Python(三)pandas数据分析、Seaborn的数据可视化
目录
一、Pandas
二、Pandas-Serise
三、DataFrame
1、DataFrame的创建
2、 删除操作:
3、获取操作:
获取列数据:
获取行数据:
根据具体条件获取数据
4、文件操作
四、使用jupyter notebook完成文件相关操作
五、Seaborn可视化
六、pandas数据写入mysql
七、pandas数据清洗
(一)处理缺失数据
(二)分析数据问题
1、没有列头
2、空值数据
3、非法数据
4、数据单位不统一
5、空值填充
6、切分为多列
一、Pandas
1、pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数
2、pandas兼具NumPy高性能的数组计算功能以及电子表格和关系型数据库灵活的数据处理功能
3、对于金融行业的用户,pandas提供了大量适合于金融数据的高性能时间序列功能和工具
4、学统计的人会对R语言比较熟悉,R提供的data.frame对象功能仅仅是pandas的DataFrame所 提供的功能的一个子集
5、pandas含有使数据分析工作变得更快更简单的高级数据结构和操作工具,它是基于Numpy构 建的,有很多操作是类似的
6、约定本小节编写程序之前默认运行了import pandas as pd和 from pandas import Series,DataFrame
7、pandas的下载:控制台中输入命令:pip install pandas进行下载pandas
二、Pandas-Serise
Series是一种类似于一维数组的对象,由数据(各种NumPy数据 类型)以及与之相关的数据标签(即索引)组成
可以通过字典构建Series对象,Series对象的索引也是可以修改的
举例:
import pandas as pd
data = [1, 2, 3]
series1 = pd.Series(data=data)
print(series1, type(series1))
# 获取下标为0的数据
print(series1[0])
print(">" * 70)
# 通过字典创建series
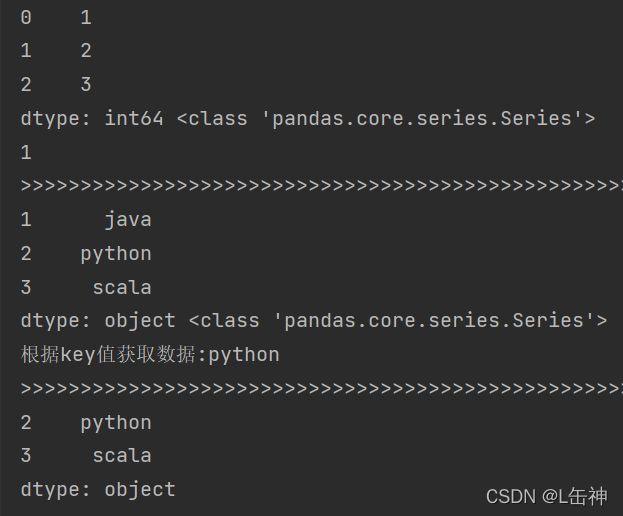
data1 = {1: "java", 2: "python", 3: "scala"}
series2 = pd.Series(data=data1)
print(series2, type(series2))
# 根据key值进行获取数据
print("根据key值获取数据:"+series2[2])
print(">" * 70)
# 创建series给定下标 根据给定key值进行创建
series3=pd.Series(data=data1, index=[2, 3])
print(series3)结果:
相关函数:获取最大值与获取最小值:series1.max();series1.min()
结果:3 1
三、DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每 列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,可以看做由Series组成的字典
1、DataFrame的创建
DataFrame的创建可以通过字典创建,也可以通过列表创建,在使用列表创建时,默认情况下输出的列名称为数字顺序,可以在创建时加入设置列名称:columns=... ...
# 创建dataframe
# 通过字典进行创建
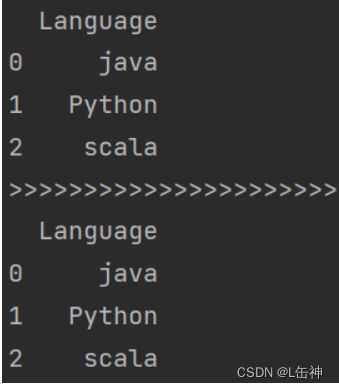
data2 = {"Language": ["Python", "java", "scala", "sql"],
"application": ["pySpark", "Hadoop", "Spark", "Hive"]
}
df1 = pd.DataFrame(data=data2)
print(df1)
# 通过列表进行创建 可以增加列名称
data3 = [["java", "1"], ["Python", "2"], ["scala", "3"]]
df2 = pd.DataFrame(data=data3, columns=["language", "year"])
print(df2, type(df2))结果:

当dataframe中只有一列数据时,仍然表示的是一个dataframe,而不是series
data4 = [[1], [2], [3]]
df3 = pd.DataFrame(data=data4)
print(df3, type(df3))结果:

2、 删除操作:
使用Drop方法进行删除操作
格式:DataFrame.drop(labels=["行/列名称"],axis=0:表示行/1:表示列)
当想要进行删除操作时,需要指定删除的是行数据还是列数据
这里的指定有一个变量axis,若在进行删除操作时,不加axis的值,axis默认为0,表示删除行数据
但是这里进行删除后的dataframe是一个新的dataframe,若想使被删除的原dataframe在删除后变为删除后的表,需要使用inplace方法进行替换
格式:DataFrame.drop(labels=["行/列名称"],axis=0:表示行/1:表示列,inplace=True)
这里的inplace默认为False
# 删除df2中的列数据Number
df4=df2.drop(labels=["Number"], axis=1)
print(df4)
# 这里删除后的数据存到了df4中,df2中并未被删除
#使用inplace使df2中数据也被删除
print(">" * 70)
df2.drop(labels=["Number"], axis=1, inplace=True)
print(df2)结果:
3、获取操作:
dataframe中进行获取数据时,有多种获取数据的方法
获取列数据:
1、通过key(列)获取数据
2、通过.+列名称进行获取
获取行数据:
1、通过dataframe.loc[index(行下标)]进行获取固定下标的一行数据
2、通过dataframe.head()进行从前获取5行数据
3、通过dataframe.tail()进行从后获取5行的数据
举例:
# 获取数据,通过key(列)进行获取
print(">" * 70)
print(df["application"], type(df["application"]))
# 通过.列名称获取
print(df.application,type(df.application))
data5 = {
"Language": ["A", "B", "C", "D", "E", "F", "G"],
"words": ["a", "b", "c", "d", "e", "f", "g"]
}
df5 = pd.DataFrame(data5)
print(df5.loc[2]) # 获取下标为2的数据
print(df5.head()) # 获取前5行数据
print(df5.tail()) # 获取后5行数据结果:

根据结果得出:通过列进行取值后,取出的数据为一个Series
获取行数据结果:
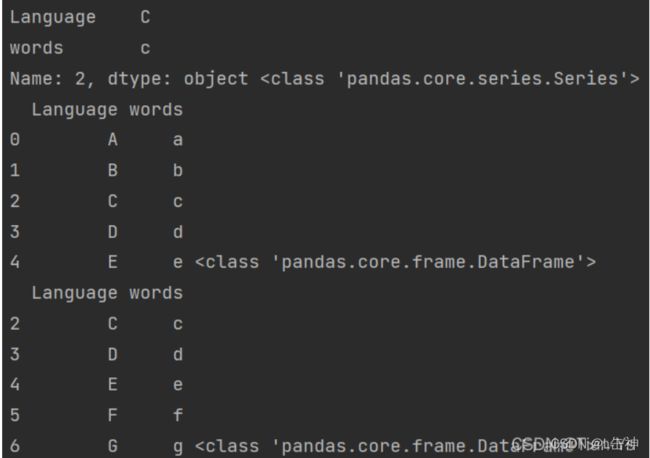
根据结果得出: 通过行获取的数据,是一个DataFrame
根据具体条件获取数据
创建一个DataFrame,从其中获取到年龄小于18的学生信息
# 创建一个学生DataFrame
data6 = {
"name": ["张同学", "李同学", "王同学"],
"age": [17, 19, 16]
}
df6 = pd.DataFrame(data=data6)
print(df6)
# 获取年龄小于18的结果
print("----获取年龄小于18的结果----")
print(df6["age"] < 18)
# 进一步获取年龄小于18的同学的信息
print("----进一步获取年龄小于18的同学的信息----")
print(df6[df6["age"] < 18])结果:

使用describe可以针对Series或者DataFrame列进行计算汇总统计
对df6进行汇总统计:print(df6.describe())

