Machine Learning——CV系列(一)——Python+OpenCV核心操作(1)
文章目录
- 一、基本操作
-
- 1.1 OpenCV读取、写入和保存图像
- 1.2 色彩空间的转换
- 1.3 基本图形绘制
- 1.4 阈值操作
-
- 1.4.1 OTSU二值化
- 1.4.2 自适应阈值二值化
- 1.5 图像上的运算
-
- 1.5.1 图像混合
- 1.5.2 按位运算
- 1.6 图像的几何变换
-
- 1.6.1 仿射变换(理解为图像里的线性操作)
- 1.6.2 透视变换
- 二、图像形态学操作
-
- 2.1 膨胀和腐蚀
- 2.2 五个基本算法
一、基本操作
1.1 OpenCV读取、写入和保存图像
读取/保存
存储空间:w*h*c*p(p是位宽)
位宽:一个数据在内存占多少位,一个位用0或1表示,8位=1字节,rgb存储最大值是255
压缩:分为有损压缩和无损压缩
jpg是对位图进行了压缩,jpg是有损压缩
png一般4个通道,α透明度
import cv2
img = cv2.imread(r"1.jpg",0)#0代表灰度图
# print(type(img)) # 

写入
import cv2
import numpy as np
img = np.empty((200,200,3),np.uint8)
img[...,0]=255# bgr
img[...,1]=0
img[...,2]=0
img = img[...,::-1]# rgb
cv2.imwrite("1ww.jpg",img)

读摄像头或视频
cap = cv2.VideoCapture(0) #创建视频对象
# cap = cv2.VideoCapture("car.mp4")
# cap = cv2.VideoCapture("rtsp协议地址")
while True:
ret, frame = cap.read() #ret是否读成功,frame图像
cv2.imshow('frame', frame)
if cv2.waitKey(30) & 0xFF == ord('q'):# 停10ms或q跳出循环
break
cap.release()
cv2.destroyAllWindows()
1.2 色彩空间的转换
RGB在cv2中顺序其实是BGR,但是其颜色过渡(指从红到绿到蓝)是离散的,
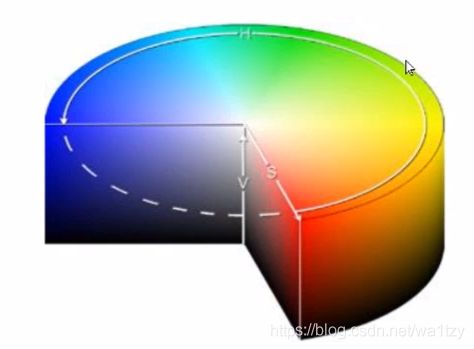
为了便于连续操作,就可以使用HSV颜色空间。
色调H[0-179]:逆时针顺序 => 红-绿-蓝。
饱和度S[0-255]:饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成
是某种光谱色与白色混合的结果。中心饱和度0,是白色;边缘饱和度达到最高。
明度V:[0-255]:V是竖着圆柱体的方向,表示颜色明亮的程度 。表面最明亮,
越往下颜色越深,底下是黑色。
色彩空间:RGB/RGBA/GRAY/HSV/YUV

HSV中,我们按颜色提取变得更加方便
例:提取图像中的字
import cv2
import numpy as np
img = cv2.imread("11.jpg")
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower_blue = np.array([100, 200, 100])
upper_blue = np.array([200, 255, 200])#字的颜色大概值
mask = cv2.inRange(hsv, lower_blue, upper_blue)#和运算
res = cv2.bitwise_and(img, img, mask=mask)
cv2.imshow('frame', img)
cv2.imshow('mask', mask)
cv2.imshow("res",res)
cv2.waitKey(0)
原图

mask.jpg

res.jpg

import cv2
src = cv2.imread("1.jpg")
# dst = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY)
# dst = cv2.cvtColor(src,cv2.COLOR_BGR2YUV)
# dst = cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
dst = cv2.convertScaleAbs(src,alpha=6,beta=1)
cv2.imshow("dst show",dst)
cv2.waitKey(0)
cv2.imwrite("1w1.jpg",dst)
YUV

