【排序】万字九大排序宝藏汇总 轻松拿下九大排序算法【带动画】 (包含超详细的解释和注释)
【算法】九大排序汇总(包含超详细的解释和注释)
先赞后看好习惯 打字不容易,这都是很用心做的,希望得到支持你 大家的点赞和支持对于我来说是一种非常重要的动力 看完之后别忘记关注我哦!️️️
我们都知道,排序算法是编程高级语言里面极其重要的算法,虽然在C语言中,我们排序可以直接使用
qsort()函数,在C++中,我们可以使用sort()等函数直接完成对数据的排序。但是,在这经典的九大排序算法中,有很多经典而且重要的思想,是需要我们掌握的,在我们日常的编程中,虽然不一定会用到这些排序,但是这些思想,是我们编程解题离不开的。
因此:接下来,随着博主的步伐和顺序,一起学习这经典的九大排序。
对于C语言中的qsort()函数,博主在早期的博客中做过详细的介绍,暂时还不会用的伙伴可以通过传送门食用哦【算法】C程序超详细的qsort排序函数解释和模拟
本篇建议收藏后食用~
文章目录
-
- 前言
- 冒泡排序 bubbleSort
- 选择排序 selectingSort
- 插入排序 insertSort
- 希尔排序 ShellSort
- 快速排序 quickSort
- 归并排序 mergeSort
- 堆排序 heapSort
- 桶排序 bucketSort
- 基数排序 radixSort
- 尾声
前言
为了方便伙伴们测试,这里博主提供一份测试用的main()函数里的源代码,各位测试的时候可以直接复制来进行测试。
本篇使用了一些C++包装的函数,例如swap,max等。
所以读者自己记得加上所需IO,算法等头文件
本期博客使用的编程语言是C++,但是,为了让目前只会C语言的伙伴也可以很好地掌握里面的算法核心,本篇博客没有使用C++包装的vector,全部使用了数组来进行演示。
本篇博客的代码实现的都是int类型数据的升序,想要实现降序或者其它数据类型排序的伙伴可以在此基础上做修改,我们本篇的目标是理解算法思想即可。
注:本篇博客的动画全部来自互联网
//头文件
#include<...>
#include<...>
//...
using namespace std;
//排序的实现
class Solution{
//排序函数实现
void...{
}
};
int main() {
Solution sort;
int arr[15] = { 44,3,38,5,47,15,36,26,27,2,46,4,19,49,48 };
sort.insertSort(arr, 15);//这里是各个排序的名称,这里以插入排序为例
for (int i = 0; i < 15; i++) {
cout<<arr[i]<<" ";
}
return 0;
}
冒泡排序 bubbleSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(n2) | O(n2) | O(n) | O(1) | 稳定 |
冒泡排序:
冒泡排序顾名思义,就是数据向冒泡一样浮到序列的最后。具体过程为:每轮排序中相邻的两个数进行比较,较大的数置于右边,然后继续进行下一相邻数字的比较,一轮排序过后,最大的数字就会置于最右边。然后进行第二轮排序,第三轮…直到不再有相邻的数字可以比较。
通过一个动画,我们就可以很好地理解这个过程
理解好这个过程之后,我们就可以用代码实现了,很明显,这个代码需要用两层循环来实现,第一层用来控制循环的轮数,里层用来控制每一轮相邻数字的交换。

冒泡排序的优化:
对于基础的冒泡排序,我们可以做出一些优化:当我们发现有一轮排序没有任何相邻数进行交换的时候,说明,序列已经有序了,不需要再进行下一轮的排序了,因此,我们可以增加一个变量
if_swap,来记录一轮里是否有数字进行了交换。
代码实现:
class Solution{
//使用数组和指针,不使用vector
void bubble_sort(int* arr, int sz) {
for (int i = 0; i < sz - 1; i++) {//外层循环
//tips:只需要sz-1次,因为最后一次是没有两个数可以交换了
int if_swap = 0;
for (int j = 0; j < sz - 1 - i; j++) {//这里的sz-1-i,我们只要画一画,把例子写出来就可以很好地明白,这里不赘述了
if (arr[j] > arr[j + 1]) {
