Tensorflow2.0 U-Net医学图像分割(胸部X光图像分割)
1.U-Net网络结构
论文题目:《U-Net: Convolutional Networks for Biomedical Image Segmentation》
论文地址:https://arxiv.org/abs/1505.04597
U-Net发表于 2015 年,其初衷是为了解决生物医学图像方面的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。
U-Net网络结构:
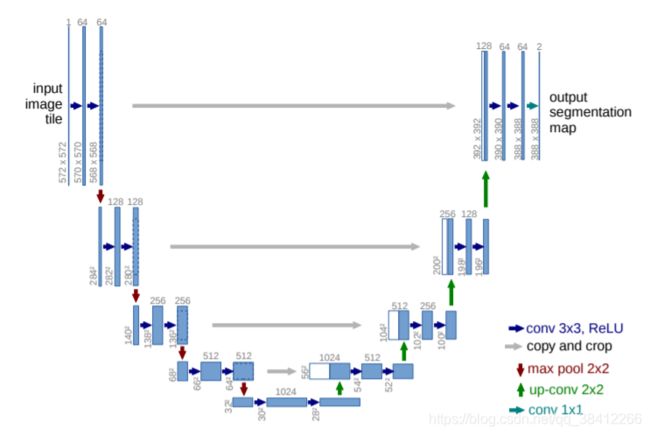
图中各个框和箭头的含义:
1.蓝色和白色的框表示feature map,即特征图
2.蓝色箭头表示将特征图进行3x3卷积+relu激活函数,主要用于特征提取
3.灰色箭头表示跳跃连接(通常用于残差网络中),在这里是用于特征融合,其中copy and crop的意思是将左边的特征图进行剪切,使其大小和右边的特征图一样,然后再进行融合
4.红色箭头表示池化 ,用于缩小特征图
5.绿色箭头表示上采样 ,用于放大特征图
6.青蓝色箭头表示 1x1 卷积,用于调整通道数,最后输出结果
左侧为特征提取部分,右侧为上采样部分,在这里每进行上采样一次就相当于和特征提取部分对应的通道数相同尺度融合,融合之前需要将特征图的大小按照左侧图中的虚线进行调整。
2.数据集
链接:https://pan.baidu.com/s/1WOn-9nFgMymA8dSQ2_bVcg
提取码:uyoi
采用的是kaggle上的胸部X光图像分割数据集,我们使用CXR_png文件夹和masks文件夹里面的图片进行实验

胸部X光图像
对应的分割图像
3.代码
#导入相应的库
import numpy as np
import pandas as pd
from tqdm import tqdm
import os
import cv2
from glob import glob
%matplotlib inline
import matplotlib.pyplot as plt
from tensorflow.keras import backend as K
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler, EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
#设置数据集路径
image_path = os.path.join("../input/chest-xray-masks-and-labels/Lung Segmentation/CXR_png/")
mask_path = os.path.join("../input/chest-xray-masks-and-labels/Lung Segmentation/masks/")
#读取图片
images = os.listdir(image_path)
mask = os.listdir(mask_path)
mask = [fName.split(".png")[0] for fName in mask]
testing_files = set(os.listdir(image_path)) & set(os.listdir(mask_path))
training_files = [i for i in mask if "mask" in i]
#处理训练集和测试集图片函数
def getData(X_shape, flag = "test"):
im_array = []
mask_array = []
if flag == "test":
for i in tqdm(testing_files):
im = cv2.resize(cv2.imread(os.path.join(image_path,i)),(X_shape,X_shape))[:,:,0]
mask = cv2.resize(cv2.imread(os.path.join(mask_path,i)),(X_shape,X_shape))[:,:,0]
im_array.append(im)
mask_array.append(mask)
return im_array,mask_array
if flag == "train":
for i in tqdm(training_files):
im = cv2.resize(cv2.imread(os.path.join(image_path,i.split("_mask")[0]+".png")),(X_shape,X_shape))[:,:,0]
mask = cv2.resize(cv2.imread(os.path.join(mask_path,i+".png")),(X_shape,X_shape))[:,:,0]
im_array.append(im)
mask_array.append(mask)
return im_array,mask_array
#设置图片大小,加载训练集和测试集
dim = 512
X_train,y_train = getData(dim,flag="train")
X_test, y_test = getData(dim)
#将训练集和测试集的图片进行预处理,然后进行数据合并
X_train = np.array(X_train).reshape(len(X_train),dim,dim,1)
y_train = np.array(y_train).reshape(len(y_train),dim,dim,1)
X_test = np.array(X_test).reshape(len(X_test),dim,dim,1)
y_test = np.array(y_test).reshape(len(y_test),dim,dim,1)
images = np.concatenate((X_train,X_test),axis=0)
mask = np.concatenate((y_train,y_test),axis=0)
#展示数据集函数
def plotMask(X,y):
sample = []
for i in range(6):
left = X[i]
right = y[i]
combined = np.hstack((left,right))
sample.append(combined)
for i in range(0,6,3):
plt.figure(figsize=(25,10))
plt.subplot(2,3,1+i)
plt.imshow(sample[i])
plt.subplot(2,3,2+i)
plt.imshow(sample[i+1])
plt.subplot(2,3,3+i)
plt.imshow(sample[i+2])
plt.show()
#训练集和测试集分别展示六张图片
print("training set")
plotMask(X_train,y_train)
print("testing set")
plotMask(X_test,y_test)
