python实现Pearson相似度/皮尔逊相关系数
pearson相似度的计算公式:
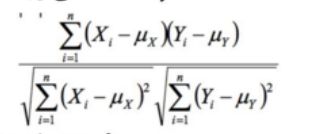
其中  是均值,
是均值,![]() 是指 x 的均值。
是指 x 的均值。
代码如下所示:
def mean_processed(a):
b = np.zeros_like(a)
num = 0
for i,j in enumerate(a):
if j != 0:
num += 1
for i,j in enumerate(a):
if j != 0:
b[i] = np.sum(a) / num
# print(np.sum(a) / num)
# print(b)
return b
def Pearson_similar(item1_score, item2_score):
# 将列表转换为可计算的np.array类型
item1_score = np.array(item1_score)
item2_score = np.array(item2_score)
# 计算item中有值的数量,以及他们的平均值
item1_score_mean = mean_processed(item1_score)
item2_score_mean = mean_processed(item2_score)
# 计算item减去均值
item1_chazhi = item1_score - item1_score_mean
item2_chazhi = item2_score - item2_score_mean
fenzi = np.sum(item1_chazhi * item2_chazhi)
print(fenzi)
# 计算差值的平方
item1_chazhi_squre = np.power(item1_chazhi, 2)
item2_chazhi_squre = np.power(item2_chazhi, 2)
fenmu = np.sqrt(np.sum(item1_chazhi_squre)) * np.sqrt(np.sum(item2_chazhi_squre))
print(fenmu)
similar = fenzi / fenmu
return similar
a = [1.0, 0.0, 3.0, 0.0, 0.0, 5.0, 0.0, 0.0, 5.0, 0.0, 4.0, 0.0]
# b1 = [0.0, 0.0, 5.0, 4.0, 0.0, 0.0, 4.0, 0.0, 0.0, 2.0, 1.0, 3.0]
b2 = [1.0, 0.0, 3.0, 0.0, 3.0, 0.0, 0.0, 2.0, 0.0, 0.0, 4.0, 0.0]
Pearson_similar(a, b2)