Mysql核心知识篇
写在前面
这是Mysql备核心知识篇,涉及知识包括,Mysql基础知识 ,sql优化,幻读,脏读,主从复制等,包含了多数的Mysql核心知识点,可用于八股文复习宝典,也可用于加深知识,建议大家以闯关的模式进行阅读,然后根据内容查漏补缺,欢迎提问相互学习交流。
之前已经完成了
- 新版javase必备核心知识篇,点击即可学习
- 并发编程必备核心知识篇,点击即可学习
- 中间件之消息队列篇,点击即可学习
后续还将更新:
- http协议核心知识点
- Spring-Mybatis核心知识点
- 分布式缓存核心知识点
Mysql核心知识篇概览
Mysql事务的四大特性
脏读、不可重复读、幻读
常见的隔离级别由低到高有哪几种
Mysql常见的存储引擎
Mysql的存储引擎InnoDB和MyISAM区别和选择问题
普通索引和唯一索引的区别
创建索引的时候主要考虑啥,使用索引的优缺点有哪些,使用应该注意些什么
select、where、from、group by、having、order by的执行顺序
数据库的时候相似类型的字段区分
千万级Mysql数据表分页查询优化思路
线上的数据库,你会做哪些监控
Mysql常见日志
数据库主从异步复制原理及流程图
数据库主从复制的好处
主从同步延迟问题,怎么解决
什么场景下会出现主从数据不⼀致
mysql间隙锁
Mysql事务的四大特性
-
原子性Atomicity:
⼀个事务必须被事务不可分割的最小⼯作单元,整个操作要么全部成功,要么全部失败,⼀般就是通过commit和rollback来控制 -
⼀致性Consistency:
数据库总能从⼀个⼀致性的状态转换到另⼀个⼀致性的状态,比如转账,只要转账方成功,收账方的钱也一定会增加相应的金额数,只要有任何一方发生异常就不会成功提交事务 -
隔离性Isolation:
⼀个事务相对于另⼀个事务是隔离的,⼀个事务所做的修改是在最终提交以前,对其他事务是不可见的的 -
持久性Durability:
⼀旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失‘
脏读、不可重复读、幻读
- 脏读: 事务中的修改即使没有提交,其他事务也能看见,事务可以读到未提交的数据称为脏读
- 不可重复读: 同个事务前后多次读取,不能读到相同的数据内容,中间另⼀个事务也操作了该同⼀数据
- 幻读:当某个事务在读取某个范围内的记录时,另外⼀个事务又在该范围内插⼊了新的记录,当之前的事务再次读取该范围的记录时,发现两次不⼀样,产生幻读
- 小结
幻读和不可重复读的区别是:前者是⼀个范围,后者是本身,从总的结果来看, 两者都表现为两次读取的结果不⼀致
常见的隔离级别由低到高有哪几种
事务的隔离级别越高,事务越安全,但是并发能力越差。
-
Read Uncommitted(未提交读,读取未提交内容)
事务中的修改即使没有提交,其他事务也能看见,事务可以读到为提交的数据称为脏读 也存在不可重复读、幻读问题 -
Read Committed(提交读,读取提交内容)
⼀个事务开始后只能看见已经提交的事务所做的修改,在事务中执性两次同样的查询可能得到不⼀样的结果,也叫做不可重复读(前后多次读取,不能读到相同的数据内容),也存幻读问题 -
Repeatable Read(可重复读,mysql默认的事务隔离级别)
解决脏读、不可重复读的问题,存在幻读的问题,使⽤ MMVC机制 实现可重复读
幻读问题:MySQL的InnoDB引擎通过MVCC自动帮我们解决,即多版本并发控制
