Kubernetes简介及集群的搭建部署
Kubernetes简介
中文文档: http://docs.kubernetes.org.cn/
Kubernetes一个用于容器集群的自动化部署、扩容以及运维的开源平台。通过Kubernetes,你可以快速有效地响应用户需求;快速而有预期地部署你的应用;极速地扩展你的应用;无缝对接新应用功能;节省资源,优化硬件资源的使用。为容器编排管理提供了完整的开源方案。
- 在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应
用了很多年,Borg系统运行管理着成千上万的容器应用。 - Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收
了Borg系统中的经验和教训。 - Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,
将最终的应用服务交给用户。 - Kubernetes的好处:
- 隐藏资源管理和错误处理,用户仅需要关注应用的开发。
- 服务高可用、高可靠。
- 可将负载运行在由成千上万的机器联合而成的集群中。
k8s应用与容器化的部署和二进制的部署,容器的应用比较多。
kubernetes设计架构
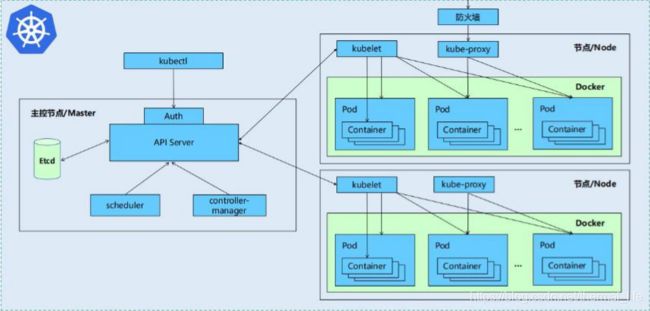
• Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etcd,),一切都基于分布式的存储系统。
- Kubernetes主要由以下几个核心组件组成:
| 组件 | 功能 |
|---|---|
| • etcd: | 保存了整个集群的状态 |
| • apiserver: | 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制 |
| • controller manager: | 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等 |
| • scheduler: | 负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上 |
| • kubelet: | 负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理 |
| • Container runtime: | 负责镜像管理以及Pod和容器的真正运行(CRI) |
| • kube-proxy: | 负责为Service提供cluster内部的服务发现和负载均衡 |
• 除了核心组件,还有一些推荐的Add-ons:
| kube-dns: | 负责为整个集群提供DNS服务 #最新的k8s版本已经集成进去了 |
| Ingress Controller: | 为服务提供外网入口 |
| Heapster: | 提供资源监控 |
| Dashboard: | 提供GUI |
| Federation: | 提供跨可用区的集群 |
| Fluentd-elasticsearch: | 提供集群日志采集、存储与查询 |
- Kubernetes设计理念和功能其实就是一个类似Linux的分层架构
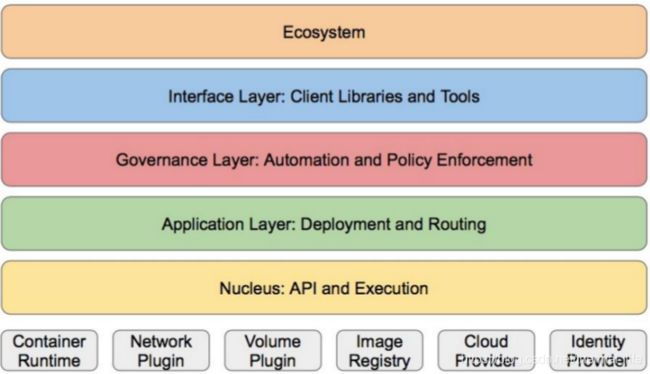
| 核心层: | Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境 |
| 应用层: | 部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等) |
| 管理层: | 系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等) |
| 接口层: | kubectl命令行工具、客户端SDK以及集群联邦 |
| 生态系统: | 在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴 |
- 生态系统 :
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、
OTS应用、ChatOps等 - Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身
的配置和管理等
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、
Kubernetes部署
参考:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
这里我们需要用到harbor仓库,因为从本地的仓库拉取,比从网上拉取速度快:
环境:
server1: 172.25.254.1 harbor仓库
server2: 172.25.254.2 master结点
server3: 172.25.254.3 node结点
server4: 172.25.254.4 node结点
在server2,3,4主机:
关闭节点的selinux和iptables防火墙
- 所有节点部署docker引擎:从阿里云上部署安装。
# step 1: 安装必要的一些系统工具
yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3: 更新并安装Docker-CE
yum -y install docker-ce # 需要container-selinux 的依赖性
[root@server1 yum.repos.d]# cat /etc/sysctl.d/bridge.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1 # 内核支持。
[root@server1 yum.repos.d]# scp /etc/sysctl.d/bridge.conf server2:/etc/sysctl.d/
[root@server1 yum.repos.d]# scp /etc/sysctl.d/bridge.conf server3:/etc/sysctl.d/
[root@server1 yum.repos.d]# scp /etc/sysctl.d/bridge.conf server4:/etc/sysctl.d/
# 让这两个参数生效
[root@server2 ~]# sysctl --system
[root@server3 ~]# sysctl --system
[root@server4 ~]# sysctl --system
systemctl enable --now docker # 打开三个结点的docker服务
- 更改docker 和k8s使用同样的控制方式:
[root@server2 ~]# docker info
Cgroup Driver: cgroupfs # docker原本使用的是cgroup进行控制的,我们要改称systemd的方式控制
[root@server2 packages]# vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
