python3 qq音乐爬取歌手名字,专辑,歌曲时间,播放链接
**爬取qq音乐的小案例**
1.寻找真正的客户端(client_search)(客户端搜索)
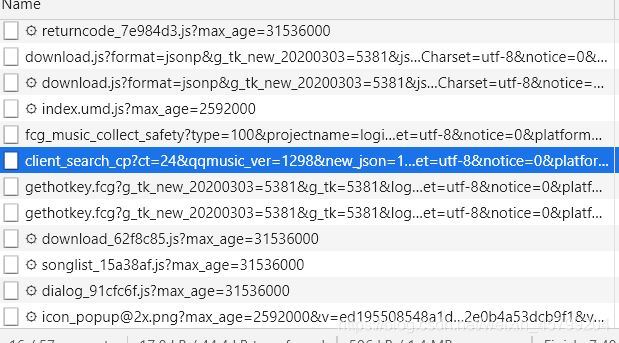
2.找到真正的url
![]()
瞧见是不是很头疼,别担心,你只需要这些(https://c.y.qq.com/soso/fcgi-bin/client_search_cp),后面的都是参数(说法不是很准确)
3.写入参数
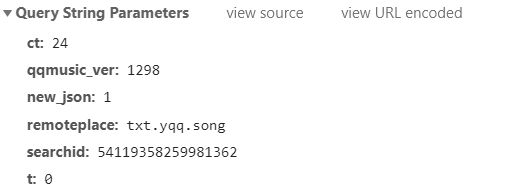
在这个位置下的所有参数复制过来,就像这样
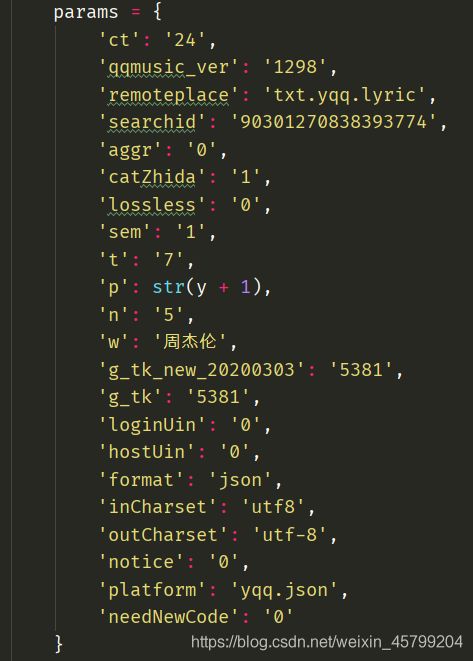
我们不难发现,p代表的是页数(我这里使用了循环,详情看一下代码),w的话代表歌手名字(可以进行更改)
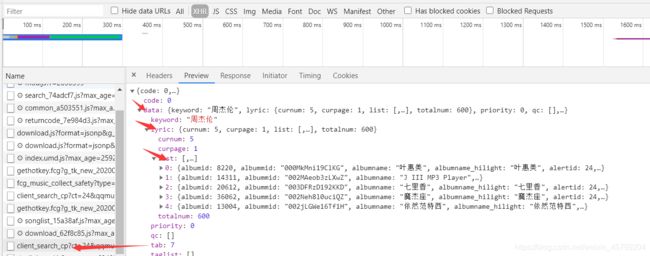
然后我们可以获取到歌手的名字,歌曲专辑,音频时间,播放链接(这一部分的代码在parse_page这个函数中)
然后就到了最要命的歌词环节,shit,头疼
1.点击歌词,Network

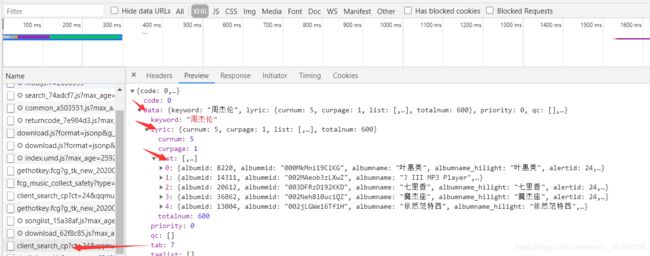
我们可以看到一页只有5首哥的歌词,然后我们进行爬取(在lyric_a代码中)
2.我们需要更改params参数,同样在最下面,与上面寻找一致
3.使用openyxl放入excel表格中
(1)导入openyxl模块
(2) 创建

(3)放入并命名excel
这是例图
这里不用csv是因为初学,技术太菜,出来全是逗号(真·逗号分隔符)

以下是完整代码模块:
import requests,openpyxl
import csv
import re
HEADERS = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"Referer":"https://y.qq.com/portal/search.html",
"Origin":"https://y.qq.com"
}
# 创建工作簿
wb=openpyxl.Workbook()
# 获取工作簿的活动表
sheet=wb.active
# 工作表重命名
sheet.title='lyrics'
sheet['A1'] ='歌曲名' # 加表头,给A1单元格赋值
sheet['B1'] ='歌词' # 加表头,给B1单元格赋值
def parse_page(url):
"""获取歌手名字,专辑,歌曲时间,播放链接"""
for x in range(5):
# 将参数封装成字典
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.song_next',
'searchid': '64405487069162918',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': str(x + 1),
'n': '20',
'w': '周杰伦',
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
# 调用get方法,获取信息
response = requests.get(url,headers=HEADERS,params=params)
# 校验状态码
#print(response.status_code)
# 使用json方法,将response对象转为列表/字典
json_music= response.json()
# 获取歌单列表
list_music = json_music["data"]["song"]["list"]
a = []
for music in list_music:
name = music["name"] # 获取歌曲名
zhuanji = music["album"]["name"] # 专辑
video_time = str(music["interval"])+"秒" #播放时间
viedo_url = 'https://y.qq.com/n/yqq/song/'+music["mid"]+".html"
a = [name,zhuanji,video_time,viedo_url]
#print(a)
def lyric_a(url):
ii = 1
for y in range(5):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'remoteplace': 'txt.yqq.lyric',
'searchid': '90301270838393774',
'aggr': '0',
'catZhida': '1',
'lossless': '0',
'sem': '1',
't': '7',
'p': str(y + 1),
'n': '5',
'w': '周杰伦',
'g_tk_new_20200303': '5381',
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
lyric_response = requests.get(url,headers=HEADERS,params=params)
json_lyric = lyric_response.json()
list_lyric = json_lyric['data']['lyric']['list']
for music_lyric in list_lyric:
name = music_lyric['songname'] # 名字
ii += 1
cc = music_lyric['content'] # 歌词信息
# 这里使歌词信息更加美观
cc = re.sub(r"[\\n ]",",",cc)
cc = re.sub(r",,,",",",cc)
# 用append函数多行写入Excel
sheet.append([name,cc])
# 最后保存并命名这个Excel文件
wb.save('Jay.xlsx')
def main():
url = "https://c.y.qq.com/soso/fcgi-bin/client_search_cp"
lyric_a(url)
if __name__ == '__main__':
main()
好的,结束了呢,青山不改,绿水长流,我们下篇见。