R 多变量数据预处理_数据科学 | 第3讲 数据清洗与预处理

点击上方蓝字,记得关注我们!

在实际数据挖掘过程中,我们拿到的初始数据,往往存在缺失值、重复值、异常值或者错误值,通常这类数据被称为“脏数据”,需要对其进行清洗。另外有时数据的原始变量不满足分析的要求,我们需要先对数据进行一定的处理,也就是数据的预处理。数据清洗和预处理的主要目的是提高数据质量,从而提高挖掘结果的可靠度,这是数据挖掘过程中非常必要的一个步骤。否则“垃圾数据进,垃圾结果出”。一个典型的数据清洗和预处理过程如图1所示。

图1
 数据分类
数据分类
数据是数据对象及其属性的集合。一个数据对象是对一个事物或者物理对象的描述,一个典型的数据对象可以是一条记录、一个实体、一个案例或一个样本等等。而数据对象的属性则是这个对象的性质或特征,例如一个人的肤色、眼球颜色是这个人的属性,而某地某天的气温则是该地该天气象记录的属性特征。
大数据时代,数据的来源越来越多样化,比如来自互联网、银行、工商、税务、公安天眼等等。同时,数据的格式和形态也越来越多样化,有数字、文字、图片、音频、视频等等。能够用统一的结构加以表示的数据,如数字、符号等,我们称之为结构化数据;无法用统一的结构表示的数据,如文本、音频、图像、视频,我们称之为非结构化数据。我们过去所分析的数据大部分是结构化数据,但是随着非结构化数据越来越多,我们有必要去研究非结构化数据。
对于结构化数据,按照对客观事物测度的程度或精确水平来划分,可将数据的计量尺度从低级到高级、由粗略到精确划分为四种,如表1所示。
表1 常见的数据类型及其特征

在计量尺度的应用中,需要注意的是,同类事物用不同的尺度量化,会得到不同的类别数据。如农民收入数据按实际填写就是区间数据;按高、中、低收入水平分就是有序;按有无收入计量则是分类;而说某人的收入是另一人的两倍,便是比例数据了。
数据清洗数据清洗是数据准备过程中最重要的一步,通过填补缺失数值、光滑噪声数据、识别或删除离群点并解决不一致性来“清洗”数据,进而达到数据格式标准化,清除异常数据、重复数据,纠正错误数据等目的。
1、处理缺失数据从缺失的分布来讲,缺失值可以分为完全随机缺失(missing completely at random, MCAR),随机缺失(missing at random, MAR)和完全非随机缺失(missing not at random, MNAR)。完全随机缺失是指数据的缺失是完全随机的,不依赖于任何完全变量或不完全变量。缺失情况相对于所有可观测和不可观测的数据来说,在统计意义上是独立的,也就是说直接删除缺失数据对建模影响不大。随机缺失指的是数据的缺失不是完全随机的,数据的缺失依赖于其他完全变量。具体来说,一个观测出现缺失值的概率是由数据集中不含缺失值的变量决定的, 与含缺失值的变量关系不大。完全非随机缺失指的是数据的缺失依赖于不完全变量,与缺失数据本身存在某种关联,比如调查时,所设计的问题过于敏感,被调查者拒绝回答而造成的缺失。
从统计角度来看,非随机缺失的数据会产生有偏估计,而非随机缺失数据处理也是比较困难的。事实上,绝大部分的原始数据都包含有缺失数据,因此怎样处理这些缺失值就很重要了。
(1)缺失数据的识别
在R中,缺失值以符号NA表示。
同样我们也可以使用赋值语句将某些值重新编码为缺失值,例如一些问卷中,年龄值被编码为99,在分析这一数据集之前,必须让R明白本例中的99表示缺失值。例如:
> dataframe $ age [ dataframe $ age == 99 ] NA
任何等于99的年龄值都将被修改为NA。在进行数据分析前,要确保所有的缺失数据被编码为缺失值,否则分析结果将失去意义。
(2)缺失数据的探索与检验
R提供了一些函数,用于识别包含缺失值的观测。函数is.na ( ) 检测缺失值是否存在。假设你有一个向量:
> y 1 , 2 , 3 , NA )
然后使用函数:
> is.na ( y )
将返回 c ( FALSE , FALSE , FALSE , TRUE )。
complete.cases()函数可用来识别矩阵或数据框的行是否完整的,也就是有无缺失值,返回结果是逻辑值,以行为单位返回识别结果。如果一行中不存在缺失值,则返回TRUE;若行中有一个或多个缺失值,则返回FALSE。由于逻辑值TRUE和FALSE分别等价于数值1和0,可用sum()和mean()来计算关于完整数据的行数和完整率。以VIM包中的sleep数据为例:
> data ( sleep , package = "VIM" ) # 读取VIM包中的sleep数据
> sleep [ ! complete.cases ( sleep ) , ] # 提取sleep数据中不完整的行
BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger1 6654.000 5712.0 NA NA 3.3 38.6 645 3 5 33 3.385 44.5 NA NA 12.5 14.0 60 1 1 14 0.920 5.7 NA NA 16.5 NA 25 5 2 313 0.550 2.4 7.6 2.7 10.3 NA NA 2 1 214 187.100 419.0 NA NA 3.1 40.0 365 5 5 519 1.410 17.5 4.8 1.3 6.1 34.0 NA 1 2 120 60.000 81.0 12.0 6.1 18.1 7.0 NA 1 1 1
…..