swap(arr[j],arr[j+1]);//交换两者的值,注:C语言实现swap需要传地址。
if_swap = 1;
}
}
//每一轮走完之后,如果if_swap==0;直接return
if (if_swap==0)
return;
}
}
};
选择排序 selectingSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(n2) | O(n2) | O(n2) | O(1) | 不稳定 |
选择排序:
选择排序相对于其它排序来说,算法方面是比较简单的。
具体过程为:
第一次从待排序的数据元素中选出最小的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。
动画:
代码实现:
使用数组,避免使用vector
class Solution {
public:
void selectSort(int* arr, int sz) {
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++) {
int min = i;
for (j = i + 1; j < sz; j++) {
//从下标为arr[i+1]开始找
//是
//上面
//和冒泡的外层循环原理一样
if (arr[j] < arr[min]) {
min = j;//打擂台
}
}
//出了这层循环之后,交换min和i的值,把i后面最小的放到i的位置
swap(arr[i], arr[min]);//交换二者的值
}
}
};
插入排序 insertSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(n2) | O(n2) | O(n) | O(1) | 稳定 |
插入排序:
插入排序是一种最简单的排序方法,它的基本思想是将一个数插入到已经排好序的有序表(可以理解为一个有序的数列)中,从而一个新的、记录数增1的有序表。在其实现过程使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,并进行移动。
一般插入排序对于序列元素较少的情况比较高效。
动画:

tips:挪动数据的时候,循环一定是反向的,从前往后挪,就要从后往前循环,否则数据会被前一个数覆盖的,这个画个图就能很好明白。
代码实现:
class Solution {
public:
//使用c,cpp共有的数组
void insertSort(int* arr, int sz) {
int sortNum = 0;
int i = 0;
int j = 0;
for (i = 0; i < sz; i++) {
sortNum = arr[i];//要排序的数字
for (j = i - 1; j >= 0; j--) {//因为要从待排序那个数的前一个数开始,往后挪一个
//从后往前挪动,所以用反向循环
//先判断,因为只需要挪动比待排序数字大的数字
if (arr[j] < sortNum) {
break;
}
arr[j + 1] = arr[j];//一个个挪动数据
}
arr[j + 1] = sortNum;//因为是j指向的数字小于sort才出循环的
//所以此时的j指向空位置前一个位置,所以arr[j+1]=sort;
}
}
};
插入排序的不足和优化:
插入排序存在两个不足:
1.寻找插入位置
2.移动元素
优化方案:
1.对已经排好序的序列,采用二分查找的方法
2.携带多个元素
3.数据链表化
4.希尔排序
希尔排序 ShellSort
希尔排序是不稳定的排序
关于希尔排序的时间复杂度,证明过程复杂,网上也有不同的观点和结果,博主在这里不做介绍了,感兴趣的伙伴可以上网搜索相关的资料。
希尔排序:
希尔排序的基本思想就是把待排序的数列分为多个组,然后对每个组进行插入排序,
先让数列整体大致有序,然后多次调整分组方式,使数列更加有序,最后再使用一次插入排序。
看到这些,我们肯定是不明白的,动画也不好表示希尔排序的过程,因此,我们用一张图来试着理解希尔排序的过程:
在希尔排序当中,引入了step,即步长这个变量
在这幅图中我们可以看到:
每一次我们都会有一个步长step,每次按照步长给序列分组,每组分别插入排序,``然后每次调整step,当step==1的时候,相当于对整个序列进行了一次插入排序。
思考:
为什么要在最后一次插入排序之前这么麻烦整这么多次,这样高效吗?
