C语言:从入门到进阶笔记(完整版)

全文约20w字(初稿,有错误、排版问题或不准确之处在所难免)
前言
本系列适合已经接触过C语言或对C语言有基本的了解的读者观看,适合用来复习巩固和夯实基础。共18大章,每个章节分为若干个小节,部分章节备有配套的练习,并且本系列附带了三套C语言笔试题以及答案详细解析。第一章由于字数原因,以贴链接的方式展示。由于作者水平有限、时间仓促紧迫,本教学有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!从第一章博客的更新到最后一章共历时四个月,难免会有排版、代码风格、图标运用的不一致的地方,还请谅解。文章内有很多表情包,目的是让读者在阅读过程中减少枯燥,并且有些表情包可以形象的记忆一些重要的知识点,但是有些章节表情包比较少,如果有机会,我将继续完善本系列教程。本次为首次发布,还有很多不足之处需要改进,感谢你的支持。
本文为整合篇,大约二十万字,由于篇幅较大,如果觉得翻阅起来比较困难,如果你想选择性地学习和阅读,可以订阅专栏 —— 《维生素C语言》 ,可以进行选择对应章节进行观看。
参考文献 / 资料
Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. .
林锐. 《高质量C/C++编程指南》[M]. 1.0. 电子工业, 2001.7.24.
陈正冲. 《C语言深度解剖》[M]. 第三版. 北京航空航天大学出版社, 2019.
俞甲子 / 石凡 / 潘爱民. 《程序员的自我修养》[M]. 电子工业出版社, 2009-4.
百度百科[EB/OL]. []. https://baike.baidu.com/.
比特科技. C语言基础[EB/OL]. 2021[2021.8.31]. .
比特科技. C语言进阶[EB/OL]. 2021[2021.8.31]. .
第一章 - 初识C语言
【简单地过一遍C语言基础部分】所有知识点,点到为止!(仅一万多字)_#define _CRT_SECURE_NO_WARNINGS 1-CSDN博客就在前几天,C语言入门到进阶部分的专栏——《维生素C语言》终于完成了。全文共计十八个章节并附带三张笔试练习篇,美中不足的是,第一章和第二章是以截图形式展现的。由于本人一开始是在有道云笔记上写的初稿,当时想方便省事(有道云排版个人感觉确实比较美观)就直接以截图的形式完成了第一章和第二章。本人考虑到因为是截图,不能复制文中出现的代码,不方便读者进行复制粘贴,所以我打算重新写一下第一章和第一章的内容,并且重新进行了排版。https://blog.csdn.net/weixin_50502862/article/details/120265591
第二章 - 分支和循环
一、语句
0x00 什么是语句
C语言中,由一个分号( ;)隔开的即为一条语句。
这些都是语句:
( 一行里只有 ;的语句,我们称其为 "空语句" )
int main(void) {
printf("hello world!\n"); // 语句;
3 + 5; // 语句;
; // 空语句;
}0x01 真与假
定义: 0为假,非0即为真(比如:1是真,0是假)
二、分支语句
0x00 if 语句

单 if 语句演示:
int main(void) {
int age = 0;
scanf("%d", &age);
if ( age >= 18 )
printf("成年\n");
return 0;
}if...else 演示:
int main(void) {
int age = 0;
scanf("%d", &age);
if ( age >= 18 )
printf("成年\n");
else
printf("未成年");
return 0;
}多分支演示:
int main(void) {
int age = 0;
scanf("%d", &age);
if(age<18) {
printf("少年\n");
}
else if(age>=18 && age<30) {
printf("青年\n");
}
else if(age>=30 && age<50) {
printf("中年\n");
}
else if(age>=50 && age<120) {
printf("老年\n");
} else {
printf("请输入正确的年龄\n");
}
return 0;
}判断一个数是否为奇数:
int main(void) {
int n = 0;
scanf("%d", &n);
if(n % 2 == 0) {
printf("不是奇数\n");
} else {
printf("是奇数\n");
}
return 0;
}0x01 代码块
如果条件成立,需要执行多条语句,应该使用代码块,一对大括号,就是一个代码块。
建议:无论是一行语句还是多行语句,建议都加上大括号。

不加大括号的隐患:悬空 else
❓ 下列代码会打印 abc 吗?
int main(void) {
int a = 0;
int b = 2;
if ( a == 1 )
if ( b == 2 )
printf("123\n");
else
printf("abc\n");
return 0;
}运行结果:(什么都没打印出来)
解析:因为没有大括号,else 与离它最近的一个if相结合( 即内部 if ),所以即使 else 与外部 if 相对应,也没用。
订正:加上大括号之后,可以使代码的逻辑更加清楚!
int main(void) {
int a = 0;
int b = 2;
if(a == 1) {
if(b == 2) {
printf("hehe\n");
}
} else {
printf("haha\n");
}
return 0;
}运行结果: abc
0x02 代码风格
代码一:可读性不好,但是节省空间

代码二:可读性强
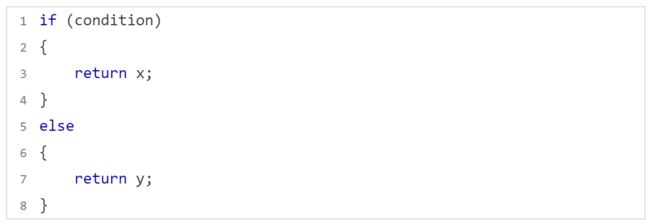
代码三:我们希望 hello 不被打印出来,但是事实上他打印出来了;
int main()
{
int num = 0;
if ( num = 5 ) {
printf("hello\n"); // = 赋值 == 判断相等;
}
return 0;
}解析:为什么会这样呢?因为在 if 语句中 num = 5 相当于重新赋值了。
为了防止把一个等号写成两个等号,发生这样的BUG,我们可以这么写:
int main()
{
int num = 0;
if (5 == num) {
printf("hehe\n");
}
return 0;
}这样写,如果不小心写成了 "=",运行都运行不了,可以让自己很容易地发现问题。这是种好的代码风格!未来如果涉及到常量和变量相比较,比较相等与否,我们不妨把变量放在双等号的右边,常量放在左边,以防不小心少打一个 "=" ,导致程序出错。
关于 return 0
int test() {
if (1) {
return 0; // 当return 0 执行了,下面的代码都不会执行了;
}
printf("hehe\n");
return 1;
}
int main(void) {
test();
return 0;
}0x04 switch 语句
介绍:switch 语句是一种多分支语句,常常用于多分支的情况。一个标准 switch 语句的组成:
① case 语句项:后面接常量表达式(类型只能是整型和枚举类型)。
② break 语句:用来跳出 switch 语句,实际效果是把语句列表划分为不同的部分。
③ default 子句:默认执行的语句,当所有 case 都无法与 switch 的值相匹配时执行。

注意事项:
1. case 和 default 后面记得加 :(冒号),而不是分号。
2. 在 switch 语句中可以出现if语句。
3. switch 后面必须是整型常量表达式。
4. 每个 switch 语句后面只能有一个 default。
5. 不一定非要加 default,也可以不加。
建议:
1. 在最后一个 case 语句的后面也加上一条 break 语句,以防未来增添语句项时遗漏。
2. 建议在每个 switch 中都加入 default 子句,甚至在后边再加一个 break 都不过分。
switch 用法演示:用户输入一个数字x,返回星期(eg. 1 >>> 星期一)
int main(void) {
int day = 0;
scanf("%d", &day);
switch (day) {
case 1:
printf("星期一\n");
break; // 跳出switch
case 2:
printf("星期二\n");
break;
case 3:
printf("星期三\n");
break;
case 4:
printf("星期四\n");
break;
case 5:
printf("星期五\n");
break;
case 6:
printf("星期六\n");
break;
case 7:
printf("星期日\n");
break;
default: // 默认执行的语句;
break;
}
return 0;
}多 case 同一个结果情况演示:输入1-5,输出 工作日;输入6-7,输出休息日;其他数字返回error
int main(void) {
int day = 0;
scanf("%d", &day);
switch (day) {
case 1:
case 2:
case 3:
case 4:
case 5:
printf("工作日\n");
break;
case 6:
case 7:
printf("休息日\n");
break; // 末尾加上break是个好习惯;
default:
printf("输入错误\n");
break; // 这里可以不加break,但是加上是个好习惯;
}
return 0;
}❓ 下列代码输出值是多少?
int main(void) {
int n = 1;
int m = 2;
switch(n) {
case 1:
m++;
case 2:
n++;
case 3:
switch(n) {
case 1:
n++;
case 2:
m++;
n++;
break;
}
case 4:
m++;
break;
default:
break;
}
printf("m = %d, n = %d\n", m, n);
return 0;
}答案:m = 5, n = 3
解析:因为n=1,所以进入switch后执行case1的语句m++,此时m=3,由于该语句项末尾没有break,继续向下流到case2的语句n++,此时n=2,又没有break,流向case3,case3中又嵌了一个switch(n),此时因n=2,执行内部switch的case2的语句m++和n++,此时m=4,n=3,后面有break,跳出内部switch,但是外部switch的case3后面依然没有break,所以流向case4,m++,此时m=5,后面终于有break了。运行下来后的结果为 m=5,n=3。
三、循环语句
0x00 while 循环
定义:当满足条件时进入循环,进入循环后,当条件不满足时,跳出循环。
注意事项:while 循环条件将会比循环体多执行一次。
while 循环中,当条件表达式成立时,才会执行循环体中语句,每次执行期间,都会对循环因子进行修改(否则就成为死循环),修改完成后如果 while 条件表达式成立,继续循环,如果不成立,循环结束。

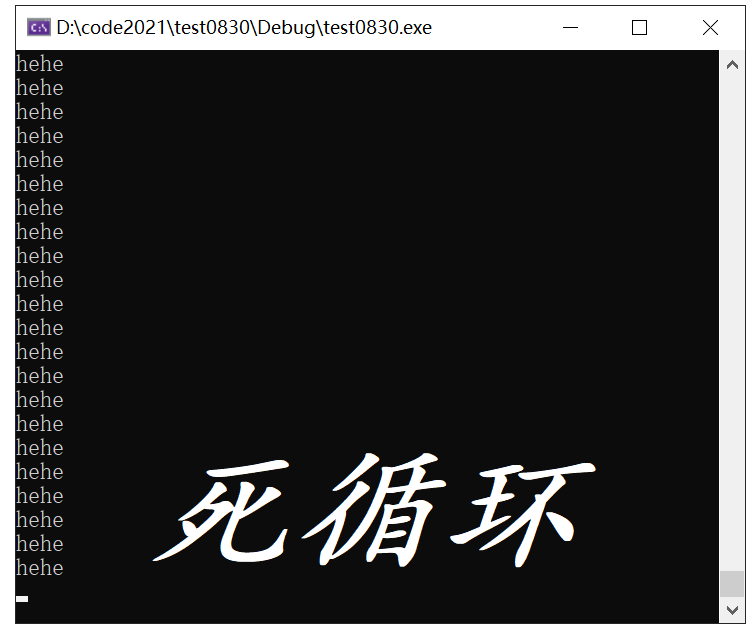
while死循环:表达式结果如果为非0,为真,循环就执行
int main(void) {
while(1)
printf("hehe\n");
return 0;
}运行结果如下:
while 循环打印 1~10 的数字:
int main(void) {
int i = 1;
while(i<=10) {
printf("%d ", i);
i++;
}
return 0;
}运行结果: 1 2 3 4 5 6 7 8 9 10
0x01 break 语句
break 语句在 while 循环中的效果:
在 while 循环中,break 用于永久地终止循环。
int main(void) {
int i = 1;
while(i <= 10) {
if(5 == i) // i=5时停止循环;
break;
printf("%d ", i);
i++;
}
return 0;
}运行结果:1 2 3 4
0x02 continue 语句
continue 语句:
int main()
{
int i = 1;
while(i<=10) {
if(i==5) {
continue; // 跳至判断部分;
}
printf("%d ", i);
i++;
}
return 0;
}运行结果: 1 2 3 4(程序会一直判断)
0x03 getchar 和 putchar
getchar:
从流(stream)或键盘上,读取一个字符。
返回值:如果正确,返回ASCII值;如果读取错误吗,返回 EOF(文件结束标志)。
putchar:单纯的输出一个字符。

getchar 使用方法演示: "输入什么就返回什么"
int main(void) {
int ch = getchar();
putchar(ch); // 输出一个字符;
return 0;
}运行结果:(假设输入a) a
getchar 与 while 的结合: "一直从键盘上读取字符的程序"
int main(void) {
int ch = 0;
// ctrl+z - getchar 就读取结束;
while ( (ch = getchar()) != EOF ) {
putchar(ch);
}
return 0;
}❓ 如果想停止输入,怎么办?
解决方法: 输入 ctrl + z 可以使 getchar 结束读取。
getchar 只打印数字:
int main(void) {
int ch = 0;
while( (ch=getchar()) != EOF ) {
if(ch<'0' || ch>'9') {
continue; // 发现不是数字,跳回判断部分,重新getchar;
}
putchar(ch);
}
return 0;
}清理缓冲区:用户输入密码后,让用户确认(Y/N)
int main(void) {
char password[20] = {0};
printf("请输入密码:>");
scanf("%s", password);
printf("请确认密码(Y/N) :>");
int ch = getchar();
if(ch == 'Y') {
printf("确认成功\n");
} else {
printf("确认失败\n");
}
return 0;
}运行结果:(假设用户输入了123456;Y)确认失败
❓ 为什么还没有让用户确认(Y/N)就显示确认失败了?
解析:输入函数并不是从键盘上读取,而是从缓冲区中读取内容的;键盘输入123456时敲下回车键,此时为 “123456\n”,这时scanf将123456取走,getchar读取到的就是“\n”了,因为“\n”不是Y,执行了else的结果,所以显示确认失败。
解决方案:在 scanf 后加上一个“读取 \n ”的 getchar()
int main(void) {
char password[20] = {0};
printf("请输入密码:>");
scanf("%s", password);
printf("请确认密码(Y/N) :>");
// 清刷缓冲区;
getchar()
int ch = getchar();
if(ch == 'Y') {
printf("确认成功\n");
} else {
printf("确认失败\n");
}
return 0;
}(假设用户输入了123456;Y)确认成功
(假设用户输入了123 456;Y)确认失败
❓“用户输入了空格,确认Y,为什么显示确认失败?”
解析:刚才加入的一个getchar()处理掉了空格,导致后面“\n”没人管了;
解决方案:加入循环
int main(void) {
char password[20] = {0};
printf("请输入密码:>");
scanf("%s", password);
printf("请确认密码(Y/N) :>");
// 清理缓冲区的多个字符;
int tmp = 0;
while( (tmp = getchar()) != '\n' ) {
;
}
int ch = getchar();
if(ch == 'Y') {
printf("确认成功\n");
} else {
printf("确认失败\n");
}
return 0;
}(假设用户输入了123 456;Y)确认成功
0x04 for 循环
定义:
① 表达式1:初始化部分,用于初始化循环变量。
② 表达式2:条件判断部分,用于判断循环终止。
③ 表达式3:调整部分,用于循环条件的调整。

注意事项:
① 为了防止for循环失去控制,禁止在for循环体内修改循环变量。
② for循环内的表达式可以省略,但是得注意。
建议:
① 建议使用“左闭区间,右开区间”的写法:
for( i=0; i<10; i++ ) 左闭,右开区间 ✅
for( i=0; i<=9; i++ ) 左右都是闭区间 ❎② 不要在for循环体内修改循环变量,防止for循环失去控制。
for 的使用方法演示
① 利用 while 循环打印1~10数字:
int main(void) {
int i = 1; // 初始化
while(i<=10) { //判断部分
printf("%d ", i);
i++; // 调整部分
}
return 0;
} 运行结果:1 2 3 4 5 6 7 8 9 10
② 利用 for 循环打印1~10数字:
int main(void) {
int i = 0;
for(i=1; i<=10; i++) {
printf("%d ", i);
}
return 0;
}运行结果:1 2 3 4 5 6 7 8 9 10
break 语句在 for 循环中的效果:
int main(void) {
int i = 0;
for(i=1; i<=10; i++) {
if(i==5) { // 当i==5时;
break; // 直接跳出循环;
}
printf("%d ", i);
}
}运行结果:1 2 3 4
❓ 什么没有打印5?
解析:因为当 i==5 时,break 跳出了循环,循环中 break 之后的语句全都不再执行,printf 位于 break 之后,所以5自然不会被打印出来;
continue 在 for 循环中的效果
if 中的 continue 会陷入死循环,但是在 for 中并不会:
int main(void) {
int i = 0;
for(i=1; i<=10; i++) {
if(i == 5)
continue; // 跳至调整部分(i++);
printf("%d ", i);
}
}运行结果:1 2 3 4 5 6 7 8 9 10
❓ 这里为什么又没打印 5?
解析:因为当 i==5 时,continue 跳至调整部分,此时 i++,i 为6。同上,所以5自然不会被打印。i 为6时,if 不成立,继续打印,最终结果为 1 2 3 4 6 7 8 9 10(跳过了5的打印);
for 循环体内修改循环变量的后果:
int main(void) {
int i = 0;
for (i=0; i<10; i++) {
if (i = 5) {
printf("haha\n");
}
printf("hehe\n");
}
return 0;
}hehehahahehehaha…… 死循环
0x05 for 循环的嵌套
定义:
① for 循环是允许嵌套的;
② 外部的 for 循环称为外部循环,内部的 for 循环称为内部循环;

for 嵌套的演示:
int main(void) {
int i = 0;
int j = 0;
for (i=0; i<10; i++) {
for (j=0; j<10; j++) {
printf("hehe\n");
}
}
// 10x10 == 100
return 0;
}(打印了100个hehe)
0x06 for 循环的省略
for 循环的省略:
① for 循环的 "初始化、判断部分、调整部分" 都可以省略。
② 判断部分的省略 - 判断部分恒为真 - 死循环 。
③ 如果不是非常熟练,建议不要省略。
判断部分的省略:
int main(void) {
// 判断部分恒为真 - 死循环
for(;;) {
printf("hehe\n");
}
return 0;
}hehehehehehe…… 死循环
省略带来的弊端
假设我们希望下列代码能打印 9 个呵呵:
int main(void) {
int i = 0;
int j = 0;
for(; i<3; i++) {
for(; j<3; j++) {
printf("hehe\n");
}
}
return 0;
}运行结果:hehe hehe hehe (只打印了3个)
解析:因为 i=0,内部 for 打印了3次 hehe,此时 j=3,这时 i++,j因为没有初始化,所以此时 j仍然是3,而判断部分要求 j<3,自然就不再打印了,程序结束。
❓ 请问要循环多少次?
int main(void) {
int i = 0;
int k = 0;
int count = 0;
for(i=0,k=0; k=0; i++,k++) {
k++;
count++;
}
printf("count:%d", count);
return 0;
}答案:count = 0,一共循环0次。
解析:判断部分 k=0,赋值为 0 时为假,所以一次都不会循环。
0x07 do...while 循环
定义:在检查 while() 条件是否为真之前,该循环首先会执行一次 do{} 之内的语句,然后在 while() 内检查条件是否为真,如果条件为真,就会重复 do...while 这个循环,直至 while() 为假。

注意事项:
① do...while 循环的特点:循环体至少执行一次。
② do...while 的使用场景有限,所以不是经常使用。
③ 简单地说就是:不管条件成立与否,先执行一次循环,再判断条件是否正确。
do...while 使用方法演示:
int main(void) {
int i = 1;
do {
printf("%d ", i);
i++;
} while(i<=10);
return 0;
}运行结果: 1 2 3 4 5 6 7 8 9 10
break 语句在 do...while 循环中的效果:
int main(void) {
int i = 1;
do {
if(i==5) {
break;
}
printf("%d ", i);
i++;
} while(i<10);
return 0;
}运行结果:1 2 3 4
continue 语句在 do...while 循环中的效果:
int main(void) {
int i = 1;
do {
if(i == 5)
continue;
printf("%d ", i);
i++;
}
while(i<=10);
return 0;
}0x08 goto 语句
C语言中提供了可以随意滥用的 goto 语句和标记跳转的标号。最常见的用法就是终止程序在某些深度嵌套的结构的处理过程。

“ goto 语句存在着争议”
1. goto 语句确实有害,应当尽量避免。
2. 理论上讲goto语句是没有必要的,实践中没有goto语句也可以很容易的写出代码。
3. 完全避免使用 goto 语句也并非是个明智的方法,有些地方使用 goto 语句,会使程序流程 更清楚、效率更高。

注意事项:goto 语句只能在一个函数内跳转。
可以考虑使用 goto 的情形:
for(...) {
for(...) {
for(...) {
// HOW TO ESCAPE?
}
}
}体会 goto 语句的特点:
int main(void) {
flag:
printf("hehe\n");
printf("haha\n");
goto flag;
return 0;
}hehehahahehehaha ( 死循环)
goto实战:一个关机程序
C语言提供的用于执行系统命令的函数:system()
关机指令:shutdown -s -t 60 (60秒后关机)
取消关机:shutdown -a
#include
#include
#include
int main(void) {
char input[20] = {0}; // 存放输入的信息;
system("shutdown -s -t 60"); // 关机指令;
printf("[系统提示] 计算机将在一分钟后关机 (取消指令:/cancel) \n");
again:
printf("C:\\Users\\Admin> ");
scanf("%s", &input);
if(strcmp(input, "/cancel") == 0) {
system("shutdown -a"); // 取消关机;
printf("[系统提示] 已取消。\n");
} else {
printf("'%s' 不是内部或外部命令,未知指令。\n", input);
printf("\n");
goto again;
}
return 0;
} 第三章 - 函数
本章将对于C语言函数的定义和用法进行讲解,并且对比较难的递归部分进行详细画图解析,并对栈和栈溢出进行一个简单的叙述。同样,考虑到目前处于基础阶段,本章配备练习便于读者巩固。
一、函数
0x00 函数的定义
数学中,f(x) = 2*x+1、f(x, y) = x + y 是函数...
在计算机中,函数是一个大型程序中的某部分代码,由一个或多个语句块组成;
它负责完成某项特定任务,并且相较于其他代码,具备相对的独立性;
注意事项:
1. 函数设计应追求“高内聚低耦合”;
(即:函数体内部实现修改了,尽量不要对外部产生影响,否则:代码不方便维护)
2. 设计函数时,尽量做到谁申请的资源就由谁来释放;
3. 关于return,一个函数只能返回一个结果;
4. 不同的函数术语不同的作用域,所以不同的函数中定义相同的名字并不会造成冲突;
5. 函数可以嵌套调用,但是不能嵌套定义,函数里不可以定义函数;
7. 函数的定义可以放在任意位置,但是函数的声明必须放在函数的使用之前;
箴言:
1. 函数参数不宜过多,参数越少越好;
2. 少用全局变量,全局变量每个方法都可以访问,很难保证数据的正确性和安全性;
0x01 主函数
( 这里不予以赘述,详见第一章)
注意事项
1. C语言规定,在一个源程序中,main函数的位置可任意;
2. 如果在主函数之前调用了那些函数,必须在main函数前对其所调用函数进行声明,或包含其被调用函数的头文件;
0x02 库函数
❓ 为什么会有库函数?
“库函数虽然不是业务性的代码,但在开发过程中每个程序员都可能用得到,为了支持可移植性和提高程序的效率,所以C语言基础库中提供了库函数,方便程序员进行软件开发”
注意事项:库函数的使用必须要包含对应的头文件;
箴言:要培养一个查找学习的好习惯;
学习库函数
1. MSDN;
2. c++:www.cplusplus.com;
3. 菜鸟教程:C 语言教程 | 菜鸟教程;
简单的总结:
IO函数、字符串操作函数、字符操作函数、内存操作函数、时间/日期函数、数学函数、其他库函数;
参照文档,学习几个库函数:
“strcpy - 字符串拷贝”
#include
#include // Required Header;
int main()
{
char arr1[20] = {0}; // strDestination;
char arr2[] = "hello world"; // strSource;
strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
} >>> hello world
参照文档,试着学习几个库函数:
“memset - 内存设置”

#include
#include // Requested Header
int main()
{
char arr[] = "hello world"; // dest
memset(arr, 'x', 5); // (dest, c, count)
printf("%s\n", arr);
return 0;
} >>> xxxxx world
0x03 自定义函数
❓ 何为自定义函数?
“顾名思义,全部由自己设计,赋予程序员很大的发挥空间”
自定义函数和其他函数一样,有函数名、返回值类型和函数参数;
1. ret_type 为返回类型;
2. func_name 为函数名;
3. paral 为函数参数;

自定义函数的演示
“需求:写一个函数来找出两个值的较大值”
int get_max(int x, int y) { // 我们需要它返回一个值,所以返回类型为int;
int z = 0;
if (x > y)
z = x;
else
z = y;
return z; // 返回z - 较大值;
}
int main()
{
int a = 10;
int b = 20;
// 函数的调用;
int max = get_max(a, b);
printf("max = %d\n", max);
return 0;
}>>> max = 20
0x04 函数的参数
实际参数(实参)
1. 真实传给函数的参数叫实参(实参可以是常量、变量、表达式、函数等);
2. 无论实参是何种类型的量,进行函数调用时,必须有确定的值,以便把这些值传送给形参;
形式参数(形参)
1. 形参实例化后相当于实参的一份临时拷贝,修改形参不会改变实参;
2. 形式参数只有在函数被调用的过程中才实例化;
3. 形式参数在函数调用完后自动销毁,只在函数中有效;
注意事项:
1. 形参和实参可以同名;
2. 函数的形参一般都是通过参数压栈的方式传递的;
3. “形参很懒”:形参在调用的时才实例化,才会开辟内存空间;

0x05 函数的调用
传值调用
1. 传值调用时,形参是实参的一份临时拷贝;
2. 函数的形参和实参分别占用不同内存块,对形参的修改不会影响实参;
3. 形参和实参使用的不是同一个内存地址;
传址调用
1. 传址调用时可通过形参操作实参;
2. 传址调用是把函数外部创建的变量的内存地址传递给函数参数的一种调用函数的方式;
3. 使函数内部可以直接操作函数外部的变量(让函数内外的变量建立起真正的联系);
交换两个变量的内容
// void,表示这个函数不返回任何值,也不需要返回;
void Swap(int x, int y) {
int tmp = 0;
tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 10;
int b = 20;
// 写一个函数 - 交换2个整形变量的值
printf("交换前:a=%d b=%d\n", a, b);
Swap(a, b);
printf("交换后:a=%d b=%d\n", a, b);
return 0;
}>>> 交换前:a=10 b=20 交换后:a=10 b=20
❓ “为何没有交换效果?是哪里出问题了吗?”
解析:Swap在被调用时,实参传给形参,其实形参是实参的一份临时拷贝。因为改变型形参并不能改变实参,所以没有交换效果;
解决方案:使用传址调用(运用指针)
// 因为传过去的是两个整型地址,所以要用int*接收;
void Swap2(int* pa, int* pb) { // 传址调用;
int tmp = *pa; // *将pa解引用;
*pa = *pb;
*pb = tmp;
}
int main()
{
int a = 10;
int b = 20;
printf("交换前:a=%d b=%d\n", a, b);
Swap2(&a, &b); // 传入的是地址;
printf("交换后:a=%d b=%d\n", a, b);
return 0;
}0x06 函数的嵌套调用
函数和函数之间可以有机合成的;
void new_line() {
printf("hehe ");
}
void three_line() {
int i = 0;
for (i=0; i<3; i++)
new_line(); // three_line又调用三次new_line;
}
int main()
{
three_line(); // 调用three_line;
return 0;
}>>> hehe hehe hehe
0x07 函数的链式访问
把一个函数的返回值作为另外一个函数的参数
int main()
{
/* strlen - 求字符串长度 */
int len = strlen("abc");
printf("%d\n", len);
printf("%d\n", strlen("abc")); // 链式访问
/* strcpy - 字符串拷贝 */
char arr1[20] = {0};
char arr2[] = "bit";
strcpy(arr1, arr2);
printf("%s\n", arr1);
printf("%s\n", strcpy(arr1, arr2)); // 链式访问
return 0;
}面试题
“结果是什么?”
int main()
{
printf("%d", printf("%d", printf("%d", 43)));
return 0;
}>>> 4321
解析: printf函数的作用是打印,但是它也有返回值,printf的返回值是返回字符的长度;printf调用printf再调用printf("%d", 43),首先打印出43,返回字符长度2,打印出2,printf("%d", printf("%d", 43)) 又返回字符长度1,打印出1;所以为4321;
“我们可以试着再MSDN里查找printf函数的详细介绍”

0x08 函数的声明和定义
函数的声明
1. 为了告诉编译器函数名、参数、返回类型是什么,但是具体是不是存在,无关紧要;
2. 函数必须保证“先声明后使用”,函数的声明点到为止即可;
3. 函数的声明一般要放在头文件中;
函数的定义:是指函数的具体实现,交代函数的功能实现;
int main()
{
int a = 10;
int b = 20;
/* 函数的声明 */
int Add(int, int);
int c = Add(a, b);
printf("%d\n", c);
return 0;
}
/* 函数的定义 */
int Add(int x, int y) {
return x + y;
}二、函数的递归
0x00 递归的定义
程序调用自身称为递归(recursion)
1. 递归策略只需要少量的程序就可以描述解题过程所需要的多次重复计算,大大减少代码量;
2. 递归的主要思考方式在于:把大事化小;
注意事项:
1. 存在跳出条件,每次递归都要逼近跳出条件;
2. 递归层次不能太深,避免堆栈溢出;

递归演示
“接收一个整型值,按照顺序打印它的每一位(eg. 输入1234,输出 1 2 3 4)”
void space(int n)
{
if (n > 9)
{
space(n / 10);
}
printf("%d ", n % 10);
}
int main()
{
int num = 1234;
space(num);
return 0;
}>>> 1 2 3 4
解析:

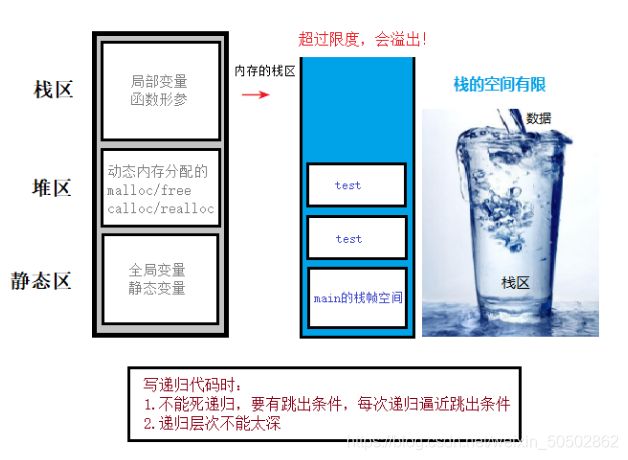
0x01 堆栈溢出
堆栈溢出现象 - stackoverflow
1. 水满则溢,堆栈也有容量限制,当其超出限制,就会发生溢出;
2. 堆栈溢出可以理解为“吃多了吐”,队列溢出就是“吃多了拉”;
3. 程序员的知乎:Stack Overflow - Where Developers Learn, Share, & Build Careers
危害:
1. 堆栈溢出时会访问不存在的RAM空间,造成代码跑飞,此时无法获取溢出时上下文数据,也无法对后续的程序修改提供有用信息;
2. 造成安全威胁,常见的攻击类型有:修改函数的返回地址,使其指向攻击代码,当函数调用结束时程序跳转到攻击者设定的地址,修改函数指针,长跳转缓冲区来找到可溢出的缓冲区;
堆栈溢出现象演示;
void test(int n) {
if(n < 10000) {
test(n + 1);
}
}
int main()
{
test(1);
return 0;
}
0x02 递归的用法
手写strlen函数
1. “创建临时变量count方法”
int my_strlen(char* str) {
int count = 0;
while (*str != '\0') {
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "abc";
int len = my_strlen(arr); // 传过去的是首元素地址;
printf("len = %d\n", len);
return 0;
}
>>> len = 3
2. “不创建临时变量,利用递归完成”
/*
my_strlen("abc");
1 + my_strlen("bc");
1 + 1 + my_strlen("c");
1 +1 + 1 + my_strlen("");
1 + 1 + 1 + 0
3
*/
int rec_strlen(char* str) {
if (*str != '\0')
return 1 + rec_strlen(str+1);
else
return 0;
}
int main()
{
char arr[] = "abc";
int len = rec_strlen(arr);
printf("len = %d\n", len);
return 0;
}>>> len = 3
0x03 递归与迭代
❓ 何为迭代:
“重复执行程序中的循环,直到满足某条件时才停止,亦称为迭代”
迭代法:也称辗转法,是一种不断用变量的旧值递推新值的过程;
求n的阶乘(不考虑溢出);
“阶乘公式: n! = n(n-1)”
int Fac(int n) {
if (n <= 1)
return 1;
else
return Fac(n-1) * n;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fac(n);
printf("%d\n", ret);
return 0;
} 求第n个斐波那契数(不考虑溢出);
“斐波拉契数列:0,1,1,2,3,5,8,13,21,34,55...”

int Fib(int n) {
if (n <= 2)
return 1;
else
return Fib(n-1) + Fib(n-2);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("第%d个斐波拉契数为%d\n", n, ret);
return 0;
}>>> (假设输入10) 第10个斐波那契数为55
>>> (假设输入20)第20个斐波那契数为6765
>>> (假设输入50)...(程序运行中,似乎卡住了)
0x04 非递归
❓ 我们发现了问题,如果用Fib这个函数计算第50个斐波那契数字的时候需耗费很长的时间;
使用Fic函数求10000的阶乘(不考虑结果的正确性),程序会崩溃;
耗费很长时间的原因是 Fib函数在调用的过程中很多计算其实在一直重复,比如计算第50个斐波那契数就要计算第49个,计算第49个斐波那契数就要计算第48个……以此类推;
优化方法:将递归改写为非递归;
箴言:
1. 许多问题是以递归的形式进行解释的,这只是因为他比非递归的形式更为清晰;
2. 但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些;
3. 当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿运行时开销;
使用非递归的方式写;
1 1 2 3 5 8 13 21 34 55...
a b c
int Fib(int n) {
int a = 1;
int b = 1;
int c = 1;
while (n > 2) {
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d\n", ret);
return 0;
}非递归方式求阶乘
int fac(int n) {
int ret = 1;
while(n > 1) {
ret *= n;
n -= 1;
}
return ret;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = fac(n);
printf("%d\n", ret);
return 0;
}三、练习
0x00 练习1
1. 写一个函数可以判断一个数是不是素数;
2. 写一个函数判断一年是不是闰年;
3. 写一个函数,实现一个整形有序数组的二分查找;
4. 写一个函数,每调用一次这个函数,就会将num的值增加1;
写一个is_prime()函数可以判断一个数是不是素数;
“质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。”
#include
int is_prime(int n) {
int i = 0;
for(i=2; i 写一个 is_leap_year 函数判断一年是不是闰年;
int is_leap_year(int y) {
if((y % 4 == 0) && (y % 100 != 0) || (y % 400 == 0))
return 1;
else
return 0;
}
int main()
{
int year = 0;
printf("请输入年份: ");
scanf("%d", &year);
if(is_leap_year(year) == 1)
printf("%d年是闰年\n", year);
else
printf("不是闰年\n");
return 0;
}写一个函数,实现一个整形有序数组的二分查找;
“ int arr[] = {1,2,3,4,5,6,7,8,9,10}; ”
int binary_search(int arr[], int k, int sz) {
int left = 0;
int right = sz - 1;
while(left <= right) {
int mid = (left + right) / 2;
if(arr[mid] < k)
left = mid + 1;
else if(arr[mid] > k)
right = mid - 1;
else
return mid;
}
return -1;
}
int main()
{
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sz = sizeof(arr) / sizeof(arr[0]);
int k = 0;
printf("请输入要查找的值: ");
scanf("%d", &k);
int ret = binary_search(arr, k, sz);
if(ret == -1)
printf("找不到\n");
else
printf("找到了,下标为%d\n", ret);
return 0;
}写一个函数,每调用一次这个函数,就会将num的值增加1;
void Add(int* pnum) {
(*pnum)++;
}
int main()
{
int num = 0;
Add(&num);
printf("%d\n", num);
Add(&num);
printf("%d\n", num);
Add(&num);
printf("%d\n", num);
return 0;
}>>> 1 2 3
0x01 练习2
1. 实现一个函数,判断一个数是不是素数,利用上面实现的函数打印100到200之间的素数;
2. 交换两个整数,实现一个函数来交换两个整数的内容;
3. 自定义乘法口诀表,实现一个函数,打印乘法口诀表,口诀表的行数和列数自己指定;
实现一个函数,判断一个数是不是素数;
“利用上面实现的函数打印100到200之间的素数,打印出一共有多少个素数”
int is_prime(int n) {
int j = 0;
for(j=2; j>>> 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 一共有21个素数
交换两个整数;
“实现一个函数来交换两个整数的内容”
void Swap(int* pa, int* pb) {
int tmp = 0;
tmp = *pa;
*pa = *pb;
*pb = tmp;
}
int main()
{
int a = 10;
int b = 20;
printf("交换前: a=%d, b=%d\n", a, b);
Swap(&a, &b);
printf("交换后: a=%d, b=%d\n", a, b);
return 0;
}>>> 交换前: a=10, b=20 交换后: a=20, b=10
自定义乘法口诀表;
“实现一个函数,打印乘法口诀表,口诀表的行数和列数自己指定”
(eg.输入9,输出9*9口诀表,输出12,输出12*12的乘法口诀表。)
void formula_table(int line)
{
int i = 0;
for(i=1; i<=line; i++) {
int j = 0;
for(j=1; j<=i; j++) {
printf("%dx%d=%-2d ", j, i, i*j);
}
printf("\n");
}
}
int main()
{
int line = 0;
printf("请定义行数: > ");
scanf("%d", &line);
formula_table(line);
return 0;
}0x02 练习3
1. 字符串逆序,非递归方式的实现和递归方式的实现;
2. 写一个函数DigitSum(n),输入一个非负整数,返回组成它的数字之和;
3. 编写一个函数实现n的k次方,使用递归实现;
字符串逆序
编写一个函数 reverse_string(char * string);
将参数字符串中的字符反向排列,不是逆序打印;
要求:不能使用C函数库中的字符串操作函数;
(eg. char arr[] = "abcdef"; 逆序之后数组的内容变成:fedcba)
非递归实现:
int my_strlen(char* str) {
if(*str != '\0') {
return 1 + my_strlen(str + 1);
}
return 0;
}
void reverse_string(char* str) {
int len = my_strlen(str);
int left = 0;
int right = len - 1;
while(left < right) {
char tmp = str[left];
str[left] = str[right];
str[right] = tmp;
left++;
right--;
}
}
int main()
{
char arr[] = "abcdef";
reverse_string(arr);
printf("%s\n", arr);
return 0;
}>>> fedcba
递归实现:
1. [] 写法
int my_strlen(char* str) {
int count = 0;
while(*str != '\0') {
count++;
str++;
}
return count;
}
void reverse_string(char *str) {
int len = my_strlen(str);
int left = 0; // 最左下标
int right = len - 1; // 最右下标
char tmp = str[left];
str[left] = str[right];
str[right] = '\0';
// 判断条件
if(my_strlen(str + 1) >= 2) {
reverse_string(str + 1);
}
str[right] = tmp;
}
int main()
{
char arr[] = "abcdef";
reverse_string(arr);
printf("%s\n", arr);
return 0;
}2. *写法
int my_strlen(char* str) {
if(*str != '\0') {
return 1 + my_strlen(str + 1);
}
return 0;
}
void reverse_string(char* str) {
int len = my_strlen(str);
char tmp = *str;
*str = *(str + len-1);
*(str + len-1) = '\0';
if(my_strlen(str + 1) >= 2) {
reverse_string(str + 1);
}
*(str + len-1) = tmp;
}
int main()
{
char arr[] = "abcdef";
reverse_string(arr);
printf("%s\n", arr);
return 0;
}
写一个递归函数DigitSum(n),输入一个非负整数,返回组成它的数字之和;
“调用DigitSum(1729),则应该返回1+7+2+9,它的和是19”(eg. 输入:1729,输出:19)
int digit_sum(int n) {
if (n > 9) {
return digit_sum(n / 10) + (n % 10);
} else {
return 1;
}
}
int main()
{
int n = 1729;
int ret = digit_sum(n);
printf("%d\n", ret);
return 0;
}>>> 19
解析:
digit_sum(1729)
digit_sum(172) + 9
digit_sum(17) + 2 + 9
digit_sum(1) + 7 + 2 + 9
1+7+2+9 = 19
编写一个函数实现n的k次方,使用递归实现
“递归实现n的k次方”
double Pow(int n, int k) {
if (k == 0)
return 1.0;
else if(k > 0)
return n * Pow(n, k-1);
else // k < 0
return 1.0 / (Pow(n, -k));
}
int main()
{
int n = 0;
int k = 0;
scanf("%d^%d", &n, &k);
double ret = Pow(n, k);
printf("= %lf\n", ret);
return 0;
}>>> (假设输入 2^3)8.000000 (假设输入 2^-3)0.125000
解析:
1. k=0,结果为1;
2. k>0,因为n的k次方等同于n乘以n的k次方-1,可以通过这个“大事化小”;
3. k<0,k为负指数幂时可化为 1 / n^k

