本文翻译自《A Guide to the BookKeeper Replication Protocol (TLA+ Series Part 2)》,作者 Jack Vanlightly。原文链接:https://medium.com/splunk-maa...。
译者简介
王嘉凌@中国移动云能力中心,移动云Pulsar产品负责人,Apache Pulsar Contributor,活跃于 Apache Pulsar 等开源项目和社区
我们知道关系型数据库中的数据是按表结构来存储,客户端可以将数据存储到表中以及从表中读取数据。Apache BookKeeper 中的数据是按日志结构来存储,客户端以日志的形式读写数据。日志结构是一种只支持数据追加操作的简单数据结构,支持多个客户端同时读取,以及非破坏性读取。
作为数据结构,日志和队列的功能非常相似,区别在于日志支持多个客户端同时独立地从不同位置读取完整的数据。因此,日志必须支持非破坏性读取。而队列则是破坏性读取, 队列的头部元素被读取后会被删除。这意味着队列中的每个元素只会被一个客户端读取到。
作为 Apache Pulsar 数据存储层的 Apache BookKeeper,本身也是一个复杂的分布式系统。BookKeeper 利用多副本机制来实现数据的安全和高可用。多副本指的是每一份 entry 数据都会被复制到多个节点保存,以便在发生部分节点故障时仍然可以提供读写服务,并且保证已保存的数据不会丢失。BookKeeper 使用一套独有的多副本协议,这个协议规定了多个服务节点之间如何协同来实现服务的高可用以及保证数据的安全。
基于分片的日志数据结构
诸如 Apache Kafka 和 RabbitMQ 这样使用基于队列和日志的消息队列,都是将每个队列或分区的数据视为一个整体来存储,这样一来整个数据必须全部存储在同一个存储节点。BookKeeper 使用了一套基于分片的日志数据结构,每个日志数据由一系列的分片数据(Segment)串联组成。Pulsar 的一个 Topic 分区 数据实际上是分为多个数据分片来保存。
我们知道每个 Pulsar Topic 都有一个唯一的 Pulsar broker 作为 owner,这个 broker 负责给所属的 Topic 创建数据分片,并将这些数据分片进行串联以便在逻辑上组成一个完整的日志数据。

图1:Pulsar Topic 的数据由一组数据分片串联组成
BookKeeper 将这些数据分片称为 Ledger,并将它们保存在 BookKeeper server 节点(称为 bookie 节点)。
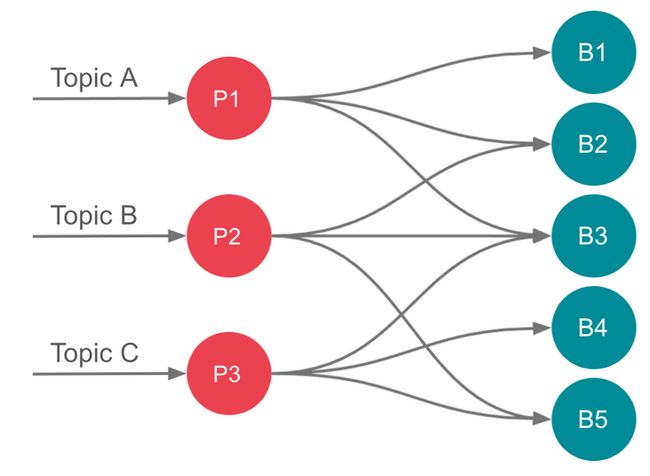
图2:Pulsar broker 将 topic 数据存储到多个 Bookie 节点
BookKeeper 多副本协议和每个 ledger 的生命周期息息相关。多副本协议本身的实现封装在 BookKeeper 客户端类库中, 每个 Pulsar broker 通过调用BookKeeper 客户端类库中的接口来和 BookKeeper 进行交互,如创建 ledger,关闭 ledger,以及读写 entry。这些接口背后包含了非常复杂的协议逻辑,在本篇博客中我们会逐层分析并展示协议的实现细节。
