论文笔记:Deep Neural Network Augmentation: Generating Faces for Affect Analysis
Deep Neural Network Augmentation: Generating Faces for Affect Analysis
Dimitrios Kollias1 · Shiyang Cheng2 · Evangelos Ververas1 · Irene Kotsia3 · Stefanos Zafeiriou1
2020年2月发表
只是对部分内容的翻译,需要配合英文原文理解
摘要
本文提出了一种综合面部表情的新方法。根据六个基本表达方式(即愤怒,厌恶,恐惧,喜悦,悲伤和惊奇),或根据效价(即情感有多积极或消极)和唤醒(即情绪激活的力量)。所提出的方法接受以下输入:(i)人的中性2D图像; (ii)基本面部表情或一对价态(VA)情感状态描述符要生成,或者在2D VA空间中要生成的情感路径作为图像序列。为了根据VA合成影响,为此人添加了来自4DFAB数据库的600,000个帧。通过在中性图像上拟合3D变形模型,然后使重构的脸部变形并添加输入的效果,并将具有给定效果的新脸部混合到原始图像中,来实现效果合成。定性实验说明了当从15个知名的实验室控制或野生数据库(包括Aff-Wild,AffectNet,RAF-DB)中采样中性图像时生成的真实图像。与生成对抗网络(GAN)的比较表明,该方法可以实现更高的质量。然后,进行定量实验,其中合成图像用于训练深度神经网络以对所有数据库进行情感识别的数据增强。在任何情况下,与最新方法以及基于GAN的数据增强方法相比,都可以大大提高性能。
1 Introduction
在保留身份信息的同时从单个静态面孔渲染逼真的面部表情是一个开放的研究主题,对情感计算领域具有重大影响。 生成具有不同面部表情的特定人的面部可用于各种应用中,包括面部识别(Cao等人,2018; Parkhi等人,2015),面部验证(Sun等人,2014; Taigman等人,2014) ),情感预测,表情数据库生成,面部表情增强和娱乐。
本文介绍了一种新颖的方法,该方法使用具有中性表情的任意人脸图像,并根据分类或维度情感表示模型生成同一个人但具有不同表情的新人脸图像。 使用带有标记面部表情的小型数据库无法解决此问题,因为通过它们解开面部表情和身份信息确实非常困难。 我们的方法基于对大型4D面部数据库4DFAB(Cheng等人,2018)的分析,我们对其进行了适当注释并用于给定对象面部的面部表情合成。
首先,从连续变量,价(即情感如何积极或消极)和唤醒(情感激活的力量)三个方面,使用维数情感模型(Whissell 1989; Russell 1978)对大量的600,000张面部图像进行注释。 该模型不仅可以表示主要的极端表达,还可以表示在人与人之间或人与机器之间的日常交互中满足的微妙表达。 根据所采用的维度视图,所有情感都可以通过它们在生成的坐标系二维价唤醒空间中的位置来区分。
与分类方法(六个基本表达式加中性状态)相比,该模型的优势在于,它可以导致对实际情绪状态的非常准确的评估; 价和唤醒是潜在的情感维度,因此能够区分不同的内部状态。 此外,分类模型还具有以下缺点:用户可能会具有除特定感觉之外的其他感觉,然后必须将其映射到模型的类别上; 这会导致实际印象的某些失真。 因此,在刻画情感上模棱两可的例子时,分类模型的分辨率较差。 相反,在表示每个情感状态的维度模型中情况并非如此。
其次,根据六种基本面部表情(愤怒,厌恶,恐惧,幸福,悲伤,惊奇)的分类情感模型,从4DFAB中选择了12,000个表情,其中六个基本表情包含包含2000个案例。
所提出的方法接受:(i)一对价值并合成各自的面部表情,(ii)2D VA空间中的情感路径并合成显示其的时间序列,(iii)表示基本面部表情的值 被合成; 在所有情况下,均使用给定的人的中性2D图像适当地传递合成的情感。 第2节涉及有关面部表情合成的相关工作以及与数据增强相关的方法。 第3节介绍了当前工作中使用的材料和方法。 我们描述了在开发中使用的4DFAB数据库和3D可变形模型的注释和使用。 第4节介绍了我们的方法,详细说明了用于合成对图像或图像序列的影响的所有步骤。 第5节提到了分类和维度数据库,我们的方法使用了这些数据库。
