AI基础:深度强化学习之路
本文来源:深度强化学习实验室
作者:侯宇清,陈玉荣
导语
深度强化学习是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了端到端学习。深度强化学习的出现使得强化学习技术真正走向实用,得以解决现实场景中的复杂问题。从2013年DQN(深度Q网络,deep Q network)出现到目前为止,深度强化学习领域出现了大量的算法,以及解决实际应用问题的论文,本文将阐述深度强化学习的发展现状,并对未来进行展望。
我正在编写AI基础系列,目前已经发布:
AI 基础:简易数学入门
AI 基础:Python开发环境设置和小技巧
AI 基础:Python 简易入门
AI 基础:正则表达式
AI 基础:Numpy 简易入门
AI 基础:Pandas 简易入门
AI 基础:Scipy(科学计算库) 简易入门
AI基础:数据可视化简易入门(matplotlib和seaborn)
AI基础:机器学习库Scikit-learn的使用
AI基础:机器学习简易入门
AI基础:机器学习的损失函数
AI基础:机器学习和深度学习的练习数据
AI基础:特征工程-类别特征
AI基础:特征工程-数字特征处理
AI基础:自然语言处理基础之序列模型
AI基础:特征工程-文本特征处理
AI基础:词嵌入基础和Word2Vec
AI基础:图解Transformer
AI基础:一文看懂BERT
AI基础:入门人工智能必看的论文
AI基础:走进深度学习
AI基础:优化算法
AI基础:卷积神经网络
AI基础:经典卷积神经网络
AI基础:深度学习论文阅读路线(127篇经典论文下载)
AI基础:数据增强方法综述
AI基础:论文写作工具
后续持续更新
正文开始
|| 一、深度强化学习的泡沫
2015 年,DeepMind 的 Volodymyr Mnih 等研究员在《自然》杂志上发表论文 Human-level control through deep reinforcement learning[1],该论文提出了一个结合深度学习(DL)技术和强化学习(RL)思想的模型 Deep Q-Network(DQN),在 Atari 游戏平台上展示出超越人类水平的表现。自此以后,结合 DL 与 RL 的深度强化学习(Deep Reinforcement Learning, DRL)迅速成为人工智能界的焦点。
过去三年间,DRL 算法在不同领域大显神通:在视频游戏 [1]、棋类游戏上打败人类顶尖高手 [2,3];控制复杂的机械进行操作 [4];调配网络资源 [5];为数据中心大幅节能 [6];甚至对机器学习算法自动调参 [7]。各大高校和企业纷纷参与其中,提出了眼花缭乱的 DRL 算法和应用。可以说,过去三年是 DRL 的爆红期。DeepMind 负责 AlphaGo 项目的研究员 David Silver 喊出“AI = RL + DL”,认为结合了 DL 的表示能力与 RL 的推理能力的 DRL 将会是人工智能的终极答案。

1.1 DRL 的可复现性危机
然而,研究人员在最近半年开始了对 DRL 的反思。由于发表的文献中往往不提供重要参数设置和工程解决方案的细节,很多算法都难以复现。2017 年 9 月,著名 RL 专家 Doina Precup 和 Joelle Pineau 所领导的的研究组发表了论文 Deep Reinforcement Learning that Matters[8],直指当前 DRL 领域论文数量多却水分大、实验难以复现等问题。该文在学术界和工业界引发热烈反响。很多人对此表示认同,并对 DRL 的实际能力产生强烈怀疑。
其实,这并非 Precup& Pineau 研究组第一次对 DRL 发难。早在 2 个月前,该研究组就通过充足的实验对造成 DRL 算法难以复现的多个要素加以研究,并将研究成果撰写成文 Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control[9]。同年 8 月,他们在 ICML 2017 上作了题为“Reproducibility of Policy Gradient Methods for Continuous Control”的报告 [10],通过实例详细展示了在复现多个基于策略梯度的算法的过程中,由于种种不确定性因素导致的复现困难。12 月,在万众瞩目的 NIPS 2017 DRL 专题研讨会上,Joelle Pineau 受邀作了题为“Reproducibility of DRL and Beyond”的报告 [11]。报告中,Pineau 先介绍了当前科研领域的“可复现性危机” :在《自然》杂志的一项调查中,90% 的被访者认为“可复现性”问题是科研领域存在的危机,其中,52% 的被访者认为这个问题很严重。在另一项调查中,不同领域的研究者几乎都有很高的比例无法复现他人甚至自己过去的实验。可见“可复现性危机”有多么严峻!Pineau 针对机器学习领域发起的一项调研显示,同样有 90% 的研究者认识到了这个危机。

机器学习领域存在严重的“可复现性危机”[11]
随后,针对 DRL 领域,Pineau 展示了该研究组对当前不同 DRL 算法的大量可复现性实验。实验结果表明,不同 DRL 算法在不同任务、不同超参数、不同随机种子下的效果大相径庭。在报告后半段,Pineau 呼吁学界关注“可复现性危机”这一问题,并根据她的调研结果,提出了 12 条检验算法“可复现性”的准则,宣布计划在 ICLR 2018 开始举办“可复现实验挑战赛”(“可复现危机”在其他机器学习领域也受到了关注,ICML 2017 已经举办了 Reproducibility in Machine Learning Workshop,并将在今年继续举办第二届),旨在鼓励研究者做出真正扎实的工作,抑制机器学习领域的泡沫。Pineau & Precup 研究组的这一系列研究获得了广泛关注。

Pineau 基于大量调查提出的检验算法“可复现性”准则 [11]
1.2 DRL 研究存在多少坑?
同样在 12 月,Reddit 论坛上也开展了关于机器学习不正之风的热烈讨论 [12]。有人点名指出,某些 DRL 代表性算法之所以在模拟器中取得了优秀却难以复现的表现,是因为作者们涉嫌在实验中修改模拟器的物理模型,却在论文中对此避而不谈。
对现有 DRL 算法的批判浪潮仍旧不断涌来。2018 年的情人节当天,曾经就读于伯克利人工智能研究实验室(Berkeley Artificial Intelligence Research Lab, BAIR)的 Alexirpan 通过一篇博文 Deep Reinforcement Learning Doesn't Work Yet[13] 给 DRL 圈送来了一份苦涩的礼物。他在文中通过多个例子,从实验角度总结了 DRL 算法存在的几大问题:
样本利用率非常低;
最终表现不够好,经常比不过基于模型的方法;
好的奖励函数难以设计;
难以平衡“探索”和“利用”, 以致算法陷入局部极小;
对环境的过拟合;
灾难性的不稳定性…
虽然作者在文章结尾试着提出 DRL 下一步应该解决的一系列问题,很多人还是把这篇文章看做 DRL 的“劝退文”。几天后,GIT 的博士生 Himanshu Sahni 发表博文 Reinforcement Learning never worked, and 'deep'>
另一位 DRL 研究者 Matthew Rahtz 则通过讲述自己试图复现一个 DRL 算法的坎坷历程来回应 Alexirpan,让大家深刻体会了复现 DRL 算法有多么难 [15]。半年前,Rahtz 出于研究兴趣,选择对 OpenAI 的论文 Deep Reinforcement Learning from Human Preferences 进行复现。在复现的过程中,几乎踩了 Alexirpan 总结的所有的坑。他认为复现 DRL 算法与其是一个工程问题,更不如说像一个数学问题。“它更像是你在解决一个谜题,没有规律可循,唯一的方法是不断尝试,直到灵感出现彻底搞明白。……很多看上去无关紧要的小细节成了唯一的线索……做好每次卡住好几周的准备。”Rahtz 在复现的过程中积累了很多宝贵的工程经验,但整个过程的难度还是让他花费了大量的金钱以及时间。他充分调动不同的计算资源,包括学校的机房资源、Google 云计算引擎和 FloydHub,总共花费高达 850 美元。可就算这样,原定于 3 个月完成的项目,最终用了 8 个月,其中大量时间用在调试上。

复现 DRL 算法的实际时间远多于预计时间 [15]
Rahtz 最终实现了复现论文的目标。他的博文除了给读者详细总结了一路走来的各种宝贵工程经验,更让大家从一个具体事例感受到了 DRL 研究实际上存在多大的泡沫、有多少的坑。有人评论到,“DRL 的成功可能不是因为其真的有效,而是因为人们花了大力气。”
很多著名学者也纷纷加入讨论。目前普遍的观点是,DRL 可能有 AI 领域最大的泡沫。机器学习专家 Jacob Andreas 发了一条意味深长的 tweet 说:

Jacob Andreas 对 DRL 的吐槽
DRL 的成功归因于它是机器学习界中唯一一种允许在测试集上训练的方法。
从 Pineau & Precup 打响第一枪到现在的 1 年多时间里,DRL 被锤得千疮百孔,从万众瞩目到被普遍看衰。就在笔者准备投稿这篇文章的时候,Pineau 又受邀在 ICLR 2018 上作了一个题为 Reproducibility, Reusability, and Robustness in DRL 的报告 [16],并且正式开始举办“可复现实验挑战赛”。看来学界对 DRL 的吐槽将会持续,负面评论还将持续发酵。那么, DRL 的问题根结在哪里?前景真的如此黯淡吗?如果不与深度学习结合,RL 的出路又在哪里?