首先,创建 ledger 的客户端即为这个 ledger 的唯一owner,只有 owner 可以往 ledger 里写数据。对于 Pulsar 来说,这个客户端就是作为分区 Topic owner 的 broker,Broker 负责创建 ledger 来组成这个 Topic 的数据段。当这个客户端由于某些原因发生故障时,另一个客户端(对于 Pulsar 来说就是另一个 broker)会介入并接管这个 Topic,这个时候需要修复之前的 ledger 中处于正在复制(under-replicated )状态的 entry 数据(即 recovery 操作)并将 ledger 关闭。
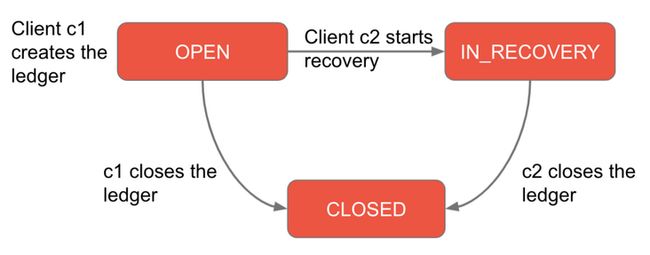
图3: Ledger 的生命周期
每个 Pulsar topic 仅包含一个 open 状态的 ledger 和多个 close 状态的 ledger。所有的写操作都会写入到 open 状态的 ledger,而读操作则可以从任何 ledger 中读取数据。

图4: 写操作只会写入到 open 状态的 ledger
每个 ledger 都会保存到多个 bookie 节点上,每个 ledger 和存有这个 ledger 的 bookie 池(称为 ensemble)的对应关系保存在 ZooKeeper。当 open 状态的 ledger 大小达到了阈值,或者这个 ledger 的 owner 发生了故障,就会关闭这个 ledger 并重新创建一个新的 ledger。根据配置的多副本参数,新创建的 ledger 可能会被保存到另一组 bookie 池上。

图5:Ledger 数据的多个副本保存在多个 bookie 节点,每个 Ledger 的元数据以及一个 Topic 包含的 ledger 信息保存在 ZooKeeper
数据写入 ledger 的过程
BookKeeper 包含以下 ledger 多副本配置相关的参数:
- Write quorum (每份 entry 数据需要写入多少个 bookie 节点), 简称 WQ。
- Ack Quorum (需要从多少个 bookie 节点收到写入成功的响应后可以确认这份 entry 写入成功 ), 简称 AQ。
- Ensemble size (用于存储 ledger 数据的 bookie 池的节点数量), 简称 E。当 E > WQ 时,entry 数据会交错地写入到不同的 bookie 节点。
一条 entry 数据实际写入的 bookie 节点的集合成为写入集合。当 E > WQ 时,相邻的 entry 的写入集合可能会不一样。
Pulsar 为每个 Topic 暴露了设置 AQ、WQ、E 参数的 API 来自定义副本设置。
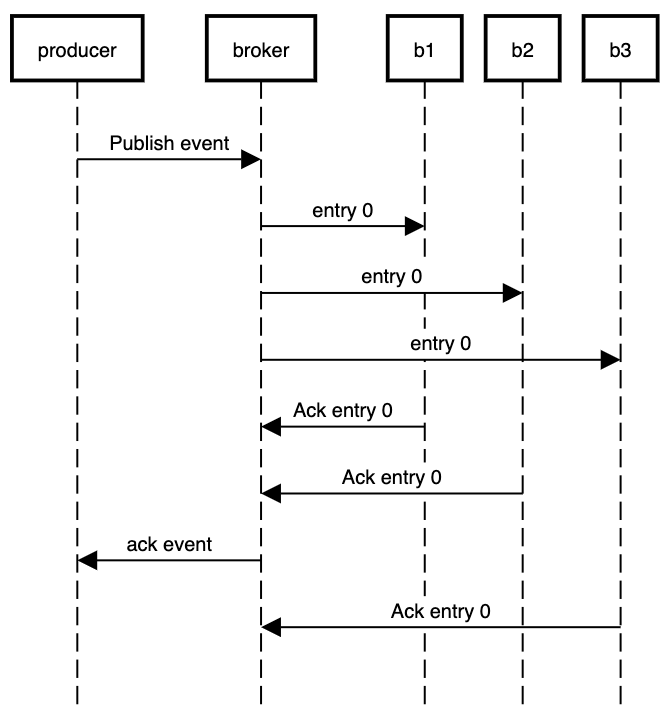
图6:WQ=3,AQ=2 时的消息写入和确认
最后添加确认 (Last Add Confirmed, LAC)
BookKeeper 客户端会持续更新已确认写入的 entry 中连续且最高的 entry ID,我们称之为 Last Add Confirmed (LAC)。这是一条水位线,高于这个 entry ID 的 entry 都还没有被确认写入,而低于和等于这个 entry ID 的 entry 都已经被确认写入。每一条发往 bookie 的 entry 数据中包含了当前最新的 LAC,这样每个 bookie 都可以知道当前 LAC 的值,尽管有一些延迟存在。我们还会在下文看到 LAC 除了作为已提交 entry 的水位线,还发挥着其他作用。
Ledger 数据段