HSV

对比度ScaleAbs

1.3 基本图形绘制
img = cv2.imread(r"1.jpg")
# cv2.line(img, (100, 30), (210, 180), color=(0, 0, 255), thickness=2)
# cv2.circle(img, (50, 50), 30, (0, 0, 255), 2)
# cv2.rectangle(img, (100, 30), (210, 180), color=(0, 0, 255), thickness=2)
# cv2.ellipse(img, (100, 100), (100, 50), 0, 0, 360, (255, 0, 0), -1)#线宽-1表示填充
# pts = np.array([[10, 5], [50, 10], [70, 20], [20, 30]], np.int32)
# pts = pts.reshape((-1, 1, 2))#OpenCV中需要先将多边形的顶点坐标需要变成顶点数×1×2维的矩阵,再来绘制
# cv2.polylines(img, [pts], True, (0, 0, 255), 2)#参数3如果是False的话,多边形就不闭合
cv2.putText(img, 'beautiful girl', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, lineType=cv2.LINE_AA)#cv2.LINE_AA抗锯齿线型
cv2.imshow("pic show", img)
cv2.waitKey(0)
1.4 阈值操作
图像灰度和二值化
灰度是指没有通道,0-255是黑色的"深浅";二值化是指通过一个阈值将像素值分为两个值,比如0和255。虽然普通图像也能做二值化,但是一般都是灰度图再去做二值化。
1.4.1 OTSU二值化
img = cv2.imread("1.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#转成灰度图像
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
#转成二值化
cv2.imshow("gray",gray)
cv2.imshow('binary', binary)
cv2.waitKey(0)
r'''
解释一下cv2.threshold。img是传入图像,thresh就是阈值,maxval是最大值,dst默认None。
返回第一个参数ret=thresh;第二个是二值化后的图片。
特别地:type可以有很多选项,之间可以+、&[and]、|[or]等操作:
------------------------------------------------------------------------
cv2.THRESH_BINARY if v > thresh : v = maxval else v = 0
cv2.THRESH_BINARY_INV THRESH_BINARY的反转
cv2.THRESH_TRUNC if v > thresh : v = maxval else v 不变
cv2.THRESH_TOZERO if v > thresh : v不变 else v = 0
cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
------------------------------------------------------------------------
'''

1.4.2 自适应阈值二值化
普通二值化是对全图操作,而自适应阈值类似"卷积核操作",
这种方法效果更好,相当于各区域动态自适应调整自己的阈值,
而不是整个图像用同一个阈值
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('2.jpg', 0)
# img = cv2.GaussianBlur(img, (5, 5), 0)
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
th2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY, 11, 2)
th3 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
r'''
参数img_gray是传入图像,maxValue是像素值上限,
adaptiveMethod:自适应方法
cv2.ADAPTIVE_THRESH_MEAN_C :领域内均值
cv2.ADAPTIVE_THRESH_GAUSSIAN_C :领域内像素点加权和,权重为一个高斯窗口
thresholdType:只有两个:cv2.THRESH_BINARY 和cv2.THRESH_BINARY_INV
blockSize: 规定正方形领域的大小,可以看做卷积核大小
C:常数C,阈值等于指定正方形领域的均值或加权和减去这个常数
'''

1.5 图像上的运算
import numpy as np
import cv2
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x,y))#[[255]]
print(cv2.subtract(y,x))#[[0]]
1.5.1 图像混合
图像混合就是 “”带权重的“” 加法,结果会给人一种混合或者透明的感觉。

img1 = cv2.imread('1.jpg')
img2 = cv2.imread('mm.jpg')
dst = cv2.addWeighted(img1, 0.7, img2, 0.3, 0)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()


1.5.2 按位运算
按位操作主要有 **AND、OR、NOT、XOR**
result = cv2.bitwise_and(img1, img2, mask)
result = cv2.bitwise_or(img1, img2, mask)
result = cv2.bitwise_not(img)
result = cv2.bitwise_xor(img1, img2, mask)
img1 = cv2.imread('1.jpg')
img2 = cv2.imread('mm.jpg')
rows, cols, channels = img2.shape
roi = img1[0:rows, 0:cols]#去掉通道,得宽高
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)#转灰度
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)#转二值图
mask_inv = cv2.bitwise_not(mask)#取反,把黑底白字变白底黑字
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)#合并
img2_fg = cv2.bitwise_and(img2, img2, mask=mask)#去背景
dst = cv2.add(img1_bg, img2_fg)
img1[0:rows, 0:cols] = dst
cv2.imshow('res', img1)
cv2.waitKey(0)