第四章 - 数组
前言
本章将对C语言的数组进行讲解,从一维数组开始讲起。已经学了三个章节了,所以本章还附加了三子棋和扫雷两个简单的小游戏,读者可以试着写一写,增加编程兴趣,提高模块化编程思想。
一、一维数组
0x00 何为数组
数组,即为一组相同类型的元素的集合;
0x01 一维数组的创建
数组的创建
① type_t:数组的元素类型;
② arr_name:数组名;
③ const_n:常量表达式,用于指定数组大小;
![]()
注意事项
① 数组创建,[ ] 中要给定常量,不能使用变量;
② 数组 [ ] 中的内容如果不指定大小(不填),则需要初始化;
一维数组创建方法演示

const_n中要给定一个常量,不能使用变量
int main()
{
int count = 10;
int arr[count]; // error
return 0;
}#define N 10
int main()
{
int arr2[N]; // yes
return 0;
}0x02 一维数组的初始化
初始化:在创建数组的同时给数组的内容置一些合理的初始值;
![]()
初始化演示
int main()
{
int arr1[10]; // 创建一个大小为10的int类型数组
char arr2[20]; // 创建一个大小为20的char类型数组
float arr3[1]; // 创建一个大小为1的float类型数组
double arr4[] = {0}; // 创建一个不指定大小的double类型数组(需要初始化)
return 0;
}
字符数组初始化
int main()
{
char ch1[5] = {'b', 'i', 't'};
char ch2[] = {'b', 'i', 't'};
char ch3[5] = "bit"; // 'b', 'i', 't', '\0', '0'
char ch4[] = "bit"; // 'b', 'i', ''t, '\0'
return 0;
}字符数组初始化的两种写法
双引号写法自带斜杠0,花括号写法不自带斜杠0(需要手动添加)
int main()
{
char ch5[] = "bit"; // b, i, t, \0 【自带斜杠0】
char ch6[] = {'b', 'i', 't'}; // b i t 【不自带斜杠0】
printf("%s\n", ch5);
printf("%s\n", ch6);
return 0;
}没有 \0 时,strlen读取时并不会知道什么时候结束,strlen:遇到斜杠0就停止
int main()
{
char ch5[] = "bit"; // b, i, t, \0 【自带斜杠0】
char ch6[] = {'b', 'i', 't'}; // b i t 【不自带斜杠0】
printf("%d\n", strlen(ch5));
printf("%d\n", strlen(ch6));
return 0;
}>>> 3 随机值
当然,你可以给他手动加上一个斜杠0,这样就不会是随机值了;
int main()
{
char ch5[] = "bit"; // b, i, t, \0 【自带斜杠0】
char ch6[] = {'b', 'i', 't', '\0'}; // b, i, t, + '\0' 【手动加上斜杠0】
printf("%d\n", strlen(ch5));
printf("%d\n", strlen(ch6));
return 0;
}>>> 3 3
0x03 一维数组的使用
下标引用操作符: [ ] ,即数组访问操作符;

数组的大小计算方法:整个数组的大小除以一个字母的大小

打印一维数组
可以利用 for 循环,逐一打印数组
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i = 0; i < sz; i++)
printf("%d ", arr[i]);
return 0;
}>>> 1 2 3 4 5 6 7 8 9 10
总结:
① 数组是使用下标来访问的,下标从0开始;
② 可以通过计算得到数组的大小;
0x04 一维数组在内存中的存储
按地址的格式打印:%p (十六进制的打印)

一维数组的存储方式
int main()
{
int arr[10] = {0};
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for(i = 0; i < sz; i++)
printf("&arr[%d] = %p\n", i, &arr[i]);
return 0;
}
运行结果如下:
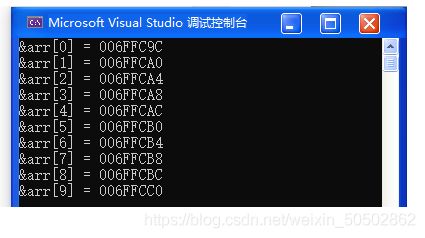
仔细检视输出结果可知:随着数组下标的增长,元素的地址也在有规律的递增;
结论:数组在内存中时连续存放的;

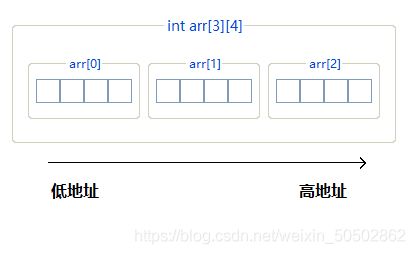
二、二维数组
0x00 二维数组的创建
二维数组 [行] [列]
① const_n1:行
② const_n2: 列
![]()
二维数组的创建
int main()
{
int arr[3][4]; // 创建一个3行4列的int型二维数组;
/*
0 0 0 0
0 0 0 0
0 0 0 0
*/
char arr[3][5]; // 创建一个3行5列的char型二维数组;
double arr[2][4]; // 创建一个2行4列的double型二维数组;
return 0;
}0x01 二维数组的初始化
初始化:在创建数组的同时给数组的内容置一些合理的初始值;
注意事项:
① 二维数组初始化时,行可以省略,但是列不可以省略;
② 二维数组在内存中也是连续存放的;
初始化演示
int main()
{
int arr[3][4] = {1,2,3,4,5};
/*
1 2 3 4
5 0 0 0
0 0 0 0
*/
int arr[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12}; // 完全初始化
int arr2[3][4] = {1,2,3,4,5,6,7}; // 不完全初始化 - 后面补0;
int arr3[3][4] = {{1,2}, {3,4}, {4,5}}; // 指定;
/*
1 2 0 0
3 4 0 0
4 5 0 0
*/
return 0;
}
关于 " 行可以省略,列不可以省略 "
int main()
{
int arr1[][] = {{2,3}, {4,5}}; // error
int arr2[3][] = {{2,3}, {4,5}}; // error
int arr2[][4] = {{2,3}, {4,5}}; // √
return 0;
}
0x03 二维数组的使用
打印二维数组
同样是通过下标的方式,利用两个 for 循环打印
int main()
{
int i = 0;
int j = 0;
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++)
printf("%d", arr4[i][j]); // 二维数组[行][列];
printf("\n"); // 换行;
}
}二维数组在内存中的存储
int main()
{
int arr[3][4];
int i = 0;
int j = 0;
for(i = 0; i < 3; i++) {
for(j = 0; j < 4; j++)
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
return 0;
}运行结果如下:
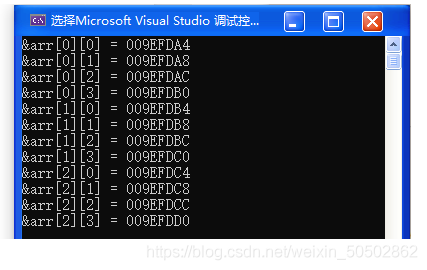
仔细检视输出结果,我们可以分析到其实二维数组在内存中也是连续存存放的;
结论:二维数组在内存中也是连续存放的;
三、数组作为函数参数
0x00 关于数组名
数组名是首元素的地址(有两个例外)
⭕ 例外1:
sizeof(数组名) 计算的是整个数组的大小
![]()
验证
int main()
{
int arr[10] = {0};
printf("%d\n", sizeof(arr));
return 0;
}>>> 40
⭕ 例外2:
& 数组名 表示整个数组,取出的是整个数组的地址
![]()
0x01 冒泡排序(Bubble Sort)
冒泡排序核心思想:两两相邻元素进行比较,满足条件则交换;
① 先确认趟数;
② 写下一趟冒泡排序的过程;
③ 最后进行交换;
注意事项:
① int arr [ ] 本质上是指针,int * arr ;
② 数组传参时,实际上传递的是数组的首元素地址;
③ sz 变量不能在 bubble_sort内部计算,需要在外部计算好再传递进去;
冒泡排序:请编写一个bubble_sort ( ) 函数,升序,int arr[] = {9,8,7,6,5,4,3,2,1,0} ;
#include
void bubble_sort (int arr[], int sz) // 形参arr本质上是指针 int* arr
{
/* 确认趟数 */
int i = 0;
for(i = 0; i < sz; i++)
{
/* 一趟冒泡排序干的活 */
int j = 0;
for(j = 0; j <= (sz-1-i); j++) // -1:最后一趟不用排,-i:减去已经走过的趟
{
/* 如果前面数比后面数大,就交换 */
if(arr[j] > arr[j + 1])
{
/* 创建临时变量交换法 */
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main(void)
{
int arr[] = {9,8,7,6,5,4,3,2,1,0};
int sz = sizeof(arr) / sizeof(arr[0]);
/* 冒泡排序 */
bubble_sort(arr, sz); // 数组传参的时候,传递的是首元素的地址
/* 打印数组 */
int i = 0;
for(i=0; i<=sz; i++)
printf("%d ", arr[i]);
return (0);
}
>>> 0 1 2 3 4 5 6 7 8 9 10
⚡ 算法优化:我们可以置一个变量来判断数组是否有序,如果已经有序,就不需要再冒泡排序了;
#include
void bubble_sort (int arr[], int sz)
{
int i = 0;
for(i = 0; i < sz; i++)
{
int j = 0;
int falg = 1; // 标记1,假设这一趟冒泡排序已经有序
for(j = 0; j <= (sz-1-i); j++)
{
if(arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0; // 仍然不有序,标记为0
}
}
if(flag == 1)
break; // 已经有序了,就不需要再冒泡排序了
}
}
int main(void)
{
int arr[] = {9,8,7,6,5,4,3,2,1,0};
int sz = sizeof(arr) / sizeof(arr[0]);
/* 冒泡排序 */
bubble_sort(arr, sz);
/* 打印数组 */
int i = 0;
for(i=0; i<=sz; i++)
printf("%d ", arr[i]);
return (0);
}
四、实现三子棋(Tic-Tac-Toe)
0x00 游戏介绍

三子棋是一种民间传统游戏,又叫九宫棋、圈圈叉叉、一条龙、井字棋等。将正方形对角线连起来,相对两边依次摆上三个双方棋子,只要将自己的三个棋子走成一条线,对方就算输了。但是,有很多时候会出现和棋的情况。
0x01 实现思路
分模块:当代码量较大,功能较多时,我们可以拆分代码,分模块来实现各个功能;
① test.c 测试游戏的逻辑;
② game.c 游戏相关函数的实现;
② game.h 关于游戏相关的函数声明、符号声明以及头文件的包含;
0x02 游戏界面
test.c
该代码实现游戏界面部分
#define _CRT_SECURE_NO_WARNINGS
#include "game.h"
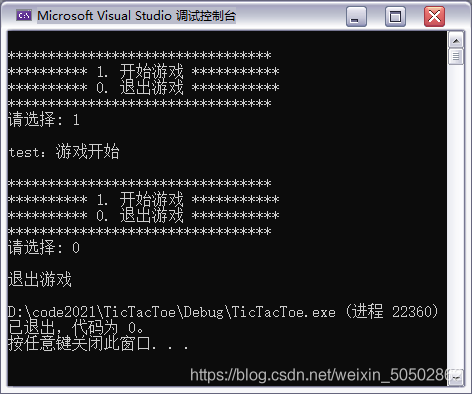
void load_game_menu()
{
printf("\n");
printf("*********************************\n");
printf("********** 1. 开始游戏 ***********\n");
printf("********** 0. 退出游戏 ***********\n");
printf("*********************************\n");
}
int main(int argc, char const* argv[])
{
int input = 0;
do
{
/* 载入游戏菜单 */
load_game_menu();
printf("请选择: ");
scanf("%d", &input);
switch (input)
{
case 1:
printf("\ntest:游戏开始\n");
// game();
break;
case 0:
printf("\n退出游戏\n");
break;
default:
printf("\n输入错误,请重新输入!\n");
break;
}
} while (input);
return( 0 );
}
该部分运行结果如下(完成一部分功能就运行一下看看,及时发现BUG,越早发现越容易找到BUG)
0x03 创建棋盘&初始化棋盘
写game() 函数,创建棋盘,然后将初始化棋盘函数
test.c
void game()
{
/* 创建棋盘 */
char board[ROW][COL];
/* 初始化棋盘 - 初始化空格 */
init_board(board, ROW, COL);
}game.h
#include
/* 宏定义 */
#define ROW 3
#define COL 3
/* 函数声明 */
void init_board(char board[ROW][COL], int row, int col);
void print_board(char board[ROW][COL], int row, int col); game.c
#include "game.h"
void init_board(char board[], int row, int col)
{
int i = 0;
int j = 0;
for (i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
board[i][j] = ' '; // 初始化为空格
}
}
}0x04 打印棋盘
print_board()函数,本质上是打印数组的内容
利用循环画一个棋盘

test.c
void game()
{
//存储数据 - 二维数组
char board[ROW][COL];
//初始化棋盘 - 初始化空格
init_board(board, ROW, COL);
//打印一下棋盘 - 本质是打印数组的内容
print_board(board, ROW, COL);
}game.h
#include
/* 宏定义 */
#define ROW 3
#define COL 3
/* 函数声明 */
void init_board(char board[ROW][COL], int row, int col);
void print_board(char board[ROW][COL], int row, int col); game.c
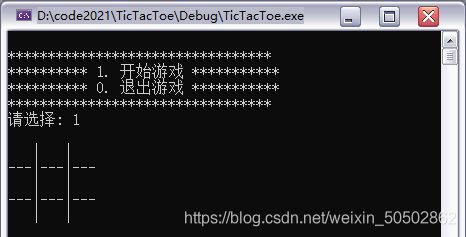
void print_board(char board[ROW][COL], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
printf(" %c | %c | %c \n", board[i][0], board[i][1], board[i][2]);
if (i < row - 1)
printf("---|---|---\n");
}
}
运行结果:
❓如果修改了棋盘大小,怎么办?
代码优化
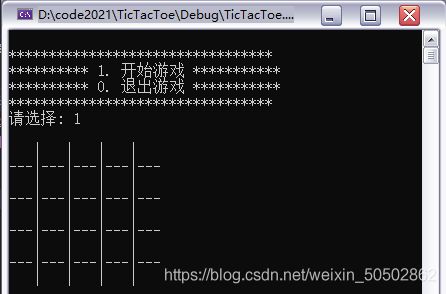
void print_board(char board[ROW][COL], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf(" %c ", board[i][j]);
if (j < col - 1)
printf("|");
}
printf("\n");
if (i < row - 1)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf("---");
if (j < col - 1)
printf("|");
}
printf("\n");
}
}
}我们将 ROW 和 COL 修改为5试试看能否生成一个5x5的棋盘;

0x05 设计玩家回合
test.c game ( )
void game()
{
//存储数据 - 二维数组
char board[ROW][COL];
//初始化棋盘 - 初始化空格
init_board(board, ROW, COL);
//打印一下棋盘 - 本质是打印数组的内容
print_board(board, ROW, COL);
//玩家下棋
player_round(board, ROW, COL);
}game.h player_round ( )
void player_round(char board[ROW][COL], int row, int col);game.c player_round ( )
void player_round(char board[ROW][COL], int row, int col)
{
/* 创建坐标 */
int x = 0;
int y = 0;
/* 要求玩家落子 */
printf("\n[玩家回合]\n");
while (1)
{
printf("请落子: ");
scanf("%d %d", &x, &y);
/* 判断坐标的合法性 */
if (x >= 1 && x <= row && y >= 1 && y <= col)
{
/* 判断坐标是否被占用 */
if (board[x - 1][y - 1] == ' ') // 玩家输的坐标 -1
{
/* 下棋 */
board[x - 1][y - 1] = '*';
break;
}
else
printf("[提示] 该处已经有棋子,请重新输入!\n");
}
else
printf("[提示] 坐标非法,请重新输入!\n");
}
}0x06 设计电脑回合
test.c main ( ) 中存放随机数种子,game ( )
int main(int argc, char const* argv[])
{
srand((unsigned int)time(NULL)); // 置随机数种子
...
}
void game()
{
/* 创建棋盘 */
char board[ROW][COL];
/* 初始化棋盘 - 初始化空格 */
init_board(board, ROW, COL);
/* 打印棋盘 */
print_board(board, ROW, COL);
/* 玩家下棋 */
player_round(board, ROW, COL);
/* 电脑下棋 */
computer_round(board, ROW, COL);
}game.h 引入随机数必要的头文件,computer_round ( )
#include
#include
void computer_round(char board[ROW][COL], int row, int col); game.c computer_round ( )
void computer_round(char board[ROW][COL], int row, int col)
{
printf("[电脑回合]");
while (1)
{
/* 随机坐标 */
int x = rand() % row;
int y = rand() % col;
/* 判断坐标坐标是否被占用 */
if (board[x][y] == ' ')
{
board[x][y] = '#';
break;
}
}
}0x07 游戏状态设计(整合玩家回合和电脑回合)
test.c game ( ) 玩家和电脑走完走打印一下棋盘,更新最新的棋盘数据
void game()
{
//存储数据 - 二维数组
char board[ROW][COL];
//初始化棋盘 - 初始化空格
init_board(board, ROW, COL);
//打印一下棋盘 - 本质是打印数组的内容
print_board(board, ROW, COL);
while (1)
{
//玩家下棋
player_round(board, ROW, COL);
print_board(board, ROW, COL);
//电脑下棋
computer_round(board, ROW, COL);
print_board(board, ROW, COL);
}0x08 判断输赢&宣布胜利条件
test.c game ( )
void game()
{
//存储数据 - 二维数组
char board[ROW][COL];
//初始化棋盘 - 初始化空格
init_board(board, ROW, COL);
//打印一下棋盘 - 本质是打印数组的内容
print_board(board, ROW, COL);
char ret = 0;//接受游戏状态
while (1)
{
//玩家下棋
player_round(board, ROW, COL);
print_board(board, ROW, COL);
//判断玩家是否赢得游戏
ret = is_win(board, ROW, COL);
if (ret != 'C')
break;
//电脑下棋
computer_round(board, ROW, COL);
print_board(board, ROW, COL);
//判断电脑是否赢得游戏
ret = is_win(board, ROW, COL);
if (ret != 'C')
break;
}
if (ret == '*')
{
printf("玩家赢了\n");
}
else if (ret == '#')
{
printf("电脑赢了\n");
}
else
{
printf("平局\n");
}
print_board(board, ROW, COL);
}game.h is_win ( )
char is_win(char board[ROW][COL], int row, int col);game.c is_win ( )
char is_win(char board[ROW][COL], int row, int col)
{
int i = 0;
/* 判断三行 */
for (i = 0; i < row; i++)
{
if (board[i][0] == board[i][1] && board[i][1] == board[i][2] && board[i][1] != ' ')
{
return board[i][1];//
}
}
/* 判断三列 */
for (i = 0; i < col; i++)
{
if (board[0][i] == board[1][i] && board[1][i] == board[2][i] && board[1][i] != ' ')
{
return board[1][i];
}
}
/* 判断对角线 */
if (board[0][0] == board[1][1] && board[1][1] == board[2][2] && board[1][1] != ' ')
{
return board[1][1];
}
if (board[0][2] == board[1][1] && board[1][1] == board[2][0] && board[1][1] != ' ')
{
return board[1][1];
}
/* 判断平局 */
//如果棋盘满了返回1, 不满返回0
int ret = is_full(board, row, col);
if (ret == 1)
{
return 'Q';
}
/* 继续 */
return 'C';
}game.c is_full
int is_full(char board[ROW][COL], int row, int col)
{
int i = 0;
int j = 0;
for (i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
if (board[i][j] == ' ')
{
return 0; // 棋盘没满
}
}
}
return 1; // 棋盘满了
}0x09 代码运行
玩家获胜
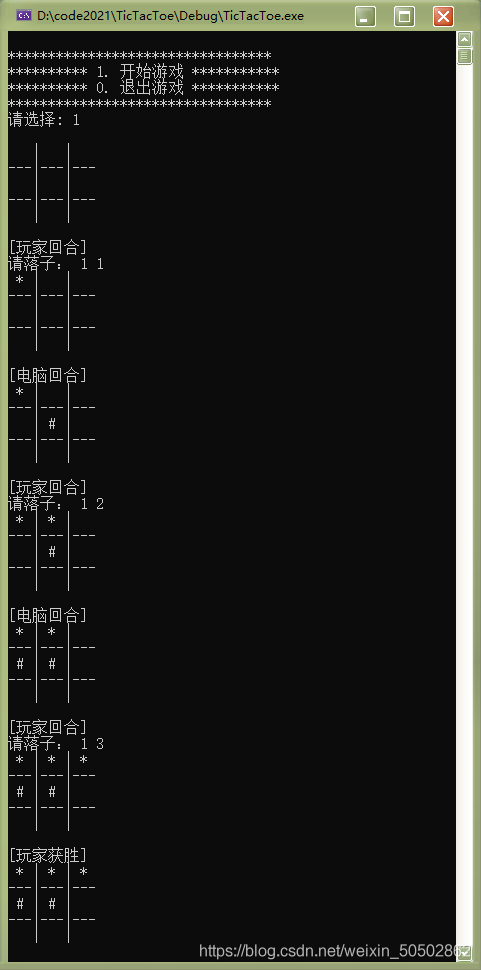
电脑获胜

平局

五、扫雷
0x00 游戏介绍
扫雷是一款大众类的益智小游戏,于1992年发行。
游戏目标是在最短的时间内根据点击格子出现的数字找出所有非雷格子,同时避免踩雷,踩到一个雷即全盘皆输。

0x01 实现思路
分模块:
① test.c 测试游戏的逻辑;
② game.c 游戏相关函数的实现;
② game.h 关于游戏相关的函数声明、符号声明以及头文件的包含;
0x02 游戏界面
思路:
① 设计开始页面,提供选择以下选择:开始游戏、退出游戏(并且检查是否输入错误);
② 为了实现玩一把还能继续玩,使用do...while函数,用户不输入0程序就一直运行;
③ 引入头文件 game.h,将头文件、函数声明、宏定义等全部置于game.h中;
test.c main函数、LoadGameMenu函数
#define _CRT_SECURE_NO_WARNINGS 1
#include "game.h"
void LoadGameMenu()
{
printf("\n");
printf("*********************************\n");
printf("********** 1. 开始游戏 ***********\n");
printf("********** 0. 退出游戏 ***********\n");
printf("*********************************\n");
}
int main()
{
int input = 0;
do {
LoadGameMenu();
printf("请选择: ");
scanf("%d", &input);
switch (input) {
case 1:
printf("开始游戏\n");
break;
case 0:
printf("退出游戏\n");
break;
default:
printf("选择错误,请重新选择\n");
break;
}
} while (input);
return (0);
}
game.h
#include 代码运行结果如下
0x03 初始化9x9的棋盘
思路:
① 设计Game函数,用来调用实现游戏功能的函数;
② 创建两个二维数组,分别存放布置好的雷的信息和已排查的雷的信息;
③ 将他们初始化,布置雷的信息用0表示(暂且设定0为非雷,1为雷),已排查的雷的信息用 * 表示;
④ 由于需要一个9x9的扫雷棋盘,外面还需要显示对应的坐标,所以实际数组的大小应该为11x11;
⑤ 定义ROW和COL,为了后续可以修改棋盘,ROWS = ROW+2,COLS = COL+2;
test.c ( main函数、Game函数 )
void Game()
{
char mine[ROWS][COLS] = { 0 }; // 存放布置好雷的信息
char show[ROWS][COLS] = { 0 }; // 存放排查好雷的信息
/* 初始化棋盘 */
InitBoard(mine, ROWS, COLS, '0');
InitBoard(show, ROWS, COLS, '*');
}
int main()
{
...
case 1:
Game(); // 扫雷游戏
break;
...
return (0);
}game.h
#include
#define ROW 9
#define COL 9
#define ROWS ROW+2
#define COLS COL+2
/* 初始化棋盘 */
void InitBoard(char board[ROWS][COLS], int rows, int cols, char set);
test.c ( InitBoard 函数 )
void InitBoard(
char board[ROWS][COLS],
int rows,
int cols,
char set
)
{
int i = 0;
int j = 0;
for (i = 0; i < rows; i++) {
for (j = 0; j < cols; j++) {
board[i][j] = set;
}
}
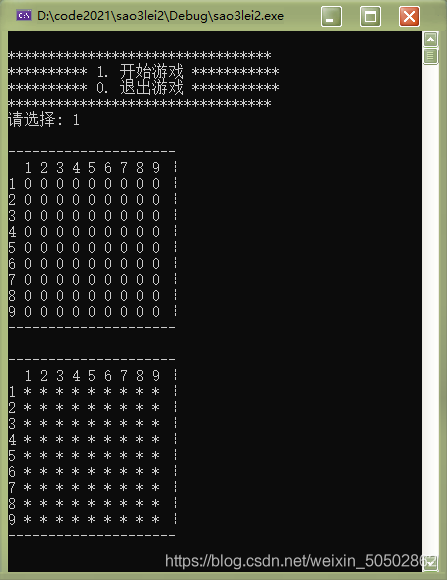
}0x04 打印棋盘
思路:
① 设计一个打印棋盘的函数,把棋盘打印出来;
② 虽然mine棋盘是不能被玩家看到的,但是为了测试我们把mine棋盘也打印出来;
③ 由于棋盘为9x9,不能出9x9之外,所以传入的应该是ROW和COL,而不是ROWS和COLS;
test.c ( Game 函数 )
void Game()
{
char mine[ROWS][COLS] = { 0 }; // 存放布置好雷的信息
char show[ROWS][COLS] = { 0 }; // 存放排查好雷的信息
/* 初始化棋盘 */
InitBoard(mine, ROWS, COLS, '0');
InitBoard(show, ROWS, COLS, '*');
/* 打印棋盘 */
DisplayBoard(mine, ROW, COL);
DisplayBoard(show, ROW, COL);
}
int main() {...}game.h
...
/* 打印棋盘 */
void DisplayBoard(char board[ROWS][COLS], int row, int col);game.c ( DisplayBoard 函数 )
void DisplayBoard (
char board[ROWS][COLS],
int row,
int col
)
{
int i = 0;
int j = 0;
printf("\n---------------------\n"); // 分界线
/* 打印列号 */
for (i = 0; i <= col; i++) {
if (i == 0) {
printf(" "); // 去除左上角xy的交接零点部分
continue;
}
printf("%d ", i);
if (i == 9)
{
printf("┆"); // 打印竖边框
}
}
printf("\n");
for (i = 1; i <= row; i++) {
/* 打印行号 */
printf("%d ", i);
for (j = 1; j <= col; j++) {
/* 打印内容 */
printf("%c ", board[i][j]);
if (j == 9) {
printf("┆"); // 打印竖边框
}
}
printf("\n"); // 打印完一行的内容后换行
}
printf("---------------------\n"); // 分界线
}
运行结果如下
0x05 布置雷
思路:
① 随机生成若干个雷(暂且定为10个),可以通过 rand 函数实现;( srand放在主函数中 );
② 由于布雷要在9x9棋盘内部布置,不能出9x9之外,所以传入的应该是ROW和COL;
③ 为了测试雷是否布置成功,我们把mine棋盘先打印出来;
④ define 雷的个数,为了测试,布置10个雷;
test.c ( Game 函数 )
void Game()
{
char mine[ROWS][COLS] = { 0 }; // 存放布置好雷的信息
char show[ROWS][COLS] = { 0 }; // 存放排查好雷的信息
/* 初始化棋盘 */
InitBoard(mine, ROWS, COLS, '0');
InitBoard(show, ROWS, COLS, '*');
/* 打印棋盘 */
// DisplayBoard(mine, ROW, COL);
DisplayBoard(show, ROW, COL);
/* 布置雷 */
SetMine(mine, ROW, COL);
DisplayBoard(mine, ROW, COL); // 暂时打印出来
}
int main()
{
srand((unsigned int)time(NULL)); // 置随机数种子
...
}
game.h
#include
#include
#include
#define EASY_COUNT 10
...
/* 设置雷 */
void SetMine(char mine[ROWS][COLS], int row, int col); game.c ( SetMine 函数 )
void SetMine (
char mine[ROWS][COLS],
int row,
int col
)
{
/* 布置10个雷 */
int count = EASY_COUNT;
while (count) {
/* 生成随机的下标 */
int x = rand() % row + 1; // 余上row变成个位数
int y = rand() % col + 1; // 余上col变成个位数
if (mine[x][y] == '0') { // 判断某个坐标是否已经有雷
mine[x][y] = '1'; // 设1为雷
count--;
}
}
}运行结果

0x06 排查雷
思路:
① 让玩家排查雷,输入雷的坐标进行排查,并且判断玩家输入的坐标是否合法;
② 如果输入的坐标上有雷(为1)则宣告游戏失败,打印出棋盘让玩家死个明白;
③ 如果输入的坐标上没有雷,那么统计周围有几个雷,并且将雷的个数显示在该坐标上,显示排查出雷的信息;
④ 统计周围雷的方法如下图所示,以xy为中心的上下左右、上左上右、下左下右的坐标进行count;
⑤ 这里要传入 ROWS 和 COLS ,就算xy在边上,计算xy周围时,也不会导致数组越界;

test.c ( Game 函数 )
void Game()
{
char mine[ROWS][COLS] = { 0 }; // 存放布置好雷的信息
char show[ROWS][COLS] = { 0 }; // 存放排查好雷的信息
/* 初始化棋盘 */
InitBoard(mine, ROWS, COLS, '0');
InitBoard(show, ROWS, COLS, '*');
/* 打印棋盘 */
//DisplayBoard(mine, ROW, COL);
DisplayBoard(show, ROW, COL);
/* 布置雷 */
SetMine(mine, ROW, COL);
//DisplayBoard(mine, ROW, COL);
/* 排查雷 */
FindMine(mine, show, ROW, COL);
}
int main() {...}game.h
...
/* 排查雷 */
void FindMine(char mine[ROWS][COLS], char show[ROWS][COLS],int row, int col);
game.c ( FineMine 函数 和 get_mine_count 函数 )
static int get_mine_count (
char mine[ROWS][COLS],
int x,
int y
)
{
/*
* (x-1, y-1) (x-1, y) (x-1, y+1)
*
* ( x , y-1) ( x , y) ( x , y+1)
*
* (x+1, y-1) (x+1, y) (x+1, y+1)
*/
return (
mine[x - 1][y] +
mine[x - 1][y - 1] +
mine[x][y - 1] +
mine[x + 1][y - 1] +
mine[x + 1][y] +
mine[x + 1][y + 1] +
mine[x][y + 1] +
mine[x - 1][y + 1] - 8 * '0'
);
}
void FindMine (
char mine[ROWS][COLS],
char show[ROWS][COLS],
int row,int col
)
{
/*
* 注释:
* 1. 输入排查的坐标
* 2. 检查坐标处是不是雷
* (1)是雷 - 很遗憾炸死了 - 游戏结束
* (2)不是雷 - 统计坐标周围有几个雷 - 存储排查类的信息
*/
int x = 0;
int y = 0;
while (1) {
printf_s("\n请输入要排查雷的坐标: "); // x(1~9) y(1~9)
scanf_s("%d%d", &x, &y);
/* 判断坐标的合法性 */
if (x >= 1 && x <= row && y >= 1 && y <= col) {
if (mine[x][y] == '1') {
/* 是雷,宣告游戏失败 */
printf_s("\n很遗憾,你被炸死了\n");
DisplayBoard(mine, row, col);
break;
}
else {
/* 不是雷,统计x,y坐标有几个雷 */
int count = get_mine_count(mine, x, y);
show[x][y] = count+'0'; // ASCII化为字符
/* 显示排查出的信息 */
DisplayBoard(show, row, col);
}
}
else {
printf("\n坐标非法,请重新输入!\n");
}
}
}0x07 设置胜利条件
思路:
① 加入一个计数器win,统计排查的雷的个数,当个数等于雷数时,说明雷都被排完了,宣告游戏胜利;
② while 循环的条件可以设置为 只要 win 仍然小于 9x9 减雷数,就进入循环;
game.c ( FineMine 函数 )
void FindMine (
char mine[ROWS][COLS],
char show[ROWS][COLS],
int row,int col
)
{
/*
* 注释:
* 1. 输入排查的坐标
* 2. 检查坐标处是不是雷
* (1)是雷 - 很遗憾炸死了 - 游戏结束
* (2)不是雷 - 统计坐标周围有几个雷 - 存储排查类的信息
*/
int x = 0;
int y = 0;
int win = 0;
while (win= 1 && x <= row && y >= 1 && y <= col) {
if (mine[x][y] == '1') {
/* 是雷,宣告游戏失败 */
printf_s("\n很遗憾,你被炸死了\n");
DisplayBoard(mine, row, col);
break;
}
else {
/* 不是雷,统计x,y坐标有几个雷 */
int count = get_mine_count(mine, x, y);
show[x][y] = count+'0'; // ASCII化为字符
/* 显示排查出的信息 */
DisplayBoard(show, row, col);
win++;
}
}
else {
printf("\n坐标非法,请重新输入!\n");
}
}
if (win == row * col - EASY_COUNT) {
printf("恭喜你,排雷成功!\n");
DisplayBoard(mine, row, col);
}
} 0x08 代码运行
排查雷的坐标

非法输入坐标

很遗憾,你被炸死了

第五章 - 操作符
前言:
本章将对C语言操作符进行深度的讲解,将每种操作符都单独拿出来精讲。最后添加了些简单的练习题,并配有详细解析。
一、算术操作符
0x00 概览

注意事项:
① 除了 % 操作符之外,其他的几个操作符都可以作用于整数和浮点数;
② 对于 / 操作符,如果两个操作数 都为整数 ,执行整数除法;
③ 对于 / 操作符,只要有浮点数出现 ,执行的就是浮点数除法;
④ 对于 % 操作符的两个数 必须为整数;
0x01 整数除法
定义:对于 / 操作数,如果两个操作数都为整数,执行整数除法;
❓ 整数除法:即一个整数除以另一个整数结果为只保留整数;
代码演示:
int main()
{
int a = 5 / 2; // 5÷2 = 商2余1
printf("a = %d\n", a); // 输出的结果是什么?
return 0;
}运行结果: a = 2
0x02 浮点数除法
定义:只要有浮点数出现,执行的就是浮点数除法;
❓ 浮点数除法:结果会保留小数部分( 给定对应的%前提下 );
代码演示:
int main()
{
double a = 5 / 2.0; // 5÷2 = 2.5,有1个浮点数,条件就成立,执行浮点数除法
printf("a = %lf\n", a); // 输出的结果是什么?
return 0;
} 运行结果: a = 2.500000
0x03 取模操作符
定义:取模运算即 求两个数相除的余数 ,两个操作数必须为非0整数;
注意事项:
① 两个操作数必须为整数;
② 两个操作数均不能为0(没有意义);
代码演示:
int main()
{
int a = 996 % 10; // 996 mod 10 = 6
int b = 996 % 100; // 996 mod 100 = 96
printf("%d\n", a);
printf("%d\n", b);
return 0;
}
运行结果:6 96
❌ 错误演示:
int main()
{
double a = 5 % 2.0; // ❌ 操作数必须为整数
printf("a = %lf\n", a);
return 0;
} 运行结果:error: invalid operands to binary % (have 'int' and 'double')
int main()
{
int a = 2 % 0; // ❌ 操作数不能为0
printf("%d\n", a);
return 0;
} 运行结果:warning: division by zero [-Wdiv-by-zero]
0x04 整除和浮点除的区分
代码演示:我们想得到 1.2
int main()
{
int a = 6 / 5;
printf("%d\n", a);
return 0;
}
运行结果: 1 ( 但是运行结果为1 )
❓ 难道是因为我们用的是 %d 打印的原因吗?
int main()
{
float a = 6 / 5;
printf("%f\n", a);
return 0;
}
运行结果: 1.000000 ( 仍然不是想要的1.2,运行结果为1.000000 )
 (气急败坏,无能狂怒)
(气急败坏,无能狂怒)
解析:其实问题不在于存到a里能不能放的下小数的问题,而是 6 / 5 得到的结果已经是为1了(执行的是整除);
解决方案:把6改成6.0,或把5改成5.0,也可以都改,让它执行浮点数除法;
int main()
{
float a = 6 / 5.0;
printf("%f\n", a);
return 0;
}
运行结果: 1.200000
❓ 虽然代码可以运行,但是编译器报了一个 warning,让我们来瞅瞅是咋回事:

解析:直接写出的这个数字(6.0或5.0),编译器会默认认为它是 double 类型
那么计算后a的结果也会是 double 类型(双精度浮点数);
如果双精度浮点数的值放到一个单精度浮点数里的话,可能会丢失精度,
好心的编译器就发出了这样的一个警告,这个是正常的;
如果你不想看到这样的警告,你可以这么做:
int main()
{
float a = 6.0f / 5.0f; // “钦定” 为float单精度浮点数
printf("%f\n", a);
return 0;
}int main()
{
double a = 6.0 / 5.0; // 改成double
printf("%lf\n", a);
return 0;
}
关于精度丢失的现象:
① 有效数字位数超过7位的时候,将会四舍五入,会丢失较多精度;
② 在运行较大数值运算的时候,将有可能产生溢出,得到错误的结果;
二、移位操作符
0x00 概览

概念: 移位操作符分为 "左移操作符" 和 "右移操作符" ;

