一点就分享系列(实践篇4-上篇)深度学习部署之Tensorrt转换思路:“授人与鱼不如授人与渔”
Tensorrt模型转换使用思路: “授人与鱼不如授人与渔”
最近做完了C++部署后,回过头来搞了几天模型转换,这一部分操作我之前只是当作工具最快时间搞定就不管了(内心还是渴望做研究的)之前大家做部署时候在转换时候用ONNX遇到不少坑,去年参考了wangxinyu git的模型demo,最近又看了看源码,趁着自己在撸tensorrt API顺手和大家分享下,该篇核心目的:分享我工作中常用到的模型转换操作方法和思路,千篇一律的东西我尽量少写,比如API尽量鼓励大家去自己看手册调试理解,希望尽量泛化性地理清逻辑,帮助到工作中的朋友(后续会多拿点案列去总结和分析C++框架封装的二次开发思路),后续整理好了上传git.
友情提示:分享的是操作思路,具体步骤可能不够详细,后面我会以一个AI部署任务从模型转换到C++封装开发完整的分享,github上其实半年前已经上传了。
关于动态ONNX到动态TRT的转换,我打算在中篇中通过实战一个完整的项目去分享给大家,其实都是些API使用写法。
一、个人转换思路
由于每个人的工作平台和硬件不一样,所以这里我只说自己常用的方法,主要两个路线:
Tensorrt7.2.3.4为例,这里要说明下,因为Tensorrt8.0的某些API写法是有变化的,会造成代码不兼容!
1.torch->onnx->tensorrt(C++/python)(过度依赖于三方库)
先说onnx吧,我们通过Python的脚本模型可以固定转换成onnx文件以及通过onnxsimplife去简化,再将onnx通过Tensorrt提供的python/C++ API去完成转换,(网上例子很多且官方安装包里也有demo)
对于很成熟的算子我们基本可以很好转移,好处就是省时省力,比如我很久前的用的centerface就是直接ONNX用tensorrt的ONNX解析器完成的引擎生成。
小黑盒性质:但是如果你模型里的OP比如自适应池化、batchnorm1等不支持的算子(Integer division by zero…),这就没法直接转,需要你调整结构后重新训练再转…所以这种方法适用程度有限,不过随着Tensorrt的版本迭代这个问题会越来越少的。
说到底:不论是你版本冲突、OP算子不支持、OP名字识别、OP操作的tenosr维度不支持错误([8] Assertion failed: axis >= 0 && axis < nbDims)等等你能遇到的问题,本质上都是一个原因:都可归咎为你模型里某层和Tensorrt提供的算子不适配引起(源码不支持或者函数不完全兼容),这也是为什么我们要用第二种自定义的方法原因。
转ONNX的脚本参考举例(网上例子很多不做重点叙述,最重要的是思路:就是加载你的模型 ,用ONNX结构定义输入输出是否动态,还有简化模型 精度等)
import argparse
import torch
from modelxxxx import xxxx 导入你的模型
parser = argparse.ArgumentParser()
parser.add_argument(
'-m', '--model', default='your model pth', type=str)
parser.add_argument(
'-o', '--output', default='your output onnx file', type=str)
parser.add_argument('-b', '--batch_size', type=int, default=1)
parser.add_argument('--width', type=int, default=112)
parser.add_argument('--height', type=int, default=112)
parser.add_argument('-d', '--enable_dynamic_axes',
action="store_true", default=False)
args = parser.parse_args()
input_size = [args.height, args.width]
dummy_input = torch.randn(
[args.batch_size, 3, args.height, args.width], device='cuda')
model.load_state_dict(torch.load(args.model))
model.cuda()
model.eval()
print(model)
