Python数据分析——Pandas基础入门+代码(一)
系列文章目录
Chapter 1:创建与探索DF、排序、子集化:Python数据分析——Pandas基础入门+代码(一)
Chapter 2:聚合函数,groupby,统计分析:Python数据分析——Pandas基础入门+代码(二)
Chapter 3:索引和切片:Python数据分析——Pandas基础入门+代码(三)
Chapter 4: 可视化与读写csv文件:Python数据分析——Pandas基础入门+代码(四)
Chapter 5:数据透视表:Python数据分析——Pandas基础入门+代码之数据透视表
文章目录
- 系列文章目录
- 前言
- 一、如何自己创建一个DataFrame
-
- 1.1 以list of dictionaries的形式建立一个DF
- 1.2 以dictionary of lists的形式建立一个DF
- 二、如何用pandas探索DataFrame中的整体和细节
-
- 2.1 整体数据的探索
- 2.2 数据细节的探索
- 三、Sorting 排序
-
- 3.1 行排序
- 四、Subsetting 子集化
-
- 4.1 按列筛选
- 4.2 按行筛选
- 4.3 多变量子集化处理
- 五、如何自己添加新的列
- Reference
前言
打算把从datacamp上学到的整理一下并记录下来,Pandas基础指的是非常入门的东西,包括数据处理,切片等。
这一篇主要讲的是:
创建与探索DF、排序、子集化以及如何添加新一列的DataFrame
一、如何自己创建一个DataFrame
简单来说,创建DataFrame的方式一共有两种,第一种是以 list of dict 的形式,第二种是以 dict of list 的形式。举例子说明一下,我们先看到下面这个表格,这里面就是甲乙丙丁的人物信息。

1.1 以list of dictionaries的形式建立一个DF
也就是外包是列表,内包是字典
dict1 = [
{'name' : 'jia', 'gender': 'm', 'weight': 66, 'height': 171, 'date_of_birth': '1990-01-01'}, # 注意都好分割好每一条
{'name' : 'yi', 'gender': 'f', 'weight': 67, 'height': 178, 'date_of_birth': '1993-05-13'},
{'name' : 'bing', 'gender': 'f', 'weight': 45, 'height': 160, 'date_of_birth': '1996-06-01'},
{'name' : 'ding', 'gender': 'm', 'weight': 70, 'height': 190, 'date_of_birth': '1950-11-21'},
]
这里我们可以看到,他是一个横向的排列,就是按行进行一个输入,一行一行的打好。紧接着我们需要导入pandas包,并用pd.DataFrame进行一个读取和转换。
import pandas as pd
dt1 = pd.DataFrame(dict1)
print(dt1.head())
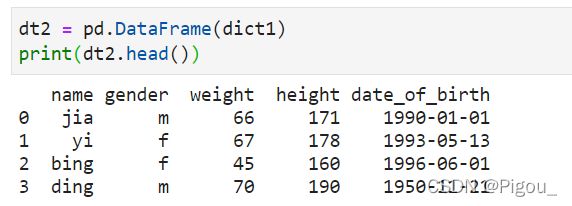
1.2 以dictionary of lists的形式建立一个DF
和上面相反,外包是dict,内是列表。同样的,代码和结果如下。
dict2 = {
'name': ['jia', 'yi', 'bing', 'ding'],
'gender': ['m', 'f', 'f', 'm'],
'weight': [66, 67, 45, 70],
'height': [171, 178, 160, 190],
'date_of_birth': ['1990-01-01', '1993-05-13', '1996-06-01', '1950-11-21']
}

上面两者的区别就在于list of dict是横向输入,而dict of list是纵向输入
二、如何用pandas探索DataFrame中的整体和细节
2.1 整体数据的探索
这里主要是看数据集里的整体部分,当你拿到数据集后应该是先对数据集的整体进行一个观察和探索

这里主要内容翻译:
-
看数据的前几行就用head(),可以输入数字表明要看前多少行
-
观察每列的信息用info()
-
DF的数据大小用shape, df.shape 后面没有括号!
-
描述性统计每列用describe()
就要刚刚上面的数据给大家看看。head()为例