其实,这正是希尔排序的精妙所在,试想,如果我们有个很小的数字,以上面那组数为例,加入那个2,在很靠后的位置的时候。按照插入排序的原理,我们需要从后往前找,找2应该插入的位置,而2应该是最前面的,因此,我们就要将很多个数据分别向后挪动一个位置,这样是非常低效的。而我们在经过前面一些操作之后,序列已经大致有序了,因此,肯定不存在挪动很多个数据的一个情况。
因此,希尔排序的核心思想就是:1)在做插排的时候,查找次数减少,2)插排的时候移动元素次数减少。
关于希尔增量的讨论:
也就是分组的方式,上面的例子的时候是,我们的步长是二分得到的,那为什么要这样二分呢,有其他分组方式吗?
希尔排序也叫缩小增量排序,
关于希尔增量的选取,是一个数学难题,没有准确的说法。
代码实现:
class Solution {
private:
void sort_in_group(int* arr, int sz, int pos, int step) {
int sortNum = 0;
int i = 0;
int j = 0;
for (i = pos + step; i < sz; i += step) {
//pos+step就是该组第一个元素的位置
//例如:当pos==0的时候,该组第一个元素就是整个序列第一个元素
//当pos=1的时候,该组第一个元素就是整个序列第二个元素
sortNum = arr[i];//要插入的数
for (j = i - step; j >= 0; j -= step) {
//i-step就是该组最后一个元素,结合上面给的图可以更好的理解
if (arr[j] < sortNum) {
break;
}
arr[j + step] = arr[j];//挪动数据,普通插排是一个一个挪,这个是,隔step个挪,道理是一样的,静下心思考就能很好地理解。
}
arr[j + step] = sortNum;
}
}
public:
void ShellSort(int* arr, int sz) {
int i = 0;
int step = 0;
//step为步长,每次减少为原来的一半,取整数,最后一次必定为1
for (step = sz / 2; step > 0; step /= 2) {
//步长为step,即共有istep个组,对每一组都执行插入排序
for (i = 0; i < step; i++) {
//这个每一组的排序groupSort就是插入排序稍微改变一点的版本
sort_in_group(arr, sz, i, step);
//i=0的时候,第三个参数是0,结合那张图,也就是红色那组进行插排
//i=1的时候,第三个参数是1,结合图,也就是绿色那组进行插排
//后面的同理
//step毋庸置疑,肯定是要传的
}
}
}
};
快速排序 quickSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(nlog2n) | O(n2) | O(nlog2n) | O(log2n) | 不稳定 |
快速排序:
- 先从数列中选取一个元素作为基准数
(pivot或者key)- 扫描数列,将比基准数小的元素全部放到它的左边,大于或等于基准数的元素全部放到它的右边,得到左右两个区间。
- 再对左右区间重复第二步,直到各区间少于两个元素。
其实这是一个挖坑填数+分治的思想
动图:
tips:图片来自互联网
接下来我们通过代码上的注释来进行进一步理解:
代码实现:
class Solution {
private:
enum {
LEFT,//表示左下标动
RIGHT//表示又下标动
};
public:
void quickSort(int* arr, size_t sz) {