注意事项:
① 移位操作符的 操作数必须为整数;
② 对于运算符,切勿移动负数位(这是标准为定义的行为);
③ 左移操作符有乘2的效果,右移操作符有除2的效果(左乘2,右除2);
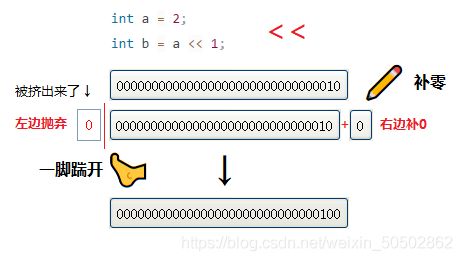
0x01 左移操作符
移位规则:左边丢弃,右边补0 ;(左边的数给爬,至于爬多远,还要看操作数是多少)
代码演示:
int main()
{
int a = 2;
int b = a << 1; // 将a的二进制位向左移动1位;
printf("b = %d\n", b); // 4 (左移操作符有乘2的效果)
/*
00000000000000000000000000000010
0|000000000000000000000000000010+0 (左边丢弃,右边补0)
*/
return (0);
}运行结果: b = 4
图解左移操作符:
0x02 右移操作符
移位规则:两种移位规则;
① 算术右移:右边丢弃,左边补原符号位(通常为算术右移);
② 逻辑右移:右边丢弃,左边补0;
注意事项:
① C编译器中默认为算术右移,如果是 signed 有符号类型时,需要注意;
② 使用 unsigned 无符号类型时,算术右移和逻辑右移的结果是一样的;
int main()
{
int a = 10;
int b = a >> 1; // 把a的二进制位向右移动一位
printf("b = %d\n", b); // 5 (右移操作符有除2的效果)
/*
00000000000000000000000000001010
0+0000000000000000000000000000101|0
*/
return 0;
}运行结果: b = 5
解析: 为了搞懂什么是算术右移,什么是逻辑右移,我们不得不了解整数的二进制表示方式:
0x03 整数的二进制表示方式(初步了解)
负数-1要存放在内存中,内存中存放的是二进制的补码;
整数的二进制表示形式(原反补):
① 原码:直接根据数值写出的二进制序列,即为原码;
② 反码:原码的符号位不变,其他位置按位取反,即为反码(如果不知道什么是按位取反,后面会讲);
③ 补码:反码 + 1,即为补码; (内存中存放的是补码)
-1 的原码、反码、补码:

此时回到上述问题,如果右移时采用逻辑右移:
int main()
{
int a = -1;
int b = a >> 1;
printf("b = %d\n", b);
return 0;
}运行结果: b = -1
图解逻辑右移与算数右移:

❌ 错误演示:操作数不能是负数!
int main()
{
int num = 10;
num >> -1; // ❌ a<<1 ?? 垃圾代码
return 0;
}运行结果: warning: right shift count is negative [-Wshift-count-negative]

三、位操作符

0x00 概览
位操作符:按位与、按位或、按位异或;

注意事项:位操作符的 操作数必须为整数;
0x01 按位与 &
定义:按2进制按位与,只有对应的两个二进位都为1时,结果位才为1;(必须都为真,结果才为真)

代码演示:按位与的用法
int main()
{
int a = 3;
int b = 5;
int c = a & b; // a和b都为真
printf("%d", c);
return 0;
}
运行结果: 1
0x02 按位或
定义:只要对应的两个二进位有一个为1时,结果位就为1;(只要有一个为真,结果就为真)

代码演示:按位或的用法
int main()
{
int a = 0;
int b = 5;
int c = a | b; // a和b有一个为真
printf("%d\n", c);
return 0;
}运行结果: 5
int main()
{
int a = 0;
int b = 0;
int c = a | b; // a和b都为假
printf("%d\n", c);
return 0;
}
运行结果: 0
0x03 按位异或 ^
定义:相同为0,相异为1;(上下相同就为假,不同为真)
巧记:觉得按位异或不好记? 试着这么记
" 这对恋人是异性恋吗?是回1,不是回0 " 0 1 是, 1 0 是, 1 1 不是, 0 0 不是;
※ 异或:a⊕b = (¬a ∧ b) ∨ (a ∧¬b) 如果a、b两个值不相同,则异或结果为1,反之结果为0;

代码演示:按位异或的用法
int main()
{
int a = 3;
int b = 5;
int c = a ^ b; // a和b不同
printf("%d\n", c);
return 0;
}运行结果: 6
int main()
{
int a = 3;
int b = 3;
int c = a ^ b; // a和b相同
printf("%d\n", c);
return 0;
}运行结果: 0
0x04 位操作符的应用
面试题:交换两个 int 变量的值,不能使用第三个变量;
(即a=3,b=5,交换之后a=5,b=3)
1. 临时变量法 - 该题禁止了此方法,但是在工作中建议使用该方法;
int main()
{
int a = 3;
int b = 5;
printf("交换前: a = %d, b = %d\n", a, b);
int tmp = a; // 创建一个临时变量,存放a
a = b; // a变为b
b = tmp; // b变为原来的a
printf("交换后: a = %d, b = %d\n", a, b);
return 0;
}运行结果: 交换前: a = 3, b = 5;交换后:a=5, b=3
2. 加减交换法 - 存在缺陷:可能会溢出(超过整型的存储极限)
int main()
{
int a = 3;
int b = 5;
printf("交换前: a = %d, b = %d\n", a, b)
a = a + b;
b = a - b;
a = a - b;
printf("交换后: a = %d, b = %d\n", a, b);
return 0;
}运行结果: 交换前: a = 3, b = 5;交换后:a=5, b=3
解析:第一步: 3 + 5 = 8,第二步: 8 - 5 = 3,第三步: 8 - 3 = 5,此时,a = 5, b = 3 ;
3. 异或交换法 - 缺点:可读性差,执行效率低下;
int main()
{
int a = 3;
int b = 5;
printf("交换前: a = %d, b = %d\n", a, b);
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("交换后: a = %d, b = %d\n", a, b);
return 0;
}运行结果: 交换前: a = 3, b = 5;交换后:a=5, b=3
解析:

编写代码实现:求一个整数存储在内存中的二进制中1的个数
1. 一般解法 - 模除
int main()
{
int num = 0;
int count = 0;
scanf("%d", &num);
/* 统计num的补码中有几个1 */
while(num != 0) {
if(num % 2 == 1) {
count++;
}
num = num / 2;
}
printf("%d\n", count);
return 0;
}
运行结果: (假设输入3) 2
解析:

2. 移位操作符 + 按位与 结合的方式解决
思路:
① 利用 for 循环,循环32/64次;
② 每次 if 判断,将 num 右移 i 位的结果与 1 按位与,为真则说明为1,count++;
③ 如果为假,进入下一次循环,最后打印出 count 即可;
int main()
{
int num = 0;
int count = 0;
scanf("%d", &num);
int i = 0;
/* 32位系统,至少循环32次 */
for(i=0; i<32; i++) {
if( ((num >> i) & 1) == 1 ) // 如果num右移i位的结果和1按位与,为真
count++;
}
printf("%d\n", count);
return 0;
}
运行结果: (假设输入3) 2
四、赋值操作符
0x00 概览

用法:用来重新赋值一个变量的值;

0x01 一般赋值
赋值方法:

赋值操作符是个很棒的操作符,它可以让你得到一个你之前不满意的值:
int main()
{
int weight = 120; // 体重120,不满意,我要变瘦点!
weight = 89; // 不满意就赋值~
double salary = 10000.0; // 我:老板!我要加薪!
salary = 20000.0; // 老板:好的,没有问题!
return 0;
}0x02 连续赋值
定义:连续赋值(continuous assignment),即一次性赋多个值;
建议:建议不要使用连续赋值,会让代码可读性变差,而且还不容易调试;

代码演示:连续赋值的使用方法;
int main()
{
int a = 10;
int x = 0;
int y = 20;
a = x = y+1;// 连续赋值
x = y+1;
a = x;
// 这样写更加清晰爽朗而且易于调试
return 0;
}0x03 复合赋值符
意义:复合赋值运算符是为了减少代码输入量而设计的;
注意事项:
① x = x + 10 与 x += 10 的意义等价;
② 可以提高代码的整洁度,让代码更加整洁;
代码演示:复合赋值符的使用方法
int main()
{
int x = 10;
x = x + 10;
x += 10; //复合赋值符的写法 (和上面是等价的)
return 0;
}五、单目操作符
0x00 概览
❓ 什么是单目操作符?
在运算中只有一个操作数的操作符,叫做单目操作符;

0x01 逻辑反操作 !
作用:可以让真变为假,也可以让假变为真;

逻辑反操作的用法:
int main()
{
int a = 10;
printf("%d\n", !a); // 将真变为假, 0
int b = 0;
printf("%d\n", !b); // 将假变为真, 1
return 0;
}
运行结果: 0 1
最常用的用法:
int main()
{
int flag = 5;
if ( flag ) // flag != 0 -> hehe
printf("hehe\n"); // flag为真,打印hehe
if ( !flag ) // flag == 0 -> haha
printf("haha\n"); // flag为假,打印haha
return 0;
}运行结果: hehe
0x02 负值 -
作用:把一个数置为负数;

负值的用法:
int main()
{
int a = 10;
a = -a; // 在a前面放一个负号
printf("%d", a);
return 0;
}运行结果: -10
0x03 正值 +
作用:一般都省略掉了,和数学里面一样;
加号一般都不写的:
int main()
{
int a = +5; // 一般都省略掉了,和数学里一样
printf("%d", a);
return 0;
}运行结果: 5
0x04 取地址操作符 & 与 解引用操作符 *

理解:
① 取地址操作符可以理解为取快递;
② 解引用操作符可以理解为拆快递;
(指针章节会详解)
用法演示:
int main()
{
int a = 10;
int* pa = &a; // 取地址操作符 ( 随后将地址存放在int* pa里 )
*pa = 20; // 解引用操作符 通过p里存的值找到它所指向的对象;
// *p就是a, 将*p赋值为20,a就会变为20;
return 0;
}解析:
① 首先 int* pa 是一个指针变量(如果不知道什么是指针,可以暂且理解为是一个快递包裹);
② 快递包裹里装的是内存地址,我们使用 取地址操作符& 取出 a 的地址,存放到这个包裹里(int* pa = &a);
③ 这时,我们想修改 a 的值,我们要打开包裹进行修改,可以通过 解引用操作符* 将 a 修改为新的值(*pa = 20);
0x05 操作数的类型长度 sizeof( )
作用:计算变量所占内存空间的大小,单位是字节;

注意事项:
① sizeof 括号中的表达式不参与运算;
② sizeof 本质上不是函数,所以可以省略括号,但是 sizeof 后面是类型时不可以省略括号;
sizeof 的用法:
int main()
{
int a = 10;
char c = 'a';
char* pc = &c;
int arr[10] = {0};
/* sizeof 计算的变量所占内存空间的大小,单位是字节 */
printf("%d\n", sizeof(a)); //4;
printf("%d\n", sizeof(int)); //4;
printf("%d\n", sizeof(c)); //1;
printf("%d\n", sizeof(char)); //1;
printf("%d\n", sizeof(pc)); //4; 32位系统中
printf("%d\n", sizeof(char*)); //4;
printf("%d\n", sizeof(arr)); //40; 4x10=40
printf("%d\n", sizeof( int [10] )); //40;
return 0;
} 下列代码的运行结果为什么?
int main()
{
short s = 0;
int a = 10;
printf("%d\n", sizeof(s = a + 5));
printf("%d\n", s);
}
运行结果: 2 0
❓ 为什么是 s 还是 0 呢? s = a + 5,s 不应该是 15吗……
解析:15个15,sizeof 括号中的表达式不参与运算!

下列代码输出后 (1) (2) (3) (4) 分别是多少(32位)?
void test1(int arr[]) //传参传过来的是首元素
{
printf("%d\n", sizeof(arr)); // (3)
}
void test2(char ch[])
{
printf("%d\n", sizeof(ch)); // (4)
}
int main()
{
int arr[10] = {0};
char ch[10] = {0};
printf("%d\n", sizeof(arr)); // (1)
printf("%d\n", sizeof(ch)); // (2)
test1(arr);
test2(ch);
return 0;
}答案:(1)40 (2)10 (3)4 (4)4
解析:
① (1) 一个int型大小为4,数组大小为10,4x10 = 40,所以答案为40;
② (3) 一个char型大小为1,数组大小为10,1x10 = 10,所以答案为10;
③ (3) (4) 数组名传参,传过去的虽然是是首元素地址,因为首元素的地址也是地址
所以要拿一个指针来接收它。本质上,arr 和 ch 为指针,而指针的大小,
是4个字节或者8个字节(具体是几个字节看操作系统),题目中为32位,所以答案为4;
❌ 错误示范:
int main()
{
/* sizeof 后面是类型时不可以省略括号 */
int a = 10;
printf("%d\n", sizeof a ); // 可以省略 ✅
printf("%d\n", sizeof int); // error! 不可以省略 ❌
return 0;
}
运行结果: error: expected expression before 'int' printf("%d\n", sizeof int);
0x06 按位取反 ~
作用:对一个数按位取反,0 变 1, 1 变 0;

注意事项:
① 按位取反,1~0互换,包括符号位;
② 按位取反后,是补码;
巧用按位取反:将某一个数的二进制位从右到左数的第三个数改为1;
int main()
{
int a = 11;
a = a | (1<<2);
// 00000000000000000000000000001011 11
// | 00000000000000000000000000000100 让他和“这个数字”按位或
//-------------------------------------
// 00000000000000000000000000001111 此时这一位变成了1
// 如何创造出“这个数字”呢?
// 1<<2;
// 00000000000000000000000000000001 1
// 00000000000000000000000000000100 把他向左移动两位时1就到这了
// a|(1<<2)
// 00000000000000000000000000001011
// | 00000000000000000000000000000100
//-------------------------------------
// 00000000000000000000000000001111
printf("%d\n", a); //15
a = a & ( ~ (1<<2) );
// 如何再改回去? ↓ 让这一位改成0
// 00000000000000000000000000001111 让他和0按位与
// | 11111111111111111111111111111011 给他按位与一个“这样的数字”
//-------------------------------------
// 00000000000000000000000000001011 把这一位又还原成0了
// 1<<2,同上
// 00000000000000000000000000000100 这个数字按位取反可以得到 ...1011
// ~
// 11111111111111111111111111111011
// a& ~
// 00000000000000000000000000001111 15
// & 11111111111111111111111111111011
//-------------------------------------
// 00000000000000000000000000001011 11
printf("%d\n", a); //11
return 0;
}运行结果: 15 11
0x07 前置、后置++
定义:
① 前置++:先加加,后使用;
② 后置++:先使用,再加加;
代码演示:后置++的用法
int main()
{
int a = 10;
printf("%d\n", a++); // 后置++:先使用,再++
printf("%d\n", a); // a此时已变为11
return 0;
}运行结果: 10 11
代码演示:前置++的用法
int main()
{
int a = 10;
printf("%d\n", ++a); // 前置++:先++,再使用
printf("%d\n", a);
return 0;
}运行结果: 11 11
0x08 前置、后置 --
定义:
① 前置--:先减减,后使用;
② 后置++:先使用,再减减;
代码演示:后置 - - 的用法
int main()
{
int a = 10;
printf("%d\n", a--);
printf("%d\n", a);
return 0;
}运行结果: 10 9
代码演示:后置 - - 的用法
int main()
{
int a = 10;
printf("%d\n", --a);
printf("%d\n", a);
return 0;
}运行结果: 9 9
0x09 强制类型转换(type)
作用:强制类型转换可以把变量从一种类型转换为另一种数据类型;

注意事项:

代码演示:强制类型转换的用法
int main()
{
int a = (int)3.14;
return 0;
}六、关系操作符
注意事项:在编程的过程中要小心 = 和 == 不小心写错,导致的错误;

代码演示:一般用于条件语句中
int main()
{
int a = 3;
int b = 5;
if(a < b) {
...
}
if(a == b) {
...
}
if(a <= b) {
...
}
if(a != b) {
...
}
return 0;
}七、逻辑操作符
0x00 逻辑与 &&
说明:逻辑与,a和b都为真时结果才为真;(都为真才为真)

代码演示:
1. a和b都为真时,结果就为真,c = 1;
int main()
{
int a = 3;
int b = 5;
int c = a && b; // 逻辑与 “并且” a和b都为真时才返回真
printf("%d\n", c);
return 0;
}运行结果: 1(真)
2. a和b只要有一个为假,结果就为假,c = 0;
int main()
{
int a = 0;
int b = 5;
int c = a && b;
printf("%d\n", c);
return 0;
}运行结构: 0(假)
0x01 逻辑或 ||
说明:a和b有一个为真,结果就为真;(有真则为真)
代码演示:
1. a和b只要有一个为真,结果就为真;
int main()
{
int a = 0;
int b = 5;
int c = a || b; //逻辑与 “并且” a和b都为真时才返回真
printf("%d\n", c);
return 0;
}运行结果: 1 (真)
2. a和b同时为假的时候,结果才为假;
int main()
{
int a = 0;
int b = 0;
int c = a || b; //逻辑与 “并且” a和b都为真时才返回真
printf("%d\n", c); // 0
return 0;
}运行结果: 0 (假)
0x02 练习
笔试题:(出自360)
❓ 1. 程序输出的结果是什么
int main()
{
int i = 0, a=0,b=2,c=3,d=4;
i = a++ && ++b && d++;
printf("a=%d\n b=%d\n c=%d\n d=%d\n", a, b, c, d);
return 0;
}运行结果: a=1;b=2;c=3;d=4
解析:
首先i的初始值是0,执行i = a++ && ++b && d++ 时,先执行的是a++,a初始值为0,因为是后置++的原因,此时a仍然为0,逻辑与碰到0,就不会再往下继续执行了,所以后面的++b,d++都不算数。打印时,因为刚才a++,所以此时a=1,打印出来的结果自然是a=1,b=2,c=3,d=4;
❓ 2. 程序的输出结果是什么
int main()
{
int i = 0, a=0,b=2,c=3,d=4;
i = a++ || ++b || d++;
printf("a=%d\n b=%d\n c=%d\n d=%d\n", a, b, c, d);
return 0;
}运行结果: a=1;b=3;c=3;d=5
解析:
i=0,执行 i = a++ || ++b || d++ 时,先执行a++,因为是后置++所以此时a还是为0,但是因为是逻辑或,会继续往下走,++b为前置++,此时b为3,为真,就不会往下继续执行了,d++不算数。打印时,因为刚才a++,d++,所以此时a=1,打印出来的结果为 a=1,b=3,c=3,d=4;
总结:
1. 逻辑与:碰到假就停;(只要左边为假,右边就不算了)
2. 逻辑或:碰到真就停;(只要左边为真,右边就不算了)
八、条件操作符
定义:
① 表达式1的结果如果为真,计算表达式2;
② 如果表达式1的结果为假,计算表达式3;

注意事项:三目操作符不要写的过于复杂,否则可读性会很差;
代码演示:
1. if...else写法:
int main()
{
int a = 3;
int b = 0;
if (a > 5)
b = 1;
else
b = -1;
return 0;
} 2. 将上面代码转换成条件表达式:
int main()
{
int a = 3;
int b = 0;
b = a>5 ? 1 : -1; // 条件操作符
return 0;
}使用条件表达式实现找两个数中的较大值:
int main()
{
int a = 10;
int b = 20;
int max = 0;
max = (a>b ? a : b );
printf("max = %d", max);
return 0;
}九、逗号表达式
❓ 什么是逗号表达式
逗号表达式,顾名思义,用逗号隔开的多个表达式;
定义:从左向右依次执行,整个表达式的结果是最后一个表达式的结果;

代码演示:逗号表达式的用法
int main()
{
int a = 1;
int b = 2;
int c = (a>b, a=b+10, a, b = a+1);
// 无结果 12 无结果 12+1=13
printf("%d\n", c);
return 0;
}运行结果: 13
判断条件的逗号表达式
if(a = b + 1, c = a / 2, d > 0) // 从左向右依次执行后,d>0则条件为真逗号表达式的应用:简化代码结构

十、下标引用、函数调用和结构成员
0x00 下标引用操作符 [ ]

这个很简单,直接上代码:
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
// 0 1 2 3 4 5 6 7 8 9
printf("%d\n", arr[4]); // 5
// ↑ 这里的方块,正是下标引用操作符;
// [] 的操作数是2个:arr,4
return 0;
}0x01 函数调用操作符 ( )

作用:接受一个或者多个操作数;
① 第一个操作数是函数名;
② 剩余的操作数就是传递给函数的参数;
代码演示:函数调用操作符
int Add(int x, int y)
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
int Add(a, b); // 此时()为函数调用操作符;
return 0;
}0x02 结构成员访问操作符 - 点操作符 .
作用:访问结构体成员;

如果忘了什么是结构体,可以去回顾第一章(初识C语言)
https://blog.csdn.net/weixin_50502862/article/details/115426860;
代码演示:点操作符的使用
struct Book {
char name[20];
char id[20];
int price;
};
int main()
{
struct Book b = {"C语言", "C20210509", 55};
printf("书名:%s\n", b.name);
printf("书号:%s\n", b.id);
printf("定价:%d\n", b.price);
return 0;
}运行结果: 书名:C语言
书号:C20210509
定价:55
0x03 结构成员访问操作符 - 箭头操作符 ->
作用:通过结构体指针访问成员;

代码演示
1. 仍然可以用点操作符来写,但是略显冗琐;❎(可以但不推荐)
注意事项: (*p).name ✅ *p.name ❌ 注意优先级问题!
struct Book {
char name[20];
char id[20];
int price;
};
int main()
{
struct Book b = {"C语言", "C20210509", 55};
struct Book* pb = &b;
printf("书名:%s\n", (*pb).name);
printf("书号:%s\n", (*pb).id);
printf("定价:%d\n", (*pb).price);
return 0;
}2. 使用箭头操作符,更加直观; ✅
struct Book {
char name[20];
char id[20];
int price;
};
int main()
{
struct Book b = {"C语言", "C20210509", 55};
struct Book* pb = &b;
printf("书名:%s\n", pb->name);
printf("书号:%s\n", pb->id);
printf("定价:%d\n", pb->price);
return 0;
}十一章、表达式求值

表达式求值的顺序一部分是由操作符的优先级和结合性决定。同样,有些表达式的操作数在求职过程中可能需要转换为其他类型。
0x00 隐式类型转换
❓ 什么是整型提升:
① C的整型算术运算至少以缺省整型的精度来进行的;
② 为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型这种转换,称为整型提升;
③ 整型提升:按照变量的数据类型的符号位来提升;

图解整型提升:

❓ 那么问题又来了,如何进行整型提升呢?
整型提升是按照变量的数据类型的符号位来进行提升的;

整型提升讲解(请仔细看注释的步骤):
int main()
{
// 我们发现 a 和 b 都是 char 类型,都没有达到一个 int 的大小
// 这里就会发生整型提升
char a = 3;
// 00000000000000000000000000000011
// 00000011 - a 因为是char类型,所以只能放8个比特位(截断)
char b = 127;
// 00000000000000000000000001111111
// 01111111 - b 同上,截断,存储的是8个比特位
char c = a + b;
// 首先看a符号:char有符号,是正数,按照原来变量的符号位来提升
// 然后看b符号:char有符号,是正数,提升的时候也是补0
// 00000000000000000000000000000011 (高位补0,提升完结果还是这个)
// + 00000000000000000000000001111111
// -------------------------------------
// 00000000000000000000000010000010 (这个结果要存到c里,c里只能存8个比特位)
// 所以进行截断
// 10000010 - c (C里存的)
/* 这时我们要打印它 */
printf("%d\n", c);
// 这时,c要发生整型提升:
// 我们看c的符号,char有符号,是负数,高位进行整型提升,补1
// 10000010 - c // 然后进行整型提升
// 11111111111111111111111110000010 (补完1 之后的结果)
// 注意:这里是负数,原反补是不相同的!
// 打印出来的是原码,内存里的是补码,现在开始反推:
// 11111111111111111111111110000010 (补码)
// 11111111111111111111111110000001 - 反码(补码-1)
// 00000000000000000000000001111110 - 原码
// == -126
return 0;
}
运行结果: -126
整型提升的栗子1:下列代码运行的结果是什么(体会整型提升的存在)
int main()
{
char a = 0xb6;
short b = 0xb600;
int c = 0xb600000;
if(a == 0xb6)
printf("a"); //无
if(b == 0xb600)
printf("b"); //无
if(c == 0xb600000)
printf("c"); //c
return 0;
}运行结果: c
❓ 为什么 a 和 b 不会被打印出来呢
解析:
① 因为表达式里的 a 是 char 类型,因为没有达到整型大小,所以需要进行整型提升;
② 提升后比较当然不会相等,所以不会打印a,short 同理,c也不会被打印;
③ 还有一种解释方式:char a 里面存不下,所以不是 0xb6 ,所以不打印;
整型提升的栗子2:下列代码运行结果是什么(体会整型提升的存在)
int main()
{
char c = 1;
printf("%u\n", sizeof(c)); // 1
printf("%u\n", sizeof(+c)); // 4 整型提升后等于计算一个整型的大小
printf("%u\n", sizeof(-c)); // 1
printf("%u\n", sizeof(!c)); // 4 gcc-4
return 0;
}解析:
① sizeof(c) ,c是char型,结果自然是1;
② sizeof(+c),+c参与运算了,就会发生整型提升,相当于计算了一个整型的大小,所以为4;
③ sizeof(-c),同上,一样的道理,所以为4;
③ sizeof( !c) ,这里值得一提的是,有些编辑器结果可能不是4,但是根据gcc为准,答案为4;
结论:
① 通过上面的例子ba,可以得到结论:到整型提升是确实存在的;
② 比 int 大的不需要整型提升,比 int 小的要进行整型提升;
0x02 算术转换
定义:如果某个操作数的各个操作数属于不同的类型,
那么除非其中一个操作数的转换为另一个操作数的类型,否则操作无法进行;
寻常算数转换:如果某个操作数类型在下面的这个表里,排名较低,
那么首先要转换为另外一个操作数的类型,然后才能执行运算;
举个栗子:(如果 int 类型的变量和 float 类型的变量放在一起,这时要把 int 转换成 float)

注意事项:算数转换要合理,要不然会产生潜在的问题;
精度丢失问题:
int main()
{
float f = 3.14;
int num = f; // 隐式转换,会有精度丢失
printf("%d\n", num); // 3
return 0;
}3
0x03 操作符的属性
复杂表达式的求值有三个影响的因素:
① 操作符的优先级;
② 操作符的结合性;
③ 是否控制求值顺序;
❓ 两个相邻的操作符先执行哪个?取决于他们的优先级,如果两者的优先级相同,
代码演示:优先级决定了计算顺序
int main()
{
int a = 3;
int b = 5;
int c = a + b * 7; // 优先级决定:先乘后加
return 0;
}代码演示:优先级一样,此时优先级不起作用,结合性决定顺序
int main()
{
int a = 3;
int b = 5;
int c = a + b + 7; // 先算左边,再算右边
return 0;
}运算符优先级表:
| 操作符 | 描述 | 用法示例 | 结合类型 | 结合性 | 是否控制求值顺序 |
| ( ) | 聚组 | (表达式) | 与表达式相同 | N/A | 否 |
| ( ) | 函数调用 | rexp(rexp, ..., rexp) | rexp | L-R | 否 |
| [ ] | 下标引用 | rexp[rexp] | lexp | L-R | 否 |
| . | 访问结构成员 | lexp.member_name | lexp | L-R | 否 |
| -> | 访问结构指针成员 | rexp->member_name | lexp | L-R | 否 |
| ++ | 后缀自增 | lexp++ | rexp | L-R | 否 |
| -- | 后缀自减 | lexp-- | rexp | L-R | 否 |
| ! | 逻辑反 | !rexp | rexp | R-L | 否 |
| ~ | 按位取反 | ~rexp | rexp | R-L | 否 |
| + | 单目,表示正值 | +rexp | rexp | R-L | 否 |
| - | 单目,表示负值 | -rexp | rexp | R-L | 否 |
| ++ | 前缀自增 | ++lexp | rexp | R-L | 否 |
| -- | 前缀自减 | --lexp | rexp | R-L | 否 |
| * | 间接访问 | *rexp | lexp | R-L | 否 |
| & | 取地址 | &lexp | rexp | R-L | 否 |
| sizeof | 取其长度,以字节表示 | sizeof rexp szieof(类型) | rexp |
R-L | 否 |
| (类型) | 类型转换 | (类型)rexp | rexp | R-L | 否 |
| * | 乘法 | rexp*rexp | rexp | L-R | 否 |
| / | 除法 | rexp/rexp | rexp |
L-R | 否 |
| % | 整数取余 | rexp%rexp | rexp | L-R | 否 |
| + | 加法 | rexp+rexp | rexp | L-R | 否 |
| - | 减法 | rexp-rexp | rexp | L-R | 否 |
| << | 左移位 | rexp<| rexp |
L-R |
否 |
|
| >> | 右移位 | rexp>>rexp | rexp | L-R | 否 |
| > | 大于 | rexp>rexp | rexp | L-R | 否 |
| >= | 大于等于 | rexp>=rexp | rexp | L-R | 否 |
| < | 小于 | rexp| rexp |
L-R |
否 |
|
| <= | 小于等于 | rexp<=rexp | rexp | L-R | 否 |
| == | 等于 | rexp==rexp | rexp | L-R | 否 |
| != | 不等于 | rexp!=rexp |
rexp | L-R | 否 |
| & | 位与 | rexp&rexp | rexp | L-R | 否 |
| ^ | 位异或 | rexp^rexp | rexp | L-R | 否 |
| | | 位或 | rexp|rexp | rexp | L-R |
否 |
| && | 逻辑与 | rexp&&rexp | rexp | L-R | 是 |
| || | 逻辑或 | rexp&&rexp | rexp | L-R | 是 |
| ?: | 条件操作符 | rexp?rexp:rexp | rexp | L-R | 是 |
| = | 赋值 | lexp=rexp | rexp | N/V | 是 |
| += | 加等于 | lexp+=rexp | rexp | R-L | 否 |
| -= | 减等于 | lexp-=rexp | rexp | R-L | 否 |
| *= | 乘等于 | lexp*=rexp | rexp | R-L | 否 |
| /= | 除等于 | lexp /= rexp | rexp | R-L | 否 |
| %= | 以...取模 | lexp %= rexp | rexp | R-L | 否 |
| <<= |
以...左移 | lexp <<= rexp | rexp | R-L | 否 |
| >>= | 以...右移 | lexp >>= rexp | rexp | R-L | 否 |
| &= | 以...与 | lexp &= rexp | rexp | R-L | 否 |
| ^= | 以...异或 | lexp ^= rexp | rexp | R-L | 否 |
| |= | 以...或 | lexp |= rexp | rexp | R-L | 否 |
| , | 逗号 | rexp, rexp | rexp | L-R | 是 |
❌ 问题表达式:

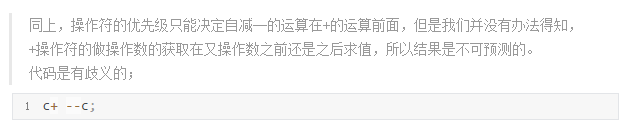
❌ 非法表达式:( 出自《C和指针》)
int main()
{
int i = 10;
i = i-- - --i * ( i = -3 ) * i++ + ++i;
printf("i = %d\n", i);
return 0;
}解析: 堪比《茴香豆的一万种写法》,
这种代码,运行结果取决于环境,不要写出这种代码!
作业
0x00 选择题
❓ 下面哪个是位操作符 ( );
A. & B. && C. || D. !
0x01 分析代码
❓ 下列代码运行后的结果是什么
#include
int main()
{
int a, b, c;
a = 5;
c = ++a;
b = ++c, c++, ++a, a++;
b += a++ + c;
printf("a = %d b = %d c = %d\n:", a, b, c);
return 0;
} 0x02 交换两个变量(不创建临时变量)
不允许创建临时变量,交换两个整数的内容;
0x03 统计二进制中1的个数
输入一个整数,写一个函数返回该数32位二进制表示中1的个数,其中负数用补码表示。
( eg. 15 0000 1111 4个1 )
牛客网OJ链接:二进制中1的个数__牛客网;
0x04 求两个数二进制中不同位的个数
编程实现:两个 int(32位)整数的 m 和 n 的二进制表达中,有多少个位 (bit) 不同?
( eg. 输入 1999 2299 输出 7 )
牛客网OJ链接:两个整数二进制位不同个数__牛客网;
0x05 打印整数二进制的奇数位和偶数位
说明:获取一个整数二进制序列中所有的偶数位和奇数位,分别打印出二进制序列;
答案
0x00 第一题:选择题
正确答案:A
解析:

0x01 第二题:下列代码运行结果
正确答案:a = 9 b = 23 c = 8
解析:

0x02 第三题:不创建临时变量交换两个整数内容
不允许创建临时变量,交换两个整数的内容;
参考答案:
void Swap (
int* pa,
int* pb
)
{
*pa = *pa ^ *pb;
*pb = *pa ^ *pb;
*pa = *pa ^ *pb;
}
int main()
{
int a = 10;
int b = 20;
printf("交换前:a = %d b = %d\n", a, b);
Swap(&a, &b);
printf("交换后:a = %d b = %d\n", a, b);
return 0;
}0x03 第四题:统计二进制中1的个数
输入一个整数,写一个函数返回该数32位二进制表示中1的个数,其中负数用补码表示。
( eg. 15 0000 1111 4个1 )
参考答案:
1. 模除法
int CountNum1(int n)
{
int count = 0;
while(n) {
if(n % 2 == 1) {
count++;
}
n /= 2;
}
return count;
}
int main()
{
int num = 0;
scanf("%d", &num);
int ret = CountNum1(num);
printf("%d\n", ret);
return 0;
}2. 移位操作符 + 按位与 结合的方式
int CountNum1(int n)
{
int count = 0;
int i = 0;
for(i=0; i<32; i++) {
if( ((n>>i) & 1) == 1) {
count++;
}
}
return count;
}
int main()
{
int num = 0;
scanf("%d", &num);
int ret = CountNum1(num);
printf("%d\n", ret);
return 0;
}
3. &=
int CountNum1(int n)
{
int count = 0;
while(n) {
n = n & (n - 1);
count++;
}
return count;
}
int main()
{
int num = 0;
scanf("%d", &num);
int ret = CountNum1(num);
printf("%d\n", ret);
return 0;
}

0x04 第五题:求两个数二进制中不同位的个数
编程实现:两个 int(32位)整数的 m 和 n 的二进制表达中,有多少个位 (bit) 不同?
( eg. 输入 1999 2299 输出 7 )
1. >> & 移位按位与
int main()
{
int m = 0;
int n = 0;
scanf("%d %d", &m, &n);
int count = 0;
int i = 0;
for(i=0; i<32; i++) {
if( ((m >> i) & 1) != ((n >> i) & 1) ) {
count++;
}
}
printf("%d\n", count);
return 0;
}
2. 异或法,然后统计二进制中有几个1
int NumberOf1(int n)
{
int count = 0;
while(n) {
n = n & (n - 1);
count++;
}
return count;
}
int main()
{
int m = 0;
int n = 0;
scanf("%d%d", &m, &n);
int count = 0;
int ret = m ^ n; // 相同为0,相异为1
// 统计一下ret的二进制中有几个1,就说明m和n的二进制位中有几个位置不同
count = NumberOf1(ret);
printf("%d\n", count);
return 0;
}
0x05 第六题:打印整数二进制的奇数位和偶数位
说明:获取一个整数二进制序列中所有的偶数位和奇数位,分别打印出二进制序列;
int main()
{
int n = 0;
scanf("%d", &n);
// 获取n的2进制中的奇数位和偶数位
int i = 0;
// 打印偶数位
for(i=31; i>=1; i -= 2) {
printf("%d ", (n >> i) & 1);
}
printf("\n");
// 打印奇数位
for(i=30; i>=0; i-=2) {
printf("%d ", (n >> i) & 1);
}
return 0;
}
第六章 - 指针
前言:
本章是指针部分的开始,将对C语言中非常重要的指针进行讲解。本章结束后有能力的读者可对应指针进阶部分进行进一步学习。指针专题配备了一些笔试题,建议尝试。
【维生素C语言】第十章 - 指针的进阶(上)
【维生素C语言】第十章 - 指针的进阶(下)
“ 祖安猎码人”在线手撕代码画图解析【C指针笔试题】
一、指针的定义

0x00 何为指针
❓ 我们先来看看定义:
指针是编程语言中的一个对象,利用地址,他的值直接指向存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址的内存单元。
简单地说:指针就是地址,地址就是指针;
注意事项:
① 指针就是变量,用来存放地址的变量(存放在之阵中的值都被当成地址处理);
② 一个小的内存单元大小为 1 个字节;
③ 指针是用来存放地址的,地址是唯一标识一块内存空间的;
④ 指针的大小在 32 位平台上是 4 个字节,在 64 位平台上是 8 个字节;
指针的创建:
int main()
{
int a = 10; // 在内存中开辟一块空间
int* pa = &a; // 使用解引用操作符&,取出变量a的地址
// 将a的地址存放在pa变量中,此时pa就是一个指针变量
return 0;
}❓ 什么是指针变量
指针变量就是存放指针的变量,这里的 int* pa 就是一个整型指针变量,里面存放了 a 的地址;
0x02 指针的大小
32位平台:4 bit , 64位平台:8 bit ;
验证当前系统的指针大小:
int main()
{
printf("%d\n", sizeof(char*));
printf("%d\n", sizeof(short*));
printf("%d\n", sizeof(int*));
printf("%d\n", sizeof(double*));
return 0;
}二、指针的指针类型
0x00 指针类型
int 型指针和 char 型指针都可以存储 a ;
int main()
{
int a = 0x11223344;
int* pa = &a;
char* pc = &a;
printf("%p\n", pa);
printf("%p\n", pc);
return 0;
}运行结果:他们的运行结果是一样的
0x01 指针类型的意义
指针类型决定了指针进行解引用时,能够访问的内存大小是多少;

不同的指针类型,访问的大小不同:
int main()
{
int a = 0x11223344;
int* pa = &a; // 44 33 22 11 (至于为什么是倒着的,后面会讲。)
*pa = 0;// 00 00 00 00
char* pc = &a; // 44 33 22 11
*pc = 0; // 00 33 22 11
// 在内存中仅仅改变了一个字节
// 解引用操作时就不一样了
// 整型指针操作了4个字节,让四个字节变为0
// 字符指针能把地址交到内存中,
// 但是解引用操作时,只敢动1个字节
return 0;
}0x02 指针加减整数
定理:指针类型决定指针步长(指针走一步走多远);

代码验证:指针类型决定指针步长;
int main()
{
int a = 0x11223344;
int* pa = &a;
char* pc = &a;
printf("%p\n", pa); // 0095FB58
printf("%p\n", pa+1); // 0095FB5C +4
printf("%p\n", pc); // 0095FB58
printf("%p\n", pc+1); // 0095FB59 +1
return 0;
}0x03 指针修改数组元素
把数组里的元素都改成1
1. 使用整型指针:
int main()
{
int arr[10] = {0};
int* p = arr; //数组名 - 首元素地址
/* 修改 */
int i = 0;
for(i=0; i<10; i++) {
*(p+i) = 1; //成功,arr里的元素都变为了1
}
/* 打印 */
for(i=0; i<10; i++) {
printf("%d ", arr[i]);
}
return 0;
}1 1 1 1 1 1 1 1 1 1
2. 使用字符指针:
int main()
{
int arr[10] = {0};
char* p = arr; //数组名 - 首元素地址
/* 修改 */
int i = 0;
for(i=0; i<10; i++)
{
*(p+i) = 1; // 一个一个字节改,只改了十个字节
}
return 0;
}解析:
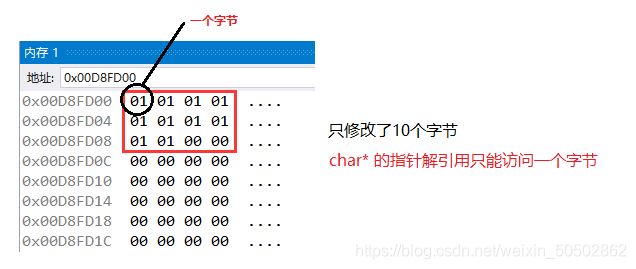
总结:
① 指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节);
② 譬如,char* 的指针解引用只能访问1个字节,而 int* 的指针解引用就能够访问4个字节
三、野指针(Wild pointer)
0x00 野指针的概念

