关于使用深度学习进行三维点云几何压缩
文章目录
-
- 前言
- 了解名词
-
- 1. 点云
- 2. 体素
- 3. 表示学习
- 4. 损失函数
- 5. BPP
- 相关工作
-
- 1. 点云表示学习
- 2. 点云几何压缩
- 层次自编码(整体解压缩流程)
-
- 1. 多尺度特征提取
- 2. 分层共建
- 评估
-
- 1. 三维点云几何压缩
- 2. 局部特征大小的影响
- 3. 损失函数的影响
- 总结
- 引文
前言
近些年来,随着计算机软硬件等的不断发展,计算机视觉、现实增强等让那些我们觉得不会发生的事情发生了,不得不说,科技正在改变我们的生活,给我们的生活带来了更多的便利。
三维点云在计算机视觉、自动驾驶、增强现实、智慧城市、虚拟现实等领域得到了广泛的应用。而高压缩比、低损耗的三维点云压缩方法是提高数据传输效率的关键。
所以这里提出了一种基于深度学习的三维点云压缩方法,该压缩方法在细节重构方面的性能优于其他网络。这使它可以在保持可容忍的损失的情况下,达到比现有技术更高的压缩比。同时,它还支持 GPU 对多个模型进行并行压缩,大大提高了处理效率。
了解名词
1. 点云
点云,简单来说就是一堆的点,这些点包含了丰富的信息,根据应用场景的不同,我们所能知道的点云的信息也有所不同。

比如上面点云组成的椅子,简单来看,我们能够知道椅子的轮廓。通过点的颜色,我们能够知道点的稠密,从而得到椅子的其他属性。
2. 体素
体素是体积元素(Volume Pixel)的简称,是数字数据于三维空间分割上的最小单位。
就像无线地拉大张图片,我们能够看到图片是由一个个的像素小方块组成的。

体素也是如此,就像著名的沙盒游戏 MineCraft 一样,这个世界中的很多建筑等都是由 1x1 的小方块组成的。
同像素一样,体素本身并不含有空间中位置的数据(即它们的坐标),然而却可以从它们相对于其他体素的位置来推敲。
3. 表示学习
为了提高机器学习的准确率,我们就需要将输入的信息转换成有效的特征,这种行为被称为表示(Representation)。
表示学习(Representation Learning)就是一种可以自动地学习出有效特征的算法,并在最终提高了机器学习的性能的一种学习。
4. 损失函数
损失函数就是一种函数,可以对我们的模型进行评估,通过损失函数我们能够看到深度学习中需要优化的部分,进而对模型进行优化。
5. BPP
BPP(bit per pixel) 是评判压缩算法好坏的重要指标之一,表示每个像素占据的比特位数。从压缩的目的来看,BPP越小越好。
相关工作
使用深度学习进行三维点云几何压缩要做的事情也就两项:点云表示学习以及点云数据压缩。点云表示学习在这里起到了一个预处理的作用,把数据预处理后能够更方便地压缩。
1. 点云表示学习
大多数处理点云的神经网络都是基于体素模型,把原始模型分割成三维的规则体素,就像把 MineCraft 中的建筑拆解成一个个方块,可以让我们更方便地处理体素模型。然而,把稀疏的点云数据转化成体素模型需要大量的时间和内存。其次,和图片一样,如果我们需要高分辨率的体素模型就需要更小的体素块,但机器的内存是有限的,内存会极大限制模型的分辨率。因此,需要想办法去平衡分辨率与时间、内存等因素的关系。
这里介绍以下几种点云表示学习的方法:
① 由 Gernot 等人提出的 OctNet。试图通过将体素模型转换为具有不同叶子节点大小的不平衡八叉树来减少计算和内存需求。这样可以将高分辨率模型表示为不同尺寸体素的组合,减少内存浪费,提高计算效率。
② Kd-Network 处理基于 kd-树的点云,降低空间复杂度。也有作品将三维点云模型描述为多视图图像,但是,转换为图像集合可能会破坏三维模型的空间特征。
③
2. 点云几何压缩
点云是一大堆点,存储这些点云数据会大量消耗内存,而且不利于传输。
举个不是特别恰当的例子,假如未来有一天你正开着无人驾驶车,开的过程中它突然无人驾驶系统突然卡了,那就一失两命了。

