Hierarchical Transformer Model for Scientific Named Entity Recognition 论文总结
Hierarchical Transformer Model for Scientific Named Entity Recognition
科学命名实体识别的层次变换模型
Github 地址:
https://github.com/urchade/HNER
摘要:
命名实体识别是关系抽取、知识图构造等自然语言处理系统的重要组成部分。在这项工作中,我们提出了一种简单有效的命名实体识别方法。我们方法的主要思想是使用一个预先训练好的转换器(如BERT)对输入子词序列进行编码,然后,在子词表示中添加另一层转换器,以更好地编码词级交互,而不是直接对词标签进行分类。我们在三个科学NER基准数据集上评估我们的方法,特别是在计算机科学和生物医学领域。实验结果表明,在不需要外部资源或特定数据扩充的情况下,我们的模型在SciERC和TDM数据集上的性能优于当前最先进的模型。代码可在
1.介绍
从科学文本中提取实体是自然语言处理的一项重要任务。虽然传统方法是基于手动生成的特征,但诸如BERT(Devlin等人,2019年)等预先训练的语言模型最近取得了有竞争力的结果。然而,由于BERT是在维基百科和Bookcorpus的一般文本上接受预训练的,在之前的几项工作中,它在特定领域任务上的表现被证明是次优的(Beltagy et al.,2019;Lee et al.,2019)。这些实证研究结果推动了特定领域预训练语言模型的发展。特别是,一些特定领域的变压器已通过拥抱脸的变压器库公开提供。例如,科学领域有SciBERT(Beltagy et al.,2019),生物医学领域有BioBERT(Lee et al.,2019) 以及金融领域的芬伯特(Yang等人,2020年)。
与之前的工作相比,经过预培训的变形金刚(如SciBERT或BioBERT)在科学领域取得了优异的性能。然而,尽管取得了这一成功,但他们对NER的传统微调可能并不理想,因为他们通常会将每个单词的第一个子项表示分类为标签序列。一些工作试图通过将NER设计为基于span的分类而不是序列标签来避免这个问题(Eberts and Ulges,2020)。然而,这些方法更难实现,并且需要许多额外的超参数,例如负样本数和窗口大小。在这项工作中,我们采用了使用BIO方案的传统序列标记方法,但不是直接对单词标签进行分类,而是在子单词表示的顶部添加了一个转换层(V aswani et al.,2017),以更好地编码单词级交互。更具体地说,每一次在单词分类之前,每个单词的名称都会通过一个附加的转换层。架构中的这一微小变化可以显著提高性能。
2.模型
在本文中,我们将NER任务视为生物标签的一种分类。我们的模型由三个主要元素组成:预训练的转换层、单词级交互层和由线性层和CRF层组成的分类层。
预训练转换器层
我们架构的第一部分是一个预训练的转换器模型,用于将输入子词编码到上下文嵌入中。通常情况下,这一步需要考虑像BERT(Devlin et al.,2019)或RoBERTa(Liu et al.,2019)这样的模型,但由于我们处理的是科学文献,所以我们使用了一种称为Scibert(Beltagy et al.,2019)的领域特定模型。
字级层
该组件将前一层中每个字的第一个子字作为输入,并对它们与单层转换器的交互进行编码(V aswani et al.,2017)。与之前直接对第一个子项进行分类的模型不同,添加该层为序列标记提供了更好的表示。
分类层
最后,该组件使用线性层将每个单词表示分类到相应的标签中。此外,通过使用CRF层(Lafferty et al.,2001),我们通过在推理过程中添加约束(例如,标签O不得位于标签I之前),确保所有输出标签有效,这也使得评估更容易。