概念:野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的);
野指针指向了一块随机的内存空间,不受程序控制;
0x01 野指针的成因
原因:
① 指针未初始化;
② 指针越界访问;
③ 指针指向的空间已释放;
指针未初始化
∵ 局部变量不初始化默认为随机值:
int main()
{
int a;//局部变量不初始化默认为随机值
printf("%d", a);
return 0;
}∴ 同理,局部的指针变量,如果不初始化,默认为随机值:
int main()
{
int *p; //局部的指针变量,就被初始化随机值
*p = 20; //内存中随便找个地址存进去
return 0;
}指针越界访问
指针越界,越出arr管理范围时会产生野指针:
int main()
{
int arr[10] = {0};
int *p = arr;
int i = 0;
for(i=0; i<12; i++)
{
//当指针越出arr管理的范围时,p就称为野指针
p++;
}
return 0;
}指针指向的空间已释放
int* test()
{
int a = 10;
return &a;
}
int main()
{
int *pa = test();
*pa = 20;
return 0;
}解析:
① 一进入test 函数内时就创建一个临时变量 a(10 - 0x0012ff44),这个a是局部变量,进入范围时创建,一旦出去就销毁,销毁就意味着这个内存空间还给了操作系统,这块空间(0x0012ff44)就不再是 a 的了;
② 进入这个函数时创建了 a,有了地址,ruturn &a 把地址返回去了,但是这个函数一结束,这块空间就不属于自己了,当你使用时,这块空间已经释放了,指针指向的空间被指放了,这种情况就会导致野指针的问题;
③ 只要是返回临时变量的地址,都会存在问题(除非这个变量出了这个范围不销毁);
0x02 如何规避野指针

指针初始化
int main()
{
int a = 10;
int* pa = &a; // 初始化
int* p = NULL; // 当你不知道给什么值的时候用NULL
return 0;
}指针指向空间释放及时置 NULL
int main()
{
int a = 10;
int *pa = &a;
*pa = 20;
//假设已经把a操作好了,pa指针已经不打算用它了
pa = NULL; //置成空指针
return 0;
}指针使用之前检查有效性
int main()
{
int a = 10;
int *pa = &a;
*pa = 20;
pa = NULL;
//*pa = 10; 崩溃,访问发生错误,指针为空时不能访问
if(pa != NULL) { // 检查 如果指针不是空指针
*pa = 10; // 检查通过才执行
}
return 0;
}四、指针运算
0x00 指针加整数
指针加整数:打印 1 2 3 4 5 6 7 8 9 10
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr; // 指向数组的首元素 - 1
for(i=0; i1 2 3 4 5 6 7 8 9 10
0x01 指针减整数
指针减整数:打印 10 8 6 4 2
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = &arr[9]; // 取出数组最后一个元素的地址
for(i=0; i0x02 指针后置++
#define N_VALUES 5
int main()
{
float values[N_VALUES];
float *vp;
// 指针+-整数;指针的关系运算
for(vp = &values[0]; vp < &values[N_VALUES] {
*vp++ = 0; // 在这调整了,后置++
}
return 0;
}0x03 指针减指针
说明:指针减指针得到的是元素之间元素的个数;
注意事项:当指针减指针时,他们必须指向同一空间(比如同一个数组的空间);
指针减指针:
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d\n", &arr[9] - &arr[0]); // 得到指针和指针之间元素的个数
return 0;
}9
❌ 错误演示:不在同一内存空间
int ch[5] = {0};
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d\n", &arr[9] - &ch[0]); // 没有意义,结果是不可预知的手写 strlen 函数(用指针方法实现):
int my_strlen(char* str)
{
char* start = str;
char* end = str;
while(*end != '\0') {
end++;
}
return end - start; //return
}
int main()
{
//strlen - 求字符串长度
//递归 - 模拟实现了strlen - 计数器方式1, 递归的方式2
char arr[] = "abcdef";
int len = my_strlen(arr); //arr是首元素的地址
printf("%d\n", len);
return 0;
}⚡ 简化(库函数的写法):
int my_strlen(const char* str)
{
const char* end = str;
while(*end++);
return (end - str - 1);
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}0x04 指针的关系运算(比较大小)
指针减减指针:
#define N_VALUES 5
int main()
{
float values[N_VALUES];
float *vp;
for(vp=&values[N_VALUES]; vp> &values[0]; ) {
*--vp = 0; //前置--
}
return 0;
}⚡ 简化(这么写更容易理解,上面代码 *--vp在最大索引后的位置开始访问的):
int main()
{
float values[5];
float *vp;
for(vp=&values[N_VALUES]; vp> &values[0]; vp--) {
*vp = 0;
}
return 0;
}❗ 实际在绝大部分编译器上是可行的,但是我们应该避免这么写,因为标准并不保证它可执行;、
解析:标准规定:允许指向数组元素的指针与指向数组最后一个元素后面的拿个内存位置的指针比较,但是不允许与指向第一个元素之前的拿个内存位置的指针进行比较;
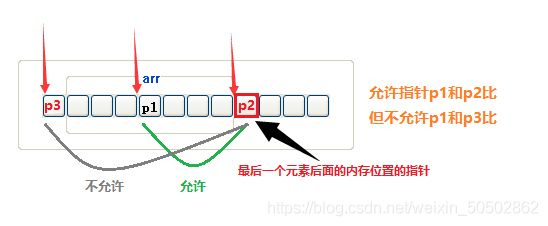
五、指针和数组
0x00 数组名
数组名在 绝大部分情况下都是首元素地址;
大多数情况下数组名是首元素地址:arr 等同于 &arr[0]
int main()
{
int arr[10] = {0};
printf("%p\n", arr); // 数组名是地址,首元素地址
printf("%p\n", &arr[0]); // 结果同上
printf("%p\n", &arr); // 看下面的 “例外”
return 0;
}00EFF8E0 00EFF8E0 00EFF8E0(这是整个元素的地址)
例外:
1. &数组名( &arr ):数组名不是首元素地址,而是表示整个数组:
&数组名 - 数组名表示的是整个数组:
int main()
{
int arr[10] = {0};
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("%p\n", &arr[0]);
printf("%p\n", &arr[0]+1);
printf("%p\n", &arr);
printf("%p\n", &arr + 1); // +1,以整个元素为单位
return 0;
}运行结果如下:
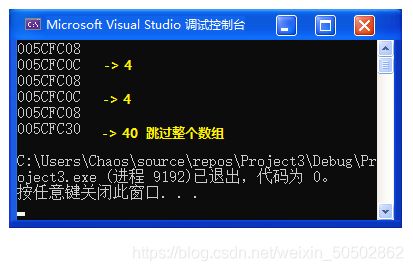
2. sizeof(数组名):计算的是整个数组的大小,单位是字节
sizeof(数组名):数组名表示的是整个数组:
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
printf("%d\n", sz);
return 0;
}10
总结:数组名是首元素地址( 除&数组名 和 sizeof 数组名 外 );
0x01 使用指针访问数组
p+i 计算的是数组 arr 下标为 i 的地址:
int main()
{
int arr[10] = {0};
int* p = arr; //这时arr数组就可以通过指针进行访问了
int i = 0;
for(i=0; i<10; i++) {
printf("%p == %p\n", p+i, &arr[i]);
}
return 0;
}运行结果如下:
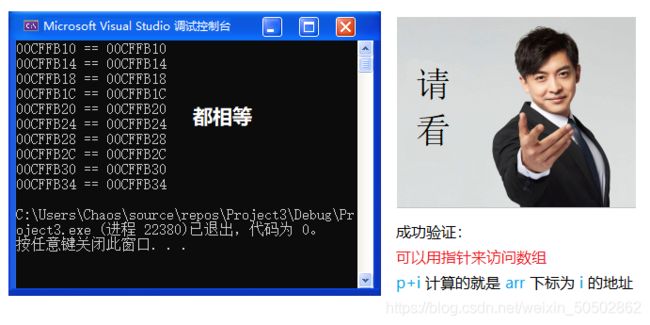
生成 0 1 2 3 4 5 6 7 8 9
int main()
{
int arr[10] = {0};
int* p = arr; // 这时arr数组就可以通过指针进行访问了
int i = 0;
printf("生成前:\n");
for(i=0; i<10; i++) {
printf("%d ", arr[i]);
}
for(i=0; i<10; i++) {
*(p+i) = i; // p+1=1, p+2=2, p+3=3...
// arr[i] = i; 等价于
}
printf("\n生成后:\n");
for(i=0; i<10; i++) {
printf("%d ", arr[i]);
// printf("%d ", *(p + i)); 等价于
}
return 0;
}运行结果如下:
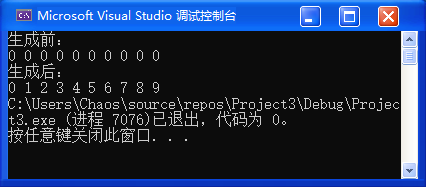
生成 6 6 6 6 6 6 6 6 6 6
int main()
{
int arr[10] = {0};
int* p = arr; // 这时arr数组就可以通过指针进行访问了
int i = 0;
for(i=0; i<10; i++) {
*(p+i) = 8; // p+1=1, p+2=2, p+3=3...
}
for(i=0; i<10; i++) {
printf("%d ", *(p + i));
}
return 0;
}6 6 6 6 6 6 6 6 6 6
六、二级指针(Second Rank Pointer)
0x00 二级指针的概念
概念:指针变量也是变量,是变量就有地址,指针的地址存放在二级指针;

二级指针:
int main()
{
int a = 10;
int* pa = &a;
int** ppa = &pa; // ppa就是二级指针
int*** pppa = &ppa; // pppa就是三级指针
...
**ppa = 20;
printf("%d\n", *ppa); // 20
printf("%d\n", a); // 20
return 0;
}对于二级指针的运算:
① *ppa 通过对 ppa 中的地址进行解引用,找到了的是 pa,*ppa 其实访问的就是pa;
② **ppa 先通过 *ppa 找到 pa,然后对 pa 进行解引用操作,*pa 找到的就是 a;
七、指针数组(Pointer to Array)
0x00 指针数组的概念
概念:指针数组本质上是数组,存放指针的数组;
注意:不要和数组指针混淆,数组指针本质上是指针;
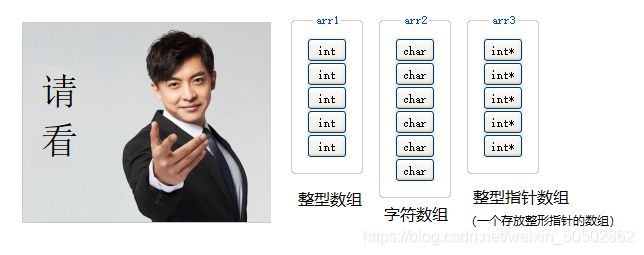
❓ 分析下面的数组:
int arr1[5];
char arr2[6];
int* arr3[5];解析:
① arr1 是一个整型数组,有 5 个元素,每个元素都是一个 整型;
② arr2 是一个字符数组,有 6 个元素,每个元素都是一个 char 型;
③ arr3 是一个整型指针数组,有 5 个元素,每个元素是一个 整型指针;
第七章 - 结构体
前言:
本章将对结构体进行简单的学习,后期在自定义类型讲解章节会进一步学习结构体。由于本章知识点较少,在文章的最后对函数栈帧的创建与销毁进行一个简要的介绍。
一、结构体的定义

0x00 结构的基础知识
知识点:
① 结构是一些值的集合,这些值称为成员变量;
② 结构的每个成员可以是不同类型得变量;
0x01 结构体的声明
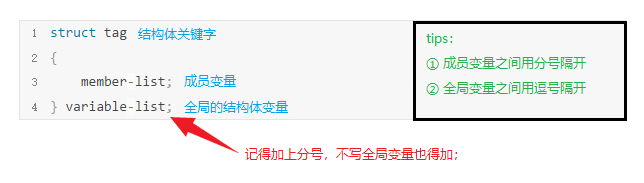
注意事项:
① 成员变量之间用分号隔开,全局变量之间用逗号隔开;
② 结构体末大括号后 必须加上分号(即使不写全局变量也要加上);
结构体的声明:使用结构体描述一个学生
描述一个学生需要一些数据:姓名、年龄、性别、学号
/* struct 结构体关键字 Stu - 结构体标签 struct Stu - 结构体类型 */
struct Stu {
/* 成员变量 */
char name[20]; // 定义一个结构体类型
int age;
char sex[10];
char id[20];
} s1, s2, s3; // s1,s2,s3 是三个全局的结构体变量
// 再次提醒,分号不能丢!
int main()
{
struct Stu s; // 创建结构体变量
// s为局部的结构体变量
return 0;
}0x02 数据类型定义 typedef
typedef struct Stu {
char name[20];
int age;
char sex[10];
char id[20];
} Stu;
int main()
{
Stu s1; // 加了之后可以作为一个单独的类型来使用
struct Stu s2;// 不影响
return 0;
}二、结构体的使用
0x00 结构体初始化
初始化方法:使用大括号对结构体进行初始化;
typedef struct Stu {
char name[20]; // 定义一个结构体类型
int age;
char sex[10];
char id[20];
} Stu;
int main()
{
Stu s0 = {}; // 使用大括号初始化
Stu s1 = {"CSDN", 20, "男", "20200408"};
Stu s2 = {"吃素的牛", 21, "男", "20201214"};
return 0;
}0x01 结构体成员的访问
方法:结构体变量访问成员(结构体变量的成员)是通过点操作符访问的;
❓ 什么是点操作符:第五章 - 操作符(十、0x02)
猛戳!
点操作符接收两个操作数:
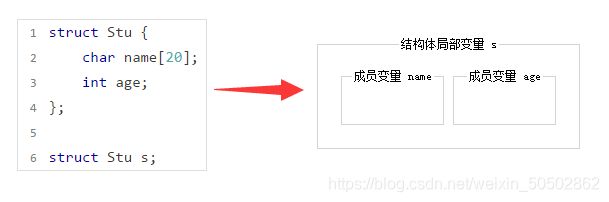
❓ 我们可以看到创建的局部变量 s 里有 name 和 age,该如何访问 s 的成员?
通过 点操作符( . )来访问:
struct Stu{
char name[20];
int age;
};
int main()
{
struct Stu s = {"mole", 13};
printf("%s\n", s.name);
// 使用点操作符访问name成员
printf("%d\n", s.age);
// 使用点操作符访问age成员
return 0;
}
mole 13
0x02 结构成员的类型
结构的成员可以是标量、数组、指针,甚至是其他结构体;
struct Stu {
char name[20];
int age;
char sex[10];
char id[20];
};
struct School {
char school_name[30]; // 数组
struct Stu s; // 结构体 完全没有问题~
char *pc; // 地址
};
int main()
{
char arr[] = "地球\n";
struct School JLD = {"家里蹲大学", {"小明", 18, "男", "20201353"}, arr};
printf("校名 - %s\n", JLD.school_name);
printf("学生 - 姓名:%s, 年龄:%d, 性别:%s, 学号:%s\n",
JLD.s.name,
JLD.s.age,
JLD.s.sex,
JLD.s.id
);
printf("地址 - %s\n", JLD.pc);
return 0;
}
运行结果如下:

0x03 结构体变量的定义和初始化
定义方法:
① 在定义结构体时定义(全局);
② 在创建结构体变量时定义(局部);
结构体变量的定义:
struct Point {
int x;
int y;
} p1;
// 声明类型的同时定义变量p1
int main()
{
struct Point p2; // 定义结构体变量p2
return 0;
}初始化:
定义变量的同时赋初值:
struct Point {
int x;
int y;
} p1;
int main()
{
struct Point p3 = {10, 20}; // 初始化:定义变量的同时赋初值
return 0;
}结构体嵌套初始化:
struct Point {
int x;
int y;
} p1;
struct Node {
int data;
struct Point p;
struct Node* next;
} n1 = {10, {5, 6}, NULL}; // 结构体嵌套初始化
int main()
{
struct Node n2 = {20, {5, 6}, NULL}; // 结构体嵌套初始化
// x,y
return 0;
}0x04 结构体传参
传参形式:
① 传结构体(使用结构体接收);
② 传地址(使用结构体指针接收);
如果选用传地址,可以通过 箭头操作符 访问
❓ 什么!忘了?
 第五章 - 操作符(十、0x03)
第五章 - 操作符(十、0x03)
戳进去瞅瞅!
传结构体:
typedef struct Stu {
char name[20];
short age;
char sex[10];
char id[20];
} Stu;
void print_by_s(Stu tmp) // 使用结构体接收
{
printf("姓名: %s\n", tmp.name);
printf("年龄: %d\n", tmp.age);
printf("性别: %s\n", tmp.sex);
printf("学号: %s\n", tmp.id);
}
int main()
{
Stu s1 = {"张三", 21, "男", "20204344"}; // 使用大括号初始化
/* 打印结构体数据 */
print_by_s ( s1 ) ; // 传结构体
return 0;
}运行结果如下:
传地址:
typedef struct Stu {
char name[20];
short age;
char sex[10];
char id[20];
} Stu;
void print_by_a(Stu* ps) // 使用地址接收
{
printf("姓名: %s\n", ps->name);
printf("年龄: %d\n", ps->age);
printf("性别: %s\n", ps->sex);
printf("学号: %s\n", ps->id);
}
int main()
{
Stu s1 = {"张三", 21, "男", "20204344"}; // 使用大括号初始化
/* 打印结构体数据 */
print_by_a ( &s1 ) ; //传地址
return 0;
}运行结果如下:

我们发现这种方法结果都一样,那么问题来了:
❓ 传结构体 和 传地址 哪种方法更好些? 答案:传地址更好;
解析:
① 懂的都懂,因为函数再传参时,参数是需要压栈的;如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,就会导致性能下降!
② 其次,传地址的效率高,并且便于修改;
简单介绍 函数栈帧的创建和销毁(后续会专门更新一篇博客详细介绍):
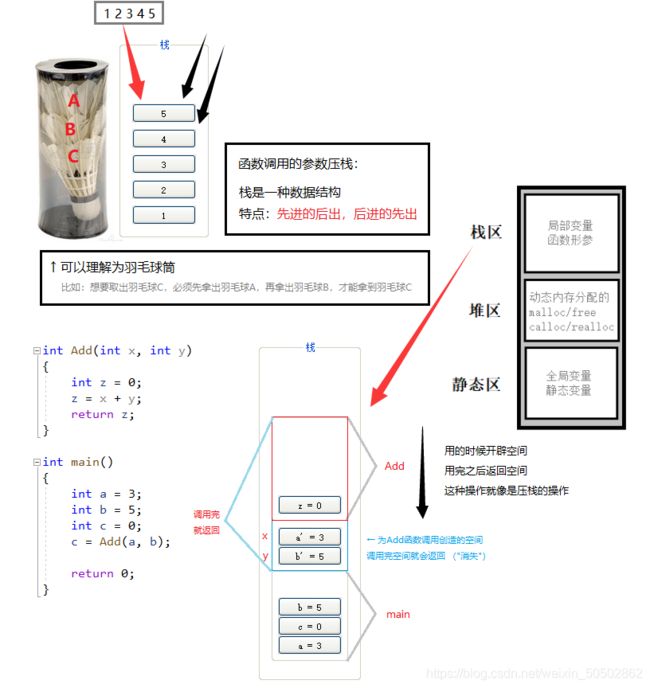
结论:结构体传参的时候,要传结构体的地址;
第八章 - 实用调试技巧
前言:
一名优秀的程序员是一名出色的侦探,每一次调试都是尝试破案的过程……本章将详细带你学习实用调试技巧!正式开启DEBUG生活。
一、调试(Debug)

0x00 何为调试

一名优秀的程序员是一名出色的侦探,每一次调试都是尝试破案的过程……
定义:调试,又称除错,是发现和减少计算机程序电子仪器设备中程序错误的一个过程;
0x01 调试的基本步骤
基本步骤:
① 发现程序错误的存在;
✅ 能够发现错误的人:
⑴ 程序员,自己发现;
⑵ 软件测试人员,测试软件;
⑶ 用户,代价严重;
箴言:要善于承认自己的错误,不能掩盖错误;
② 以隔离、消除等方式对错误进行定位;
✅ 能知道大概在什么位置,再确定错误产生的原因是什么;
③ 提出纠正错误的解决方案;
④ 对程序错误订正,重新调试;
二、Debug和Release的介绍
0x00 对比
Debug 通常称为调试版本,它包含调试信息,并且不做任何优化,便于程序员调试程序;
Release 称为发布版本,他往往是进行了各种优化,使得程序在代码大小和运行速度上是最优的,以便用户更好的使用;
注意事项:Release 版本是不能调试的;
用 Debug 和 Release 分别运行:
int main()
{
char* p = "hello,world!";
printf("%s\n", p);
return 0;
}Debug 环境下运行结果如下:
Release 环境下运行结果如下:
我们可以发现:Release进行了优化,使得程序在运行速度和代码大小上是最优的;
Debug和Release反汇编展示对比:

0x01 Release的优化
❓ 使用Release版本调试时,编辑器进行了那些优化呢?
请看下列代码:
int main()
{
int arr[10] = {0};
int i = 0;
for(i=0; i<=12; i++) {
arr[i] = 0;
printf("hehe\n");
}
return 0;
}如果是 debug 模式去编译,程序结果是 死循环:
如果是 release 模式去编译,程序没有死循环:
因为 release 的优化,避免了死循环的发生;
三、Windows环境调试介绍
0x00 调试环境准备
在环境中选择 debug 选项,才能使代码正常调试;
注意事项:本章使用 VS2019 演示;
0x01 开始调试(F5)
✅ 快捷键:F5
作用:启动调试,经常用来直接调到下一个断点处;
注意事项:
① 如果直接按 F5 ,如果没有阻挡的话程序一口气就干完了;
② 使用 F5 之前要先使用 F9 ,设置断点;
按 F5 开始调试下列代码:
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++) {
arr[i] = i + 1;
}
for (i = 0; i < sz; i++) {
printf("%d\n", arr[i]);
}
return 0;
}运行后结果如下:
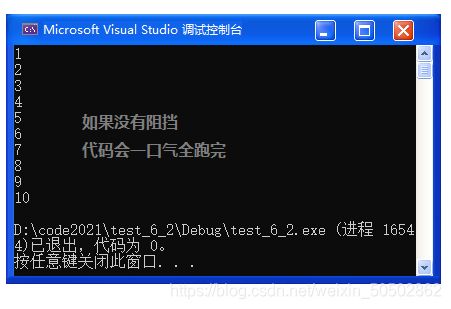
0x02 断点(F9)
✅ 快捷键:F9
作用:创建断点和取消断点,断电的重要作用可以在程序的任意位置设置断点;这样就可以使得程序在想要的位置随意停止执行,继而可以一步步执行下去;
按 F9 设置断点

这时按下 F5 就会直接跳到断点部分:
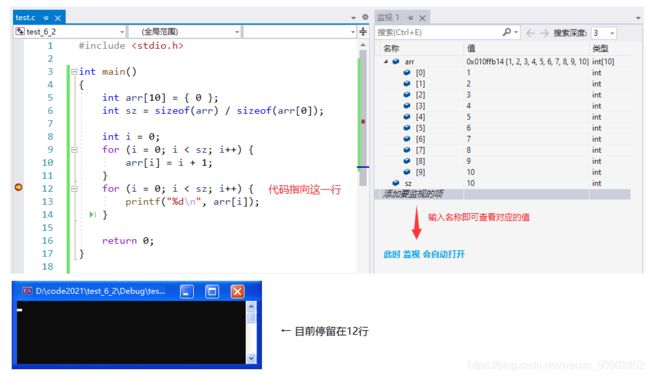
0x03 逐过程(F10)
✅ 快捷键:F10
作用:通常用来处理一个过程,一个过程可以是一次函数的调用,或者是一条语句;
逐过程:

按一次 F10 代码就往下走一步;
0x04 逐语句(F11)
✅ 快捷键:F11(这是最常用的)
作用:每次都执行一条语句,观察的细腻度比 F10 还要高,可以进入到函数内部;
注意事项:F10 和 F11 大部分情况是一样的,区别在于 F11 遇到函数时可以进到函数内部去,函数的内部也可以一步步观察,而 F10 遇到函数调用完之后就跳出去了;
观察函数内部:
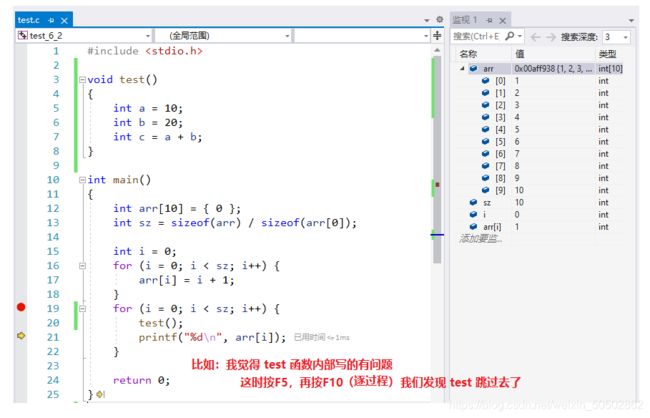
如果想观察函数内部,就要使用 F11 (逐语句);
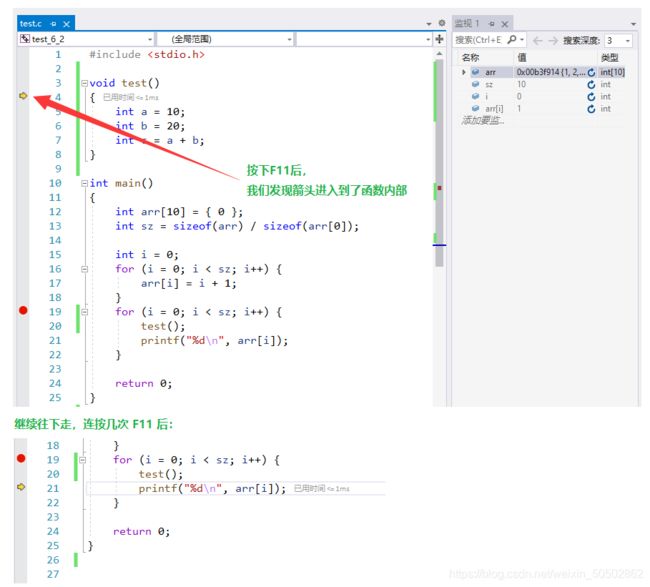
0x05 开始执行不调试(Ctrl + F5)
✅ 快捷键: Ctrl + F5
作用:开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用;
0x06 总结
F5 - 启动调试
F9 - 设置/取消断点
F10 - 逐过程
F11 - 逐语句 - 更加细腻
Ctrl + F5 - 运行
注意事项:如果你按上面的快捷键不起作用时,可能是因为辅助功能键(Fn)导致的,此时按下 Fn 再按上面的快捷键即可;
❓ 想知道更多快捷键?
VS中常用的快捷键 戳我!
0x07 调试时查看程序当前信息
查看方法:调试(D) → 窗口(W) → 选择相应的选项;
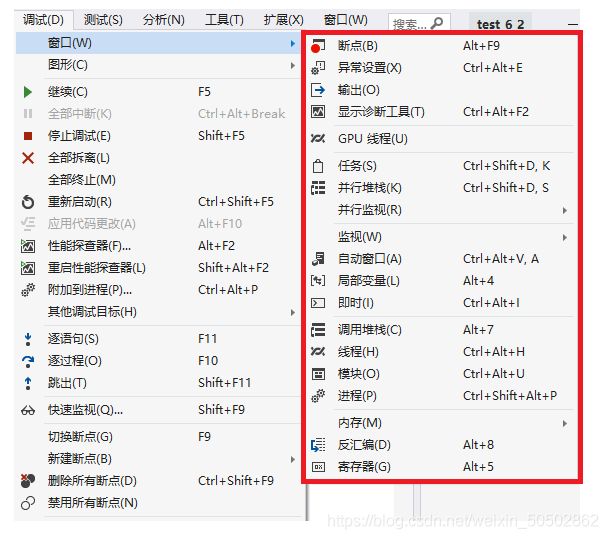
注意事项:只有调试之后才会显示调试窗口里的选项;

0x08 查看断点
作用:调试多个文件时,可以很好地管理多个文件的断点;

0x09 监视
作用:在调试开始之后,便于观察变量的值;
注意事项:要填入合法的表达式;
监视操作(手动添加):
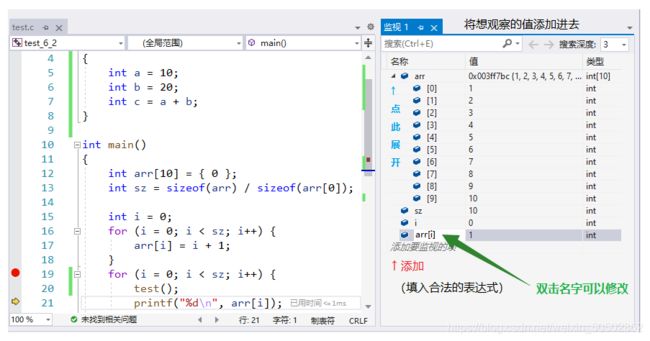
0x0A 自动窗口
作用:编辑器自行监视,随着代码自动给出值;
注意事项:
① 自动窗口和监视是一样的效果,但是自动窗口里的表达式会自动发生变化;
② 自由度低,自动窗口是编辑器自己监视,你管不了;
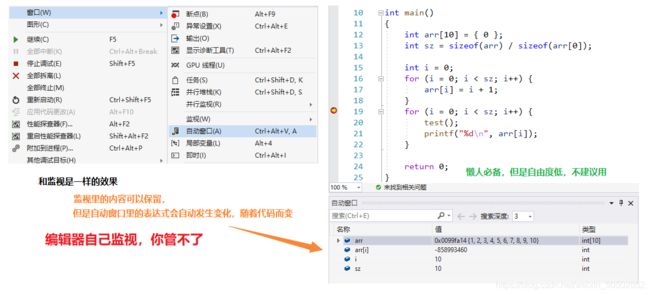
0x0B 查看局部变量
作用:查看程序进行到当前位置时上下文的局部变量,编辑器自主放到窗口中进行相应的解释,只有局部变量和数组;
查看局部变量:
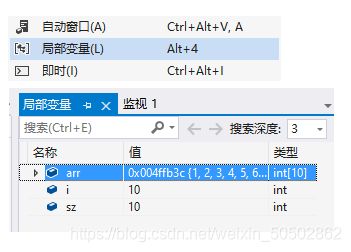
0x0C 查看内存信息
作用:在调试开始之后,用于观察内存信息;
查看内存信息:
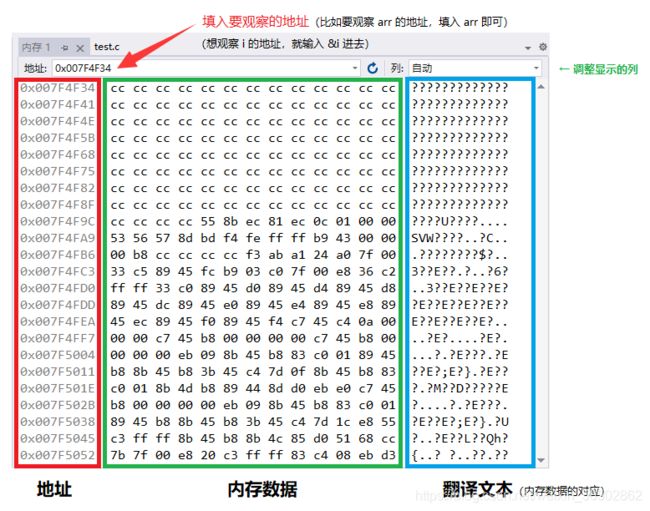
0x0D 查看调用堆栈
作用:通过调用堆栈,可以清晰地反应函数的调用关系和所处的位置;
查看调用堆栈:
0x0E 查看汇编信息
在调试开始后,有两种方式转到汇编:
① 第一种方式:右击鼠标,选择 " 转到反汇编 "
② 第二种方式:调试 → 窗口 → 反汇编
查看反汇编:

0x0F 查看寄存器信息
作用:可以查看当前运行环境的寄存器的实用信息;
查看寄存器:
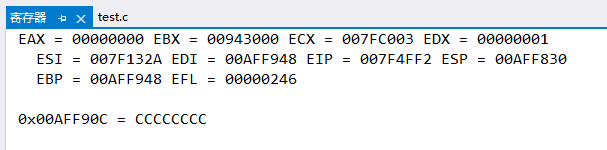
0x10 条件断点
❓ 假设某个循环要循环1000次,我怀疑第500次循环时程序会出问题,那么我要打上断点然后再按500次 F10 吗?这样一来手指头不得按断了?
方法:使用条件断点;
在断点设置好之后右键鼠标,选中条件:
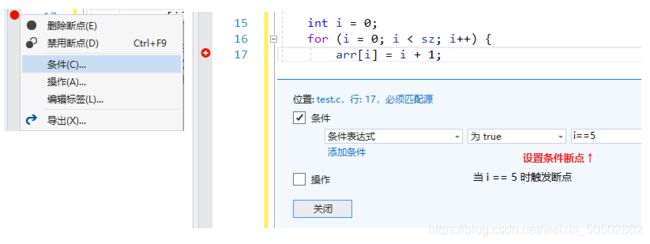
按下 F5 后,i 会直接变为 5 :
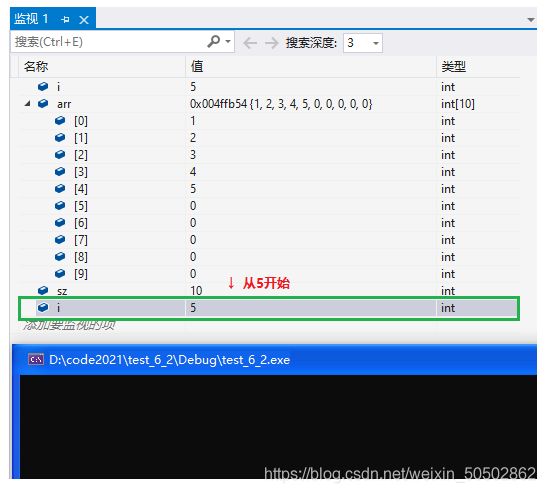
0x11 调试的感悟
箴言:
① 多多动手,尝试调试,才能有进步;
② 一定要熟练掌握调试的技巧;
③ 初学者可能80%的时间在写代码,20%的时间在调试。
但是一个程序员可能20%的时间在写程序,但是80%的时间在调试;
④ 我们所讲的都是一些简单的调试。
以后可能会出现很复杂的调试场景:多线程程序的调试等;
⑤ 多多使用快捷键,提升效率;
四、一些调试的实例
0x00 实例一
实现代码:求 1!+ 2! + 3! ··· + n!(不考虑溢出)
int main()
{
int n = 0;
scanf("%d", &n); // 3
// 1!+ 2!+ 3!
// 1 2 6 = 9
int i = 0;
int ret = 1;
int sum = 0;
int j = 0;
for (j = 1; j <= n; j++) {
for (i = 1; i <= j; i++) {
ret *= i;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
运行结果如下:
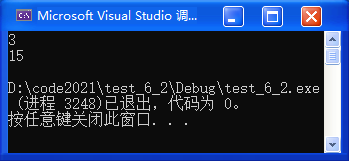
❓ 结果应该是9才对,但是输出结果为15,代码出错了;代码又没有语法错误,代码能够运行,属于运行时错误,而调试解决的就是运行时错误;
此时我们试着调试:
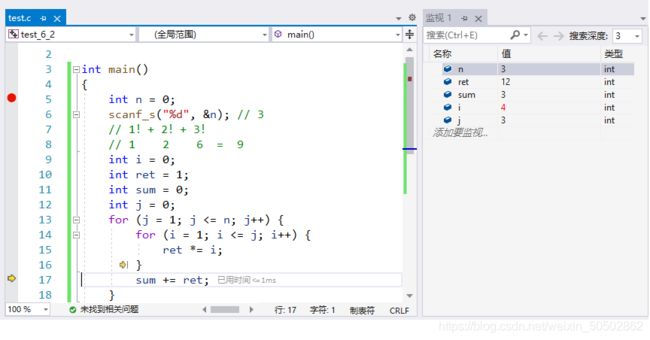
此时我们发现了问题:每一次求阶乘时,应该从1开始乘,所以每一次进入时 ret 要置为1;
int main()
{
int n = 0;
scanf_s("%d", &n); // 3
// 1!+ 2!+ 3!
// 1 2 6 = 9
int i = 0;
int ret = 1;
int sum = 0;
int j = 0;
for (j = 1; j <= n; j++) {
ret = 1; // 每次进入,置为1,重新开始乘
for (i = 1; i <= j; i++) {
ret *= i;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}运行结果如下:

解决问题:
① 要知道程序应该是什么结果:预期
② 调试的时候发现不符合预期,就找到问题了;
0x01 实例二
下列代码运行的结果是什么?
int main()
{
int i = 0;
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
// 越界访问了
for (i = 0; i <= 12; i++) {
printf("hehe\n");
arr[i] = 0;
}
return 0;
}运行结果如下:
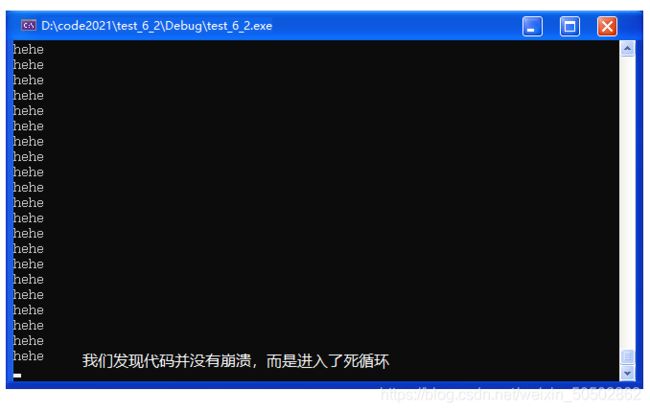
❓ 研究导致死循环的原因:
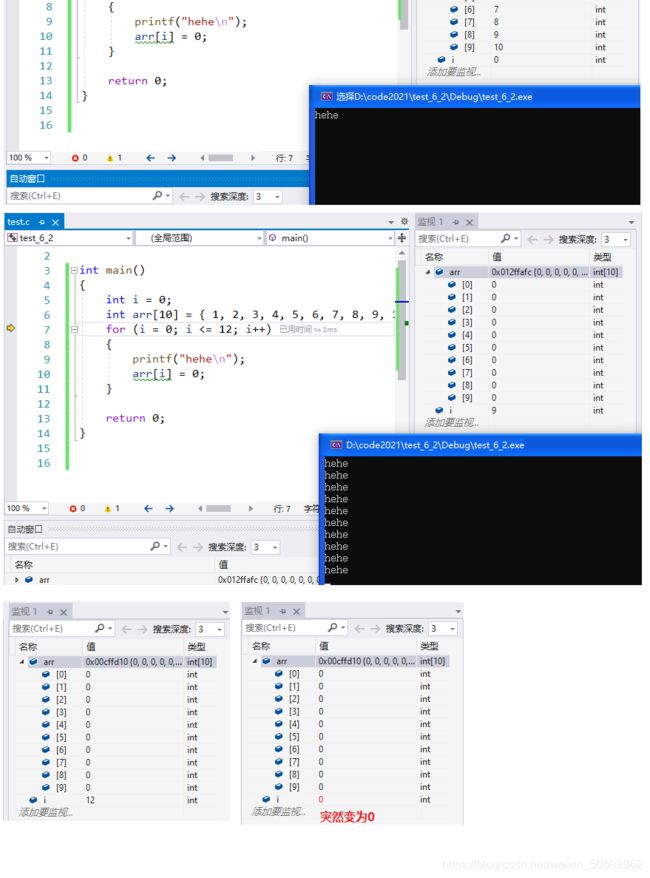