1.6 图像的几何变换
常见的操作如图像的缩放、平移、旋转、倾斜、镜像等。可以理解成空间的坐标系的变换导致了图像矩阵的变换。
import cv2
img = cv2.imread("1.jpg")
img2 = cv2.transpose(img)
img3 = cv2.flip(img,1)
img4 = cv2.flip(img,-1)
img5 = cv2.flip(img,0)
img6 = cv2.resize(img, (300,300), interpolation=cv2.INTER_CUBIC)
cv2.imshow("img",img)
cv2.imshow("img2",img2)
cv2.imshow("img3",img3)
cv2.imshow("img4",img4)
cv2.imshow("img5",img5)
cv2.imshow("img6",img6)
cv2.waitKey(0)
"""
缩放图 = cv2.resize(img, (W,H), interpolation=cv2.INTER_CUBIC)
r'''
W'和H'是原图的W,H变换后值,interpolation有以下选项:
cv2.INTER_CUBIC # 立方插值[常用]
cv2.INTER_LINEAR # 双线形插值
cv2.INTER_NN # 最近邻插值
cv2.INTER_AREA # 使用象素关系重采样。当图像缩小时候,该方法可以避免波纹出现。
当图像放大时,类似于 CV_INTER_NN 方法
'''
翻转图 = cv2.transpose(img) #效果相当于给图像转置了
镜像图 = cv2.flip(img, flipCode=0)
r'''
关于flipCode,有三个区间:
0 垂直方向翻转
1 水平方向翻转
-1 水平、垂直方向同时翻转
'''
"""
原图

cv2.flip(img,-1)

cv2.flip(img,0)

cv2.flip(img,1)

cv2.transpose(img)