在Sect6中进行了广泛的实验研究。首先,对所提出的方法进行了定性评估,与GAN产生的面部表情相比,该方法还显示出更高的质量。然后,我们使用合成的面部图像进行数据增强,并在8个数据库上训练深度神经网络,并用尺寸或类别影响标签进行注释。我们表明,所实现的性能远高于(i)通过相应的最新方法获得的性能,(ii)具有由StarGAN和GANimation网络提供的数据增强功能的相同DNN的性能。与GAN进行进一步比较,将合成的面部图像与原始图像一起用作DNN训练和/或测试数据;这也验证了我们方法的改进性能。还进行了一项消融研究,阐明了数据粒度和受试者年龄对所提出方法的性能的影响。最后,在Sect6中介绍了结论和未来的工作。
所提出的方法包括许多新颖的贡献。 据我们所知,这是第一次在合成人脸图像时考虑到情感的维度模型。 经实验研究验证,生成的图像质量高且逼真。 所有其他方法都会根据六个基本表达式或其他几个表达式来生成合成人脸。 我们进一步表明,提出的方法可以准确地合成六个基本表达式。而且,这是第一次在价和唤醒方面对4D人脸数据库进行注释,然后将其用于情感合成。 这个时态数据库可确保连续的视频帧的注释在VA空间中相邻。 因此,我们产生时间通过使用VA空间中相邻的注释来影响给定中性面上的序列。 在定性实验研究中给出了结果,说明了这种新功能。
还应该提到的是,所提出的方法在呈现中性的面部图像时,无论是在受控环境中还是在野外(例如,不管图像中出现的人的头部姿势)获得时,都很好用。 在涉及情感的大多数重要数据库上进行了广泛的实验研究,结果表明,基于拟议的面部表情合成方法开发的DNN优于 现有的最新技术,以及 基于由GAN架构产生的面部表情合成的相同DNN 所产生的效果。
2 Related Work
面部表情转移是用于映射和生成指定对象和面部表情的所需图像的研究领域。 对于高分辨率图像,许多方法均取得了显着效果,并被应用于多种应用,例如面部动画,面部编辑和面部表情识别。
从单个图像进行面部表情转移的方法主要有两类:传统的基于图形的方法和新兴的生成方法。 在第一种情况下,某些方法通过2D扭曲(Fried等人2016; Garrido等人2014)或3D扭曲(Blanz等人2003; Cao等人2014; Liu等人2008)直接扭曲输入面以创建目标表情 。 其他方法可构造参数全局模型。 在Mohammed等人(2009)中,学习了一种概率模型,其中现有图像和生成的图像均服从结构约束。 Averbuch-Elor等人(2017)添加了与面部表情相关的精细动态细节,例如皱纹和内口。 尽管这些方法在高分辨率和一对多图像合成方面取得了一些积极的成果,但是由于其复杂的设计和昂贵的计算,它们仍然受到限制。
Thies等人(2016)开发了实时的面对面表情传递系统,并为嘴部增加了额外的混合步骤。这种2D到3D的方法显示出令人鼓舞的结果,但是由于其公式化的性质,它无法检索到精细的细节,并且其适用性仅限于位于已知秩的线性子空间中的表达式。作者将该系统扩展为人像视频传输(Thies等人2018)。他们捕获了面部表情,眼睛凝视,僵硬的头部姿势以及源演员上半身的动作,并将其实时传输到目标演员。第二类方法基于数据驱动的生成模型。最初,一些生成模型,如深度信任网(DBN)(Susskind等,2008)和高阶Boltzmann机器(Reed等,2014)已应用于面部表情合成。然而,这些模型面临诸如生成的图像模糊,不能精细控制面部表情和低分辨率输出之类的问题。
随着生成式对抗网络(GANs)的最新发展(Goodfellow等人,2014),这些网络已被应用于面部表情转移。 由于生成的图像质量很高,因此提供了肯定的结果。 在执行面部表情转移时,将根据数据集训练生成模型,包括有关身份,表达,视角等的所有信息。 生成建模方法减少了面部纹理和情绪状态之间联系的复杂设计,并将直觉的面部特征编码为数据分布的参数。 但是,GAN的主要缺点是训练不稳定以及视觉质量和图像多样性之间的权衡。
