Pytorch《DCGAN模型》
这一博文我们来共同学习下DCGAN,也就是深度卷积GAN的意思。
一:DCGAN(Deep Convolutional Generative Adversarial Networks)原理
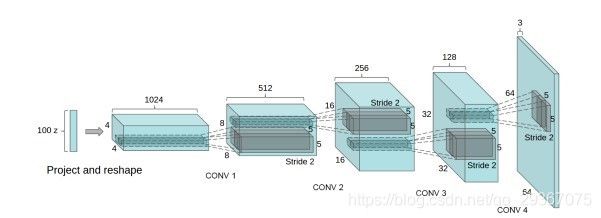
上图是构造器的结构。
和普通的卷积神经网络很相似,作为GAN发展出来的网络,其实原理和GAN是一样的,是把D模型和D模型网络换成了卷积神经网络,还做了一些结构上的变化,这些变化可以提高网络输出样本的质量和收敛速度。另外顺带提一下,GAN的作用还有就是构造数据的作用,有时候我们无法得到大量的数据,我们可以自己只在一些数据,比如图像数据,可以对图像翻转,旋转,加噪声,锐化,模糊化,卷积等操作,我们还可以利用GAN网络来生成类似于现实的图片,这样得到的信息就会更多。
如下是DCGAN设计技巧
- 所有的pooling层使用步幅卷积(判别网络)和微步幅度卷积(生成网络)进行替换;
- 在生成网络和判别网络上使用批处理规范化;
- 对于更深的架构移除全连接隐藏层;
- 在生成网络的所有层上使用ReLU激活函数,除了输出层使用Tanh激活函数;
- 在判别网络的所有层上使用LeakyReLU激活函数;
这里是翻译自论文:https://arxiv.org/abs/1511.06434
这几个结构上的改变挺容易明白的,下面我用个简单的例子来实践一下。
二:运行实例(生成Naruto的图片的图片)
今天是10月10号,也是火影迷心中的男神漩涡鸣人的生日,就用DCGAN生成一个漩涡鸣人的照片,
定义构造器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.genProcess = nn.Sequential(
nn.ConvTranspose2d(100, image_size * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(image_size * 8),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 8, image_size * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 4),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 4, image_size * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 2),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 2, image_size, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size),
nn.ReLU(True),
nn.ConvTranspose2d(image_size, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
x = self.genProcess(x)
return x
定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.disProcess = nn.Sequential(
nn.Conv2d(3, image_size, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size, image_size * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 2, image_size * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 4, image_size * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.disProcess(x)
return x
这里完整代码如下:
这里完整代码如下:
这里完整代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import os
from torch.autograd import Variable
from torchvision.utils import save_image
# ===================
# 今天是10.10号,是火影迷男神漩涡鸣人的生日,今天用DCGAN来生成鸣人的生日
# 作品完成的时候是欧洲东三区时间晚上10点多,因此还是赶得上时间的尾巴了。
# Step 1: 加载图片数据===============================================
image_size = 64 # 图片大小
batch_size = 6 # 批量大小,我就只用6个鸣人的图片做个测试的哈,都是从百度上取截图取得的。
def preprocess_img(img):
out = 0.5 * (img + 1)
out = out.clamp(0, 1)
out = out.view(-1, 3, 64, 64)
return out
data_path = os.path.abspath("D:/software/Anaconda3/doc/3D_Img/")
print (os.listdir(data_path))
# 请注意,在data_path下面再建立一个目录,存放所有图片,ImageFolder会在子目录下读取数据,否则下一步会报错。
dataset = datasets.ImageFolder(root=data_path, transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Step 2: 定义模型===============================================
# 定义鉴别器网络G
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.genProcess = nn.Sequential(
nn.ConvTranspose2d(100, image_size * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(image_size * 8),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 8, image_size * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 4),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 4, image_size * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 2),
nn.ReLU(True),
nn.ConvTranspose2d(image_size * 2, image_size, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size),
nn.ReLU(True),
nn.ConvTranspose2d(image_size, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
x = self.genProcess(x)
return x
# 定义鉴别器网络D
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.disProcess = nn.Sequential(
nn.Conv2d(3, image_size, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size, image_size * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 2, image_size * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 4, image_size * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(image_size * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(image_size * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.disProcess(x)
return x
# Step 3: 定义模型和损失函数和优化器===============================================
# 实例化构造器和生成器
G = Generator()
D = Discriminator()
# 定义损失函数,依然用的是二分类的交叉熵损失函数
criterion = nn.BCELoss()
# 和两个模型的优化器
g_optimizer = optim.Adam(G.parameters(), lr=3e-4, betas=(0.9, 0.999))
d_optimizer = optim.Adam(D.parameters(), lr=3e-4, betas=(0.9, 0.999))
# 判别器的损失值计算的函数
def discriminator_loss(d_real_decision, d_fake_decision): # 判别器的 loss
size = d_real_decision.shape[0]
true_labels = Variable(torch.ones(size, 1)).float()
size = d_fake_decision.shape[0]
false_labels = Variable(torch.zeros(size, 1)).float()
loss = criterion(d_real_decision, true_labels) + criterion(d_fake_decision, false_labels)
return loss
# 生成器的损失值计算的函数
def generator_loss(g_fake_decision): # 生成器的 loss
size = g_fake_decision.shape[0]
true_labels = Variable(torch.ones(size, 1)).float()
loss = criterion(g_fake_decision, true_labels)
return loss
# Step 4: 开始训练===============================================
os.mkdir('D:/software/Anaconda3/doc/3D_Img/dcgan')
num_epochs = 3000 # 循环次数
for epoch in range(num_epochs):
for index, imgs in enumerate(dataloader, 0):
# step 1,训练判别器
img_data = imgs[0]
print(img_data.shape)
train_batch_size = img_data.size(0)
# img_data = img_data.view(train_batch_size, -1) # 这里是展开成[batch_size, w * h] 维度
d_real_decision = D(Variable(img_data)) # 训练真实的图片,经过D模型,标签是1
d_fake_input = Variable(torch.randn(train_batch_size, 100, 1, 1)) # 生随机数 100 * 1 * 1
d_fake_imgs = G(d_fake_input).detach()
d_fake_decision = D(d_fake_imgs) # 训练构造的图片,经过D模型,标签是0
d_total_error = discriminator_loss(d_real_decision, d_fake_decision) # 计算判别器的 loss
d_optimizer.zero_grad()
d_total_error.backward()
d_optimizer.step()
# step 2,训练生成器
g_fake_imgs = G(d_fake_input)
g_fake_decision = D(g_fake_imgs) # 训练构造的图片,经过D模型,假想标签是1
g_fake_error = generator_loss(g_fake_decision) # 计算构造器的 loss
g_optimizer.zero_grad()
g_fake_error.backward()
g_optimizer.step()
if epoch % 200 == 0:
print("Epoch[{}/{}]".format(epoch, index))
real_images = preprocess_img(g_fake_imgs.data)
save_image(real_images, 'D:/software/Anaconda3/doc/3D_Img/dcgan/test_%d.png' % (epoch))
饲喂的数据是,没错我就在百度上截取了6个:

训练效果如下,感觉很模糊啊,但是已经有鸣人的大致轮廓了,可能是数据太少了:

参考学习:
https://blog.csdn.net/qq_37172182/article/details/103650862
https://www.it610.com/article/1289832950736691200.htm
https://blog.csdn.net/Sophia_11/article/details/107960750
https://zhuanlan.zhihu.com/p/24767059
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#