单阶段目标检测算法之YOLOv1详解
官方网站C语言版本:https://pjreddie.com/darknet/yolov1/
tensorflow版本的代码下载: https://github.com/hizhangp/yolo_tensorflow
论文: http://arxiv.org/abs/1506.02640
目录
一、YOLO介绍
二、YOLOv1的结构
三、YOLOV1原理
(一)基本核心思想
(二)网络结构
(三)输出7x7的理解
(四)输出维度30的理解
(五)一次预测98个框
(六)对98个预测框处理
(七)回归坐标xywh
(八)训练样本标签
四、总结
一、YOLO介绍
YOLO的全称叫做“You Only Look Once”,简单来说,YOLO可以做到将一张图片输入,直接输出最终结果,包括框和框内物体的名称及score(得分)。
相比RCNN系列的算法(提取候选框+分类回归),YOLO仅仅一个网络就能完成检测框和分类任务,所以说它是单阶段目标检测算法;
YOLO主要特点是:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。
二、YOLOv1的结构
YOLO V1是单阶段one stage体系开创者,一次卷积可得结果。
如下:

YOLOv1是端到端进行训练,因此YOLOv1只有一条单一的网络分支。
步骤:
- 输入图像(固定大小到448x448)到卷积神经网络,得到特征图;
- 经过全连接网络,然后分类和回归;输出包含分类信息、置信度、坐标等信息;
- 使用NMS方法筛选获得结果。
三、YOLOV1原理
(一)基本核心思想
如下图:
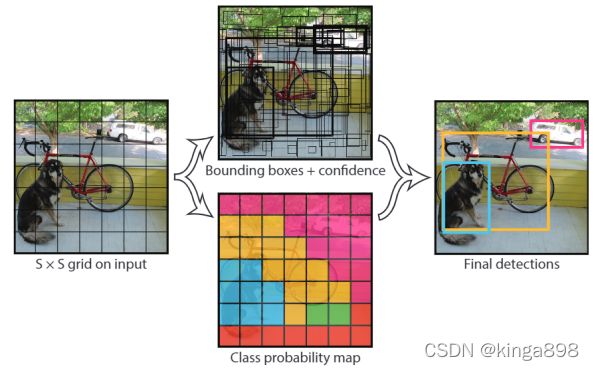
- 首先将原图像分成S x S grid;在论文里S=7,即将图像分为7 x 7 grid;
- 每个grid cell都会预测B个Bounding Box 去进行物体的框定和分类;在论文里B=2,那么一图像预测7x7x2=98个预测框;
- 每个预测框包含有4个边框的值和1个的置信度,如:(x,y,w,h,confidence);
- 预测出来相同物体有重复的边框,利用NMS (非极大值抑制) 算法得到最后的final detections。
(二)网络结构
如下图:

输入图像为448x448,输出特征图大小为7x7x30;
(三)输出7x7的理解
特征图7x7映射至原图,即图像被分成7×7个网格(grid cell);映射关系如下图:

如果GT物体的中心落在某个网格中,则这个网格就负责预测这个物体;
(四)输出维度30的理解
(1)每个网格使用B(B=2)个Bbox进行回归预测,共产生5个值;
A.置信度confidence,包含物体的可能性大小;
B.回归坐标(x,y,w,h);
(2)每个网格还要预测C个类别概率,以判断当前cell属于哪个类别C;因此1个网格的输出维度是(5×B+C),S×S个网格就输出就是S × S×(5×B+C)。

论文:B=2,VOC有20个类别,那么网络输出维度就是5x2+20=30。
(五)一次预测98个框
如下图:

(1)图像被划分成7×7,可知产生的特征图大小为7×7,因此S=7;
(2)真实的人物体中心落在黄色网格,使用黄色网格预测分类人;黄色网格产生了2个蓝色的Bbox用来回归预测,因此B=2;
(3)每个Bbox的检测结果会包含有关人的置信度和回归坐标信息;
(4)黄色网格会使用softmax进行分类预测,如果使用VOC数据集C=20。
最终,根据公式可得输出维度5×B+C=30,即输出特征图7×7×30;预测框的个数7×7×2=98。
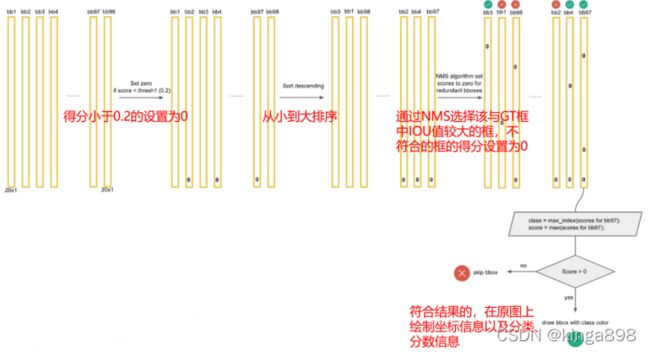
(六)对98个预测框处理
使用NMS算法对预测框进行处理,最后保留最优的预测框:
(七)回归坐标xywh
如下图:
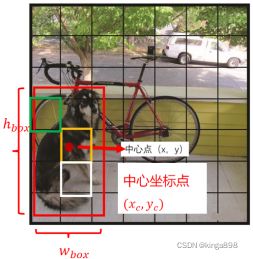
实际Bbox框的预测结果包含(xc, yc ,wbox,ℎbox):
- xc是预测框的中心点相对于原图的横坐标;
- yc是预测框的中心点相对于原图的纵坐标;
- wbox是预测框的宽度;
- ℎbox是预测框的高度。
回归坐标的目的是将坐标映射到0-1之间,方便计算损失;有如下要求
- x,y是相对于当前网格的偏移值,范围是0~1;
- w,h是归一化(分别除以图像的W和H)的结果,范围是0~1;
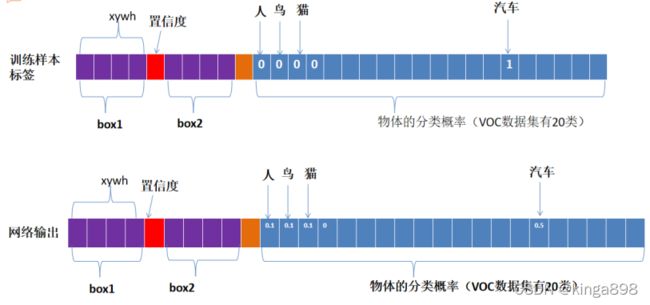
(八)训练样本标签
训练样本的标签理解:
四、总结
Yolov1是单目标检测的开创者,相比较RCNN等两阶段系列,预测速度上有天然的优势,就是检测速度快。但是也存在许多缺点:
- YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。