期末java突击,Java面试突击——01 Redis(上)
前言:
Redis是Java后端面试中必不可少的一环,因为在日常项目中使用的泛用性,以及功能和场景的多样性,所以也是一个能由浅入深,探查技术栈,复杂场景考察的面试切入点,重中之重。有时候对Redis的深入能让你一些非大厂面试中在面试啊sir心里默默一句:小伙子可以啊。


1 数据结构
1.1基础数据结构
1.1.1 String
小白难度
1)String类型常用的使用?存储形式?
白话版:塞值,取值,塞值取旧值,不存在的时候塞值,塞值并设置过期时间,赛多个键值对
分别对应SET,GET,GETSET,SETNX,SETEX,MSET命令,具体自己搜
存储形式:KEY VALUE形式
2)日常使用场景?
白话版:
缓存:存储key-value,减轻数据库压力
验证码:别忘了设置过期时间
尚可难度
1) 使用场景?
value形式多,比如json串,文件二进制码,整个前端页面,XML,NOSQL的一种形式,适应多场景
计数器:因为Redis是线程安全的,所以可以做计数器
分布式session:存放一个大系统的session信息,用户信息,认证信息,登录态,取代以往的tomcat广播形式,甚至可以往大了在微服务中做认证域/用户态服务
略高难度
1)说一说String数据结构Redis是怎么实现的?
tip:这种问题如果不是很透彻的就别说了,不懂别装,给人留个踏实的好印象,面试啊sir很可能基于这个问题深挖数据结构,到算法,以及基于这种模式优缺点的使用注意点,甚至让你提出优化的思路
这里不深挖,简单说下实现,否则免不了深挖数据结构和优缺点,请体谅下笔者的头发。
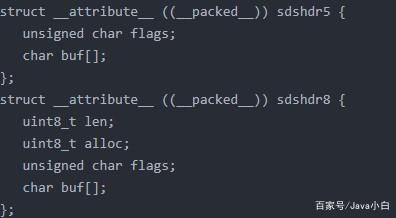
Redis自定义了String类型的数据结构,叫SDS没有使用C的字符串。老版本有三个属性
buf[]:实际存储数据的地方,len:实际数据的长度,free:buf[]未使用的长度
新版本四个属性
buf[]:同上,len:同上 alloc:数据去头去尾后的长度 flag:8位 低三种表示value 的实际类型
改进了什么呢?取值时间复杂度降到1,修改value时降低内存分配次数,兼容c的字符串,可用的方法更多,因为写入和读取格式一样所以更安全
1.1.2 List
1)常用的使用?存储形式?
白话版:塞值,按下标取值,按给定下表范围取值,取值删除,外加阻塞操作(比如取不到值时一直等待),对应LPUSH,LINDEX,LRANGE,LPOP,BLPOP等
存储形式:KEY LIST形式
2) 场景?
白话版:存一组值,要求有序,哈哈哈毕竟小白难度。
1)场景?
白话版:LPOP/LPUSH,RPOP/RPUSH作为栈,LPUSH/RPOP,RPUSH/LPOP作为队列,LPUSH/BRPOP,RPUSH/BLPOP作为消息队列,取不到值时阻塞,但也只是极为简单的消息队列,并且还有丢失数据的风险
特性:有序可重复,消息队列很重要的一点
1)内部实现?
tip:这部分建议有兴趣去结合图看一下。
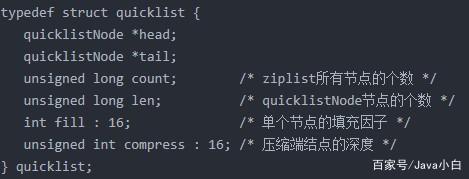
白话版:3.2版本后使用quickList作为数据结构,quickList又由zipList和普通的LinkedList组成,这里着重说一下zipList,看名字知道是个压缩的list,压缩了数据,实际内存大小是按数据大小分配的,所以每次增删数据都会引发内存重新分配,内存波动的开销不小,所以zipList在这里是作为查询用的,并不会作为增删数据的结构,而linkedList作为普通双向链表参考java的实现增删的场景适用。
每个quickList都是一个linkedList,每个节点是一个zipList,元素数量最大2的32次方-1
1.1.3 Hash
1)常用的使用?存储形式?