Serializable(可串行化)
解决脏读、不可重复读、幻读,可保证事务安全,但强制所有事务串行执行,所以并发效率低
Mysql常见的存储引擎
常见的有多类,InnoDB、MyISAM、MEMORY、MERGE、ARCHIVE、CSV等
⼀般比较常用的有InnoDB、MyISAM
MySQL 5.5以上的版本默认是InnoDB,5.5之前默认存储引擎是MyISAM
Mysql的存储引擎InnoDB和MyISAM区别和选择问题
可参考这篇博文,点击即可查看
普通索引和唯一索引的区别
可参考这篇博文,点击即可查看
创建索引的时候主要考虑啥,使用索引的优缺点有哪些,使用应该注意些什么
考虑点:结合实际的业务场景,在哪些字段上创建索引,创建什么类型的索引
索引好处:
快速定位到表的位置,减少服务器扫描的数据
有些索引存储了实际的值,特定情况下只要使用索引就能完成查询
索引缺点:
索引会浪费磁盘空间,不要创建非必要的索引
插⼊、更新、删除需要维护索引,带来额外的开销
索引过多,修改表的时候重构索引性能差
索引优化实践
尽量使用数据量少的索引,索引值过长查询速度会受到影响
选择合适的索引列顺序
内容变动少,且查询频繁,可以建立多几个索引
内容变动频繁,谨慎创建索引
根据业务创建适合的索引类型,比如某个字段常用来做查询条件,则为这个字段建立索引提高查询速度
组合索引选择业务查询最相关的字段
我对SQL优化的理解
可参考这篇博文
** select、where、from、group by、having、order by的执行顺序**
重点知道[重点]的三个
- from 从哪个表查询
- where 初步过滤条件
- group by 过滤后进⾏分组[重点]
- having 对分组后的数据进⾏⼆次过滤[重点]
- select 查看哪些结果字段
- order by 按照怎样的顺序进⾏排序返回[重点]
数据库的时候相似类型的字段区分
可参考这篇博文,点击即可查看
千万级Mysql数据表分页查询优化思路
可参考这篇博文,点击即可查看
线上的数据库,你会做哪些监控
业务性能
- 应用上线前会审查业务新增的sql,和分析sql执⾏计划,比如是否存在 select * ,索引建立是否合理
- 开启慢查询日志,定期分析慢查询日志
- 监控CPU/内存利用率,读写、网关IO、流量带宽 随着时间的变化统计图
- 吞吐量QPS/TPS,⼀天内读写随着时间的变化统计图
数据安全 - 短期增量备份,比如⼀周⼀次。 定期全量备份,比如⼀月⼀次
- 检查是否有非授权用户,是否存在弱⼝令,网络防火墙检查
- 导出数据是否进行脱敏,防⽌数据泄露或者黑产利用
- 数据库 全量操作⽇志审计,防止数据泄
- 高可用 主从架构,多机房部署
Mysql常见日志
-
redo 重做日志
作用:确保事务的持久性,防止在发生故障,脏页(缓存中数据与磁盘中不相同的页)未写入磁盘。重启数据库会进行redo log执行重做,到达事务⼀致性 -
undo 回滚日志
作用:保证数据的原子性,记录事务发生之前的数据的⼀个版本,用于回滚。 innodb事务的可重复读和读取已提交 隔离级别就是通过mvcc+undo实现 -
errorlog 错误⽇志
作⽤:Mysql本身启动、停止、运行期间发生的错误信息 -
slow query log 慢查询日志
作用:记录执⾏时间过长的sql,时间阈值可以配置,只记录执行成功 -
binlog ⼆进制⽇志
作用:用于主从复制,实现主从同步 -
