10}
do
echo "num的值为$num"
done
测试:
[root@qianfeng01 bin]# bash test10.sh
sum的值为36
----------命令产生的列表---------
文件名:bin
文件名:boot
文件名:dev
文件名:etc
文件名:home
文件名:lib
文件名:lib64
文件名:media
文件名:mnt
文件名:opt
文件名:proc
文件名:root
文件名:run
文件名:sbin
文件名:srv
文件名:sys
文件名:tmp
文件名:usr
文件名:var
num的值为:1
num的值为:2
num的值为:3
num的值为:4
num的值为:5
num的值为:6
num的值为:7
num的值为:8
num的值为:9
num的值为:10
--------seq命令的一种简化方式列表------------
num的值为1
num的值为2
num的值为3
num的值为4
num的值为5
num的值为6
num的值为7
num的值为8
num的值为9
num的值为10
扩展:for循环还有另外一种写法,适合在数值的处理上使用
语法如下:
for ((变量初始化;循环条件;变量的改变))
do
执行逻辑
done
练习:
[root@qianfeng01 ~]# vim ~/bin/test11.sh
#!/bin/bash
sum=0
for ((num=0;num<=100;num+=2))
do
sum=$[sum+num]
done
echo "sum的值为$sum"
6.8.4 select表单循环
有的时候,需要将一些数据设置成表单的模式,供用户来选择。我们就可以使用select表单循环结构
语法:
select variable in 列表
do
#作业内容
done
案例演示:
[root@qianfeng01 ~]# vim ~/bin/test12.sh
#!/bin/bash
select var in monday tuesday wenseday thursday friday saturday sunday
do
echo "your option is $var"
if [ $var == "sunday" ];then
break
fi
done
[root@qianfeng01 ~]# sh ~/bin/test12.sh
1) monday 3) wenseday 5) friday 7) sunday
2) tuesday 4) thursday 6) saturday
#? 2
your option is tuesday
#? 1
your option is monday
#? 2
your option is tuesday
#? 7
your option is sunday #然后退出
6.8.4 shift指令的应用
shift这个单词,在计算机中,有“使数据产生位移”的含义。对于linux系统来说,在shell中,shift命令可以使参数产生位移。我通过案例来给大家解释一下:
[root@qianfeng01 bin]# vim ~/bin/test13.sh
#!/bin/bash
echo "all parameters ========>: $@"
echo "the first parameters ==>: $1"
echo "---------------------黄金分割线---------------------------"
shift
echo "all parameters ========>: $@"
echo "the first parameters ==>: $1"
echo "---------------------黄金分割线---------------------------"
shift
echo "all parameters ========>: $@"
echo "the first parameters ==>: $1"
echo "---------------------黄金分割线---------------------------"
shift
echo "all parameters ========>: $@"
echo "the first parameters ==>: $1"
测试如下:
[root@qianfeng01 bin]# bash test13.sh a b c d e f
all parameters ========>: a b c d e f
the first parameters ==>: a
---------------------黄金分割线---------------------------
all parameters ========>: b c d e f
the first parameters ==>: b
---------------------黄金分割线---------------------------
all parameters ========>: c d e f
the first parameters ==>: c
---------------------黄金分割线---------------------------
all parameters ========>: d e f
the first parameters ==>: d
案例:计算所有的位置参数之和
[root@qianfeng01 bin]# vim ~/bin/test14.sh
#!/bin/bash
sum=0
until [ "$1" == "" ]
do
sum=`expr $sum + $1 `
shift #使参数向左移动