1.6.1 仿射变换(理解为图像里的线性操作)
线性一定是仿射,仿射不一定是线性。
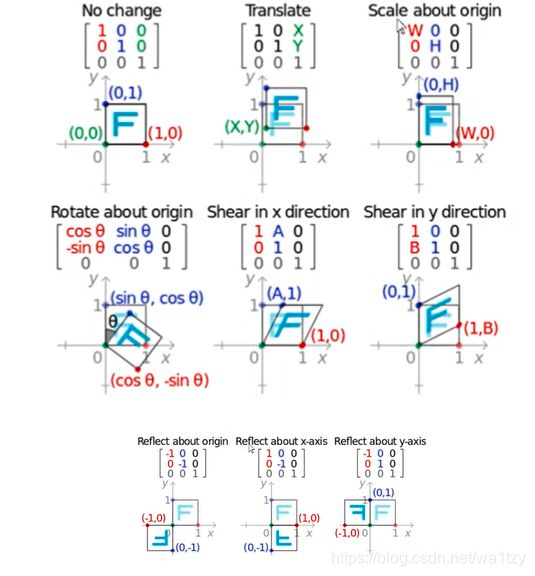
更一般的情况是构造一个矩阵M,即式中3x3的矩阵,然后调warpAffine方法进行具体变换:(不是一步到位的图像,可以设计一个矩阵,一步即可以操作到位)
任意一个二维图像,我们乘以一个仿射矩阵,就能得到仿射变换后的图像,变换包含:缩放、旋转、平移、倾斜、镜像。
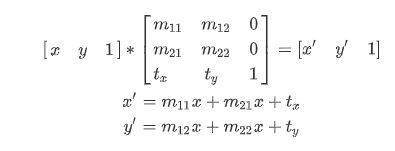
import cv2
import numpy as np
src = cv2.imread('1.jpg')
h, w, c = src.shape
M1 = np.float32([[1, 0, 50], [0, 1, 50]])
M2 = np.float32([[0.5, 0, 0], [0, 0.5, 0]])
M3 = np.float32([[-1, 0, w], [0, 1, 0]])
M4 = np.float32([[1, 0.5, 0], [0, 1, 0]])
M5 = cv2.getRotationMatrix2D(center=(w/2, h/2), angle=45, scale=0.7)
dst = cv2.warpAffine(src, M=M5, dsize=(w, h))
cv2.imshow('src pic', src)
cv2.imshow("dst pic",dst)
cv2.waitKey(0)
r'''
h,w是原图的高和宽
M1~M5分别是对原图img进行平移[50px]、缩放[0.5倍]、左右镜像、倾斜、旋转[45°]
其中M5方法参数:center是旋转点坐标,angle是角度,scale是缩放大小。
最后将不是方阵的M传给warpAffine方法,会自动补全,其参数为:
src:输入图像
M:传入的仿射矩阵
dsize:元组,表示图片的大小.必须是int
'''
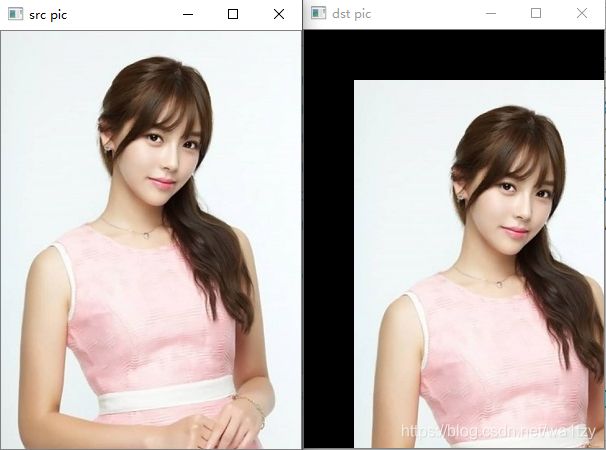
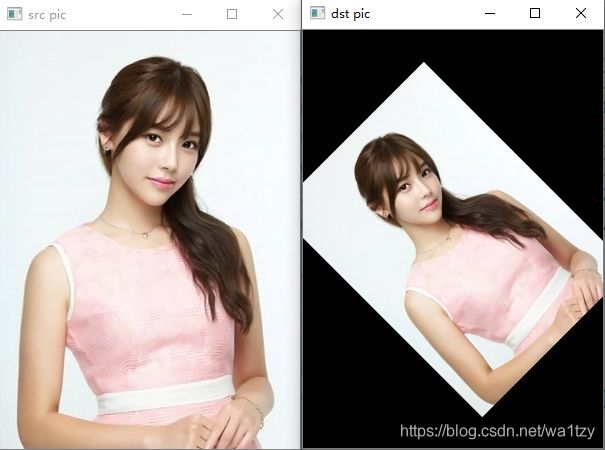
1.6.2 透视变换
透视变换是一种【非线性变换】,比如可以把侧着的图片"掰正拉直"
import cv2
import numpy as np
img = cv2.imread("2.jpg")
pts1 = np.float32([[25, 30], [179, 25], [12, 188], [189, 190]])
pts2 = np.float32([[0, 0], [200, 0], [0, 200], [200, 200]])
M = cv2.getPerspectiveTransform(pts1, pts2)
dst = cv2.warpPerspective(img, M, (200, 201))
cv2.imshow("src", img)
cv2.imshow("dst", dst)
cv2.waitKey(0)
"""
pts1 = np.float32([[a1, a2], [b1, b2], [c1, c2], [d1, d2]])
pts2 = np.float32([[a1’, a2’], [b1’, b2’], [c1’, c2’], [d1’, d2’]])
M = cv2.getPerspectiveTransform(pts1, pts2)
dst = cv2.warpAffine(img, M=M_, dsize=(w, h))
r'''
上面操作是指把img上固定四个点,坐标分别为[a1, a2], [b1, b2], [c1, c2], [d1, d2]
然后取另外四个点,坐标分别为[a1’, a2’], [b1’, b2’], [c1’, c2’], [d1’, d2’]
然后把a1移到a1’...以此类推,通过cv2.getPerspectiveTransform(pts1, pts2)得到M矩阵
假设pts1是梯形,pts2是矩形,最后效果就是梯形被"拉伸"成了矩形。
'''
"""

二、图像形态学操作
2.1 膨胀和腐蚀
膨胀:颜色值大的变粗,比如黑白的,白色变粗
腐蚀:颜色值大的变细,比如黑白的,白色变细
膨胀操作前,需要二值化图像
import cv2 as cv
img = cv.imread("3.jpg", 0)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (3, 3))
# dst = cv.dilate(img, kernel) # 膨胀
dst = cv.erode(img, kernel) #腐蚀
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
"""
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
r'''
生成的kernel叫结构元素,因为形态学操作其实也是应用卷积来实现的。
可以用该方法来生成不同形状的结构元素(第一个参数):
cv2.MORPH_RECT :矩形
cv2.MORPH_ELLIPSE :椭圆形
cv2.MORPH_CROSS :十字形
第二个参数是卷积核大小。
'''
dilate = cv2.dilate(img, kernel)
erode = cv2.erode(img, kernel)
r'''
kernel是5x5的核(向内向外扩展几个像素),dilate是膨胀,erode是腐蚀
'''
"""
膨胀