Ledger 本身也可以分成一个或多个数据段(fragment)。当 Ledger 创建时,包含了一个数据段,分配了一个 bookie 池用于存储这个 Ledger 的数据。当发生某个 bookie 写入失败时,客户端会用一个新的 bookie 来替代。这个时候会创建一个新的数据段,并重新发送未确认的 entry 数据和之后的 entry 数据到新的 bookie 上。当 bookie 再次写入失败时,又会再次创建一个新的数据段,以此类推。Bookie 写入失败并不意味着这个 bookie 节点不可用,网络波动等其他情况也会造成单次的写入失败。不同数据段的数据存储在不同的 bookie 池上。数据段也通常被认为是写入集合(Ensemble)。

图7:第二个数据段的创建过程
Ledger 数据段可以看作是告诉 BookKeeper 客户端去哪里找到某个 ledger 中的 entry 数据的元数据。Bookie 节点自身是不知道这些元数据信息的,它们只负责存储接收到的 entry 数据并创建基于 ledger ID 和 entry ID 的索引。
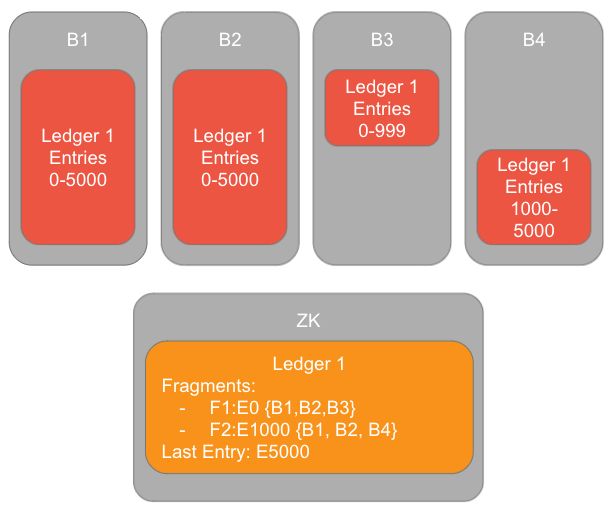
图8:往 B3 bookie 节点写入 entry 1000 失败并导致 ledger 创建第二个数据段
从 ledger 读取数据的过程
从 ledger 中读取数据的操作分为以下几种情况:
- 正常读取 entry 数据
- 长轮询读取 LAC 数据
- Quorum LAC 机制下的读取数据
- 恢复性读取数据
和写数据不一样的是,我们只需要读取一个存有数据的 bookie 节点就可以得到想要的数据。如果这次读取失败了,也只需要从存有这个数据其他副本的 bookie 节点上重新读取数据即可。
客户端通常只希望读取到已确认的数据,所以只会读取到 LAC 值标识的位置。在读取历史数据时,bookie 节点会依据当前的 LAC 值来通知客户端何时停止读取。当客户端读取到 LAC 值并停止读取时,可以发起长轮询读取 LAC 数据。这个请求会先被 bookie 挂起,直到有新的 entry 数据被确认时才响应并返回新的 entry 数据。
另外两种读取数据的情况主要发生在数据修复时,我们稍后再介绍。
完成不同的操作需要不同的响应数量
完成不同的操作需要从 bookie 节点接收到的成功响应的数量不一样。比如,对于正常读数据的操作,只需要从一个 bookie 节点成功收到响应即可完成。而有些操作则需要从多个 bookie 节点(quorum)收到成功的响应才可完成。
这些操作根据需要收到响应数量的不同,可以分为以下几种类型:
- Ack quorum (AQ)
- Write quorum (WQ)
- Quorum Coverage (QC) QC = (WQ - AQ) + 1
- Ensemble Coverage (EC) EC = (E - AQ) + 1
Quorum Coverage (QC) 和 Ensemble Coverage (EC) 都满足于以下定义(以下两种定义本质上相同,只是说法不同),QC 和 EC 的区别仅在于“集合”的范围 :
- 对于指定请求,从足够多的 bookie 节点收到成功响应,使得在给定集合中 ack quorum(AQ)数量的 bookie 节点组成的任意组合中,都至少包含一个收到成功响应的 bookie 节点。
- 对于指定请求,从足够多的 bookie 节点收到成功响应,使得在给定集合中不存在 ack quorum(AQ)数量的 bookie 节点没有收到成功响应。
