SpringBoot入门(Web服务端笔记)
SpringBoot
第一节课
1.图例

2.三大组件
Servlet
-
作用
- 接受请求–>处理请求–>返回响应
-
流程
- 客户端发送请求到服务端
- 服务端将请求消息发送给Servlet
- Servlet生成响应发送给服务器
- 服务器将响应发送给客户端

Filter
-
作用
- 过滤请求和响应
-
流程
- 1.请求进入Filter,执行相关操作
- 2.判断通行,进入Servlet,执行完毕,再返回给Filter,最后返回请求方
- 3.判断失败,直接返回失败结果

Listener
- 监听对象的状态
- (类似观察者模式)
3.三大框架(SSM)
组成
Spring,SpringMVC,Mybatis
思考
- Spring和SpringMVC的区别
- Spring是IOC和AOP的容器框架,SpringMVC是基于Spring功能之上添加的Web框架,想用SpringMVC必须先依赖Spring

-
IOC(控制反转)和AOP(面向切片编程)的实现原理
- 配置文件,反射机制
-
SpringBoot和SpringMVC的区别
- SpringBoot实现了自动配置,降低了项目搭建的复杂度,是一套快速开发整合包,内嵌了常用的样板代码
- Spring MVC提供了一种轻度耦合的方式来开发web应用
-
为什么不使用JDBC
- 因为MyBatis ,只需要提供 SQL 语句就好了,其余的诸如:建立连接,操作 Statment,ResultSet,处理 JDBC 相关异常等等都可以交给 MyBatis 去处理,我们的关注点于是可以就此集中在 SQL 语句上,关注在增删改查这些操作层面上
MVC模式组成
有点类似于适配器模式
- M(模型层,即数据)
- V(视图层,展示模型的数据)
- C(控制层,不同的model展现到不同的view)
课后作业
1.MVC设计模式与传统Web开发模式的区别
与传统Web的区别
-
传统Web将显示层、控制层、数据层的操作全部交给 JSP 或者 JavaBean 来进行处理的缺点
- 代码严重耦合,不利于扩展和维护
- 代码难以复用
- 工作模式同步,前端等待后端,后端等待前段
-
传统Web水平划分视图和逻辑两层,MVC垂直划分3层
2.接口定义及其实现分开的好处
-
有利于代码规范化
- 接口相当于类的行为规范
-
代码可维护和易扩展
- 就拿最近学习设计模式的例子来说,商家卖红茶,直接new BlackTea(),需求变化,扩展业务,卖绿茶,就得添加new GreenTea(),需求再变,红茶不卖了,这时如果修改就得一个个去删,会显得很繁琐,但如果采用工厂模式的话,完全可以只去修改工厂中的接口实现时的类型,而在外的代码一直是new Factory()不会发生变化
-
有利于代码安全和严密
- 对接口的调用不需要关注接口内部的实现,保证了接口内部的严密
-
丰富了继承的形式
- java中没有多继承,但可以通过继承多个接口的方式变相实现多继承
-
实现松耦合,方便注入
第二节课
1.JUnit单元测试
基本概念
- 区分与人工测试,更加快捷方便和有保证
- java单元测试框架
- 测试驱动编程
用处
-
测试代码逻辑的正确性(尤其是复杂工程)
-
已知输入的先决条件,预期输出后置条件
- TestCase断言
-
正负检验
实践
首先需要在测试类配置如下的注解,特别注意@SpringBootTest后面跟着的是主程序入口类的class
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {Ex1Application.class})
@AutoConfigureMockMvc
前置理论
-
@Before,发生在测试之前
-
@Test,测试时
-
@After,测试之后
-
MockMvc类,主要用于模拟http请求
-
get
MvcResult mvcResult = mockMvc.perform(MockMvcRequestBuilders.get("/api/ex1/hello/list")) .andExpect(MockMvcResultMatchers.status().isOk()).andReturn(); int status = mvcResult.getResponse().getStatus(); TestCase.assertEquals(200, status);- 执行MockMvcRequestBuilders请求,如果获取的状态码不是200(OK),抛出异常,正常就返回MvcResult对象
-
post
MvcResult mvcResult = mockMvc.perform(MockMvcRequestBuilders.post("/api/ex1/user/login") .content(JSONArray.toJSON(user).toString()) .contentType(MediaType.APPLICATION_JSON)) .andExpect(MockMvcResultMatchers.status().isOk()).andReturn(); JsonData jsonData = JSONArray.parseObject(mvcResult.getResponse().getContentAsString(UTF_8), JsonData.class); TestCase.assertEquals(jsonData.getCode(), 0);- post在http请求报文的body中有数据,所以还得传递一个json格式的对象user
-
-
碰到的问题
-
post测试时传参时json对象和自定义对象的转化
解决方法:http://www.mamicode.com/info-detail-2668986.html
-
-
热部署
- 编译器会根据修改的代码重新调整程序
2.Thymeleaf
轻量级引擎模板
静态模板放在templates
注意点:
- 需要添加xmlns:th=“http://www.thymeleaf.org”
- 具体用法参考文档,https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html
public class ThymeleafProperties {
private static final Charset DEFAULT_ENCODING;
public static final String DEFAULT_PREFIX = "classpath:/templates/";
public static final String DEFAULT_SUFFIX = ".html";
private boolean checkTemplate = true;
private boolean checkTemplateLocation = true;
private String prefix = "classpath:/templates/";
private String suffix = ".html";
private String mode = "HTML";
private Charset encoding;
private boolean cache;
private Integer templateResolverOrder;
private String[] viewNames;
private String[] excludedViewNames;
private boolean enableSpringElCompiler;
private boolean renderHiddenMarkersBeforeCheckboxes;
private boolean enabled;
private final ThymeleafProperties.Servlet servlet;
private final ThymeleafProperties.Reactive reactive;
.....
}
上面是一部分的ThymeleafProperties的源码,我们可以看到,Thymeleaf默认是去"classpath:/templates/"里找后缀为.html的文件的
第三节课(2020-10-15/第四周)
1.自定义全局异常错误
如何配置全局自定义全局异常

对应异常的处理方法上添加@ExceptionHandler(value = Exception.class)注解
类型
- Json格式
@RestControllerAdvice
public class JsonUserHandler {
@ExceptionHandler(value = Exception.class)//捕获什么异常
JsonData handlerException(Exception ex, HttpServletRequest request) {
return JsonData.buildError("服务端异常报错");
}
}
- 自定义页面,通过ModelAndView实现
@ControllerAdvice
public class ViewUserHandler {
@ExceptionHandler(value = Exception.class)
Object handlerException(Exception ex, HttpServletRequest request) {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("error.html");
modelAndView.addObject("msg", ex.getMessage());
return modelAndView;
}
}
2.过滤器
作用
权限控制,用户状态控制
编码
实现Filter接口,并重写init,doFilter,destroy方法,添加@WebFilter注解,使启动类可以回调自定义的Filter
@WebFilter(urlPatterns = "/api/ch/pri/*", filterName = "LoginFilter")
public class LoginFilter implements Filter {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init");
}
@Override
public void destroy() {
System.out.println("destroy");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("doFilter");
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String token = request.getHeader("token");
if (StringUtils.isEmpty(token))
token = request.getParameter("token");
if (!StringUtils.isEmpty(token)) {
User user = UserServiceImpl.sessionMap.get(token);
if (user != null) {
filterChain.doFilter(servletRequest, servletResponse);
} else {
JsonData jsonData = JsonData.buildError("登录失败", -2);
String jsonStr = objectMapper.writeValueAsString(jsonData);
renderJson(response, jsonStr);
}
} else {
JsonData jsonData = JsonData.buildError("未登录", -3);
String jsonStr = objectMapper.writeValueAsString(jsonData);
renderJson(response, jsonStr);
}
}
public void renderJson(HttpServletResponse response, String json) {
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json");
try (PrintWriter writer = response.getWriter()) {
writer.print(json);
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
3.拦截器
作用
同过滤器
编码
public class LoginInterceptor implements HandlerInterceptor {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle");
String token = request.getHeader("token");
if (StringUtils.isEmpty(token))
token = request.getParameter("token");
if (!StringUtils.isEmpty(token)) {
User user = UserServiceImpl.sessionMap.get(token);
if (user != null) {
return true;
} else {
JsonData jsonData = JsonData.buildError("登录失败", -2);
String jsonStr = objectMapper.writeValueAsString(jsonData);
renderJson(response, jsonStr);
return false;
}
} else {
JsonData jsonData = JsonData.buildError("未登录", -3);
String jsonStr = objectMapper.writeValueAsString(jsonData);
renderJson(response, jsonStr);
return false;
}
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion");
}
public void renderJson(HttpServletResponse response, String json) {
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json");
try (PrintWriter writer = response.getWriter()) {
writer.print(json);
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
多个拦截器的执行过程
实践
如果请求一旦被某个拦截器拦截,那后面的拦截器就不会再执行,相当for-if-break
多个拦截器阻拦效果,首先需要配置拦截器的路由
@Configuration
public class UserWebMvcController implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(getLoginInterceptor()).addPathPatterns("/api/ch/pri/**");
registry.addInterceptor(new TwoInterceptor()).addPathPatterns("/api/ch/pri/**");
registry.addInterceptor(new ThreeInterceptor()).addPathPatterns("/api/ch/pri/**");
WebMvcConfigurer.super.addInterceptors(registry);
}
@Bean
public LoginInterceptor getLoginInterceptor() {
return new LoginInterceptor();
}
}
-
部分放行(第二个拦截)