由于原始GAN无法生成具有针对特定人的特定面部表情的面部图像,因此提出了一些基于表情类别的方法。 条件GAN(cGAN)(Mirza和Osindero 2014)(和条件变量自动编码器(cVAE)Sohn等人2015)可以在属性信息可用的情况下生成样本。 这些网络需要大型培训数据库,以便可以正确区分身份信息。 否则,当出现看不见的脸时,网络往往会生成看起来像训练数据集中“最近”的对象的脸。 在训练期间,这些网络需要了解属性标签; 目前尚不清楚如何在不重新训练的情况下将它们适应新的属性。 最终,这些网络遭受模式崩溃(例如,生成器仅输出来自单一模式或具有极低变化的样本)和模糊性。
条件差异对抗自动编码器(CDAAE)(Zhou and Shi 2017)的目的是为有目标情感或面部动作单元标签的看不见的人合成特定情感。 然而,这种基于GAN的方法仍然限于离散的面部表情合成,即,它们不能生成表示从一种情感到另一种平滑过渡的面部序列。 Ding等人 (2018)提出了一个表达生成对抗网络(ExprGAN),其中可以以从弱到强的连续方式控制表达强度。 身份和表达表示学习被解开,对配对样本的训练没有严格的要求。 作者开发了一种三阶段增量学习算法,以在小型数据集上训练模型。
Pham等人(2018)提出了一种用于自动面部表情的弱监督adver sarial学习框架基于连续作用单位系数的合成。在Pumarola等人(2018)中,提出了GANimation,它通过AU标签额外控制生成的表达,并允许连续表达转化。作者介绍了一种基于注意力的生成器,以提高其模型用于分散背景和光照的鲁棒性。基于AU和VA的连续表达合成之间存在一些差异。首先,AUs与某些面部肌肉有关,只有很少一部分被映射到面部表情建模。相反,VA模型涵盖了整个情绪范围。此外,将AU映射到情绪上并不容易(不同的心理学研究提供不同的结果)。 GANimation仅基于AU的自动注释,而建议的方法基于4DFAB数据库的手动(即更健壮和可信的VA注释)。最后,可以提到的是,对AU的注释需要有经验的FACS编码人员;尤其是在野生数据集中。这就是为什么只有一个为AU(存在而不是强度信息)进行注释的野生数据库EmotioNet,它仅包含50,000个注释(以12个AU为单位)。
最近,Song等人(2018)利用地标并提出了几何学指导的GAN(G2GAN)以生成平滑的面部表情图像序列。 G2GAN使用基于双重对抗网络的几何信息来表达面部变化并合成面部图像。 通过操纵地标,还可以生成平滑变化的图像。 然而,该方法需要目标人物的中性脸作为面部表情传递的中间。 尽管表情删除网络可以生成特定人的中性表情,但是此过程会带来其他问题,并降低表情转换的性能。
Qiao等人(2018)使用几何(面部标志)通过面部几何嵌入网络控制表情合成,并提出了几何对比生成对抗网络(GC-GAN)在不同对象之间传递连续情感,即使存在在形状上存在很大差异。 Wu等人(2018)提出了边界潜在空间和边界变换器。他们将原始人脸映射到边界的潜在空间中,并将原始人脸的边界转换为目标的边界,这是捕获表达式传递过程中面部几何变化的媒介。在Ma and Deng(2019)中,开发了一个不成对的学习框架来学习面部混合形状空间中任意两个面部表情之间的映射。该框架自动将输入视频剪辑中的源表达式转换为指定的目标表达式。这项工作缺乏生成个性化表达的能力;个体的特定表达特征(例如皱纹和折痕)将被忽略。同样,不考虑不同ent表达式之间的转换。最后,这项工作受到局限,因为它无法产生高度夸张的表达。
基于图形的方法和面部表情传递的生成方法都已用于创建合成数据,这些数据在网络训练中用作辅助数据,从而扩大了训练数据集。 Abbasnejad等人创建了具有3D卷积神经网络(CNN)的合成数据生成系统。 (2017)自信地创建表情具有不同饱和度的面部。 Antoniou等。 (2017)提出了基于cGAN的数据增强型生成对抗网络(DAGAN),并测试了其在香草分类器和一次射击学习中的有效性。 DAGAN是基于cGAN的数据扩充的基本框架。 Zhu等人(2018)提出了另一个基于CycleGAN的面部数据增强基本框架(Zhu等人2017)。与cGAN相似,CycleGAN也是图像到图像转换的通用解决方案,但是它同时学习两个域之间的双重映射,而无需配对训练示例,因为它结合了循环一致性损失和对抗性损失。作者使用此框架为不平衡数据集生成辅助数据,其中选择样本较少的数据类作为传输目标,而样本较多的数据类作为参考。