在大家纷纷吐槽 DRL 的时候,著名的优化专家 Ben Recht,从另一个角度给出一番分析。
|| 二、免模型强化学习的本质缺陷
RL 算法可以分为基于模型的方法(Model-based)与免模型的方法(Model-free)。前者主要发展自最优控制领域。通常先通过高斯过程(GP)或贝叶斯网络(BN)等工具针对具体问题建立模型,然后再通过机器学习的方法或最优控制的方法,如模型预测控制(MPC)、线性二次调节器(LQR)、线性二次高斯(LQG)、迭代学习控制(ICL)等进行求解。而后者更多地发展自机器学习领域,属于数据驱动的方法。算法通过大量采样,估计代理的状态、动作的值函数或回报函数,从而优化动作策略。
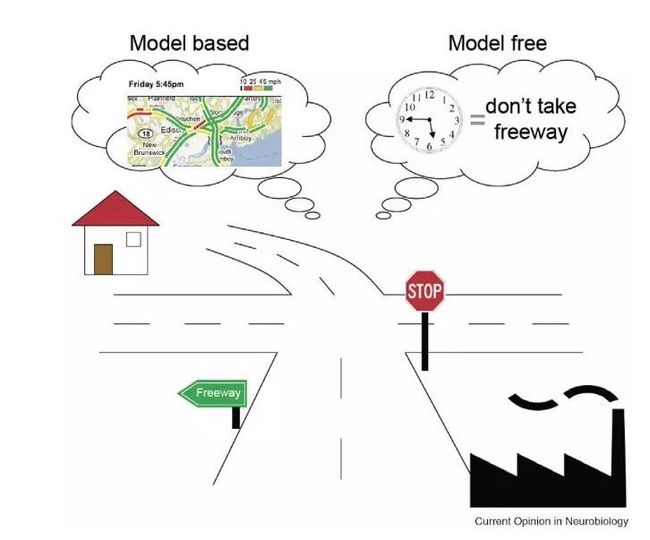
基于模型 vs. 免模型 [17]
从年初至今,Ben Recht 连发了 13 篇博文,从控制与优化的视角,重点探讨了 RL 中的免模型方法 [18]。Recht 指出免模型方法自身存在以下几大缺陷:
免模型方法无法从不带反馈信号的样本中学习,而反馈本身就是稀疏的,因此免模型方向样本利用率很低,而数据驱动的方法则需要大量采样。比如在 Atari 平台上的《Space Invader》和《Seaquest》游戏中,智能体所获得的分数会随训练数据增加而增加。利用免模型 DRL 方法可能需要 2 亿帧画面才能学到比较好的效果。AlphaGo 最早在 Nature 公布的版本也需要 3000 万个盘面进行训练。而但凡与机械控制相关的问题,训练数据远不如视频图像这样的数据容易获取,因此只能在模拟器中进行训练。而模拟器与现实世界间的 Reality Gap,直接限制了训练自其中算法的泛化性能。另外,数据的稀缺性也影响了其与 DL 技术的结合。
免模型方法不对具体问题进行建模,而是尝试用一个通用的算法解决所有问题。而基于模型的方法则通过针对特定问题建立模型,充分利用了问题固有的信息。免模型方法在追求通用性的同时放弃这些富有价值的信息。
基于模型的方法针对问题建立动力学模型,这个模型具有解释性。而免模型方法因为没有模型,解释性不强,调试困难。
相比基于模型的方法,尤其是基于简单线性模型的方法,免模型方法不够稳定,在训练中极易发散。
为了证实以上观点,Recht 将一个简单的基于 LQR 的随机搜索方法与最好的免模型方法在 MuJoCo 实验环境上进行了实验对比。在采样率相近的情况下,基于模型的随机搜索算法的计算效率至少比免模型方法高 15 倍 [19]。
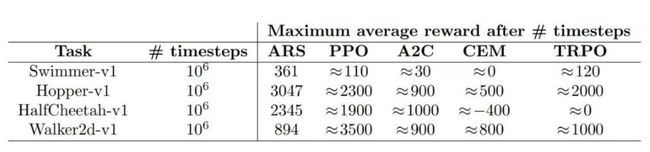
基于模型的随机搜索方法 ARS 吊打一众免模型方法 [19]
通过 Recht 的分析,我们似乎找到了 DRL 问题的根结。近三年在机器学习领域大火的 DRL 算法,多将免模型方法与 DL 结合,而免模型算法的天然缺陷,恰好与 Alexirpan 总结的 DRL 几大问题相对应(见上文)。
看来,DRL 的病根多半在采用了免模型方法上。为什么多数 DRL 的工作都是基于免模型方法呢?笔者认为有几个原因。第一,免模型的方法相对简单直观,开源实现丰富,比较容易上手,从而吸引了更多的学者进行研究,有更大可能做出突破性的工作,如 DQN 和 AlphaGo 系列。第二,当前 RL 的发展还处于初级阶段,学界的研究重点还是集中在环境是确定的、静态的,状态主要是离散的、静态的、完全可观察的,反馈也是确定的问题(如 Atari 游戏)上。针对这种相对“简单”、基础、通用的问题,免模型方法本身很合适。最后,在“AI = RL + DL”这一观点的鼓动下,学界高估了 DRL 的能力。DQN 展示出的令人兴奋的能力使得很多人围绕着 DQN 进行拓展,创造出了一系列同样属于免模型的工作。

绝大多数 DRL 方法是对 DQN 的扩展,属于免模型方法 [20]
那么,DRL 是不是应该抛弃免模型方法,拥抱基于模型的方法呢?