第二个拦截器拦截:第一个拦截器preHandle和afterCompletion会被执行,但因为被第二个拦截器拦截,所以第一个postHandle不会被执行
-
(部分拦截)第三个拦截

同理
-
全部放行

栈的既视感,先进后出
全部放行:具体流程可以用下图解释
原理

4.监听器(了解)
- 应用启动监听
- 会话监听
- 请求监听
5.课后作业
过滤器和拦截器比较
1.编码
- 过滤器
- 实现Filter接口,重载init,destroy,doFilter(过滤逻辑实现的地方)方法,同时需要添加注解
- @WebFilter(urlPatterns = “/api/ch/pri/*”, filterName = “LoginFilter”),访问/api/ch/pri/*就会触发过滤器
- 拦截器
- 实现HandlerInterceptor接口,重载preHandle(拦截器逻辑实现的地方),postHandle,afterCompletion,不需要添加注解,但需要配合自定义的config类,覆盖原来的WebMvcConfigure类
- 重载addInterceptors方法添加对应的路由(注意添加@Configuration)
registry.addInterceptor(getLoginInterceptor()).addPathPatterns("/api/ch/pri/**");
2.生命周期
- 过滤器
- init随程序启动被调用,init和destroy在整个Filter生命周期只会被调用一次,而doFilter在对应的每一次请求都被会调用
- 拦截器
- 在每一次对应请求都会执行一个完整的生命周期,即preHandle,postHandle,afterCompletion都会在一次请求中被执行
3.实现原理
- 过滤器
- 函数回调
filterChain.doFilter(servletRequest, servletResponse);
接下来我们重点分析这一句代码
我们先来看一下FilterChain这个类
public interface FilterChain {
void doFilter(ServletRequest var1, ServletResponse var2) throws IOException, ServletException;
}
通过上面的代码我们可以发现它是一个接口,那我们再来看一下它的应用级实现类,也就是ApplicationFilterChain这个类

ApplicationFilterChain.this.internalDoFilter(req, res);
我截取了比较doFilter核心语句,所以我们再来扒一扒internalDoFilterf方法
if (this.pos < this.n)
ApplicationFilterConfig filterConfig = this.filters[this.pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
从上面的这几句中我们可以发现,这个方法其实是对过滤器的一个遍历,不断获取我们定义的过滤器,然后进行过滤操作,最后将结果回调,当不符合过滤条件就抛出异常
总结:ApplicationFilterChain里面能拿到我们自定义的xxxFilter类,在其内部回调方法doFilter()里调用各个自定义xxxFilter过滤器,并执行 doFilter() 方法。而每个xxxFilter 会先执行自身的 doFilter() 过滤逻辑,最后在执行结束前会执行filterChain.doFilter(servletRequest, servletResponse),也就是回调ApplicationFilterChain的doFilter() 方法,以此循环执行实现函数回调

- 拦截器
- 基于Java的反射机制,动态代理==(留坑)==
4.灵活度
- 过滤器
- 实现javax.servlet.Filter接口,依赖于Servlet,需要使用服务器容器,只能限于web程序中
- 拦截器
- spring的一个组件,使用范围包括application,web等等
5.触发时机

过滤器几乎可以对所有进入容器的请求起作用,而拦截器只会对Controller中请求或访问static目录下的资源请求起作用
6.参考文献
过滤器 和 拦截器的 6个区别(别再傻傻分不清了)
第四节课(2020-10-22/第五周)
1.JDBC(了解)
基本流程
- 加载JDBC驱动
- 创建数据库连接
- 创建preparedStatement对象
- 执行sql语句
- 处理结果集
- 关闭JDBC对象资源
2.ORM框架
理解
数据库的表和java对象做映射关系,比如User类中的username字段映射user表中的username字段
Mybatis(重点)
1.简介
Mybatis是什么?
- MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射
- MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作
- MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
- 存储地:apache——>google——>github(现在)
如何获得?
- maven
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.4version>
dependency>
- github:https://github.com/mybatis/mybatis-3/releases
- 中文文档:https://mybatis.org/mybatis-3/zh/index.html
持久化
持久化是将程序数据在持久状态和瞬时状态间转换的机制。通俗的讲,就是瞬时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)
JDBC就是一种持久化机制。文件IO也是一种持久化机制。
2.流程
1.导入依赖
mysql,mybatis,log4j(可以不添加)
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.4version>
dependency>
2.环境配置
- 配置连接数据库的信息
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://127.0.0.1:3306/mailDB?useUnicode=true&characterEncoding=utf-8&useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="XXXXX"/>
dataSource>
environment>
environments>
- 配置数据库操作的xml映射
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
<mapper resource="mapper/MailMapper.xml"/>
mappers>
- 注意(xml需添加这一段,不然不会联想)
3.java类和sql语句的映射
- 定义数据表的实体类
@Getter
@Setter
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String username;
private String password;
private String mobile;
}
- 定义sql语句的接口
public interface UserMapper {
User selectById(int useId);
int add(User user);
List<User> selectListByXML();
List<User> selectByMobileAndUsernameLike(@Param("mobile") String mobile, @Param("username") String username);
User update(User user);
}
- 定义sql语句的xml
- id对应java类中的接口方法名
- resultType对应结果集类型,parameterType对应传入参数的类型
- 其中插入的#{username,jdbcType=VARCHAR}
username是传入对象的字段,jdbcType是对应的类型
<select id="selectById" parameterType="java.lang.Integer" resultType="com.example.ex4.domain.User">
select * from users where id=#{userId,jdbcType=INTEGER}
select>
<select id="selectListByXML" resultType="com.example.ex4.domain.User">
select * from users
select>
<select id="selectByMobileAndUsernameLike" resultType="com.example.ex4.domain.User">
select * from users where mobile like concat('%',#{mobile},'%') and username like concat('%',#{username},'%')
select>
<insert id="add" parameterType="com.example.ex4.domain.User">
INSERT INTO mailDB.users(`username`,`password`,`mobile`)
VALUE
(#{username,jdbcType=VARCHAR},#{password,jdbcType=VARCHAR},#{mobile,jdbcType=VARCHAR})
insert>
<update id="update" parameterType="com.example.ex4.domain.User">
UPDATE users
set `username`=#{username,jdbcType=VARCHAR},
`password`=#{password,jdbcType=VARCHAR},
`mobile`=#{mobile,jdbcType=VARCHAR}
where id=#{id,jdbcType=INTEGER}
update>
4.获取配置,投入使用
String resource = "config/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
try (SqlSession sqlSession = sqlSessionFactory.openSession()) {
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.selectById(1);
}
JPA(额外)
流程
1.创建映射
@Getter
@Setter
@Entity//数据库实体
@Table(name = "book")//对应表明book
@JsonIgnoreProperties({"handler", "hibernateLazyInitializer"})
public class Book {
@Id//主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//自增策略
@Column(name = "id")//对应book表的id字段
private int id;
private String cover;
private String title;
private String author;
private String date;
private String press;
private String abs;
@ManyToOne//多对一
@JoinColumn(name = "cid")//cid字段作为外键,引用category表的id
private Category category;
}