3 Material and Methods
在下文中,我们首先描述4DFAB数据库,其以价原子为注释以及从中选择表达性分类序列。 带注释的4DFAB数据库已用于构建3D面部表情库,这是我们在下一节中描述的情感合成管道的基础。 然后,我们描述所使用的方法:a)将3D图库的所有组件注册并关联到通用坐标系中; b)用于构建本作品中使用的3D变形模型。
3.1 The 4DFAB Database
4DFAB数据库(Cheng等人2018)是第一个为生物识别应用设计的大规模4D人脸数据库和面部表情分析。它包括180名受试者(60名女性,120名男性),年龄从5岁到75岁。 4DFAB是在5年内以四种不同方式收集的会话,包含超过1,800,000张3D面孔。该数据库旨在捕获清晰的面部动作和自发性面部表情,后者是通过观看情感视频剪辑来诱发的。在这四个阶段的每个阶段中,都显示了不同的视频片段,这些片段激发了不同的脊柱神经行为。在本文中,我们将所有1580个自发表达序列(视频剪辑)用于维度情感分析和合成。 4DFAB数据库的帧速率为60 FPS,自发表达序列的平均片段长度为380帧。因此,1580个表达序列对应于600,000个帧,我们在价数和唤醒方面进行了注释(详细信息在下一节中)。这些序列涵盖了广泛的表达方式,如图1和2所示。 2和3。
此外,为了能够开发分类情感综合模型,我们使用了与4DFAB一起提供的每个基本表达式2000个可表达3D网格(总计12,000个网格)。 那些3D网格对应于4DFAB中所放置的表达序列的(带注释)顶点帧。 这样的例子如图1所示。
3.2 4DFAB Dimensional Annotation
为了开发新颖的维数表达合成方法,已对4DFAB的所有1580个动态3D序列(即,超过600,000帧)进行了价数和唤醒情感维数标注。总共选择了三位专家来执行注释任务。每个专家都对两个情感维度执行时间连续注释。 Zafeiriou等人中描述的应用工具。 (2017),用于注释过程。每位专家都使用标识符(例如,他/她的名字)登录到应用程序注释工具,并选择了适当的操纵杆;然后应用程序显示所有视频的滚动列表,专家选择了要注释的视频;然后出现一个屏幕,显示所选的视频以及价位或唤醒值范围在[-1,1]中的滑块;专家通过上下移动操纵杆为视频添加注释;最后,创建带有注释的文件。每个注释者的平均注释间相关性价分别为0.66、0.70、0.68(唤醒)和0.59、0.62、0.59(唤醒)。这些平均注释间相关性的平均价为0.68,唤醒为0.60。这些值很高,表明注释者之间有很好的一致性。结果,最终标签值被选择为这三个注释的平均值。
图2显示了来自4DFAB的帧示例及其注释。图3显示了4DFAB注释的二维图。 在本文的其余部分中,我们将4DFAB数据库称为:(i)600,000帧及其相应的3D网格,这些网格已用2D价和唤醒(VA)情感值进行注释,或者(ii)12,000根顶点帧 姿势表达式及其对应的3D网格的分类注释。
3.3 Mesh Pre-Processing: Establishing Dense Correspondence
首先将每个3D网格重新参数化为一致的形式,其中使所有网格上的顶点数量,每个顶点的三角剖分和解剖学含义一致。 例如,如果在一个网格中索引为i的顶点对应于鼻尖,则要求在每个网格中具有相同索引的顶点也对应于鼻尖。 满足上述特性的网格被称为彼此紧密对应。 因此,将所有这些网格与通用坐标系(即3D人脸模板)相关联是遵循步骤以建立密集的对应关系。
为此,我们需要为每个网格定义2D UV空间,实际上是嵌入3D面部表面的连续的扁平化图集。 通过双射映射,这样的UV空间与其对应的3D表面相关联; 因此,在两个UV图像之间建立密集的对应关系将隐式为映射的网格建立3D到3D对应关系。 UV贴图是将2D图像投影到3D模型的表面以进行纹理贴图的3D建模过程。 字母U和V表示2D纹理的轴,因为X,Y和Z已被用来表示模型空间中3D对象的轴。