|| 三、基于模型或免模型,问题没那么简单
3.1 基于模型的方法,未来潜力巨大
基于模型的方法一般先从数据中学习模型,然后基于学到的模型对策略进行优化。学习模型的过程和控制论中的系统参数辨识类似。因为模型的存在,基于模型的方法可以充分利用每一个样本来逼近模型,数据利用率极大提高。基于模型的方法则在一些控制问题中,相比于免模型方法,通常有 10^2 级的采样率提升。此外,学到的模型往往对环境的变化鲁棒, 当遇到新环境时,算法可以依靠已学到的模型做推理,具有很好的泛化性能。

基于模型的方法具有更高采样率 [22]
此外,基于模型的方法还与潜力巨大的预测学习(Predictive Learning)紧密相关。由于建立了模型,本身就可以通过模型预测未来,这与 Predictive Learning 的需求不谋而合。其实,Yann LeCun 在广受关注的 NIPS 2016 主题报告上介绍 Predictive Learning 时,也是以基于模型的方法作为例子的 [21]。笔者认为,基于模型的 RL 方法可能是实现 Predictive Learning 的重要技术之一。
这样看来,基于模型的方法似乎更有前途。但天下没有免费的午餐,模型的存在也带来了若干问题
3.2 免模型方法,依旧是第一选择
基于模型的 DRL 方法相对而言不那么简单直观,RL 与 DL 的结合方式相对更复杂,设计难度更高。目前基于模型的 DRL 方法通常用高斯过程、贝叶斯网络或概率神经网络(PNN)来构建模型,典型的如 David Silver 在 2016 年提出的 Predictron 模型 [23]。另外一些工作,如 Probabilistic Inference for Learning COntrol (PILCO)[24],本身不基于神经网络,不过有与 BN 结合的扩展版本。而 Guided Policy Search (GPS) 虽然在最优控制器的优化中使用了神经网络,但模型并不依赖神经网络 [25]。此外还有一些模型将神经网络与模型耦合在一起 [26]。这些工作不像免模型 DRL 方法那样直观且自然,DL 所起的作用也各有不同。
除此之外,基于模型的方法也还存在若干自身缺陷:
针对无法建模的问题束手无策。有些领域,比如 NLP,存在大量难以归纳成模型的任务。在这种场景下,只能通过诸如 R-max 算法这样的方法先与环境交互,计算出一个模型为后续使用。但是这种方法的复杂度一般很高。近期有一些工作结合预测学习建立模型,部分地解决了建模难的问题,这一思路逐渐成为了研究热点。
建模会带来误差,而且误差往往随着算法与环境的迭代交互越来越大,使得算法难以保证收敛到最优解。
模型缺乏通用性,每次换一个问题,就要重新建模。
针对以上几点,免模型方法都有相对优势:对现实中非常多的无法建模的问题以及模仿学习问题,免模型算法仍是最好的选择。并且,免模型方法在理论上具备渐近收敛性,经过无数次与环境的交互可以保证得到最优解,这是基于模型的方法很难获得的结果。最后,免模型最大的优势就是具备非常好的通用性。事实上,在处理真正困难的问题时,免模型方法的效果通常更好。Recht 也在博文中指出,控制领域很有效的 MPC 算法其实与 Q-Learning 这样的免模型方法非常相关 [18]。
基于模型的方法与免模型的方法的区别其实也可以看做基于知识的方法与基于统计的方法的区别。总体来讲,两种方法各有千秋,很难说其中一种方法优于另一种。在 RL 领域中,免模型算法只占很少一部分,但基于历史原因,当前免模型的 DRL 方法发展迅速数量庞大,而基于模型的 DRL 方法则相对较少。笔者认为,我们可以考虑多做一些基于模型的 DRL 方面的工作,克服当前 DRL 存在的诸多问题。此外,还可以多研究结合基于模型方法与免模型方法的半模型方法,兼具两种方法的优势。这方面经典的工作有 RL 泰斗 Rich Sutton 提出的 Dyna 框架 [27] 和其弟子 David Silver 提出的 Dyna-2 框架 [28]。
通过以上讨论,我们似乎对 DRL 目前的困境找到了出路。但其实,造成当前 DRL 困境的原因远不止这些。
3.3 不仅仅是模型与否的问题
上文提到 Recht 使用基于随机搜索的方法吊打了免模型方法,似乎宣判了免模型方法的死刑。但其实这个对比并不公平。
2017 年 3 月,机器学习专家 Sham Kakade 的研究组发表文章 Towards Generalization and Simplicity in Continuous Control,试图探寻针对连续控制问题的简单通用的解法 [29] 。他们发现当前的模拟器存在非常大的问题,经过调试的线性策略就已经可以取得非常好的效果——这样的模拟器实在过于粗糙,难怪基于随机搜索的方法可以在同样的模拟器上战胜免模型方法!
可见目前 RL 领域的实验平台还非常不成熟,在这样的测试环境中的实验实验结果没有足够的说服力。很多研究结论都未必可信,因为好性能的取得或许仅仅是因为利用了模拟器的 bugs。此外,一些学者指出当前 RL 算法的性能评判准则也不科学。Ben Recht 和 Sham Kakade 都对 RL 的发展提出了多项具体建议,包括测试环境、基准算法、衡量标准等 [18,29]。可见 RL 领域还有太多需要改进和规范化。
那么,RL 接下来该如何突破呢?
|| 四、重新审视强化学习
对 DRL 和免模型 RL 的质疑与讨论,让我们可以重新审视 RL,这对 RL 今后的发展大有裨益。
4.1 重新审视 DRL 的研究与应用
DQN 和 AlphaGo 系列工作给人留下深刻印象,但是这两种任务本质上其实相对“简单”。因为这些任务的环境是确定的、静态的,状态主要是离散的、静态的、完全可观察的,反馈是确定的,代理也是单一的。目前 DRL 在解决部分可见状态任务(如 StarCraft),状态连续的任务(如机械控制任务),动态反馈任务和多代理任务中还没取得令人惊叹的突破。

DRL 取得成功的任务本质上相对简单 [30]
当前大量的 DRL 研究,尤其是应用于计算机视觉领域任务的研究中,很多都是将计算机视觉的某一个基于 DL 的任务强行构造成 RL 问题进行求解,其结果往往不如传统方法好。这样的研究方式造成 DRL 领域论文数量暴增、水分巨大。作为 DRL 的研究者,我们不应该找一个 DL 任务强行将其 RL 化,而是应该针对一些天然适合 RL 处理的任务,尝试通过引入 DL 来提升现有方法在目标识别环节或函数逼近环节上的能力。
在计算机视觉任务中,通过结合 DL 获得良好的特征表达或函数逼近是非常自然的思路。但在有些领域,DL 未必能发挥强大的特征提取作用,也未必被用于函数逼近。比如 DL 至今在机器人领域最多起到感知作用,而无法取代基于力学分析的方法。虽然有一些将 DRL 应用于物体抓取等现实世界的机械控制任务上并取得成功的案例,如 QT-Opt[70],但往往需要大量的调试和训练时间。我们应该清晰地认识 DRL 算法的应用特点:因为其输出的随机性,当前的 DRL 算法更多地被用在模拟器而非真实环境中。而当前具有实用价值且只需运行于模拟器中的任务主要有三类,即视频游戏、棋类游戏和自动机器学习(AutoML,比如谷歌的 AutoML Vision)。
这并不是说 DRL 的应用被困在模拟器中——如果能针对某一具体问题,解决模拟器与真实世界间的差异,则可以发挥 DRL 的强大威力。最近 Google 的研究员就针对四足机器人运动问题,通过大力改进模拟器,使得在模拟器中训练的运动策略可以完美迁移到真实世界中,取得了令人惊艳的效果 [71]。不过,考虑到 RL 算法的不稳定性,在实际应用中不应盲目追求端到端的解决方案,而可以考虑将特征提取(DL)与决策(RL)分开,从而获得更好的解释性与稳定性。此外,模块化 RL(将 RL 算法封装成一个模块)以及将 RL 与其他模型融合,将在实际应用中有广阔前景。而如何通过 DL 学习一个合适于作为 RL 模块输入的表示,也值得研究。
4.2 重新审视 RL 的研究
机器学习是个跨学科的研究领域,而 RL 则是其中跨学科性质非常显著的一个分支。RL 理论的发展受到生理学、神经科学和最优控制等领域的启发,现在依旧在很多相关领域被研究。在控制理论、机器人学、运筹学、经济学等领域内部,依旧有很多的学者投身 RL 的研究,类似的概念或算法往往在不同的领域被重新发明,起了不同的名字。

RL 的发展受到多个学科的影响 [31]