有人可能会说我们只要不断的往车里堆加内存等不就行了?但是车的容量是有限的,堆加这些设备就意味着要增大车的体积或者降低其它部件的体积,而且汽车厂商也是要考虑成本滴。
所以,为了大家都从中获益,点云压缩显得尤为重要。
点云压缩主要包括三种类型:几何压缩、属性压缩和动态运动补偿压缩。 在这里主要研究几何压缩。一般而言,体素模型的体、面、边、点的形状分布既不规则、也不均衡,其它压缩技术难以适应它的特点以取得高效的压缩结果。而几何压缩用尽可能少的比特来反应连接信息和几何信息,并将这些比特顺序排列形成比特数据流,然后用数据压缩方法压缩这个比特数据流。
层次自编码(整体解压缩流程)
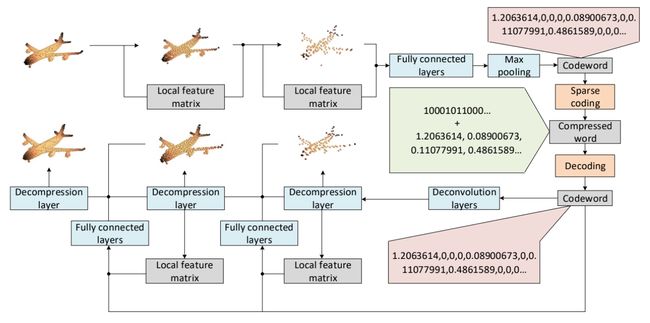
1. 多尺度特征提取
在这里,使用率改进的多尺度分层编码器。通过最远点采样(FPS)得到局部区域中心,即在静止点集中迭代地选择距离之前所有采样点最远的点。利用一维卷积层和最大池化层提取局部区域特征。局部区域中心用来确定新的局域特征提取中心。

这些中心的坐标与局部特征相结合,构成新的特征,并提供给下一局部特征提取层。最后,所有的局部特征通过全连接层将被最大化池层组合起来,产生了最终的综合特征模型。
2. 分层共建
在对压缩数据进行点云重构时,采用分层结构来提高细节的重构能力。