我们采用最佳的圆柱投影方法(Booth和Zafeiriou 2014)为每个网格综合创建一个UV空间。制作了一个UV图(它是图像I),每个像素都对空间信息(X,Y,Z)和纹理信息(R,G,B)都进行了编码,然后在该图上执行非刚性对齐。通过使用关键地标拟合和薄板样条线(TPS)翘曲的UV-TPS方法执行非刚性对准(Cosker等,2011)。继程等。 (2018),我们对Cosker等人进行了一些修改。 (2011),以适合我们的数据。首先,我们建立特定于会话和个人的主动外观模型(AAM)(Alabort-i Medina和Zafeiriou 2017)以自动跟踪UV序列中的特征点。这意味着将针对一个主题分别构建和使用4种不同的AAM。造成这种情况的主要原因如下:(i)由于几个事实(例如,老化,胡须,化妆,实验照明条件),不同会话的纹理有所不同;(ii)在特定领域,针对特定人的模型被证明更加准确和健壮( Chew et al.2012)。
总共435个中性网格和1047个表达网格(每人每次会话1个中性网格和2–3个表达网格)在4DFAB中被选中;这些包含带有79个3D地标的注释。将它们展开并栅格化到UV空间,然后分组以构建相应的AAM。翻转每个UV贴图以增加拟合的鲁棒性。一旦用79个界标跟踪了所有UV序列,然后使用TPS将它们扭曲到相应的参考帧,从而实现3D密集对应。对于每个主题和会话,从他/她的中性UV贴图构建一个特定的参考坐标系。从每个变形的帧中,我们可以统一采样纹理和3D坐标。最终,获得了一组在相同拓扑和密度下非刚性对应的3D网格。
假定网格已与它们的指定参考框架对齐,则最后一步是在这些参考框架和3D模板面之间建立密集的3D到3D对应关系。这是一个3D网格配准问题,可以通过非刚性ICP解决(Amberg等,2007)。我们雇用了它可以将中性参考网格注册到一个通用模板-大比例面部模型(LSFM)(Booth等人2018)。我们将所有600,000个3D网格与LSFM的平均面完全对应。结果,我们创建了一组新的600,000个3D面,它们共享相同的网格拓扑,同时保持其原始的面部表情。在下文中,该集合构成了我们用于面部表情合成的3D面部表情库。
3.4 Constructing a 3D Morphable Model
3.4.1 General Pipeline
3.4.2 The Large Scale Facial Model (LSFM)
4 The Proposed Approach
在本节中,我们介绍了全自动的面部表情综合框架。 用户需要提供中性图像和情感,可以是VA对值,2D VA空间中的路径或基本表达类别之一。 我们的方法:(1)在输入的中性图像上执行人脸检测和界标定位,(2)在结果图像上拟合3D变形模型(3DMM)(Booth et al.2017),(3)使重构的人脸变形并添加 输入效果,然后(4)将具有给定效果的新面孔混合到原始图像中。 在这里让我们注意到,前两个步骤所需的总时间约为400毫秒。 如果从同一输入图像生成多个图像,则仅需执行一次。 以下是有关我们所描述方法的具体细节。 该过程如图4所示。
【图4 图片怎么一直上传失败==】
4.1 Face Detection and Landmark Localization
编辑图像的第一步是找到将用于拟合3DMM的界标点。 我们首先使用Zhang等人(2016)的人脸检测模型执行人脸检测,然后利用(Deng等人2018)定位68个2D人脸界标点,这些点可以识别人脸的3D结构, 正确定位面部的遮挡部分(最常见的下巴部分)。
4.2 3DMM-Fitting: Cost Function and Optimization
此步骤的目标是使用从原始图像中采样的纹理来检索重建的3D人脸。 为此,我们首先需要一个3DMM。 我们选择LSFM。
