介绍 (Introduction)
As a data scientist at VATBox, I’ve mainly worked on projects which at their core involve building Machine Learning models. What’s nice about this project is that it purely includes building an algorithm to solve the given task. A real-world problem with a custom-made solution.
作为VATBox的数据科学家,我主要从事以构建机器学习模型为核心的项目。 这个项目的好处在于,它纯粹包括构建用于解决给定任务的算法。 定制解决方案的实际问题。
问题定义 (Problem Definition)
The problem in hand is essentially matching between two images which are close to being identical (changes can be due to image size, for example). The goal here is to do so in real-time, therefore we need the algorithm to be relatively fast.
当前的问题实质上是两个几乎相同的图像之间的匹配(例如,变化可能是由于图像大小引起的)。 这里的目标是实时执行此操作,因此我们需要算法相对较快。
At VATBox our world is a world of invoices. Users upload reports, which contain images of invoices, to our platform. A single report contains two groups of images, one is a collection of separate invoices, and the other is all the collection together in one single file. For reasons which we will not go into, there may be images in one group that won’t appear in the other. The goal is to detect the images which don’t appear in the other group (if there are any). If we match between all the images which are essentially the same image, we can also identify the spare ones.
在VATBox,我们的世界就是发票的世界。 用户将包含发票图像的报告上载到我们的平台。 单个报告包含两组图像,一组是单独发票的集合,另一组是所有集合在一起的一个文件。 由于我们不愿讨论的原因,一组中的图像可能不会出现在另一组中。 目的是检测未出现在另一组中的图像(如果有)。 如果我们在本质上是相同图像的所有图像之间匹配,我们也可以识别备用图像。
解 (Solution)
So to find the spare images, we need to perform a comparison between every two images (or do we..? we’ll get to that..), one image being from the first group and the other from the second group. Once that is done, we can match between images, and then see which images are left without any match. We can build a Comparison Matrix which holds these comparisons.
因此,要查找备用图像,我们需要在每两个图像之间进行比较(否则我们将进行比较。),一个图像来自第一组,另一图像来自第二组。 完成后,我们可以在图像之间进行匹配,然后查看剩下的图像没有任何匹配。 我们可以建立一个包含这些比较的比较矩阵。
During my research, I mostly encountered solutions that are based on features extracted from images to match between images, but that’s computationally expensive for our case, as we’re interested in doing this for every pair of images. Therefore we are in need of a different approach.
在研究过程中,我经常遇到基于从图像中提取的特征以在图像之间进行匹配的解决方案,但这对于我们的案例而言在计算上是昂贵的,因为我们有兴趣对每对图像进行此操作。 因此,我们需要一种不同的方法。
As described, the images that actually match, are close to being identical. So we can expect their pixel values to be relatively similar. So can we perhaps calculate the correlation between the two given signals? But how can this be done efficiently with images?
如上所述,实际匹配的图像几乎是相同的。 因此,我们可以期望它们的像素值相对相似。 那么也许我们可以计算两个给定信号之间的相关性吗? 但是,如何使用图像有效地做到这一点呢?
OpenCV has a Template Matching module. The purpose of this module is to find a given template within a (larger) image. The module enables us to “swipe” a template (T) across an image (I) and perform calculations efficiently (similarly to how a convolutional kernel is swiped on an image in a CNN).