#定义损失函数
def dice_coef(y_true, y_pred):
y_truef=K.flatten(y_true)
y_predf=K.flatten(y_pred)
And=K.sum(y_truef* y_predf)
return (2* And + 1) / (K.sum(y_truef) + K.sum(y_predf) + 1)
def dice_coef_loss(y_true, y_pred):
return -dice_coef(y_true, y_pred)
#搭建U-Net模型
def unet(input_size=(256,256,1)):
inputs = tf.keras.Input(input_size)
conv1 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(inputs)
conv1 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(conv1)
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(pool1)
conv2 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(conv2)
pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same')(pool2)
conv3 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same')(conv3)
pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same')(pool3)
conv4 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same')(conv4)
pool4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv4)
conv5 = tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same')(pool4)
conv5 = tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same')(conv5)
up6 = tf.keras.layers.concatenate([tf.keras.layers.Conv2DTranspose(256, (2, 2), strides=(2, 2), padding='same')(conv5), conv4], axis=3)
conv6 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
conv6 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
up7 = tf.keras.layers.concatenate([tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv6), conv3], axis=3)
conv7 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same')(up7)
conv7 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same')(conv7)
up8 = tf.keras.layers.concatenate([tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(conv7), conv2], axis=3)
conv8 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(up8)
conv8 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(conv8)
up9 = tf.keras.layers.concatenate([tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(conv8), conv1], axis=3)
conv9 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(up9)
conv9 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(conv9)
conv10 = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(conv9)
return tf.keras.Model(inputs=[inputs], outputs=[conv10])
#创建模型保存文件夹
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
#编译模型
model = unet(input_size=(512,512,1))
model.compile(optimizer=tf.keras.optimizers.Adam(lr=2e-4), loss=dice_coef_loss,
metrics=[dice_coef, 'binary_accuracy'])
#打印模型参数
model.summary()
#设置训练参数
checkpoint = ModelCheckpoint(filepath='./save_weights/myUnet.ckpt', monitor='val_loss', verbose=1,
save_best_only=True, mode='auto', save_weights_only = True)
reduceLROnPlat = ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=3,
verbose=1, mode='auto', epsilon=0.0001, cooldown=2, min_lr=1e-6)
early = EarlyStopping(monitor="val_loss",
mode="auto",
patience=20)
callbacks_list = [checkpoint, early, reduceLROnPlat]
#将整合后的数据重新划分为训练集,验证集和测试集
train_vol, test_vol, train_seg, test_seg = train_test_split((images-127.0)/127.0,
(mask>127).astype(np.float32),
test_size = 0.1,random_state = 2020)