在人脸图像上拟合3DMM是3D重建的逆向图形方法,包括优化3DMM的三个参数模型,形状,纹理和相机模型。 优化的目的是渲染尽可能接近输入图像的2D图像。 在我们的pipeline中,我们遵循Booth等人(2017)的3DMM拟合方法。 如前所述,我们采用LSFM(Booth et al.2018)S(p)对面部的身份变形建模。 此外,我们采用Booth等人(2017)的稳健的,基于特征的纹理模型T(λ),该模型基于野外图像构建。 所采用的相机模型是透视变换W(p,c),其在图像平面上投影形状S(p)。 因此,我们优化的目标函数可以表述为:
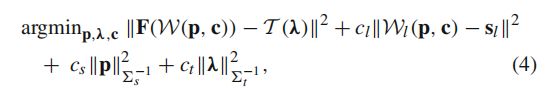
其中第一项表示在投影形状位置采样的基于特征的图像F与模型生成的纹理之间的像素损失; 第二项表示图像2D界标和相应的2D投影3D点之间的稀疏界标损失,其中2D形状sl由Deng等人(2018年)提供; 其余两个项是正则化项,用作反过拟合机制,其中6s和6t是对角矩阵,主要对角线分别是形状和纹理模型的特征值; cl,cs和ct是用于在优化过程中调整每个术语的重要性的权重,并根据Booth等人(2017)的经验将其分别设置为105、3×106和1。还要注意,2D地标项非常有用,因为它可以推动优化收敛。 如Booth等人(2017)所述,通过高斯-牛顿优化的Project-Out变量解决方程4的问题。
从优化模型中,最佳形状实例构成了输入面的中性3D表示。 此外,通过使用最佳形状和相机模型,我们能够在恢复的网格的投影位置对输入图像进行采样,并提取UV纹理,我们稍后将其用于渲染。
4.3 Deforming Face and Adding Affect
给定affect和任意2D图像I,我们首先使用上述3DMM拟合方法将LSFM拟合到该图像。 之后,我们可以使用从原始图像中采样的纹理来检索重构的3D脸部轮廓s_orig(纹理采样只是为图像平面中每个投影的3D顶点提取图像像素值)。 让我们假设我们已经创建了一个情感综合模型M_Af f,该模型将情感作为输入并生成一个新的表情面孔(表示为s_gen),即s = M_Aff(affect)(有关生成的具体细节) 富有表情的面孔,请参见第4.5节)。 接下来,我们通过从LSFM模板s中减去合成的面部s_gen(即δs = s_gen-s)来计算面部变形δs,并将此变形施加到重建的网格上,即s_new = s_orig + δs。 因此,我们获得了具有面部表情的3D面孔(称为s
_new)。
4.4 Synthesizing 2D Face
我们管道中的最后一步是将新的3D人脸重新渲染为原始2D图像。 为此,我们使用根据给定的效果,已提取的UV纹理和3DMM的最佳摄影机转换而变形的网格。 为了进行渲染,我们将三个模型实例传递给渲染器,并将输入图像的背景用作背景。 最后,通过泊松混合将渲染的图像与原始图像融合(Pérez等,2003),以平滑前景表面与图像背景之间的边界,从而产生自然逼真的结果。 在我们的实验中,我们同时使用了基于CPU的渲染器(Alabort-i-Medina等人2014)和基于GPU的渲染器(Genova等人2018)。 基于GPU的渲染器大大减少了渲染时间,因为渲染单个图像需要20 ms,而基于CPU的渲染器则需要400 ms。
4.5 Synthesizing Expressive Faces with Given Affect
4.5.1 VA and Basic Expression Cases: Building Blendshape Models and Computing Mean Faces
让我们首先描述VA情况。我们有60万个3D网格(已建立为密集的对应关系)及其VA注释。我们要适当地将VA空间离散化为多个类,以便每个类包含足够数量的数据。这是由于以下事实:如果类仅包含少量示例,则更可能包含身份信息。但是,合成的面部表情只能描述与VA对值相关的表情,而不能描述人的身份,性别或年龄的信息。我们选择使用欧氏距离作为度量标准并使用ward 作为链接标准(保持VA值和3D网格之间的对应关系)对VA值执行聚集聚类(Maimon和Rokach 2005)。通过这种方式,我们创建了550个聚类,即类。然后,我们建立了blendshape模型并计算了每个类的平均面数。图5说明了各种类别的平均面。应当指出的是,大多数类别对应于VA空间的前两个象限,即正价区域(可以在图3的2D直方图中看到)。
.