解析:

本题正确答案:死循环,因为 i 和 arr 是里昂个局部变量,先创建 i,再创建 arr,又因为局部变量是放在栈区上的,栈区的使用习惯是先使用高地址再使用低地址,所以内存的布局是这样子的(如图),又因为数组随着下标的增长地址是由低到高变化的,所以数组用下标访问时只要适当的越界,就有可能覆盖到 i,而 i 如果被覆盖的话,就会导致程序的死循环;
五、如何写出易于调试的代码(模拟实现strcpy)
0x00 优秀的代码

0x01 常见的coding技巧

0x02 strcpy函数介绍

/* strcpy: 字符串拷贝 */
#include
#include
int main()
{
char arr1[20] = "xxxxxxxxxx";
char arr2[] = "hello";
strcpy(arr1, arr2); // 字符串拷贝(目标字符串,源字符串)
printf("%s\n", arr1); // hello
return 0;
} 0x03 模拟实现strcpy
示例 - 模拟实现 strcpy
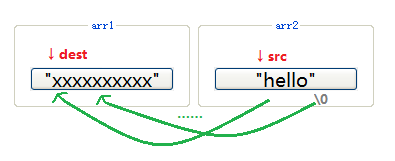
#include
char* my_strcpy (
char* dest, // 目标字符串
char* src // 源字符串
)
{
while (*src != '\0') {
*dest = *src;
dest++;
src++;
}
*dest = *src; // 拷贝'\0'
}
int main()
{
char arr1[20] = "xxxxxxxxxx";
char arr2[] = "hello";
my_strcpy(arr1, arr2);
printf("%s\n", arr1); // hello
return 0;
} 0x04 优化 - 提高代码简洁性
函数部分的代码,++ 部分其实可以整合到一起:
#include
char* my_strcpy (char* dest, char* src)
{
while (*src != '\0') {
*dest++ = *src++;
}
*dest = *src;
} 0x05 优化 - 修改while
2. 甚至可以把这些代码都放到 while 内:
( 利用 while 最后的判断 ,*dest++ = *src++ 正好拷走斜杠0 )
char* my_strcpy (char* dest, char* src)
{
while (*dest++ = *src++) // 既拷贝了斜杠0,又使得循环停止
;
}0x06 优化 - 防止传入空指针
❓ 如果传入空指针NULL,会产生BUG

解决方案:使用断言
断言是语言中常用的防御式编程方式,减少编程错误;
如果计算表达式expression值为假(0),那么向stderr打印一条错误信息,然后通过调用abort来终止程序运行;
断言被定义为宏的形式(assert(expression)),而不是函数;

#include
#include
char* my_strcpy(char* dest, char* src)
{
assert(dest != NULL); // 断言 "dest不能等于NULL"
assert(src != NULL); // 断言 "src 不能等于NULL"
while (*dest++ = *src++)
;
}
int main()
{
char arr1[20] = "xxxxxxxxxx";
char arr2[] = "hello";
my_strcpy(arr1, NULL); // 实验:传入一个NULL
printf("%s\n", arr1);
return 0;
}
运行结果如下:
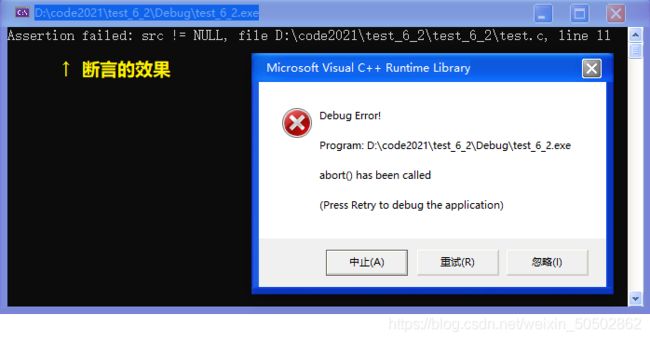
0x07 关于const的使用
将 num的值修改为20:
int main()
{
int num = 10;
int* p = #
*p = 20;
printf("%d\n", num);
return 0;
}20
此时在 int num 前放上 const :
const 修饰变量,这个变量就被称为常变量,不能被修改,但本质上还是变量;

但是!但是呢!!
int main()
{
const int num = 10;
int* p = #
*p = 20;
printf("%d\n", num);
return 0;
}运行结果如下
❗ 我们希望 num 不被修改,结果还是改了,这不出乱子了吗?!
num 居然把自己的地址交给了 p,然后 *p = 20,通过 p 来修改 num 的值,不讲武德!
解决方案:只需要在 int* p 前面加上一个 const,此时 *p 就没用了
int main()
{
const int num = 10;
const int* p = #
// 如果放在 * 左边,修饰的是 *p,表示指针指向的内容,是不能通过指针来改变的
*p = 20; // ❌ 不可修改
printf("%d\n", num);
return 0;
}运行结果如下:

解释:const 修饰指针变量的时候,const 如果放在 * 左边,修饰的是 *p,表示指针指向的内容是不能通过指针来改变的;
❓ 如果我们再加一个变量 n = 100, 我们不&num,我们&n,可不可以?
int main()
{
const int num = 10;
int n = 100;
const int* p = #
*p = 20 // ❌ 不能修改
p = &n; // ✅ 但是指针变量的本身是可以修改的
printf("%d\n", num);
return 0;
}可以,p 虽然不能改变 num,但是 p 可以改变指向,修改 p 变量的值
❓ 那把 const 放在 * 右边呢?
int main()
{
const int num = 10;
int n = 100;
int* const p = #
// 如果放在 * 右边,修饰的是指针变量p,表示的指针变量不能被改变
// 但是指针指向的内容,可以被改变
p = 20; // ✅ 可以修改
p = &n; // ❌ 不能修改
printf("%d\n", num);
return 0;
}此时指针指向的内容可以修改,但是指针变量
❓ 如果两边都放 const :
int main()
{
const int num = 10;
const int* const p = #
int n = 100;
*p = 20; // ❌ 不能修改
p = &n; // ❌ 不能修改
printf("%d\n", num);
return 0;
}0x08 优化 - 提高代码健壮性(加入const)

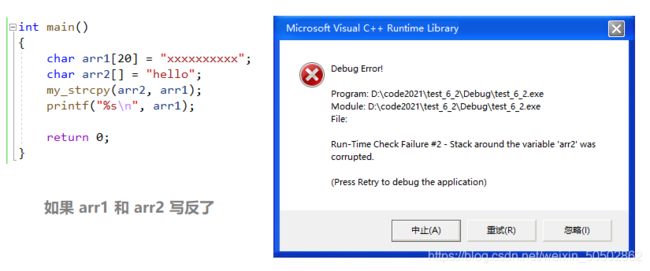
为了防止两个变量前后顺序写反,我们可以利用 const 常量,给自己“设定规矩”,这样一来,当我们写反的时候, 因为是常量的原因,不可以被解引用修改,从而报错,容易发现问题之所在!
char* my_strcpy (char* dest, const char* src)
{
assert(dest != NULL);
assert(src != NULL);
// while(*src++ = *dest) 防止写反,加一个const
while (*dest++ = *src++)
;
}可以无形的防止你写出 while(*src++ = *dest) ,即使你写错了,编译器也会报错(语法错误);
注意事项:按照逻辑加 const,不要随便加const(比如在dest前也加个const);
0x09 最终优化 - 使其支持链式访问
实现返回目标空间的起始位置
#include
#include
char* my_strcpy (char* dest,const char* src)
{
char* ret = dest; // 在刚开始的时候记录一下dest
assert(dest != NULL);
assert(src != NULL);
while (*dest++ = *src++)
;
return ret; // 最后返回dest
}
int main()
{
char arr1[20] = "xxxxxxxxxx";
char arr2[] = "hello";
printf("%s\n", my_strcpy(arr1, arr2)); // 链式访问
return 0;
} 0x0A 库函数写法
/***
*char *strcpy(dst, src) - copy one string over another
*
*Purpose:
* Copies the string src into the spot specified by
* dest; assumes enough room.
*
*Entry:
* char * dst - string over which "src" is to be copied
* const char * src - string to be copied over "dst"
*
*Exit:
* The address of "dst"
*
*Exceptions:
*******************************************************************************/
char * strcpy(char * dst, const char * src)
{
char * cp = dst;
assert(dst && src);
while( *cp++ = *src++ )
; /* Copy src over dst */
return( dst );
}
六、模拟实现strlen函数
0x00 计数器实现
#include
#include
int my_strlen(const char* str)
{
assert(str);
int count = 0;
while (*str) {
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
} 0x01 指针减指针实现
#include
#include
size_t my_strlen(const char* str)
{
assert(str);
const char* eos = str;
while (*eos++);
return(eos - str - 1);
}
int main()
{
char arr[] = "abcdef";
printf("%d\n", my_strlen(arr));
return 0;
} 0x02 库函数写法
/***
*strlen.c - contains strlen() routine
*
* Copyright (c) Microsoft Corporation. All rights reserved.
*
*Purpose:
* strlen returns the length of a null-terminated string,
* not including the null byte itself.
*
*******************************************************************************/
#include
#include
#pragma function(strlen)
/***
*strlen - return the length of a null-terminated string
*
*Purpose:
* Finds the length in bytes of the given string, not including
* the final null character.
*
*Entry:
* const char * str - string whose length is to be computed
*
*Exit:
* length of the string "str", exclusive of the final null byte
*
*Exceptions:
*
*******************************************************************************/
size_t __cdecl strlen (
const char * str
)
{
const char *eos = str;
while( *eos++ ) ;
return( eos - str - 1 );
}
size_t :无符号整型(unsigned int)
__cdecl :函数调用约定
七、编程常见的错误
0x00 编译型错误
直接看错误提示信息(双击),解决问题;
或者凭借经验就可以搞定,相对来说简单;
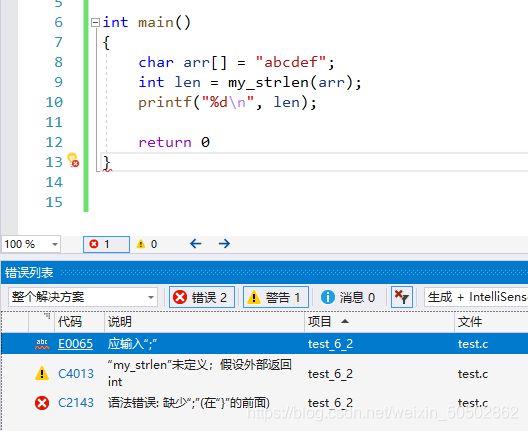
0x01 链接型错误
看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。
一般是 标识符名不存在 或者 拼写错误 ;

0x02 运行时错误
代码明明跑起来了,但是结果是错的;
借助调试,逐步定位问题,利用本章说的实用调试技巧解决;
0x03 建议
做一个有心人,每一次遇到错误都进行自我总结,积累错误经验!
第九章 - 数据的存储
前言:
本章将学习C语言数据的存储,对数据类型进行详细的介绍。正式讲解原码、反码、补码,以及大小端等知识,还会对浮点数的存储进行一个探讨,介绍IEEE754规定。
一、数据类型介绍
0x00 内置类型

0x01 类型的意义
意义:
① 类型决定开辟内存空间的大小(大小决定了使用的范围)
② 类型决定了看待内存空间的视角
二、类型的基本归类
0x00 整型家族

❓ 为什么 char 算整型:
因为字符类型底层存储的是 ASCII 码值,而ASCII码值也是整数,所以在归类的时候会把 char 类型归结到整型家族里去。( ASCII码:美国信息交换标准代码 )
(有符号类型和无符号类型本文后续会详细讲解)
0x01 浮点型家族
0x02 构造类型
定义:构造类型又叫自定义类型,是我们自己创建的类型;
注意事项:他们都是整型数组,但是他们的类型完全不一样
int arr[10]; 类型为:int[10]
int arr2[5]; 类型为:int[5] 0x03 指针类型
0x04 空类型
![]()
void 表示空类型(无类型),通常应用于函数的返回类型、函数的参数、指针类型
void 定义函数返回类型和函数参数:
void test(void) // 不需要返回值的函數
{
printf("hehe\n");
}
int main(void)
{
test(); // test(100) error 函数内声明的是无参
return 0;
}void 定义空指针:
void* p三、整型在内存中的存储
0x00 引入
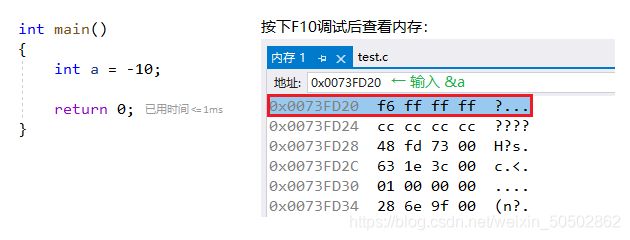
数据在内存中以2进制的形式存储:
① 对于整数来说,内存中存储的二进制有3种表示形式:原码、反码、补码
② 正整数:原码、反码、补码相同
③ 负整数:原码、反码、补码要进行计算
0x00 原码
原码:按照数据的数值直接写出的二进制序列就是原码

❗ 符号位:最高位1表示负数,最高位0表示正数
0x01 反码
反码:原码的符号位不变,其他位按位取反,即为反码
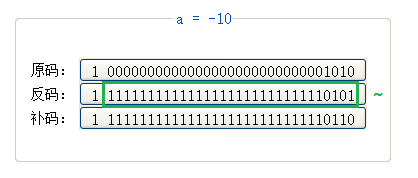
0x02 补码
补码:反码 +1,得到的就是补码

0x03 内存中为何存放补码
此时我们再看前面引入里提到的:
虽然整数的二进制表示形式有三种,但是内存中存储的是补码

结论:整数在内存中存储的是补码
❓ 为什么在内存中存的是补码呢:
在计算机系统中,整数数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数字域统一处理;同时,加法和减法也可以统一处理( CPU只有加法器 )。此外,补码与补码相互转换,其运算过程是相同的,不需要额外的硬件电路。
四、大小端
0x00 问题引入
我们在仔细观察下刚才内存中的存储,这次我们再添加一个 b = 10
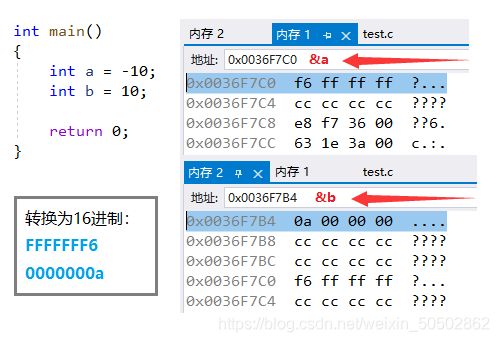
❓ 我们可以看到对于 a 和 b 分别存储的是补码,
但是我们发现顺序好像是倒过来的,为什么会这样呢?
大端小端存储问题,当一个数据的大小存储到内存空间大于1个字节时,会存在一个存储顺序的问题,这个存储顺序的问题就有两种,一个为大端,一个为小端。

0x01 大端模式
作用:把数据的低位保存在内存的高地址处,高位字节序的内容存放在低地址中(正着存)
总结:大端模式,低位放在高地址,高位放在低地址
0x02 小端模式
作用:把数据的低位保存在内存的低地址处,高位字节序的内容存放在高地址中(倒着存)
总结:小端模式,低位放在低地址,高位放在高地址
0x03 产生的原因
❓ 为什么会有大端和小端呢:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一 个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具 体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小 端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小 端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
0x04 判断当前系统大小端
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序(10分)
实现思路:
代码实现:
int main()
{
int a = 1;
char* pa = (char*)&a; // 这里需要进行一下强制类型转换
if(*pa == 1)
printf("小端");
else
printf("大端");
return 0;
}⚡ 优化 - 封装成函数:
int check_sys()
{
int a = 1;
char* pa = (char*)&a;
return *pa; // 返回1表示小端,返回0表示大端
// return *(char*)&a;
}
int main()
{
int ret = check_sys();
if(ret == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}五、有符号数和无符号数
0x00 定义
无符号数(unsigned),有符号数(signed)
0x01 两种char的范围
有符号 char 的范围是: -128 ~ 127
无符号 char 的范围是: 0 ~ 255
signed char 解析:
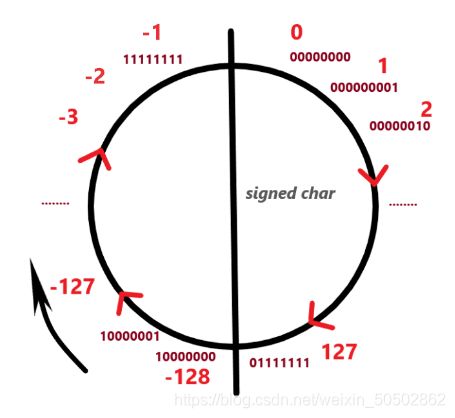
0x02 专项练习
练习1:
下列代码的输出结果是什么?
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d, b=%d, c=%d", a, b, c);
return 0;
}a = -1, b = -1, c = 255
解析:

注意事项:
① int 就是 signed int,short 是 signed short ……这是 C语言标准 规定的。
② 但是,char 比较特殊!char 到底是 signed char 还是 unsigned char,C语言标准 并没有规定,取决于编译器,大部分编译器 char 指的都是 signed char 。
练习2:
下列程序输出的结果是什么?
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}4294967168
解析:

❓ 如果不用 %u 形式打印,用 %d 形式打印的是什么:

练习3:
和上题相似,运行后结果是什么?
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}4294967168
解析:

❓ char a 放得下128吗?
(只是放进去了一部分,发生了截断)
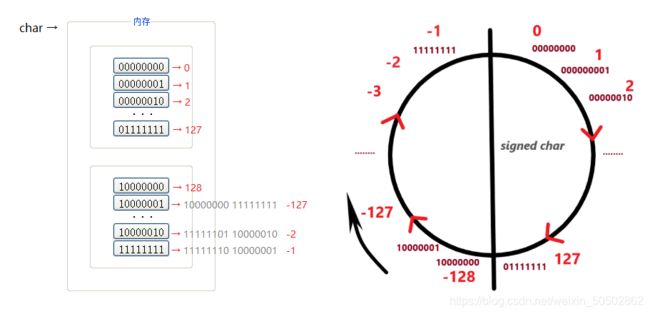
练习4:
下列代码运行结果是什么?
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--) {
printf("%u\n", i);
}
return 0;
}
运行结果如下:
解析:因为 i 是一个无符号整型,判断条件为 i >= 0,因为什么情况下 i 都不可能小于0,所以这个条件恒成立,恒成立导致死循环。
练习5:
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++) {
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
255
解析:
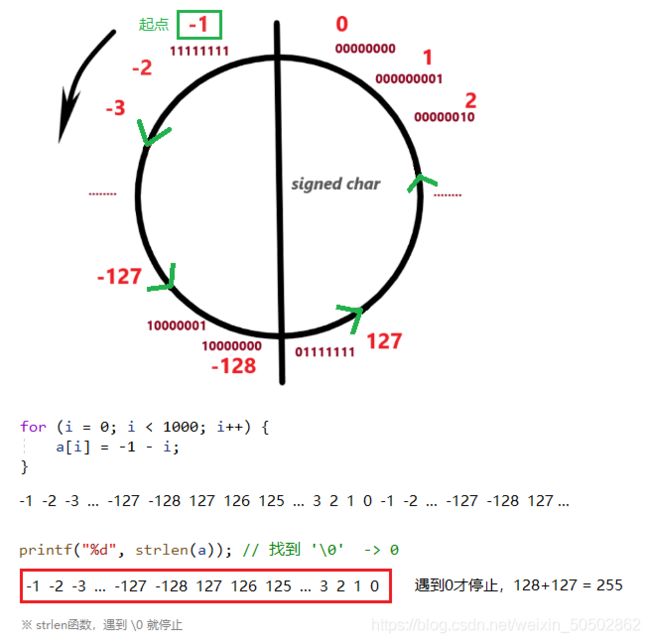
练习6:
下列代码运行后结果是什么?
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++) {
printf("hello world\n");
}
return 0;
}运行结果如下:
解析:i 是无符号 char,无符号 char 的取值范围为 0 ~ 255,而判断条件为 i <= 255,这个条件永远都满足不了,因为无符号 char 里面能放的最大的值就是 255,所以是死循环。
六、浮点数在内存中的存储
0x00 常见的浮点数
浮点数家族包括:float、double、long double 类型
0x01 查看定义取值范围
整型的取值范围:limit.h 中定义
浮点数的取值范围:float.h 中定义
0x02 浮点数存储的例子
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为: %d\n", n);
printf("*pFloat的值为 %f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为: %d\n", n);
printf("*pFloat的值为: %f\n", *pFloat);
return 0;
}运行结果如下:

❓ num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和正数的解读结果会差别这么大?
解析:
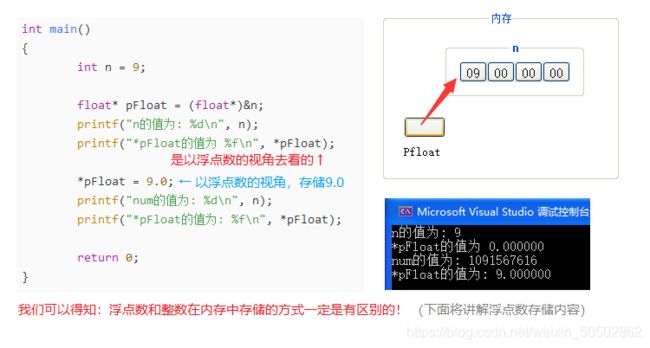
0x03 IEEE754规定
IEEE754:根据国际标准IEEE(电器和电子工程协会)754 规定,任意一个二进制浮点数V可以表示成以下形式: (-1)^S * M * 2^E
① (-1)^s 表示符号位,当 s = 0,V为正数;当s = 1, v为负数
② M表示有效数字,大于等于1,小于2
③ 2^E 表示指数位
例子:
浮点数:5.5 - 10进制
二进制:101.1 → 1.011 * 2^2 → (-1) ^0 * 1.011 * 2^2
s=0 M=1.011 E=2
IEEE 754 规定:
对于32位的浮点数,最高的1位是符号位S,接着8位是指数E,剩下的23位位有效数字M:

对于64位的浮点数,最高位1位是符号位S,接着的11位是指数E,剩下的52位位有效数字M:
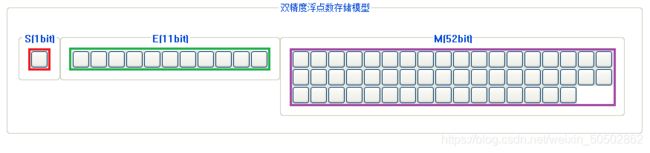
IEEE 754对有效数字M和指数E,还有一些特别规定。 前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形 式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。 比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。 以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int) 这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的 取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真 实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如,2^10的E 是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前 加上第一位的1。 比如: 0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位, 则为1.0*2^(-1),其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位 00000000000000000000000,则其二进制表示形式为
0 01111110 00000000000000000000000E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值, 有效数字M不再加上第一位的1,而是还原为 0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
0x04 解释前面的例子

第十章 - 指针的进阶(上)
前言:
指针的主题,我们在初级阶段的 【维生素C语言】第六章 - 指针 章节已经接触过了,我们知道了指针的概念:
1. 指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
2. 指针的大小是固定的4/8个字节(32位平台/64位平台)。
3. 指针是有类型的,指针的类型决定了指针的 + - 整数步长,指针解引用操作时的权限。
4. 指针的运算。
这个章节,我们将继续探讨指针的高级主题。
【维生素C语言】第十章 - 指针的进阶(下)
一、字符指针
0x00 字符指针的定义
定义:字符指针,常量字符串,存储时仅存储一份(为了节约内存)
![]()
0x01 字符指针的用法
用法:
int main()
{
char ch = 'w';
char *pc = &ch;
*pc = 'w';
return 0;
}关于指向字符串:
❓ 这里是把一个字符串放在 pstr 里了吗?
int main()
{
char* pstr = "hello world";
printf("%s\n", pstr);
return 0;
}hello world
解析:上面代码 char* pstr = " hello world " 特别容易让人以为是把 hello world 放在字符指针 pstr 里了,但是本质上是把字符串 hello world 首字符的地址放到了 pstr 中;
0x02 字符指针练习
下列代码输出什么结果?
int main()
{
char str1[] = "abcdef";
char str2[] = "abcdef";
const char* str3 = "abcdef";
const char* str4 = "abcdef";
if (str1 == str2)
printf("str1 == str2\n");
else
printf("str1 != str2\n");
if (str3 == str4)
printf("str3 == str4\n");
else
printf("str3 != str4\n");
return 0;
}运行结果如下:

解析:
① 在内存中有两个空间,一个存 arr1,一个存 arr2,当两个起始地址在不同的空间上的时候,这两个值自然不一样,所以 arr1 和 ar2 不同。
② 因为 abcdef 是常量字符串,本身就不可以被修改,所以内存存储的时候为了节省空间只存一份,叫 abcdef。这时,不管是 p1 还是 p2,都指向同一块空间的起始位置,即第一个字符的地址,p1 和 p2值又一模一样,所以 arr3 和 arr4 相同。
0x03 Segmentfault 问题
把一个常量字符串的首字符 a 的地址存放到指针变量 pstr 中:
二、指针数组
0x00 指针数组的定义
指针数组是数组,数组:数组中存放的是指针(地址)

[] 优先级高,先与 p 结合成为一个数组,再由 int* 说明这是一个整型指针数组,它有 n 个指针类型的数组元素。这里执行 p+1 时,则 p 指向下一个数组元素。

0x01 指针数组的用法
几乎没有场景用得到这种写法,这个仅供理解:
int main()
{
int a = 10;
int b = 20;
int c = 30;
int* parr[4] = {&a, &b, &c};
int i = 0;
for(i=0; i<4; i++) {
printf("%d\n", *(parr[i]) );
}
return 0;
}10 20 30
指针数组的用法:
#include
int main()
{
int arr1[] = {1, 2, 3, 4, 5};
int arr2[] = {2, 3, 4, 5, 6};
int arr3[] = {3, 4, 5, 6, 7};
int* p[] = { arr1, arr2, arr3 }; // 首元素地址
int i = 0;
for(i=0; i<3; i++) {
int j = 0;
for(j=0; j<5; j++) {
printf("%d ", *(p[i] + j)); // j-> 首元素+0,首元素+1,+2...
// == p[i][j]
}
printf("\n");
}
return 0;
} 运行结果如下:
解析:

三、数组指针
0x00 数组指针的定义
数组指针是指针,是指向数组的指针,数组指针又称 行指针,用来存放数组的地址
整形指针 - 是指向整型的指针
字符指针 - 是指向字符的指针
数组指针 - 是指向数组的指针

int main()
{
int a = 10;
int* pa = &a;
char ch = 'w';
char* pc = &ch;
int arr[10] = {1,2,3,4,5};
int (*parr)[10] = &arr; // 取出的是数组的地址
// parr 就是一个数组指针
return 0;
}试着写出 double* d [5] 的数组指针:
double* d[5];
double* (*pd)[5] = &d;0x01 数组名和&数组名的区别
观察下列代码:
int main()
{
int arr[10] = {0};
printf("%p\n", arr);
printf("%p\n", &arr);
return 0;
}
运行后我们发现,它们地址是一模一样的
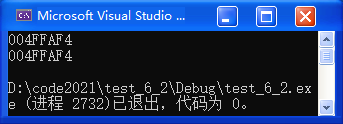
解析:

验证:
int main()
{
int arr[10] = { 0 };
int* p1 = arr;
int(*p2)[10] = &arr;
printf("%p\n", p1);
printf("%p\n", p1 + 1);
printf("%p\n", p2);
printf("%p\n", p2 + 1);
return 0;
}运行结果如下:

数组名是数组首元素的地址,但是有 2 个 例外:
① sizeof ( 数组名 ) - 数组名表示整个数组,计算的是整个数组的大小,单位是字节。
② &数组名 - 数组名表示整个数组,取出的是整个数组的地址。
0x02 数组指针的用法
数组指针一般不在一维数组里使用:
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int (*pa)[10] = &arr; // 指针指向一个数组,数组是10个元素,每个元素是int型
int i = 0;
for(i=0; i<10; i++) {
printf("%d ", *((*pa) + i));
}
return 0;
}❓ 上面的代码是不是有点别扭?数组指针用在这里非常尴尬,并不是一种好的写法。
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = arr;
int i = 0;
for(i=0; i<10; i++) {
printf("%d ", *(p + i));
}
return 0;
}二维数组以上时使用数组指针:
void print1 (
int arr[3][5],
int row,
int col
)
{
int i = 0;
int j = 0;
for(i=0; i运行结果如下:
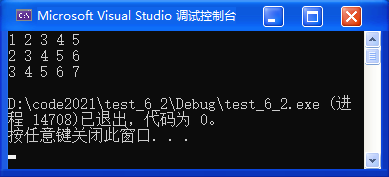
0x03 关于数组访问元素的写法
以下写法全部等价:
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
int* p = arr;
for(i=0; i<10; i++)
{
//以下写法全部等价
printf("%d ", p[i]);
printf("%d ", *(p+i));
printf("%d ", *(arr+i));
printf("%d ", arr[i]); //arr[i] == *(arr+i) == *(p+i) == p[i]
}
}0x04 练习
分析这些代码的意思:
int arr[5];
int* parr1[10];
int (*parr2)[10];
int (*parr3[10])[5];解析:

四、数组参数和指针参数
写代码时要把数组或者指针传递给函数的情况在所难免,那函数参数该如何设计呢?
0x00 一维数组传参
判断下列形参的设计是否合理:

void test(int arr[]) //合理吗?
{}
void test(int arr[10]) // 合理吗?
{}
void test(int *arr) // 合理吗?
{}
void test(int *arr[]) // 合理吗?
{}
void test2(int *arr[20]) // 合理吗?
{}
void test2(int **arr) // 合理吗?
{}
int main()
{
int arr[10] = {0};
int* arr2[20] = {0};
test(arr);
test2(arr2);
}答案:以上都合理
解析:
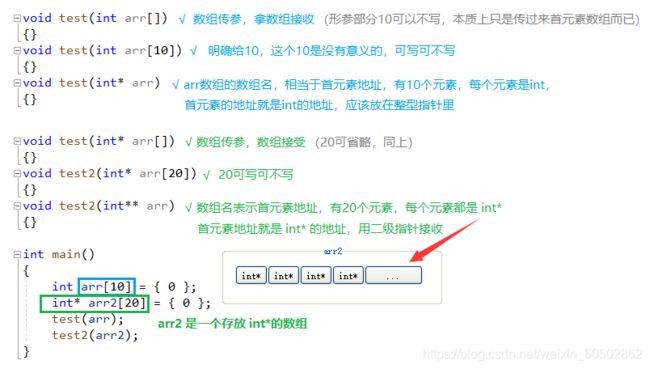
0x01 二维数组传参
判断下列二维数组传参是否合理:
void test(int arr[3][5]) // 合理吗?
{}
void test(int arr[][5]) // 合理吗?
{}
void test(int arr[3][]) // 合理吗?
{}
void test(int arr[][]) // 合理吗?
{}
int main()
{
int arr[3][5] = {0};
test(arr); // 二维数组传参
return 0;
} 答案:前两个合理,后两个不合理
解析:

总结:二维数组传参,函数形参的设计只能省略第一个 [ ] 的数字(行可省略但列不可以省略)
因为对一个二维数组来说,可以不知道有多少行,但是必须确定一行有多少多少元素!
判断下列二维数组传参是否合理:
void test(int* arr) // 合理吗?
{}
void test(int* arr[5]) // 合理吗?
{}
void test(int(*arr)[5]) // 合理吗?
{}
void test(int** arr) // 合理吗?
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
return 0;
}
答案:只有第三个合理,其他都不合理
解析:

0x02 一级指针传参
一级指针传参例子:
void print(int* ptr, int sz) // 一级指针传参,用一级指针接收
{
int i = 0;
for(i=0; i1 2 3 4 5 6 7 8 9 10
❓ 思考:当函数参数为一级指针的时,可以接收什么参数?
一级指针传参,一级指针接收:
void test1(int* p)
{}
void test2(char* p)
{}
int main()
{
int a = 10;
int* pa = &a;
test1(&a); // ✅
test1(pa); // ✅
char ch = 'w';
char* pc = &ch;
test2(&ch); // ✅
test2(pc); // ✅
return 0;
}需要掌握:
① 我们自己在设计函数时参数如何设计
② 别人设计的函数,参数已经设计好了,我该怎么用别人的函数
0x03 二级指针传参
二级指针传参例子:
void test(int** ptr)
{
printf("num = %d\n", **ptr);
}
int main()
{
int n = 10;
int* p = &n;
int** pp = &p;
// 两种写法,都是二级指针
test(pp);
test(&p); // 取p指针的地址,依然是个二级指针
return 0;
}num = 10 num = 10
❓ 思考:当函数的参数为二级指针的时候,可以接收什么参数?
当函数参数为二级指针时:
void test(int **p) // 如果参数时二级指针
{
;
}
int main()
{
int *ptr;
int** pp = &ptr;
test(&ptr); // 传一级指针变量的地址 ✅
test(pp); // 传二级指针变量 ✅
//指针数组也可以
int* arr[10];
test(arr); // 传存放一级指针的数组,因为arr是首元素地址,int* 的地址 ✅
return 0;
}第十章 - 指针的进阶(下)
前言:
传送门:【维生素C语言】第十章 - 指针的进阶(上)
本章将继续对继续讲解指针的进阶部分,并对指针知识进行一个总结。并且介绍qsort函数的用法以及模拟实现qsort函数。本章学习完毕后C语言指针专题就结束了,配备了相应的练习和讲解,强烈推荐做一做。另外,C语言的指针靠这个专题并不能完全讲完,还有更多指针的用法需要通过书籍、实战进行学习,不断地积累才能学好C语言最具代表性的东西——指针。
知识梳理:
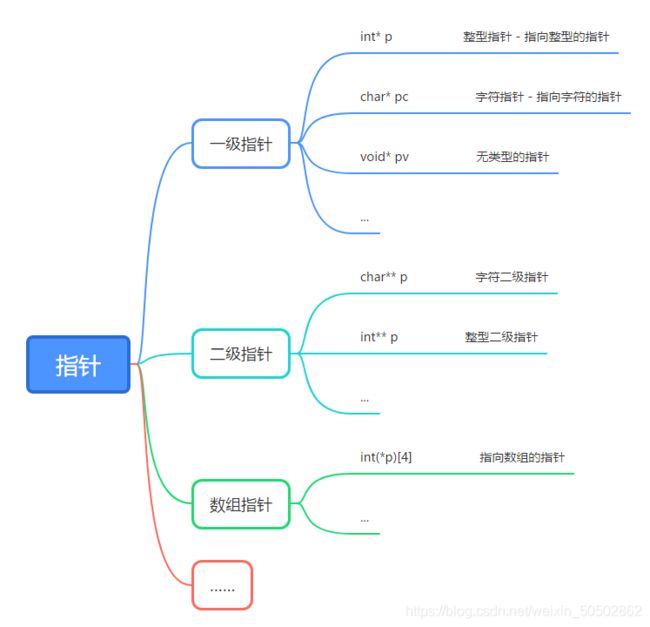
int main()
{
int a = 10;
int* pa = &a;
char ch = 'w';
char* pc = &ch;
int arr[10] = {0};
int (*parr)[10] = &arr; // 取出数组的地址
return 0;
}一、函数指针
0x00 函数指针介绍
指针数组:存放指针的数组。数组指针:指向数组的指针,
函数指针:指向函数的指针,存放函数地址的指针。

0x01 取函数指针地址
函数也是有地址的,取函数地址可以通过 &函数名 或者 函数名 实现。
注意事项:
① 函数名 == &函数名 (这两种写法只是形式上的区别而已,意义是一模一样的)
② 数组名 != &数组名
取函数地址:
int Add(int x, int y)
{
return x + y;
}
int main()
{
// 函数指针 - 存放函数地址的指针
// &函数名 - 取到的就是函数的地址
printf("%p\n", &Add);
printf("%p\n", Add);
return 0;
}
运行结果如下:
0x02 函数指针的定义
函数返回类型( * 指针变量名 )( 函数参数类型... ) = &函数名;
创建函数指针变量:
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*pf)(int, int) = &Add;
// pf 就是一个函数指针变量
return 0;
}解析:

函数指针定义练习:
请完成下面函数指针的定义。
void test(char* str)
{
;
}
int main()
{
pt = &test;
return 0;
}参考答案:
void (*pt)(char*) = &test
0x03 函数指针的调用
( *指针变量名 )( 传递的参数... );
函数指针的调用:
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*pf)(int, int) = &Add;
int ret = (*pf)(3, 5);
// 对 pf 进行解引用操作,找到它所指向的函数,然后对其传参
printf("%d\n", ret);
return 0;
}
❓ 那能不能把 (*pf) (3,5) 写成 *pf (3,5) 呢?