对于 Quorum Coverage (QC) 来说,这个集合是指某个 entry 的写入集合。QC 主要用于保证单个 entry 数据一致性的场景,如校验单个 entry 写入操作是否已被客户端确认。对于Ensemble Coverage (EC) 来说,这个集合是指存储当前 ledger 数据段对应的 bookie 池,EC 主要用于保证 ledger 数据段一致性的场景,如设置 ledger 的 fence 状态。
WQ 和 AQ 主要用于写数据,而 QC 和 EC 主要用于 ledger 修复过程。
Ledger 修复的过程
前面我们讲到每个 ledger 只有一个客户端作为 owner,当这个客户端不可用时,另一个客户端就会介入并触发 ledger 修复过程然后关闭这个 ledger。对于 Pulsar 来说就相当于作为一个 Topic owner 的 broker 变得不可用,然后这个 Topic 的所有权转移到另一个 broker 上。
Ledger 修复过程包括找到最高的已被 bookie 确认的 entry ID,保证在这之前的每个 entry 都已复制了足够多的副本数量。之后将这个 ledger 关闭,此时会将这个 ledger 的状态设置为 CLOSED,并将最新的 entry ID 设置为最后被确认的 entry ID。
如何防止脑裂
BookKeeper 是一个分布式系统,这意味着网络波动可能会导致集群被分隔成两个或者更多的区块。我们设想如果一个客户端和 ZooKeeper 断开连接,那么这个客户端就被认为已不可用,另一个客户端会接管这个客户端负责的 ledger 并开始 ledger 修复流程。但这个客户端可能仍在正常运行,它可以正常的连接到 BookKeeper 集群,于是就会出现两个客户端试图同时操作同一个 ledger,这种情况就属于脑裂。脑裂是指一个分布式系统由于网络波动分裂为多个独立的系统,在一定时间后网络恢复导致的数据不一致的情况。
BookKeeper 引入了 fence 这个概念来防止脑裂的发生。当第二个客户端 (例如另一个 Pulsar broker)试图开始 ledger 修复流程时,会先将 ledger 设置为 fence 状态,在这个状态下 ledger 会拒接所有新的写入请求。当足够多的 bookie 节点将这个 ledger 状态设置为 fence 时,就算第一个客户端仍然处于正常运行状态,它也不能再进行任何新的写入操作。然后第二个客户端就可以在没有其他客户端会继续写入数据或者试图修复同一个 ledger 的安全状态下开始 ledger 修复流程。
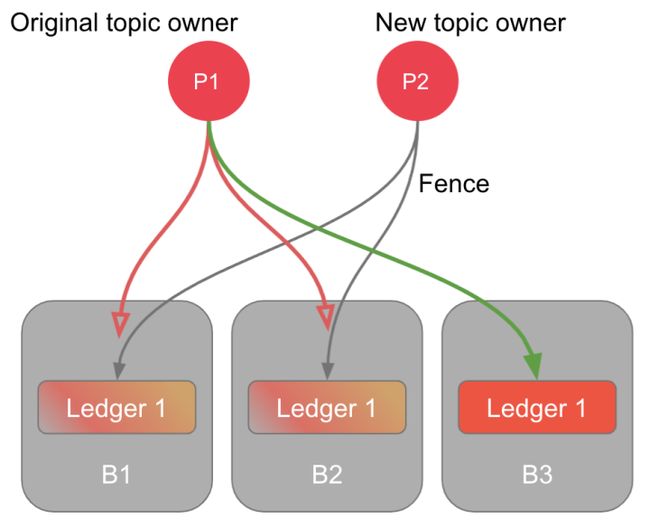
图9:一个新的 Topic owner 开始将 ledger 设置为 fence,原先的 owner 写入新数据时无法写入 Ack Quorum 设定的副本数,则无法完成写入
修复流程第一步 — 设置 fence 状态
将 ledger 设为 fence 状态,并确认 LAC 的值。
Fence 请求实际上是一次 Ensemble Coverage 类型的读请求,获取 LAC 的值并带有 fencing 标识。每个 bookie 节点收到这个请求时会将这个 ledger 的状态设为 fence,并返回这个节点上对应 ledger 的 LAC 值。当客户端从足够多的 bookie 节点收到响应时,就表示请求成功可以进行下一步操作。那么从多少个 bookie 节点收到响应才算足够呢?
