BERT-QE:用于文档Rerank的上下文化查询扩展模型

BERT-QE
论文名称:EMNLP2020 | BERT-QE: Contextualized Query Expansion for Document Re-ranking
arxiv地址:https://arxiv.org/abs/2009.07258v1
代码:https://github.com/zh-zheng/BERT-QE
1)Intro
查询扩展通过对用户的初始查询进行扩展和重构,解决了用户查询用词与文档用词不匹配以及用户表达不完整的问题。其目的为减少查询中使用的语言与文档中使用的语言之间的不匹配。伪相关反馈(pseudo relevance feedback,PRF)方法是一种极其有效的方法,通常将Top-k篇文档认作相关文档,使用如TF-IDF权重的方法从这些排名靠前的文档中提取m个关键词,将这些关键词加入到查询中,然后再去匹配查询所返回的文档,最终返回最相关的文档。显然,这种方法的效果非常依赖于所选择的扩展词语的质量。
然而,查询扩展方法在扩展查询时可能会引入不相关的信息。为了解决这一问题,受近年来诸如BERT之类的上下文模型应用于文档检索任务的进展的启发,该文提出了一种新的利用上下文的查询扩展模型。
目前使用预训练模型进行信息检索任务依旧遵循“Retrieve+Rerank”的pipline机制。Retrieve阶段使用BM25或DPH+KL等检索算法对文档集合进行粗排,一般取前1000篇作为feedback document。Rerank阶段就使用BERT等预训练模型进行重排,获取最终的文档排名。
该篇论文主要在Rerank阶段做了一些工作,提出了一种新的查询扩展模型。与19年的Simple Applications of BERT for Ad Hoc Document Retrieval不同的是,该篇论文并不是把文档分成段落,而是使用滑动窗口的方式,在更小的粒度上以期获得更深层的语义信息。
这项工作的贡献有三点:
- 提出一种新的查询扩展模型,增强BERT模型获取反馈文档中相关信息的能力;
- 在两个TREC测试集Robust04和GOV2上进行了评估,在模型的三个阶段中均使用BERT-Large可以显著提高BERT-Large在浅池和深池中的性能;
- 在不同阶段应用不同大小的BERT模型,可以权衡效率和精度。
2)Method
fine-tune阶段
该模型使用了基于交互的方式,以查询query为Segment A ,以段落passage为Segment B构建BERT的输入序列S,如下图所示。输出则为最后一层[CLS]的向量表示,以此来获得Segment A和Segment B的相关性得分。
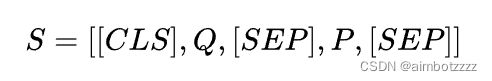
BERT-QE中首先使用在MS MARCO数据集上训练过的BERT模型为基础,然后在目标数据集(如:Robust04)上进行微调。微调阶段首先使用BERT获取目标数据中排名靠前的passages,然后用这些query-passages对,使用如等式1所示的损失函数对BERT进行微调。
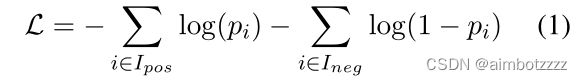
其中,![]() 和
和![]() 分别是相关文档和非相关文档的索引集,
分别是相关文档和非相关文档的索引集,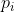 是文档
是文档 与查询相关的概率。
与查询相关的概率。
Rerank阶段
阶段1:首先使用DPH+KL得到k篇粗排文档,基于给定的query与文档使用经过微调的BERT获取如等式2所示的文档的相关性得分,依据这些相关性得分对文档进行初步重排。
![]()
阶段2:将初步重排后的![]() 个文档作为PRF文档,使用滑动窗口的方法将每一篇文档分为长度为m个词项的文本块,如下图所示。相邻的两个滑动窗口最多重叠m/2个词项,也就是说,使用了长度为m,步长为m/2的滑动窗口来把文档划分为文本块。
个文档作为PRF文档,使用滑动窗口的方法将每一篇文档分为长度为m个词项的文本块,如下图所示。相邻的两个滑动窗口最多重叠m/2个词项,也就是说,使用了长度为m,步长为m/2的滑动窗口来把文档划分为文本块。