答:不行,这么写会导致星号对函数返回值进行解引用操作,这合理吗?这不合理!所以如果你要加星号,一定要用括号括起来。当然你可以选择不加,因为不加也可以:
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*pf)(int, int) = &Add;
// int ret = Add(3, 5);
int ret = pf(3, 5);
printf("%d\n", ret);
return 0;
}解析:结果是一样的,说明 (*pf)只是摆设,没有实际的运算意义,所以 pf(3, 5) 也可以。
总结:
Add(3, 5); // ✅
(*pf)(3, 5); // ✅
pf(3, 5); // ✅
*pf(3, 5); // ❌字符指针 char* 型函数指针:
void Print(char*str)
{
printf("%s\n", str);
}
int main()
{
void (*p)(char*) = Print; // p先和*结合,是指针
(*p)("hello wrold"); // 调用这个函数
return 0;
}hello world
0x04 分析下列代码
《C陷阱与缺陷》中提到了这两个代码。
代码1:
(*(void (*)())0)();解析:这段代码的作用其实是调用 0 地址处的函数,该函数无参,返回类型是 void


代码2:
void (*signal(int, void(*)(int)))(int);解析:

⚡ 简化代码:

int main()
{
void (* signal(int, void(*)(int)) )(int);
// typedef void(*)(int) pfunc_t; ❌ 不能这么写,编译器读不出
typedef void(*pfun_t)(int); // 对void(*)(int)的函数指针类型重命名为pfun_t
pfun_t signal(int, pfun_t); // 和上面的写法完全等价
return 0;
}二、函数指针数组
数组是一个存放相同类型数据的存储空间,我们已经学习了指针数组,比如:
int *arr[10]; // 函数的每个元素都是 *int 指针数组
0x00 函数指针数组的介绍
如果要把函数的地址存到一个数组中,那这个数组就叫 函数指针数组
![]()
0x01 函数指针数组的定义
函数指针数组的定义:
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int main()
{
int (*pf)(int, int) = Add;
int (*pf2)(int, int) = Sub;
int (*pfArr[2])(int, int) = {Add, Sub};
// pfArr 就是函数指针数组
return 0;
}0x02 函数指针数组的应用
实现一个计算器,可以进行简单的加减乘除运算。
代码1:
#include
void menu()
{
printf("*****************************\n");
printf("** 1. add 2. sub **\n");
printf("** 3. mul 4. div **\n");
printf("** 0. exit **\n");
printf("*****************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
int main()
{
// 计算器 - 计算整型变量的加、减、乘、除
int input = 0;
do {
menu();
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:> ");
scanf("%d", &input);
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
switch(input) {
case 1:
ret = Add(x, y);
break;
case 2:
ret = Div(x, y);
break;
case 3:
ret = Mul(x, y);
break;
case 4:
ret = Div(x, y);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("重新选择\n");
break;
}
printf("ret = %d\n", ret);
} while(input);
return 0;
}
让我们来测试一下代码:
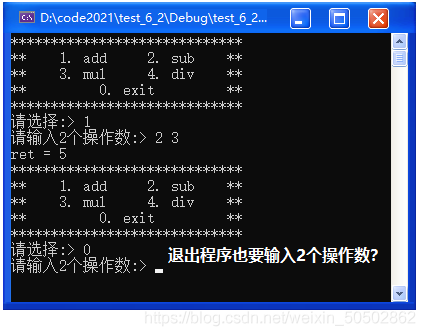
❗ 此时我们发现了问题点,即使选择0或选择错误,程序也依然要求你输入2个操作数。这合理吗?这不合理!所以我们需要对代码进行修改:
① 需要计算才让用户输入2个操作数
② 计算完之后有结果才打印
修改:
#include
void menu()
{
printf("*****************************\n");
printf("** 1. add 2. sub **\n");
printf("** 3. mul 4. div **\n");
printf("** 0. exit **\n");
printf("*****************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
int main()
{
int input = 0;
do {
menu();
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:> ");
scanf("%d", &input);
switch(input) {
case 1:
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("重新选择\n");
break;
}
} while(input);
return 0;
} 让我们来测试一下代码:
❗ 修改之后代码合理多了,虽然功能都实现了,但是存在可以优化的地方:
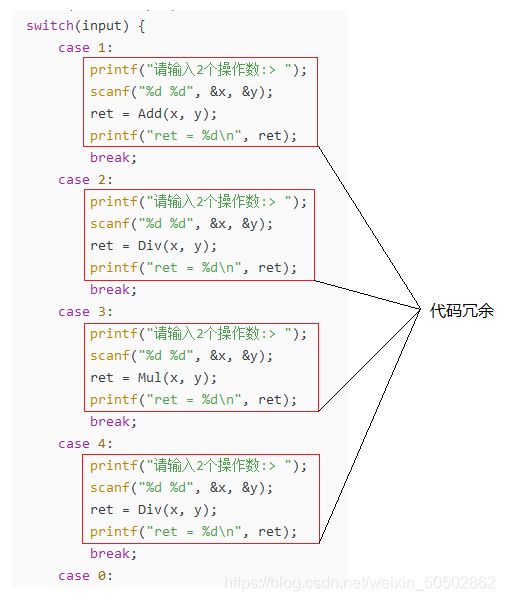
① 当前代码比较冗余,存在大量重复出现的语句。
② 添加计算器的功能(比如 a & b)时每加一个功能都要写一段case,能否更方便地增加?
⚡ 使用函数指针数组改进代码:
#include
void menu()
{
printf("*****************************\n");
printf("** 1. add 2. sub **\n");
printf("** 3. mul 4. div **\n");
printf("** 0. exit **\n");
printf("*****************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
int main()
{
int input = 0;
do {
menu();
// pfArr 就是函数指针数组
int (*pfArr[5])(int, int) = {NULL, Add, Sub, Mul, Div};
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:> ");
scanf("%d", &input);
if(input >= 1 && input <= 4) {
printf("请输入2个操作数:> ");
scanf("%d %d", &x, &y);
ret = (pfArr[input])(x, y);
printf("ret = %d\n", ret);
}
else if(input == 0) {
printf("退出程序\n");
break;
} else {
printf("选择错误\n");
}
} while(input);
return 0;
} 让我们来测试一下代码:

解析:这就是函数指针数组的应用。接收一个下标,通过下标找到数组里的某个元素,这个元素如果恰好是一个函数的地址,然后去调用那个函数。它做到了一个 "跳板" 的作用,所以我们通常称这种数组叫做 转移表(转移表在《C和指针》这本书中有所提及)。
三、指向函数指针数组的指针
0x00 函数指针数组的指针定义
定义:指向函数指针数组的指针是一个指针,指针指向一个数组,数组的元素是函数指针。
![]()

0x01 函数指针数组的例子
ppfArr 就是一个函数指针数组:
int Add(int x, int y) {
return x + y;
}
int main()
{
int arr[10] = {0};
int (*p)[10] = &arr; // 取出数组的地址
int (*pfArr[4])(int, int); // pfArr是一个数组 - 函数指针的数组
// ppfArr是一个指向[函数指针数组]的指针
int (* (*ppfArr)[4])(int, int) = &pfArr;
// ppfArr 是一个数组指针,指针指向的数组有4个元素
// 指向的数组的每个元素的类型是一个函数指针 int(*)(int, int)
return 0;
}0x02 指针的总结
指针:

四、回调函数(call back)
0x00 回调函数的概念
回调函数是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时候,我们就称之为回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的时间或条件发生时由另外的一方调用的,用于该事件或条件进行响应。
0x01 回调函数的例子
用刚才的 switch 版本的计算器为例:
#include
void menu()
{
printf("*****************************\n");
printf("** 1. add 2. sub **\n");
printf("** 3. mul 4. div **\n");
printf("** 0. exit **\n");
printf("*****************************\n");
}
int Add(int x, int y) {
return x + y;
}
int Sub(int x, int y) {
return x - y;
}
int Mul(int x, int y) {
return x * y;
}
int Div(int x, int y) {
return x / y;
}
void Calc(int (*pf)(int, int))
{
int x = 0;
int y = 0;
printf("请输入2个操作数:>");
scanf("%d %d", &x, &y);
printf("%d\n", pf(x, y));
}
int main()
{
int input = 0;
do {
menu();
printf("请选择:>");
scanf("%d", &input);
switch(input) {
case 1:
Calc(Add);
break;
case 2:
Calc(Sub);
break;
case 3:
Calc(Mul);
break;
case 4:
Calc(Div);
break;
case 0:
printf("退出\n");
break;
default:
printf("选择错误\n");
break;
}
} while(input);
return 0;
} 解析:上面的代码做到了想要做什么计算就做什么计算的目的,这就是函数指针能够做到的事。一个 Calc 函数就可以做很多的功能,给它传递不同的参数,它就可以做不同的事情。

0x02 无指针类型 void*
void*0x03 qsort 函数
说明:qsort 函数是C语言编译器函数库自带的排序函数( 需引入头文件 stdlib.h )

回顾冒泡排序:
【维生素C语言】第四章 - 数组 ( 3 - 0x01 )
#include
void bubble_sort (int arr[], int sz)
{
int i = 0;
// 确认趟数
for (i = 0; i < sz-1; i++) {
// 一趟冒泡排序
int j = 0;
for (j = 0; j < sz-1-i; j++) {
if(arr[j] > arr[j + 1]) {
// 交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[10] = {9,8,7,6,5,4,3,2,1,0};
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);
bubble_sort(arr, sz);
print_arr(arr, sz);
return 0;
} ❓ 问题点:我们自己实现的冒泡排序函数只能排序整型顺序,如果我们要排序字符串或者一个结构体,我们是不是要单独重新实现这个函数呢?而 qsort 函数可以帮我们排任意想排的数据类型。
qsort 函数的四个参数:


qsort 整型数据排序(升序):
#include
#include
/*
void qsort (
void* base,
size_t num,
size_t size,
int (*cmp_int)(const void* e1, const void* e2)
);
*/
int cmp_int(const void* e1, const void* e2)
{
// 升序: e1 - e2
return *(int*)e1 - *(int*)e2;
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
void int_sort()
{
int arr[] = {9,8,7,6,5,4,3,2,1,0};
int sz = sizeof(arr) / sizeof(arr[0]);
// 排序(分别填上四个参数)
qsort(arr, sz, sizeof(arr[0]), cmp_int);
// 打印
print_arr(arr, sz);
}
int main()
{
int_sort();
return 0;
} 0 1 2 3 4 5 6 7 8 9
❓ 如果我想测试一个结构体数据呢?
那我们就写结构体的cmp函数(升序):
( 需求:结构体内容为 " 姓名 + 年龄 ",使用qsort,实现按年龄排序和按姓名排序 )
#include
#include
#include
struct Stu
{
char name[20];
int age;
};
/*
void qsort (
void* base,
size_t num,
size_t size,
int (*cmp_int)(const void* e1, const void* e2)
);
*/
int cmp_struct_age(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int cmp_struct_name(const void* e1, const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
void struct_sort()
{
// 使用qsort函数排序结构体数据
struct Stu s[3] = {
{"Ashe", 39},
{"Hanzo", 38},
{"Ana", 60}
};
int sz = sizeof(s) / sizeof(s[0]);
// 按照年龄排序
qsort(s, sz, sizeof(s[0]), cmp_struct_age);
// 按照名字来排序
qsort(s, sz, sizeof(s[0]), cmp_struct_name);
}
int main()
{
struct_sort();
return 0;
} 解析:按照年龄排序则比较年龄的大小,按照名字排序本质上是比较Ascii码的大小。

❓ 现在是升序,如果我想实现降序呢?
很简单,只需要把 e1 - e2 换为 e2 - e1 即可:
int cmp_int(const void* e1, const void* e2)
{
// 降序: e2 - e1
return( *(int*)e2 - *(int*)e1 );
}
int cmp_struct_age(const void* e1, const void* e2)
{
return( ((struct Stu*)e2)->age - ((struct Stu*)e1)->age );
}
int cmp_struct_name(const void* e1, const void* e2)
{
return( strcmp(((struct Stu*)e2)->name, ((struct Stu*)e1)->name) );
}0x04 模拟实现 qsort 函数
模仿 qsort 实现一个冒泡排序的通用算法
完整代码(升序):
#include
#include
struct Stu
{
char name[20];
char age;
};
// 模仿qsort实现一个冒泡排序的通用算法
void Swap(char*buf1, char*buf2, int width) {
int i = 0;
for(i=0; i 0) {
//交换
Swap((char*)base+j*width, (char*)base+(j+1)*width, width);
}
}
}
}
int cmp_struct_age(const void* e1, const void* e2) {
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int cmp_struct_name(const void* e1, const void* e2) {
return strcmp( ((struct Stu*)e1)->name, ((struct Stu*)e2)->name );
}
void struct_sort()
{
// 使用qsort排序结构体数据
struct Stu s[] = {"Ashe", 39, "Hanzo", 38, "Ana", 60};
int sz = sizeof(s) / sizeof(s[0]);
// 按照年龄排序
bubble_sort_q(s, sz, sizeof(s[0]), cmp_struct_age);
// 按照名字排序
bubble_sort_q(s, sz, sizeof(s[0]), cmp_struct_name);
}
void print_arr(int arr[], int sz)
{
int i = 0;
for(i=0; i 0 1 2 3 4 5 6 7 8 9
第十一章 - string.h和stype.h常用函数介绍
前言:
在C语言中对字符和字符串的处理是很常见的,但是C语言本身是并没有字符串类型的,字符串通常放在 常量字符串 中或 字符数组 中。字符串常量 适用于那些对它不做修改的字符串函数。
一、求字符串长度
0x00 strlen 函数
头文件: string.h

链接:strlen - C++ Reference
说明:字符串以 \0 作为结束标志,strlen 返回的是在字符串中 \0 前面出现的字符个数
注意事项:
① 参数指向的字符串必须以 \0 结束
② 函数的返回值为 size_t ,无符号(unsigned)
代码演示:
#include
#include
int main()
{
int len = strlen("abcdef");
printf("%d\n", len);
return 0;
} 6
二、长度不受限制的字符串函数
0x00 strcpy 函数
头文件: string.h

链接:strcpy - C++ Reference
说明:字符串拷贝,将含有 \0 的字符串复制到另一个地址空间,返回值的类型为 char*
注意事项:
① 源字符串 src 必须以 \0 结束
② 会将源字符串 src 中的 \0 一同拷贝到目标空间 dest
③ 目标空间必须足够大,以确保能够存放源字符串 dest (下面讲 strncmp 的时候演示)
④ 目标空间必须可变,即目标空间 dest 不可以被 const 声明
代码演示:
#include
#include
int main()
{
char arr1[] = "abcdefghi";
char arr2[] = "123";
printf("拷贝前:%s\n", arr1);
strcpy(arr1, arr2); // 字符串拷贝(目标空间,源字符串)
printf("拷贝后:%s\n", arr1);
return 0;
} 运行结果如下:
0x02 strcat 函数
头文件: string.h

链接: http://www.cplusplus.com/reference/cstring/strcat/
说明:将 src 所指向的字符串复制到 dest 所指向的字符串后面(删除 *dest 原来末尾的 \0 )
注意事项:
① 源字符串 src 必须以 \0 结束
② 会将源字符串 src 中的 \0 一同拷贝到目标空间 dest ,并删除 *dest 原来末尾的 \0
③ 目标空间必须足够大,以确保能够存放源字符串 dest
④ 目标空间必须可变,即目标空间 dest 不可以被 const 声明
代码演示:
#include
#include
int main()
{
char arr1[30] = "hello";
char arr2[] = "world";
strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
} hello world
0x03 strcmp 函数
头文件: string.h

链接: http://www.cplusplus.com/reference/cstring/strcmp/
说明:用于比较两个字符串并根据比较结果返回整数, 两个字符串自左向右逐个字符相比,按照 ASCII值 大小相比较,从第一对字符开始比,如果相等则比下一对,直到出现不同的字符或遇 \0 才停止。对比规则如下:

代码演示:
#include
#include
int main()
{
char *p1 = "abcdef";
char *p2 = "aqwer";
int ret = strcmp(p1, p2); // p1和p2比
// a==a, 对比下一对,b -1( 返回负数,所以 p1< p2 )
解析:

注意事项:根据编译器的不同,返回的结果也不同
在 VS2013 中,大于返回 1,等于返回 0,小于返回 -1。但在 Linux-gcc 中,大于返回正数,等于返回0,小于返回负数。因此,我们需要注意判断部分的写法:
// 不推荐 ❌
if(strcmp(p1, p2) == 1) {
printf("p1 > p2");
} else if(strcmp(p1, p2 == 0)) {
printf("p1 == p2");
} else if(strcmp(p1, p2) == -1) {
printf("p1 < p2");
}
// 推荐 ✅
if(strcmp(p1, p2) > 0) {
printf("p1 > p2");
} else if(strcmp(p1, p2 == 0)) {
printf("p1 == p2");
} else if(strcmp(p1, p2) < -1) {
printf("p1 < p2");
}三、长度受限制的函数字符串
0x00 strncpy 函数
头文件: string.h

链接: http://www.cplusplus.com/reference/cstring/strncpy/
说明:从源字符串中拷贝 n 个字符到目标空间
注意事项:
① 如果源字符串的长度小于 n,则拷贝完源字符串之后,在目标的后面追加 0,填充至 n 个
② dest 和 src 不应该重叠(重叠时可以用更安全的 memmove 替代)
③ 目标空间必须足够大,以确保能够存放源字符串 dest
④ 目标空间必须可变,即目标空间 dest 不可以被 const 声明
代码演示:
#include
#include
int main()
{
char arr1[5] = "abc";
char arr2[] = "hello world";
strncpy(arr1, arr2, 4); // 从arr2中拷贝4个到arr1
printf("%s\n", arr1);
return 0;
} hell
❌ 目标空间不够大会导致报错:
#include
#include
int main()
{
char arr1[5] = "abc"; // 大小为5的数组
char arr2[] = "hello world";
strncpy(arr1, arr2, 6); // 要求拷贝6个字节
printf("%s\n", arr1);
return 0;
} 运行结果如下:

0x01 strncat 函数
头文件: string.h

链接: strncat - C++ Reference
说明:追加 n 个字符到目标空间
注意事项:如果源字符串的长度小于 n,则只复制 \0 之前的内容。
代码演示:
#include
#include
int main()
{
char arr1[30] = "hello";
char arr2[] = "world";
strncat(arr1, arr2, 3); // 从arr2中取3个追加到arr1中
printf("%s\n", arr1);
return 0;
} hellowor
0x02 strncmp 函数

链接: strncmp - C++ Reference
说明:比较到出现另个字符不一样或者一个字符串结束或者 n 个字符全部比较完。
( 除了增了了个 n,其他和 strcmp 一样 )
代码演示:
#include
#include
int main()
{
const char* p1 = "abczdef";
const char* p2 = "abcqwer";
// int ret = strcmp(p1, p2);
int ret = strncmp(p1, p2, 1);
int ret2 = strncmp(p1, p2, 4);
printf("%d %d\n", ret, ret1);
return 0;
} 0 1
四、字符串查找
0x00 strstr 函数
头文件: string.h

链接: strstr - C++ Reference
说明:返回字符串中首次出现子串的地址。若 str2 是 str1 的子串,则返回 str2 在 str1 中首次出现的地址。如果 str2 不是 str1 的子串,则返回 NULL 。
代码演示:是子串,返回首次出现的地址
#include
#include
int main()
{
char* p1 = "abcdef";
char* p2 = "def";
char* ret = strstr(p1, p2); // 判断p2是否是p1的子串
printf("%s\n", ret);
return 0;
} def ( p2 是 p1 的子串,所以返回 def )
代码演示:不是子串,返回 NULL
#include
#include
int main()
{
char* p1 = "abcdef";
char* p2 = "zzz";
char* ret = strstr(p1, p2);
printf("%s\n", ret);
return 0;
} (null)
我们用 if 判断来添加描述,更好地呈现:
#include
#include
int main()
{
char* p1 = "abcdef";
char* p2 = "def";
char* ret = strstr(p1, p2);
if ( ret == NULL ) {
printf("子串不存在\n");
} else {
printf("%s\n", ret);
}
return 0;
} 0x01 strtok 函数
头文件: string.h
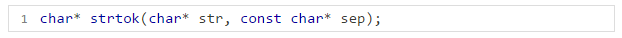
链接: strtok - C++ Reference
说明:

注意事项:strtok 会破坏原字符串,分割后原字符串保留第一个分割符前的字符
代码演示:分割ip
#include
#include
int main()
{
//192.168.0.1
//192 168 0 1 - strtok
char ip[] = "192.168.0.1";
// const char* sep = ".";
// char* ret = strtok(ip, sep);
char* ret = strtok(ip, ".");
printf("%s\n", ret);
ret = strtok(NULL, ".");
printf("%s\n", ret);
ret = strtok(NULL, ".");
printf("%s\n", ret);
ret = strtok(NULL, ".");
printf("%s\n", ret);
return 0;
}
运行结果如下:
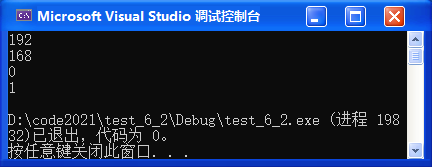
代码演示:分割邮箱
#include
#include
int main()
{
//[email protected]
//1300300100 qq com
char arr[] = "[email protected]";
printf("原字符串: %s\n", arr);
const char* sep = "@."; // 创建sep
char arr1[30];
char* ret = NULL;
strcpy(arr1, arr); // 将数据拷贝一份,保留arr数组的内容
// 分行打印切割内容
for (ret = strtok(arr, sep); ret != NULL; ret = strtok(NULL, sep)) {
printf("%s\n", ret);
}
printf("保留的原内容:%s\n", arr1); // 保存的arr数组的内容
printf("分割后原字符串被破坏: %s\n", arr); // 分割后原字符串保留第一个分割符前的字符
return 0;
}
运行结果如下:
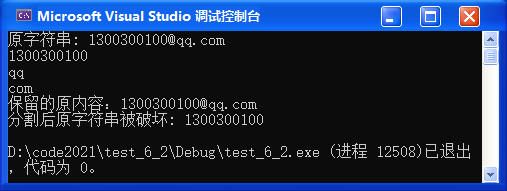
0x02 strerror 函数
头文件: string.h
链接: strerror - C++ Reference
说明:返回错误码,返回错误码所对应的错误信息
代码演示:
#include
#include
#include
int main()
{
// 错误码 错误信息
// 0 - No error
// 1 - Operation not permitted
// 2 - No such file or directory
// ...
//errno 是一个全局的错误码变量
//当c语言的库函数在执行过程中,发生了错误,
//就会把对应的错误码赋值到errno中
char* str = strerror(errno);
printf("%s\n", str);
return 0;
} No error
关于 errno:查看 errno 的详细介绍 [百度百科]
errno 是记录系统的最后一次错误代码。代码是一个 int 型的值,在 errno.h 中定义
文件操作的时候可以使用(后面会讲文件操作)
FILE* pf = fopen("test.txt", "r");
if ( pf == NULL ) {
printf("%s\n", strerror(errno));
} else {
printf("*****open file success*****\n")
}五、字符操作
0x00 字符分类
头文件: stype.h

代码演示:islower
#include
#include
int main()
{
char ch1 = 'a';
int ret = islower(ch1); // 判断ch1是否为小写
printf("%d\n", ret);
char ch2 = 'B';
int res = islower(ch2); // 判断ch2是否为小写
printf("%d\n", res);
return 0;
} 运行结果如下:

0x01 字符转换
需引入头文件 stype.h

代码演示:tolower
int main()
{
char ch = tolower('Q'); // 大写转小写
putchar(ch);
return 0;
}q
代码演示:toupper
int main()
{
char ch = toupper('q'); // 小写转大写
putchar(ch);
return 0;
}Q
代码演示:字符串内容全部大写转小写( 利用 while 循环 )
#include
#include
int main()
{
char arr[] = "I Am A Student";
int i = 0;
while(arr[i]) {
if ( isupper(arr[i]) ) {
arr[i] = tolower(arr[i]);
}
i++;
}
printf("%s\n", arr);
return 0;
} i am a student
模拟实现 Python 中的 swapcase 函数 ( 字符串大小写互换 )
#include
#include
#include
void swapcase(char arr[])
{
assert(arr != NULL); // 断言防止传空
int i = 0;
while (arr[i] != '\0') {
if (islower(arr[i])) { //是小写吗?
arr[i] = toupper(arr[i]); //如果是,让它变成大写
} else { //不是小写
arr[i] = tolower(arr[i]); //把它变成小写
}
i++;
}
}
int main()
{
char arr[] = "AaBbCcDdEeFf";
swapcase(arr);
printf("%s\n", arr);
return 0;
} aAbBcCdDeEfF
六、字符操作函数
0x00 memcpy 函数
头文件: string.h

链接: memcpy - C++ Reference
说明:从源内存地址 src 的起始位置开始拷贝 n 个字节到目标内存地址 dest 中
注意事项:
① memcpy 没有刹车,这个函数遇到 \0 并不会停下来
② 如果 src 和 dest 有任何的重叠,复制的结果都是未定义的
代码演示:
#include
#include
int main()
{
int arr1[] = {1, 2, 3, 4, 5};
int arr2[5] = {0};
memcpy(arr2, arr1, sizeof(arr1));
// 打印 arr2 的内容
int i = 0;
for(i=0; i<5; i++) {
printf("%d ", arr2[i]);
}
return 0;
} 1 2 3 4 5
代码演示:拷贝结构体
#include
#include
struct S
{
char name[20];
int age;
};
int main()
{
struct S arr3[] = { {"张三", 20}, {"李四", 30} };
struct S arr4[3] = { 0 };
memcpy(arr4, arr3, sizeof(arr3));
return 0;
} 调试一下看看是否拷贝成功:

0x02 memmove 函数
头文件: string.h

链接: memcpy - C++ Reference
说明:用于拷贝字节,如果目标区域和源区域有重叠时,memmove 能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中,但复制后源内容会被更改。
注意事项:
① 和 memcpy 的差别就是 memmove 函数处理的源内存块和目标内存块时可以重叠的
② 如果原空间和目标空间出现重叠,应使用 memmove 函数处理
C语言标准要求:
memcpy 用来处理不重叠的内存拷贝,而 memmove 用来处理重叠内存的拷贝。
代码演示:
#include
#include
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
memmove(arr+2, arr, 20);
for(i=0; i<10; i++) {
printf("%d ", arr[i]);
}
return 0;
} 运行结果如下:

0x03 memcmp 函数
头文件: string.h

链接: memcmp - C++ Reference
说明:比较 ptr1 和 ptr2 指针开始的 n 个字节,按字节比较

注意事项:memcmp 不同于 strcmp,memcmp 遇到 \0 不会停止比较
代码演示:
#include
#include
int main()
{
float arr1[] = {1.0, 2.0, 3.0, 4.0};
float arr2[] = {1.0, 3.0};
int ret = memcmp(arr1, arr2, 8); // arr1是否比arr2大,比较8个字节
printf("%d\n", ret);
return 0;
} -1 ( 说明 arr1 小于 arr2 )
0x04 memset 函数
头文件: string.h

链接: http://www.cplusplus.com/reference/cstring/memset/
说明:将某一块内存中的内容全部设置为指定的值,通常为新申请内存做初始化工作。
注意事项:memset 是以字节为单位设置内存的
代码演示:把整型数组将前 20 个字节全部设置为 1
#include
#include
int main()
{
// 40
int arr[10] = {0};
memset(arr, 1, 20); // 将前20个字节全部设置为1
return 0;
} 
第十二章 - C语言自定义类型讲解(联合体、枚举、联合体)
前言:
本章将对C语言自定义类型进行讲解,前期我们讲过结构体,这章将会把前面结构体还没讲完的知识继续补充。
一、结构体(struct)

结构体我们在第七章已经讲过了,在本章里我们将先简略的复习,再做一些补充。
0x00 结构的基础知识
结构体是一些值的集合,这些值称为成员变量。结构的每个成员以是不同类型的变量。
0x01 结构的声明
代码演示:描述一个学生
struct Stu
{
char name[20]; // 名字
int age; // 年龄
char sex[5]; // 性别
char id[20]; // 学号
}; // 分号不能丢 0x02 匿名结构体

定义:在声明结构的时候,可以不完全声明。匿名结构体在声明时省略掉结构体标签(tag),因为没有结构体标签导致无法构成类型,所以匿名结构体自然只能用一次。
代码演示:匿名结构体
struct
{
int a;
char b;
float c;
double d;
} s;
struct
{
int a;
char b;
float c;
double d;
} *ps;注意事项:
对于上面的代码如果进行如下操作,是非法的
int main()
{
ps = &s; // error
return 0;
}❌ 此时编译器会报出如下警告:
 在编译器看来,虽然成员是一模一样的,但是编译器仍然认为它们是两个完全不同的类型。 因为不相同,所以 *ps 不能存变量 s 的地址。
在编译器看来,虽然成员是一模一样的,但是编译器仍然认为它们是两个完全不同的类型。 因为不相同,所以 *ps 不能存变量 s 的地址。
0x03 结构的自引用
介绍:结构体中包含一个类型为该结构体本身的成员,包含同类型的结构体指针(不是包含同类型的结构体变量)
代码演示:结构体自引用
struct A
{
int i;
char c;
};
struct B
{
char c;
struct A sa;
double d;
};注意事项1:结构体不能自己包含自己,不能包含同类型的结构体变量

❌ 错误演示:
struct N
{
int d;
struct N n; // ❌ 结构体里不能存在结构体自己类型的成员
};为了加深理解,我们先引入一下数据结构的一些知识:

注意事项2:结构体自引用时,不要用匿名结构体:
❌ 错误演示:
struct // 如果省略结构体名字
{
int data;
struct Node* next; // 这里的 struct Node* 是哪里来的?
};即使使用 typedef 重新取名为 Node,也是不行的。因为你要产生 Node 必须先有结构体类型之后才能重命名 Node,即先 Node* next 定义完成员之后才 typedef 才能对这个类型重命名为 Node。所以这种方式仍然是不行的:
typedef struct
{
int data;
Node* next; // 先有鸡还是先有蛋???
} Node;解决方案:
typedef struct Node
{
int data;
struct Node* next;
} Node;0x04 结构体变量的定义和初始化
声明类型的同时直接创建变量:
struct S
{
char c;
int i;
} s1, s2; // 声明类型的同时创建变量
int main()
{
struct S s3, s4;
return 0;
}创建变量的同时赋值(初始化)
struct S
{
char c;
int i;
} s1, s2;
int main()
{
struct S s3 = {'x', 20};
// c i
return 0;
}结构体包含结构体的初始化方法:
struct S
{
char c;
int i;
} s1, s2;
struct B
{
double d;
struct S s;
char c;
};
int main()
{
struct B sb = {3.14, {'w', 100}, 'q'};
printf("%lf %c %d %c\n", sb.d, sb.s.c, sb.s.i, sb.c);
return 0;
}3.140000 w 100 q
0x05 结构体内存对齐
本段我们将讨论结构体占多大的内存空间,学习如何计算结构体的大小
我们先来观察下面的代码:
#include
struct S
{
char c1; // 1
int i; // 4
char c2; // 1
};
int main()
{
struct S s = { 0 };
printf("%d\n", sizeof(s));
return 0;
} 12
❓ 为什么是12呢?这就涉及到结构体内存对齐的问题了。
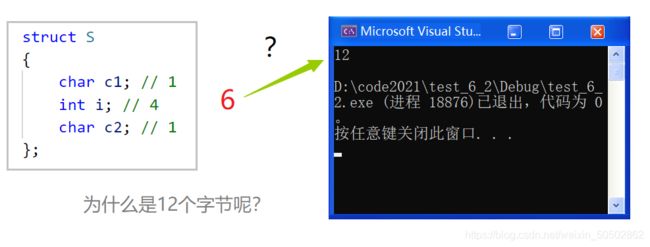
结构体的对齐规则:
① 结构体的第一个成员放在结构体变量在内存中存储位置的0偏移处开始。
② 从第2个成员往后的所有成员,都要放在一个对齐数(成员的大小和默认对齐数的较小值)的整数的整数倍的地址处。VS中默认对齐数为8!
③ 结构体的总大小是结构体的所有成员的对齐数中最大的那个对齐数的整数倍。
④ 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
注意事项:VS中默认对其数为8,Linux中没有默认对齐数概念!
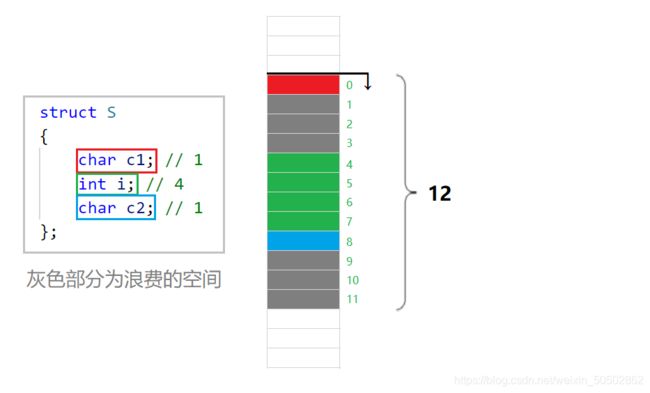
练习1:
#include
struct S2
{
char c;
int i;
double d;
};
int main()
{
struct S2 s2 = {0};
printf("%d\n", sizeof(s2));
return 0;
} 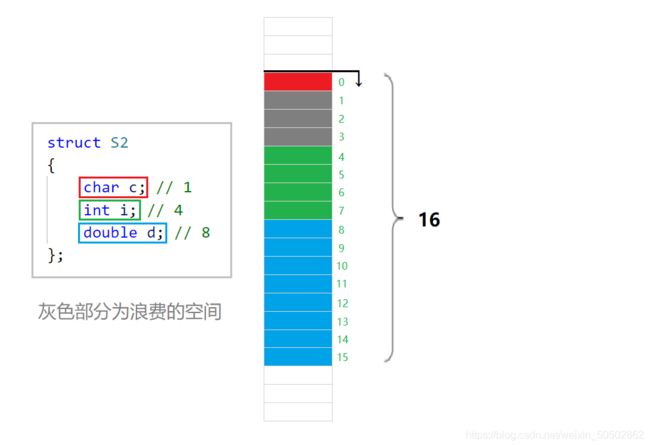
练习2:
#include
struct S3
{
char c1;
char c2;
int i;
};
int main()
{
struct S3 s3 = { 0 };
printf("%d\n", sizeof(s3));
return 0;
} 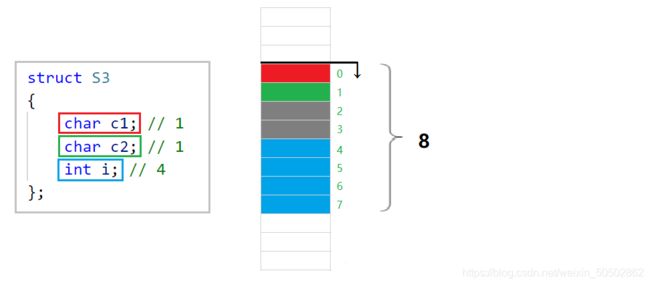
练习3:
#include
struct S4
{
double d;
char c;
int i;
};
int main()
{
struct S4 s4 = { 0 };
printf("%d\n", sizeof(s4));
return 0;
} 
结构体嵌套问题:
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
#include
struct S4
{
double d;
char c;
int i;
};
struct S5
{
char c1;
struct S4 s4;
double d;
};
int main()
{
struct S5 s5 = {0};
printf("%d\n", sizeof(s5));
return 0;
} 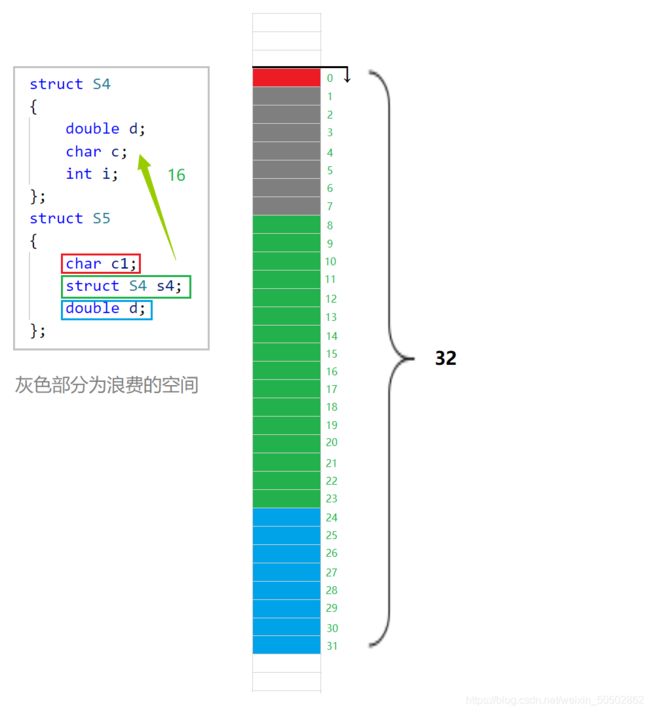
❓ 为什么会存在内存对齐?
1. 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特 定类型的数据,否则抛出硬件异常。
2. 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
结构体的内存对齐是拿空间来换取时间的做法。
⚡ 在设计结构体时,如何做到既满足对齐又能节省空间呢?
让空间小的成员尽量集中在一起。
虽然S1和S2类型的成员一模一样,但是通过让空间小的成员尽量计中在一起,使所占空间的大小有了一些区别。
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
char c1;
char c2;
int i;
};0x06 修改默认对齐数
预处理指令 #pragma 可以改变我们的默认对齐数,#pragma pack(2)
#include
// 默认对齐数是8
#pragma pack(2) // 把默认对齐数改为2
struct S
{
char c1; //1
int i; // 4
char c2; // 1
};
#pragma pack() // 取消
int main()
{
printf("%d\n", sizeof(struct S)); //12
return 0;
} 
结论:结构体在对齐方式不合适的时候,我们可以通过使用 #pragma 自行修改默认对齐数
0x07 offsetof
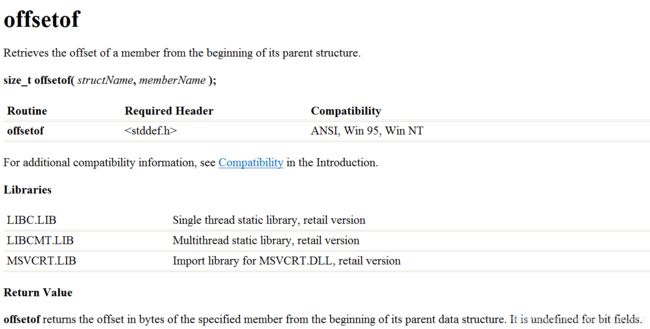
作用:该宏用于求结构体中一个成员在该结构体中的偏移量。
头文件: stddef.h
使用方法演示:
#include
#include
struct S
{
char c1; //1
int i; // 4
char c2; // 1
};
int main()
{
printf("%d\n", offsetof(struct S, c1));
printf("%d\n", offsetof(struct S, i));
printf("%d\n", offsetof(struct S, c2));
return 0;
} 0 4 8
百度笔试题:写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明。
0x08 结构体传参
观察下列代码:
#include
struct S
{
int data[1000];
int num;
};
struct S s = {{1, 2, 3, 4}, 1000};
//结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}
❓ print1(传结构体) 和 print2 (传地址)函数哪个更好?
答案:首选 print2 (传地址)函数
解析:函数传参的时候是需要压栈的,会产生时间和空间上的系统开销。如果传递一个结构体对象时,结构体过大,参数压栈的系统开销就会很大,从而导致性能的下降。
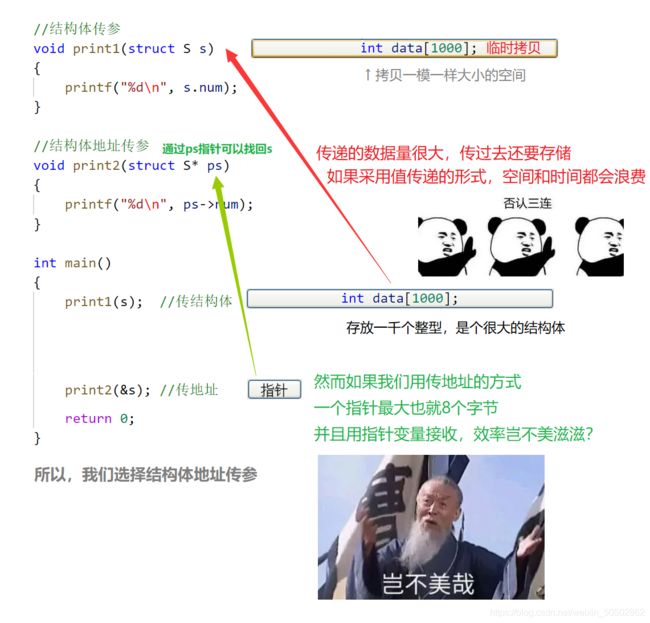
结论:结构体传参得时候,要传结构体的地址。
二、位段(bit field)
0x00 何为位段
定义:位段,C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”( bit field) 。利用位段能够用较少的位数存储数据。
位段的声明和结构体是类似的,但有两个不同点:
① 位段的成员只能是: int、unsigned int、signed int
② 位段的成员名后面有一个冒号和一个数字:member_name : number
代码演示:
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
}
// A就是一个位段类型❓ 那么问题来了,位段A的大小是多少?
#include
struct A
{
int _a:2; // _a 成员占2个比特位
int _b:5; // _b 成员占5个比特位
int _c:10; // _c 成员占10个比特位
int _d:30; // _d 成员占30个比特位
};
int main()
{
printf("%d\n", sizeof(struct A));
return 0;
} 8
运行结果居然是8,四个成员占47个比特位,而8个字节是64个比特位,为什么会这样呢?
0x01 位段的内存分配
位段的意义:位段在一定程度上帮助我们节省空间。
注意事项:
① 位段的成员可以是 int、unsigned int、signed int 或者是 char (属于整形家族)类型。
② 位段的空间上是 按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
③ 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
❓ 空间是如何开辟的?
struct S
{
char a : 3;
char b : 4;
char c : 5;
char d : 4;
};
int main()
{
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
}
0x02 位段的跨平台问题
1. int 位段被当成有符号数还是无符号数是不确定的。
2. 位段中最大位的数目不能确定。比如16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,但位段可以更好地节省空间,缺陷是存在跨平台问题。
三、枚举(enumerate)
0x00 何为枚举
在数学和计算机科学理论中,一个集的枚举是列出某些有穷序列集的所有成员的程序,或者是一种特定类型对象的计数。这两种类型经常(但不总是)重叠。
是一个被命名的整型常数的集合,枚举在日常生活中很常见,例如表示星期的SUNDAY、MONDAY、TUESDAY、WEDNESDAY、THURSDAY、FRIDAY、SATURDAY就是一个枚举。 [ 百度百科 ]
枚举,顾名思义就是壹壹列举,把可能的取值壹壹列举。
eg. 性别有男、女和保密,我们就可以列举他们,或者一年有12个月,可以把每个月都壹壹列举。