就基本表达式而言,基于六个基本表达式的每一个的2000个3D网格(12000个),我们建立了六个blendshape模型和六个对应的均值面。
4.5.2 User Selection: VA/Basic Expr and Static/Temporal Synthesis
用户首先选择我们的方法将产生的affect类型。 affect可以是VA空间中的一点或路径,也可以是六个基本表达类别之一。 如果用户选择后者,则我们将检索该类别的平均脸并将其添加到根据用户输入的中性图像重建的3D脸上。 在这种情况下,图4中的唯一区别在于,用户可以输入一个基本表达式,即快乐表达式,而不是VA对值。 如果用户选择了前者,则他/她需要另外澄清我们的方法是否应生成具有这种affect的图像(“静态合成”)或图像序列(“时间合成”)。
静态综合:如果用户选择“静态综合”,则用户应输入特定的VA对值。 然后,我们检索该VA值所属的类的平均值。 我们使用该平均脸部作为要添加到从提供的中性图像重建的3D脸部上的效果。 图4显示了针对此特定情况的建议方法。 假设已经创建了550 VA类,图6说明了第4.5.1节中描述的过程。
时间合成:如果用户选择“时间合成”,则他应该在VA空间中提供一条路径(例如通过绘制),合成序列应遵循该路径。然后,检索路径的VA值所属的类的均值面,并使用这些均值面作为要添加到从提供的中性图像重建的3D面上的效果。结果,生成了表达序列,该序列显示了对用户指定的VA路径的影响演变。
在这里让我们提到,我们的方法中使用的4DFAB是一个时间数据库,这一事实确保了连续视频帧的注释在VA空间中是相邻的,因为它们通常显示相同或略有不同的情感状态。因此,连续视频帧的3D网格将位于2-D VA空间中的相同和相邻类别中。因此,如上所述,来自相邻类别的平均面孔可用于显示情感的时间演变。
4.5.3 Expression Blendshape Model
表情混合形状模型提供了一种有效的方法来参数化面部行为。 局部混合形状模型(Neumann等,2013)已用于描述选定的VA样品。 为了建立这个模型,我们首先按照第3.3节中描述的密集配准方法,使所有网格完全对应。 结果,我们得到了一组具有相同数量的顶点和相同拓扑的训练网格。 请注意,我们还为每个主题选择了一个中性网格,该网格应与其余数据完全对应。 接下来,我们从各自的中性网格中减去每个3D网格,并创建一组m个差分矢量di∈R3N。 然后,将它们堆叠到矩阵D = [d1,…,dm]∈R(3N×m),其中N是网格中的顶点数。 最后,将稀疏主成分分析(PCA)的变体应用于数据矩阵D,以识别稀疏变形成分C∈R(h×1):
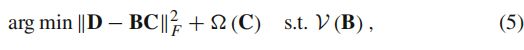
其中约束V可以为max(| B_k |)= 1,∀k或max(B_k)= 1,B≥1,∀k,其中Bk∈R^3N×1表示稀疏权重矩阵B的第k个分量B = [ B1,…,Bh]。 这两个约束的选择取决于实际使用情况。 主要区别在于后者允许负重,因此可以朝两个方向变形,这对于描述肌肉凸起等形状非常有用。 在本文中,我们选择了后一种约束,因为我们希望能够实现双向肌肉运动并合成多种表达式。 稀疏分量C的正则化以1/2范数执行(Wright等,2009; Bach等,2012)。 为了允许更多的局部变形,将附加的正则化参数添加到(C)中。 为了计算最佳的C和B,采用了迭代交替优化(更多细节请参考Neumann等人2013)。