2.通过继承JpaRepository,再定义sql语句的接口
public interface BookDAO extends JpaRepository<Book, Integer> {
List<Book> findAllByCategory(Category category);
List<Book> findAllByTitleLikeOrAuthorLike(String keyword1, String keyword2);
}
3.在@Server中对结果集做相应的逻辑操作
@Service
public class BookService {
@Autowired
BookDAO bookDAO;
@Autowired
CategoryService categoryService;
public List<Book> list() {
Sort sort = Sort.by(Sort.Direction.DESC, "id");
return bookDAO.findAll(sort);//调用接口
}
public void addOrUpdate(Book book) {
bookDAO.save(book);//主键不存在就添加,存在就更新
}
public void deleteById(int id) {
bookDAO.deleteById(id);
}
public List<Book> listByCategory(int cid) {
Category category = categoryService.get(cid);
return bookDAO.findAllByCategory(category);
}
public List<Book> listSearch(String keywords) {
return bookDAO.findAllByTitleLikeOrAuthorLike('%' + keywords + '%', '%' + keywords + '%');
}
}
4.相应路由访问@Controller
@Controller
public class LoginController {
@Autowired
UserService userService;
@CrossOrigin
@PostMapping("api/login")
@ResponseBody
public Result login(@RequestBody User user) {
if (user == null) return new Result(400);
String username = user.getUsername();
username = HtmlUtils.htmlEscape(username);
User userByName = userService.getByName(username);
User tmpUser = userService.get(username, new SimpleHash("md5", user.getPassword(), userByName.getSalt(), 2).toString());
if (null != tmpUser)
return new Result(200);
else
return new Result(400);
}
}
3.课后作业
ORM框架和原生JDBC访问的差异点
1.编码方式
- JDBC
- 每次加载驱动,连接使用硬编码,将数据嵌入到代码中开发,如有改动需要重新编译,不合理且成本大
- ORM
- 采用软编码,在配置文件中加载数据,如有改动,修改配置文件即可,与代码解耦,便于管理
2.sql语句
- JDBC(java代码中静态编写sql)
- 通过对结果集操作返回数据,处理繁琐,且不能自动映射到实体类
- ORM(xml中动态编写sql)
- 实体类与配置相互映射,如JPA中的@Entry,MyBatis中的resultType=“com.example.ex4.domain.User”,且省去了对结果集的操作,更加的方便
3.提交方式
- JDBC
- 对于增删改查都是直接提交
- ORM
- 增删改都是未提交,需程序猿执行commit操作
4.资源问题
- JDBC
- 不利于复用,每次执行sql语句时打开连接,不用时断开连接,需要操作多个对象
- ORM
- 利于资源复用,关闭资源只需要关闭一个Session即可
5.性能问题
JDBC因为采用硬编码,直接在代码中操作,相对于ORM读取XML中配置会来得更加快,性能方面更有优势
6.参考文献
传统JDBC与ORM框架之间的性能比较
第六节课(2020-11-9/第七周)
1.添加
<insert id="add" parameterType="com.example.ex4.domain.User">
INSERT INTO mailDB.users(`username`,`password`,`mobile`)
VALUE
(#{username,jdbcType=VARCHAR},#{password,jdbcType=VARCHAR},#{mobile,jdbcType=VARCHAR})
insert>
2.全更新&选择性更新
<update id="update" parameterType="com.example.ex4.domain.User">
UPDATE users
set `username`=#{username,jdbcType=VARCHAR},
`password`=#{password,jdbcType=VARCHAR},
`mobile`=#{mobile,jdbcType=VARCHAR}
where id=#{id,jdbcType=INTEGER}
update>
这里使用的是全更新,我们需要获取对象的全部属性,否则更新不更新的字段会被设为null,所以下面介绍选择性更新
<update id="updateSelective" parameterType="com.example.ex4.domain.User">
UPDATE users
<trim prefix="set" suffixOverrides=",">
<if test="username!=null">`username`=#{username,jdbcType=VARCHAR},if>
<if test="password!=null">`password`=#{password,jdbcType=VARCHAR},if>
<if test="mobile!=null">`mobile`=#{mobile,jdbcType=VARCHAR},if>
trim>
where id=#{id,jdbcType=INTEGER}
update>
我们来看一下区别,我们发现xml中的sql语句多了一层if判断和trim,if的意思很好理解,字段为null就不更新,不为null才更新
trim中是定义具体的规则,这里定义的规则是这对标签里面的前缀为set,并移除最后后缀中的,,这里就是把mobile字段后面的,给移除掉,其他的和全更新一样
3.删除(万能的Map)
<delete id="delete" parameterType="java.util.Map">
delete from users where id=#{id} or username=#{username}
delete>
删除的语句本身很简单,要注意的点是参数的类型Map,这个是第一次遇到,记录一下具体怎么传参
int delete(Map<String, Object> mp);//接口中的方法
Map<String, Object> mp = new HashMap<>();
mp.put("id", 13);
mp.put("username", "xxxxxxxx");
int outUser = userMapper.delete(mp);
System.out.println(outUser);
sqlSession.commit();
我们可以看到我们直接new HashMap再put就可以了,然后在xml中用HashMap的key取对应的value即可,#{id}对应的就是HashMap中的13,还是很简单的吧哈哈哈
4.resultMap
这里的resultMap还是有点迷的,具体的可以查看第七节课中对resultMap的解释,这里知道他适用于复杂查询就可以了
<resultMap id="UserResultMap" type="com.example.ex4.domain.User">
<id column="id" property="id" jdbcType="INTEGER"/>
<result column="username" property="username" jdbcType="VARCHAR"/>
<result column="password" property="password" jdbcType="VARCHAR"/>
<result column="mobile" property="mobile" jdbcType="VARCHAR"/>
resultMap>
5.数据库类型和java类型映射表


6.配置解析(MyBatis扩展)
1.核心配置文件
MyBatis 的配置文件包含了会深深影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下
configuration(配置)
properties(属性)
settings(设置)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境配置)
environment(环境变量)
transactionManager(事务管理器)
dataSource(数据源)
databaseIdProvider(数据库厂商标识)
mappers(映射器)
2.环境配置(environments)
MyBatis 可以配置成适应多种环境
不过要记住:尽管可以配置多个环境,但每个 SqlSessionFactory 实例只能选择一种环境。
<environment id="development">
3.事务管理器(transactionManager)
在 MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]"):
- JDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域
- MANAGED – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)
<transactionManager type="JDBC"/>
4.数据源(dataSource)
数据源(dataSource)有三种内建的数据源类型(也就是 type="[UNPOOLED|POOLED|JNDI]"):
POOLED– 这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这种处理方式很流行,能使并发 Web 应用快速响应请求
5.属性(properties)
优化配置文件
数据库的配置文件
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/mailDB?useUnicode=true&characterEncoding=utf-8&useSSL=false
username=root
password=XXXX
导入配置文件,外部的配置优先级高于内部的配置,这也就是为什么我在内部配置错误的密码,但还是能够成功查询到数据的原因
<properties resource="db.properties">
<property name="password" value="123"/>
properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
dataSource>
environment>
environments>
6.类型别名(typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
typeAliases>
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
<typeAliases>
<package name="domain.blog"/>
typeAliases>
每一个在包 domain.blog 中的 Java Bean,在没有注解的情况下,会使用 Bean 的首字母小写的非限定类名来作为它的别名。 比如 domain.blog.Author 的别名为 author;若有注解,则别名为其注解值。见下面的例子:
@Alias("author")
public class Author {
...
}
下面是一些为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
7.设置(settings)
这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为,这里罗列了4个常用的,具体查看官方文档
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true | false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 |
true | false | false |
| mapUnderscoreToCamelCase | 是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn。 | true | false | False |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 | SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING | 未设置 |
8.作用域和生命周期
SqlSessionFactoryBuilder
这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。 你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但最好还是不要一直保留着它,以保证所有的 XML 解析资源可以被释放给更重要的事情。
SqlSessionFactory
SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例。 使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,多次重建 SqlSessionFactory 被视为一种代码“坏习惯”。因此 SqlSessionFactory 的最佳作用域是应用作用域。 有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式。
SqlSession
每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。 绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行(????)。 也绝不能将 SqlSession 实例的引用放在任何类型的托管作用域中,比如 Servlet 框架中的 HttpSession。 如果你现在正在使用一种 Web 框架,考虑将 SqlSession 放在一个和 HTTP 请求相似的作用域中。 换句话说,每次收到 HTTP 请求,就可以打开一个 SqlSession,返回一个响应后,就关闭它。 这个关闭操作很重要,为了确保每次都能执行关闭操作,你应该把这个关闭操作放到 finally 块中。 下面的示例就是一个确保 SqlSession 关闭的标准模式:
try (SqlSession session = sqlSessionFactory.openSession()) {
// 你的应用逻辑代码
}
在所有代码中都遵循这种使用模式,可以保证所有数据库资源都能被正确地关闭
以上摘自官方文档,我根据官方文档对我的代码进行了一定的修改,下面是修改以后的代码
public class SqlSessionUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
String resource = "config/mybatis-config.xml";
try (InputStream inputStream = Resources.getResourceAsStream(resource)) {
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public static SqlSession newInstanceof() {
return sqlSessionFactory.openSession(true);//设置事务自动提交
}
}
我把SqlSessionFactory改成了单例模式,在每个方法中生产一个SqlSession,最后再关闭
下面是一个关于通过userid筛选邮箱信息的实例
@Override
public List<UserMail> selectMailsById() {
SqlSession sqlSession = SqlSessionUtils.newInstanceof();//获取单例的接口
MailMapper mailMapper = sqlSession.getMapper(MailMapper.class);//载入MailMapper接口
//正常的业务逻辑
User user = UserThreadLocal.get();
List<UserMail> userMailList = mailMapper.queryUserMailById(user.getId());
//关闭sqlSession
sqlSession.close();
return userMailList;
}
9.日志
作用:用于sql语句的排错
STDOUT_LOGGING日志
如何应用:(见下面代码)
<setting name="logImpl" value="STDOUT_LOGGING"/>
具体效果:

Log4j
- Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等
- 我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程
- 最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码
导入依赖
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
Mybatis文件配置
<setting name="logImpl" value="LOG4J"/>
Log4j文件配置
# 全局日志配置
log4j.rootLogger=ERROR,stdout
# MyBatis 日志配置
# 只输出sql语句
log4j.logger.com.example.ex4=DEBUG
# 输出sql语句和结果集
#log4j.logger.com.example.ex4=TRACE
# 具体到映射器的某个接口
#log4j.logger.com.example.ex4.dao.UserMapper.selectById=TRACE
# 控制台输出
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
具体效果

10.基于注解的开发
@Select("select * from users where id=#{userId,jdbcType=INTEGER}")
User selectById(int useId);
@Select("select * from users where username=#{userName,jdbcType=VARCHAR} and `password`=#{pwd,jdbcType=VARCHAR}")
User selectByUsernameAndPassword(@Param("userName") String username, @Param("pwd") String password);
简单的sql语句可以使用注解来完成,其中sql语句中使用的传入变量名可以用@Param("XXX"),上面的第二句就是用注解将username转化为userName,这样在sql语句中使用的就是userName了
基于注解的Mybatis开发实际上是基于反射机制的,通过获取到Mapper.class反射到类对象,再获取它的方法,属性以及注解等等,再与配置文件联系起来,注入到某个对象中,我们再使用这个对象完成数据库的查询
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.selectById(1);
11.Mybatis执行流程剖析
流程图



源码分析
读取配置文件,通过XMLConfigBuilder去解析文件,解析到Configuration configuration对象中,并返回SqlSessionFactory对象
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
创建事务管理器和执行器,再创建DefaultSqlSession(实现SqlSession接口)的对象,并返回
SqlSession sqlSession = sqlSessionFactory.openSession(true);
public SqlSession openSession(boolean autoCommit) {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, autoCommit);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
使用SqlSession反射加载Mapper.class实现CURD(基于注解的开发中有提到,不赘述)
接下来就是错误的话会进行事务回滚(留坑,又不会了哈哈哈)
12.多对一
表结构


@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student {
int id;
String name;
Teacher teacher;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Teacher {
int id;
String name;
}
1.子查询
<select id="testManyToOne" resultMap="StudentTeacher">
select * from student
select>
<resultMap id="StudentTeacher" type="student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<association property="teacher" column="t_id" javaType="teacher" select="getTeacher"/>
resultMap>
<select id="getTeacher" resultType="teacher">
select * from teacher where id=#{id}
select>
2.根据结果嵌套处理
<select id="testManyToOne1" resultMap="StudentTeacher1">
select s.id as sid ,s.name as sname ,t.id as tid ,t.name as tname
from student as s ,teacher as t
where t.id = #{id}
select>
<resultMap id="StudentTeacher1" type="student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
association>
resultMap>
13.一对多
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student {
int id;
String name;
int tId;//因为有在mybatis配置文件中配置驼峰转化,所以数据库的字段会被转换为驼峰命名
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Teacher {
int id;
String name;
List<Student> students;
}
1.根据结果嵌套处理(推荐这个)
<select id="testOneToMany" resultMap="StudentTeacher">
select s.id as sid ,s.name as sname ,t.id as tid ,t.name as tname
from student as s ,teacher as t
where t.id=1
select>
<resultMap id="StudentTeacher" type="teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
collection>
resultMap>
2.子查询
<select id="testOneToMany1" resultMap="StudentTeacher1">
select * from teacher where id=#{id}
select>
<resultMap id="StudentTeacher1" type="teacher">
<id property="id" column="id"/>
<collection property="students" javaType="ArrayList" ofType="student" select="queryStudentsByTeacherId"
column="id">
collection>
resultMap>
<select id="queryStudentsByTeacherId" resultType="student">
select * from student where t_id=#{id}
select>
记录一下坑点
-
Mybatis配置文件中如果使用了
-
Mybatis主键需要特别声明
-
collection如果是为了存放结果,不需要声明javaType,但如果是为了返回某个查询,就需要声明,具体可以参考上面的两个例子==(这个点还是有点迷)==
-
如果是基本类型,那么jdbcType和javaType可以忽略,但写上也可以,毕竟让Mybatis自己推断也会有性能上的消耗的吧
-
类的属性名和数据表的字段名一致,如
里只写需要转化的就好了
14.动态SQL
为什么使用动态SQL:
- 如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦
- 如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。学习成本低
if,trim,set
可以参考选择性更新的例子
choose (when, otherwise)
有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
还是上面的例子,但是策略变为:传入了 “title” 就按 “title” 查找,传入了 “author” 就按 “author” 查找的情形。若两者都没有传入,就返回标记为 featured 的 BLOG
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
when>
<otherwise>
AND featured = 1
otherwise>
choose>
select>
where
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除
foreach
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
foreach>
select>
上面的foreach中会变成(1,2,3,…,n)这种格式,open代表起始,separator代表分隔符,close代表结尾
sql片段
可以定义一个类似于函数一样的sql片段用于sql语句的代码复用
<select id="queryTest" resultType="blog">
select * from Blogs
<where>
<include refid="titleTest">include>
where>
select>
<sql id="titleTest">
<if test="title!=null">title=#{title}if>
<if test="author!=null">or author=#{author}if>
sql>
script
要在带注解的映射器接口类中使用动态 SQL,可以使用 script 元素。比如:
@Update({""})
void updateAuthorValues(Author author);
15.缓存(见第七节课2.3)
第七节课(2020-11-16/第八周)
1.期中回顾
重点分析上周的作业,总结了一下做的好的地方和有待完善的地方
好的地方:
- 目录结构清晰
- controller包用于与前端路由交互
- dao是用于访问数据库数据的接口
- domain则是数据域,定义数据类
- handler用于异常处理
- service用于基本的逻辑构建,也是主要的业务逻辑实现的包
- utils是工具类,有我们自己定义的json对象
有待完善的:
- 单元测试不是测试路由接口,那个postman就可以完成(丢人)
- SqlSession不需要,我的理解是这个配置其实只需要一次,所以借用单例模式,把SqlSession放在静态代码块,只初始化一次
- 不要alert,密码错误的话可以采用更加人性化的提示,所以我这周作业会用Element UI去完善界面这一块
- 添加安全机制,这算扩展部分,这周如果有时间就写,没时间晚后推一下,应该是token机制或jwt框架的使用
- 前后端没有分离,改成两个项目
2.Mybatis的多表集合和缓存
1.多表集合的使用
@Getter
@Setter
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String username;
private String password;
private String mobile;
private List<UserMail> userMailList;
}
<resultMap id="UserMailResultMap" type="com.example.ex4.domain.User">
<id column="id" property="id" jdbcType="INTEGER"/>
<result column="username" property="username" jdbcType="VARCHAR"/>
<result column="password" property="password" jdbcType="VARCHAR"/>
<result column="mobile" property="mobile" jdbcType="VARCHAR"/>
<collection property="userMailList" ofType="com.example.ex4.domain.UserMail">
<id column="mail_id" property="id" jdbcType="INTEGER"/>
<result column="mail_name" property="mailName" jdbcType="VARCHAR"/>
<result column="user_id" property="userId" jdbcType="INTEGER"/>
<result column="is_used" property="isUsed" jdbcType="INTEGER"/>
collection>
resultMap>
<select id="queryUserMailById" resultMap="UserMailResultMap">
select
m.id mail_id,
m.mail_name,
m.user_id,
m.is_used
from mails m left join users u on u.id=m.user_id
where m.user_id=#{id,jdbcType=INTEGER} and m.is_used=1
select>
我们逐步分析一下,id="UserMailResultMap"是这个resultMap的唯一标识符,,type是返回的具体对象,