[root@server2 packages]# scp /etc/docker/daemon.json server3:/etc/docker/
root@server3's password:
daemon.json 100% 201 238.1KB/s 00:00
[root@server2 packages]# scp /etc/docker/daemon.json server4:/etc/docker/
root@server4's password:
daemon.json
[root@server2 packages]# systemctl restart docker
Cgroup Driver: systemd # 变成了systemd的方式
- 禁用swap分区:
#禁用swap分区,使性能更好
[root@server3 ~]# swapoff -a #server 2 3 4 都做
[root@server3 ~]# vim /etc/fstab
[root@server3 ~]# vim /etc/fstab
[root@server3 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Tue Apr 28 02:35:30 2020
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=004d1dd6-221a-4763-a5eb-c75e18655041 /boot xfs defaults 0 0
#/dev/mapper/rhel-swap swap swap defaults 0 0
- 安装部署软件kubeadm:
我们从阿里云上进行下载:
[root@server2 yum.repos.d]# vim k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
[root@server2 yum.repos.d]#yum install -y kubelet kubeadm kubectl # kubectl 只需要在master结点安装就可以
其它两个结点作一样的操作。
[root@server2 yum.repos.d]# systemctl enable --now kubelet.service #查看默认配置信息
imageRepository: k8s.gcr.io
# 默认从k8s.gcr.io上下载组件镜像,需要才可以,所以需要修改镜像仓库:
[root@server2 yum.repos.d]# kubeadm config images list # 列出所需要的镜像
W0618 15:03:59.486677 14931 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.18.4
k8s.gcr.io/kube-controller-manager:v1.18.4
k8s.gcr.io/kube-scheduler:v1.18.4
k8s.gcr.io/kube-proxy:v1.18.4
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7
# 指定阿里云仓库列出
[root@server2 yum.repos.d]# kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
W0618 15:04:21.098999 14946 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.4
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.4
registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.4
registry.aliyuncs.com/google_containers/kube-proxy:v1.18.4
registry.aliyuncs.com/google_containers/pause:3.2
registry.aliyuncs.com/google_containers/etcd:3.4.3-0
registry.aliyuncs.com/google_containers/coredns:1.6.7
[root@server2 yum.repos.d]# kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=1.18.3
# 拉取镜像
[root@server2 yum.repos.d]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.aliyuncs.com/google_containers/kube-proxy v1.18.3 3439b7546f29 4 weeks ago 117MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.18.3 7e28efa976bd 4 weeks ago 173MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.18.3 da26705ccb4b 4 weeks ago 162MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.18.3 76216c34ed0c 4 weeks ago 95.3MB
registry.aliyuncs.com/google_containers/pause 3.2 80d28bedfe5d 4 months ago 683kB
registry.aliyuncs.com/google_containers/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
registry.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 7 months ago 288MB
然后我们把这些镜像放到harbor仓库中去,方便我们其它的结点拉取。
[root@server1 yum.repos.d]# scp -r /etc/docker/certs.d/ server2:/etc/docker/
root@server2's password: # 把harbor的证书给server2
ca.crt
[root@server2 yum.repos.d]# vim /etc/hosts
[root@server2 yum.repos.d]# cat /etc/hosts
172.25.254.1 server1 reg.caoaoyuan.org # 给harbor仓库做解析。
[root@server2 yum.repos.d]# docker login reg.caoaoyuan.org