train_vol, validation_vol, train_seg, validation_seg = train_test_split(train_vol,train_seg,
test_size = 0.1,
random_state = 2020)
#开始训练
history = model.fit( x = train_vol,
y = train_seg,
batch_size = 16,
epochs = 50,
validation_data =(validation_vol,validation_seg),
callbacks=callbacks_list)
#保存模型
model.save_weights('./save_weights/myUnet.ckpt',save_format='tf')
# 记录训练的损失值和准确率
history_dict = history.history
train_loss = history_dict["loss"]
train_accuracy = history_dict["binary_accuracy"]
val_loss = history_dict["val_loss"]
val_accuracy = history_dict["val_binary_accuracy"]
# 绘制损失值曲线
plt.figure()
plt.plot(range(50), train_loss, label='train_loss')
plt.plot(range(50), val_loss, label='val_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
# 绘制准确率曲线
plt.figure()
plt.plot(range(50), train_accuracy, label='train_accuracy')
plt.plot(range(50), val_accuracy, label='val_accuracy')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
#抽取测试集3张图片进行预测,并进行比较
pred_candidates = np.random.randint(1,validation_vol.shape[0],10)
preds = model.predict(validation_vol)
plt.figure(figsize=(20,10))
for i in range(0,9,3):
plt.subplot(3,3,i+1)
plt.imshow(np.squeeze(validation_vol[pred_candidates[i]]))
plt.title("Base Image")
plt.xticks([])
plt.yticks([])
plt.subplot(3,3,i+2)
plt.imshow(np.squeeze(validation_seg[pred_candidates[i]]))
plt.title("Mask")
plt.xticks([])
plt.yticks([])
plt.subplot(3,3,i+3)
plt.imshow(np.squeeze(preds[pred_candidates[i]]))
plt.title("Pridiction")
plt.xticks([])
plt.yticks([])
4.运行结果
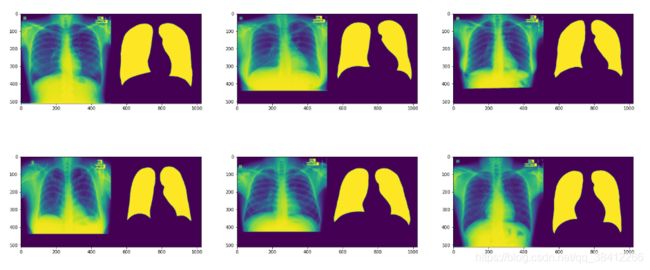
训练集图片
每幅图左半边是X光图象,右半边是经过分割后的图像
training set

测试集图片
每幅图左半边是X光图象,右半边是经过分割后的图像
testing set
U-Net模型参数
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 512, 512, 1) 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 512, 512, 32) 320 input_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 512, 512, 32) 9248 conv2d[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 256, 256, 32) 0 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 256, 256, 64) 18496 max_pooling2d[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 256, 256, 64) 36928 conv2d_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 128, 128, 64) 0 conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 128, 128, 128 73856 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 128, 128, 128 147584 conv2d_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 64, 64, 128) 0 conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 64, 64, 256) 295168 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 64, 64, 256) 590080 conv2d_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 32, 32, 256) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 32, 32, 512) 1180160 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 32, 32, 512) 2359808 conv2d_8[0][0]
__________________________________________________________________________________________________
conv2d_transpose (Conv2DTranspo (None, 64, 64, 256) 524544 conv2d_9[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 64, 64, 512) 0 conv2d_transpose[0][0]
conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 64, 64, 256) 1179904 concatenate[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 64, 64, 256) 590080 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_transpose_1 (Conv2DTrans (None, 128, 128, 128 131200 conv2d_11[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 128, 128, 256 0 conv2d_transpose_1[0][0]
conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 128, 128, 128 295040 concatenate_1[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 128, 128, 128 147584 conv2d_12[0][0]
__________________________________________________________________________________________________
conv2d_transpose_2 (Conv2DTrans (None, 256, 256, 64) 32832 conv2d_13[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 256, 256, 128 0 conv2d_transpose_2[0][0]
conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 256, 256, 64) 73792 concatenate_2[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 256, 256, 64) 36928 conv2d_14[0][0]
__________________________________________________________________________________________________
conv2d_transpose_3 (Conv2DTrans (None, 512, 512, 32) 8224 conv2d_15[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 512, 512, 64) 0 conv2d_transpose_3[0][0]
conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 512, 512, 32) 18464 concatenate_3[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 512, 512, 32) 9248 conv2d_16[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 512, 512, 1) 33 conv2d_17[0][0]
==================================================================================================
Total params: 7,759,521
Trainable params: 7,759,521
Non-trainable params: 0
__________________________________________________________________________________________________
训练过程
总共训练50轮,最后验证集的准确率达到了98.24%,没有存在过拟合现象
Epoch 00022: val_loss improved from -0.96205 to -0.96231, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 567ms/step - loss: -0.9609 - dice_coef: 0.9609 - binary_accuracy: 0.9804 - val_loss: -0.9623 - val_dice_coef: 0.9623 - val_binary_accuracy: 0.9810 - lr: 2.0000e-04
Epoch 23/50
36/36 [==============================] - ETA: 0s - loss: -0.9598 - dice_coef: 0.9597 - binary_accuracy: 0.9798
Epoch 00023: val_loss did not improve from -0.96231
36/36 [==============================] - 20s 555ms/step - loss: -0.9598 - dice_coef: 0.9597 - binary_accuracy: 0.9798 - val_loss: -0.9619 - val_dice_coef: 0.9619 - val_binary_accuracy: 0.9808 - lr: 2.0000e-04
Epoch 24/50
36/36 [==============================] - ETA: 0s - loss: -0.9613 - dice_coef: 0.9614 - binary_accuracy: 0.9806
Epoch 00024: val_loss did not improve from -0.96231
36/36 [==============================] - 20s 558ms/step - loss: -0.9613 - dice_coef: 0.9614 - binary_accuracy: 0.9806 - val_loss: -0.9592 - val_dice_coef: 0.9592 - val_binary_accuracy: 0.9796 - lr: 2.0000e-04
Epoch 25/50
36/36 [==============================] - ETA: 0s - loss: -0.9611 - dice_coef: 0.9611 - binary_accuracy: 0.9805
Epoch 00025: val_loss did not improve from -0.96231
Epoch 00025: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-05.