我们将 ledger 设置为 fence 状态是为了防止之前的客户端继续往 ledger 里写入数据。所以我们只要保证还没有将这个 ledger 设置为 fence 状态的 bookie 节点的数量小于设置的 Ack Quorum 值,那么之前的客户端因为无法收到足够多的写入确认而无法写入新数据。新的客户端发起的 fence 操作不需要等到所有的 bookie 节点都将这个 ledger 设置为 fence,只需要满足还没有设置为 fence 状态的 bookie 节点数小于设置的 Ack Quorum 就可确认 fence 操作完成。满足这个条件所需要收到的响应数量就是 Ensemble Coverage。
修复流程第二步 — 修复 entry 数据
接下来,客户端从 LAC + 1 的 entry ID 开始发送恢复性读取数据的请求,并将这些 entry 数据重新写到新的 bookie 池中。写操作属于幂等操作,也就是说如果这个 entry 已经写入到了某个 bookie 节点,再次向这个节点写入同样的 entry 不会造成数据重复写入。客户端会持续进行读和写的操作直到读完所有数据。确保在关闭 ledger 之前,这个 entry 的写入集合中的所有 bookie 节点都写入了该 entry 的副本。
正常的读操作只需要从一个 bookie 节点接收到响应。与之不同的是,Recovery读操作需要根据从这个 entry 的所有写入集合的 bookie 节点上收到的响应内容来明确这个 entry 是否已确认。具体来说有以下两种情况:
- 已确认 :收到 Ack Quorum 数量的成功响应
- 未确认 :收到 Quorum Coverage 数量的数据不存在响应 (已写入这个 entry 数据的 bookie 节点数量未达到 Ack Quorum)
如果所有响应都已收到,但两个阈值都未达到,那就无法判断这个 entry 是否已确认,修复流程就会终止(可能存在收到其他错误类型响应的情况,如网络波动,这种情况无法判断 entry 是否已成功写入对应 bookie 节点)。修复流程可以重复执行直到可以明确每个 entry 最终的确认状态。
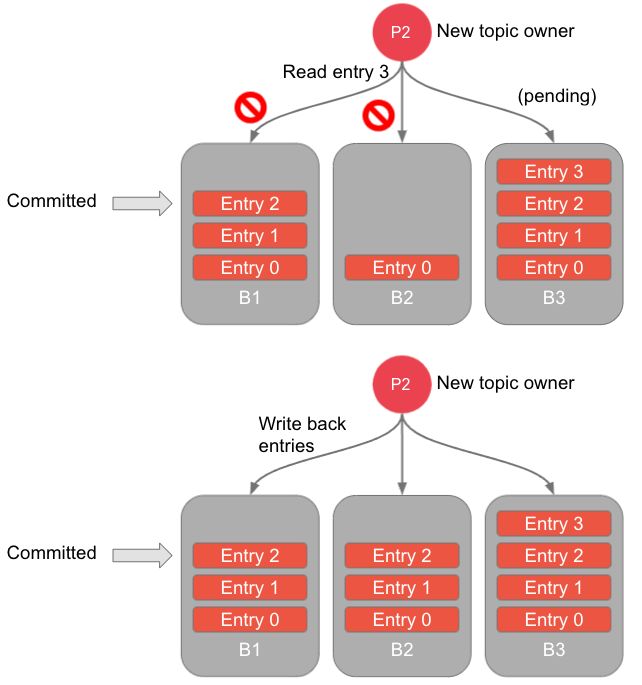
图10:新的客户端在读取 entry 3 时收到了足够多的数据不存在请求,可以判断 entry 3 的状态为未确认。然后保证到 entry 2 为止的数据都复制到足够多的副本数
修复流程第三步 — 关闭 Ledger
一旦明确了所有已确认的 entry ,且这些 entry 复制了足够多的副本数,客户端就会关闭 ledger。关闭 ledger 的操作主要是对 ZooKeeper 上 ledger 元数据的更新,将状态设置为 CLOSED,并将 Last Entry Id 设置为最新的已确认的 entry ID。这些操作和 bookie 本身不相关,bookie 也不会感知 ledger 是否被关闭,bookie 自身没有 open 或 closed 的概念。
ZooKeeper 上元数据的更新是一个基于版本控制的 CAS 操作。如果有另一个客户端同时在修复这个 ledger 并且已经将 ledger 关闭,那么这次 CAS 操作就会失败。通过这种方式可以防止多个客户端同时对同一个 ledger 进行修复操作。
总结
本篇博客介绍了 BookKeeper 多副本协议的大部分实现内容。需要记住的重点是,bookie 节点只是单纯用来存储和读取 entry 数据的存储节点,在 BookKeeper 客户端中包含了创建 ledger、选择存储 ledger 的 bookie 池、创建 ledger 数据段的操作,通过 Write Quorum 和 Ack Quorum 来保证多副本的机制,以及在发生故障时对 ledger 进行修复和关闭等一系列逻辑。
相关阅读
Pulsar Storage 特别兴趣小组(SIG)已成立!扫描下方️ Pulsar Bot 二维码,回复 BookKeeper 加入 Pulsar Storage 讨论群。

扫码加入
关注公众号「Apache Pulsar」,获取更多技术干货