Princeton 大学著名的运筹学专家 Warren Powell 曾经写了一篇题为 AI, OR and Control Theory: A Rosetta Stone for Stochastic Optimization 的文章,整理了 RL 中同一个概念、算法在 AI、OR(运筹学)和 Control Theory(控制理论)中各自对应的名称,打通了不同领域间的隔阂 [32] 。由于各种学科各自的特点,不同领域的 RL 研究又独具特色,这使得 RL 的研究可以充分借鉴不同领域的思想精华。
在这里,笔者根据自身对 RL 的理解,试着总结一些值得研究的方向:
基于模型的方法。如上文所述,基于模型的方法不仅能大幅降低采样需求,还可以通过学习任务的动力学模型,为预测学习打下基础。
提高免模型方法的数据利用率和扩展性。这是免模型学习的两处硬伤,也是 Rich Sutton 的终极研究目标。这个领域很艰难,但是任何有意义的突破也将带来极大价值。
更高效的探索策略(Exploration Strategies)。平衡“探索”与“利用”是 RL 的本质问题,这需要我们设计更加高效的探索策略。除了若干经典的算法如 Softmax、ϵ-Greedy[1]、UCB[72] 和 Thompson Sampling[73] 等,近期学界陆续提出了大批新算法,如 Intrinsic Motivation [74]、Curiosity-driven Exploration[75]、Count-based Exploration [76] 等。其实这些“新”算法的思想不少早在 80 年代就已出现 [77],而与 DL 的有机结合使它们重新得到重视。此外,OpenAI 与 DeepMind 先后提出通过在策略参数 [78] 和神经网络权重 [79] 上引入噪声来提升探索策略, 开辟了一个新方向。
与模仿学习(Imitation Learning, IL)结合。机器学习与自动驾驶领域最早的成功案例 ALVINN[33] 就是基于 IL;当前 RL 领域最顶级的学者 Pieter Abbeel 在跟随 Andrew Ng 读博士时候, 设计的通过 IL 控制直升机的算法 [34] 成为 IL 领域的代表性工作。2016 年,英伟达提出的端到端自动驾驶系统也是通过 IL 进行学习 [68]。而 AlphaGo 的学习方式也是 IL。IL 介于 RL 与监督学习之间,兼具两者的优势,既能更快地得到反馈、更快地收敛,又有推理能力,很有研究价值。关于 IL 的介绍,可以参见 [35] 这篇综述。
奖赏塑形(Reward Shaping)。奖赏即反馈,其对 RL 算法性能的影响是巨大的。Alexirpan 的博文中已经展示了没有精心设计的反馈信号会让 RL 算法产生多么差的结果。设计好的反馈信号一直是 RL 领域的研究热点。近年来涌现出很多基于“好奇心”的 RL 算法和层级 RL 算法,这两类算法的思路都是在模型训练的过程中插入反馈信号,从而部分地克服了反馈过于稀疏的问题。另一种思路是学习反馈函数,这是逆强化学习(Inverse RL, IRL)的主要方式之一。近些年大火的 GAN 也是基于这个思路来解决生成建模问题, GAN 的提出者 Ian Goodfellow 也认为 GAN 就是 RL 的一种方式 [36]。而将 GAN 于传统 IRL 结合的 GAIL[37] 已经吸引了很多学者的注意。
RL 中的迁移学习与多任务学习。当前 RL 的采样效率极低,而且学到的知识不通用。迁移学习与多任务学习可以有效解决这些问题。通过将从原任务中学习的策略迁移至新任务中,避免了针对新任务从头开始学习,这样可以大大降低数据需求,同时也提升了算法的自适应能力。在真实环境中使用 RL 的一大困难在于 RL 的不稳定性,一个自然的思路是通过迁移学习将在模拟器中训练好的稳定策略迁移到真实环境中,策略在新环境中仅通过少量探索即可满足要求。然而,这一研究领域面临的一大问题就是现实鸿沟(Reality Gap),即模拟器的仿真环境与真实环境差异过大。好的模拟器不仅可以有效填补现实鸿沟,还同时满足 RL 算法大量采样的需求,因此可以极大促进 RL 的研究与开发,如上文提到的 Sim-to-Real[71]。同时,这也是 RL 与 VR 技术的一个结合点。近期学术界和工业界纷纷在这一领域发力。在自动驾驶领域,Gazebo、EuroTruck Simulator、TORCS、Unity、Apollo、Prescan、Panosim 和 Carsim 等模拟器各具特色,而英特尔研究院开发的 CARLA 模拟器 [38] 逐渐成为业界研究的标准。其他领域的模拟器开发也呈现百花齐放之势:在家庭环境模拟领域, MIT 和多伦多大学合力开发了功能丰富的 VirturalHome 模拟器;在无人机模拟训练领域,MIT 也开发了 Flight Goggles 模拟器。
提升 RL 的的泛化能力。机器学习最重要的目标就是泛化能力, 而现有的 RL 方法大多在这一指标上表现糟糕 [8],无怪乎 Jacob Andreas 会批评 RL 的成功是来自“train>
层级 RL(Hierarchical RL, HRL)。周志华教授总结 DL 成功的三个条件为:有逐层处理、有特征的内部变化和有足够的模型复杂度 [39]。而 HRL 不仅满足这三个条件,而且具备更强的推理能力,是一个非常潜力的研究领域。目前 HRL 已经在一些需要复杂推理的任务(如 Atari 平台上的《Montezuma's Revenge》游戏)中展示了强大的学习能力 [40]。
与序列预测(Sequence Prediction)结合。Sequence Prediction 与 RL、IL 解决的问题相似又不相同。三者间有很多思想可以互相借鉴。当前已有一些基于 RL 和 IL 的方法在 Sequence Prediction 任务上取得了很好的结果 [41,42,43]。这一方向的突破对 Video Prediction 和 NLP 中的很多任务都会产生广泛影响。
(免模型)方法探索行为的安全性(Safe RL)。相比于基于模型的方法,免模型方法缺乏预测能力,这使得其探索行为带有更多不稳定性。一种研究思路是结合贝叶斯方法为 RL 代理行为的不确定性建模,从而避免过于危险的探索行为。此外,为了安全地将 RL 应用于现实环境中,可以在模拟器中借助混合现实技术划定危险区域,通过限制代理的活动空间约束代理的行为。
关系 RL。近期学习客体间关系从而进行推理与预测的“关系学习”受到了学界的广泛关注。关系学习往往在训练中构建的状态链,而中间状态与最终的反馈是脱节的。RL 可以将最终的反馈回传给中间状态,实现有效学习,因而成为实现关系学习的最佳方式。2017 年 DeepMind 提出的 VIN[44] 和 Pridictron[23] 均是这方面的代表作。2018 年 6 月,DeepMind 又接连发表了多篇关系学习方向的工作如关系归纳偏置 [45]、关系 RL[46]、关系 RNN[47]、图网络 [48] 和已经在《科学》杂志发表的生成查询网络(Generative Query Network,GQN)[49]。这一系列引人注目的工作将引领关系 RL 的热潮。
对抗样本 RL。RL 被广泛应用于机械控制等领域,这些领域相比于图像识别语音识别等等,对鲁棒性和安全性的要求更高。因此针对 RL 的对抗攻击是一个非常重要的问题。近期有研究表明,会被对抗样本操控,很多经典模型如 DQN 等算法都经不住对抗攻击的扰动 [50,51]。
处理其他模态的输入。在 NLP 领域,学界已经将 RL 应用于处理很多模态的数据上,如句子、篇章、知识库等等。但是在计算机视觉领域,RL 算法主要还是通过神经网络提取图像和视频的特征,对其他模态的数据很少涉及。我们可以探索将 RL 应用于其他模态的数据的方法,比如处理 RGB-D 数据和激光雷达数据等。一旦某一种数据的特征提取难度大大降低,将其与 RL 有机结合后都可能取得 AlphaGo 级别的突破。英特尔研究院已经基于 CARLA 模拟器在这方面开展了一系列的工作。
4.3 重新审视 RL 的应用
当前的一种观点是“RL 只能打游戏、下棋,其他的都做了”。而笔者认为,我们不应对 RL 过于悲观。其实能在视频游戏与棋类游戏中超越人类,已经证明了 RL 推理能力的强大。通过合理改进后,有希望得到广泛应用。往往,从研究到应用的转化并不直观。比如,IBM Watson® 系统以其对自然语言的理解能力和应答能力闻名世界,曾在 2011 年击败人类选手获得 Jeopardy! 冠军。而其背后的支撑技术之一竟然是当年 Gerald Tesauro 开发 TD-Gammon 程序 [52] 时使用的 RL 技术 [53]。当年那个“只能用于”下棋的技术,已经在最好的问答系统中发挥不可或缺的作用了。今天的 RL 发展水平远高于当年,我们怎么能没有信心呢?