2.resultType和resultMap的区别
- resultType查询出的字段必须和domain中的属性有对应,否则需要通过修改sql语句来完成映射,所以适合做简单查询
- resultMap查询的字段在resultMap定义时就规定了映射关系,所以不需要修改sql语句,耦合度更低了一点,所以适合做复杂查询,比如一对多的关系
3.缓存
1.一级缓存
一级缓存的作用域是SQLSession,第一次查询数据库并写在缓存中,第二次从缓存中取
一级缓存默认开启
失效策略:
- insert,update,delete等操作commit后会清空该SQLSession缓存
- 关闭SqlSession或手动清空缓存
2.二级缓存
开启某个mapper.xml的缓存
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024">cache>
开启全局的二级缓存配置,优先级大于局部的二级缓存配置
<setting name="cacheEnable" value="true"/>
3.缓存顺序
优先查询二级缓存——>查询一级缓存——>数据库

4.Mybatis缓存结构图

3.作业及扩展
1.使用的框架
springboot+vue+mybatis
前端用vue实现基本逻辑,element UI美化界面
后端用springtboot+mybatis
数据库用MySql
2.基本流程

- 用户发送用户名&密码请求,服务端校验,正确就存储token,并返回token给客户端,客户端将token存储,接下来的每次操作的请求都携带token作为身份识别的标志
- 对于接下来用户的每个操作,都会先验证token,验证正确才会执行相应的处理,否则返回错误信息
3.Vue的学习
emmmmmm,其实我没怎么学过Vue,所以这里稍微学一下
怎么安装就不讲了,主要讲一下目录结构和怎么使用吧
1.Vue的src目录结构

这个是我的目录结构:
- assets存放图片资源
- components存放组件
- config存放配置
- router存放路由信息
- store存放钩子
- App.vue是页面的入口
- main.js是全局配置
2.App.vue&./router/index.js
这个文件最关键的一点其实是第四行,
import Vue from 'vue'
import Router from 'vue-router'
import Login from '@/components/LoginInterface'
import HomeIndex from "@/components/HomeIndex";
Vue.use(Router)
export default new Router({
routes: [
// 下面都是固定的写法
{
path: '/login',
name: 'Login',
component: Login
},
{
path: '/index',
name: 'HomeIndex',
component: HomeIndex,
meta: {
requireAuth: true
}
}
]
})
@/components/LoginInterface
3.main.js&index.html
看完上面的不知道你们有没有一些疑惑,我们写的这些怎么和html关联起来
<html lang="en">
<head>
<title>作业7title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<link rel="icon" href="<%= BASE_URL %>favicon.ico">
<title><%= htmlWebpackPlugin.options.title %>title>
head>
<body>
<noscript>
<strong>We're sorry but <%= htmlWebpackPlugin.options.title %> doesn't work properly without JavaScript enabled.
Please enable it to continue.strong>
noscript>
<div id="app">div>
body>
html>
这是public文件夹下的index.html,我们看到的其实也是这张页面
那为什么单纯打开这张页面是一片空白呢,这就要看我们的main.js了
import Vue from 'vue'
import App from './App.vue'
new Vue({
el: '#app',
router,
store,
render: h => h(App)
}).$mount("#app")
截选了一段main.js的代码
在这个 js 文件中,我们创建了一个 Vue 对象(实例),el 属性提供一个在页面上已存在的 DOM 元素作为 Vue 对象的挂载目标,router 代表该对象包含 Vue Router,并使用项目中定义的路由。render则是渲染函数,所以也就是把指定的内容挂载到了index.html的id="app"的div上,并使用App.vue去渲染这个节点
这样差不多最基本的vue结构就搞明白了
4.结构图

5.前后端数据交互
1.axios交互
两个问题
- 怎么交互
- 跨域问题
首先需要安装axios这个模块。npm install --save axios
系统登录
登录
这里使用到了this.$router.replace({path: '/index'});的路由转换,切换到了index页面
这些代码还是很容易懂的,关键是写这段代码会碰到一个问题,就是跨域问题
//SpringBoot后端加一个注解就OK了,是不是很方便
@CrossOrigin
2.设置反向代理
// 设置反向代理,前端请求默认发送到 http://localhost:8443/api
var axios = require('axios')
axios.defaults.baseURL = 'http://localhost:8443/api'
// 全局注册,之后可在其他组件中通过 this.$axios 发送数据
Vue.prototype.$axios = axios
6.引入Element UI
npm i element-ui -S安装Element UI模块
在main.js中添加如下代码,引入Elment UI
import ElementUI from 'element-ui'
import 'element-ui/lib/theme-chalk/index.css'
Vue.use(ElementUI)
具体代码就不放了,放个效果图

Elment UI官网 有兴趣可以学习一下哈哈哈
7.后续的一系列问题
碰到最多的就是跨域问题,尤其是我在后端设置了拦截器以后,拦截器死活接收不到前端发来的Cookie,但使用postman,拦截器却可以接收到Cookie,所以我判断是前端出了问题。但百度了好几种方案,都失败了,也试过用原生js,但还是会出现跨域问题。
后来我请教了一个前端的大佬,他给出了解决方案
首先配置代理
//vue.config.js
module.exports = {
outputDir: 'dist', //build输出目录
assetsDir: 'assets', //静态资源目录(js, css, img)
lintOnSave: false, //是否开启eslint
devServer: {
open: true, //是否自动弹出浏览器页面
host: "localhost",
port: '8081',
https: false,
hotOnly: false,
proxy: {
'/api': {
target: 'http://localhost:8443',
changeOrigin: true,
pathRewrite: {
'^/api': ''//这里是正则表达式,把开头的/api的替换成'http://localhost:8443'
}
}
},
}
}
封装axios
//vue2.0以后,vue就不再对vue-resource进行更新,而是推荐axios
//Axios 是一个基于 promise 的 HTTP 库,封装好了许多http请求响应的方法
import axios from 'axios';
const service = axios.create({
//请求路径的前面被加上/api
baseURL:'/api/api',//第一个/api会被替换掉
timeout:10000,
});
export default service;
//export default命令用于指定模块的默认输出。显然,一个模块只能有一个默认输出,因此export default命令只能使用一次
封装post和get方法
import request from '../utils/request';
export function m_post(m_url, m_data) {
return request({
url: '/user/' + m_url,
method: 'post',
data: m_data
})
}
export function m_get(m_url) {
return request({
url: '/user/' + m_url,
method: 'get'
})
}
调用封装好的post
login() {
var that = this;
m_post("/login", {
username: this.loginForm.username,
password: this.loginForm.password
}).then(successResponse => {
if (successResponse.data.code === 200) {
that.$store.commit('login', {token: successResponse.data.data});
this.$router.replace({path: '/index'});
} else {
this.$message({
message: '用户名或密码错误',
type: 'error',
effect: "dark"
});
}
}).catch(failResponse => {
console.log("失败" + failResponse);
})
}
完美解决问题哈哈哈,感谢大佬
4.SpringBoot的学习
我们先来理清思路,大致3个功能,查询邮箱,添加邮箱,删除邮箱(软删除),以查询为例,其他的流程都差不多,就不多说了
后端
domain层
@Getter
@Setter
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class UserMail {
private int id;
private String mailName;
private int userId;
private int isUsed;
}
dao层
public interface MailMapper {
List<UserMail> queryUserMailById(int id);//用于查询的
int softDeleteMailByMailIdSelective(UserMail userMail);
List<UserMail> queryUserMailLikeMailName(UserMail userMail);
int insertUserMail(UserMail userMail);
}
service层
public interface UserService {
String login(String username, String pwd);
List<UserMail> selectMailsById(String token);
int deleteMail(UserMail userMail, String token);
List<UserMail> selectMailsLikeMailName(UserMail userMail, String token);
int addMail(UserMail userMail, String token);
}
service具体实现层
先验证再给数据,验证成功后获得用户的信息,根据这个信息以及前端传过来的数据决定返回给前端的数据
@Override
public List<UserMail> selectMailsLikeMailName(UserMail userMail, String token) {
User user = sessionMap.getOrDefault(token, null);
if (user == null) return null;
userMail.setUserId(user.getId());
return mailMapper.queryUserMailLikeMailName(userMail);
}
controller层
@PostMapping("selectMailsLikeMailName")
public JsonData selectMailsLikeMailName(@RequestBody Map<String, Object> map) {
ObjectMapper mapper = new ObjectMapper();
UserMail userMail = mapper.convertValue(map.getOrDefault("userMail", null), UserMail.class);
String token = (String) map.getOrDefault("token", null);
List<UserMail> mails = userService.selectMailsLikeMailName(userMail, token);
return mails != null ? JsonData.buildSuccess(mails) : JsonData.buildError("令牌错误");
}
数据操作
这里的id是dao层中mapper的函数名,传递的参数类型是UserMail,返回的结果是UserMailResultMap
<resultMap id="UserMailResultMap" type="com.example.ex4.domain.UserMail">
<id column="mail_id" property="id" jdbcType="INTEGER"/>
<result column="mail_name" property="mailName" jdbcType="VARCHAR"/>
<result column="user_id" property="userId" jdbcType="INTEGER"/>
<result column="is_used" property="isUsed" jdbcType="INTEGER"/>
resultMap>
<select id="queryUserMailLikeMailName" parameterType="com.example.ex4.domain.UserMail"
resultMap="UserMailResultMap">
select m.id mail_id,
m.mail_name,
m.user_id,
m.is_used
from mails m
where user_id=#{userId,jdbcType=INTEGER}
and is_used=1
and mail_name like concat('%',#{mailName,jdbcType=VARCHAR},'%')
select>
前端
vue展示
v-model="searchText":输入框的数据和searchText绑定@click="searchMails":按钮的点击事件
<div slot="header" class="clearfix">
<span style="display: flex;justify-content: center;align-items: center">
<el-input
prefix-icon="el-icon-search"
size="large"
style="margin-right: 10px"
v-model="searchText">
el-input>
<el-button size="large" type="primary" icon="el-icon-search" @click="searchMails">搜索el-button>
span>
div>
js
访问接口,并携带token和想要查询的信息,返回数据填充到cardList中用于展示
关于token的逻辑刚才已经讲过了,大家可以看一下前面的哈哈哈
searchMails() {
var that = this;
this.$axios.post('/selectMailsLikeMailName', {
userMail: {mailName: that.searchText},
token: JSON.parse(window.localStorage.getItem("user")).token
}).then(function (res) {
that.cardList = res.data.data;
});
}
以上就是我编写一个功能的全部流程,像添加和删除也是差不多的流程,如果这周有时间的话我应该会把session的安全机制改成token的,看有没有时间吧,先留个坑
5.token机制
为什么使用token,而不是session?
session
我们先来聊一下传统的session认证,http本身是一种无状态的的协议,即根据http协议我们无法知道识别是哪个用户发出的请求,所以就有了cookie和session的认证,但是这种基于session的认证使应用本身很难得到扩展,随着不同客户端用户的增加,独立的服务器已无法承载更多的用户,而这时候基于session认证应用的问题就会暴露出来