36/36 [==============================] - 20s 555ms/step - loss: -0.9611 - dice_coef: 0.9611 - binary_accuracy: 0.9805 - val_loss: -0.9622 - val_dice_coef: 0.9622 - val_binary_accuracy: 0.9808 - lr: 2.0000e-04
Epoch 26/50
36/36 [==============================] - ETA: 0s - loss: -0.9631 - dice_coef: 0.9633 - binary_accuracy: 0.9815
Epoch 00026: val_loss improved from -0.96231 to -0.96433, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 565ms/step - loss: -0.9631 - dice_coef: 0.9633 - binary_accuracy: 0.9815 - val_loss: -0.9643 - val_dice_coef: 0.9643 - val_binary_accuracy: 0.9820 - lr: 1.0000e-04
Epoch 27/50
36/36 [==============================] - ETA: 0s - loss: -0.9640 - dice_coef: 0.9640 - binary_accuracy: 0.9820
Epoch 00027: val_loss improved from -0.96433 to -0.96450, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 560ms/step - loss: -0.9640 - dice_coef: 0.9640 - binary_accuracy: 0.9820 - val_loss: -0.9645 - val_dice_coef: 0.9645 - val_binary_accuracy: 0.9820 - lr: 1.0000e-04
Epoch 28/50
36/36 [==============================] - ETA: 0s - loss: -0.9646 - dice_coef: 0.9646 - binary_accuracy: 0.9823
Epoch 00028: val_loss did not improve from -0.96450
36/36 [==============================] - 20s 555ms/step - loss: -0.9646 - dice_coef: 0.9646 - binary_accuracy: 0.9823 - val_loss: -0.9644 - val_dice_coef: 0.9644 - val_binary_accuracy: 0.9820 - lr: 1.0000e-04
Epoch 29/50
36/36 [==============================] - ETA: 0s - loss: -0.9646 - dice_coef: 0.9646 - binary_accuracy: 0.9823
Epoch 00029: val_loss did not improve from -0.96450
36/36 [==============================] - 20s 557ms/step - loss: -0.9646 - dice_coef: 0.9646 - binary_accuracy: 0.9823 - val_loss: -0.9640 - val_dice_coef: 0.9640 - val_binary_accuracy: 0.9819 - lr: 1.0000e-04
Epoch 30/50
36/36 [==============================] - ETA: 0s - loss: -0.9648 - dice_coef: 0.9649 - binary_accuracy: 0.9824
Epoch 00030: val_loss improved from -0.96450 to -0.96455, saving model to ./save_weights/myUnet.ckpt
Epoch 00030: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
36/36 [==============================] - 20s 564ms/step - loss: -0.9648 - dice_coef: 0.9649 - binary_accuracy: 0.9824 - val_loss: -0.9645 - val_dice_coef: 0.9645 - val_binary_accuracy: 0.9821 - lr: 1.0000e-04
Epoch 31/50
36/36 [==============================] - ETA: 0s - loss: -0.9653 - dice_coef: 0.9653 - binary_accuracy: 0.9827
Epoch 00031: val_loss improved from -0.96455 to -0.96466, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 564ms/step - loss: -0.9653 - dice_coef: 0.9653 - binary_accuracy: 0.9827 - val_loss: -0.9647 - val_dice_coef: 0.9647 - val_binary_accuracy: 0.9820 - lr: 5.0000e-05
Epoch 32/50
36/36 [==============================] - ETA: 0s - loss: -0.9658 - dice_coef: 0.9656 - binary_accuracy: 0.9828
Epoch 00032: val_loss improved from -0.96466 to -0.96512, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 563ms/step - loss: -0.9658 - dice_coef: 0.9656 - binary_accuracy: 0.9828 - val_loss: -0.9651 - val_dice_coef: 0.9651 - val_binary_accuracy: 0.9824 - lr: 5.0000e-05
Epoch 33/50
36/36 [==============================] - ETA: 0s - loss: -0.9661 - dice_coef: 0.9660 - binary_accuracy: 0.9830
Epoch 00033: val_loss improved from -0.96512 to -0.96539, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 567ms/step - loss: -0.9661 - dice_coef: 0.9660 - binary_accuracy: 0.9830 - val_loss: -0.9654 - val_dice_coef: 0.9654 - val_binary_accuracy: 0.9824 - lr: 5.0000e-05
Epoch 34/50
36/36 [==============================] - ETA: 0s - loss: -0.9662 - dice_coef: 0.9662 - binary_accuracy: 0.9830
Epoch 00034: val_loss did not improve from -0.96539
36/36 [==============================] - 20s 556ms/step - loss: -0.9662 - dice_coef: 0.9662 - binary_accuracy: 0.9830 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9825 - lr: 5.0000e-05
Epoch 35/50
36/36 [==============================] - ETA: 0s - loss: -0.9665 - dice_coef: 0.9665 - binary_accuracy: 0.9832
Epoch 00035: val_loss improved from -0.96539 to -0.96545, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 561ms/step - loss: -0.9665 - dice_coef: 0.9665 - binary_accuracy: 0.9832 - val_loss: -0.9654 - val_dice_coef: 0.9654 - val_binary_accuracy: 0.9825 - lr: 5.0000e-05
Epoch 36/50
36/36 [==============================] - ETA: 0s - loss: -0.9667 - dice_coef: 0.9666 - binary_accuracy: 0.9832
Epoch 00036: val_loss did not improve from -0.96545
Epoch 00036: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05.