2.2 数据细节的探索

-
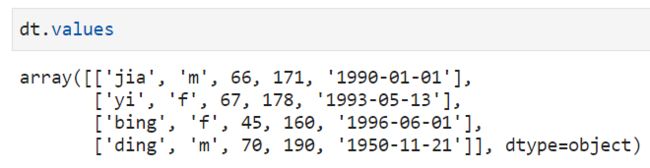
values 就是生成一个二维的numpy数组
-
columns 查看每列的名称
-
index 可以查看每行的行名称
同样的,大家可以自行试试,试验试验
三、Sorting 排序
3.1 行排序

sort.values里面如果需要降序需要用到 ascending,默认是True(升序),ascending = False就是降序了
注意:sort_values()是小括号不是中括号,如果选择的是一列直接用引号,多列就要把这些列再用中括号框起来。
如果有要求说,先对x1列进行升序排列,再按x2列进行降序排列,用一行写出来,那就是:
'''
Example :
df.sort_values(["column1", "column2"], ascending=[True, False])
'''
dt.sort_values(['weight', 'height'], ascending = [True, False])

四、Subsetting 子集化
意思其实就是在原数据上筛选出我们所要的数据,也就变为了子集,称之为子集化
4.1 按列筛选

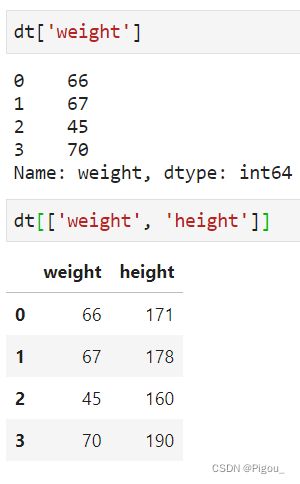
这里就是分别列举了取一列和多列之间的区别,要注意的地方就是需要多列的话我们要两个中括号!!
假设,我们这里就身高体重有用
dt['weight']
dt[['weight', 'height']]
4.2 按行筛选

我们可以试验一下,首先看看我们在没有最外层的框下是什么结果
dt['height'] < 180
得到的是布林值
Out [1]:
0 True
1 True
2 True
3 False
Name: height, dtype: bool
pandas就把小于180的都筛选出来了,表示为真。那如何将真变为数值呢?——再加一层框
In [1]: dt[dt['height'] < 180]
Out [1]:
name gender weight height date_of_birth
0 jia m 66 171 1990-01-01
1 yi f 67 178 1993-05-13
2 bing f 45 160 1996-06-01
这样就被筛选出来了。
另外,筛选行列的区别其实就是一个是特征维度,一个是在该特征下的数值。所以选取行不仅要将列选出来,也要给予特定的条件让python去选取行,为什么这么选
多条件筛选的话记得用 & 作为连接,用&说明的是两个条件都需要满足,是交集。不同的条件需要用()括起来表示这个为其中一个筛选条件
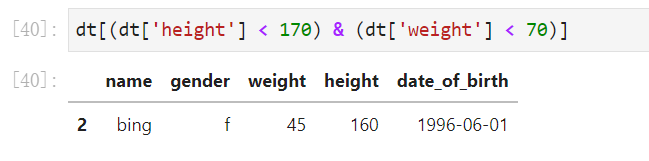
4.3 多变量子集化处理

用 ” | “ 代表or,表示条件 ”或者“,这表示满足其中一个条件即可,为并集。
isin()的含义就是字面上的意思:is in。表示在这个数据里面,包含了什么什么,要筛选出来,返回一个布林值结果。
比如下面的代码和结果。代码将根据列表‘canu’去找在‘state’列下包含列表中的内容。
这里值的注意的是isin()里面是一个列表,用的网站上的数据
# The Mojave Desert states
canu = ["California", "Arizona", "Nevada", "Utah"]
# Filter for rows in the Mojave Desert states
mojave_homelessness = homelessness[homelessness['state'].isin(canu)]
# See the result
print(mojave_homelessness)

五、如何自己添加新的列
# 固定搭配
df['new_column'] = xxxxx
添加新的列就直接在df后面框起来写上列的名字就完成一半了,等号后面一般可以接一下其他筛选条件和计算条件。
dt['BMI'] = dt['weight'] / dt['height']**2 # 实际上身高应该换算成 米 为单位哈

Reference
学习网站:datacamp
链接地址:https://campus.datacamp.com/