第2例 基于卷积神经网络LeNet的手写体数字识别
第2例 基于卷积神经网络LeNet的手写体数字识别
卷积操作就是提取图像的边缘纹理特征的。
卷积神经网络去做图像分类的思路非常简单:
- 先使用卷积运算对图像进行边缘纹理特征提取,多层卷积即是提取深度特征的边缘纹理特征;卷积核是通过机器学习得到的,所以具体提取到什么样的纹理我们不必要去考究。
- 再使用全连接(分类器)最提取到的特征进行分类。
思路: 卷积神经网络 = 提取特征(卷积层、池化) + 分类器(全连接层)
1. 卷积神经网络LeNet的结构
LeNet网络结构如下:
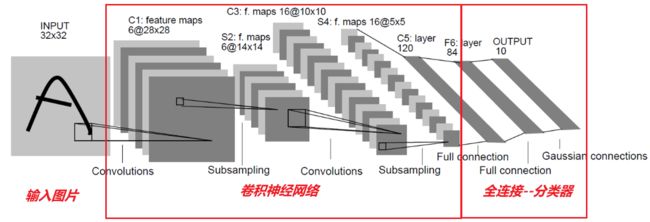
相比全连接网络做分类图像,它多了一些卷积网络的层,如卷积层、池化层。
LeNet的过程:
C1卷积层:输入是灰度图像1x32x32,输出是6x28x28,卷积核大小是5x5,卷积滑动步长Stride是1。
S2池化层:输入6x28x28,输出6x14x14,采样区域是2x2,步长是2,使用平均池化;池化后通过sigmoid。
C3卷积层:输入6x14x14,输出16x10x10,卷积核使用5x5,步长1;
S4池化层:使用最大池化进行下采样,输入16x10x10,输出16x5x5,采样区域是2x2,步长是2;
C5卷积层:卷积层替换全连接层,输入16x5x5,卷积核还是5x5,输出120x1x1;
F6全连接层:输入120,输出84;
输出层:也是全连接层,输入84,输出10;
最后:经过softmax层,输入84,输出10数据(表示0-9十个数据的概率)。
2. 代码实现
2.1 网络搭建
LeNet的网络结构代码实现如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class LeNet(keras.Model):
def __init__(self, num_classes=10):
""" 搭建网络的层 """
super(LeNet, self).__init__()
self.c1 = layers.Conv2D(6, (5,5), strides=1, padding="same")
self.s2 = layers.AveragePooling2D(pool_size=(2, 2), strides=2, padding='same')
self.a1 = layers.Activation('sigmoid')
self.c3 = layers.Conv2D(16, (5,5), strides=1, padding="same")
self.s4 = layers.AveragePooling2D(pool_size=(2, 2), strides=2, padding='same')
self.c5 = layers.Conv2D(120, (5,5), strides=1, padding="same")
self.flatten1 = layers.Flatten()
self.f6 = layers.Dense(84, activation="sigmoid", use_bias=True)
self.out = layers.Dense(10, activation="sigmoid", use_bias=True) # 输出层
self.softmax = layers.Softmax() # 定义softmax层
def call(self, x):
x = self.c1(x)
x = self.a1(self.s2(x))
x = self.c3(x)
x = self.s4(x)
x = self.flatten1(self.c5(x))
x = self.f6(x)
x = self.out(x)
x = self.softmax(x)
return x
2.2 数据集MNIST读取
这里读取MNIST的压缩包数据,即解压并读取到内存。
import struct
import os
import numpy as np
import gzip
def load_images(filename):
"""load images
filename: the name of the file containing data
return -- a matrix containing images as row vectors
"""
g_file = gzip.GzipFile(filename)
data = g_file.read()
magic, num, rows, columns = struct.unpack('>iiii', data[:16])
dimension = rows*columns
X = np.zeros((num,rows,columns), dtype='uint8')
offset = 16
for i in range(num):
a = np.frombuffer(data, dtype=np.uint8, count=dimension, offset=offset)
X[i] = a.reshape((rows, columns))
offset += dimension
return X
def load_labels(filename):
"""load labels
filename: the name of the file containing data
return -- a row vector containing labels
"""
g_file = gzip.GzipFile(filename)
data = g_file.read()
magic, num = struct.unpack('>ii', data[:8])
d = np.frombuffer(data,dtype=np.uint8, count=num, offset=8)
return d
def load_data(foldername):
"""加载MINST数据集
foldername: the name of the folder containing datasets
return -- train_X训练数据集, train_y训练数据集对应的标签,
test_X测试数据集, test_y测试数据集对应的标签
"""
# filenames of datasets
train_X_name = "train-images-idx3-ubyte.gz"
train_y_name = "train-labels-idx1-ubyte.gz"
test_X_name = "t10k-images-idx3-ubyte.gz"
test_y_name = "t10k-labels-idx1-ubyte.gz"
train_X = load_images(os.path.join(foldername, train_X_name))
train_y = load_labels(os.path.join(foldername,train_y_name))
test_X = load_images(os.path.join(foldername, test_X_name))
test_y = load_labels(os.path.join(foldername, test_y_name))
return train_X, train_y, test_X, test_y
2.3 数据预处理
调用tensorflow2.x的数据集管理接口,在process_image函数中,我把:
- 数据维度转成HWC(tensorflow框架默认格式);