内存开销:每个用户经过我们的应用认证之后,我们的应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大
扩展性用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力
CSRF:因为是基于cookie来进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击

token
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或者会话信息。这就意味着基于token认证机制的应用不需要去考虑用户在哪一台服务器登录了,这就为应用的扩展提供了便利
基本流程:
- 用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息
- 服务器通过验证发送给用户一个token
- 客户端存储token,并在每次请求时附送上这个token值
- 服务端验证token值,并返回数据
JWT
Json Web Token
1.JWT能干嘛?
- 授权。这是使用JWT的最常见方案。一旦用户登录,每个后续请求将包括JWT,从而允许用户访问该令牌允许的路由,服务和资源。单点登录是当今广泛使用JWT的一项功能,因为它的开销很小并且可以在不同的域中轻松使用
- 信息交换。JSON Web Token是在各方之间安全地传输信息的好方法。因为可以对JWT进行签名(例如,使用公钥/私钥对),所以您可以确保发件人是他们所说的人。此外,由于签名是使用标头和有效负载计算的,因此您还可以验证内容是否遭到篡改
2.基于JWT的认证

3.JWT的结构
JWT通常如下所示:xxxxx.yyyyy.zzzzz Header.Payload.Signature

- 1.标头(Header)
- 标头通常由两部分组成:令牌的类型(即JWT)和所使用的签名算法,例如HMAC SHA256或RSA。它会使用 Base64 编码组成 JWT 结构的第一部分。
- 注意:Base64是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
{
"alg": "HS256",
"typ": "JWT"
}
- 2.有效载荷(Payload)
- 令牌的第二部分是有效负载,其中包含声明。声明是有关实体(通常是用户)和其他数据的声明。同样的,它会使用 Base64 编码组成 JWT 结构的第二部分
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
- 3.签名(Signature)
- 前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过
- HMACSHA256(base64UrlEncode(header) + “.” + base64UrlEncode(payload),secret);
4.签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的JWT的话,那么服务器端会判断出新的头部和负载形成的签名和JWT附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
5.信息安全问题
Base64是一种编码,是可逆的。所以,在JWT中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的User ID。这个值实际上不是什么敏 感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在JWT中了。如果将用户的密码放在了JWT中,那么怀有恶意的第 三方通过Base64解码就能很快地知道你的密码了。因此JWT适合用于向Web应用传递一些非敏感信息。JWT还经常用于设计用户认证和授权系统,甚至实现Web应用的单点登录
使用
1.导入JWT依赖
<dependency>
<groupId>com.auth0groupId>
<artifactId>java-jwtartifactId>
<version>3.4.0version>
dependency>
2.生成token
Calendar instance = Calendar.getInstance();
instance.add(Calendar.HOUR, 1);
Map<String, Object> map = new HashMap<>();
String token = JWT.create()
.withHeader(map)//header,可以不写,默认也是这个
.withClaim("userId", 1)//payload
.withClaim("userName", "ch")
.withExpiresAt(instance.getTime())//令牌过期时间
.sign(Algorithm.HMAC256("CH"));//签名
System.out.println(token);
3.token解码
JWTVerifier jwtVerifier = JWT.require(Algorithm.HMAC256("CH")).build();//生成验证者
DecodedJWT verify = jwtVerifier.verify("eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyTmFtZSI6ImNoIiwiZXhwIjoxNjA1OTM4NjU0LCJ1c2VySWQiOjF9.7w-1tcd4k8B-R_5sctk__-fxbAnplNjDe6f18_neLAA");
System.out.println(verify.getClaim("userId").asInt());//打印信息
System.out.println(verify.getClaim("userName").asString());
System.out.println(verify.getExpiresAt());//打印过期时间
4.工具类
public class JWTUtils {
private static final String SIGN = "!E@R#T$G%B^D&8";
/**
* 生成token
*/
public static String getToken(Map<String, String> map) {
Calendar instance = Calendar.getInstance();
instance.add(Calendar.DATE, 7);
JWTCreator.Builder builder = JWT.create();
map.forEach(builder::withClaim);
return builder.withExpiresAt(instance.getTime()).sign(Algorithm.HMAC256(SIGN));
}
/**
* 验证token合法性
*/
public static void verifyToken(String token) {
JWT.require(Algorithm.HMAC256(SIGN)).build().verify(token);
}
/**
* 获取token信息方法
*/
public static DecodedJWT getTokenInfo(String token) {
return JWT.require(Algorithm.HMAC256(SIGN)).build().verify(token);
}
}
5.常见的异常
- SignatureVerificationException: 签名不一致异常
- TokenExpiredException: 令牌过期异常
- AlgorithmMismatchException: 算法不匹配异常
- InvalidClaimException: 失效的payload异常

6.AOP优化JWT
其实就是添加拦截器,验证前端发来的HTTP头部中有无“Authentication-Token”(自定义的字段),然后根据token验证得到结果,如果token有效,就把它存进这个线程的局部变量里,也就是UserThreadLocal这个工具类中(自定义的工具类);token不合法就拦截并发送错误信息==(错误信息还没写,留坑)==
public class SessionInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String token = request.getHeader("Authentication-Token");
if (token == null) return false;
User user = JSONObject.parseObject(JWTUtils.getTokenInfo(token).getClaim("user").asString(), User.class);
if (user != null) {
UserThreadLocal.set(user);
return true;
}
return false;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
UserThreadLocal.set(null);
UserServiceImpl.getSqlSession().commit();
}
}
参考文献
什么是 JWT – JSON WEB TOKEN
JWT认证原理、流程整合springboot实战应用,前后端分离认证的解决方案!
6.总结
累!!!心累!!!
4.深入学习SpringBoot原理
耦合概念