3.实验
3.1数据集
SciERC是(Luan等人,2018年)引入的用于科学信息提取的数据集。该数据集由500篇摘自人工智能相关论文的摘要组成。它们被标注为科学实体、它们之间的关系和会议集群。
TDM是最近发布的一个NER数据集(Hou等人,2021年),用于检测自然语言处理论文中的任务、数据集和度量(TDM)。它由从自然语言处理论文全文中提取的句子组成,而不仅仅是摘要。
NCBI(Do˘gan等人,2014)是一个NER数据集,旨在识别PubMed文章摘要中生物医学文本中提到的疾病。

表1:数据集的统计数据
3.2实施细节
结构
对于所有实验,我们使用了推荐版本的SciBERT(Beltagy等人,2019),其中包含12个变换层,预训练模型的隐藏维度为768。在字级层的情况下,我们使用了一个隐藏维度为768和8个注意头的单层双向转换器。我们还实验了一个Bi LSTM(Hochreiter和Schmidhuber,1997),在字级转换器层中使用了768的隐藏dim,以查看性能上的差异。最后一层是一个线性层,用于将单词表示投影到标签空间,然后将其送入CRF层进行解码。
超参数
我们没有对超参数进行广泛搜索,而是根据(Devlin等人,2019年)的建议进行搜索。对于所有数据集,我们选择了3e-5的学习率,并对TDM和SciERC使用了4的批量大小,对NCBI数据集使用了16的批量大小。我们对所有模型进行了多达25个历次的训练,完成后,我们选择了验证集中f1成绩最好的模型。
受半监督和自监督学习研究(Tarvainen和V alpola,2018;He等人,2020)的启发,我们在学习期间保持所有参数的指数移动平均值(EMA)。我们发现,这种简单的技术几乎不需要任何成本就能产生额外的性能。更正式地说,在每个梯度之后,θ0 k=λθ0 k−1 + (1 − λ) θk,其中θk和θ0 k分别表示模型的参数和k阶移动平均值的参数。此外,λ是EMA更新的超参数,通常设置为接近1.0的浮点数;在我们的实验中,我们使用了0.99的λ。
我们所有的模型都是用一个V100 GPU训练的。
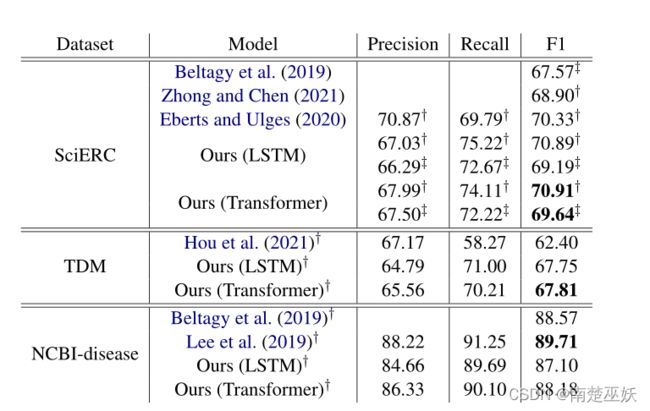
表2 此表比较了我们的模型在科学文本命名实体识别方面的性能与最新水平。这里给出的结果是从三种不同的随机种子中获得的最佳结果。†:微平均;——:宏观平均
3.3评估
我们根据黄金实体和预测实体之间的精确对应关系评估模型。此外,与之前的研究一致,我们排除了非实体跨度。因此,我们考虑精度,回忆和F评分作为衡量标准,由SEQEAL图书馆(NKAYAMA,2018)。对于SciERC,我们报告了微观和宏观平均值,然而,我们仅报告了TDM和NCBI疾病的微观平均值,以与之前的工作进行比较。
3.4主要结果
我们实验的主要结果如表2所示。这表明,我们的最佳模型能够在SciERC和TDM方面超越最新水平,并在NCBI数据集上获得有竞争力的结果。
在SciERC上,我们的模型能够以显著的优势超过SciBERT(Beltagy et al.,2019)(F1宏为+2)。我们的方法也能够超越基于跨度的方法,如PURE(Zhong和Chen,2021)和Spert(Eberts和Ulges,2020),同时采用更简单的方法。更具体地说,我们在F1 micro上的成绩是70.91,而斯佩特目前的水平是70.33。
我们的模型在不使用任何数据增强技术的情况下,在F1 micro上比TDM数据集上的最新水平高出5个点。
最后,我们的方法在NCBI数据集上也显示了有竞争力的结果,但没有超过最先进的水平。我们的模型与原始的SciBERT-NER模型具有大致相同的性能。然而,目前最先进的BioBERT-NER模型在F1微型赛车上比我们的模型高出一个百分点以上