if (sz < 2)
return;//如果数组元素小于两个就不用排了
int pivot = arr[0];//首先选取最左边的数为中心轴
int ileft = 0;//控制下标
int iright = sz - 1;
int imoving = RIGHT;//当前应该移动的下标,LEFT表示要移动左下标,RIGHT表示移动右下标
//因为一开始先把最左边空出来了,所以下标一开始从右边开始走
while (ileft < iright) {//一轮排序结束的标志为左右下标重叠
if (imoving == RIGHT) {
if (arr[iright] >= pivot) {//如果右下标所对应的数比基准数大,表示不用动
iright--;//直接下标减减
continue;//进入到下一轮移动下标操作
}
else if (arr[iright] < pivot) {//如果右下标所对应的数比基准数小,把这个数丢到坑里。
//更换该移动的下标
arr[ileft] = arr[iright];
ileft++;//左下标++
imoving = LEFT;//更换
continue;
}
}
//另一边是同样道理的
if (imoving == LEFT) {
if (arr[ileft] <= pivot) {
ileft++;
continue;
}
else if (arr[ileft] > pivot) {
arr[iright] = arr[ileft];
iright--;
imoving = RIGHT;
continue;
}
}
}
arr[ileft] = pivot;//别忘了把基准值放进来
//到这里我们完成了一轮排序
//此时的基准值换到最后的坑里了
quickSort(arr, ileft);//基准值左边序列快排
quickSort(arr + ileft + 1, sz - ileft - 1);//基准值右边序列快排
}
};
快速排序的优化:
关于中心轴的选取:
在我们介绍的代码中,最初选取的基准轴是来自最左边的数,这样会导致区间是很不均匀的。我们采取分治的思想,区间均匀的话,可以减少递归深度。
所以我们在此基础上是可以适当进行优化的:
- 采用更合理的基准数(中心轴),减少递归的深度。从数列中选取多个数,取中间数。
- 结合插入排序,区间在10个元素之内采用插入排序,效率更高。
在这里博主不再多做讲解了,最重要的就是理解我们最基本的那个快速排序的分治思想,关于后续的优化,感兴趣的伙伴可以继续研究。
归并排序 mergeSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(nlog2n) | O(nlog2n) | O(nlog2n) | O(n) | 稳定 |
归并排序:
归并排序所用的核心思想就是分治!
归并排序(mergeSort)就是将已经有序的子序列合并,得到另一个有序的数列
归是归并的归,不是递归的归,归并排序就是合并排序
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
动画:
tip:动画表示的是总过程,不是实现过程,实现过程如图:
分开-排序-合并
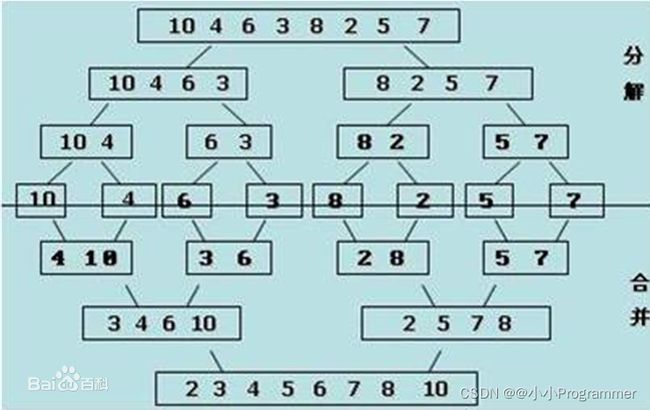
归并排序的实现方法由递归和循环两种方法
递归方法的源代码简单一些
循环方法的源代码复杂一些,但效率高
tips:为了让C语言的伙伴也可以看懂,这里代码的开辟空间使用的是malloc()函数
由于一开始传参只有两个参数,所以定义多一个_mergeSort()函数来真正实现归并排序内部的操作。
这里博主提供递归法的代码,对循环法感兴趣的伙伴可以继续研究哦!