# Providing input and output names sets the display names for values
# within the model's graph. Setting these does not change the semantics
# of the graph; it is only for readability.
#
# The inputs to the network consist of the flat list of inputs (i.e.
# the values you would pass to the forward() method) followed by the
# flat list of parameters. You can partially specify names, i.e. provide
# a list here shorter than the number of inputs to the model, and we will
# only set that subset of names, starting from the beginning.
input_names = ["input"]
output_names = ["output"]
if args.enable_dynamic_axes:
# Dynamic batch size
dynamic_axes = {'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
torch.onnx.export(model, dummy_input, args.output, dynamic_axes=dynamic_axes,
verbose=True, input_names=input_names, output_names=output_names)
else:
# Fixed batch size
torch.onnx.export(model, dummy_input, args.output,
verbose=True, input_names=input_names, output_names=output_names)
import onnxsim
#看需求简化模型 也可以用Python onnxsim命令 具体自己查
# model_onnx = onnx.load("facenet.onnx") # load onnx model
# # onnx.checker.check_model(model_onnx)
# # model_onnx = onnxsim.simplify(
# # model_onnx,
# # dynamic_input_shape=dynamic,
# # input_shapes={'images': list(img.shape)} if dynamic else None)
# # onnx.save(model_onnx, "simfacenet.onnx")
# print("convert onnx over")
ONNX->Tensorrt
这个其实更简单:核心API为onnxTOTRTModel()。。。比PYTHON的其实更简单,后面Tensorrt主要C++叙述

2.wts->tensorrt(C++/python)(自给自足自产自销)
本质上所有的权重文件不管是什么形式,逻辑上都是按照字典的概念去进行遍历解析!因此下面我会举例,总结下我自己使用的操作思路方法:
总结:核心还是取决你转换的网络模型结构,自己做转换前要做一个路线评估:在能不加大工作量的前提下,完成转换,比如ONNX直接转换适用那么就没必要自己提取参数重构网络,当然你转换的模型并不一定就正确,还需要验证;所以当你足够熟悉tensorrt的API的情况下,还是推荐第二种,同时还能提高你对结构的熟练度!
1.自定义提取模型的参数脚本
这一步就是支持所有框架简单方便和比ONNX更简单:遍历建议权重存储,代码模板也比较固定,如下
port torch
from torch import nn
from torch.nn import functional as F
from xxxxx import xxxxx(填你源码的模型) ##任意的模型 比如torch tensorflow mxnet框架
import struct
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
'-m', '--model', default='输入权重路径', type=str)
parser.add_argument(
'-o', '--output', default='存储的权重wts', type=str)
parser.add_argument('-w', '--wts',action='store_true', default=False)
parser.add_argument('-b', '--batch_size', type=int, default=1)