0x01 枚举的定义

代码演示:
enum Day //星期
{
// 枚举常量
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Sex //性别
{
// 枚举常量
MALE,
FEMALE,
SECRET
};
enum Color //颜色
{
// 枚举常量
RED,
GREEN,
BLUE
};
上述代码定义的 enum Day,enum Sex,enum Color 都是枚举类型。{ } 中的内容是枚举类型的可能取值,即枚举常量。这些可能取值都是有值的,默认从0开始,依次递增1。当然,可以在定义的时候也可以对其赋予初值,例如:
enum Color //颜色
{
// 枚举常量
RED = 1, // 赋初值
GREEN = 2,
BLUE = 4
};
0x02 枚举的优点
❓ 我们可以用 #define 定义常量,为什么非要使用枚举?
枚举的优点:
① 增加代码的可读性和可维护性。
② 与 #define 定义的标识符相比,枚举有类型检查,更加严谨。
③ 有效防止命名污染(封装)。
④ 便于调试。
⑤ 使用方便,一次可以定义多个常量。
0x03 枚举的使用
代码演示:
#include
enum Color //颜色
{
RED = 1,
GREEN = 2,
BLUE = 4
};
int main()
{
enum Color c = GREEN;
c = 5;
printf("%d\n", c);
return 0;
} 注意事项:
① 默认从0开始,依次递增1。(可赋初值,上面赋值如果下面不赋,随上一个赋的值 +1 )
② 枚举常量是不能改变的。 (MALE = 3 error!)
#include
enum Sex
{
// 枚举常量
MALE = 3, // 赋初值为3
FEMALE, // 不赋初值,默认随上一个枚举常量,+1为4
SECRET // +1为5
};
int main(void)
{
enum Sex s = MALE;
printf("%d\n", MALE);
// MALE = 3 error ❌ 不可修改
printf("%d\n", FEMALE);
printf("%d\n", SECRET);
return 0;
}
3 4 5
③ 枚举常量虽然是不能改变的,但是通过枚举常量创造出来的变量是可以改变的!
enum Color
{
// 枚举常量
RED,
YEELOW,
BULE
};
int main(void)
{
enum Color c = BULE; // 我们创建一个变量c,并将BULE赋给它
c = YEELOW; // 这时将YEELOW赋给它,完全没有问题 ✅
BULE = 6; // error!枚举常量是不能改变的 ❌
return 0;
}0x04 实际运用演示
之前我们在实现计算器的时候是这么写代码的:(仅演示部分代码)
#include
void menu()
{
printf("*****************************\n");
printf("** 1. add 2. sub **\n");
printf("** 3. mul 4. div **\n");
printf("** 0. exit **\n");
printf("*****************************\n");
}
int main()
{
int input = 0;
do {
menu();
printf("请选择:> ");
scanf("%d", &input);
switch {
case 1:
break;
case 2:
break;
case 3:
break;
case 4:
break;
case 0:
break;
default:
break;
} while (input);
return 0;
} ❓ 思考:阅读代码的时候如果不看上面的 menu,是很难知道 case 中的 12340 分别是什么的。1 为什么是加?2 为什么是减?看到数字的时候联想不到它的到底是干什么的。
⚡ 为了提高代码的可读性,我们可以使用枚举来解决:
#include
void menu() {...}
enum Option
{
EXIT, // 0
ADD, // 1
SUB, // 2
MUL, // 3
DIV, // 4
};
int main()
{
int input = 0;
do {
menu();
printf("请选择:> ");
scanf("%d", &input);
switch {
case ADD: // 替换后就好多了,代码的可读性大大增加
break;
case SUB:
break;
case MUL:
break;
case DIV:
break;
case EXIT:
break;
default:
break;
} while (input);
return 0;
}
四、联合体(union)
0x00 何为联合体
定义:联合体又称共用体,是一种特殊的自定义类型。可以在相同的内存位置存储不同的数据类型。可以定义一个带有多成员的联合体,但是任何时候只能有一个成员带有值。

0x01 联合体的定义
代码演示:
#include
union Un
{
char c; // 1
int i; // 4
};
int main()
{
union Un u; // 创建一个联合体变量
printf("%d\n", sizeof(u)); // 计算联合体变量的大小
return 0;
} 4
❓ 为什么是4个字节呢?我们来试着观察下它的内存:
#include
union Un
{
char c; // 1
int i; // 4
};
int main()
{
union Un u;
printf("%p\n", &u);
printf("%p\n", &(u.c));
printf("%p\n", &(u.i));
return 0;
}
运行结果如下:

结论:联合体的成员是共用同一块内存空间的。因为联合至少要有保存最大的那个成员的能力,所以一个联合变量的大小至少是最大成员的大小。
0x02 联合体的初始化
代码演示:
#include
union Un
{
char c; // 1
int i; // 4
};
int main()
{
union Un u = {10};
return 0;
}
调试:打开监视后,我们可以看到 i 和 c 是是共用一个10的:
❓ 如果想在每个成员里放上独立的值呢?
#include
union Un
{
char c; // 1
int i; // 4
};
int main()
{
union Un u = {10};
u.i = 1000;
u.c = 100;
return 0;
} 观察调试过程:
结论:在同一时间内你只可以使用联合体中的一个成员。
0x03 联合体大小的计算
看代码:
#include
union Un
{
char a[5]; // 5
int i; // 4
};
int main()
{
union Un u;
printf("%d\n", sizeof(u));
return 0;
} 8
❓ 为什么又是8个字节了?
其实联合体也是存在对齐的,我们来更加系统地、详细的探究下联合体的大小规则:
联合体大小的计算:
① 联合的大小至少是最大成员的大小。
② 当最大成员的大小不是最大对齐数的整数倍时,对要对齐到最大对齐数的整数倍。
union Un
{
char a[5]; // 对齐数是1
int i; // 对齐数是4
};
// 所以最后取了8个字节为该联合体的大小0x04 实际运用演示
通过联合体判断当前机器大小端
复习链接: 【维生素C语言】第九章 - 数据的存储 (四、大小端)
实现思路:
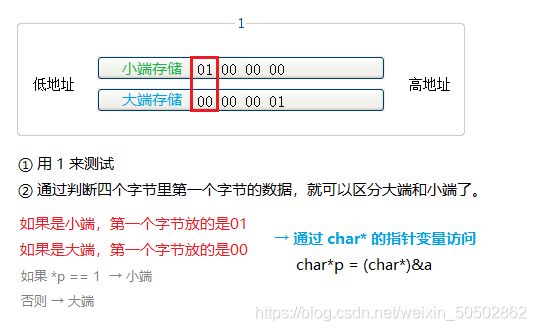
之前学的方法:
#include
int main()
{
int a = 1;
if ( ( *(char*)&a ) == 1 )
printf("小端\n");
else
printf("大端\n");
return 0;
} ⚡ 将其封装成函数:
#include
int check_sys()
{
int a = 1;
return *(char*)&a;
}
int main()
{
int ret = check_sys();
if(ret == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
通过联合体的方式判断: (通过深刻理解联合体特点写出来的代码)
#include
int check_sys()
{
union U {
char c;
int i;
} u;
u.i = 1;
return u.c;
// 返回1 就是小端
// 返回0 就是大端
}
int main()
{
int ret = check_sys();
if(ret == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
} 
第十三章 - 动态内存管理
前言:
本章将讲解C语言动态内存管理,由浅到深的讲解动态内存管理。学习完本章后可以做一下动态内存分配的练习加深巩固,降低踩动态内存分配坑的概率:
传送门:动态内存分配笔试题题目+答案+详解)
一、动态内存分配
0x00 引入
目前我们已经掌握了以下两种开辟内存的方式:
// 在栈上开辟4个字节
int val = 20;
// 在栈空间上开辟10个字节的连续空间
char arr[10] = {0};上述开辟空间的方式有两个特点:
① 空间开辟的大小是固定的。
② 数组在声明时必须指定数组的长度,在编译时会开辟并分配其所需要的内存空间。
0x01 定义
[百度百科] 动态分配内存
所谓动态内存分配(Dynamic Memory Allocation) 就是指在程序执行的过程中动态地分配或者回收存储空间的分配内存的方法。动态内存分配不象数组等静态内存分配方法那样需要预先分配存储空间,而是由系统根据程序的需要即时分配,且分配的大小就是程序要求的大小。
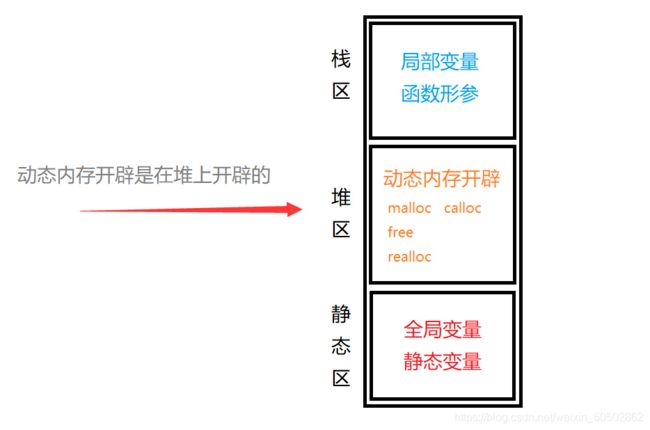
0x02 存在的原因
❓ 为什么会存在动态内存开辟?
有时我们需要的空间大小在程序运行的时候才能知道,这时在数组编译时开辟空间的方式就不能满足了,这时我们就需要动态内存开辟来解决问题。
二、动态内存函数介绍
0x00 malloc 函数

头文件:stdlib.h
介绍:malloc 是C语言提供的一个动态内存开辟的函数,该函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。具体情况如下:
① 如果开辟成功,则返回一个指向开辟好空间的指针。
② 如果开辟失败,则返回一个 NULL 指针。
③ 返回值的类型为 void* ,malloc 函数并不知道开辟空间的类型,由使用者自己决定。
④ 如果 size 为 0(开辟0个字节),malloc 的行为是标准未定义的,结果将取决于编译器。
官方介绍:malloc - C++ Reference

0x01 free 函数

头文件:stdlib.h
介绍:free 函数用来释放动态开辟的内存空间。具体情况如下:
① 如果参数 ptr 指向的空间不是动态开辟的,那么 free 函数的行为是未定义的。
② 如果参数 ptr 是 NULL 指针,那么 free 将不会执行任何动作。
注意事项:
① 使用完之后一定要记得使用 free 函数释放所开辟的内存空间。
② 使用指针指向动态开辟的内存,使用完并 free 之后一定要记得将其置为空指针。
官方介绍:http://www.cplusplus.com/reference/cstdlib/malloc/?kw=free

代码演示:动态内存开辟10个整型空间(完整步骤)
#include
#include
int main(void)
{
// 假设开辟10个整型空间
int arr[10]; // 在栈区上开辟
// 动态内存开辟
int* p = (int*)malloc(10*sizeof(int)); // 开辟10个大小为int的空间
// 使用这些空间的时候
if (p == NULL) {
perror("main"); // main: 错误信息
return 0;
}
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = i;
}
for (i = 0; i < 10; i++) {
printf("%d ", p[i]);
}
// 回收空间
free(p);
p = NULL; // 需要手动置为空指针
return 0;
} 0 1 2 3 4 5 6 7 8 9

❗ 动态内存开辟失败的情况:(perror 函数)
#include
#include
int main(void)
{
...
int* p = (int*)malloc(9999999999*sizeof(int)); // 狮子大开口。拿来吧你
...
} main: Not enough space
❓ 为什么 free 之后,一定要把 p 置为空指针?
解析:因为 free 之后那块开辟的内存空间已经不在了,它的功能只是把开辟的空间回收掉,但是 p 仍然还指向那块内存空间的起始位置,这合理吗?这不合理。所以我们需要使用 p = NULL 把他置成空指针。为了加深印象,举一个形象的例子:

❓ 为什么 malloc 前面要进行强制类型转换呢?
int* p = (int*)malloc(10*sizeof(int));解析:为了和 int* p 类型相呼应,所以要进行强制类型转换。你可以试着把强转删掉,其实也不会有什么问题。但是因为有些编译器要求强转,所以最好进行一下强转,避免不必要的麻烦。
0x02 calloc 函数

头文件:stdlib.h
介绍:calloc 函数的功能实为 num 个大小为 size 的元素开辟一块空间,并把空间的每个字节初始化为 0 ,返回一个指向它的指针。
⭕ 对比:
① malloc 只有一个参数,而 calloc 有两个参数,分别为元素的个数和元素的大小。
② 与函数 malloc 的区别在于 calloc 会在返回地址前把申请的空间的每个字节初始化为 0 。
官方介绍:http://www.cplusplus.com/reference/cstdlib/malloc/?kw=calloc

验证: calloc 会对内存进行初始化
#include
#include
int main()
{
// malloc
int* p = (int*)malloc(40); // 开辟40个空间
if (p == NULL)
return 1;
int i = 0;
for (i = 0; i < 10; i++)
printf("%d ", *(p + i));
free(p);
p = NULL;
return 0;
} (运行结果是10个随机值)
#include
#include
int main()
{
// calloc
int* p = (int*)calloc(10, sizeof(int)); // 开辟10个大小为int的空间,40
if (p == NULL)
return 1;
int i = 0;
for (i = 0; i < 10; i++)
printf("%d ", *(p + i));
free(p);
p = NULL;
return 0;
} 0 0 0 0 0 0 0 0 0 0
总结:说明 calloc 会对内存进行初始化,把空间的每个字节初始化为 0 。如果我们对于申请的内存空间的内容,要求其初始化,我们就可以使用 calloc 函数来轻松实现。
0x03 realloc 函数

头文件:stdlib.h
介绍:realloc 函数,让动态内存管理更加灵活。用于重新调整之前调用 malloc 或 calloc 所分配的 ptr 所指向的内存块的大小,可以对动态开辟的内存进行大小的调整。具体介绍如下:
① ptr 为指针要调整的内存地址。
② size 为调整之后的新大小。
③ 返回值为调整之后的内存起始位置,请求失败则返回空指针。
④ realloc 函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到新的空间。
realloc 函数在调整内存空间时存在的三种情况:
情况1:原有空间之后有足够大的空间。
情况2:原有空间之后没有足够大的空间。
情况3:realloc 有可能找不到合适的空间来调整大小。

情况1:当原有空间之后没有足够大的空间时,直接在原有内存之后直接追加空间,原来空间的数组不发生变化。
情况2:当原有空间之后没有足够大的空间时,会在堆空间上另找一个合适大小的连续的空间来使用。函数的返回值将是一个新的内存地址。
情况3:如果找不到合适的空间,就会返回一个空指针。
官方介绍:http://www.cplusplus.com/reference/cstdlib/malloc/?kw=realloc

代码演示:realloc 调整内存大小
#include
#include
int main()
{
int* p = (int*)calloc(10, sizeof(int));
if (p == NULL) {
perror("main");
return 1;
}
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = 5;
}
// 此时,这里需要p指向的空间更大,需要20个int的空间
// realloc 调整空间
p = (int*)realloc(p, 20*sizeof(int)); // 调整为20个int的大小的空间
// 释放
free(p);
p = NULL;
}
❗ 刚才提到的第三种情况,如果 realloc 找不到合适的空间,就会返回空指针。我们想让它增容,他却存在返回空指针的危险,这怎么行?
解决方案:不要拿指针直接接收 realloc,可以使用临时指针判断一下。
#include
#include
int main()
{
int* p = (int*)calloc(10, sizeof(int));
if (p == NULL) {
perror("main");
return 1;
}
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = 5;
}
// 此时,这里需要 p 指向的空间更大,需要 20 个int的空间
// realloc 调整空间
int* ptmp = (int*)realloc(p, 20*sizeof(int));
// 如果ptmp不等于空指针,再把p交付给它
if (ptmp != NULL) {
p = ptmp;
}
// 释放
free(p);
p = NULL;
} 
有趣的是,其实你可以把 realloc 当 malloc 用:
// 在要调整的内存地址部分,传入NULL:
int* p = (int*)realloc(NULL, 40); // 这里功能类似于malloc,就是直接在堆区开辟40个字节三、常见的动态内存错误
0x00 对空指针的解引用操作
❌ 代码演示:
#include
#include
int main()
{
int* p = (int*)malloc(9999999999);
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = i; // 对空指针进行解引用操作,非法访问内存
}
return 0;
} 解决方案:对 malloc 函数的返回值做判空处理
#include
#include
int main()
{
int* p = (int*)malloc(9999999999);
// 对malloc函数的返回值做判空处理
if (p == NULL) {
perror("main")
return 1;
}
int i = 0;
for (i = 0; i < 10; i++) {
*(p + i) = i; // 对空指针进行解引用操作,非法访问内存
}
return 0;
} 0x01 对动态开辟空间的越界访问
❌ 代码演示:
#include
#include
int main()
{
int* p = (int*)malloc(10*sizeof(int)); // 申请10个整型的空间
if (p == NULL) {
perror("main");
return 1;
}
int i = 0;
// 越界访问 - 指针p只管理10个整型的空间,根本无法访问40个
for (i = 0; i < 40; i++) {
*(p + i) = i;
}
free(p);
p = NULL;
return 0;
}
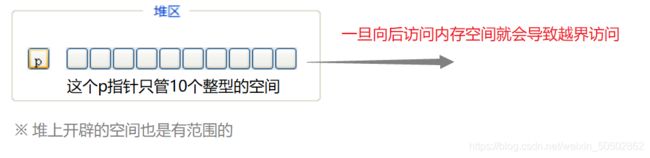
提醒:为了防止越界访问,使用空间时一定要注意开辟的空间大小。
0x02 对非动态开辟的内存使用free释放
❌ 代码演示:
#include
#include
int main()
{
int arr[10] = {0}; // 在栈区上开辟
int* p = arr;
// 使用 略
free(p); // 使用free释放非动态开辟的空间
p = NULL;
return 0;
} 
提醒:不要对非动态开辟的内存使用 free,否则会出现难以意料的错误。
0x03 使用 free 释放一块动态开辟内存的一部分
❌ 代码演示:
#include
#include
int main()
{
int* p = malloc(10*sizeof(int));
if (p == NULL) {
return 1;
}
int i = 0;
for (i = 0; i < 5; i++) {
*p++ = i; // p指向的空间被改变了
}
free(p);
p = NULL;
return 0;
} 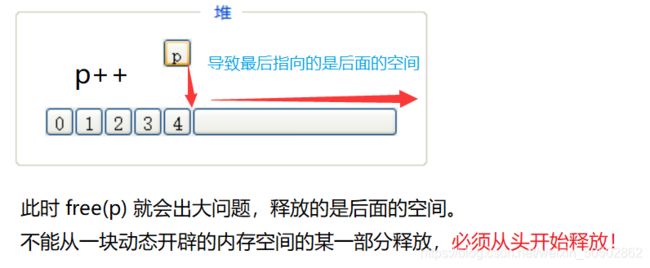
注意事项:这么写代码会导致 p 只释放了后面的空间。没人记得这块空间的起始位置,再也没有人找得到它了,这是很件很可怕的事情,会存在内存泄露的风险。
提醒:释放内存空间的时候一定要从头开始释放。
0x04 对同一块动态内存多次释放
❌ 代码演示:
#include
#include
int main()
{
int* p = malloc(10*sizeof(int));
if (p == NULL) {
return 1;
}
int i = 0;
for (i = 0; i < 10; i++) {
p[i] = i;
}
// 释放
free(p);
// 一时脑热,再一次释放
free(p);
return 0;
}
解决方案:在第一次释放后紧接着将 p 置为空指针
// 释放
free(p);
p = NULL;
free(p); // 此时p为空,free什么也不做0x05 动态开辟内存忘记释放导致内存泄漏
❌ 代码演示:
#include
#include
void test()
{
int* p = (int*)malloc(100);
if (p == NULL) {
return;
}
// 使用 略
// 此时忘记释放了
}
int main()
{
test();
free(p); // 此时释放不了了,没人知道这块空间的起始位置在哪了
p = NULL;
} 动态开辟的内存空间有两种回收方式: 1. 主动释放(free) 2. 程序结束
如果这块程序在服务器上 7x24 小时运行,如果你不主动释放或者你找不到这块空间了,最后就会导致内存泄漏问题。内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
提醒:malloc 这一系列函数 和 free 一定要成对使用,记得及时释放。你自己申请的空间,用完之后不打算给别人用,就自己释放掉即可。如果你申请的空间,想传给别人使用,传给别人时一定要提醒别人用完之后记得释放。
第十四章 - 浅析C/C++程序的内存开辟
前言:
本篇博客旨在加深动态内存开辟的理解,以 C/C++ 程序的内存开辟为主题进行简要的分析。
C/C++ 程序内存分配的区域:
1.栈区(stack)
执行函数时,函数内部局部变量的存储单元都可以在栈上创建。函数执行结束后这些存储单元会被自动释放。栈内存分配运算内置于处理器的指令集中,拥有很高的效率,但是分配的内存容量是有限的。栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。
2.堆区(heap)
一般由程序员自主分配释放,若程序员不主动不释放,程序结束时可能由操作系统回收。其分配方式类似于链表。
3.数据段(data segment)
静态存储区,存放全局变量和静态数据,程序结束后由系统释放。
4.代码段(code segment)
存放函数体(类成员函数和全局函数)的二进制代码。
内存区域划分图:

我们在前几章讲过 static 关键字修饰局部变量,有了这幅图,我们可以更好地理解了:
实际上,普通的局部变量是在栈区分配空间的,在栈区上创建的变量,出了作用域就会销毁。但是,如果一个变量被 static 修饰,就会存放到数据段(静态区),而在数据段上创建的变量,直到程序结束才会销毁,所以生命周期因此而变长。
栈区的特点:在上面创建的变量出了作用域就销毁。
数据段的特点:在上面创建的变量直到程序结束才销毁
第十五章 - 柔性数组(可变长数组)
前言:
本篇将对C99标准中引入的新特性——柔性数组,进行讲解。并探讨柔性数组的优势,简单的介绍内存池的相关概念,来体会柔性数组的优点。
一、柔性数组介绍
定义:柔性数组(Flexible Array),又称可变长数组。一般数组的长度是在编译时确定,而柔性数组对象的长度在运行时确定。在定义结构体时允许你创建一个空数组(例如:arr [ 0 ] ),该数组的大小可在程序运行过程中按照你的需求变动。
出处:柔性数组(Flexible Array),是在C语言的 C99 标准中,引入的新特性。结构中的最后一个元素的大小允许是未知的数组,即为柔性数组。
【百度百科】在 ANSI 的标准确立后,C语言的规范在一段时间内没有大的变动,然而C++在自己的标准化创建过程中继续发展壮大。《标准修正案一》在1994年为C语言创建了一个新标准,但是只修正了一些C89标准中的细节和增加更多更广的国际字符集支持。不过,这个标准引出了1999年ISO 9899:1999的发表。被称为C99,C99被ANSI于2000年3月采用。
演示:
struct S {
int n;
int arr[]; // 柔性数组成员
};❗ 部分编译器可能会报错,可以试着将 a [ 0 ] 改为 a [ ] :
struct S {
int n;
int arr[]; // 柔性数组成员
};二、柔性数组的特点
结构中的柔性数组成员的前面必须至少有一个其他成员:
typedef struct st_type {
int i; // 必须至少有一个其他成员
int a[0]; // 柔性数组成员
} type_a;sizeof 计算这种结构的大小是不包含柔性数组成员的:
#include
struct S {
int n; // 4
int arr[]; // 大小是未知的
};
int main() {
struct S s = {0};
printf("%d\n", sizeof(s));
return 0;
} 4
包含柔性数组成员的结构,用 malloc 函数进行内存分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小:
#include
#include
struct S {
int n;
int arr[0];
};
int main() {
// 期望arr的大小是10个整型
// 给n的 给arr[]的
//
struct S* ps = (struct S*)malloc(sizeof(struct S) + sizeof(int));
// 后面+的大小就是给柔性数组准备的
return 0;
} 分析:
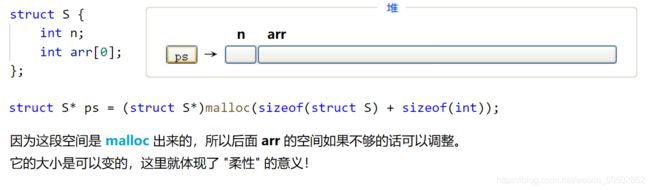
三、柔性数组的使用
代码演示:
#include
#include
struct S {
int n;
int arr[0];
};
int main() {
// 期望arr的大小是10个整型
struct S* ps = (struct S*)malloc(sizeof(struct S) + sizeof(int));
ps->n = 10;
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
ps->arr[i];
}
// 增容
struct S* ptr = (struct S*)realloc(ps, sizeof(struct S) + 20*sizeof(int));
if (ptr != NULL) {
ps = ptr;
}
// 再次使用 (略)
// 释放
free(ps);
ps = NULL;
return 0;
} 查看地址:
四、柔性数组的优势
代码1:使用柔性数组
/* 代码1 */
#include
#include
struct S {
int n;
int arr[0];
};
int main() {
// 期望arr的大小是10个整型
struct S* ps = (struct S*)malloc(sizeof(struct S) + sizeof(int));
ps->n = 10;
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
ps->arr[i];
}
// 增容
struct S* ptr = (struct S*)realloc(ps, sizeof(struct S) + 20*sizeof(int));
if (ptr != NULL) {
ps = ptr;
}
// 再次使用 (略)
// 释放
free(ps);
ps = NULL;
return 0;
} 代码2:直接使用指针
想让n拥有自己的空间,其实不使用柔性数组也可以实现。
/* 代码2 */
#include
#include
struct S {
int n;
int* arr;
};
int main() {
struct S* ps = (struct S*)malloc(sizeof(struct S));
if (ps == NULL)
return 1;
ps->n = 10;
ps->arr = (int*)malloc(10 * sizeof(int));
if (ps->arr == NULL)
return 1;
// 使用
int i = 0;
for (i = 0; i < 10; i++) {
ps->arr[i];
}
// 增容
int* ptr = (struct S*)realloc(ps->arr, 20 * sizeof(int));
if (ptr != NULL) {
ps->arr = ptr;
}
// 再次使用 (略)
// 释放
free(ps->arr); // 先free第二块空间
ps->arr = NULL;
free(ps);
ps = NULL;
return 0;
}
❓ 上面的 代码1 和 代码2 可以完成同样的同能,哪个更好呢?
显而易见, 代码1 更好:
① 第一个好处:有利于内存释放
虽然 代码2 实现了相应的功能,但是和 代码1 比还是有很多不足之处的。代码2 使用指针完成,进行了两次 malloc ,而两次 malloc 对应了两次 free ,相比于 代码1 更容易出错如果我们的代码是在一个给别人用的函数中,你在里面做了两次内存分配,并把整个结构体返回给用户。虽然用户调用 free 可以释放结构体,但是用户并不知道这个结构体内的成员也需要 free,所以你不能指望用户来发现这件事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好(而不是多次分配),并且返回给用户一个结构体指针,用户只需使用一次 free 就可以把所有的内存都给释放掉,可以间接地减少内存泄露的可能性。
② 第二个好处:有利于访问速度
连续内存多多少少有益于提高访问速度,还能减少内存碎片。malloc 的次数越多,产生的内存碎片就越多,这些内存碎片不大不小,再次被利用的可能性很低。内存碎片越多,内存的利用率就会降低。频繁的开辟空间效率会变低,碎片也会增加。

总结:因此,使用柔性数组,多多少少是有好处的。
第十六章 - 文件操作(上)
前言:
本章为文件操作教学上篇,由浅入深的引入问题,然后逐一介绍知识。将详细讲解文件的打开和关闭、文件的顺序读写并精讲函数部分,初步学习“流”的概念!
传送门:文件操作(下)
一、问题引入
0x00 什么是文件?

【百度百科】电脑文件,也可以称之为计算机文件,是存储在某种长期储存设备或临时存储设备中的一段数据流,并且归属于计算机文件系统管理之下。所谓“长期储存设备”一般指磁盘、光盘、磁带等。而“短期存储设备”一般指计算机内存。需要注意的是,存储于长期存储设备的文件不一定是长期存储的,有些也可能是程序或系统运行中产生的临时数据,并于程序或系统退出后删除。
简单来讲,就是磁盘上的文件。
0x01 为什么使用文件?

举个例子,我们想实现一个 “通讯录” 程序时,在通讯录中新建联系人、删除联系人等一系列操作,此时的数据存储于内存中,程序退出后所有数据都会随之消失,为了让通讯录中的信息得以保存,也就是想让数据持久化,我们就需要采用让数据持久化的方法。我们一般数据持久化的方法有:把数据存放在磁盘文件中,或存放到数据库等方式。
0x02 什么是程序文件和数据文件?
但在程序设计中,我们一般所说的文件为 程序文件 和 数据文件 。
程序文件:程序文件包括源程序文件(后缀为.c),目标文件(Windows环境下后缀为.obj),可执行程序(Windows环境下后缀为.exe)。
数据文件:数据文件的内容不一定是程序,而是程序在运行时读写的数据,比如程序运行需要从中读取数据的文件,或输出内容的文件。
我们随便写一段代码,用于演示:
#include
int main(void) {
printf("Hello,World!\n");
return 0;
} 随后运行代码(便于生成文件):
❓ 那么,什么是程序文件呢?
找到代码路径,打开文件夹查看 “可执行程序” :

退回到上层目录,找 “目标文件”:

❓ 那数据文件又是什么呢?
在代码路径下创建一个文件:
0x03 什么是文件名?
【百度百科】文件名是文件存在的标识,操作系统根据文件名来对其进行控制和管理。不同的操作系统对文件命名的规则略有不同,即文件名的格式和长度因系统而异。为了方便人们区分计算机中的不同文件,而给每个文件设定一个指定的名称。由文件主名和扩展名组成。
存在的意义:一个文件要有一个惟一的文件标识,方便用户识别和引用。
❗ 文件名包含三个部分:文件路径 + 文件名主干 + 文件后缀
( 例如:C:\code2021\TestDemo.txt )
为了方便起见,文件标识通常被称为 文件名 。
本章我们将对 数据文件 进行探讨!
二、文件的打开和关闭
文件读写之前应该先打开文件,在使用结束后应该关闭文件。
在编写程序的时候,再打开文件的同时,都会返回一个 FILE* 指针变量指向该文件,也相当于建立了指针和文件的关系。
ANSIC 规定使用 fopen 函数来打开文件, fclose 函数来关闭文件。
0x00 文件指针
❓ 什么是文件指针:
【百度百科】在C语言中用一个指针变量指向一个文件,这个指针称为文件指针。通过文件指针就可对它所指的文件进行各种操作。
在缓冲文件系统中,有一个关键的概念是 "文件类型指针" ,简称 "文件指针" 。
每个被使用的文件,都会在内存中开辟出一个相应的文件信息区。该信息区用来存放文件相关信息(如文件名、文件状态以及文件当前位置等)。这些信息是保存在一个结构体变量中的,该结构体类型是由系统申明的,名为 FILE (注意是类型)。

例如由 VS2013 编译环境提供的 stdio.h 头文件中有以下的文件类型声明:
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;注意事项:
① FILE 的结构在不同的C编辑器中包含的内容并不是不完全相同的,但还是颇为相似的。
② 每当打开一个文件时,系统会根据文件的状况自动创建一个 FILE 结构的变量,并填充其中的信 息,只要文件被读写发生变化,文件信息区也会跟着发生变化。至于文件变化时文件信息区是怎么变化和修改的,我们其实并不需要关心这些细节,因为C语言已经帮你弄好了。
③ 我们一般会通过一个 FILE 的指针来维护这个 FILE 结构的变量。并不会直接使用,而是拿一个结构体指针指向这个结构,通过这个指针来访问和维护相关的数据,这样使用起来会更加方便。
下面我们来创建一个 FILE* 的指针变量:
定义 pf 是一个指向 FILE 类型的指针变量。可以使 pf 指向某个文件的文件信息区(是一个结构体变量)。通过该文件信息区的信息就能够访问该文件。
FILE* pf; // 文件指针变量也就是说,通过文件指针变量能够找到与他关联的文件。
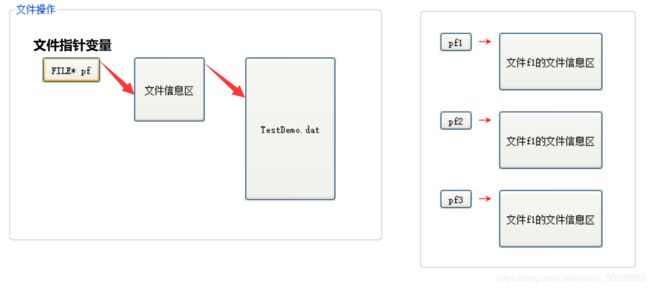
0x01 fopen 函数与 fclose 函数
头文件:stdlib.h
ANSIC 规定使用 fopen 函数来打开文件, fclose 函数来关闭文件。
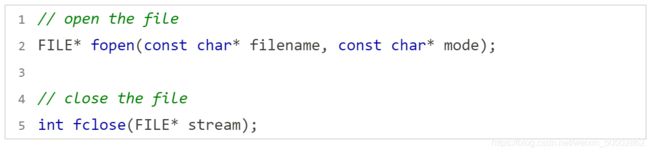
✅ filename 参数指的是文件名,mode 参数为打开方式,打开方式如下:
| 文件使用方式 |
含义 |
如指定文件不存在 |
|---|---|---|
| " r "(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| " w "(只写) | 为了输出数据,打开一个文本文件 | 建立一个新文件 |
| " a "(追加) | 像文本文件尾添加数据 | 建立一个新文件 |
| " rb "(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| " wb "(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新文件 |
| " ab "(追加) | 象一个二进制文件尾添加数据 | 出错 |
| " r+ "(读写) | 为了读和写,打开一个文本文件 | 出错 |
| " w+ "(读写) | 为了读和写,建立一个新的文件 | 建立一个新的文件 |
| " a+ "(读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| " rb+ "(读写) | 为了读和写,打开一个二进制文件 | 出错 |
| " wb+ "(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| " ab+ "(读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
代码演示:打开我们刚刚手动创建的 test.dat 文件
#include
int main(void) {
FILE* pf = fopen("test.dat", "w");
// 检查是否为空指针
if (pf == NULL) {
perror("fopen");
return 1;
}
/* 写文件 */
// 关闭文件
fclose(pf);
pf = NULL; // 记得将pf置为空指针
return 0;
} (代码正常运行)
❓ 之前我们创建的 test.dat 的路径是在  路径下的,如果放在其他路径下可以读吗?
路径下的,如果放在其他路径下可以读吗?
可以,但文件必须在该工程的路径下才行。
我们把 test.dat 文件删除,然后打开方式改成 r 试试看:
#include
int main(void) {
FILE* pf = fopen("test.dat", "r");
// 检查是否为空指针
if (pf == NULL) {
perror("fopen");
return 1;
}
/* 写文件 */
// 关闭文件
fclose(pf);
pf = NULL; // 记得将pf置为空指针
return 0;
} 运行结果如下: (通过刚才的表格可知,如果 r 找不到指定的文件,会导致报错)
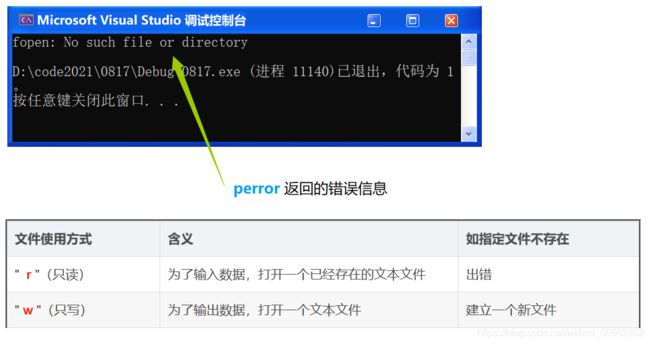
如果不适用相对路径,使用绝对路径读文件:
可以使用绝对路径,但是要注意转义绝对路径中的斜杠!
#include
int main(void) {
// FILE* pf = fopen("D:\code2021\0817\0817\test2.dat", "w"); // error
FILE* pf = fopen("D:\\code2021\\0817\\0817\\test2.dat", "w"); // 转移字符\
// 检查是否为空指针
if (pf == NULL) {
perror("fopen");
return 1;
}
/* 写文件 */
// 关闭文件
fclose(pf);
pf = NULL; // 记得将pf置为空指针
return 0;
} 注意事项: 不关闭文件的后果:一个程序能够打开的文件是有限的,文件属于一种资源。如果只打开不释放,文件就会被占用。可能会导致一些操作被缓冲在内存中,如果不能正常关闭,缓冲在内存中的数据就不能正常写入到文件中从而导致数据的丢失。
三、文件的顺序读写
0x00 什么是顺序读写
首先要了解什么是读写:我们写的程序是在内存中,而数据是要放到文件中的,文件又是在硬盘上的。当我们把文件里的数据读到内存中去时,这个动作我们称之为输入/读取。反过来,如果把程序中的东西放到硬盘上,这个动作我们称之为输出/写入。
顺序读写,顾名思义就是按照顺序在文件中读和写。