代码实现(递归):
//arr-待排序数组的首地址,arrtmp-用于排序的临时数组的首地址
//start-排序区间第一个元素的位置,end-排序区间最后一个元素的位置
//注:
//这里的istart1,iend1,istart2,iend2都是下标,不是指针,当然,用指针实现也是可以的
class Solution {
private:
void _mergeSort(int* arr, int* arrtmp, int start, int end) {
//如果start>=end,表示该区间的元素少于两个,递归终止
if (start >= end) return;
int mid = start + (end - start) / 2;//找到排序中间位置
//把一个数组分为两个区间
int istart1 = start;
int iend1 = mid;
int istart2 = mid + 1;
int iend2 = end;
//对两边分别递归排序
_mergeSort(arr, arrtmp, istart1, iend1);
_mergeSort(arr, arrtmp, istart2, iend2);
//开始合并各个分开的区间
int i = start;
//把区间左右两边数列合并到已经排序数组arrtmp中
while (istart1 <= iend1 && istart2 <= iend2) {
arrtmp[i] = arr[istart1] < arr[istart2] ? arr[istart1++] : arr[istart2++];
//此处istart1,istart2后面的++是不能拿到下面来的,因为拿了哪个哪个才要++,另外一个较大的是不用动的
i++;
}
while (istart1 <= iend1) {//如果数组1还有剩,数组1后面的全部跟到arrtmp[]后面即可
arrtmp[i] = arr[istart1];
i++;
istart1++;
}
while (istart2 <= iend2) {
arrtmp[i] = arr[istart2];
i++;
istart2++;
}
//最后再把arrtmp[]里面的数据拷贝回去
memcpy(arr + start, arrtmp + start, sizeof(int) * (end - start + 1));
}
public:
void mergeSort(int* arr, const int sz) {
if (sz < 2)return;//小于两个元素不需要排序
int* arrtmp = (int*)malloc(sz * sizeof(int));//分配一个与待排序数组相同大小的数组
_mergeSort(arr, arrtmp, 0, sz - 1);
}
};
堆排序 heapSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | 不稳定 |
堆排序:
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
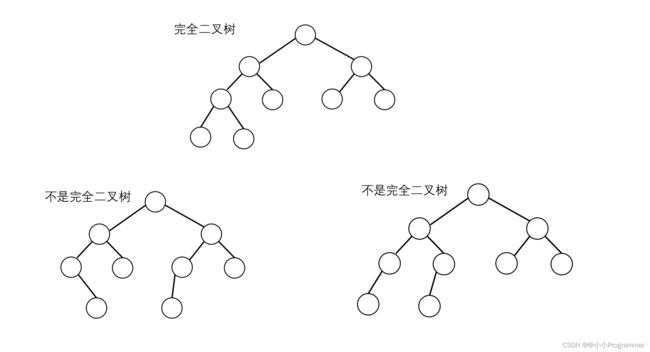
完全二叉树:
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
说直白点:就是一个一个从上到下从左到右放,举几个例子我们就明白了:
这是一棵完全二叉树:
堆:
堆一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
大顶堆(最大堆)和小顶堆(最小堆):
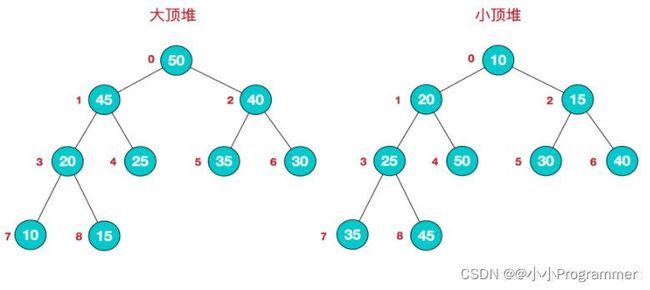
算法思路:(升序,构建大顶堆)
完全二叉树每个结点对应数组下标
N[i]的左结点:N[2i+1]
N[i]的右结点:N[2i+2]
N[i]的父结点:N[(i-1)/2]
有了上面知识的铺垫之后,我们要开始学习堆排序的思路了:
- 将无序的数组的各个数字看作一棵完全二叉树,而每个元素的下标所对应的节点如上面那张图所示,从下标0开始从上到下,从左到右。
- 实现函数
