《 Recent Advances in Deep Learning-based Dialogue Systems 》:Neural Models in Dialogue Systems
关注微信公众号:NLP分享汇。【喜欢的扫波关注,每天都在更新自己之前的积累】

文章链接:https://mp.weixin.qq.com/s/vsEH5wj9Y5dShnH42hCX_Q
前言
本文将以2021年南洋理工大学发表的论文《Recent Advances in Deep Learning-based Dialogue Systems》为基础,介绍「深度学习对话系统」综述系列,共分七篇,本文是第二篇。本文较长,建议读者直接阅读感兴趣的部分。
开篇链接:2021深度学习对话系统大综述 [一]
本文简介
这篇文章介绍了在最先进的对话系统和相关子任务中流行的神经模型。我们还将讨论这些模型或其变体在现代对话系统研究中的应用,以使读者从模型的角度看一看。
该部分讨论包括:
-
Convolutional Neural Networks (CNNs)
-
Recurrent Neural Networks (RNNs)
-
Vanilla Sequence-tosequence Models
-
Hierarchical Recurrent Encoder-Decoder (HRED)
-
Memory Networks
-
Attention Networks and Transformer
-
Pointer Net and CopyNet
-
Deep Reinforcement Learning models
-
Knowledge Graph Augmented Neural Networks

一、Convolutional Neural Networks
原理:如何理解NLP中的图像?一文知悉TextCNN文本分类
CNN是很好的文本特征提取器,但它们可能不是理想的序列编码器。一些对话系统直接使用CNN作为编码器编码语言和知识[1、2、3],但是大多数历史最佳对话系统选择在编码文本信息之后使用CNN作为层次特征抽取器,代替直接应用CNN作为编码器[4、5、6、7、8、9、10、11、12]。这是由于CNN的固定输入长度和有限的卷积跨度。
通常,使用CNN来处理对话系统中编码信息有两种主流方法:
-
应用CNN抽取特征直接基于从编码器中得到的特征向量[7、8、9、10],这些工作中[9]从character-level embeddings中抽取特征,证明了CNN的层级抽取能力。
-
使用CNN的另一种情况是在响应检索任务中提取特征映射。一些工作建立了基于检索的对话系统[4、5、6、11]。他们使用单独的编码器对对话上下文和候选回应进行编码,然后将CNN用作从被编码的对话上下文和候选回应(responses)计算相似度矩阵的提取器。
总结
近几年较新的工作之所以不选择CNN作为对话编码器的主要原因是,它们无法连续,灵活地跨时间序列步骤提取信息。
二、Recurrent Neural Networks and Vanilla Sequence-to-sequence Models
注:我们将上述「本文简介」中的2、3部分和在一起讲。
相关神经网络原理
-
RNN:追根溯源:循环神经网络(Recurrent Neural Networks)
-
LSTM:长短期记忆网络 Long Short-Term Memory
-
GRU:GRU
-
Vanilla Sequence-to-sequence Models (Encoder-decoder Models):
Sutskever等人[13] 2014年首次提出了序列到序列模型来解决机器翻译任务。序列到序列模型旨在首先通过使用编码器将输入序列映射到中间向量,然后解码器基于中间向量和由解码器生成的历史来生成输入,从而将输入序列映射到输出序列。以下等式说明了编码器-解码器模型:
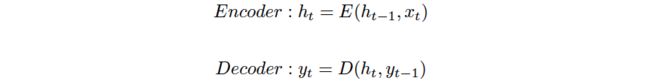
-
其中t是时间步长,h是隐藏矢量,y是输出矢量。E和D分别是编码器和解码器使用的顺序单元。编码器的最后一个隐藏状态是中间向量,该向量通常用于初始化解码器的第一个隐藏状态。在编码时,每个隐藏状态由上一个时间步长的隐藏状态和当前时间步长的输入决定,而在解码时,每个隐藏状态由当前的隐藏状态和前一个时间步长的输出决定。
-
该模型功能强大,因为它不局限于固定长度的输入和输出。相反,源序列和目标序列的长度可以不同。
-
RNN在神经对话系统中起着至关重要的作用,因为它们具有对顺序文本信息进行编码的强大能力。在许多对话系统中都可以找到RNN及其变体。
1、面向任务的系统(Task-oriented systems)将RNN用作对话上下文,对话状态,知识库条目和领域标签的编码器。
-
Opendialkg: Explainable conversational reasoning with attention-based walks over knowledge graphs.(ACL2019)
-
Semantically conditioned dialog response generation via hierarchical disentangled self-attention.(2019b)
-
Self-supervised dialogue learning. (2019b/a)
2、开放领域系统(Open-domain systems)应用RNN作为对话 历史信息编码器。
-
Do neural dialog systems use the conversation history effectively? an empirical study. (2019)
-
Boosting dialog response generation.(ACL2019)
-
Bridging the gap between prior and posterior knowledge selection for knowledge-grounded dialogue generation. (EMNLP2020)
3、基于检索的系统(retrieval-based systems)通过RNN一起建模对话历史信息和候选回复。
-
Retrieval-enhanced adversarial training for neural response generation. (2018)
-
Target-guided open-domain conversation.(2019)
-
Multi-hop paragraph retrieval for open-domain question answering.(2019)
-
Constructing interpretive spatio-temporal features for multi-turn responses selection. (ACL2019)
4、在以知识为基础的系统(knowledge-grounded systems)中,RNN是外部知识源(例如背景,角色,主题等)的编码器。
-
The dialogue dodecathlon: Open-domain knowledge and image grounded conversational agents. (2019)
-
Interview: Large-scale modeling of media dialog with discourse patterns and knowledge grounding. (EMNLP2020)
-
Bridging the gap between prior and posterior knowledge selection for knowledge-grounded dialogue generation.(EMNLP2020)
-
Grounding conversations with improvised dialogues.(2020)
在对话系统中,RNN通常通过greedy search或beam search来解码语言序列的隐藏状态。一些工作将RNN作为对话表示模型的一部分进行了组合,以训练对话embedding并进一步提高与对话相关的任务的性能。这些embedding模型针对对话任务进行了训练,并提供了更多的对话功能。当这些上下文表示模型未针对特定任务进行微调时,它们在某些对话任务中始终优于最新的上下文表示模型(例如BERT,ELMo和GPT)。
三、Hierarchical Recurrent Encoder-Decoder (HRED)
HRED is a context-aware sequence-to-sequence model
首次被提出[14]去解决上下文意识(context-aware)在线查询建议问题,它旨在意识历史查询,并且所提出的模型可以提供罕见的高质量结果。2016年Serban扩展HRED到对话领域中并且建立一个end-to-end的上下文意识对话系统。HRED在对话和end-to-end的问答中取得显著提升。这项工作比原始论文引起了更多的关注,因为对话系统是HRED应用程序的理想设置。传统的对话系统(Ritter等,2011[16])基于单轮消息生成了回应(responses),这牺牲了对话历史中的信息。Sordoni[17]将对话历史与窗口大小为3的组合作为一个序列到序列模型的输入,用于生成响应,这也是受限制的,因为它们仅以token-level对对话历史记录进行编码。对话的“turn-by-turn”特征表明turn-level信息也很重要。HRED学习了token-level和turn-level的表示,因此有机会去获取对话上下文意识。
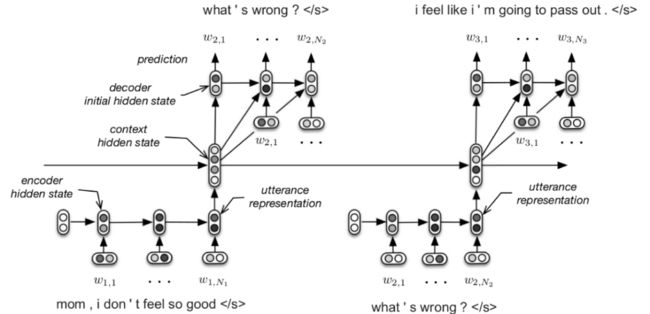
图1 The HRED model in a dialogue setting (Serban et al., 2016)
上图1为HRED的模型结构图,HRED用两个层次的RNN对token-level和turn-level序列进行分层建模:一个由编码器和解码器组成的token-level RNN和一个turn-level上下文RNN。编码器RNN将每一轮的话语逐个token编码为隐藏状态。然后在每个turn-level时间步长,将这种隐藏状态作为上下文RNN的输入。因此,turn-level上下文RNN迭代地跟踪历史话语。上下文RNN在第t轮的隐藏状态表示在第t轮上的话语的摘要,并用于初始化解码器RNN的第一个隐藏状态,这类似于序列到序列模型中的标准解码器[18]。上述三种rnn都采用GRU cells作为循环单元,并且每个话语的编码器和解码器参数都是共享的。
VHRED用对数似然的变分下界进行训练,生成的回应(responses)在多样性、长度和质量方面表现出了很好的改善。在解码阶段,为了便于解码,计算了编码器-解码器的注意力。
-
A hierarchical latent variable encoder-decoder model for generating dialogues.(AAAI2017)
该文更进一步提出了VHRED(Latent Variable Hierarchical Recurrent Encoder-Decoder)去建模序列之间复杂依赖。基于HRED,VHRED结合一个潜变量(latent variable)至解码器中,并且将解码过程转换为两步生成过程:
-
1、sampling a latent variable;
-
2、然后有条件地生成响应。
-
-
Recosa: Detecting the relevant contexts with self-attention for multi-turn dialogue generation.(2019)
许多在对话相关任务上的近期工作应用基于HRED框架去抓取层级对话特征。该文认为标准HRED系统不分青红皂白地处理对话历史中的所有语境。受Transformer的启发,他们提出ReCoSa,一个基于self-attention的层级模型。该方法首次应用LSTM去编码token-level信息到上下文隐藏向量中,然后为上下文向量(context vectors)和被遮掩的回应向量(masked response vectors)计算self-attention。
-
Modeling semantic relationship in multi-turn conversations with hierarchical latent variables.(2019)
该文提出一个由3层次组成的层级模型:1、discourse-level抓取全局知识;2、pair-level抓取话语对中的话题信息;3、utterance level抓取文本信息。这样的多层次结构有助于其在多样性,连贯性和流畅性方面得到更高质量响应。
-
Ordinal and attribute aware response generation in a multimodal dialogue system.(ACL2019)
该文应用HRED和VGG-19作为多模态HRED(MHRED)。HRED对层次对话上下文进行编码,而VGG-19提取相应论数中所有图像的视觉特征。随着位置感知注意机制(position-aware attention)的加入,该模型在视觉背景下表现出更加多样和准确的回应。
-
Pretraining methods for dialog context representation learning.(2019)
该文通过四个子任务学习对话上下文表示,其中三种(下一话语生成next-utterance generation、掩蔽话语检索masked-utterance retrieval和不一致性识别inconsistency identification)采用了HRED作为上下文编码,并取得了良好的性能。
-
Observing dialogue in therapy:Categorizing and forecasting behavioral codes.(2019)
该文使用HRED编码治疗师和患者之间的对话历史,对治疗师和患者MI行为代码进行分类,并预测未来代码。
-
Structured attention for unsupervised dialogue structure induction.(2020)
该文应用基于lstm的VHRED以无监督方式解决了双智能体(two-agent)和多智能体(multi-agent)对话结构归纳问题。在此基础上,他们将条件随机场模型应用于双智能体对话中,将非投影依赖树(non-projective dependency tree)应用于多智能体对话中,两者在对话结构建模方面都取得了较好的效果。
四、Memory Networks
原理:神经网络中的人脑海马体:Memory Networks
1、许多与对话相关的工作将记忆网络纳入其框架,特别是涉及外部知识库的任务,如面向任务的对话系统、基于知识的对话系统和QA。
-
A working memory model for task-oriented dialog response generation.(ACL2019)
认为最先进的面向任务的对话系统倾向于将对话历史和知识库条目合并到一个单一的记忆模块中,从而影响了响应质量。他们提出了一种面向任务的系统,该系统由三个记忆模块组成:两个长期记忆模块分别存储对话历史和知识库;一种工作记忆模块,它记忆两个分布并控制最后的单词预测。
-
Amalgamating knowledge from two teachers for task-oriented dialogue system with adversarial training.(EMNLP2020)
提出以“两老师一学生”的框架训练任务导向对话系统,以提高他们记忆网络的知识检索和回应质量。他们首先训练了两个教师网络,分别使用强化学习和互补目标特定的奖励函数(complementary goal-specific reward functions)。然后使用GAN框架,他们训练了两个鉴别器,教学生记忆网络产生类似于老师的回应,将两名老师的专家知识传递给学生。优点是这种训练框架只需要弱监督,学生网络可以受益于教师网络的互补目标。
-
Efficient dialogue state tracking by selectively overwriting memory. (2019)
解决了面向任务的对话系统的对话状态跟踪问题。与其他工作不同的是,它们并没有从头开始更新内存模块中的所有对话状态。相反,他们的模型首先预测需要更新的状态,然后覆盖目标状态。通过有选择地覆盖内存模块,提高了对话状态跟踪任务的效率。
-
Learning to abstract for memory-augmented conversational response generation.(ACL2019)
提出了一种基于知识的聊天系统。一个内存网络用于存储查询-回应对(query-response pairs),在回应生成阶段,生成器生成基于输入查询和存储对的回应。它从内存中的查询-回应对中提取键-值信息,并将其组合为token预测。
-
Neural response generation with metawords. (2019)
提出在开放域系统中使用元词(meta-words)以一种可控的方式生成回应。元词是描述回应属性的短语。使用目标跟踪记忆网络,他们记住了元词,并根据用户的信息生成回应,同时合并元词。
-
Multi-step reasoning via recurrent dual attention for visual dialog.(2019)
以对话历史记忆模块和视觉记忆模块为条件执行多步推理。两个内存模块周期性地改进表示,以执行下一个推理过程。实验结果表明,将图像线索与对话线索相结合可以提高视觉对话系统的性能。
-
Episodic memory reader: Learning what to remember for question answering from streaming data.(2019)
训练一个强化学习agent,在内存模块满时决定替换哪个内存向量,以提高基于文档的问答任务的准确性和效率。他们通过学习每个内存对应的查询特定值来解决内存网络的可伸缩性问题。
-
Explicit memory tracker with coarse-to-fine reasoning for conversational machine reading.(ACL2020)
在对话式机器阅读任务中解决了同样的问题。他们提出了一个显式内存跟踪器(EMT)来决定内存中提供的信息是否足以进行最终预测。此外,还采用了一种由粗到细的策略,使代理提出澄清问题,以请求额外的信息和细化推理。
五、Attention Networks and Transformer
原理:Attention and Transformer
Attention 和 Transformer无疑是最近对话系统研究中最受欢迎的架构。
1、注意力是捕捉目标序列中不同部分重要性的工具。
-
Retrieval-enhanced adversarial training for neural response generation.(2018)
采用two-level attention生成单词。给定由检索系统选择的用户消息和候选响应,生成程序首先计算word-level的注意力权重,然后使用sentence-level的注意力来调整权重。这种two-level attention有助于生成器捕捉到给定编码上下文的不同重要性。
-
Vocabulary pyramid network: Multi-pass encoding and decoding with multi-level vocabularies for response generation. (ACL2019)
使用基于注意力的循环架构来生成响应。他们设计了一种多级编码器-解码器(multi-level encoder-decoder),多级编码器试图将原始单词(raw words)、低级聚类(low-level clusters)和高级聚类(high-level clusters)映射到分层嵌入式表示(hierarchical embedded representations)中,而多级解码器则使用注意力来利用分层表示,然后生成响应。在每个解码阶段,该模型为更高级别解码器的输出和当前级别编码器的隐藏状态计算两个注意力权值。
-
Semantically conditioned dialog response generation via hierarchical disentangled self-attention.(2019)
计算了对话行为预测器输出的多头自注意。与连接不同头输出的transformer不同,它们直接将输出传递到下一个多头层。然后堆叠的多头层生成带有对话的响应作为输入。
2、Transformer是强大的序列到序列模型,同时,它们的编码器也作为良好的对话表示模型。
-
Training neural response selection for task-oriented dialogue systems.(2019)
为面向任务的对话系统构建了基于transformer的响应检索模型。设计了一种双通道transformer编码器,用于编码用户消息和响应,这两种信息最初都以unigrams和bigrams的形式出现。然后应用简单余弦距离计算用户消息和候选响应之间的语义相似度。
-
Incremental transformer(2019)
构建了多个增量transformer编码器,对轮对话及其相关文档知识进行编码。编码的话语和前一轮的相关文档被视为下一轮transformer编码器输入的一部分。预训练的模型适用于多个领域,只需要目标领域的少量数据。
-
Plato: Pre-trained dialogue generation model with discrete latent variable.(2019)
使用堆叠transformers进行对话生成预训练。除了回复生成任务外,他们还和潜在行为预测任务一起进行了预训练。采用潜变量来解决响应生成中的“一对多”问题。多任务训练方案提高了transformer预训练模型的性能。
3、基于大型transformer的上下文表示模型适用于许多任务,因此在最近的研究中得到了广泛的应用。
-
Large-scale transfer learning for natural language generation.(ACL2019)
采用GPT作为序列到序列的模型直接生成话语,并比较了单输入和多输入条件下的性能。
-
Interview: Large-scale modeling of media dialog with discourse patterns and knowledge grounding.(EMNLP2020)
首先使用概率模型检索相关新闻语料库,然后将新闻语料库与对话上下文结合作为GPT-2生成器的输入进行响应生成。他们提出,将话语模式识别和疑问句类型预测作为多任务学习的两个子任务,可以进一步改进对话建模。
-
Proactive human-machine conversation with explicit conversation goals.(2019)
在基于目标的响应检索系统中,使用BERT作为上下文和候选响应的编码器。
-
Towards persona-based empathetic conversational models.(EMNLP2020)
构建基于bert的回复选择模型Co-BERT,在基于人物的训练语料下检索共情反应。
-
Knowledge-grounded dialogue generation with pre-trained language models.(2020)
以综合的方式构建了一个基于知识的对话系统。他们使用BERT和GPT-2共同进行知识选择和应答生成,其中BERT进行知识选择,GPT-2根据对话上下文和所选知识生成应答。
六、Pointer Net and CopyNet
原理:Pointer Net and CopyNet
复制机制(Copy mechanism)适用于涉及术语或外部知识来源的对话,是知识型或任务型对话系统中较为流行的对话机制。
1、对于基于知识的系统(knowledge-grounded systems),外部文档或对话是复制的来源。
-
Generating informative conversational response using recurrent knowledge-interaction and knowledge-copy.(ACL2020)
将循环知识交互解码器与知识感知指针网络(pointer network)相结合,实现了基于知识生成(knowledge-grounded generation)和知识复制(knowledge copy)。在该模型中,他们首先计算对外部知识的注意力分布,然后分别使用「对话上下文」和「知识来源」两个指针复制OOV词。
-
Diverse and informative dialogue generation with context-specific commonsense knowledge awareness.(ACL2020)
利用多类分类器灵活融合三种分布:生成词、生成知识实体和复制查询词。他们使用上下文知识融合(Context-Knowledge Fusion)和灵活模式融合(Flexible Mode Fusion)来联合进行知识检索、响应生成和复制,使生成的响应精确、连贯和附有知识。
-
Cross copy network for dialogue generation.(2020)
提出了一个交叉复制网络,分别从内部话语(对话历史)和外部话语(类似情况)中复制。他们首先使用预先训练的语言模型进行相似案例检索,然后结合两个指针的概率分布进行预测。他们只尝试了法庭辩论和客户服务内容生成任务,在这些任务中,类似的案件很容易获得。
2、许多对话状态跟踪任务(dialogue state tracking tasks)使用复制组件生成槽位(slots)和槽位值。
-
Transferable multi-domain state generator for task-oriented dialogue systems.(2019)
提出了可转移对话状态发生器「TRAnsferable Dialogue statE generator」(TRADE),一种基于复制的对话状态发生器。该生成器对每个可能的(域、槽)对的槽值进行多次解码,然后应用一个槽门来决定哪一对属于对话。输出分布是词汇表和对话历史中选择的(域、槽)对的槽位值的拷贝。
-
Parallel interactive networks for multi-domain dialogue state generation.(2020)
使用了不同于TRADE的复制策略。它们不是使用整个对话历史作为复制源,而是分别从用户话语和系统消息中复制状态值,这些状态值将槽级上下文(slot-level context)作为输入。
-
Dialogue state tracking with explicit slot connection modeling.(ACL2020)
提出了槽连接机制,以有效利用来自其他领域的现有状态。通过计算注意力权重来衡量目标槽位与其他域相关槽位值元组之间的联系。通过token生成、对话上下文复制和过去状态复制的三个分布最终被门控和融合来预测下一个token。
-
Recursive template-based frame generation for task oriented dialog.(ACL2020)
将指针网络和基于模板的树解码器结合起来,递归地分层填充模板。复制机制也缓解了端到端面向任务的对话系统中昂贵的数据标注问题。复制增强对话生成模型的性能明显优于有限领域特定或多领域数据的强壮baseline(Zhang et al., 2020[19];Li等人,2020b[20];Gao等人,2020a[21])。
3、指针网络和CopyNet也用于解决其他与对话相关的任务。
-
Online conversation disentanglement with pointer networks.(2020)
使用了一个指针网络来解析在线对话。指针模块指向当前消息响应的祖先消息,一个分类器预测两条消息是否属于同一个线程。在对话解析任务中,使用指针网络作为主干解析模型来构建话语树。
-
Simple and effective curriculum pointer-generator networks for reading comprehension over long narratives.(2019)
使用了一个指针生成器框架来执行文本跨度长的机器阅读理解,其中复制机制减少了在上下文中包含目标答案的需求。
七、Deep Reinforcement Learning Models
原理:强化学习(Reinforcement Learning) & 强化学习:马尔可夫决策过程
1、强化学习在对话系统中的一个常见应用是任务导向系统中的强化对话管理(the reinforced dialogue management)。对话状态跟踪(Dialogue state tracking)和策略学习(policy learning)是对话管理器的两个典型模块。
-
Meta-reinforced multi-domain state generator for dialogue systems. Huang et.al(ACL2020c)
-
Slot-consistent nlg for task-oriented dialogue systems with iterative rectification network. Li et.al(ACL2020b)
Huang等人(2020c)和Li等人(2020b)用强化学习对对话状态跟踪器进行训练。他们都在追踪器中加入了奖励管理器,以提高追踪的准确性。对于策略学习模块,强化学习似乎是最好的选择,因为最近几乎所有的相关著作都使用强化学习来学习策略。
2、在策略学习任务中越来越偏好用强化学习去解决,是因为:在策略学习任务,模型预测对话行动(action)基于DST模块的状态(state),这完全符合强化学习框架中agent的功能。
由于直接生成语言需要巨大的行动空间,许多经过强化学习框架训练的对话系统并没有生成回应,而是选择回应。基于检索的系统有一个有限的行动集,适合在强化学习方案中进行训练。一些工作在基于检索的对话任务中取得了很好的表现。然而,检索系统不能概括所有用户消息,可能会给出不相关的响应,这使得基于生成的对话系统更可取。仍然考虑到行动空间问题,一些工作则结合检索和生成方法构建了他们的系统。
-
Retrieval-enhanced adversarial training for neural response generation. (2018)
选择首先检索一组n-best响应候选项,然后根据检索结果和用户消息生成响应。
-
A deep reinforcement learning chatbot. (2017)
相比之下,该文首先使用不同的对话模型生成和检索候选答案,然后使用在线强化学习训练评分模型,从生成和检索的答案中选择答案。由于使用强化学习从头训练生成对话agent特别困难,首先用监督学习对agent进行预热训练是一个很好的选择。
八、Knowledge Graph Augmented Neural Networks
有标签数据的监督训练试图学习数据集的知识分布。然而,数据集相对稀疏,因此学习可靠的知识分布需要大量的标注数据(Annervaz et al.,2018[22])。
知识图谱(Knowledge Graph:KG)近年来引起了越来越多的研究兴趣。KG是一个结构化的知识库,由实体及其关系组成。换句话说,KG是以图形形式表示的知识事实。
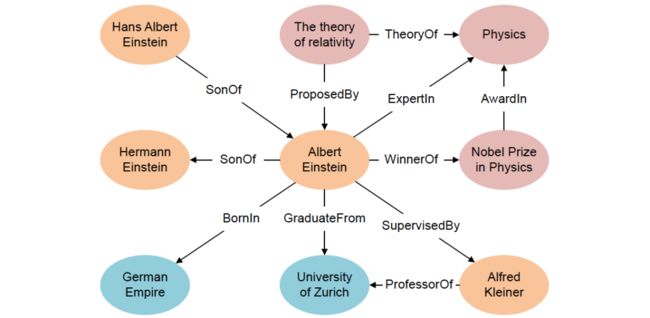
图2 Entities and relations in knowledge graph
上图2显示了一个由实体及其关系组成的KG示例。KG在资源描述框架(Resource Description Framework:RDF)下以三元组的形式存储。例如:
-
Albert Einstein(阿尔伯特·爱因斯坦)
-
University of Zurich(苏黎世大学)
-
他们的关系可以表示为:
-
( AlbertEinstein ; GraduateFrom ; UniversityofZurich )
-
知识图谱增强神经网络首先在低维空间中表示实体及其关系,然后使用神经网络模型检索相关事实。
知识图表示学习可以分为两类:
-
基于结构的表示
基于结构的表示使用多维向量来表示实体和关系。TransE、TransR、TransH、TransD、TransG、TransM、HolE和 project 等模型属于这一类。
-
语义丰富的表示。像NTN、SSP和DKRL等语义丰富的表示模型将语义信息结合到实体和关系的表示中。
神经检索模型也有两个主要方向:
-
基于距离的匹配模型
基于距离的匹配模型考虑投射实体之间的距离
-
基于语义匹配模型。
语义匹配模型计算实体和关系的语义相似度来检索事实。
基于知识的对话系统受益于KG的结构化知识格式,其中的事实是广泛相互关联的。通过KG进行推理是将常识知识结合到响应生成中的理想方法,从而产生准确和信息性的响应。
-
Attnio: Knowledge graph exploration with in-and-out attention flow forknowledge-grounded dialogue.(EMNLP2020)
提出了一种基于知识的对话系统中检索知识的双向图探索模型AttnIO。在每个遍历步骤中计算注意力权重,模型可以选择更广泛的知识路径,而不是一次只选择一个节点。在这种方案中,即使只有目的地节点作为标签,模型也可以预测适当的路径。
-
Grounded conversation generation as guided traverses in commonsense knowledge graphs.(2019)
构建了ConceptFlow,一个引导更有意义的未来对话的对话代理。它在常识性知识图谱中遍历,以探索概念级会话流。最后,通过一个门来决定词汇词(vocabulary words)、中心概念词(central concept words)和外部概念词(outer concept words)之间的生成。
-
Graphdialog: Integrating graph knowledge into end-to-end task-oriented dialogue systems.(2020)
在面向任务的对话系统中将知识图谱作为外部知识来源,在响应中加入领域特定的知识。首先,对话历史被解析为依赖树并编码为固定长度的向量。然后他们使用注意力机制在图上应用了多跳推理。解码器最终通过从图形实体中复制或生成词汇词来预测token。
-
Opendialkg: Explainable conversational reasoning with attention-based walks over knowledge graphs.(ACL2019)
提出DialKG Walker用于会话推理任务。独特的是,他们计算了KG embedding和ground KG embedding之间的zero-shot relevance score,以促进跨域预测。此外,他们应用了一个基于注意力的图漫步器(graph walker)来生成基于相关性得分的图路径。
-
Grade: Automatic graph-enhanced coherence metric for evaluating open-domain dialogue systems.(2020)
通过结合话语级上下文表示和话题级图表示对对话系统进行了评价。他们首先构建基于编码(context, response)对的对话图,然后对图进行推理,得到主题级的图表示。通过将上下文表示和图表示的连接向量传递给前馈网络来计算最终得分。
![]() 参考文献
参考文献
[1] Qiu L, Li J, Bi W, Zhao D, Yan R (2019) Are training samples correlated? learning to generate dialogue responses with multiple references. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp 3826–3835
[2] Bi W, Gao J, Liu X, Shi S (2019) Fine-grained sentence functions for short-text conversation. arXiv preprint arXiv:190710302
[3] Ma W, Cui Y, Liu T, Wang D, Wang S, Hu G (2020a) Conversational word embedding for retrieval-based dialog system. arXiv preprint arXiv:200413249
[4] Feng J, Tao C,WuW, Feng Y, Zhao D, Yan R (2019) Learning a matching model with co-teaching for multi-turn response selection in retrieval-based dialogue systems. arXiv preprint arXiv:190604413
[5] Wu Y, Wu W, Xing C, Zhou M, Li Z (2016) Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. arXiv preprint arXiv:161201627
[6] Tao C, Wu W, Xu C, Hu W, Zhao D, Yan R (2019) One time of interaction may not be enough:Go deep with an interaction-over-interaction network for response selection in dialogues. In:Proceedings of the 57th annual meeting of the association for computational linguistics, pp 1–11
[7] Wang X, Shi W, Kim R, Oh Y, Yang S, Zhang J, Yu Z (2019b) Persuasion for good: Towards a personalized persuasive dialogue system for social good. arXiv preprint arXiv:190606725
[8] Chauhan H, Firdaus M, Ekbal A, Bhattacharyya P (2019) Ordinal and attribute aware response generation in a multimodal dialogue system. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp 5437–5447
[9] Feldman Y, El-Yaniv R (2019) Multi-hop paragraph retrieval for open-domain question answering.arXiv preprint arXiv:190606606
[10] Chen X, Xu J, Xu B (2019c) A working memory model for task-oriented dialog response generation.In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp2687–2693
[11] Lu J, Zhang C, Xie Z, Ling G, Zhou TC, Xu Z (2019) Constructing interpretive spatio-temporal features for multi-turn responses selection. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp 44–50
[12] Coope S, Farghly T, Gerz D, Vuli´c I, Henderson M (2020) Span-convert: Few-shot span extraction for dialog with pretrained conversational representations. arXiv preprint arXiv:200508866
[13] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." arXiv preprint arXiv:1409.3215 (2014).
[14] Sordoni A, Bengio Y, Vahabi H, Lioma C, Grue Simonsen J, Nie JY (2015a) A hierarchical recurrent encoder-decoder for generative context-aware query suggestion. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, pp 553–562
[15] Serban I, Sordoni A, Bengio Y, Courville A, Pineau J (2016) Building end-to-end dialogue systems using generative hierarchical neural network models. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 30, no 1
[16] Ritter A, Cherry C, Dolan WB (2011) Data-driven response generation in social media. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pp583–593
[17] Sordoni A, Galley M, Auli M, Brockett C, Ji Y, Mitchell M, Nie JY, Gao J, Dolan B (2015b) A neural network approach to context-sensitive generation of conversational responses. arXiv preprint arXiv:150606714
[18] Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. arXiv preprint arXiv:14093215
[19] Zhang Y, Ou Z, Wang H, Feng J (2020) A probabilistic end-to-end task-oriented dialog model with latent belief states towards semi-supervised learning. arXiv preprint arXiv:200908115
[20] Li Y, Yao K, Qin L, Che W, Li X, Liu T (2020b) Slot-consistent nlg for task-oriented dialogue systems with iterative rectification network. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp 97–106
[21] Gao S, Zhang Y, Ou Z, Yu Z (2020a) Paraphrase augmented task-oriented dialog generation. arXiv preprint arXiv:200407462
[22] Annervaz K, Chowdhury SBR, Dukkipati A (2018) Learning beyond datasets: Knowledge graph augmented neural networks for natural language processing. arXiv preprint arXiv:180205930