腐蚀
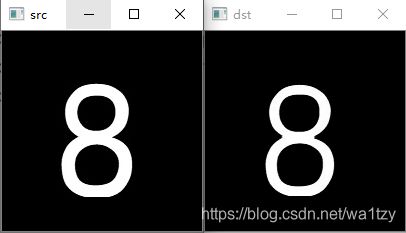
2.2 五个基本算法
开运算:先腐蚀后膨胀,去外部的噪点(可以用于去噪)
闭运算:先膨胀后腐蚀,去内部的噪点(补洞)
梯度操作:膨胀-腐蚀:相当于镂空的环
顶帽操作:原图-开运算:提取背景噪点(提噪点和坑)
黑帽操作:原图-闭运算:提取图像噪点(取洞)
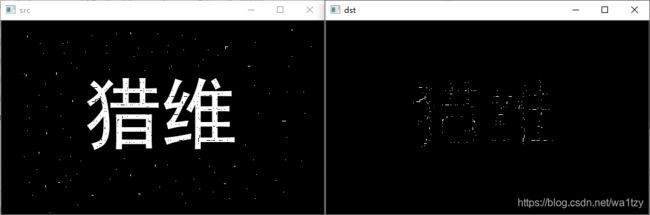
import cv2 as cv
img = cv.imread("4.jpg", 0)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (3, 3))
# dst = cv.morphologyEx(img, cv.MORPH_OPEN, kernel) #开
# dst = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel) # 闭
# dst = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel) # 梯度
# dst = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel) # 顶帽
dst = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel) # 黑帽
"""
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
result = cv2.morphologyEx(src=img, op=cv.MORPH_OPEN, kernel=kernel, iterations=1)
r'''
morphologyEx方法主要参数:
src:输入图片
kernel:可类比成卷积核
iterations:默认None,有值时代表对图像操作的轮次
op:对应五个基本算法
cv2.MORPH_OPEN: 开运算
cv2.MORPH_CLOSE: 闭运算
cv2.MORPH_GRADIENT: 梯度操作
cv2.MORPH_TOPHAT: 顶帽操作
cv2.MORPH_BLACKHAT: 黑帽操作
'''
"""
cv.imshow('src', img)
cv.imshow('dst', dst)
cv.waitKey(0)
开运算
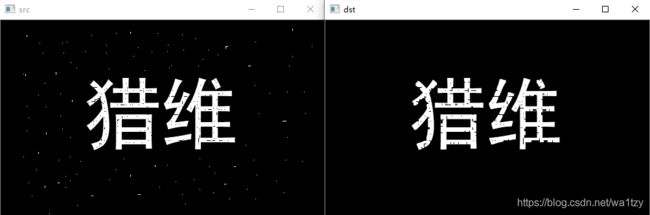
闭运算
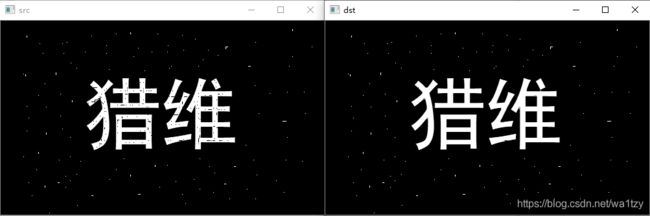
梯度运算(边缘信息比较重要)
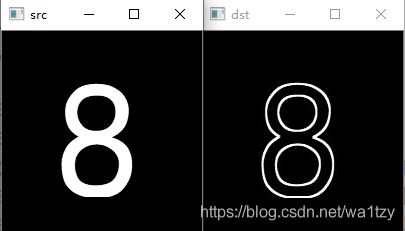
顶帽操作(礼帽操作)
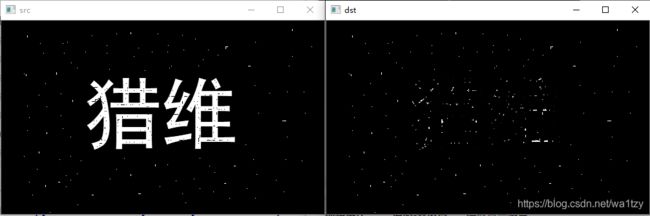
黑帽运算