done
echo "sum:$sum"
测试如下:
[root@qianfeng01 bin]# bash test14.sh 1 2 3 4 5 6 7 8
sum:36
6.9 shell的函数
语法:
function funcName(){
}
语法解析:
1、关键字function 可加可不加
2、调用时,直接写函数名称,不添加()。
3、因为script是从上往下,从左往右执行的,所以,要先定义,后调用
4、return关键字,可加可不加,看需求
加的话,返回值只能是0~255的整数,使用$?获取返回值
6、可以使用$n位置参数变量向函数里传值
案例1:
[root@qianfeng01 bin]$ vim test15.sh
#!/bin/bash
function sum(){
a=0
for i in {1..100}
do
a=$[a+i]
done
echo "1~100 的和:$a"
}
sum # 调用函数sum
[root@qianfeng01 bin]$ bash test15.sh
1~100 的和:5050
[root@qianfeng01 bin]$ source test15.sh #另外一种执行方式
1~100 的和:5050
#因为test.sh已经被source指令引入到当前shell环境中,因此可以直接将函数当成命令进行使用,很方便吧
[root@qianfeng01 ~]$ sum
1~100 的和:5050
案例2:
[root@qianfeng01 bin]$ vim test16.sh
#!/bin/bash
#定义函数func2
func2(){
result=$[ $1 + $2 ]
echo "result的值为$result"
# 使用return 书写返回值
return $result
}
#调用函数,并指定位置参数,调用函数其实就相当于在命令行上操作,函数名后的就是位置参数
func2 100 156
echo "func2的返回值为$?"
测试如下:
[root@qianfeng01 bin]# bash test16.sh
result的值为256
func2的返回值为0 <===因为 100+156 为256 超出255,开始从0循环,相当于蛇头药蛇尾,转圈了
[root@qianfeng01 bin]# source test16.sh #引入当前shell环境中
result的值为256
func2的返回值为0
[root@qianfeng01 bin]# func2 100 157 #直接测试func2
result的值为257
[root@qianfeng01 bin]# echo $? #获取func2的返回值
1
[root@qianfeng01 bin]# func2 100 158 #再测试func2
result的值为258
[root@qianfeng01 bin]# echo $? #再获取func2的返回值
2
6.10 脚本之间的引入
即在一个脚本中,使用另外一个脚本,调用方式如下:
. filename
或
source filename
案例演示:
[root@ qianfeng01 ~]# vim ~/bin/test17.sh
#!/bin/bash
function f1(){
echo "hello,welcome to china"
}
[root@ qianfeng01 ~]# vim ~/bin/test18.sh
#!/bin/bash
source /root/bin/test17.sh
# 或者
# . /root/bin/test17.sh
echo "micheal"
f1
测试如下:
[root@ qianfeng01 ~]# vim ~/bin/test18.sh
micheal
hello,welcome to china
6.11 脚本的调试方式
#!/bin/bash
a=$1
set -x
b=3
echo "b:"+$b
c=$a
echo $a
bash -x test19.sh 10
[root@qianfeng01 bin]# bash -x test19.sh 10
+ a=10
+ b=3
+ echo b:3
b:3
+ c=10
+ echo 10
10
-x的作用:可以将每一行中的$变量 替换成具体的值,进行显示
bash -n test19.sh
作用:不执行脚本里的逻辑,只检查脚本中的语法是否有错误。如果有,就打印错误
bash -v test10.sh
-v的作用,就是打印脚本里的所有信息到屏幕上,相当于cat指令查看
set -x 可以书写到脚本中
作用:调试set -x 以下的脚本内容,之前的内容正常
=>: $1"
echo “---------------------黄金分割线---------------------------”
shift
echo “all parameters ========>: $@”
echo “the first parameters ==>: $1”
echo “---------------------黄金分割线---------------------------”
shift
echo “all parameters ========>: $@”
echo “the first parameters ==>: $1”
测试如下:
[root@qianfeng01 bin]# bash test13.sh a b c d e f
all parameters ========>: a b c d e f
the first parameters ==>: a
---------------------黄金分割线---------------------------