heapify(),将这颗完全二叉树构建成大顶堆,具体如何实现heapify()我接下来会详解。- 将堆的最后一个元素和第一个元素(顶元素)交换,并将最后一个元素脱离出堆。
我们知道,步骤2将数组构建成大顶堆之后,顶元素就是最大的元素,我们在这一步就可以找到最大的元素了。然后我们取出这个元素,重复上面的步骤,就可以找到第二大的元素,第三大的…,最后就完成了排序。
动画:
tips:动画来自互联网
heapify()的实现:
构建大顶堆函数的实现核心就是:元素下沉:
什么意思,就是较小的元素不断下沉。
我们从顶开始遍历树中每个元素,判断该元素是否需要下沉(下沉的条件是,该节点作为父结点的数字,比两个子节点中较大的那个小)
循环过后就可以得到堆了
代码实现:
tips:这里提供了循环和递归两种方法,伙伴们需要调整条件编译条件来选着用
class Solution {
private:
void heapify(int* arr, int start, int end) {
//1.循环法
#if 0
//确定父结点和左子结点的数组下标
int dad = start;
int son = dad * 2 + 1;
//循环条件:子结点的下标不越界
while (son <= end) {
//先比较两个子节点的大小,选大的
if ((son + 1 <= end) && (arr[son] < arr[son + 1])) {//注意条件防止越界
//先判断是否右边有兄弟节点才能比较
son++;//这一步就是从左结点转到右结点
}
//如果父结点大于子结点代表该元素不需要下沉或者已调整完毕,直接跳出函数
if (arr[dad] > arr[son])return;
//否则交换父子节点内容再继续子结点和孙结点的比较
swap(arr[dad], arr[son]);
//迭代
dad = son;//子结点变成新的父节点,继续循环
son = dad * 2 + 1;//通过新的父结点找到新的子结点
}
#endif
//2.递归法
#if 1
//确定父结点和左子结点的数组下标
int dad = start;
int son = dad * 2 + 1;
//如果超出范围了,return
if (son > end) return;//递归结束条件
//先比较两个子结点,选择大的
if ((son + 1 <= end) && (arr[son] < arr[son + 1])) {
son++;//这里和循环法同一个道理
}
if (arr[dad] > arr[son]) {
return;//表示不需要下沉了
}
swap(arr[dad], arr[son]);
//迭代
heapify(arr, son, end);//子结点成为新的父节点来递归
#endif
}
public:
void heapSort(int* arr, int sz) {
int i = 0;
//1.构建二叉树,构建大顶堆
//初始化堆,从最后一个父结点开始调整
for (i = (sz - 1) / 2; i >= 0; i--) {//这里一定要i>=0,因为最顶上的元素也是要下沉的
//每一个元素都检查一下是否需要下沉
heapify(arr, i, sz - 1);//heapify元素下沉函数
}
//2.把第一个元素和堆最后一个元素交换,然后重新调整,直到排序完毕
for (i = sz - 1; i > 0; i--) {
swap(arr[0], arr[i]);
//换完之后重新构建大顶堆
heapify(arr, 0, i - 1);
}
}
};
桶排序 bucketSort
桶排序的时间复杂度,是取决于每个桶里排序方法的。这里不给出桶排序时间复杂度结论
很显然,桶划分的越小,各个桶之间的数据越少,排序所用时间也会越少,但相应的空间消耗就会增大
核心思想:
桶排序顾名思义,是将数据放在几个有序的桶内,将每个桶内的数据进行排序,最后有序地将每个桶中的数据从小到大依次取出,即完成了排序。
当然,这里我介绍的桶排序,是按照数字的十位进行排序的。即1~9放一个桶,10 ~19放一个桶,以此类推。
当然看到这里看,可能觉得桶排序没有那么的厉害,其实,在这里,更重要的,是学会桶思想。这是一种分治思想的经典体现,分而治之,再合起来。这方面其实和归并排序有些类似