OpenCV具有模板匹配模块。 该模块的目的是在(较大)图像中找到给定的模板。 该模块使我们能够在图像(I)上“滑动”模板(T)并高效地执行计算(类似于卷积核如何在CNN中的图像上滑动)。
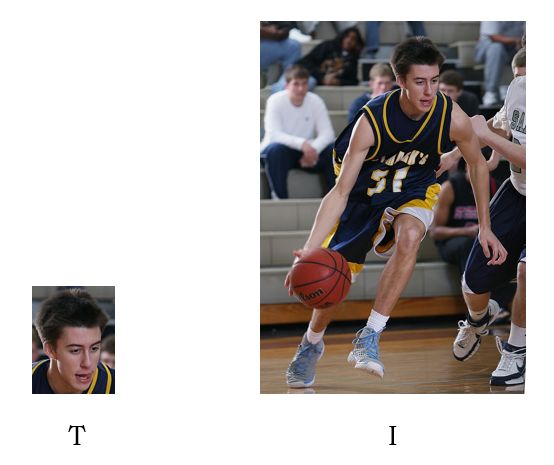
This can be great for our needs! We can use this to swipe an image from the first group on an image of the other group efficently, as OpenCV’s implementation is optimal. Of course, since we’re looking for two images that match (and not a template in another image) the swiping is just done a single time.
这可以满足我们的需求! 因为OpenCV实现是最佳的,所以我们可以使用它从第一组的图像有效地刷到另一组的图像上。 当然,由于我们要查找匹配的两个图像(而不是另一个图像中的模板),因此只需一次刷卡即可。
The Template Matching module includes different methods of calculating correlations, one of them being a normalized calculation, returning values between 0 (no similarity) to 1 (completely identical images):
模板匹配模块包括计算相关性的不同方法 ,其中之一是归一化计算,返回0(无相似性)到1(完全相同的图像)之间的值:
corr = cv2.matchTemplate(group1_image, group2_image,
cv2.TM_CCOEFF_NORMED)[0][0]The indexing shows that we’re accessing a matrix. As mentioned, we’re essentially performing a single swipe, therefore we’re just grabbing the single value from a matrix with a single element.
索引显示我们正在访问矩阵。 如前所述,我们实际上是在执行一次滑动,因此我们只是从具有单个元素的矩阵中获取单个值。
A word about the calculation. Prior to the actual correlation calculation, the images are normalized, resulting in a matrix (or tensor) with negative values as well as positive values. When performing the correlation calculation, similar regions will get positive values within the correlation calculation, whereas dissimilar regions will get negative values (resulting in lower correlation).
关于计算的一句话。 在实际的相关性计算之前,将图像标准化,从而得到具有负值和正值的矩阵(或张量)。 当执行相关计算时,相似区域在相关计算中将获得正值,而不同区域将获得负值(导致较低的相关性)。
复杂 (Complexity)
Since we’re comparing every pair of images, the complexity of the algorithm is O(n*m), n being the number of images in group one, and m being the number of images in group two. Can we make the algorithm more efficient?
由于我们正在比较每对图像,因此算法的复杂度为O(n * m),n为第一组中的图像数量,m为第二组中的图像数量。 我们可以使算法更有效吗?
As the above function returns values close to 1 for similar images, we can set a threshold (e.g. 0.9) for which there’s no need to keep on searching for a match if one is found. In addition, if a match is found, we’ll remove the matched images from our search. For example, if in the first iteration we are comparing an image from group one with 4 images from group two, on the second iteration we’ll do a comparison with only 3 images, and so on.
由于上述函数针对相似图像返回的值接近1,因此我们可以设置一个阈值(例如0.9),如果找到该阈值,则无需继续搜索匹配项。 此外,如果找到匹配项,我们将从搜索中删除匹配的图像。 例如,如果在第一次迭代中我们将来自第一组的图像与来自第二组的4个图像进行比较,那么在第二次迭代中,我们将仅对3个图像进行比较,依此类推。
摘要 (Summary)
In this article, we reviewed a somewhat out of the ordinary real-world data science problem which required a tailor-made solution. We dug into OpenCV’s Template Matching and understood how it can be used to fulfill the requirements of the problem at hand. Hope you enjoyed it!
在本文中,我们回顾了一个与众不同的现实世界数据科学问题,该问题需要量身定制的解决方案。 我们深入研究了OpenCV模板匹配,并了解了如何将其用于满足当前问题的要求。 希望你喜欢!
翻译自: https://towardsdatascience.com/image-matching-with-opencvs-template-matching-5df577a3ce2e