数据仓库主要有四种架构,Kimball的DW/BI架构、独立数据集市架构、辐射状企业信息工厂Inmon架构、混合Inmon与Kimball架构。不过不管是那种架构,基本上都会使用到维度建模。
Kimball的DW/BI架构,可以参考这篇文章 数据仓库(4)基于维度建模的KimBall架构。
独立数据集市架构,采用这种架构的数据仓库,数据以部门为基础来部署,不考虑企业级别的信息共享和集成。也就是各个部门各自按照需要,各自在数据源同步数据,按照各自的标准,对数据进行处理。这种实际上就是没有架构,会造成分析数据的冗余存储,计算资源的浪费,会导致每一个统计部门统计口径的不统一,也就会导致因为数据口径不一致导致长时间的对数据。
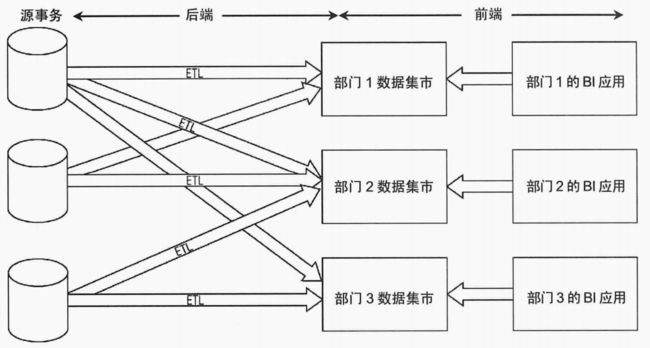
辐射状企业信息工厂Inmon架构,数据从操作型数据源中获取,在ETL中进行处理,获得的原子数据保存在满足第三范式的数据库中,这种规范化,原子数据的仓库就是企业信息工厂Inmon架构。Inmon架构与Kimball架构的差别之一就是,Inmon的数据仓库是规范化的,而Kimball架构是基于维度建模的星型模型。
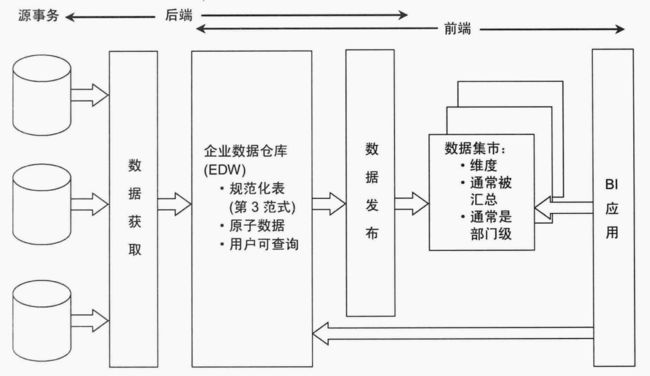
混合Inmon与Kimball架构,这种就是将Kimball与Inmon两种架构进行嫁接,抽取过来的数据,存放在规范化的数据仓库中,然后在这个的基础之上抽取基于维度建模的数据展现,开发给数据分析人员等。
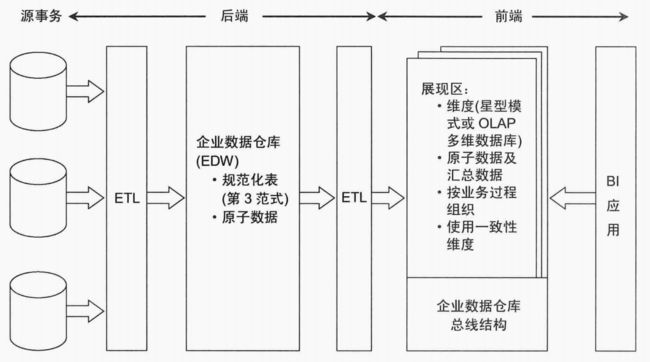
在经典的理论认为,混合Inmon与Kimball架构是最好的方式。这种方法可以将数据规范化,然后通过维度建模,以一种比较简单的方式开发给分析人员。但是这种方式适合比较传统的行业,或者政府单位,这种业务发展缓慢的模式,如果是互联网企业,特别是创业型团队,业务还在快速的迭代中,使用维度建模需要花费很长的前期准备工作,而且扩展性不好,使用Kimball维度建模是比较合适的。
Kimball 模式从流程上看是是自底向上的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。对于Kimball模式,数据源每每是给定的若干个数据库表,数据较为稳定可是数据之间的关联关系比较复杂,须要从这些OLTP中产生的事务型数据结构抽取出分析型数据结构,再放入数据集市中方便下一步的BI与决策支持。所以KimBall是根据需求来确定需要开发ETL哪些数据。
Inmon 模式从流程上看是自顶向下的,即从数据源到数据仓库再到数据集市的(先有数据仓库再有数据市场)一种瀑布流开发方法。对于Inmon模式,数据源每每是异构的,好比从自行定义的爬虫数据就是较为典型的一种,数据源是根据最终目标自行定制的。这里主要的数据处理工做集中在对异构数据的清洗,包括数据类型检验,数据值范围检验以及其余一些复杂规则。在这种场景下,数据没法从stage层直接输出到dm层,必须先经过ETL将数据的格式清洗后放入dw层,再从dw层选择须要的数据组合输出到dm层。在Inmon模式中,并不强调事实表和维度表的概念,由于数据源变化的可能性较大,须要更增强调数据的清洗工做,从中抽取实体-关系。immon是将整个数据仓库规划好,统一按照范式建模进行开发。
下面是两种架构的优劣比较。
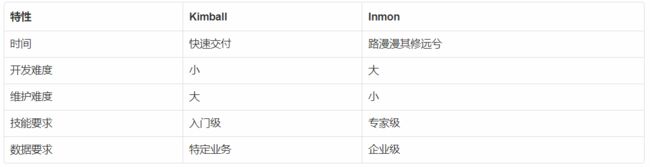
> 参考文章: 数据仓库(5)数仓Kimball与Inmon架构的对比