36/36 [==============================] - 20s 557ms/step - loss: -0.9667 - dice_coef: 0.9666 - binary_accuracy: 0.9832 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9825 - lr: 5.0000e-05
Epoch 37/50
36/36 [==============================] - ETA: 0s - loss: -0.9670 - dice_coef: 0.9671 - binary_accuracy: 0.9834
Epoch 00037: val_loss did not improve from -0.96545
36/36 [==============================] - 20s 557ms/step - loss: -0.9670 - dice_coef: 0.9671 - binary_accuracy: 0.9834 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9824 - lr: 2.5000e-05
Epoch 38/50
36/36 [==============================] - ETA: 0s - loss: -0.9671 - dice_coef: 0.9671 - binary_accuracy: 0.9835
Epoch 00038: val_loss improved from -0.96545 to -0.96552, saving model to ./save_weights/myUnet.ckpt
36/36 [==============================] - 20s 564ms/step - loss: -0.9671 - dice_coef: 0.9671 - binary_accuracy: 0.9835 - val_loss: -0.9655 - val_dice_coef: 0.9655 - val_binary_accuracy: 0.9825 - lr: 2.5000e-05
Epoch 39/50
36/36 [==============================] - ETA: 0s - loss: -0.9673 - dice_coef: 0.9673 - binary_accuracy: 0.9836
Epoch 00039: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 556ms/step - loss: -0.9673 - dice_coef: 0.9673 - binary_accuracy: 0.9836 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9824 - lr: 2.5000e-05
Epoch 40/50
36/36 [==============================] - ETA: 0s - loss: -0.9674 - dice_coef: 0.9672 - binary_accuracy: 0.9836
Epoch 00040: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 557ms/step - loss: -0.9674 - dice_coef: 0.9672 - binary_accuracy: 0.9836 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9824 - lr: 2.5000e-05
Epoch 41/50
36/36 [==============================] - ETA: 0s - loss: -0.9675 - dice_coef: 0.9676 - binary_accuracy: 0.9837
Epoch 00041: val_loss did not improve from -0.96552
Epoch 00041: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05.
36/36 [==============================] - 20s 556ms/step - loss: -0.9675 - dice_coef: 0.9676 - binary_accuracy: 0.9837 - val_loss: -0.9654 - val_dice_coef: 0.9654 - val_binary_accuracy: 0.9825 - lr: 2.5000e-05
Epoch 42/50
36/36 [==============================] - ETA: 0s - loss: -0.9678 - dice_coef: 0.9678 - binary_accuracy: 0.9838
Epoch 00042: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 556ms/step - loss: -0.9678 - dice_coef: 0.9678 - binary_accuracy: 0.9838 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9825 - lr: 1.2500e-05
Epoch 43/50
36/36 [==============================] - ETA: 0s - loss: -0.9677 - dice_coef: 0.9678 - binary_accuracy: 0.9838
Epoch 00043: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 558ms/step - loss: -0.9677 - dice_coef: 0.9678 - binary_accuracy: 0.9838 - val_loss: -0.9651 - val_dice_coef: 0.9651 - val_binary_accuracy: 0.9824 - lr: 1.2500e-05
Epoch 44/50
36/36 [==============================] - ETA: 0s - loss: -0.9679 - dice_coef: 0.9679 - binary_accuracy: 0.9839
Epoch 00044: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 558ms/step - loss: -0.9679 - dice_coef: 0.9679 - binary_accuracy: 0.9839 - val_loss: -0.9654 - val_dice_coef: 0.9654 - val_binary_accuracy: 0.9825 - lr: 1.2500e-05
Epoch 45/50
36/36 [==============================] - ETA: 0s - loss: -0.9680 - dice_coef: 0.9681 - binary_accuracy: 0.9839
Epoch 00045: val_loss did not improve from -0.96552
Epoch 00045: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-06.