3.5 Bi LSTM与Transformer
表2还报告了我们使用Bi LSTM作为字级层的实验。我们可以看到,对于所有数据集,transformer比Bi LSTM层更高效。然而,变压器的额外增益可能是因为它包含更多参数。
3.6消融研究
在这里,我们进行了一项消融研究,以了解我们提出的模型的不同组成部分的贡献。详细地说,我们检验了单词层的添加和指数移动平均模型的有效性。报道的结果是三种不同随机种子的微F1平均值。
字级层
在这项研究中,我们通过将我们的单词级交互方法与相同参数数的子单词级交互方法进行比较,来检验其有效性。更具体地说,子词级交互是通过简单地在scibert表示的顶部添加另一层转换器来实现的。下表显示了两种方法之间的比较

表3 消融研究:词级与子词级表征
如表3所示,在单词级别对信息进行编码实际上是有益的。我们从实验结果中证明,我们的方法提供的额外性能不仅是由于参数数量较多,而且是因为它在单词之间产生了更好的表示来预测NER标记。直观地说,我们的方法迫使每个第一个子项通过自我注意机制对整个单词信息进行编码,然后添加转换层来模拟它们之间的交互。
指数移动平均线
如表3所示,在单词级别对信息进行编码实际上是有益的。我们从实验结果中证明,我们的方法提供的额外性能不仅是由于参数数量较多,而且是因为它在单词之间产生了更好的表示来预测NER标记。直观地说,我们的方法迫使每个第一个子项通过自我注意机制对整个单词信息进行编码,然后添加转换层来模拟它们之间的交互。
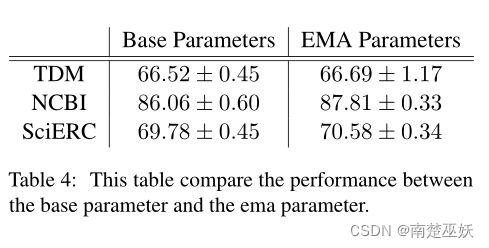
表 4 此表比较了基本参数和ema参数之间的性能。
表4显示,在训练期间保持参数的指数移动平均值几乎可以免费提供额外的性能增益。对于我们训练模型的所有数据集,EMA版本的性能都优于基线。事实上,保持参数的移动平均值可以被视为对之前所有模型检查点的软集成。此外,保持模型参数的EMA可用于任何深度学习任务,而不限于命名实体识别。在更广泛的NLP任务中研究它的有效性可能很有趣,但它不在我们的研究范围内,所以我们将其留给未来的工作。
4 相关工作
NER的早期作品由手工制作的特征和类似CRF的模型组成。深度学习的出现使得端到端的模型培训成为可能。在深度学习的早期,大多数NER模型使用基于LSTM的架构,具有单词和字符级编码,CRF层用于解码(Lample等人,2016;Huang等人,2015)。最近,伯特的到来极大地改变了自然语言处理领域。在NER方面,BERT的论文提出通过对每个单词的第一个子项的隐藏表示进行分类来进行NER,以进行序列标记。然后,通过Beltagy等人(2019年)和Lee等人(2019年)等的工作,这种方法已经适应了不同的领域,如科学领域。例如,Beltagy等人(2019年)使用scibert作为编码器,将第一个子项投影到标签空间,然后使用CRF层进行解码(Eberts and Ulges,2020;Zhong and Chen,2021)。一些研究采用了基于广度的方法,而不是传统的序列标记。在基于跨度的方法中,序列中最大长度的每个跨度都被枚举、聚合,然后分类。这些方法特别适用于建模联合实体和关系提取(Wadden等人,2019)以及嵌套命名实体识别。
5 结论
在本文中,我们提出了一种新的应用命名实体识别体系结构。我们的模型在两个科学NER基准(即SciERC和TDM数据集)上的表现优于最新水平,并在NCBI疾病数据集上实现了具有竞争力的性能。我们的模型的优点是简单,不需要额外的数据或外部资源(如gazetter)来实现竞争结果。我们的实证结果还表明,在学习过程中保持模型参数的指数移动平均值可以在可忽略的计算资源(时间复杂度)下提供额外的性能增益。