Username: admin
Password:
Login Succeeded # 登陆进去
[root@server2 ~]# docker images |grep reg.ca | awk '{print $1":"$2}'
reg.caoaoyuan.org/library/kube-proxy:v1.18.3 #给上面的镜像打标签成这样子。
reg.caoaoyuan.org/library/kube-apiserver:v1.18.3
reg.caoaoyuan.org/library/kube-controller-manager:v1.18.3
reg.caoaoyuan.org/library/kube-scheduler:v1.18.3
reg.caoaoyuan.org/library/pause:3.2
reg.caoaoyuan.org/library/coredns:1.6.7
reg.caoaoyuan.org/library/etcd:3.4.3-0
# 上传到harbor仓库
[root@server2 ~]# for i in `docker images |grep reg.ca | awk '{print $1":"$2}'`;do dicker push $i ;done
# 删除阿里云的镜像
[root@server2 ~]# for i in `docker images |grep regis | awk '{print $1":"$2}'`;do docker rmi $i ;done
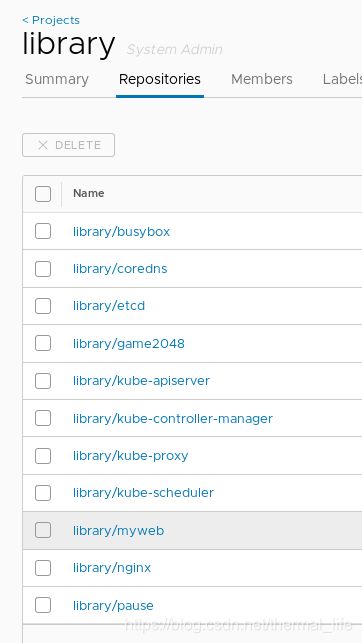
上传成功了。其它的结点就可以拉取了,注意先把证书放过去,还有本地解析:
[root@server1 harbor]# scp -r /etc/docker/certs.d/ server3:/etc/docker/
root@server3's password:
ca.crt 100% 2114 39.7KB/s 00:00
[root@server1 harbor]# scp -r /etc/docker/certs.d/ server4:/etc/docker/
root@server4's password:
ca.crt # 这两个结点还没有放
在master结点执行集群初始化:
[root@server2 ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.caoaoyuan.org/library/
Your Kubernetes control-plane has initialized successfully!
--kubernetes-version=1.18.3
kubeadm join 172.25.254.2:6443 --token 61xkmb.qd1alzh6winolaeg \
--discovery-token-ca-cert-hash sha256:ef9f8d0f0866660e7a01c54ecfc65abbbb11f25147ec7da75453098a9302e597
生成了token(用于加入集群)和hash码(用于验证master端)token默认保存24H
[kubeadm@server2 ~]$ kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
61xkmb.qd1alzh6winolaeg 23h 2020-06-19T17:31:47+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
# 过期后可以使用 kubeadm token create 生成。
官方建议我们使用普通用户操作集群,我们只需要:
[root@server2 ~]# useradd kubeadm
[root@server2 ~]# visudo # 给kubeadm下放权限
su[root@server2 ~]# su - kubeadm
[kubeadm@server2 ~]$ mkdir -p $HOME/.kube
[kubeadm@server2 ~]$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #里面其实是证书。
#把认证放过来,就可以操纵集群了
[kubeadm@server2 ~]$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
[kubeadm@server2 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
server2 NotReady master 12m v1.18.3 #当前只有master结点,且为notready状态
节点扩容,将server3和server4加入到server2:
sysctl -w net.ipv4.ip_forward=1 #可能需要执行这个命令才可以进行
[root@server4 ~]# kubeadm join 172.25.254.2:6443 --token 61xkmb.qd1alzh6winolaeg --discovery-token-ca-cert-hash sha256:ef9f8d0f0866660e7a01c54ecfc65abbbb11f25147ec7da75453098a9302e597
[root@server3 ~]# kubeadm join 172.25.254.2:6443 --token 61xkmb.qd1alzh6winolaeg --discovery-token-ca-cert-hash sha256:ef9f8d0f0866660e7a01c54ecfc65abbbb11f25147ec7da75453098a9302e597
[kubeadm@server2 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server2 NotReady master 20m v1.18.3
server3 NotReady 88s v1.18.3
server4 NotReady 31s v1.18.3
# 就有两个结点加进来了。
- 安装flannel网络组件:
[root@server2 demo]# docker images
quay.io/coreos/flannel v0.12.0-amd64 4e9f801d2217 3 months ago 52.8MB
# 导入这个网络组件,在3和4两个结点都导入
# 切换至kubeadm用户应用这个文件。
[kubeadm@server2 ~]$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
[kubeadm@server2 ~]$ kubectl get pod -n kube-system #,系统组件它的pod都是以namespace的方式进行隔离的
NAME READY STATUS RESTARTS AGE