parser.add_argument('--width', type=int, default=112)
parser.add_argument('--height', type=int, default=112)
parser.add_argument('-d', '--enable_dynamic_axes',
action="store_true", default=False)
args = parser.parse_args()
#初始化你引用的模型,根据你的python框架而定,用torch语法举例
net=xxxx(xxx).to('cuda:0')
your_model=torch.load("your model path")
model=net.load_state_dict(your)
#记载后打印下最好 因为存的只有带参数的网络层,但是整个Print是所有模型的结构,后面自己定义网络的时候有可能回漏掉一些reshape的操作
print(model)
f = open(args.output, 'w')
print("get wts!!!!!!!!!!!!!")
f.write("{}\n".format(len(model.state_dict().keys())))
for k,v in model.state_dict().items():
# if 'num_batches_tracked' in k:
#这里要看你的结构而定,其实就是遍历解析,比如你的某层需要换名字等等,没特殊需要就是以下else分支即可
#del (k,v)
# continue
# else:
#遍历存储下即可,也可以修改名字
print('key: ', k)
print('value: ', v.shape)
vr = v.reshape(-1).cpu().numpy()
f.write("{} {}".format(k, len(vr)))
for vv in vr:
f.write(" ")
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
1.对照源码结构和实际存储参数结构,用Tensortt的api搭建模型,需要你了解基本的Tensorrt的基本API用法(自己动手撸一个模型调试后基本就熟悉了),整体的架构就是基于Tensorrt的源码模板,Python和C++是一样的,语言形式不同而已,网上有很多例子,下面我简单举例一些操作思路:
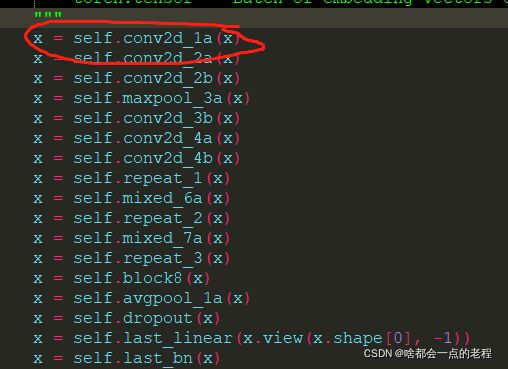
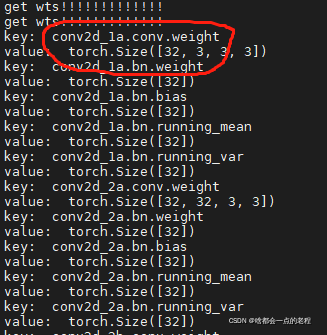
比如我打开一个模型的使用结构、打印结构、文件权重存储信息, 这时候我使用C++编码网络算子:
![]()
使用Tensorrt和一些注册好的算子去自己构建网络,代码太多了我举几个例子即可:
比如上图模型,在Tensorrt中使用函数模板去定义网络模型:
- 注意好拼接的名字,你转换的权重名字是你WTS里存储的名字,你在定义每层网络时候要对应好了,错一个就挂了!这里我定义了红圈标记的一层,这是一组CONV+Bn+RELU的操作,名字为conv2d_1a.xxx对应了我代码中的basicConv2d,这部分是封装好的函数,便于使用。
IActivationLayer* basicConv2d(INetworkDefinition *network,
std::map<std::string, Weights>& weightMap, ITensor& input, int
outch, DimsHW ksize, int s, DimsHW p, std::string lname) {
Weights emptywts{DataType::kFLOAT, nullptr, 0};
IConvolutionLayer* conv1 = network->addConvolutionNd(input, outch, ksize, weightMap[lname + "conv.weight"], emptywts);
assert(conv1);
conv1->setStrideNd(DimsHW{s, s});
conv1->setPaddingNd(p);
IScaleLayer* bn1 = addBatchNorm2d(network, weightMap, *conv1->getOutput(0), lname + "bn", 1e-3);
IActivationLayer* relu1 = network->addActivation(*bn1->getOutput(0), ActivationType::kRELU);
assert(relu1);
return relu1; }
- 如果要自己定义的话,避免不了有些api的函数调用理解,要查阅一下的Tensorrt手册:tensorrt手册
注意一点:权重文件中,某些操作如POOLING和reshape是没有参数存储的OP,所以需要你对准网络实际结构去搭建:
具体查阅官方手册API,去使用理解;
比如池化操作:
IPoolingLayer* pool1 = network->addPoolingNd(input, PoolingType::kAVERAGE, DimsHW{3, 3}); 大小为3的均值池化
assert(pool1);
pool1->setStrideNd(DimsHW{1, 1}); //步长
pool1->setPaddingNd(DimsHW{1, 1}); //设置PADDING :1`
比如reshape:
//reshape 2D
IShuffleLayer* shuffle=network->addShuffle(*fc1->getOutput(0)); //#拿到上一次FC1的输出作为输入
assert(shuffle);
shuffle->setReshapeDimensions(Dims3{512,1,1}) ;
API熟练度问题~~~~~~
- 不支持的OP怎么办?比如adaptiveaveragepooling:(尽量满足使用trt的算子函数去取代,不然你就要改原始网络去重新训练)
使用普通的均值池化替代,因为你知道这一层的输入和输出
// nn.AdaptiveAvgPool2d(1) 替换成为:
IPoolingLayer* pool2 = network->addPoolingNd(*cat6->getOutput(0), PoolingType::kAVERAGE, DimsHW{1, 1);
assert(pool2);
pool2->setStrideNd(DimsHW{3, 3});
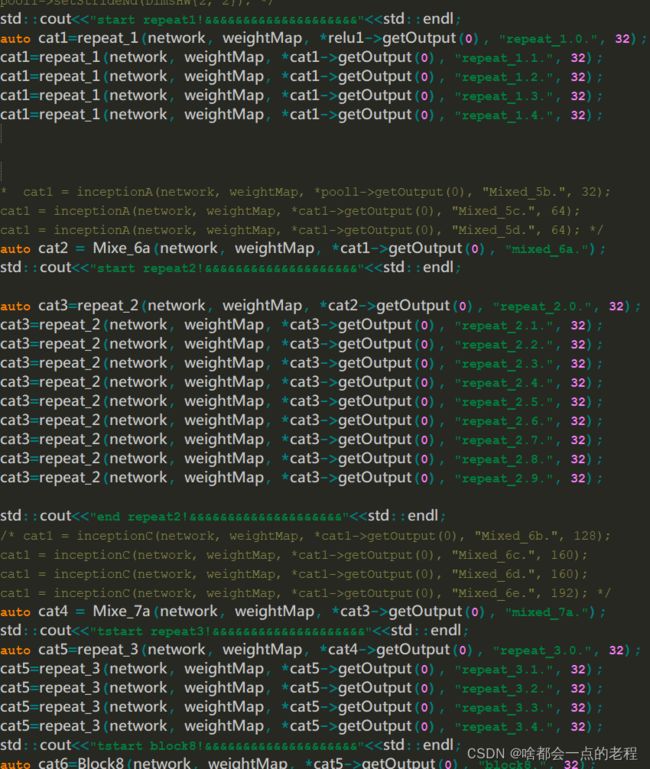
反复以上过程和疯狂调试,基本就码完了:
三、一些实际操作中遇到的错误案例(不包含语法错误)
1)当你的通道有错时候trt会有Log提示,对着自己结构改就好了我就不复现这种问题了
这是我利用tensorrt的demo,把Inceptionv3重构成facenet的改版结构,无尽调试中!!!!就是细致的活,需要很认真,错一步楼就塌了。。。
2)这种错误是因为你的值空了,null触发代码断言,也是最好解决的问题null了,一般都是你的网络层定义名字和你模型权重的不一样,所以没取到权重的值。

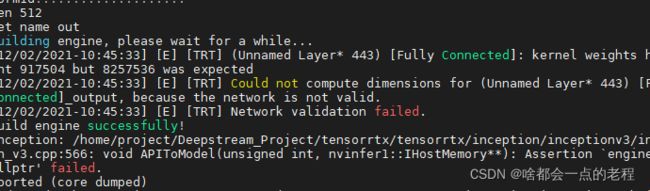
3)这种错误比较麻烦,是你搭的结构参数和模型参数量不符合,需要详细检查结构,一般是你的定义的算子和原模型有出入或者少了一些reshape、pooling等不带参数的算子。
4)终极难点其实就是转换成功够的结果是有问题的,这个其实比较难办,这种现象我在ONNX和自定义的模型上都遇到过,这个并没有一致的解决方案,比较棘手,真出现了这种问题,可能每一个不确定的OP都需要反复检测。
1.至于Tensorrt推理都是固定的模板(c++/PYTHON都一样,只是语言风格不同而已)
std::ifstream file("x'x'x'x.engine", std::ios::binary);
if (file.good()) {
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
//定义输入和输出的数组
static float data[3 * INPUT_H * INPUT_W];
static float prob[BATCH_SIZE * OUTPUT_SIZE];
//TRT源码模板
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr); //反序列化
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
cv::Mat img = cv::imread("图像"); //或者给data初始化一个输入
//cv::resize(img, img, cv::Size(160,160)); //图像根据训练的BN存储的方差和均值进行归一化
for (int i = 0; i < INPUT_H * INPUT_W; i++) {
data[i] = ((float)img.at<cv::Vec3b>(i)[2] - 127.5) * 0.0078125;
data[i + INPUT_H * INPUT_W] = ((float)img.at<cv::Vec3b>(i)[1] - 127.5) * 0.0078125;
data[i + 2 * INPUT_H * INPUT_W] = ((float)img.at<cv::Vec3b>(i)[0] - 127.5) * 0.0078125;
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, data, prob, BATCH_SIZE,onnx_flag);
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
总结
所以说工程每一点细节都决定成败,整体的难点就是你构建模型的算子上了,需要操作完全正确适配!该篇分享的是思路,具体的代码熟练度其实是要靠自己使用调试API后才能得到反馈,这种动手的事情要亲力亲为,后面会结合一些模型示例进行部署开发的分享,有精力和时间的话会出点视频。