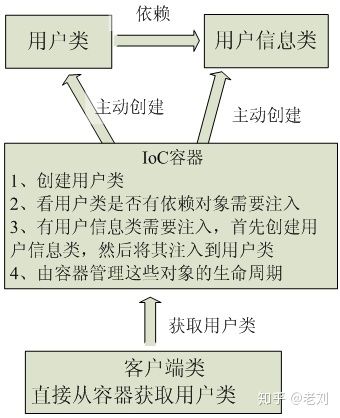
1.IOC(控制反转)
Inversion of Control
对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系
Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。

2.DI(依赖注入)
Dependency Injection
DI是IoC的一种实现方式
IOC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的,就比如下面这段代码,你是否有过疑问,我都没new,怎么就能使用了呢?这个就可以用DI去解释了,IOC容器会帮我们自动注入这个对象,从而使原来由自己把控的主动权转移给了IOC容器
@Autowired
private UserService userService;
DI的原理则是反射,在运行时根据类名反射得到它的方法,注解,属性等等
DI**(依赖注入)**其实就是IOC的另外一种说法,DI是由Martin Fowler 在2004年初的一篇论文中首次提出的。他总结:控制的什么被反转了?就是:获得依赖对象的方式反转了
3.AOP(面向切面编程)
Aspect Oriented Program
静态代理模式

- 抽象类——(租房)要完成的事情
public interface Rent {
void rent();
}
- 代理类——(中介)代理
public class Agent implements Rent {
public Host host;
public Agent() {
}
public Agent(Host host) {
this.host = host;
}
public void rent() {
seeHouse();
signContract();
host.rent();
}
public void signContract() {
System.out.println("签合同");
}
public void seeHouse() {
System.out.println("看房");
}
}
- 被代理类——(房东)
public class Host implements Rent{
public void rent() {
System.out.println("房东租房");
}
}
- 客户端类——(租客)
public class Client {
public static void main(String[] args) {
Host host = new Host();
Agent agent = new Agent(host);
agent.rent();
}
}
好处:
- 可以使真实角色的操作更加纯粹,不用关注一些公共的业务
- 公共部分交给代理角色,实现业务的分工
- 公共业务发生扩展的时候,方便集中管理
坏处:
- 一个真实角色就会产生一个代理角色,代码量翻倍,开发效率也低
动态代理模式
使用动态代理的原因(为什么使用动态而不是静态):
- 真实角色多,代理角色也会变多,导致代码臃肿
- 真实角色类中方法越多,代理角色的代码也会变多,如果增加公共代码也会变得复杂
- 试想一个场景,你的服务中有update,add,delete,query操作,你为它们需要为它们统一添加日志操作,你是不是会构建一个代理类,然后在每个方法前面加一句话。这样是可以做到公共业务的处理,也确实比在原有的service类中修改要来得更好一点,但依然没有解决你要在每个方法前加一个日志的操作,而动态代理则可以通过反射机制在运行时判断方法名来进行统一管理,极大缩减了代码量,下面我们来看一下例子
public interface MySqlService {
void query();
void add();
void delete();
void update();
}
public class MySqlServiceImpl implements MySqlService {
public void query() {
System.out.println("Mysql查询");
}
public void add() {
System.out.println("MySql添加");
}
public void delete() {
System.out.println("Mysql删除");
}
public void update() {
System.out.println("Mysql更新");
}
}
public class MyProxyHandler implements InvocationHandler {
private Object tar;
public Object bind(Object tar) {
this.tar = tar;
return Proxy.newProxyInstance(tar.getClass().getClassLoader(), tar.getClass().getInterfaces(), this);
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
log(method.getName());//面向切面编程
Object result = null;
result = method.invoke(tar, args);
return result;
}
private void log(String msg) {
System.out.println(msg);
}
}
public class Client {
public static void main(String[] args) {
MyProxyHandler proxy = new MyProxyHandler();
MySqlService service = (MySqlService) proxy.bind(new MySqlServiceImpl());
service.add();
}
}
重点关注第三段代码,可以发现如果我们使用静态代理,那是不是就要在每个方法前面都加一个log,但动态代理的话就只加了一次,是不是很方便
然后我们来总结一下动态代理的好处:
- Proxy类的代码量被固定下来了(浓缩到了一个类一个方法中)
- 可以实现AOP编程

AOP
这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程
AOP是对OOP的补充
面向切面编程(AOP是Aspect Oriented Program的首字母缩写) ,我们知道,面向对象的特点是继承、多态和封装。而封装就要求将功能分散到不同的对象中去,这在软件设计中往往称为职责分配。实际上也就是说,让不同的类设计不同的方法。这样代码就分散到一个个的类中去了。这样做的好处是降低了代码的复杂程度,使类可重用。
但是人们也发现,在分散代码的同时,也增加了代码的重复性。什么意思呢?比如说,我们在两个类中,可能都需要在每个方法中做日志。按面向对象的设计方法,我们就必须在两个类的方法中都加入日志的内容。也许他们是完全相同的,但就是因为面向对象的设计让类与类之间无法联系,而不能将这些重复的代码统一起来。
也许有人会说,那好办啊,我们可以将这段代码写在一个独立的类独立的方法里,然后再在这两个类中调用。但是,这样一来,这两个类跟我们上面提到的独立的类就有耦合了,它的改变会影响这两个类。那么,有没有什么办法,能让我们在需要的时候,随意地加入代码呢?这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
一般而言,我们管切入到指定类指定方法的代码片段称为切面,而切入到哪些类、哪些方法则叫切入点。有了AOP,我们就可以把几个类共有的代码,抽取到一个切片中,等到需要时再切入对象中去,从而改变其原有的行为。
这样看来,AOP其实只是OOP的补充而已。OOP从横向上区分出一个个的类来,而AOP则从纵向上向对象中加入特定的代码。有了AOP,OOP变得立体了。如果加上时间维度,AOP使OOP由原来的二维变为三维了,由平面变成立体了。从技术上来说,AOP基本上是通过代理机制实现的。
AOP在编程历史上可以说是里程碑式的,对OOP编程是一种十分有益的补充。
4.参考文献
如何完美的向面试官阐述你对IOC的理解?
什么是面向切面编程AOP?
Java 动态代理作用是什么?
第八节课(2020-11-26/第十周)
1.定时任务
对于定时任务我的理解是就是Linux里面的守护进程
1.1.作用
- 发邮件,短信
- 消息提醒
- 订单通知
- 统计系统信息
1.2.常见的实现
- java自带的Timer类
- Quartz框架
- SpringBoot自带的定时任务
1.3.SpringBoot自带的定时任务的使用
1.3.1.启动类添加注解@EnableScheduling

1.3.2.添加定时业务类
注意点:
- 需添加@Component才可以被启动类扫描到
- @Scheduled(fixedRate = 1000 * 60)用于规定定时任务的周期,这里以毫秒为单位,1000*60就是一分钟
- @Scheduled(cron = “*/1 * * * * *”)是非延时定时器的另一种写法
在线工具(可以了解一下,挺好用的)
cron表达式语法
[秒] [分] [小时] [日] [月] [周] [年]
注:[年]不是必须的域,可以省略[年],则一共6个域
/**
* @Description: 定时器类用于统计
* @Author: 陈恒
* @Time: 2020/11/29 下午2:50
*/
@Component
public class CountTask {
@Autowired
private TaskService taskService;//定时器服务
/**
* @param
* @Description: 每隔1分钟输出邮箱总数和用户总数
* @Return: void
* @Author: 陈恒
* @Time: 2020/11/29 下午2:51
*/
@Scheduled(fixedRate = 1000 * 60)//非延时定时器
//@Scheduled(fixedDelay = 2000)//延迟定时器
//@Scheduled(cron = "*/1 * * * * *")//非延时定时器的另一种写法
public void sumMailAndUser() throws InterruptedException {
//邮箱总数
System.out.println(LocalDateTime.now() + "当前邮箱总注册数:" + taskService.sumMail());
//用户总数
System.out.println(LocalDateTime.now() + "当前用户注册数:" + taskService.sumUser());
}
}
1.3.3.结果显示
相差了一分钟

2.异步任务
2.1.作用
- 适用于处理log,发送邮件,短信等
- 例如下单前的处理
- 下单接口——》查库存1000ms
- 余额校验1500ms
- 风控用户1000ms
我们可以试想一下,如果这个操作都是同步的,那我们所要花的时间是4500ms,但如果是异步的,理想情况下就是1500ms,会极大的缩减用户的等待时间,所以针对某些关联性不强的操作,我们可以采用异步的形式去完成1⃣️缩短时间
2.2.异步任务的使用
2.2.1.启动类添加注解@EnableAsync