桶排序的误区(也就是不准确的说法)
- 如果数据分布不均匀,大量的数据集中在少量的桶里,桶排序就没效果了。
- 桶排序要时间就节省不了空间,要空间就节省不了时间。桶排序意义不大
桶思想 : (tips:来自网络)
在现实世界中,大部分的数据分布是均匀的,或者在设计的时候可以让它均匀分布,或者说可以转换为均匀的分布
既然数据均匀分布了,桶排序的效率就能发挥出来 理解桶思想就可以设计出很高效的算法(数据库里面的分库分表) 这个其实就是很重要的分治的思想。
代码实现:
class Solution {
public:
void bucketSort(int* arr, int sz) {
int bucket[5][5] = { 0 };//分配五个桶,因为在我们例子中最大的数是49,所以5个桶
//如果测试用例变了,我们桶的个数也要变
int bucket_size[5] = { 0 };//每个桶都需要计数,因为我们要知道我们往桶里扔了多少元素
//把数组arr的数据放到桶里面
int i = 0;
for (i = 0; i < sz; i++) {
//这种方法把每个元素除以十,也就是取十位的方法不是完美的,如果数组里面有50几以上的,五个桶就不够了
bucket[arr[i] / 10][bucket_size[arr[i] / 10]++] = arr[i];
//arr[i]/10表示桶的序号,
//所以bucket_size[arr[i]/10]++]表示相对应桶序号的计数器序号
}
//对每个桶进行快排,读者要自己另外调用一种排序方式,这里用快排做例子
for (i = 0; i < 5; i++) {
quickSort(bucket[i], bucket_size[i]);
//bucket_size[i]表示每个桶里面的元素
}
//把每个桶中的数据填充到数组arr中
//也就是一个简单的把二维数组中的元素放到一个一维数组中
int j = 0;//和i一起控制二维数组
int k = 0;//控制arr
for (i = 0; i < 5; i++) {
for (j = 0; j < bucket_size[i]; j++) {
arr[k++] = bucket[i][j];
}
}
}
};
基数排序 radixSort
| 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O( r ) | 稳定 |
基数排序是桶排序的扩展,它的基本思想是:
将整数按位数切割成不同的数字,然后按照每个位数分别比较
具体做法是:将所有待比较数值统一为同样的位数长度,数位较短的数前面补零。
然后,从最低位开始,依次进行依次排序。
这样从最低位排序一直到最高位排序完成后,就变成了有序的数列。
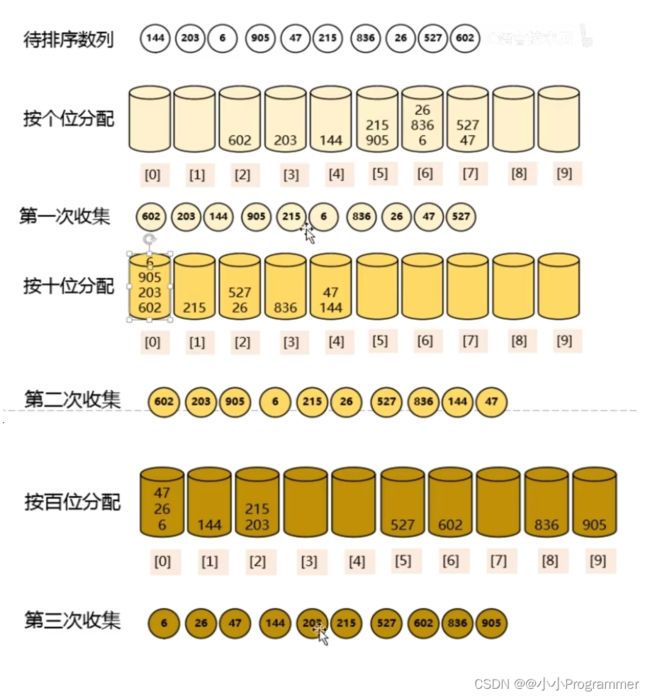
当然,这样是非常难理解的,我通过一张图给大家进行讲解,为了更好地讲解和理解基数排序,我们将测试用例稍作改动。
tips:图片来自于互联网
从这张图片我们开始分析:
- 第一次分配按个位进行分配,144放到下标为4的桶里,205放到下标为5的桶里,6放到下标为6的桶里…
然后按顺序取出来,注意:谁后放进去的先被取出来
此时我们发现,整个序列的个位已经有序了- 第二次分配按照十位进行分配
分配完成并取出来之后,整个序列的十位已经有序了,而且,在十位相同的前提下,个位也是有序的- 第三次按照百位分配并取出之后,整个序列就已经有序了。
代码实现:
class Solution {
private:
int arrMax(int* arr, int sz) {
int max = INT_MIN;
for (int i = 0; i < sz; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}
void _radixSort(int* arr, int sz, int exp) {
int i = 0;//控制循环
int* ret = (int*)calloc(sz, sizeof(int));//存放从桶收集后的临时数组