all parameters ========>: b c d e f
the first parameters ==>: b
---------------------黄金分割线---------------------------
all parameters ========>: c d e f
the first parameters ==>: c
---------------------黄金分割线---------------------------
all parameters ========>: d e f
the first parameters ==>: d
案例:计算所有的位置参数之和
```shell
[root@qianfeng01 bin]# vim ~/bin/test14.sh
#!/bin/bash
sum=0
until [ "$1" == "" ]
do
sum=`expr $sum + $1 `
shift #使参数向左移动
done
echo "sum:$sum"
测试如下:
[root@qianfeng01 bin]# bash test14.sh 1 2 3 4 5 6 7 8
sum:36
6.9 shell的函数
语法:
function funcName(){
}
语法解析:
1、关键字function 可加可不加
2、调用时,直接写函数名称,不添加()。
3、因为script是从上往下,从左往右执行的,所以,要先定义,后调用
4、return关键字,可加可不加,看需求
加的话,返回值只能是0~255的整数,使用$?获取返回值
6、可以使用$n位置参数变量向函数里传值
案例1:
[root@qianfeng01 bin]$ vim test15.sh
#!/bin/bash
function sum(){
a=0
for i in {1..100}
do
a=$[a+i]
done
echo "1~100 的和:$a"
}
sum # 调用函数sum
[root@qianfeng01 bin]$ bash test15.sh
1~100 的和:5050
[root@qianfeng01 bin]$ source test15.sh #另外一种执行方式
1~100 的和:5050
#因为test.sh已经被source指令引入到当前shell环境中,因此可以直接将函数当成命令进行使用,很方便吧
[root@qianfeng01 ~]$ sum
1~100 的和:5050
案例2:
[root@qianfeng01 bin]$ vim test16.sh
#!/bin/bash
#定义函数func2
func2(){
result=$[ $1 + $2 ]
echo "result的值为$result"
# 使用return 书写返回值
return $result
}
#调用函数,并指定位置参数,调用函数其实就相当于在命令行上操作,函数名后的就是位置参数
func2 100 156
echo "func2的返回值为$?"
测试如下:
[root@qianfeng01 bin]# bash test16.sh
result的值为256
func2的返回值为0 <===因为 100+156 为256 超出255,开始从0循环,相当于蛇头药蛇尾,转圈了
[root@qianfeng01 bin]# source test16.sh #引入当前shell环境中
result的值为256
func2的返回值为0
[root@qianfeng01 bin]# func2 100 157 #直接测试func2
result的值为257
[root@qianfeng01 bin]# echo $? #获取func2的返回值
1
[root@qianfeng01 bin]# func2 100 158 #再测试func2
result的值为258
[root@qianfeng01 bin]# echo $? #再获取func2的返回值
2
6.10 脚本之间的引入
即在一个脚本中,使用另外一个脚本,调用方式如下:
. filename
或
source filename
案例演示:
[root@ qianfeng01 ~]# vim ~/bin/test17.sh
#!/bin/bash
function f1(){
echo "hello,welcome to china"
}
[root@ qianfeng01 ~]# vim ~/bin/test18.sh
#!/bin/bash
source /root/bin/test17.sh
# 或者
# . /root/bin/test17.sh
echo "micheal"
f1
测试如下:
[root@ qianfeng01 ~]# vim ~/bin/test18.sh
micheal
hello,welcome to china
6.11 脚本的调试方式
#!/bin/bash
a=$1
set -x
b=3
echo "b:"+$b
c=$a
echo $a
bash -x test19.sh 10
[root@qianfeng01 bin]# bash -x test19.sh 10
+ a=10
+ b=3
+ echo b:3
b:3
+ c=10
+ echo 10
10
-x的作用:可以将每一行中的$变量 替换成具体的值,进行显示
bash -n test19.sh
作用:不执行脚本里的逻辑,只检查脚本中的语法是否有错误。如果有,就打印错误
bash -v test10.sh
-v的作用,就是打印脚本里的所有信息到屏幕上,相当于cat指令查看
set -x 可以书写到脚本中
作用:调试set -x 以下的脚本内容,之前的内容正常