2.2.2.定义异步任务
需要添加上@Component,@Async以确保被启动类扫描到
@Component
@Async
public class AsyncTask {
public void task1() throws InterruptedException {
Thread.sleep(4000);
System.out.println("task 1");
}
public void task2() throws InterruptedException {
Thread.sleep(4000);
System.out.println("task 2");
}
public void task3() throws InterruptedException {
Thread.sleep(4000);
System.out.println("task 3");
}
public Future<String> task4() throws InterruptedException {
Thread.sleep(4000);
System.out.println("task 4");
return new AsyncResult<>("task4");
}
public Future<String> task5() throws InterruptedException {
Thread.sleep(4000);
System.out.println("task 5");
return new AsyncResult<>("task5");
}
}
2.2.3.编写Controller测试
@RestController
@RequestMapping(value = "/api/test/")
public class AsyncTaskController {
@Autowired
private AsyncTask asyncTask;
@GetMapping("async")
public JsonData testAsync() throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
asyncTask.task1();
asyncTask.task2();
asyncTask.task3();
long end = System.currentTimeMillis();
return JsonData.buildSuccess(end - start);
}
}
2.2.4.观察结果
这个结果很明显是Controller把异步任务跑起来以后就直接返回了,相当于创建了3个子线程在跑异步任务,主线程就直接返回了

单看这个结果可能不明显,我们采用同步的方式试一下,我们把@Async这个注解注释掉,变成同步的了,4000+4000+4000=12000

2.2.5.改善
上面的那个结果是主线程不管异步任务的结果直接返回,但大多数情况下我们需要主线程和异步任务的线程有同步关系,简单点来说就是我们需要让这些线程有一定的执行顺序,比如1号线程执行完了,返回结果,但现在还不需要1号线程的结果,那主线程就先阻塞,直到等到需要的那个线程的结果
其实,我们会发现单线程执行的同步,速度太慢,和主线程没关联的异步任务虽然快,但我们不知道结果,所以我们可以折衷,异步任务多线程再跑,但是结果我们同步的拿取,我们下面就来介绍这个方法
其他的不用改,只要把Controller类改一下就好了,通过Future的get去阻塞的等待异步结果(关于Future的知识点在《网络编程笔记》中有详细记录,做个标记,可以回去复习一下)
@RestController
@RequestMapping(value = "/api/test/")
public class AsyncTaskController {
@Autowired
private AsyncTask asyncTask;
@GetMapping("async")
public JsonData testAsync() throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
Future<String> task4 = asyncTask.task4();
Future<String> task5 = asyncTask.task5();
while (true) {
if (task4.isDone() && task5.isDone()) {
System.out.println(task4.get());
System.out.println(task5.get());
break;
}
}
long end = System.currentTimeMillis();
return JsonData.buildSuccess(end - start);
}
}
2.5.6.改善后的结果
结果就变成了4s左右,符合我们的预期,不仅成功缩短了时间,而且还能在主线程中得到异步任务的结果

3.课后作业
3.1.去掉Mybatis中实体类的命名空间

下面截止官方文档,可以通过在xml或在实体类上写@Alias注解的方式去掉

<typeAliases>
<package name="com.example.ex4.pojo"/>
typeAliases>
3.2.加延时执行后定时任务的执行情况
3.2.1.@Scheduled(fixedRate = 1000 * 2)
我们可以发现,线程sleep(4000)的情况下,定时器会以这个任务为主,只有等到任务结束,才会继续启动定时器
———— ?———— ?———— ?
—— —— ——
也就是上面这个执行逻辑,?代表一个任务周期,包括定时器在内的
@Scheduled(fixedRate = 1000 * 2)//非延时定时器
public void sumMailAndUser() throws InterruptedException {
//邮箱总数
System.out.println(LocalDateTime.now() + "当前邮箱总注册数:" + taskService.sumMail());
//用户总数
//System.out.println(LocalDateTime.now() + "当前用户注册数:" + taskService.sumUser());
Thread.sleep(4000);
}

3.2.2.@Scheduled(cron = “*/2 * * * * *”)
在这里我们发现,这种定时器的写法是在任务执行完后的再定时执行,在这里任务执行需要6s,定时器每隔2s执行一次,所以是8s
—————— | —— ?—————— | —— ?—————— | —— ?
差不多就是上面这个执行逻辑
@Scheduled(cron = "*/2 * * * * *")//另一种写法
public void sumMailAndUser() throws InterruptedException {
//邮箱总数
System.out.println(LocalDateTime.now() + "当前邮箱总注册数:" + taskService.sumMail());
//用户总数
//System.out.println(LocalDateTime.now() + "当前用户注册数:" + taskService.sumUser());
Thread.sleep(6000);
}

3.3.fixedRate和fixedDelay的区别
fixedRate在上面已经看过了,我们主要看一下fixedDelay
我们可以发现它和@Scheduled(cron = “*/2 * * * * *”)这种写法的生命周期是一样的
—————— | —— ?—————— | —— ?—————— | —— ?
@Scheduled(fixedDelay = 2000)//延迟定时器
public void sumMailAndUser() throws InterruptedException {
//邮箱总数
System.out.println(LocalDateTime.now() + "当前邮箱总注册数:" + taskService.sumMail());
//用户总数
//System.out.println(LocalDateTime.now() + "当前用户注册数:" + taskService.sumUser());
Thread.sleep(5000);
}

总结一下区别:
fixedRate:
———— ?———— ?———— ?
—— —— ——
fixedDelay:
—————— | —— ?—————— | —— ?—————— | —— ?
第九节课(2020-12-3/第十一周)
1.IOC & AOP
在第七节课的深入学习SpringBoot原理和另外一篇关于Spring的笔记中有详细说明,这里不再赘述
2.补充
JDK动态代理和CGLib的动态代理的区别:
- JDK的动态代理基于接口实现
- CgLib动态代理的原理是对指定的业务类生成一个子类,并覆盖其中的业务方法来实现代理
- JDK代理是自带的,CGLib需要引入第三方包
- CgLib动态代理基于继承来实现代理,所以无法对final类,private方法和static方法实现代理
第十节课(2020-12-10/第十二周)
这节课主要讲了如何绘制功能图,协作时序图,完善数据库
详见画的那几张图
第十一节课(2020-12-17/第十三周)
主要讲了JWT,详见第七节课的第3小节:作业及扩展
课程总结
讲一下这个学期的心路历程吧
其实两门web课我都想选的,一个讲流行的框架,一个讲linux,我都很感兴趣,一时间难以抉择,但最后还是选了springboot,原因嘛,可能就是另外室友选了另外一门web,他们的作业我也可以做,这样就都能学到了。
从最初接触springboot,还是有点迷茫的,因为那个时候自己对自己的定位是C++的技术栈,想去学习关于C++和底层的东西,但学校的基本体系好像是想把我们培养成java栈(Android,网络编程,JSP,Springboot…),一时间有点迷惑,虽然很多时候告诉自己语言不是第一决定因素,但最后还是动摇了,选择去学习java,但我不想一开始就学习框架,我还是认为要先打好基础,事实证明我的想法是正确的,springboot的上手也就花了几天时间嘿嘿嘿
我的学习路线是:
java基础回顾——》java集合,IO,常用类,流——》网络编程,多线程基础(没有太深入,主要是没有应用场景不好模拟,没有那么多流量来完成高并发的模拟)——》注解&反射(太重要了!!!!想学好框架这个必学)——》JVM虚拟机(《深入JVM虚拟机》好书,但没看完,有点枯燥)——》javaWeb(Servlet,Filter,Listener,现流行的框架感觉也只是在这些基础上进行封装的)——》Mybatis(官方文档真的是学习一门新技术最好的教材)——》Spring——》SpringMVC——》SpringBoot
这就是我这个学习干的事情了,SpringBoot的学习和这些步骤是并行的,感觉学起来挺快乐的,说明我的基础还是蛮扎实的嘛哈哈哈
顺便安排一下关于寒假和下个学期的事情好了,继续学习Spring实战(第四版),然后重温数据库这一块的东西,包括但不限于Mysql底层,Redis,Mybatis实现原理等等,再则就是学习一下高并发和IO这一块的东西,最后就是算法和面经这一块的东西(这个可以穿插整个学习过程中),希望还来得及,最近事情也挺多的,外包,大作业。。。。自己的学习有点停滞,等忙完这一阵再开始学自己的东西吧,加油