《动手学深度学习》task2——文本预处理,语言模型,循环神经网络基础笔记
系统学习《动手学深度学习》点击这里:
《动手学深度学习》task1_1 线性回归
《动手学深度学习》task1_2 Softmax与分类模型
《动手学深度学习》task1_3 多层感知机
《动手学深度学习》task2_1 文本预处理
《动手学深度学习》task2_2 语言模型
《动手学深度学习》task2_3 循环神经网络基础
笔记目录
-
- 1 文本预处理
-
-
- 1.1 关于建立词典
- 1.2 关于在词典中的pad,bos, eos, unk
- 1.3 关于用现有工具进行分词
- 1.4 关于正则表达式
-
- 2 语言模型
-
-
- 2.1 n-gram
- 2.2 统计语言模型——n-gram模型的缺陷
- 2.3 关于one-hot编码
- 2.4 随机采样和相邻采样的区别:
-
- 3 循环神经网络
-
-
- 3.1 关于创建RNN模型,当前的最大预测字符
- 3.2 关于裁剪梯度
- 3.3 关于语言模型评价指标(perplexity)
- 3.4 关于困惑度
- 3.5 关于RNN模型训练函数
- 3.6 相邻采样为什么在每次迭代之前都需要将参数detach
- 3.7 其他的一些tips
- 3.8 反向传播、梯度消失、梯度爆炸
-
- 4 RNN的简洁实现
-
-
- 4.1 Pytorch中的RNN的实现
-
1 文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
1.1 关于建立词典
这里是对Vocab类实现的理解,首先是这个类想干什么?
Vocab类想实现将词映射成一个索引,既然是索引那么相同的词就应该具有相同的索引,所以这里对于输入的文本还会进行一个去重的操作。
此外,Vocab还想方便的获取给定某个词对应的索引,以及给定一个索引获取这个索引所对应的词。除了上面说的两个功能,还有一个就是
统计了每一个词的词频。
代码部分主要是由几个列表的复杂操作,理解了那几行代码,应该就能完全看懂代码在干什么了。
1.2 关于在词典中的pad,bos, eos, unk
- pad的作用是在采用批量样本训练时,对于长度不同的样本(句子),对于短的样本采用pad进行填充,使得每个样本的长度是一致的
- bos( begin of sentence)和eos(end of sentence)是用来表示一句话的开始和结尾
- unk(unknow)的作用是,处理遇到从未出现在预料库的词时都统一认为是unknow ,在代码中还可以将一些频率特别低的词也归为这一类
1.3 关于用现有工具进行分词
前面的分词方式非常简单,它至少有以下几个缺点:
- 标点符号通常可以提供语义信息,但是我们的方法直接将其丢弃了
- 类似“shouldn’t", "doesn’t"这样的词会被错误地处理
- 类似"Mr.", "Dr."这样的词会被错误地处理
我们可以通过引入更复杂的规则来解决这些问题,但是事实上,有一些现有的工具可以很好地进行分词,我们在这里简单介绍其中的两个:spaCy和NLTK。
家里网太差了,这两个包下载不了,等网好了再实验
1.4 关于正则表达式
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
# 上面这行代码的正则部分为
re.sub('[^a-z]+', ' ', str)
# re.sub()函数是用来字符串替换的函数
# '[^a-z]+' 注意这里的^是非的意思,就是说非a-z字符串,+表示1个或多个
# 上面句子的含义是:将字符串str中的非小写字母开头的字符串以空格代替
正则表达式推荐链接:https://blog.csdn.net/qq_41185868/article/details/96422320#3%E3%80%81%E6%A3%80%E7%B4%A2%E5%92%8C%E6%9B%BF%E6%8D%A2
2 语言模型
2.1 n-gram
N N N元语法是基于 n − 1 n-1 n−1阶马尔可夫链的概率语言模型,其中 n n n权衡了计算复杂度和模型准确性
语言模型可用于提升语音识别和机器翻译的性能。例如,在语音识别中,给定一段“厨房里食油用完了”的语音,有可能会输出“厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。如果语言模型判断出前者的概率大于后者的概率,我们就可以根据相同读音的语音输出“厨房里食油用完了”的文本序列。在机器翻译中,如果对英文“you go first”逐词翻译成中文的话,可能得到“你走先”“你先走”等排列方式的文本序列。如果语言模型判断出“你先走”的概率大于其他排列方式的文本序列的概率,我们就可以把“you go first”翻译成“你先走”。
2.2 统计语言模型——n-gram模型的缺陷
-
参数空间过大
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) . P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3). P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).
假设计算 P ( w 1 ) P(w_1) P(w1) 需要的参数空间为v,则上述式子需要的总参数空间为v + v^2 + v^3 + v^4
-
数据稀疏
齐夫定律:在自然语言的语料库中,一个单词出现的频率与它在频率表中的排名成反比,表明大部分单词出现的频率会很小,甚至不会出现,这就会出现概率估计不准确的问题,比如「荸荠」这个单词,很可能在我们所给的数据集中不会出现,所以他的频率为0,但是我们可以确定,他真的在真实世界中是不会出现的单词么?
如果使用n元语法模型存在数据稀疏问题,最终计算出来的大部分参数都为0
2.3 关于one-hot编码
"""
n_class,x为索引,比如x = torch.tensor([0, 2]),x.shape = (n, class),
词典大小为n,向量的长度等于词典的大小
"""
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
# print(x.long())
# print('x.long().view(-1, 1)', x.long().view(-1, 1))
# result[i][x[i][j]] = 1
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
scatter_()函数:
scatter() 和 scatter_() 的作用是一样的,只不过 scatter() 不会直接修改原来的 Tensor,而 scatter_() 会
PyTorch 中,一般函数加下划线代表直接在原来的 Tensor 上修改
scatter(dim, index, src) 的参数有 3 个
- **dim:**沿着哪个维度进行索引
- **index:**用来 scatter 的元素索引
- **src:**用来 scatter 的源元素,可以是一个标量或一个张量
这个 scatter 可以理解成放置元素或者修改元素
简单说就是通过一个张量 src 来修改另一个张量,哪个元素需要修改、用 src 中的哪个元素来修改由 dim 和 index 决定
官方文档给出了 3维张量 的具体操作说明,如下所示
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
详细解析见此链接
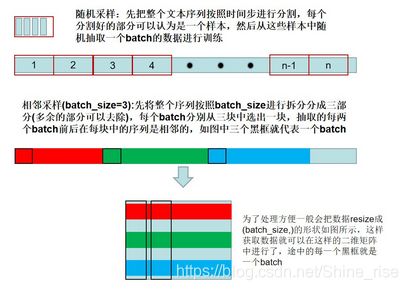
2.4 随机采样和相邻采样的区别:
-
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相毗邻。因此,我们无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态。在训练模型时,每次随机采样前都需要重新初始化隐藏状态。
-
在相邻采样中,用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网络造成了两方面影响:一方面,
在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状态;另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。
为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将隐藏状态从计算图中分离出来
3 循环神经网络
循环神经网络的参数包括隐藏层的权重 W x h ∈ R d × h \boldsymbol{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h、 W h h ∈ R h × h \boldsymbol{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h和偏差 b h ∈ R 1 × h \boldsymbol{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及输出层的权重 W h q ∈ R h × q \boldsymbol{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q和偏差 b q ∈ R 1 × q \boldsymbol{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q。值得一提的是,即便在不同时间步,循环神经网络也始终使用这些模型参数。因此,循环神经网络模型参数的数量不随时间步的增加而增长。
- W_xh: 状态-输入权重
- W_hh: 状态-状态权重
- W_hq: 状态-输出权重
- b_h: 隐藏层的偏置
- b_q: 输出层的偏置
循环神经网络的参数就是上述的三个权重和两个偏置,并且在沿着时间训练(参数的更新),参数的数量没有发生变化,仅仅是上述的参数的值在更新。循环神经网络可以看作是沿着时间维度上的权值共享
在卷积神经网络中,一个卷积核通过在特征图上滑动进行卷积,是空间维度的权值共享。在卷积神经网络中通过控制特征图的数量来控制每一层模型的复杂度,而循环神经网络是通过控制W_xh和W_hh中h的维度来控制模型的复杂度。
3.1 关于创建RNN模型,当前的最大预测字符
if i < (len(prefix) - 1):
output.append(char_to_idx[prefix[i+1]])
else:
output.append(int(Y[0].argmax(dim=1).item()))
argmax函数:torch.argmax(input, dim=None, keepdim=False)返回指定维度最大值的序号,dim给定的定义是:the demention to reduce.也就是把dim这个维度的,变成这个维度的最大值的index。例如:
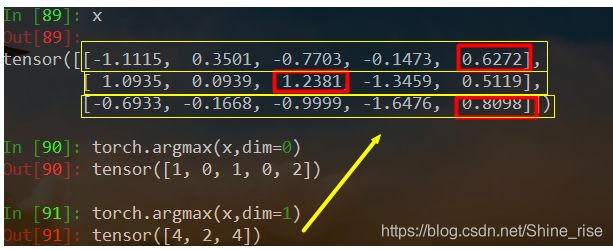
torch.argmax(x, dim=0),取每一列的数据的最大值,返回行序号
torch.argmax(x, dim=1),取每一行的数据的最大值,返回列序号
3.2 关于裁剪梯度
循环神经网络中较容易出现梯度衰减或梯度爆炸。为了应对梯度爆炸,我们可以裁剪梯度(clip gradient)。假设我们把所有模型参数梯度的元素拼接成一个向量 g \boldsymbol{g} g,并设裁剪的阈值是 θ \theta θ。裁剪后的梯度
min ( θ ∥ g ∥ , 1 ) g \min\left(\frac{\theta}{\|\boldsymbol{g}\|}, 1\right)\boldsymbol{g} min(∥g∥θ,1)g
的 L 2 L_2 L2范数不超过 θ \theta θ。
先计算所有参数的梯度的L2范数,然后与theta比较,如果大于theta,就乘以这个系数
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
3.3 关于语言模型评价指标(perplexity)
语言模型(Language Model,LM),给出一句话的前k个词,希望它可以预测第k+1个词是什么,即给出一个第k+1个词可能出现的概率的分布p(xk+1|x1,x2,…,xk)。
PPL是用在自然语言处理领域(NLP)中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize,公式为
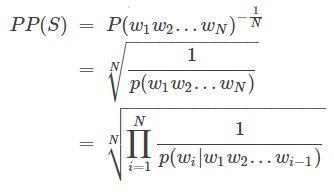
S代表sentence,N是句子长度,p(wi)是第i个词的概率。第一个词就是 p(w1|w0),而w0是START,表示句子的起始,是个占位符。
详细见链接
3.4 关于困惑度
困惑度是对交叉熵损失函数做指数运算后得到的值。特别地,
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。
3.5 关于RNN模型训练函数

当我们再训练网络的时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整;或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,这时候我们就需要使用detach()函数来切断一些分支的反向传播
detach()
返回一个新的Variable,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个Variable永远不需要计算其梯度,不具有grad。 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad .这样我们就会继续使用这个新的Variable进行计算,后面当我们进行反向传播时,到该调用detach()的Variable就会停止,不能再继续向前进行传播
detach_()
将一个Variable从创建它的图中分离,并把它设置成叶子variable .其实就相当于变量之间的关系本来是x -> m -> y,这里的叶子variable是x,但是这个时候对m进行了.detach_()操作,其实就是进行了两个操作:
1.将m的grad_fn的值设置为None,这样m就不会再与前一个节点x关联,这里的关系就会变成x, m -> y,此时的m就变成了叶子结点。
2.然后会将m的requires_grad设置为False,这样对y进行backward()时就不会求m的梯度。
其实detach()和detach_()很像,两个的区别就是detach_()是对本身的更改,detach()则是生成了一个新的variable 。比如x -> m -> y中如果对m进行detach(),后面如果反悔想还是对原来的计算图进行操作还是可以的 。但是如果是进行了detach_(),那么原来的计算图也发生了变化,就不能反悔了。
详细见解析
3.6 相邻采样为什么在每次迭代之前都需要将参数detach
(下面为小罗同学的回答,觉得写的很好就引用了~)
是因为pytorch动态计算图构建的原因,这里主要结合本次的视频内容(循环神经网络使用相邻采样时)
分享自己的理解,下图是知乎上找到的,需要详细了解pytorch动态图相关的东西可以看下面给出
的参考链接
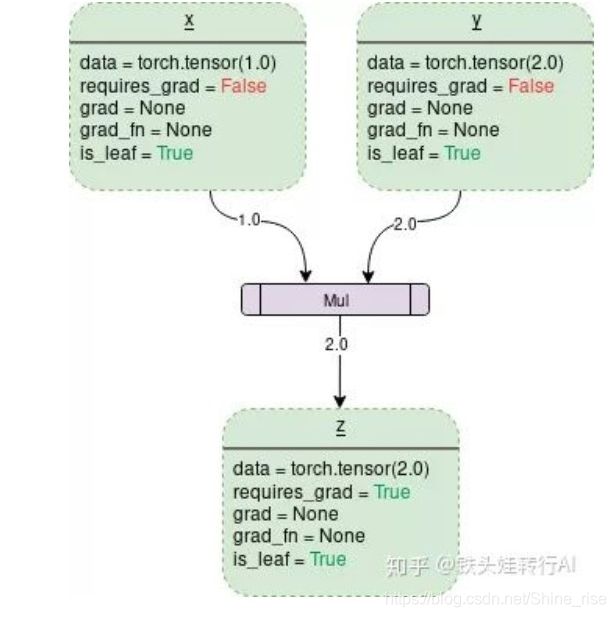
从上图可以看出,一个动态图是从叶子节点到叶子节点的一张图,如上图中的输入是x,y,输出是z.但是
需要注意的是,输入的叶子节点其中有个参数requires_grad = False, 而最后输出的叶子节点是
requires_grad = True. 当参数值为True的时候表示的是,该节点可以计算梯度,为False表示不能计算
节点梯度,而在反向传播的时候对于不可以计算梯度的节点可以认为是图反向传播的终点。
现在来理解一下循环神经网络使用相邻采样的时候为什么要detach参数。
我们知道相邻采样的前后两个批量的数据在在时间步上是连续的,所以模型会使用上一个批量的隐藏
状态初始化当前的隐藏状态,表现形式就是不需要在一个epoch的每次迭代时随机初始化隐藏状态,那么
根据上面所说的。假如没有detach的操作,每次迭代之后的输出是一个叶子节点,并且该叶子节点的
requires_grad = True(从上面的计算图就可以看出),也就意味着两次或者说多次的迭代,计算图一直都是连着
的,因为没有遇到梯度计算的结束位置,这样将会一直持续到下一次隐藏状态的初始化。所以这将会导致
计算图非常的大,进而导致计算开销非常大。而每次将参数detach出来,其实就是相当于每次迭代之后虽然是
使用上一次迭代的隐藏状态,只不过我们希望重新开始,具体的操作就是把上一次的输出节点的参数requires_grad
设置为False的叶子节点。
我们知道循环神经网络的梯度反向传播是沿着时间进行反向传播的,而时间是不会停止的,所以我们会每隔一段时间、
进行一次反向传播,而我们这里的一段时间其实指的就是时间步,我们希望每间隔时间步之后进行一次反向传播,这样
来减小在梯度反向传播时带来的计算开销以及一定程度上缓解梯度消失或者爆炸的问题
以上是我对循环神经网络使用相邻采样为什么要detach参数的理解,可能也有问题,如果有问题希望可以指出来
参考链接:https://zhuanlan.zhihu.com/p/79801410
3.7 其他的一些tips
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cYrdLQ2c-1581659037416)(task2.assets/1581591834774.png)]](http://img.e-com-net.com/image/info8/8ce2ffedbfbe4269985060a8d5b4db25.png)
transpose()函数:转置
contiguous()函数:
在PyTorch中,有一些对Tensor的操作不会真正改变Tensor的内容,改变的仅仅是Tensor中字节位置的索引。这些操作有:
narrow(), view(), expand(), transpose()
例如执行view操作之后,不会开辟新的内存空间来存放处理之后的数据,实际上新数据与原始数据共享同一块内存。
而在调用contiguous()之后,PyTorch会开辟一块新的内存空间存放变换之后的数据,并会真正改变Tensor的内容,按照变换之后的顺序存放数据。
3.8 反向传播、梯度消失、梯度爆炸
为什么会发生梯度爆炸和消失:
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。
梯度消失梯度爆炸的解决方案:
参考链接:https://zhuanlan.zhihu.com/p/76772734
https://zhuanlan.zhihu.com/p/44306077
(写的非常详细,值得多看)
4 RNN的简洁实现
使用Pytorch中的nn.RNN来构造循环神经网络。在本节中,我们主要关注nn.RNN的以下几个构造函数参数:
input_size- The number of expected features in the input xhidden_size– The number of features in the hidden state hnonlinearity– The non-linearity to use. Can be either ‘tanh’ or ‘relu’. Default: ‘tanh’batch_first– If True, then the input and output tensors are provided as (batch_size, num_steps, input_size). Default: False
这里的batch_first决定了输入的形状,我们使用默认的参数False,对应的输入形状是 (num_steps, batch_size, input_size)。
forward函数的参数为:
inputof shape (num_steps, batch_size, input_size): tensor containing the features of the input sequence.h_0of shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the initial hidden state for each element in the batch. Defaults to zero if not provided. If the RNN is bidirectional, num_directions should be 2, else it should be 1.
forward函数的返回值是:
outputof shape (num_steps, batch_size, num_directions * hidden_size): tensor containing the output features (h_t) from the last layer of the RNN, for each t.h_nof shape (num_layers * num_directions, batch_size, hidden_size): tensor containing the hidden state for t = num_steps.
4.1 Pytorch中的RNN的实现
- PyTorch的
nn模块提供了循环神经网络层的实现。 - PyTorch的
nn.RNN实例在前向计算后会分别返回输出和隐藏状态。该前向计算并不涉及输出层计算。