> sum ( ! complete.cases ( sleep ) )
[1] 20
> mean ( complete.cases ( sleep ) )
[1] 0.6774194
结果列出了20个含有一个或多个缺失值的观测值,并有67.7%的完整实例。
(3)缺失数据的处理
(a)行删除:可以通过函数 na.omit()移除所有含缺失值的观测。na.omit()可以删除所有含有缺失数据的行。
> newsleep
删除缺失值后,观测值变为42个。
行删除法假定数据是MCAR(即完整的观测值只是全数据集的一个随机样本)。此例中则为42个实例为62个样本的一个随机子样本。
如果缺失比例比较小的话,该方法简单有效。但这种方法却有很大的局限性。直接删除有点简单而暴力,以减少样本量来换取信息的完备,可能会丢弃了一些有用的信息。在本身样本量较小的情况下,直接删除缺失值会影响到数据的客观性和分析结果的正确性。
(b)均值插补法(Mean Imputation):如果缺失数据是数值型的,根据该变量的平均值来填充缺失值;如果缺失值是非数值型的,就根据该变量的众数填充缺失值。
均值插补法是一种简便、快速的缺失数据处理方法。使用均值替换法插补缺失数据,对该变量的均值估计不会产生影响。但该方法是建立在完全随机缺失的假设之上的,当缺失比例较高时会低估该变量的方差。同时,这种方法会产生有偏估计。
(c)多重插补(Multiple Imputation,MI):在面对复杂的缺失值问题时,MI是最常用的方法,它将从一个包含缺失值的数据集中生成一组完整的数据集。每个模拟的数据集中,缺失数据将用蒙特卡洛方法来填补。由于多重插补方法并不是用单一值来替换缺失值,而是试图产生缺失值的一个随机样本,反映出了由于数据缺失而导致的不确定。R中的mice包可以用来多重插补。
> library ( mice )
> data ( sleep , package = "VIM" )
> imp 5, seed = 6666 )
iter imp variable1 1 NonD Dream Sleep Span Gest1 2 NonD Dream Sleep Span Gest1 3 NonD Dream Sleep Span Gest1 4 NonD Dream Sleep Span Gest1 5 NonD Dream Sleep Span Gest2 1 NonD Dream Sleep Span Gest2 2 NonD Dream Sleep Span Gest
…………
> fit > pooled > summary ( pooled )
est se t df Pr(>|t|)
(Intercept) 2.567686376 0.285838016 8.9830122 35.85560 1.042952e-10
Span -0.004053181 0.013236038 -0.3062231 43.05292 7.609108e-01
Gest -0.003842965 0.001698092 -2.2631079 35.17917 2.990444e-02
lo 95 hi 95 nmis fmi lambda
(Intercept) 1.987898937 3.1474738156 NA 0.2089325 0.1660046
Span -0.030745247 0.0226388849 4 0.1549945 0.1166313
Gest -0.007289647 -0.0003962828 4 0.2143316 0.1708996
其中,imp是包含m个插补数据集的列表对象,m默认为5,exp是一个表达式对象,用来设定应用于m个插补数据集的统计分析方法,例如线性回归模型的lm()函数、广义线性模型的glm()函数,做广义可加模型的gam()等。fit是一个包含m个单独统计分析结果的列表对象。pooled是一个包含这m个统计分析平均结果的列表对象。
2、处理噪声数据数据噪声是指数据中存在的随机性错误或偏差,产生的原因很多。噪声数据的处理方法通常有分箱、聚类分析和回归分析等,有时也会将与人的经验判断相结合。
分箱是一种将数据排序并分组的方法,分为等宽分箱和等频分箱。所谓等宽分箱,是用同等大小的格子来将数据范围分成N个间隔,箱宽为![]() 。等宽分箱比较直观和容易操作,但是对于偏态分布的数据,等宽分箱并不是太好,因为可能出现许多箱中没有样本点的情况。所谓等频分箱是将数据分成N个间隔,每个间隔包含大致相同的数据样本个数,这种分箱方法有着比较好的可扩展性。将数据分箱后,可以用箱均值、箱中位数和箱边界来对数据进行平滑,平滑可以在一定程度上削弱离群点对数据的影响。