强大的 IBM Watson®背后也有 RL 发挥核心作用
通过调查,我们可以发现 RL 算法已经在各个领域被广泛使用:
控制领域。这是 RL 思想的发源地之一,也是 RL 技术应用最成熟的领域。控制领域和机器学习领域各自发展了相似的思想、概念与技术,可以互相借鉴。比如当前被广泛应用的 MPC 算法就是一种特殊的 RL。在机器人领域,相比于 DL 只能用于感知,RL 相比传统的法有自己的优势:传统方法如 LQR 等一般基于图搜索或概率搜索学习到一个轨迹层次的策略,复杂度较高,不适合用于做重规划;而 RL 方法学习到的则是状态 - 动作空间中的策略,具有更好的适应性。
自动驾驶领域。驾驶就是一个序列决策过程,因此天然适合用 RL 来处理。从 80 年代的 ALVINN、TORCS 到如今的 CARLA,业界一直在尝试用 RL 解决单车辆的自动驾驶问题以及多车辆的交通调度问题。类似的思想也广泛地应用在各种飞行器、水下无人机领域。
NLP 领域。相比于计算机视觉领域的任务,NLP 领域的很多任务是多轮的,即需通过多次迭代交互来寻求最优解(如对话系统);而且任务的反馈信号往往需要在一系列决策后才能获得(如机器写作)。这样的问题的特性自然适合用 RL 来解决,因而近年来 RL 被应用于 NLP 领域中的诸多任务中,如文本生成、文本摘要、序列标注、对话机器人(文字 / 语音)、机器翻译、关系抽取和知识图谱推理等等。成功的应用案例也有很多,如对话机器人领域中 Yoshua Bengio 研究组开发的 MILABOT 的模型 [54]、Facebook 聊天机器人 [55] 等;机器翻译领域 Microsoft Translator [56] 等。此外,在一系列跨越 NLP 与计算机视觉两种模态的任务如 VQA、Image/Video Caption、Image Grounding、Video Summarization 等中,RL 技术也都大显身手。
推荐系统与检索系统领域。RL 中的 Bandits 系列算法早已被广泛应用于商品推荐、新闻推荐和在线广告等领域。近年也有一系列的工作将 RL 应用于信息检索、排序的任务中 [57]。
金融领域。RL 强大的序列决策能力已经被金融系统所关注。无论是华尔街巨头摩根大通还是创业公司如 Kensho,都在其交易系统中引入了 RL 技术。
对数据的选择。在数据足够多的情况下,如何选择数据来实现“快、好、省”地学习,具有非常大的应用价值。近期在这方面也涌现出一系列的工作,如 UCSB 的 Jiawei Wu 提出的 Reinforced Co-Training [58] 等。
通讯、生产调度、规划和资源访问控制等运筹领域。这些领域的任务往往涉及“选择”动作的过程,而且带标签数据难以取得,因此广泛使用 RL 进行求解。
关于 RL 的更全面的应用综述请参见文献 [59,60]。
虽然有上文列举的诸多成功应用,但我们依旧要认识到,当前 RL 的发展还处于初级阶段,不能包打天下。目前还没有一个通用的 RL 解决方案像 DL 一样成熟到成为一种即插即用的算法。不同 RL 算法在各自领域各领风骚。在找到一个普适的方法之前,我们更应该针对特定问题设计专门的算法,比如在机器人领域,基于贝叶斯 RL 和演化算法的方法(如 CMAES[61])比 DRL 更合适。当然,不同的领域间应当互相借鉴与促进。RL 算法的输出存在随机性,这是其“探索”哲学带来的本质问题,因此我们不能盲目 All in RL, 也不应该 RL in All, 而是要找准 RL 适合解决的问题。

针对不同问题应该使用的不同 RL 方法 [22]
4.4 重新审视 RL 的价值
在 NIPS 2016 上,Yan LeCun 认为最有价值的问题是“Predictive Learning”问题,这其实类似于非监督学习问题。他的发言代表了学界近来的主流看法。而 Ben Recht 则认为,RL 比监督学习(Supervised Learning, SL)和非监督学习(Unsupervised Learning, UL)更有价值。他把这三类学习方式分别与商业分析中的描述分析(UL)、预测分析(SL)和指导分析(RL)相对应 [18]。
描述分析是对已有的数据进行总结,从而获得更鲁棒和清晰的表示,这个问题最容易,但价值也最低。因为描述分析的价值更多地在于美学方面而非实际方面。比如,“用 GAN 将一个房间的图片渲染成何种风格”远没有“依据房间的图片预测该房间的价格”更重要。而后者则是预测分析问题——基于历史数据对当前数据进行预测。但是在描述分析和预测分析中,系统都是不受算法影响的,而指导分析则更进一步地对算法与系统间的交互进行建模,通过主动影响系统,最大化价值收益。
类比以上两个例子,指导分析则是解决“如何通过对房间进行一系列改造来最大化提升房间价格”之类的问题。这种问题最难,因为涉及到了算法与系统的复杂交互,但也最有价值,因为指导性分析(RL)的天然目标就是价值最大化,也是人类解决问题的方式。并且,无论是描述分析还是预测分析,所处理的问题的环境都是静态的、不变的,这个假设对大多数实际的问题都不成立。而指导分析则被用来处理环境动态变化的问题,甚至还要考虑到与其他对手的合作或竞争,与人类面临的大多数实际问题更相似。
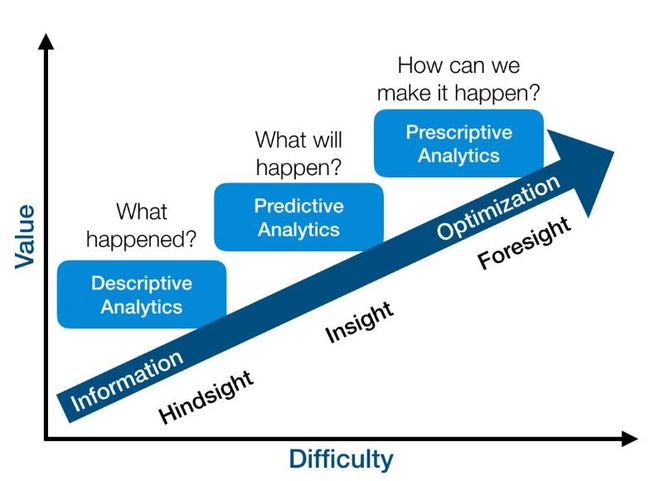
指导分析问题最难,也最有价值 [18]
在最后一节,笔者将试图在更广的范围内讨论类似于 RL 的从反馈中学习的方法,从而试图给读者介绍一种看待 RL 的新视角。
|| 五、广义的 RL——从反馈学习
本节使用“广义的 RL”一词指代针对“从反馈学习”的横跨多个学科的研究。与上文中介绍的来自机器学习、控制论、经济学等领域的 RL 不同,本节涉及的学科更宽泛,一切涉及从反馈学习的系统,都暂且称为广义的 RL。
5.1 广义的 RL,是人工智能研究的最终目
1950 年,图灵在其划时代论文 Computing Machinery and Intelligence[62] 中提出了著名的“图灵测试”概念:如果一个人(代号 C)使用测试对象皆理解的语言去询问两个他不能看见的对象任意一串问题。对象为:一个是正常思维的人(代号 B)、一个是机器(代号 A)。如果经过若干询问以后,C 不能得出实质的区别来分辨 A 与 B 的不同,则此机器 A 通过图灵测试。
请注意,“图灵测试”的概念已经蕴含了“反馈”的概念——人类借由程序的反馈来进行判断,而人工智能程序则通过学习反馈来欺骗人类。同样在这篇论文中,图灵还说到“除了试图直接去建立一个可以模拟成人大脑的程序之外,为什么不试图建立一个可以模拟小孩大脑的程序呢?如果它接受适当的教育,就会获得成人的大脑。”——从反馈中逐渐提升能力,这不正是 RL 的学习方式么?可以看出,人工智能的概念从被提出时其最终目标就是构建一个足够好的从反馈学习的系统。
1959 年,人工智能先驱 Arthur Samuel 正式定义了“机器学习”这概念。也正是这位 Samuel,在 50 年代开发了基于 RL 的的象棋程序,成为人工智能领域最早的成功案例 [63]。为何人工智能先驱们的工作往往集中在 RL 相关的任务呢?经典巨著《人工智能:一种现代方法》里对 RL 的评论或许可以回答这一问题:可以认为 RL 囊括了人工智能的所有要素:一个智能体被置于一个环境中,并且必须学会在其间游刃有余(Reinforcement Learning might be considered to encompass all of AI: an agent is placed in an environment and must learn to behave successfully therein.) [64]。
不仅仅在人工智能领域,哲学领域也强调了行为与反馈对智能形成的意义。生成论(Enactivism)认为行为是认知的基础,行为与感知是互相促进的,智能体通过感知获得行为的反馈,而行为则带给智能体对环境的真实有意义的经验 [65]。
行为和反馈是智能形成的基石 [65]
看来,从反馈学习确实是实现智能的核心要素。