relay log 中继⽇志
作用:用于数据库主从同步,将主库发送来的binlog先保存在本地,然后从库进行回放 -
general log 普通日志
作用:记录数据库操作明细,默认关闭,开启会降低数据库性能
数据库主从异步复制原理及流程图
流程图如下:
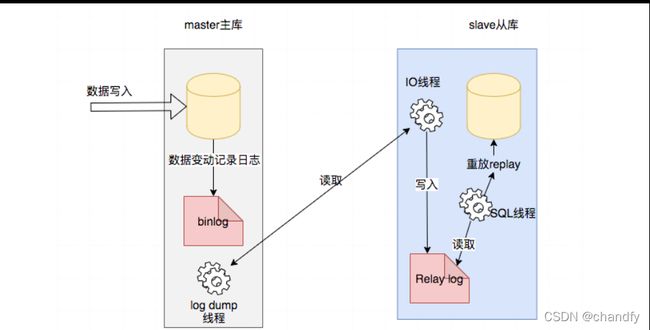 流程概述:
流程概述:
- 主库生成一个log dump 线程,主动与从库IO线程交互
- IO线程请求主库binlog,写入到中继日志relay log
- SQL线程读取中继日志,解析然后写入从库
更多详细内容可以参考
mysql连环问,点击即可阅读
数据库主从复制的好处
容灾使用,用于故障切换
业务需要,进行读写分离减少主库压⼒
主从同步延迟问题,怎么解决
保证性能第⼀情况下,不能百分百解决主从同步延迟问题,只能增加缓解措施。
现象:主从同步,大数据量场景下,会发现写入主库的数据,在从库没找到。
原因:
- 主从复制是单线程操作,当主库TPS高,产生的超过从库sql线程执⾏能⼒
- 从库执行了大的sql操作,阻塞等待
- 服务器硬件问题,如磁盘,CPU,还有网络延迟等
解决办法:
-
业务需要有⼀定的容忍度,程序和数据库直接增加缓存,降低读压力
-
业务适合的话,写⼊主库后,再写缓存,读的时候可以读缓存,没命中再读从库
-
读写分离,⼀主多从,分散主库和从库压力
-
提⾼硬件配置,比如使用SSD固态硬盘、更好的CPU和网络
-
进行分库分表,减少单机压力
什么场景下会出现主从数据不⼀致
- 本身复制延迟导致
- 主库宕机或者从库宕机都会导致复制中断
- 把⼀个从库提升为主库,可能导致从库和主库的数据不⼀致性
主从⼀致性校验,怎么做?
Mysql主从复制是基于binlog复制,难免出现复制数据不⼀致的风险,引起⽤户数据访问前后不⼀致的风险
所以要定期开展主从复制数据⼀致性的校验并修复,避免这些问题
解决方案之⼀,使用Percona公司下的⼯具
pt-table-checksum⼯具进⾏⼀致性校验
原理:
主库利用表中的索引,将表的数据切割成⼀个个chunk(块),然后进行计算得到checksum值。
从库也执相应的操作,并在从库上计算相同数据块的checksum,然后对⽐主从中各个表的checksum是否⼀致并存储到数据库,最后通过存储校验结果的表就可以判断出哪些表的数据不⼀致
pt-table-sync(在从库执行)⼯具
进行修复不⼀致数据,可以修复主从结构数据的不⼀致,也可以修复非
主从结构数据表的数据不⼀致
原理:在主库上执行数据的更改,再同步到从库上,不会直接更改成从的数据。在主库上执行更改是基于主库现在的数据,也不会更改主库上的数据,可以同步某些表或整个库的数据,但它不同步表结构、索引,只同步不⼀致的数据
注意:
默认主库要检查的表在从库都存在,并且同主库表有相同的表结构
如果表中没有索引,pt-table-checksum将没法处理,⼀般要求最基本都要有主键索引
pt-table-sync⼯具会修改数据,使用前最好备份下数据,防止误操作
拓展
pt-table-checksum怎么保证某个chunk的时候checksum数据⼀致性?
当pt⼯具在计算主库上某chunk的checksum时,主库可能在更新且从库可能复制延迟,那该怎么保证主库与从库计算的是”同⼀份”数据,答案把要checksum的⾏加上for update锁并计算,这保证了主库的某个chunk内部数据的⼀致性
mysql间隙锁
mysql间隙锁,点击即可阅读