。等宽分箱比较直观和容易操作,但是对于偏态分布的数据,等宽分箱并不是太好,因为可能出现许多箱中没有样本点的情况。所谓等频分箱是将数据分成N个间隔,每个间隔包含大致相同的数据样本个数,这种分箱方法有着比较好的可扩展性。将数据分箱后,可以用箱均值、箱中位数和箱边界来对数据进行平滑,平滑可以在一定程度上削弱离群点对数据的影响。
聚类分析处理噪声数据是指先对数据进行聚类,然后使用聚类结果对数据进行处理,如舍弃离群点、对数据进行平滑等。类似于分箱,可以采用中心点平滑、均值平滑等方法来处理。
回归分析处理噪声数据是指对于利用数据建立回归分析模型,如果模型符合数据的实际情况,并且参数估计是有效的,就可以使用回归分析的预测值来代替数据的样本值,降低数据中的噪声和离群点的影响。
数据变换数据变换包括平滑、聚合、泛化、规范化、属性和特征的重构等操作。下面将具体介绍这些操作。
1、数据平滑 数据平滑指的是将噪声从数据中移出,前文已经讲过,这里就不再赘述。 2、数据聚合 数据聚合指的是将数据进行汇总,以便于对数据进行统计分析。 3、数据泛化 数据泛化是将数据在概念层次上转化为较高层次的概念的过程。例如,将分类替换为其父分类。数据泛化的主要目的是减少数据的复杂度。 4、数据规范化 数据规范化的常用方法有:(1)标准差标准化
所谓标准差标准化是将变量的各个记录值减去其平均值,再除以其标准差,即

其中, 是均值,
是均值, 是标准差。
是标准差。
经过标准差标准化处理后的数据的平均值为0,标准差为1。
(2)极差标准化
极差标准化是将各个记录值减去记录值的平均值,再除以记录值的极差,即
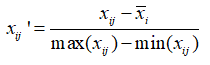
经过极差标准化处理后的数据的极差等于1。
(3)极差正规化
极差正规化将各个记录值减去记录值的极小值,再除以记录值的极差,极差正规化后的数据取值范围在区间![]() 之内,即
之内,即

(4)最小-最大规范化
最小-最大规范化把所有的数据转化到我们新设定的最小值和最大值的区间内,即
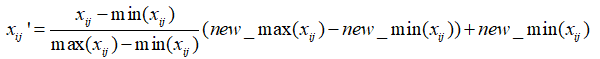
对于时间序列数据,我们还有两个常用的数据转换方法,即分别计算数据的差值和比值。所谓数据差值,是用![]() 的相对改动来代替
的相对改动来代替![]() 。而数据比值是采用
。而数据比值是采用 的相对改动来代替
的相对改动来代替![]() 。
。
对于数据预处理的基本函数,比如数据集合并merge()、数据筛选subset()等,请参考方匡南等(2015)《R数据分析》。本节将主要介绍R中的dplyr包,该包作者是 Hadley Wickham,他将原本plyr 包中的ddply()等函数进一步分离强化,专注接受dataframe对象,大幅提高了速度,并且提供了更稳健的与其他数据库对象间的接口。其可以非常灵活、快速实现数据的清洗和整理。下面主要以R中rpart包中的car90数据集为例进行示范。
1、数据集的基本操作由于dplyr包是用C语言开发的,处理tbl(表格)对象非常迅速,因此在使用dplyr包做数据预处理时,可以使用tbl_df()函数将原数据转换为tbl对象。
> library ( dplyr )
> library ( rpart ) #需要载入rpart包中的car90数据集
> data ( car90 )
> car90_df
(1)记录筛选
如果需要对数据集按某些逻辑条件进行筛选得到符合要求的记录,可以用filter()函数。例如,分别筛选出产自日本的中型车数据和产自日本或美国的汽车数据:
> filter ( car90_df , Country == "Japan" , Type == "Medium" ) # 且的关系
> filter ( car90_df , Country == "Japan" | Country == "USA" ) # 或的关系
此外filter.all(),filter.if(),filter.at()函数跟all_vars()和any_vars()等结合起来实现更强大的记录筛选功能。比如要筛选car90_df数据集中所有变量值都大于100的:
> filter_all ( car90_df , all_vars (.> 100 ) )
或者筛选car90_df数据集中任一变量值都大于100的:
> filter_all ( car90_df , any_vars ( .> 100 ) )
如果需要选取数据集中的部分行,则可以使用slice()函数。例如,选取car90_df数据中的前20行:
> slice ( car90_df , 1 : 20 )
dplyr包还可以实现从数据集中随机地抽取样本,在建模时,当需要把样本随机划分训练集和测试集时这个包就很有用。比如:
> sample_n ( car90_df , 20 ) # 随机从数据集中选取20个样本
> sample_frac ( car90_df , 0.2 ) # 随机从数据集中选取20%的样本
> sample_frac ( car90_df , 2 , replace = TRUE ) # 重复抽样选取2倍的样本
arrange()函数可以实现按给定的列名依次对行进行排序。例如,按产国和汽车类型的顺序将car_df数据集重新进行升序排序:
> arrange ( car90_df , Country , Type )
对列名加desc()可按该列进行倒序排序:
> arrange ( car90_df , desc ( Weight ) )
如果想选择部分列构建子数据集,可以用dplyr包中的select()函数。这个函数是用列名作参数来选择子数据集,可以用“:”来连接列名,就是把列名当作数字一样使用,还可以用“-”来排除列名。例如:选择car90_df数据集中Country、Disp、Disp2和Eng.Rev这四列数据,选择从Country到Eng.Rev的所有数据,删除从Country到Eng.Rev的所有数据:
> select ( car90_df , Country , Disp , Disp2 , Eng.Rev )
> select ( car90_df , Country : Eng.Rev ) # 筛选出Country到Eng.Rev的列
> select ( car90_df , - ( Country : Eng.Rev ) ) # 剔除Country到Eng.Rev的列
另外,比如对iris数据集petal开头的两列都筛选出来,或者width结果的两列都筛选出来:
> select ( iris , starts_with ( "Petal" ) ) # 选择以petal字符开头的变量
Petal.Length Petal.Width1 1.4 0.22 1.4 0.23 1.3 0.2
> select ( iris , ends_with ( "Width" ) ) # 选择以Width字符结尾的变量
Sepal.Width Petal.Width1 3.5 0.22 3.0 0.23 3.2 0.2
> select ( iris , matches ( ".t." ) ) # 正则表达式匹配,返回变量名中包含t的列
Sepal.Length Sepal.Width Petal.Length Petal.Width1 5.1 3.5 1.4 0.22 4.9 3.0 1.4 0.23 4.7 3.2 1.3 0.2
此外,contains ( x )选择所有包含x的变量,matches ( x )选择匹配正则表达式的变量,num_range ( 'x' , 1 : 5 , width = 2 )选择x01到x05的变量。
(4)数据变形
对已有的列进行数据运算并添加为新列,可以使用mutate()函数,并且mutate()函数可以在同一语句中对刚增加的列进行操作。比如计算手动变速器和自动变速器齿轮转动比的差(Gear.Ratio-Gear2):
> mutate ( car90_df , diff = Gear.Ratio - Gear2 )
(5)汇总操作
dplyr包中的summarise()函数可以对调用了其他函数所执行的操作进行汇总,返回一个一维的结果,例如:
> summarise ( car90_df , a = n_distinct ( Country ) , b = mean ( Price , na.rm = TRUE ) ,
c = max ( Luggage ) )
summarise()跟mean(),median(),sd(),quantile()等函数结合起来,可以返回想要的汇总数据。
(6)数据分组
在dplyr包中,有一个很好用的功能就是可以用group_by()函数对数据集进行分组操作,当对数据集通过group_by ( )添加了分组信息后,mutate()、arrange()和summarise()函数会自动对这些 tbl 类数据执行分组操作。例如,对car90_df数据集按汽车类型(Type)进行分组,计算不同类型汽车数(count = n ( ))和平均价格(meanprice = mean ( Price , na.rm = TRUE )):
> cars > analysis TRUE ) )
> analysis2 5 , meanprice 10000 )
dplyr包中用rename()函数实现对变量的重命名,例如:
> rename ( car90_df , Eng_Rec = Eng.Rev )
此外,重命名函数还有rename_all(),rename_at(),rename_if()。
(8)其他小函数
dplyr包中还提供了一些有用的小函数,如表2所示。
表2 dplyr包中有用的小函数

但是,这些小函数可以跟summarise()、mutate()和filter()等函数结合使用,例如:
> summarise ( car90_df , a = n_distinct ( Country ) )
(9)管道函数
dplyr包中有一个特有的管道函数(pipe function),即通过%>%将上一个函数的输出作为下一个函数的输入,就像管道输送一样,因为被称为管道函数,这种方法可以大大提高程序的运行速度,并简化程序代码。例如对car90_df数据,需要对其按汽车类型进行分组,分组后筛选出Price , Weight两列变量,并分别计算这两个变量的均值,可以用如下程序:
> car90_df %>%
group_by ( Type ) %>%
select ( Price , Weight ) %>%
summarise ( meanprice = mean ( Price , na.rm = TRUE ) ,
meanweight = mean ( Weight , na.rm = TRUE ) )
返回结果:# A tibble: 7 x 3
Type meanprice meanweight 1 Compact 14395.368 2818.6842 Large 21499.714 3750.0003 Medium 22750.154 3327.6924 Small 7736.591 2250.227
….
2、数据集间的操作
dplyr包中用inner_join()、left_join()、right_join()和full_join()实现两个数据集间的内连接、左连接、右连接和全连接操作。用semi_join ( x , y , by = "x1" )实现返回x中的与y匹配的行,用anti_join ( x , y , by = "x1" )实现返回x中的不与y匹配的行。另外,用bind_rows ( x , y )将数据集y按行拼接到数据集x中,用bind_cols ( x , y )将数据集y按列拼接到数据集x中。比如dplyr包有两个数据集band_members和band_instruments:
> band_members# A tibble: 3 x 2
name band 1 Mick Stones2 John Beatles3 Paul Beatles
> band_instruments# A tibble: 3 x 2
name plays 1 John guitar2 Paul bass3 Keith guitar
> left_join ( band_members , band_instruments ) # 按第一个数据集的ID匹配合并
Joining, by = "name"# A tibble: 3 x 3
name band plays 1 Mick Stones
> band_members %>% right_join ( band_instruments ) # 按第二个数据集ID匹配合并
Joining, by = "name"# A tibble: 3 x 3
name band plays 1 John Beatles guitar2 Paul Beatles bass3 Keith
> band_members %>% full_join ( band_instruments )#按两个数据集ID的并集匹配合并
Joining, by = "name"# A tibble: 4 x 3
name band plays 1 Mick Stones
3、连接数据库数据
dplyr包可以直接访问数据库中的数据,利用src_mysql()函数可以获取MySQL数据库中的数据,其功能类似于RMySQL包。其语法如下:
src_mysql ( dbname , host = NULL , port = 0L , user = "root" , password = " " )
连接MySQL数据库后,使用tbl()函数获取数据集,tbl()函数语法为:
tbl ( src , from , ... ),其中,src为src_mysql()函数对象,from为SQL语句。
一个具体例子如下:
> my_db "blah.com" , user = "hadley" , password = "pass" )
> my_tbl "my_table" )
—END—