该结构由三个不同分辨率的输出层组成。第一个输出层的输出给出整个点云的基本框架,后面的输出层逐渐为框架添加了更多的细节。后一层的输出依赖于前一层的输出。通过这种方法,我们可以得到原始点云数据的多种分辨率表示。
评估
模型建成后,我们需要对模型进行一系列的评估,来判断我们所完成的模型的优劣,就像我们考完试老师给我们打分一样。
为了清晰地显示网络的训练过程,证明文中的编码器从点云中提取了有效的特征,这里在潜在空间中实现了两个码字之间的差值,并根据差值结果重建模型。
1. 三维点云几何压缩
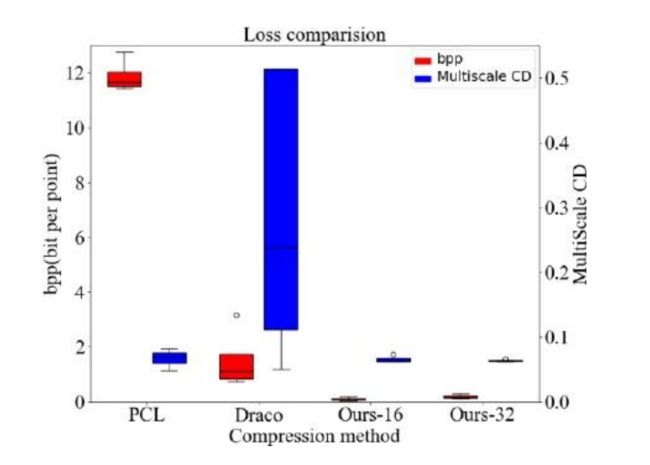
从上图可知,bpp较小时,文中的深度学习压缩算法可以达到比Draco 高 10 倍的压缩比,甚至比 PCL 高 110 倍,同时保持较小的重构损失。
但是 PCL和 Draco 更快,更节省内存,这是因为 PCL 和 Draco 都是基于 C 程序的,这比 Python 要高效得多。其次,文中作者使用 Tensorflow 来替换文中大部分的工作,这会大大增加深度学习压缩器的内存开销。因此,用 C程序简化网络模型,替换 Tensorflow 中的大部分操作,可以提高效率,减少内存负载。
2. 局部特征大小的影响
文中的编码器是基于原始点云的局部特征提取。改变了局部特征提取的邻域大小会对训练结果产生很大的影响。研究了局部区域规模与重建质量之间的关系。
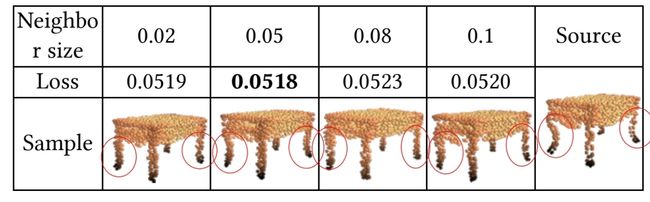
结果表明,局部特征提取的邻域大小对细节重建有很大影响。邻域大小过小不能包含足够多的点来描述局部特征,过大就会忽略了局部区域的细节,导致重建不准确。
3. 损失函数的影响
通过不同的损耗函数来训练模型,可以看到 CD 和 RMS 可以保留模型的基本轮廓,但会导致重建不均匀。虽然 EMD 可以得到更均匀的结果,但它生成的图比较粗糙。多尺度RMS 和 多尺度CD 都可以实现精确、均匀的重建。
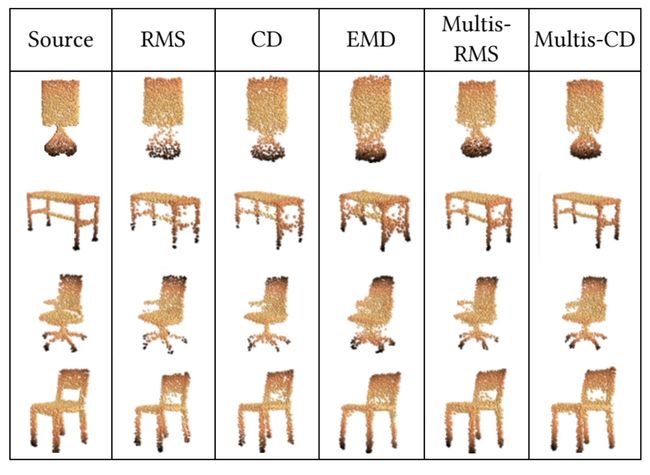
从下表可以看出,用 CD 训练的网络CD 和 RMS 损耗都较小,说明 CD 比 RMS 的约束更强。多尺度CD 和 多尺度RMS 也遵循着同样的规律。
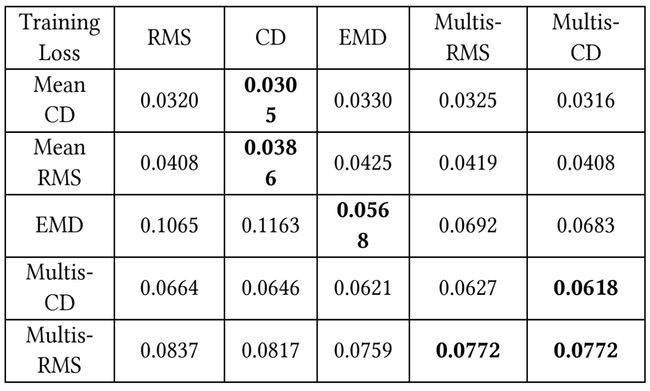
综上,多尺度CD 是最佳的损耗函数,对网络进行精确、均匀的重构具有强大的训练能力。
总结
这篇论文提出了一种新的深度学习自编码器处理来处理无序点云数据,与以往的无监督神经网络相比,具有更低的重构损失和更强的细节重构能力。
同时,作者设计了一种新的基于深度学习的稀疏点云几何压缩方法。它比现有的任何压缩方法都能达到更高的压缩比,且压缩损耗可接受。 它还提供了三种不同分辨率的输出,适合不同的场合。
毫无疑问,深度学习是数据压缩未来的发展方向!
引文
- 3D Point Cloud Geometry Compression on Deep Learning
- Deep Learning for 3D Point Clouds: A Survey
- 人工智能之表示学习
- 干货 | 用深度学习设计图像视频压缩算法:更简洁、更强大
- On Visual Similarity Based 3D Model Retrieval