coredns-5fd54d7f56-22fwz 1/1 Running 0 123m
coredns-5fd54d7f56-l9z5k 1/1 Running 0 123m
etcd-server2 1/1 Running 3 124m
kube-apiserver-server2 1/1 Running 2 124m
kube-controller-manager-server2 1/1 Running 3 124m
kube-flannel-ds-amd64-6t4tp 1/1 Running 0 9m31s
kube-flannel-ds-amd64-gk9r2 1/1 Running 0 9m31s # 网络组件
kube-flannel-ds-amd64-mlcvm 1/1 Running 0 9m31s
kube-proxy-f7rnh 1/1 Running 0 104m
kube-proxy-hww5t 1/1 Running 1 104m
kube-proxy-wn4h8 1/1 Running 3 123m
kube-scheduler-server2 1/1 Running 3 124m
# 都是running才ok
[kubeadm@server2 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server2 Ready master 125m v1.18.3
server3 Ready 106m v1.18.3
server4 Ready 105m v1.18.3 #ready
# 我们就可以用这个集群了
- 查看命名空间
[kubeadm@server2 ~]$ kubectl get pod --all-namespaces #查看所有的命名空间
[kubeadm@server2 ~]$ kubectl get pod -o wide -n kube-system # -o wide 查看详细
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-5fd54d7f56-22fwz 1/1 Running 0 3h34m 10.244.2.2 server4
coredns-5fd54d7f56-l9z5k 1/1 Running 0 3h34m 10.244.1.2 server3
etcd-server2 1/1 Running 3 3h34m 172.25.254.2 server2
kube-apiserver-server2 1/1 Running 2 3h34m 172.25.254.2 server2
kube-controller-manager-server2 1/1 Running 3 3h34m 172.25.254.2 server2
kube-flannel-ds-amd64-6t4tp 1/1 Running 0 100m 172.25.254.3 server3
kube-flannel-ds-amd64-gk9r2 1/1 Running 0 100m 172.25.254.2 server2
kube-flannel-ds-amd64-mlcvm 1/1 Running 0 100m 172.25.254.4 server4
kube-proxy-f7rnh 1/1 Running 0 3h14m 172.25.254.4 server4
kube-proxy-hww5t 1/1 Running 1 3h15m 172.25.254.3 server3
kube-proxy-wn4h8 1/1 Running 3 3h34m 172.25.254.2 server2
kube-scheduler-server2 1/1 Running 3 3h34m 172.25.254.2 server2
可以看到这些组件运行的位置。flannel组件用dameset的控制器,它的特点就是每个节点运行一个。
proxy在每个结点也有。
[root@server4 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
reg.caoaoyuan.org/library/kube-proxy v1.18.3 3439b7546f29 4 weeks ago 117MB
quay.io/coreos/flannel v0.12.0-amd64 4e9f801d2217 3 months ago 52.8MB
reg.caoaoyuan.org/library/pause 3.2 80d28bedfe5d 4 months ago 683kB
reg.caoaoyuan.org/library/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
server3 和server4 加入集群也获取了harbor仓库的信息,拉取了这几个镜像,kubernete就可以运行了,所有的服务都是以容器的方式运行的。
- 自动补齐
[kubeadm@server2 ~]$ echo "source <(kubectl completion bash)" >> ~/.bashrc
[kubeadm@server2 ~]$ logout
[root@server2 demo]# su - kubeadm
Last login: Thu Jun 18 19:26:19 CST 2020 on pts/0
[kubeadm@server2 ~]$ kubectl
alpha apply certificate convert #就可以自动补齐了。
- 删除结点
[kubeadm@server2 ~]$ kubectl drain server4 --delete-local-data --force --ignore-daemonsets
kunode/server4 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-amd64-mlcvm, kube-system/kube-proxy-f7rnh
evicting pod kube-system/coredns-5fd54d7f56-22fwz
bec pod/coredns-5fd54d7f56-22fwz evicted
node/server4 evicted
[kubeadm@server2 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server2 Ready master 3h56m v1.18.3
server3 Ready 3h37m v1.18.3
server4 Ready,SchedulingDisabled 3h36m v1.18.3 # 不再调用此结点
[kubeadm@server2 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
server2 Ready master 3h56m v1.18.3
server3 Ready 3h37m v1.18.3
server4 Ready,SchedulingDisabled 3h36m v1.18.3