- 图像的数据用Numpy读取是int8,要转成float32才能送入网络。
- 标签转换网络onehot格式,如类别1 --> [0 1 0 0 0 0 0 0 0 0]。
def process_image(image, label):
""" 图片预处理 """
image = tf.expand_dims(image, axis=2) # 扩充一个维度,变成HWC
image = tf.cast(image, dtype=tf.float32) # 数据类型转换为float32
label = tf.one_hot(label, depth=10) # 标签转成onehot格式
return image, label
def get_dataset(X, Y, is_shuffle=False, batch_size=64):
ds = tf.data.Dataset.from_tensor_slices((X, Y))
ds = ds.map(process_image)
ds = ds.shuffle(buffer_size=1024)
ds = ds.batch(batch_size)
return ds
2.4 训练模型代码
import os
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import layers,losses, metrics
from data_manager import load_data
from network.lenet import LeNet
class TrainModel():
def __init__(self, lr=0.1):
self.model = LeNet(num_classes=10) # 定义网络
self.model.build(input_shape=(None, 28, 28, 1)) # BHWC
self.model.summary()
self.loss_fun = losses.CategoricalCrossentropy() # 定义损失函数, 这里交叉熵
self.opt = tf.optimizers.SGD(learning_rate=lr) # 随机梯度下降优化器
self.train_acc_metric = metrics.CategoricalAccuracy() # 设定统计参数
self.val_acc_metric = metrics.CategoricalAccuracy()
def train(self, fpath="./data/MNIST", epochs=200, m=50):
""" 训练网络 """
batch_size = 64
test_acc_list = []
# 读取数据集
train_X, train_y, test_X, test_y = load_data(fpath)
train_dataset = get_dataset(train_X, train_y, is_shuffle=True, batch_size=batch_size)
val_dataset = get_dataset(test_X, test_y, is_shuffle=False, batch_size=batch_size)
# 训练
loss_val = 0
for epoch in range(epochs):
print(" ** Start of epoch {} **".format(epoch))
# 每次获取一个batch的数据来训练
for nbatch, (inputs, labels) in enumerate(train_dataset):
with tf.GradientTape() as tape: # 开启自动求导
y_pred = self.model(inputs) # 前向计算
loss_val = self.loss_fun(labels, y_pred) # 误差计算
grads = tape.gradient(loss_val, self.model.trainable_variables) # 梯度计算
self.opt.apply_gradients(zip(grads, self.model.trainable_variables)) # 权重更新
self.train_acc_metric(labels, y_pred) # 更新统计传输
if nbatch % m == 0: # 打印
correct = tf.equal(tf.argmax(labels, 1), tf.argmax(y_pred, 1))
acc = tf.reduce_mean(tf.cast(correct, tf.float32))
print('{}-{} train_loss:{:.5f}, train_acc:{:.5f}'.format(epoch, nbatch, float(loss_val), acc))
# 输出统计参数的值
train_acc = self.train_acc_metric.result()
self.train_acc_metric.reset_states()
print('Training acc over epoch: {}, acc:{:.5f}'.format(epoch, float(train_acc)))
# 每次迭代在验证集上测试一次
for nbatch, (inputs, labels) in enumerate(val_dataset):
y_pred = self.model(inputs)
self.val_acc_metric(labels, y_pred)
val_acc = self.val_acc_metric.result()
self.val_acc_metric.reset_states()
print('Valid acc over epoch: {}, acc:{:.5f}'.format(epoch, float(val_acc)))
test_acc_list.append(val_acc)
# 训练完成保存模型
tf.saved_model.save(self.model, "./output/mnist_model")
# 画泛化能力曲线(横坐标是epoch, 测试集上的精度),并保存
x = np.arange(1, len(test_acc_list)+1, 1)
y = np.array(test_acc_list)
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("val_acc")
plt.title('model acc in valid dataset')
plt.savefig("./output/val_acc.png", format='png')
2.5 执行训练
if __name__ == "__main__":
path = "./output"
if not os.path.exists(path):
os.makedirs(path)
model = TrainModel()
model.train()
2.6 结果
-
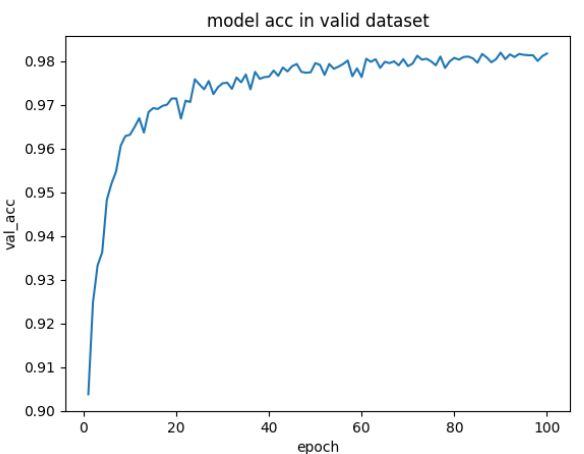
卷积神经网络相对全连接,训练精度收敛很快,在第5个epoch的时候就达到0.95;
(全连接网络训练到140个批次才收敛到0.95,而且是最高精度)

-
最后结果:
我训练了100次迭代,在训练精度0.98,验证集0.98

epoch-valid_acc曲线图:
要是对大家有所帮助,不要忘记点赞、关注、收藏哦~~~~~