数据1到3的内容表示他的四分位数
4、文件操作
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,常用的函数为read_csv和read_table
read_csv:从文件、URL、文件型对象中加载带分隔符 的数据。默认分隔符为逗号。
read_table:从文件、URL、文件型对象中加载带分隔 符的数据。默认分隔符为制表符(“\t”)
read_csv中可以指定name的值,即读取到的文件存入dataframe中的列名称,使用names=[... ...]
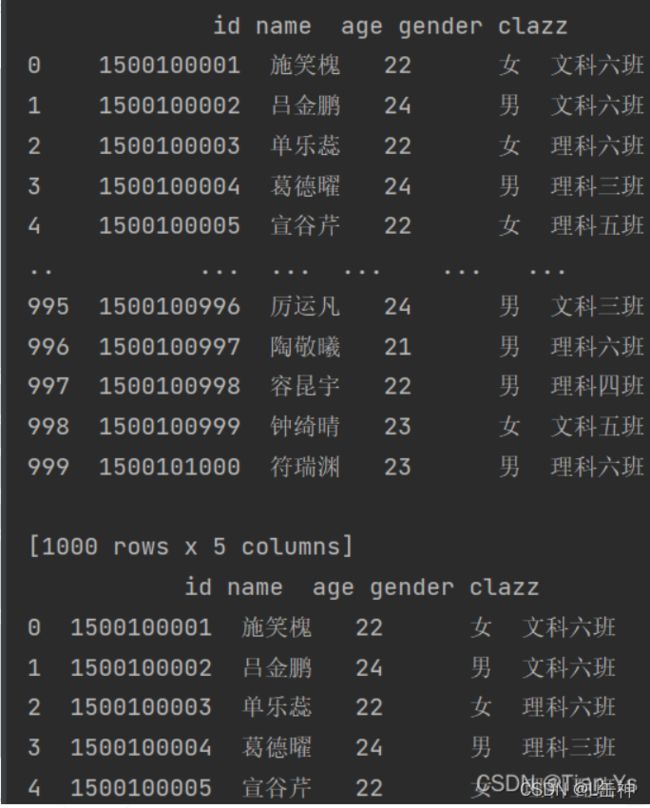
# 读取文件
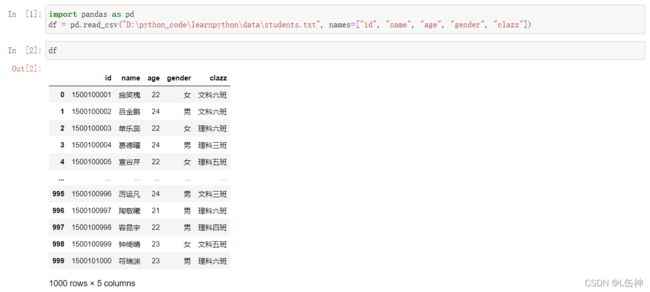
df7 = pd.read_csv("D:\PyCharmProjects\day47\data\students.txt", names=["id", "name", "age", "gender", "clazz"])
print(df7)
print(df7.head())结果:
read_csv/read_table常用参数介绍:
path :表示文件系统位置、URL、文件型对象的字符串
sep/delimiter:用于对行中个字段进行拆分的字符序列或正则表达式
header:用做列名的行号。默认为0(第一行),若无header行,设为None
names:用于结果的列名列表,结合header=None skiprows: 需要忽略的行数
na_values:一组用于替换NA的值
nrows:需要读取的行数(从文件开始处算起)
verbose:打印各种解析器信息,比如“非数值列中缺失值的数量”
encoding:用于unicode的文本格式编码。例如,“utf-8”表示用UTF-8 编码的文本
四、使用jupyter notebook完成文件相关操作
在控制台输入jupyter notebook启动jupyter,跳转页面至网页,没有跳转就手动点击网址跳转
在跳转后的网址中新建一个ipynb文件

点击该名称,可以重命名该文件,初次创建该文件时,文件名默认为Untitled


在jupyter下先导入pandas,再执行读取文件操作
取该文件前一百行数据

需求:统计各班级的人数
实现:

![]()
这里可以看见对该结果进行获取类型,发现是Series
想要将其转换为DataFrame需要加上命令:reset_index()

进一步改进,更改列名id为人数cnt,并将结果替换原来的clazz_num保存

以cnt的值从大到小实现排序:


读取成绩文件score.txt,设置列名

更改列名称并替换:

将该成绩表与学生表相关联:
实现关联需要使用merge方法
格式:左表.merge(右表,left_on="左表关联列",right_on="右表关联列",how='关联方式')
left_on表示左表中用来关联的列名称
right_on表示右表中用来关联的列名称
how表示用来关联的方式,类似于sql中连表联查中的左联右联和内联,这其中的关联方式有很多种:left,right,outer,inner,cross

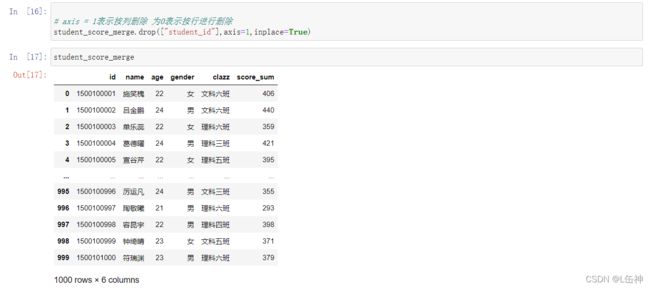
改进:有关学生id出现了两个,删除其中一个student_id
统计每个班的前三名,先进行分组,然后使用rank函数进行排名操作,并且设置ascending=False
使连接后的表进行倒序排列

五、Seaborn可视化
。。。。。。。。。。。。。。。。。
六、pandas数据写入mysql
写入MySQL操作需要先下载包sqlalchemy
下载完之后进入到jupyter中
为虚拟机创建一个新的数据库,用于将数据写入该数据库中,这里创建一个stu数据库
写入MySQL,使用to_sql即可写入MySQL中,具体流程可以看成:
获取引擎,生成执行器,执行to_sql,具体格式如下:
结果:生成日志文件,自动创建表,再执行写入操作
进入到表中检验:进入stu数据库再进行查看


pandas读取数据库数据
使用read_sql进行读取数据库数据

七、pandas数据清洗
(一)处理缺失数据
读取所要清洗的数据

发现表中有的地方是NaN,表示null值
缺失数据是最常见的问题之一。产生这个问题有以下原因:
1、从来没有填正确过
2、数据不可用
3、计算错误
无论什么原因,只要有空白值得存在,就会引起后续的数据分析的错误。下面介绍几个处理缺失数据的方法:
1、为缺失数据赋值默认值
2、去掉/删除缺失数据行
3、去掉/删除缺失率高的列
使用fillna填充null值为空字符串:


加上赋值操作:country列中的第五行的NaN值被换为了空字符串

将电影时长duration列中的NaN使用均值填充:
上面提到过表中取出一列数据,该数据为Series类型,所以可以使用Series中的mean方法求出均值,再将均值填充NaN

删除某行全部为null值的数据
movie.dropna(how='all'),该表中没有全部为null的数据,故执行后不改变
规范化数据类型
movie.info:查看当前表的各列属性
加载数据集时指定数据类型:加载该数据集时可以把该数据集中的title_year类型指定为str类型
data = pd.read_csv('./data/movie_metadata.csv', dtype={'title_year':str})
将内容转为大写
将genres中的内容全部转为大写

切分数据
将导演director_name列的名字切分为两列数据

结果:

(二)分析数据问题
1、没有列头
读取数据时发现该数据集没有列头,需要再加载数据集时加入列名


2、空值数据
删除其中行数据全部为null值的行

3、非法数据
观察发现这其中的name列含有非法的字符
去除非法字符:

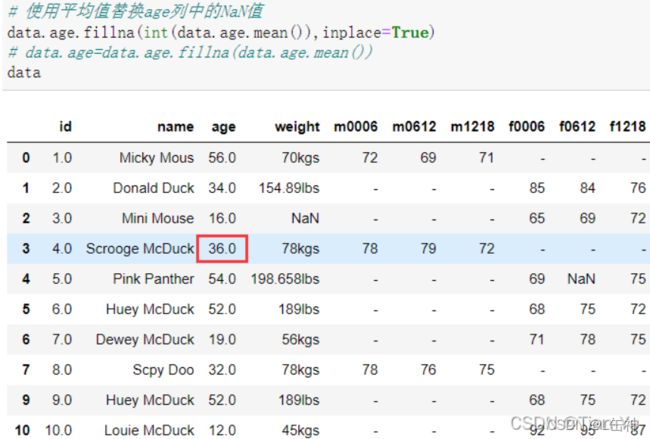
用平均值替换age中的NaN值:
4、数据单位不统一
表中weight列的数据单位不统一,需要将lbs单位换位kgs,同时用均值填充NaN值:
这里由于取出的数据是一个Series类型,所以不可以转为int,使用map方法实现该操作
将数据除去单位换算为千克单位的数值,通过切分[:-3]从后往前的第四个数取出,先转为str,再转为float,再换算,换算后转为int不保留小数


换算之后将其加入到data表中

5、空值填充
将空值填充为平均值:
过程中使用astype将取到的没有单位的数据转为int类型,然后才能求平均值

将f0612列中的空值填充为均值:

6、切分为多列
需求:
将后六列变为三列,分别表示性别,时间段,心率
需要使用melt方法
melt方法参数:
参数一:具体的dataframe;参数二:id_vars:表示不需要变更的列
参数三:需要转换的列的新列名;参数四: value_name表示原表中数值列的列名
使用melt方法对表进行初步转换:

结果:共六十行

去除为'-'的行:结果共三十行
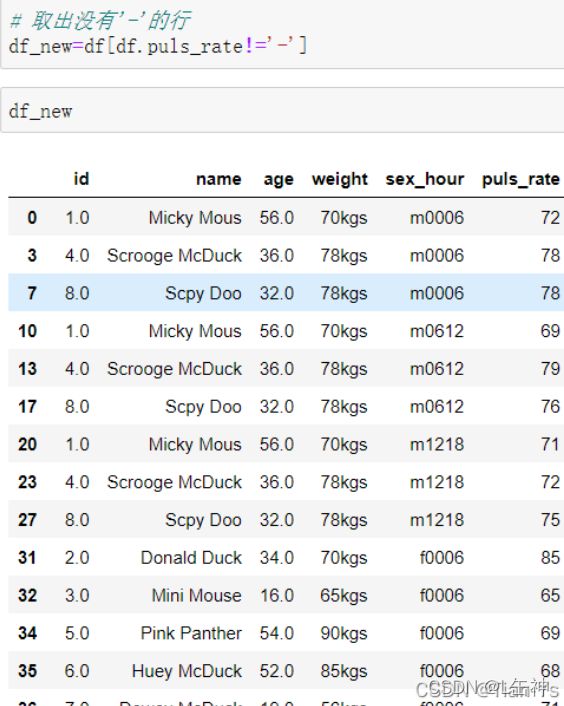
将取出的数据变成一个新的dataframe:

将新的dataframe的sex_hour进行切分:

结果:共三十行
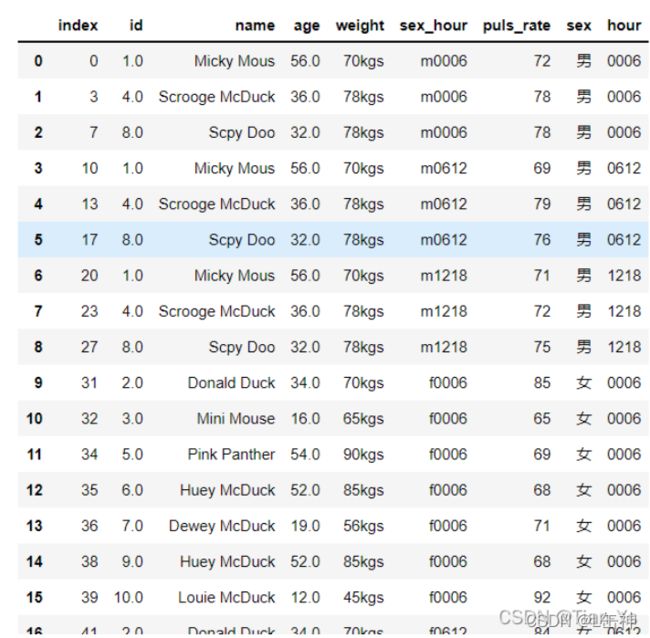
这里已经基本完成了该需求,可以改进:将多余的sex_hour列删除:

