一、Pandoc转换
1.1 问题
由于我们markdown编辑器比较特殊,一般情况下,我们不太好看,如果转换成pdf的话,我们就不需要可以的去安装各种编辑器才可以看了,所以我们有了md转pdf或者是docx的需求。
1.2 下载
资源地址
安装后,本地查看版本,是否安装成功:
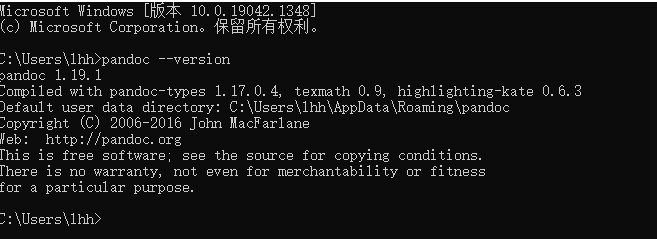
出现如上图表示安装成功。
1.3 md转docx
cd进入我们需要转换的文件目录下,输入:
pandoc xxx.md -s -o xxxx.docx
-s:生成恰当的文件头部和底部。
-o:指定输出的文件。
查看实际效果:

![]()
此时发现文件已经生成好.我们打开看下,

整体转换效果还是不错的。
1.4 md转pdf
pandoc xxx.md -o xxxx.pdf --pdf-engine=xelatex
二、python库实现
使用 Typora可以直接转换
结合 wkhtmltopdf 使用 markdown 库 和 pdfkit 库
2.1 安装 wkhtmltopdf
wkhtmltopdf 下载地址
2.2 安装 mdutils
pip install markdown pip install pdfkit
参考案例:
import pdfkit
from markdown import markdown
input = r"F:\csdn博客\pytorch\【Pytorch】pytorch安装.md"
output = r"【Pytorch】pytorch安装.pdf"
with open(input, encoding='utf-8') as f:
text = f.read()
html = markdown(text, output_format='html') # MarkDown转HTML
htmltopdf = r'D:\htmltopdf\wkhtmltopdf\bin\wkhtmltopdf.exe'
configuration = pdfkit.configuration(wkhtmltopdf=htmltopdf)
pdfkit.from_string(html, output_path=output, configuration=configuration, options={'encoding': 'utf-8'}) # HTML转PDF
但是我们此时存在一个问题,如果我们的md中有表格的话,如图:

那么转换之后会发现是乱的:

我们此时需要设定参数,修改为如下:
html = markdown(text, output_format='html',extensions=['tables'])
我们再看下效果:

2.3 引入数学公式
pip install python-markdown-math
import pdfkit
from markdown import markdown
input_filename = 'xxxx.md'
output_filename = 'xxxx.pdf'
html = '{}