[kubeadm@server2 ~]$ kubectl delete node server4 # 删除结点
node "server4" deleted
[kubeadm@server2 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
server2 Ready master 3h57m v1.18.3
server3 Ready 3h38m v1.18.3
[kubeadm@server2 ~]$
这种只适用于已经正常加入的结点,对于还没有正常加入的结点,直接在那个结点上执行:
[root@server4 ~]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
把刚才join的信息清除掉
如果想再加入进来的话:
[kubeadm@server2 ~]$ kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
61xkmb.qd1alzh6winolaeg 19h `还没过期` 2020-06-19T17:31:47+08:00
[root@server4 ~]# kubeadm join 172.25.254.2:6443 --token 61xkmb.qd1alzh6winolaeg --discovery-token-ca-cert-hash sha256:ef9f8d0f0866660e7a01c54ecfc65abbbb11f25147ec7da75453098a9302e597
再加入进去就行了,前提是要做好上面结点中的所有配置。
[kubeadm@server2 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
server2 Ready master 4h3m v1.18.3
server3 Ready <none> 3h43m v1.18.3
server4 Ready <none> 2m1s v1.18.3
- 删除flannel网络组件
[root@server4 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
56862b391eda 4e9f801d2217 "/opt/bin/flanneld -…" 33 minutes ago Up 33 minutes k8s_kube-flannel_kube-flannel-ds-amd64-sklll_kube-system_84e2eb08-2b85-4cc2-a167-5ea78629af3c_1
[root@server4 ~]# docker rm -f 56862b391eda
56862b391eda
[root@server4 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f7db2b985cc5 4e9f801d2217 "/opt/bin/flanneld -…"
集群会事时监控状态,当有服务关闭时,会自动一直restart服务。
- 创建一个pod
[kubeadm@server2 ~]$ kubectl run demo --image=nginx # 自主式pod,还有一种deployment控制器方式
kubecpod/demo created
[kubeadm@server2 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
demo 0/1 ContainerCreating 0 5s
[kubeadm@server2 ~]$ kubectl logs demo
Error from server (BadRequest): container "demo" in pod "demo" is waiting to start: ContainerCreating
[kubeadm@server2 ~]$ kubectl describe pod demo #查看pod 详细信息
Name: demo
Namespace: default
Priority: 0
Node: server3/172.25.254.3
IP: 10.244.1.3
IPs:
IP: 10.244.1.3
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/demo to server3
Normal Pulling 47s kubelet, server3 Pulling image "nginx"
Normal Pulled 19s kubelet, server3 Successfully pulled image "nginx"
Normal Created 19s kubelet, server3 Created container demo
Normal Started 18s kubelet, server3 Started container demo
[kubeadm@server2 ~]$ kubectl logs demo #查看pod 日志
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
[kubeadm@server2 ~]$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo 1/1 Running 0 8m58s 10.244.1.3 server3 <none> <none>
# 已经运行在了server3上下次再部署相同的容器时,依然会到server3上,因为他已经拉取过镜像了
[kubeadm@server2 ~]$ curl 10.244.1.4
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
[kubeadm@server2 ~]$ kubectl delete pod demo
pod "demo" deleted
然后我们去server3和server4两个工作结点配置仓库:
[root@server3 ~]# vim /etc/docker/daemon.json
[root@server4 ~]# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://reg.caoaoyuan.org"], # 把这一行加进去。
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
[root@server3 ~]# systemctl restart docker
这时拉取镜像就会从我们的harbor仓库去拉取了。我们集群的配置就基本ok了。
- kubectl命令指南:
- https://kubernetes.io/docs/reference/generated/kubectl/kubectl-
commands
- https://kubernetes.io/docs/reference/generated/kubectl/kubectl-