int buckets[10] = { 0 };//只有0-9十种数字,所以10个桶
/*
* 这里的一维数组buckets就是这个排序的精妙所在,我们思考的时候是把数字放到桶里面
* 但是我们实际写代码的时候,是只需要计数就可以了。
* 因为我们一次排序,也就是一次_radixSort是不用关心其它位数是什么的
*/
//遍历arr,将数据出现次数存储在buckets中
for (i = 0; i < sz; i++) {
buckets[(arr[i] / exp) % 10]++;
}
//下面这两个for,是比较难理解的
//调整buckets各元素的值,调整后的值就是arr中元素在ret中的位置
for (i = 1; i < 10; i++) {
buckets[i] = buckets[i] + buckets[i - 1];//后面有解释
}
//将arr中的元素填充到result中
//以下这个循环非常精妙,我们可以观察到调整bucket[]后里面的数值和排序完之后ret[]里面应有的数值是有一个精妙的关系的
for (i = sz - 1; i >= 0; i--) {
int iexp = (arr[i] / exp) % 10;//这个iexp就是我要排的那一位的那个数,比如134,我现在正在排个位,那iexp就是4
//我在排十位,iexp就是3
ret[buckets[iexp] - 1] = arr[i];//后面有解释
buckets[iexp]--;//每放一个数到ret里,所对应的计数器要减减
}
//将排序好的数组ret复制到arr中
memcpy(arr, ret, sz * sizeof(int));
}
public:
void radixSort(int* arr, int sz) {
int imax = arrMax(arr, sz);//获取数组arr中的最大值,因为数组中最大的数决定分配的次数
int iexp;//排序指数,iexp=1:按各位排序,iexp=10:按十位排序.....
//从个位开始,对数组arr按指数位进行排序
for (iexp = 1; imax / iexp > 0; iexp *= 10) {//循环条件恰恰就可以确定我们要循环的次数
//imax/iexp就是最大循环次数,当iexp增大的时候就会接近这个循环条件
_radixSort(arr, sz, iexp);//每一次的基数排序
//iexp告诉_radixSort()这次是要对哪一位数进行排序
}
}
};
_radixSort中最后两个for循环的解释:
第一个for中
buckets[i] = buckets[i] + buckets[i - 1];
为什么要进行这样的调整?
假设buckets[]现在是 4 1 2 …这代表着(假设现在对个位排序) 个位是0的有4个数,个位是1的有1个,那么,很明显,个位是1的那个数,在从桶中取出来之后,是放在临时数组ret里面的第五个位置的,也就是第4+1=5个位置,
所以,下面这个for调整元素的值其实就是把前面的叠加起来看看有几个,我们不就知道下一个该放到哪里了吗**,比如:前面一共有七个,那下一个数在ret里面的位置,就是第八个数字啊。**所以这一次调整的作用,就是让调整过后buckets[]里面的值刚好就是arr在ret中的位置。
第二个for中
对ret[buckets[iexp] - 1] = arr[i];的理解
我们上面解释了,buckets[]中的数代表arr中的数在此次分配以后在ret中的位置
那么,buckets[iexp]不就是那个数字的位置吗,buckets[iexp]-1就是它的下标
因此,ret[buckets[iexp]-1]=arr[i];就可以理解了。
注:基数排序的桶,是不需要用二维数组的,我们只需要计数就可以了,而且计数的数,和每个数字,下标之间有个精妙的联系,这一部分可能比较难以明白,如果看完解释还不明白的伙伴可以私信我哦。
尾声
看到这里,我相信伙伴们对九大排序已经有一定了解了,在这九大排序里面,其实渗透了很多人的智慧结晶,我们掌握这些排序知识一部分,更重要的还是掌握里面精妙的算法思路。
如果这篇博客对你有帮助,一定不要忘了点赞关注和收藏哦!