36/36 [==============================] - 20s 560ms/step - loss: -0.9680 - dice_coef: 0.9681 - binary_accuracy: 0.9839 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9824 - lr: 1.2500e-05
Epoch 46/50
36/36 [==============================] - ETA: 0s - loss: -0.9682 - dice_coef: 0.9682 - binary_accuracy: 0.9840
Epoch 00046: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 557ms/step - loss: -0.9682 - dice_coef: 0.9682 - binary_accuracy: 0.9840 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9825 - lr: 6.2500e-06
Epoch 47/50
36/36 [==============================] - ETA: 0s - loss: -0.9681 - dice_coef: 0.9682 - binary_accuracy: 0.9840
Epoch 00047: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 556ms/step - loss: -0.9681 - dice_coef: 0.9682 - binary_accuracy: 0.9840 - val_loss: -0.9653 - val_dice_coef: 0.9653 - val_binary_accuracy: 0.9824 - lr: 6.2500e-06
Epoch 48/50
36/36 [==============================] - ETA: 0s - loss: -0.9681 - dice_coef: 0.9682 - binary_accuracy: 0.9840
Epoch 00048: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 557ms/step - loss: -0.9681 - dice_coef: 0.9682 - binary_accuracy: 0.9840 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9824 - lr: 6.2500e-06
Epoch 49/50
36/36 [==============================] - ETA: 0s - loss: -0.9681 - dice_coef: 0.9681 - binary_accuracy: 0.9841
Epoch 00049: val_loss did not improve from -0.96552
Epoch 00049: ReduceLROnPlateau reducing learning rate to 3.12499992105586e-06.
36/36 [==============================] - 20s 557ms/step - loss: -0.9681 - dice_coef: 0.9681 - binary_accuracy: 0.9841 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9824 - lr: 6.2500e-06
Epoch 50/50
36/36 [==============================] - ETA: 0s - loss: -0.9682 - dice_coef: 0.9683 - binary_accuracy: 0.9841
Epoch 00050: val_loss did not improve from -0.96552
36/36 [==============================] - 20s 555ms/step - loss: -0.9682 - dice_coef: 0.9683 - binary_accuracy: 0.9841 - val_loss: -0.9652 - val_dice_coef: 0.9652 - val_binary_accuracy: 0.9824 - lr: 3.1250e-06
损失值曲线
记录每个epoch的损失值
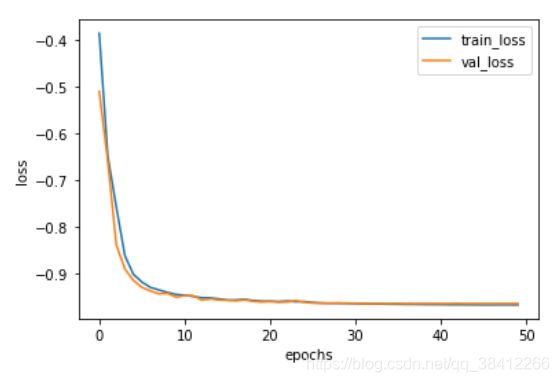
准确率曲线
记录每个epoch的准确率

测试集预测结果
左边是测试集图片,中间是测试集的原始分割图像,最右边的是预测的分割图像,可以看出预测的结果跟原始分割图像差别不大