使用微调后的BERT模型对每个文本块进行相关性评估,选择其中得分最高的![]() 个文本块,用
个文本块,用![]() 代表第i个文本块,这些最相关的文本块集合表示为
代表第i个文本块,这些最相关的文本块集合表示为![]()
![]() 。
。
阶段3:使用阶段2得到的文本块与原始query结合,获得最终的文档排名。过程如下图所示:
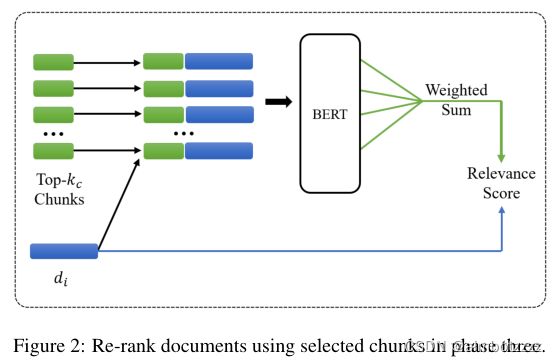
对于每一个文档d,都用阶段2中得到的top文本块来评估文档的相关性。可以理解为文本块与query的相关性得分越高排名就越靠前,如果文档d与这些排名靠前的文本块的相关性得分也很高,那么就代表了文档d和query越相关。将![]() 个文本块与文档d的相关性分数聚合,生成文档的查询扩展项的相关性分数,具体如下:
个文本块与文档d的相关性分数聚合,生成文档的查询扩展项的相关性分数,具体如下:
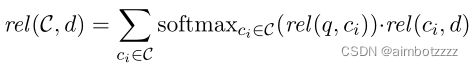
其中,![]() 是query与文本块
是query与文本块![]() 的相关性分数,通过softmax函数进行归一化,获取每个文本块在文档中所占权重;
的相关性分数,通过softmax函数进行归一化,获取每个文本块在文档中所占权重;![]() 为文本块
为文本块![]() 与文档d的相关性分数;通过加权求和,获得了最终的查询扩展项分数。
与文档d的相关性分数;通过加权求和,获得了最终的查询扩展项分数。
最后,将此分数与原始查询线性结合,生成基于反馈与原始查询的组合分数,依据此分数来进行最后阶段的文档排序,具体如下:
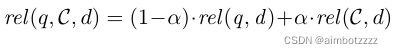
其中, 是控制两部分重要性的超参数。
是控制两部分重要性的超参数。
注意:三个阶段可以分别使用不同规模的BERT模型,例如BERT-QE-LLL就是三个阶段均使用BERT-Large,以此类推BERT-QE-TML即第一阶段Tiny,第二阶段Medium,第三阶段Large。
3)Experimental Setup
模型最大序列长度设置为384,在TPU v3进行训练,batch_size为32,训练2个epoch;使用Adam optimizer,学习率初始值为1e-6。并且进行了五折交叉验证,将quuery等分成5份,每一次,使用三分进行训练、一份进行验证,一份进行测试。
经过测试的最佳超参数为:阶段2中,文本块切割时的窗口大小m为10个words;阶段1中, ![]() 为靠前的10个文档。
为靠前的10个文档。![]() 为10个文本块。在阶段1和阶段3中,使用BERT模型对前1000个文档进行重新排序。
为10个文本块。在阶段1和阶段3中,使用BERT模型对前1000个文档进行重新排序。
使用的BERT模型规模如下图所示:

4)Results

如表3所示,该论文比较了BERT-QE-LLL、BERT Base和BERT Large在Robust04和GOV2上的性能。可以看出,无论是否使用查询扩展,BERT-Large都显著优于所有非BERT基线。在Robust04数据集上BERT-QE-LLL与BERT Large相比,在NDCG@20与MAP@1K这两个评价指标上分别提高了2.5%和3.3%。

如表4所示,BERT-QE-LLL的计算量为BERT-Large的11.19倍,计算成本非常高。如果第三节阶段使用小规模模型,那么计算成本将会急剧下降,可以看到BERT-QE-LMT和BERT-QE-LLS的计算量分别为BERT-Large的1.03倍和1.30倍,但是仍然有改进效果。
5)Analysis
由于计算开销太大,这个方法即使有效果,也很难在工业界应用落地。可以对其进行一些改进,如融入SBERT或者colBERT这种弱交互的模型框架,应该可以有效减少计算开销。