白话版:增删查,为全部key的值加值操作,元素数量,获取所有,KEY不存在时设值
对应,HSET,HGET,HDEL,HGETALL,HINCRBY,HLEN,HSETNX
特性:最多存放2的32次方-1个数量
白话版:存储对象,存储大结构值,存储多结构层次值
tip:想象下java中的map实现,从来map都不会太简单,取决于这个对象的成员变量数。
白话版:Redis的hash有两种实现,取决于数据量的大小,考虑到了轻实现的少量内存消耗。简易实现是zipmap,实现方式很简单,key后面接value再接key。时间复杂度是n,所以数据多了之后转为dict。
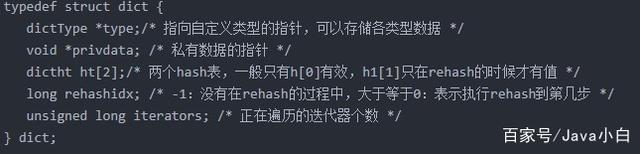
实际内部呢还是取决于dictType,我们看看dictType的实现:
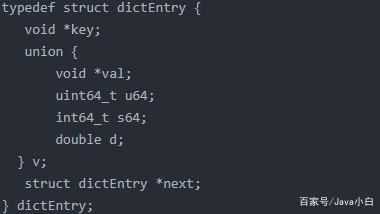
实际是个链表
1.1.4 Set
白话版:因为无序不重复所以与list的区分就是没有两端塞值取值了。但有趣的是和中学数学中的集合一样,支持一堆交集并集操作,是不是有点意思?
特性:无序,不重复
存储形式:key,Set
白话版:一组标记类数据,分别有自己的作用,相互没有干预不需要耦合操作。因为有交并集操作又适用于对标记类数据的划分和计算,统计特征。
基于sadd操作存放标签类数据,sinter交集操作可以匹配人群,数据特征等。spop移出首位数据,结合sranmember可以做随机数抽奖用。
tip:set的实现容易理解,不懂再去看一遍其他解析。利用好交并集操作能简单的处理一些复杂场景
略专业白话版:由编码(数据占几个字节),长度,数组组成。存放字符串的时候利用hash来存储,value为空,来检验key是否存在,以此来判断是否重复。在存入整数类型数据时,为了内存利用考虑会使用int16,int32,int64三种规格来存储,一旦存放大类型数据,小类型会升级,只升级不降级。
1.1.5 Zset
1) 常用使用?存储形式?
白话版:和set除了排序区分很小,完事!
存储形式:key,Zset
2)场景?
白话版:排行榜。看排序的定义是怎样有不少可以使用的场景
白话版:延时队列:这里是考虑到了排序的定义,我们讲排序维度定义为时间呢,那是不是取数据的时候就可以按照时间来划分区间取数据了呢,不断的在取时间时和实际数据的时间比对,符合定义的时间标准就可以取数据了。
2)内部实现?
白话版:两种:也是基于内存使用率考虑,一种是zipLIst/zipMap,参考上面。还有一种叫skipList,看图体会:
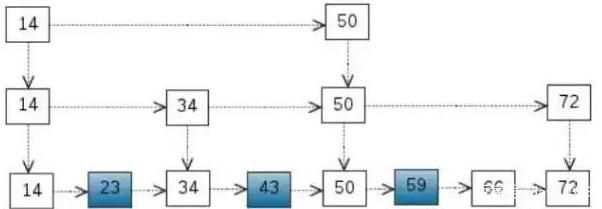
时间复杂度和平衡树没差,像数组,把同值元素划组存放,每个组的头与下个排序值连接,其他元素则直连同样组下标的另一个组元素,细品。
本期结束 以上
笔者简介:
6年经验,一个在路上拼搏的青年。
PS:
欢迎评论,转发,收藏。如有错误,欢迎指正。
请在评论区留下你的建议!
