机器学习:朴素贝叶斯(Naive Bayes) --阿里云天池
概述
- 学习地址:
- https://tianchi.aliyun.com/specials/promotion/aicampml?invite_channel=3&accounttraceid=baca918333cb45008b70655b544a5aeadgkm
- https://zhuanlan.zhihu.com/p/26262151
- https://zhuanlan.zhihu.com/p/26329951
- https://www.cnblogs.com/wj-1314/p/10560870.html
- 学习内容:机器学习算法(二): 朴素贝叶斯(Naive Bayes)
- 问题:算法中具体参数没有深究。
- 总结:当我们在探寻问题的发生概率的时候,我们常常会忽略现实中已经存在的先验估计,最终导致错误估计一事件发生的概率。比如,一位女士在大学致力于女权活动,我们预测她毕业后会从事哪份工作。A:女权斗士; B:银行柜员。在其背景描述下,我们可能会推断她成为一名女权斗士的概率大于银行柜员。但如果我们考虑的先验分布,在这个城市女权都是和银行柜员的占比为1:2000。那么在考虑先验分布的情况下,她成为银行柜员的概率应远大于女权斗士。所以在生活中,我们也可以用贝叶斯的思想去估计事件发生的概率,考虑先验分布。
逻辑回归算法
- 概述
- 一、朴素贝叶斯算法逻辑
-
- (一)什么是朴素贝叶斯
- (二)特征条件独立——朴素贝叶斯算法的朴素一词解释
- (三)拉普拉斯平滑:
- (四)朴素贝叶斯分类器的优缺点
- 二、算法实战
-
- (一)莺尾花数据集--贝叶斯分类
- (二)模拟离散数据集--贝叶斯分类
一、朴素贝叶斯算法逻辑
(一)什么是朴素贝叶斯
朴素贝叶斯法 = 贝叶斯定理 + 特征条件独立。
- 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
- 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
贝叶斯公式:

换个表达形式就会明朗很多,如下:
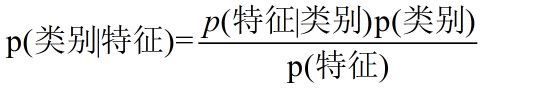
选择后验概率最大的结果,由于分母一致,这里直接去掉分母。最后的计算公式:

(二)特征条件独立——朴素贝叶斯算法的朴素一词解释
假设需要预测一个不帅、性格不好、身高矮、不上进的男生,女生是否愿意嫁给他的概率。

- 其中只需要求解:
p(不帅、性格不好、身高矮、不上进|嫁)
p(不帅、性格不好、身高矮、不上进)
p(嫁)
当计算:
p(不帅、性格不好、身高矮、不上进|嫁) = p(不帅|嫁)*p(性格不好|嫁)*p(身高矮|嫁)*p(不上进|嫁)
其成立的条件需要特征之间相互独立。
(,|)=(|)⋅(|)
- 此处需要假设特征之间相互独立的原因:
- 四个特征的联合概率分布维度高,当特征变得非常多时,用统计来估计概率值非常困难。
- 假如我们没有假设特征之间相互独立,那么我们统计的时候,就需要在整个特征空间中去找,比如统计p(不帅、性格不好、身高矮、不上进|嫁), 由于数据的稀疏性,很容易为0
(三)拉普拉斯平滑:
在处理具体例子中,我们常会遇到某一分类没有数据的问题,基于此引入laplace平滑。
Laplace校准(这就引出了我们的拉普拉斯平滑),它的思想非常简单,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
引入拉普拉斯平滑的公式如下:

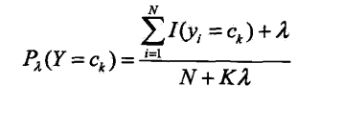
其中ajl,代表第j个特征的第l个选择,[公式]代表第j个特征的个数,K代表种类的个数。
gamma为1,这也很好理解,加入拉普拉斯平滑之后,避免了出现概率为0的情况,又保证了每个值都在0到1的范围内,又保证了最终和为1的概率性质!
(四)朴素贝叶斯分类器的优缺点
- 优点:
(1) 算法逻辑简单,易于实现,使用先验概率估计后验概率具有很好的模型的可解释性。
(2)分类过程中时空开销小
- 缺点:
(1)理论上,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
(2)而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
二、算法实战
(一)莺尾花数据集–贝叶斯分类
# Step1: 库函数导入
import warnings
warnings.filterwarnings('ignore') # 利用过滤器来实现忽略告警。
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB # GaussianNB就是先验为高斯分布的朴素贝叶斯
from sklearn.model_selection import train_test_split
# Step2: 数据导入&分析
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Step3: 模型训练
# 使用高斯朴素贝叶斯进行计算
clf = GaussianNB(var_smoothing=1e-8)
# var_smoothing: Portion of the largest variance of all features that is added to variances for calculation stability.
clf.fit(X_train, y_train)
# Step4: 模型预测
# 评估
y_pred = clf.predict(X_test)
acc = np.sum(y_test == y_pred) / X_test.shape[0]
print("Test Acc : %.3f" % acc)
# 预测
y_proba = clf.predict_proba(X_test[:1])
print(clf.predict(X_test[:1]))
print("预计的概率值:", y_proba)
'''
Test Acc : 0.967
[2]
预计的概率值: [[1.63542393e-232 2.18880483e-006 9.99997811e-001]]
'''
(二)模拟离散数据集–贝叶斯分类
# Step1: 库函数导入
import numpy as np
# 使用基于类目特征的朴素贝叶斯
from sklearn.naive_bayes import CategoricalNB
#CategoricalNB对分类分布的数据实施分类朴素贝叶斯算法。 它假定由索引描述的每个特征都有其自己的分类分布。
from sklearn.model_selection import train_test_split
# Step2: 数据导入&分析
# 模拟数据
rng = np.random.RandomState(1) #random_state=1指的是伪随机数生成器的种子
# 随机生成600个100维的数据,每一维的特征都是[0, 4]之前的整数
X = rng.randint(5, size=(600, 100))
y = np.array([1, 2, 3, 4, 5, 6] * 100)
data = np.c_[X, y]
# X和y进行整体打散
random.shuffle(data)
X = data[:,:-1]
y = data[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Step3: 模型训练&预测
clf = CategoricalNB(alpha=1)
clf.fit(X_train, y_train)
acc = clf.score(X_test, y_test)
print("Test Acc : %.3f" % acc)
# 随机数据测试,分析预测结果,贝叶斯会选择概率最大的预测结果
# 比如这里的预测结果是6,6对应的概率最大,由于我们是随机数据
# 读者运行的时候,可能会出现不一样的结果。
x = rng.randint(5, size=(1, 100))
print(clf.predict_proba(x))
print(clf.predict(x))