回到人工智能领域。DL 取得成功后,与 RL 结合成为 DRL。知识库相关的研究取得成功后,RL 算法中也逐渐加入了 Memory 机制。而变分推理也已经找到了与 RL 的结合点。近期学界开始了反思 DL 的热潮,重新燃起对因果推理与符号学习的兴趣,于是也出现了关系 RL 和符号 RL[66] 相关的工作。通过回顾学术的发展,我们也可以总结出人工智能发展的一个特点:每当一个相关方向取得突破,总是会回归到 RL 问题, 寻求与 RL 相结合。与其把 DRL 看作 DL 的拓展,不如看作 RL 的一次回归。因此我们不必特别担心 DRL 的泡沫,因为 RL 本就是人工智能的最终目标,有着旺盛的生命力,未来还会迎来一波又一波的发展。
5.2 广义的 RL,是未来一切机器学习系统的形式
Recht 在他的最后一篇博文中 [67] 中强调,只要一个机器学习系统会通过接收外部的反馈进行改进,这个系统就不仅仅是一个机器学习系统,而且是一个 RL 系统。当前在互联网领域广为使用的 A/B 测试就是 RL 的一种最简单的形式。而未来的机器学习系统,都要处理分布动态变化的数据并从反馈中学习。因此可以说,我们即将处于一个“一切机器学习都是 RL”的时代,学界和工业界都亟需加大对 RL 的研究力度。Recht 从社会与道德层面对这一问题进行了详细探讨 [67],并将他从控制与优化角度对 RL 的一系列思考总结成一篇综述文章供读者思考 [69]。
5.3 广义的 RL,是很多领域研究的共同目标
4.2 节已经提到 RL 在机器学习相关的领域被分别发明与研究,其实这种从反馈中学习的思想,在很多其他领域也被不断地研究。仅举几例如下:
在心理学领域,经典条件反射与操作性条件反射的对比,就如同 SL 和 RL 的对比;而著名心理学家 Albert Bandura 提出的“观察学习”理论则与 IL 非常相似;精神分析大师 Melanie Klein 提出的“投射性认同”其实也可以看做一个 RL 的过程。在心理学诸多领域中,与 RL 关联最近的则是行为主义学派(Behaviorism)。其代表人物 John Broadus Watson 将行为主义心理学应用于广告业,极大推动了广告业的发展。这很难不让人联想到,RL 算法的一大成熟应用就是互联网广告。而行为主义受到认知科学影响而发展出的认知行为疗法则与 RL 中的策略迁移方法有异曲同工之妙。行为主义与 RL 的渊源颇深,甚至可以说是 RL 思想的另一个源头。本文限于篇幅无法详述,请感兴趣的读者参阅心理学方面的文献如 [53]。
在教育学领域,一直有关于“主动学习”与“被动学习”两种方式的对比与研究,代表性研究有 Cone of Experience,其结论与机器学习领域关于 RL 与 SL 的对比非常相似。而教育学家杜威提倡的“探究式学习”就是指主动探索寻求反馈的学习方法;
在组织行为学领域,学者们探究“主动性人格”与“被动性人格”的不同以及对组织的影响;
在企业管理学领域,企业的“探索式行为”和“利用式行为”一直是一个研究热点;
……
可以说,一切涉及通过选择然后得到反馈,然后从反馈中学习的领域,几乎都有 RL 的思想以各种形式存在,因此笔者称之为广义的 RL。这些学科为 RL 的发展提供了丰富的研究素材,积累了大量的思想与方法。同时,RL 的发展不会仅仅对人工智能领域产生影响,也会推动广义的 RL 所包含的诸多学科共同前进。
|| 六、资料综述
1. 视频(从入门到放弃)
1.1 腾讯_周沫凡_强化学习、教程、代码
https://www.bilibili.com/video/av16921335?from=search&seid=7037144790835305588
https://morvanzhou.github.io/
https://github.com/AndyYue1893/Reinforcement-learning-with-tensorflow 1.2 DeepMind_David Silver_UCL深度强化学习课程(2015)、PPT、笔记及代码
https://www.bilibili.com/video/av45357759?from=search&seid=7037144790835305588
https://blog.csdn.net/u_say2what/article/details/89216190
https://zhuanlan.zhihu.com/p/37690204 1.3 台大_李宏毅_深度强化学习(国语)课程(2018)、PPT、笔记
https://www.bilibili.com/video/av24724071?from=search&seid=7037144790835305588
http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
https://blog.csdn.net/cindy_1102/article/details/87904928 1.4 UC Berkeley_Sergey Levine_CS285(294)深度强化学习(2019)、PPT、代码
https://www.bilibili.com/video/av69455099?from=search&seid=7037144790835305588
http://rail.eecs.berkeley.edu/deeprlcourse/
https://github.com/berkeleydeeprlcourse/homework
2. 书籍
2.1 强化学习圣经_Rich Sutton_中文书、英文电子书、代码 ★★★★★(基础必读,有助于理解强化学习精髓)
https://item.jd.com/12696004.html
http://incompleteideas.net/book/the-book-2nd.html
https://github.com/AndyYue1893/reinforcement-learning-an-introduction
2.2 Python强化学习实战_Sudharsan Ravichandiran、代码 ★★★★★(上手快,代码清晰)
https://item.jd.com/12506442.html
https://github.com/AndyYue1893/Hands-On-Reinforcement-Learning-With-Python
2.3 强化学习精要_冯超 ★★★★(从基础到前沿,附代码)
https://item.jd.com/12344157.html
2.4 Reinforcement Learning With Open AI TensorFlow and Keras Using Python_OpenAI(注重实战)
https://pan.baidu.com/share/init?surl=nQpNbhkI-3WucSD0Mk7Qcg(提取码: av5p)
3. 教程
3.1 OpenAI Spinning Up英文版、中文版、介绍by量子位(在线学习平台,包括原理、算法、论文、代码)
https://spinningup.openai.com/en/latest/
https://spinningup.readthedocs.io/zh_CN/latest/index.html
https://zhuanlan.zhihu.com/p/49087870
3.2 莫烦Python( 通俗易懂)
https://morvanzhou.github.io/
4. PPT
4.1 Reinforcement learning_Nando de Freitas_DeepMind_2019
https://pan.baidu.com/s/1KF10W9GifZCDf9T4FY2H9Q
4.2 Policy Optimization_Pieter Abbeel_OpenAI/UC Berkeley/Gradescope
https://pan.baidu.com/s/1zOOZjvTAL_FRVTHHapriRw&shfl=sharepset
5. 算法
请问DeepMind和OpenAI身后的两大RL流派有什么具体的区别?
https://www.zhihu.com/question/316626294/answer/627373838 三大经典算法
5.1 DQN
Mnih. Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529. (Nature版本)
https://storage.googleapis.com/deepmind-data/assets/papers/DeepMindNature14236Paper.pdf
5.2 DDPG
David. Silver, et al. "Deterministic policy gradient algorithms." ICML. 2014.
http://proceedings.mlr.press/v32/silver14.pdf
5.3 A3C
Mnih. Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. 2016.
https://www.researchgate.net/publication/301847678_Asynchronous_Methods_for_Deep_Reinforcement_Learning
6. 环境
6.1 OpenAI Gym
http://gym.openai.com/
6.2 Google Dopamine 2.0
https://github.com/google/dopamine
6.3 Emo Todorov Mujoco
http://www.mujoco.org/
6.4 通用格子世界环境类
https://zhuanlan.zhihu.com/p/28109312
https://cs.stanford.edu/people/karpathy/reinforcejs/index.html
7. 框架
7.1 OpenAI Baselines(代码简洁,使用广泛)
https://github.com/openai/baselines
7.2 百度 PARL( 扩展性强,可复现性好,友好)
https://github.com/paddlepaddle/parl
7.3 DeepMind OpenSpiel(仅支持Debian和Ubuntu,28种棋牌类游戏和24种算法)
https://github.com/deepmind/open_spiel
8. 论文
8.1 清华张楚珩博士 ★★★★★[2]
https://zhuanlan.zhihu.com/p/46600521 张楚珩:强化学习论文汇总
8.2 NeuronDance ★★★★
https://github.com/AndyYue1893/DeepRL-1/tree/master/A-Guide-Resource-For-DeepRL
8.3 paperswithcode ★★★★
https://www.paperswithcode.com/area/playing-games
https://github.com/AndyYue1893/pwc
8.4 Spinning Up推荐论文 ★★★★★
https://zhuanlan.zhihu.com/p/50343077
9. 会议&期刊
9.1 会议:AAAI、NIPS、ICML、ICLR、IJCAI、 AAMAS、IROS等
9.2 期刊:AI、 JMLR、JAIR、 Machine Learning、JAAMAS等
9.3 计算机和人工智能会议(期刊)排名
https://www.ccf.org.cn/xspj/rgzn/
https://mp.weixin.qq.com/s?__biz=Mzg4MDE3OTA5NA==&mid=2247490957&idx=1&sn=b9aa515f7833ba1503be298ac2360960&source=41#wechat_redirect
https://www.aminer.cn/ranks/conf/artificial-intelligence-and-pattern-recognition
10. 公众号
10.1 深度强化学习实验室 ★★★★★
10.2 机器之心 ★★★★★
10.3 AI科技评论 ★★★★
10.4 新智元 ★★★
11.知乎
11.1 用户
许铁-巡洋舰科技(微信公众号同名)、Flood Sung(GitHub同名)
田渊栋、周博磊、俞扬、张楚珩、天津包子馅儿、JQWang2048 及其互相关注大牛等
11.2 专栏
David Silver强化学习公开课中文讲解及实践(叶强,很经典)
强化学习知识大讲堂(《深入浅出强化学习:原理入门》作者天津包子馅儿)
智能单元(杜克、Floodsung、wxam,聚焦通用人工智能,Flood Sung:深度学习论文阅读路线图 Deep Learning Papers Reading Roadmap很棒)
深度强化学习落地方法论(西交 大牛,实操经验丰富)
深度强化学习(知乎:JQWang2048,GitHub:NeuronDance,CSDN:J. Q. Wang)
神经网络与强化学习(《Reinforcement Learning: An Introduction》读书笔记)
强化学习基础David Silver笔记(陈雄辉,南大,DiDi AI Labs)
12. 博客
12.1 草帽BOY
https://blog.csdn.net/u013236946/category_6965927.html
12.2 J. Q. Wang
https://blog.csdn.net/gsww404
12.3 Keavnn
https://stepneverstop.github.io/
12.4 大卜口
http://blog.otoro.net/
13. 官网
13.1 OpenAI
https://www.openai.com/
13.2 DeepMind
https://www.deepmind.com/
13.3 Berkeley
https://bair.berkeley.edu/blog/?refresh=1
结语
虽然 RL 领域目前还存在诸多待解决的问题,在 DRL 这一方向上也出现不少泡沫,但我们应该看到 RL 领域本身在研究和应用领域取得的长足进步。这一领域值得持续投入研究,但在应用时需保持理性。而对基于反馈的学习的研究,不仅有望实现人工智能的最终目标,也对机器学习领域和诸多其他领域的发展颇有意义。这确实是通向人工智能的最佳路径。这条路上布满荆棘,但曙光已现。
|| 作者简介
侯宇清,博士,现为英特尔中国研究院认知计算实验室和清华大学计算机科学与技术系智能技术与系统国家重点实验室联合培养博士后研究员,研究兴趣为强化学习的理论以及应用,研究方向为基于深度强化学习的视觉信息处理以及元学习。2016 年毕业于北京大学,研究方向为多模态学习。发表学术论文 7 篇,拥有 5 项美国 / 国际专利及申请。
陈玉荣,博士,现任英特尔首席研究员、英特尔中国研究院认知计算实验室主任。负责领导视觉认知和机器学习研究工作,推动基于英特尔平台的智能视觉数据处理技术创新。发表学术论文 50 余篇,拥有 50 余项美国 / 国际专利及申请。
|| 致谢
在本文的写作过程中,得到了英特尔研究院郭怡文研究员、刘忠轩研究员和史雪松研究员的积极反馈。剑桥大学的 Shane Gu 博士、清华大学交叉信息学院的张崇洁教授和北京大学信息科学学院智能科学系的林宙辰教授分别在基于模型的方法、RL 泛化性能和 RL 模型优化方法方面提供了很多非常有价值的指导意见。此外特别感谢强化学习研究者 Flood Sung,为笔者介绍了 RL 领域多个最前沿的研究应用,并提供了这一研究交流平台。
参考文献
[1] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
[2] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[3] Silver, David, et al. "Mastering the game of go without human knowledge." Nature 550.7676 (2017): 354.
[4] Levine, Sergey, et al. "End-to-end training of deep visuomotor policies." arXiv preprint arXiv:1504.00702, 2015.
[5] Mao, Hongzi, et al. "Resource management with deep reinforcement learning." Proceedings of the 15th ACM Workshop on Hot Topics in Networks. ACM, 2016.
[6] deepmind.com/blog/deepm
[7] Jaques, Natasha, et al. "Tuning recurrent neural networks with reinforcement
learning." (2017).
[8] Henderson, Peter, et al. "Deep reinforcement learning that matters." arXiv
preprint arXiv:1709.06560 (2017).
[9] Islam, Riashat, et al. "Reproducibility of benchmarked deep reinforcement
learning tasks for continuous control." arXiv preprint arXiv:1708.04133 (2017).
[10] riashatislam.files.wordpress.com
[11] sites.google.com/view/d
[12]reddit.com/r/MachineLea
[13] alexirpan.com/2018/02/1
[14] himanshusahni.github.io
[15] amid.fish/reproducing-d
[16] rodeo.ai/2018/05/06/rep
[17] Dayan, Peter, and Yael Niv. "Reinforcement learning: the good, the bad and the ugly." Current opinion in neurobiology 18.2 (2008): 185-196.
[18] argmin.net/2018/05/11/o
[19] Mania, Horia, Aurelia Guy, and Benjamin Recht. "Simple random search provides a competitive approach to reinforcement learning." arXiv preprint arXiv:1803.07055 (2018).
[20] Justesen, Niels, et al. "Deep Learning for Video Game Playing." arXiv preprint arXiv:1708.07902 (2017).
[21] youtube.com/watch?
[22] sites.google.com/view/i
[23] Silver, David, et al. "The predictron: End-to-end learning and planning." arXiv preprint arXiv:1612.08810 (2016).
[24] Deisenroth, Marc, and Carl E. Rasmussen. "PILCO: A model-based and data-efficient approach to policy search." Proceedings of the 28th International Conference on machine learning (ICML-11). 2011.
[25] Levine, Sergey, and Vladlen Koltun. "Guided policy search." International Conference on Machine Learning. 2013.
[26] Weber, Théophane, et al. "Imagination-augmented agents for deep reinforcement learning." arXiv preprint arXiv:1707.06203 (2017).
[27] Sutton, Richard S. "Dyna, an integrated architecture for learning, planning, and reacting." ACM SIGART Bulletin 2.4 (1991): 160-163.
[28] Silver, David, Richard S. Sutton, and Martin Müller. "Sample-based learning and search with permanent and transient memories." Proceedings of the 25th international conference on Machine learning. ACM, 2008.
[29] Rajeswaran, Aravind, et al. "Towards generalization and simplicity in continuous control." Advances in Neural Information Processing Systems. 2017.
[30] andreykurenkov.com/writ
[31] UCL Course on RL: www0.cs.ucl.ac.uk/staff
[32] Powell, Warren B. "AI, OR and control theory: A rosetta stone for stochastic optimization." Princeton University (2012).
[33] Pomerleau, Dean A. "Alvinn: An autonomous land vehicle in a neural network." Advances in neural information processing systems. 1989.
[34] Abbeel, Pieter, and Andrew Y. Ng. "Apprenticeship learning via inverse reinforcement learning." Proceedings of the twenty-first international conference on Machine learning. ACM, 2004.
[35] Osa, Takayuki, et al. "An algorithmic perspective on imitation learning." Foundations and Trends® in Robotics 7.1-2 (2018): 1-179.
[36] fermatslibrary.com/arxi url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdf
[37] Ho, Jonathan, and Stefano Ermon. "Generative adversarial imitation learning." Advances in Neural Information Processing Systems. 2016.
[38] github.com/carla-simula
[39] 36kr.com/p/5129474.html
[40] Vezhnevets, Alexander Sasha, et al. "Feudal networks for hierarchical reinforcement learning." arXiv preprint arXiv:1703.01161 (2017).
[41] Ranzato, Marc'Aurelio, et al. "Sequence level training with recurrent neural networks." arXiv preprint arXiv:1511.06732 (2015).
[42] Bahdanau, Dzmitry, et al. "An actor-critic algorithm for sequence prediction." arXiv preprint arXiv:1607.07086 (2016).
[43] Keneshloo, Yaser, et al. "Deep Reinforcement Learning For Sequence to Sequence Models." arXiv preprint arXiv:1805.09461 (2018).
[44] Watters, Nicholas, et al. "Visual interaction networks." arXiv preprint arXiv:1706.01433 (2017).
[45] Hamrick, Jessica B., et al. "Relational inductive bias for physical construction in humans and machines." arXiv preprint arXiv:1806.01203 (2018).
[46] Zambaldi, Vinicius, et al. "Relational Deep Reinforcement Learning." arXiv preprint arXiv:1806.01830 (2018).
[47] Santoro, Adam, et al. "Relational recurrent neural networks." arXiv preprint arXiv:1806.01822 (2018).
[48] Battaglia, Peter W., et al. "Relational inductive biases, deep learning, and graph networks." arXiv preprint arXiv:1806.01261 (2018).
[49] Eslami, SM Ali, et al. "Neural scene representation and rendering." Science 360.6394 (2018): 1204-1210.
[50] Huang, Sandy, et al. "Adversarial attacks on neural network policies." arXiv preprint arXiv:1702.02284 (2017).
[51] Behzadan, Vahid, and Arslan Munir. "Vulnerability of deep reinforcement learning to policy induction attacks." International Conference on Machine Learning and Data Mining in Pattern Recognition. Springer, Cham, 2017.
[52] Tesauro, Gerald. "Temporal difference learning and TD-Gammon." Communications of the ACM 38.3 (1995): 58-68.
[53] Jones, Rebecca M., et al. "Behavioral and neural properties of social reinforcement learning."Journal of Neuroscience 31.37 (2011): 13039-13045.
[54] github.com/YBIGTA/DeepN
[55] Lewis, Mike, et al. "Deal or no deal? end-to-end learning for negotiation dialogues." arXiv preprint arXiv:1706.05125 (2017).
[56] microsoft.com/zh-cn/tra
[57] Derhami, Vali, et al. "Applying reinforcement learning for web pages ranking algorithms." Applied Soft Computing 13.4 (2013): 1686-1692.
[58] Wu, Jiawei, Lei Li, and William Yang Wang. "Reinforced Co-Training." arXiv preprint arXiv:1804.06035 (2018).
[59] Li, Yuxi. "Deep reinforcement learning: An overview." arXiv preprint arXiv:1701.07274 (2017).
[60] Feinberg, Eugene A., and Adam Shwartz, eds. Handbook of Markov decision processes: methods and applications. Vol. 40. Springer Science & Business Media, 2012.
[61] en.wikipedia.org/wiki/C
[62] Turing, Alan M. "Computing machinery and intelligence." Parsing the Turing Test. Springer, Dordrecht, 2009. 23-65.
[63] en.wikipedia.org/wiki/A
[64] Russell, Stuart J., and Peter Norvig. Artificial intelligence: a modern approach. Malaysia; Pearson Education Limited,, 2016.
[65] Noë, Alva. Action in perception. MIT press, 2004.
[66] Garnelo, Marta, Kai Arulkumaran, and Murray Shanahan. "Towards deep symbolic reinforcement learning." arXiv preprint arXiv:1609.05518 (2016).
[67] argmin.net/2018/04/16/e
[68] Bojarski, Mariusz, et al. "End to end learning for self-driving cars." arXiv preprint arXiv:1604.07316 (2016).
[69] Recht, Benjamin . "A Tour of Reinforcement Learning:The View from Continuous Control." arXiv preprint arXiv: 1806.09460
[70] Kalashnikov, Dmitry, et al. "QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation." arXiv preprint arXiv:1806.10293 (2018).
[71] Tan, Jie, et al. "Sim-to-Real: Learning Agile Locomotion For Quadruped Robots." arXiv preprint arXiv:1804.10332 (2018).
[72] Auer, Peter. "Using confidence bounds for exploitation-exploration trade-offs." Journal of Machine Learning Research 3.Nov (2002): 397-422.
[73] Agrawal, Shipra, and Navin Goyal. "Thompson sampling for contextual bandits with linear payoffs." International Conference on Machine Learning. 2013.
[74] Mohamed, Shakir, and Danilo Jimenez Rezende. "Variational information maximisation for intrinsically motivated reinforcement learning." Advances in neural
information processing systems. 2015.
[75] Pathak, Deepak, et al. "Curiosity-driven exploration by self-supervised prediction." International Conference on Machine Learning (ICML). Vol. 2017. 2017.
[76] Tang, Haoran, et al. "# Exploration: A study of count-based exploration for deep reinforcement learning." Advances in Neural Information Processing Systems. 2017.
[77] McFarlane, Roger. "A Survey of Exploration Strategies in Reinforcement Learning." McGill University, www. cs. mcgill. ca/∼ cs526/roger. pdf, accessed: April (2018).
[78] Plappert, Matthias, et al. "Parameter space noise for exploration." arXiv preprint arXiv:1706.01905 (2017).
[79] Fortunato, Meire, et al. "Noisy networks for exploration." arXiv preprint arXiv:1706.10295 (2017).
[80] Kansky, Ken, et al. "Schema networks: Zero-shot transfer with a generative causal model of intuitive physics." arXiv preprint arXiv:1706.04317 (2017).
[81] Li, Da, et al. "Learning to generalize: Meta-learning for domain generalization." arXiv preprint arXiv:1710.03463 (2017).
[82] berkeleyautomation.github.io
[83] contest.openai.com/2018

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)备注:加入本站微信群或者qq群,请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看