0x01 顺序读写函数一览表
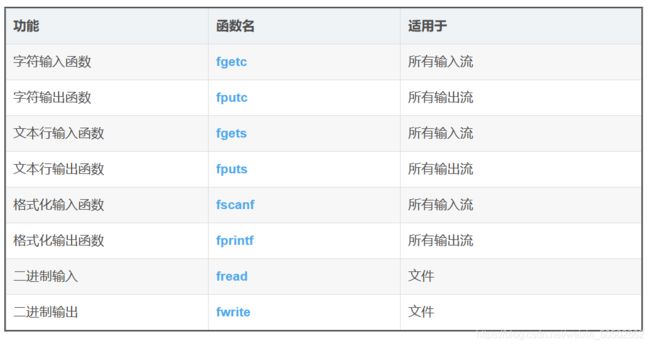
0x02 字符输出函数 fputc

介绍:将参数 char 指定的字符写入到指定的流 stream 中,并把位置标识符向前移动 (字符必须为一个无符号字符)。适用于所有输出流。
代码演示:创建一个 test.txt,随后使用 fputc 函数分别写入 "abc" 到文件中
#include
int main(void) {
FILE* pf = fopen("test.txt", "w");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} (代码正常运行)
此时打开工程文件夹可以成功看到 test.txt 被创建了(大小为1kb可以看出写入成功了):

我们正好测试下 w 的覆盖效果,我们把写的内容注释掉:
#include
int main(void) {
FILE* pf = fopen("test.txt", "w");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件
//fputc('a', pf);
//fputc('b', pf);
//fputc('c', pf);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 此时再次运行,我们发现那个文件里的内容不见了(大小也变为0kb):
❗ 值得注意的是,文件的写入是有顺序的。abc,先是a,然后是b,最后是c:
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
0x03 字符输入函数 fgetc

介绍:从指定的流 stream 获取下一个字符,并把位置标识符向前移动(字符必须为一个无符号字符)。如果读取成功会返回相应的ASCII码值,如果读取失败它会返回一个EOF。适用于所有输入流。
代码演示:在工程文件夹里打开 test.txt ,随便写入一些数据,随后使用 fgetc 函数读取:
#include
// 使用fgetc从文件里读
int main(void) {
FILE* pf = fopen("test.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读文件
int ret = fgetc(pf);
printf("%c\n", ret);
ret = fgetc(pf);
printf("%c\n", ret);
ret = fgetc(pf);
printf("%c\n", ret);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
}
运行结果如下:

❓ 如果读完了会发生什么?
我们来调试一下看看:
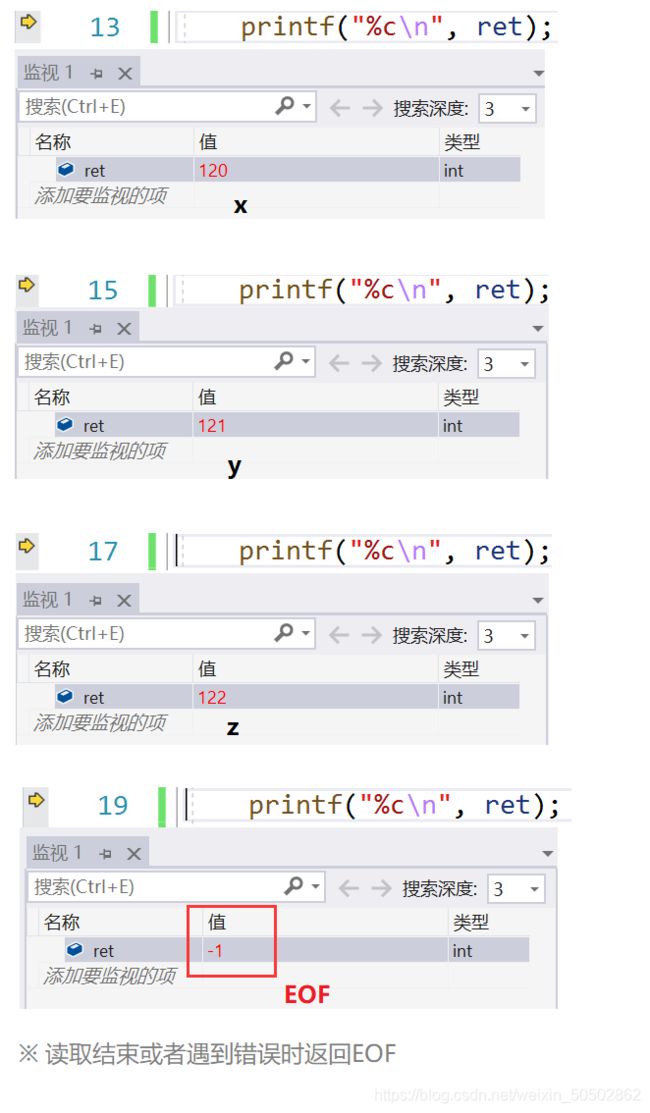
0x04 文本行输出函数 fputs

介绍:将字符串写入到指定的流 stream 中(不包括空字符)。适用于所有输出流。
代码演示:利用 fputs 在 test2.txt 中随便写入几行数据:
#include
int main(void) {
FILE* pf = fopen("test2.txt", "w");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件 - 按照行来写
fputs("abcdef", pf);
fputs("123456", pf);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} (代码成功运行)
❓ 如果想换行呢?
换行需要在代码里自行加 \n :
fputs("abcdef\n", pf);
fputs("123456", pf); (这时候打开文件,就是换行的了)
(这时候打开文件,就是换行的了)
0x05 文本行输入函数 fgets

介绍:从指定的流 stream 读取一行,并把它存储在 string 所指向的字符串中,当读取(n-1)个字符时,或者读取到换行符、到达文件末尾时,它会停止,具体视情况而定。适用于所有输入流。
注意事项:假如 n 是100,读取到的就是99个字符(n-1),因为要留一个字符给斜杠0。
代码演示:利用 fgets 读取 test2.txt 中的内容:
#include
int main(void) {
char arr[10] = "xxxxxx"; // 存放处
FILE* pf = fopen("test2.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读文件 - 按照行来读
fgets(arr, 4, pf);
printf("%s\n", arr);
fgets(arr, 4, pf);
printf("%s\n", arr);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 代码运行结果如下:
调试一下看看:

0x06 格式化输出函数 fprintf

介绍:fprintf 用于对格式化的数据进行写文件,发送格式化输出到流 stream 中。适用于所有输出流。
代码演示:将结构体的三个数据利用 fprintf 写到 test3.txt 中:
#include
struct Player {
char name[10];
int dpi;
float sens;
};
int main(void) {
struct Player p1 = { "carpe", 900, 3.12f };
// 对格式化的数据进行写文件
FILE* pf = fopen("test3.txt", "w");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件
fprintf(pf, "%s %d %f", p1.name, p1.dpi, p1.sens);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} (代码成功运行)
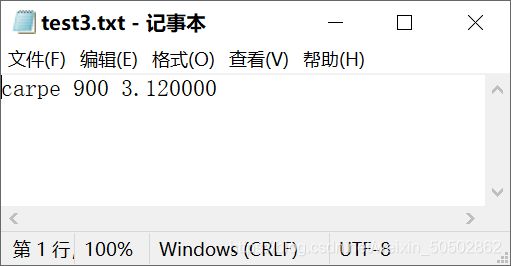
0x07 格式化输入函数 fscanf

介绍:fscanf 用于对格式化的数据进行读取,从流 stream 读取格式化输入。适用于所有输入流。
代码演示:利用 fscanf 读取 test4.txt 中的内容,并打印:
#include
struct Player {
char name[10];
int dpi;
float sens;
};
int main(void) {
struct Player p1 = { 0 }; // 存放处
// 对格式化的数据进行写文件
FILE* pf = fopen("test3.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读文件
fscanf(
pf, "%s %d %f",
p1.name, &(p1.dpi), &(p1.sens)
); // p1.name本身就是地址(不用&)
// 将读到的数据打印
printf("%s %d %f\n", p1.name, p1.dpi, p1.sens);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 运行结果如下:

0x08 二进制输出函数 fwrite

介绍:写一个数据到流中去,把 buffer 所指向的数组中的数据写入到给定流 stream 中。
创建一个 test5.txt,用 fwrite 写入一个数据到 text5.txt 中去:
#include
// 二进制的形式写
struct S {
char arr[10];
int num;
float score;
};
int main(void) {
struct S s = { "abcde", 10, 5.5f };
FILE* pf = fopen("test5.txt", "w");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件
fwrite(&s, sizeof(struct S), 1, pf);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} (代码成功运行)
我们发现他烫起来了2333(划掉)
打开文件后我们发现只有abcde看得懂,后面是什么我们看不懂。
我们试着用 nodepad++ 打开:

❓ 为什么还是乱码?为什么 abcde 不是乱码?
解答:
① 我们刚才用的都是文本编译器,文本编译器打开二进制形式的文件完全是两种状态。
② 因为字符串以文本形式写进去和以二进制形式写进去是一样的,但是对于整数、浮点数等来说就不一样了,文本形式写入和二进制形式写入完全是两个概念。
(那么该怎么读呢,我们来看下面的 fread 函数)
0x08 二进制输入函数 fread

介绍:从流中读取,从给定流 stream 读取数据到 buffer 所指向的数组中。
用 fread 读取 text5.txt 中的二进制数据:
#include
// 二进制的形式读
struct S {
char arr[10];
int num;
float score;
};
int main(void) {
struct S s = { 0 }; // 存放处
FILE* pf = fopen("test5.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读文件
fread(&s, sizeof(struct S), 1, pf);
// 将读到的数据打印
printf("%s %d %f", s.arr, s.num, s.score);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} (代码正常运行)

总结: fwrite 和 fread 是一对,fwrire 写进去用 fread 读。
0x09 流的概念(stream)
在这里,我们补充一下流的概念。
观察刚才的表格我们可以发现有的函数是适用于所有xx流的(比如 fputc 函数)。fputc 就适用于所有输出流,也就是说它不仅仅可以给文件里写。我们来读一下MSDN的介绍:
 我们发现它还可以写到 stdout 上。
我们发现它还可以写到 stdout 上。
❓ 那么 stdout 是什么呢?
stdout 就是标准输出流,在这里,我们要来讲一下流的概念。
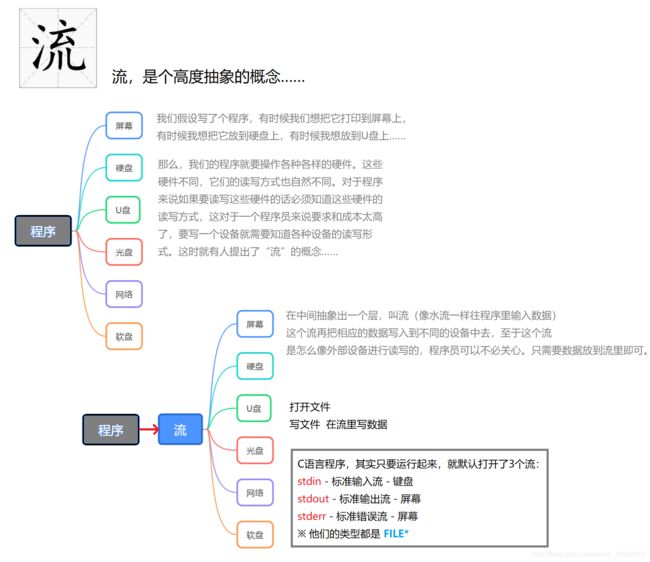
C语言默认打开的3个流:
① stdin - 标准输入流 - 键盘
② stdout - 标准输出流 - 屏幕
③ stderr - 标准输出流 - 屏幕
我们用流向屏幕上输出信息 - stdout:
#include
int main(void) {
fputc('a', stdout);
fputc('b', stdout);
fputc('c', stdout);
return 0;
} a b c
fgetc 从标准输入流读取 - stdin
#include
// 使用fgetc从标准输入流中读
int main(void) {
int ret = fgetc(stdin);
printf("%c\n", ret);
ret = fgetc(stdin);
printf("%c\n", ret);
ret = fgetc(stdin);
printf("%c\n", ret);
return 0;
} 运行:
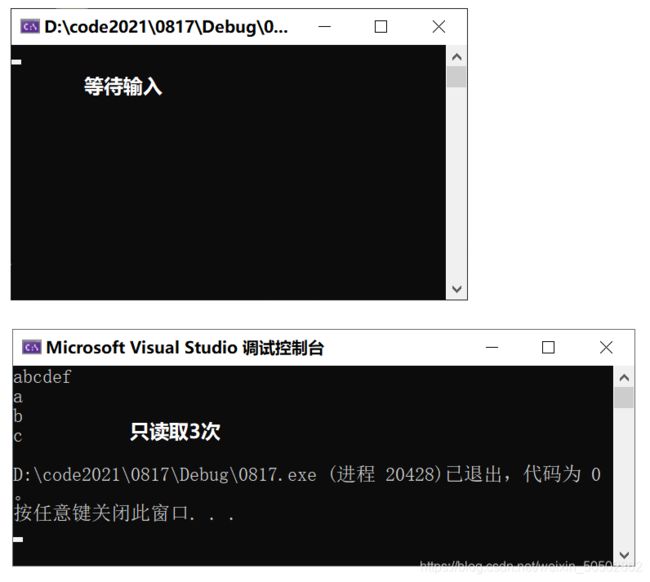
第十六章 - 文件操作(下)
前言:
在文件操作(上)中,我们讲了文件的打开和关闭和文件的顺序读写,还有对流(stream)进行一个简单的讲解。本章将对文件的随机读写、文本文件和二进制文件、文件读取结束的判定,以及文件缓冲区进行讲解。
传送门:文件操作(上)
一、文件的随机读写
0x00 文件指针定位函数 fseek

介绍:根据文件指针的位置和偏移量来定位指针。
1️⃣ 参数:offset 是偏移量。
2️⃣ 参数:origin 是起始位置,有三种选项:
① SEEK_CUR 当前文件指针的位置开始偏移。
② SEEK_END 文件的末尾位置开始偏移。
③ SEEK_SET 文件的起始位置开始偏移。
代码演示:手动创建一个文件,打开文件随便写点内容
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读取文件
int ch = fgetc(pf);
printf("%c\n", ch);
ch = fgetc(pf);
printf("%c\n", ch);
ch = fgetc(pf);
printf("%c\n", ch);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 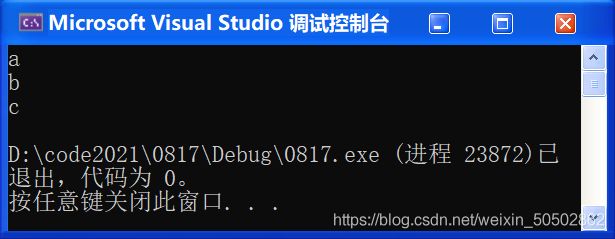
❓ 如果我想得到 a a b,该怎么做?
我们可以试着使用 fseek 函数:
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读取文件
int ch = fgetc(pf);
printf("%c\n", ch);
// 调整文件指针
fseek(pf, -1, SEEK_CUR); // SEEK_CUR为当前文件指针位置,偏移量为-1,向前移动1个单位
ch = fgetc(pf);
printf("%c\n", ch);
ch = fgetc(pf);
printf("%c\n", ch);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 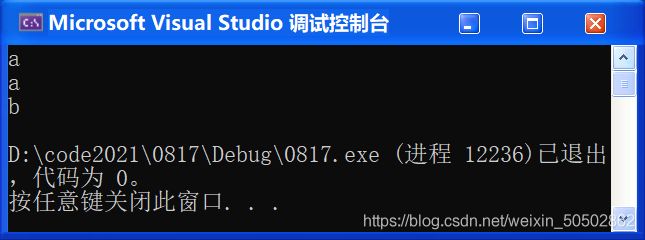
用 SEEK_SET ,打印 a d e:
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读取文件
int ch = fgetc(pf);
printf("%c\n", ch);
// 调整文件指针
fseek(pf, 3, SEEK_CUR); // SEEK_SET为文件的起始位置,偏移量为3,向后移动3个单位
ch = fgetc(pf);
printf("%c\n", ch);
ch = fgetc(pf);
printf("%c\n", ch);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 用 SEEK_END ,打印 a e f :
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 读取文件
int ch = fgetc(pf);
printf("%c\n", ch);
// 调整文件指针
fseek(pf, -2, SEEK_END); // SEEK_END为当前文件末尾位置,偏移量为-2,向前移动2个单位
ch = fgetc(pf);
printf("%c\n", ch);
ch = fgetc(pf);
printf("%c\n", ch);
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 0x01 返回偏移量函数 ftell

介绍:返回文件指针相对于起始位置的偏移量。
代码演示:ftell 的使用方法
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 调整文件指针
fseek(pf, 5, SEEK_CUR); // SEEK_CUR为当前文件指针位置,偏移量为5,向后移动5个单位
// 读取文件
int ch = fgetc(pf);
printf("%c\n", ch); // f
// 返回偏移量
int ret = ftell(pf);
printf("%d\n", ret); // 6
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 运行结果如下:

0x02 文件指针回到起始位置函数 rewind

介绍:rewind(意为倒带,磁带倒带),设置文件位置为给定流 stream 的文件的开头,让文件指针回到起始位置。

代码演示:利用 rewind 函数让文件指针回到起始位置
#include
int main(void) {
FILE* pf = fopen("test6.txt", "r");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 调整文件指针
fseek(pf, 5, SEEK_CUR); // SEEK_CUR为当前文件指针位置,偏移量为5,向后移动5个单位
// 返回偏移量
int loc = ftell(pf);
printf("fseek调整文件指针后:%d\n", loc); // 6
// 让文件指针回到起始位置
rewind(pf);
// 再次返回偏移量,看看是不是回到起始位置了
loc = ftell(pf);
printf("使用rewind后:%d\n", loc); // 6
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
} 运行结果如下:

二、文本文件和二进制文件
0x00 引入
再上一节中,我们已经对文本文件和二进制文件开了个头,在这里我们将进行详细的探讨!
根据数据的组织形式,数据文件被称为文本文件或者二进制文件。
0x01 文本文件
❓ 什么是文本文件?
如果要求在外存上以 ASCII 码的形式存储,则需要在存储之前进行转换。以 ASCII 字符的形式存储的文件,就是文本文件。
0x02 二进制文件
❓ 什么是二进制文件?
数据在内存中以二进制的形式存储,如果不加以转换地输出到外存,就是二进制文件。
0x03 数据在文件中的存储方式
❓ 一个数据在文件中是如何存储的呢?
存储方式如下:
① 字符一律以 ASCII 形式存储。
② 数值型数据既可以用 ASCII 形式存储,也可以使用二进制形式存储。
举个简单的例子:比如整数10000,如果以 ASCII 码的形式形式输出到磁盘,则磁盘中占用5个字节(每个字符占1个字节)。而如果以二进制的形式输出,则在磁盘上只占4个字节。
测试代码:
#include
int main(void) {
int a = 10000;
FILE* pf = fopen("test6.txt", "wb");
if (pf == NULL) {
perror("fopen");
return 1;
}
// 写文件
fwrite(&a, sizeof(int), 1, pf); // 二进制的形式写到文件中
// 关闭文件
fclose(pf);
pf = NULL;
return 0;
}
(代码成功运行)
我们来使用非常强大的【宇宙第一编辑器】Visual Studio(2013版本)来打开我们的二进制文件 test6.txt ,详细步骤如下:
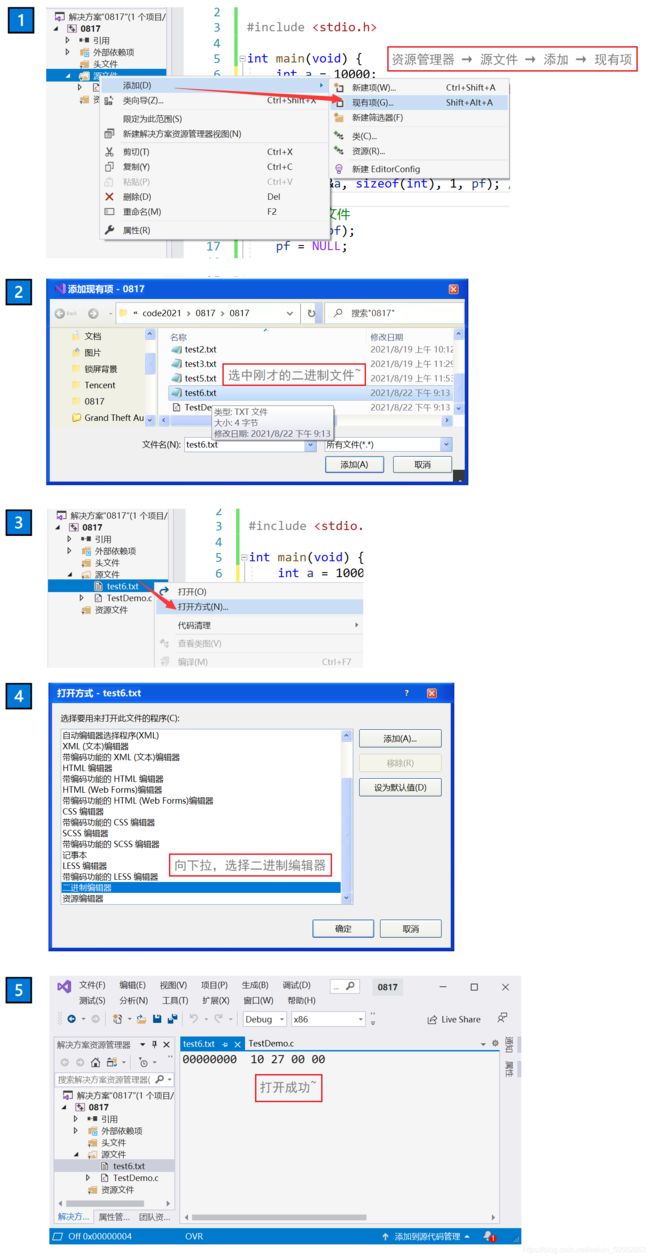
最后,我们来检测一下 10000 是不是 10 27 00 00 :
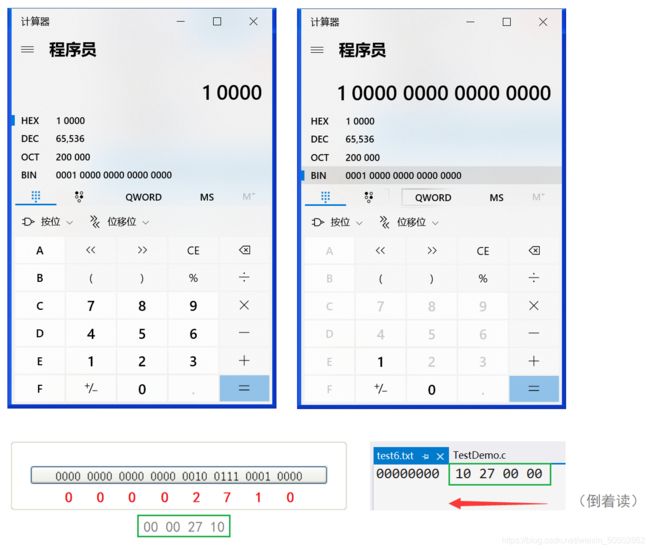
总结:文本文件和二进制文件的存储方式
① 文本文件:将内存里的数据转换成 ASCII 码值的形式存储到文件中。
② 二进制文件:将内存里的二进制数据不加任何转化直接存储到二进制文件中。

三、文件读取结束的判定
读文件读到什么时候才算结束,是个非常值得我们探讨的问题。
0x00 经常被错误使用的 " feof 函数 "

介绍:在文件结束时,判断文件因为何种原因导致文件结束的函数,判断是因为读取失败而结束,还是因为遇到文件尾而结束。如果文件结束,则返回非0值,否则返回0。
❌ 错误用途:feof 函数是个经常被错误使用的一个函数。在文件读取过程中,不能用 feof 函数的返回值直接判断文件是否结束!feof 函数绝对不是用来判断文件是否结束的函数!feof 不是用来判定文件是否结束了的,还是在文件已经结束时,判断是什么原因导致文件结束的。
✅ 正确用途:当文件读取结束时,判断是因为读取失败而结束,还是因为遇到文件尾而结束。
代码演示:feof 的用法:
#include
#include
int main(void) {
int ch = 0; // 注意:为int型而非char,要求处理EOF
FILE* pf = fopen("test.txt", "r");
if (!pf) { // pf == NULL
perror("fopen");
return EXIT_FAILURE; // 符号常量EXIT_FAILURE,表示没有成功地执行一个程序
}
// fgetc - 当读取失败的时候或者遇到文件结束的时候,都会返回EOF
while ( (ch = fgetc(pf)) != EOF ) {
putchar(ch);
} printf("\n");
// 判断文件结束的原因
if (ferror(pf)) { // ferror - 检查是否出现错误。
puts("读取失败错误(I/O error when reading)");
} else if (feof(pf)) {
puts("遇到文件尾而结束(End of file reached successfully) ");
}
// 文件关闭
fclose(pf);
pf = NULL;
} 运行结果如下:

0x01 正确判定文件是否读取结束的方法
文本文件读取是否结束,判断返回值是否为 EOF(fgetc),或者 NULL(fgets),例如:
① fgetc 函数在读取结束时会返回 EOF,正常读取时,返回读取到的字符的 ASCII 码值。
② fgets 函数在读取结束时会返回 NULL,正常读取时,返回存放字符串的空间的起始地址。
③ fread 函数在读取结束时会返回 实际读取到的完整元素的个数,如果发现读取到的完整的元素个数小于指定的元素个数,那么就是最后一次读取了。
代码演示:在工程路径下手动创建一个叫 file.txt 的文件,在里面随便写几行文字。然后通过代码将 file.txt 文件拷贝一份,生成 file2.txt :
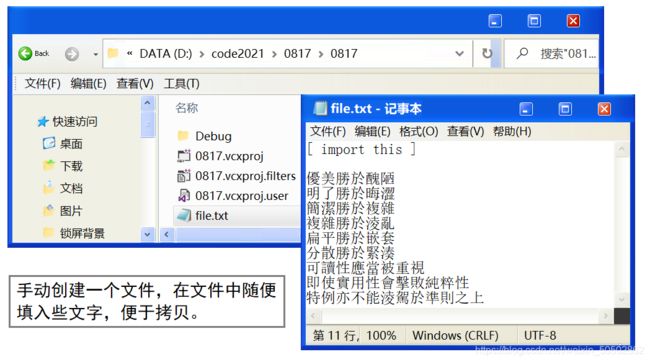
#include
int main(void) {
FILE* pfRead = fopen("file.txt", "r");
if (pfRead == NULL) {
return 1;
}
FILE* pfWrite = fopen("file2.txt", "w");
if (pfWrite == NULL) {
fclose(pfRead);
pfRead = NULL;
return 1;
}
// 文件打开成功,读写文件
int ch = 0;
// 读文件
ch = fgetc(pfRead);
while ( (ch = fgetc(pfRead)) != EOF ) {
// 写文件
fputc(ch, pfWrite);
}
// 关闭文件
fclose(pfRead);
pfRead = NULL;
fclose(pfWrite);
pfWrite = NULL;
return 0;
} (代码成功运行)
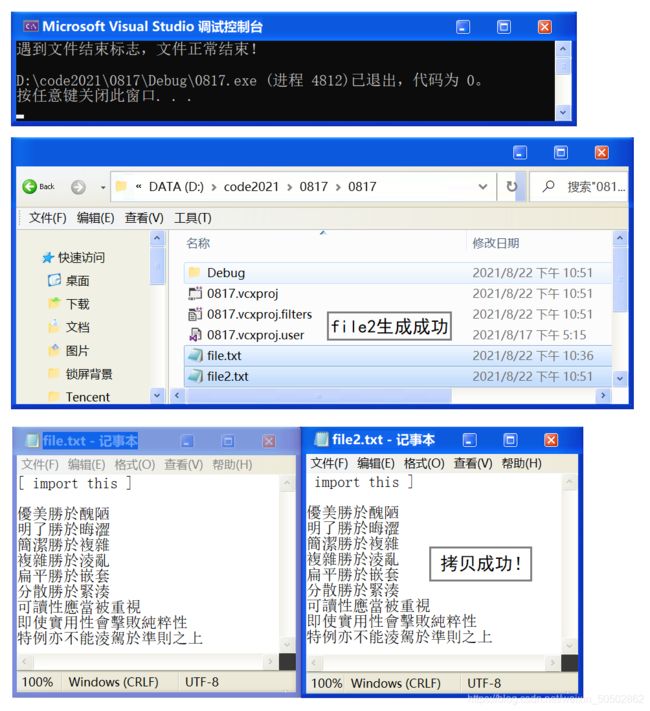
代码演示:二进制读取的例子
#inlucde
enum {
SIZE = 5
};
int main(void)
{
double a[SIZE] = {1.,2.,3.,4.,5.};
FILE *fp = fopen("test.bin", "wb"); // 必须用二进制模式
fwrite(a, sizeof *a, SIZE, fp); // 写double的数组
fclose(fp);
double b[SIZE];
fp = fopen("test.bin","rb");
size_t ret_code = fread(b, sizeof *b, SIZE, fp); // 读double的数组
if (ret_code == SIZE) {
puts("数组读取成功,数组内容如下:");
for(int n = 0; n < SIZE; ++n) printf("%f ", b[n]);
putchar('\n');
} else { // 异常处理
if (feof(fp)) {
printf("test.bin 读取错误!unexpected end of file\n");
} else if (ferror(fp)) {
perror("test.bin 读取错误!");
}
}
fclose(fp);
}
运行结果如下:
四、文件缓冲区(File Buffer)
0x00 什么是文件缓冲区
【百度百科】文件是指存储在外部存储介质上的、由文件名标识的一组相关信息的集合。由于CPU 与 I/O 设备间速度不匹配。为了缓和 CPU 与 I/O 设备之间速度不匹配矛盾。文件缓冲区是用以暂时存放读写期间的文件数据而在内存区预留的一定空间。使用文件缓冲区可减少读取硬盘的次数。
介绍:ANSIC 标准采用缓冲文件系统来处理数据文件,所谓的缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块文件缓冲区。规则如下:
① 如果从内存向磁盘输出数据,会先送到内存中的缓冲区,缓冲区装满后再一起输送到磁盘上。
② 如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。
注意事项:缓冲区的大小根据C编译系统决定的。

0x01 冲刷缓冲区函数 fflush

介绍:强迫将缓冲区内的数据写回参数 stream 指定的文件中。刷新成功返回 0 ,如果发生错误则返回 EOF ,且设置错误标识符,即 feof 。
注意事项:fflush 不适用于高版本VS

0x02 感受文件缓冲区的存在
观察代码:验证缓冲区概念的存在(VS2013 - Win10)
#include
#include
int main(void) {
FILE* pf = fopen("test7.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n");
Sleep(10000);
printf("刷新缓冲区\n");
fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)
//注:fflush 在高版本的VS上不能使用了
printf("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose在关闭文件的时候,也会刷新缓冲区
pf = NULL;
return 0;
}
运行结果如下:
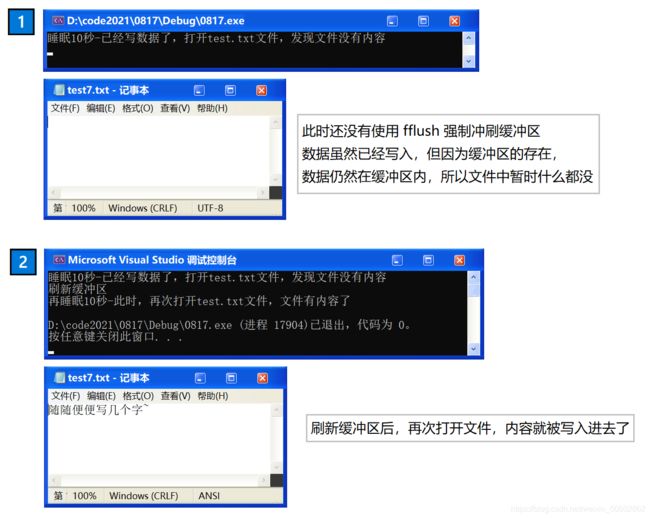
结论: 因为有缓冲区的存在,C语言在操作文件时,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。如果不做,可能导致读写文件的问题。
第十七章 - C语言预处理(上)
前言:
本章将对预处理知识进行讲解。首先介绍预定义符号,随后着重讲解预处理指令。介绍预处理操作符,最后将宏和函数进行对比。
一、预处理
0x00 什么是预处理
【百度百科】程序设计领域中,预处理一般是指在程序源代码被翻译为目标代码的过程中,生成二进制代码之前的过程。典型地,由预处理器(preprocessor) 对程序源代码文本进行处理,得到的结果再由编译器核心进一步编译。这个过程并不对程序的源代码进行解析,但它把源代码分割或处理成为特定的单位——(用C/C++的术语来说是)预处理记号(preprocessing token)用来支持语言特性(如C/C++的宏调用)。
0x01 预定义符号

介绍:在预处理阶段被处理的已经定义好的符号为预定义符号。这些符号是可以直接使用的,是在C语言中已经内置好的。
注意事项:值得注意的是,__ 为两个下划线!
代码演示:
#include
int main(void) {
printf("%s\n", __FILE__); // 返回使用行代码所在的源文件名,包括路径
printf("%d\n", __LINE__); // 返回行号
printf("%s\n", __DATE__); // 返回程序被编译的日期
printf("%s\n", __TIME__); // 返回程序被编译的时间
printf("%s\n", __FUNCTION__); // 返回所在函数的函数名
return 0;
} 运行结果如下:
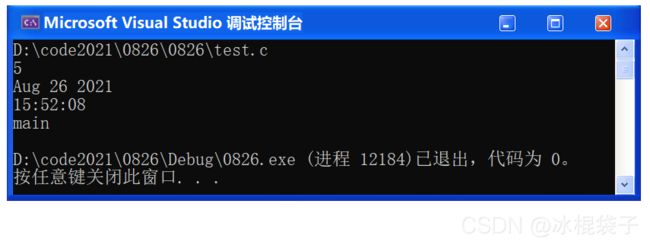
❓ 这些预定义符号有什么用?
如果一个工程特别复杂,这时去调试时可能会无从下手。所以需要代码在运行的过程中记录一些日志信息,通过日志信息分析程序哪里出了问题,再进行排查就如同瓮中捉鳖。
举个例子:
#include
int main(void) {
int i = 0;
FILE* pf = fopen("log.txt", "a+"); //追加的形式,每运行一次就追加
if (pf == NULL) {
perror("fopen");
return 1;
}
for (i = 0; i < 5; i++) {
printf("* 错误日志 ");
printf("%d *\n", i+1);
printf("发生时间:%s %s\n", __DATE__, __TIME__);
printf("具体位置:%s,函数名为%s,第%d行。\n", __FILE__, __FUNCTION__, __LINE__);
printf("\n");
}
fclose(pf);
pf = NULL;
return 0;
} (测试,运行三次代码)
❗ 关于 __STDC__ ,如果编译器完全遵循 ANSI C 标准则返回1,否则未定义。

二、#define
0x00 #define 定义标识符

代码演示:#define 定义标识符的方法
#include
#define TIMES 100
int main(void) {
int t = TIMES;
printf("%d\n", t);
return 0;
} 运行结果:100
解析:在预处理阶段就会把 TIMES 替换为 100。预处理结束后 int t = TIMES 这里就没有TIMES 了,会变为 int t = 1000。
// 预处理前
int t = TIMES;
// 预处理后
int t = 1000;当然了, #define 定义的符号可不仅仅只有数字,还可以用来做很多事,比如:
#define REG register //给关键字register,创建一个简短的名字
#define DEAD_LOOP for(;;) //用更形象的符号来替换一种实现
① #define REG register,给关键字 register,创建一个简短的名字:
#define REG register
int main(void) {
register int num = 0;
REG int num = 0; // 这里REG就等于register
return 0;
}
② #define DEAD_LOOP for(;;) ,用更形象的符号来替换一种实现:
#define DEAD_LOOP for(;;)
int main(void) {
DEAD_LOOP // 预处理后替换为 for(;;);
; // 循环体循环的是一条空语句
DEAD_LOOP; // 那么可以这么写,这个分号就是循环体,循环的是一个空语句
return 0;
}③ 这里假设一个程序里 switch 语句后面都需要加上break,但是某人原来不是写C语言的,他以前用的语言 case 后面是不需要加 break 的,因为他不适应每个 case 后面都要加上 break,所以总是会忘。这时可以妙用 #define 来解决:
#define CASE break;case // 在写case语句的时候自动字上break
int main(void) {
int n = 0;
//switch (n) {
// case 1:
// break;
// case 2:
// break;
// case 3:
// break;
//}
switch (n) {
case 1: // 第一个case不能替换
CASE 2: // 相当于 break; case 2:
CASE 3: // 相当于 break; case 3:
}
return 0;
}

④ 如果定义的 stuff 过长,可以分行来写,除了最后一行外,每行的后面都加一个续行符即可 \ :
#include
#define DEBUG_PRINT printf("file:%s\nline:%d\n \
date:%s\ntime:%s\n" , \
__FILE__,__LINE__ , \
__DATE__,__TIME__ )
int main(void) {
DEBUG_PRINT;
return 0;
}
❓ #define 定义标识符时,为什么末尾没有加上分号?
#define TIMES 100;
#define TIMES 100举个例子:加上分号后,预处理替换的内容也会带分号 100;
#include
#define TIMES 100;
int main(void) {
int t = TIMES; // int t = 100;;
// 等于两个语句
// int t = 100;
// ;
return 0;
} ❌ 举个例子:加上分号,代码会出错的情况
#define _CRT_SECURE_NO_WARNINGS 1
#include
#define TIMES 100;
int main(void) {
int a, b;
if (a > 10)
b = TIMES; // b = 100;;
else // else不知道如何匹配了
b = -TIMES; // b = 100;;
return 0;
} 结论:在 #define 定义标识符时,尽量不要在末尾加分号!(必须加的情况除外)
0x01 #define 定义宏

介绍:#define 机制允许把参数替换到文本中,这种实现通常被称为宏(macro)或 定义宏(define macro),parament-list 是一个由逗号隔开的符号表,他们可能出现在 stuff 中。
注意事项:
① 参数列表的左括号必须与 name 紧邻。
② 如果两者之间由任何空白存在,参数列表就会将其解释为 stuff 的一部分。
代码演示:3×3=9
#include
#define SQUARE(X) X*X
int main(void) {
printf("%d\n", SQUARE(3)); // printf("%d\n", 3 * 3);
return 0;
} 
❓ SQUARE (3+1) 的结果是什么?
#include
#define SQUARE(X) X*X
int main(void) {
printf("%d\n", SQUARE(3+1));
return 0;
} 答案:7 。这里将 3+1 替换成 X,那么 X 就是3+1, 3+1 * 3+1, 根据优先级结果为 7。要看作为一个整体,完全替换。宏的参数是完成替换的,他不会提前完成计算,而是替换进去后再计算。替换是在预处理阶段时替换,表达式真正计算出结果是在运行时计算。
如果想获得 3+1 相乘(也就是得到 4×4 = 16) 的结果,我们需要给他们添加括号:
#include
// 整体再括一个括号,严谨
#define SQUARE(X) ((X)*(X))
int main(void) {
printf("%d\n", SQUARE(3+1));
return 0;
} 
另外,整体再套一个括号!让代码更加严谨,防止产生不必要的错误。举个例子,我们DOUBLE实现两数相加,我希望得到 10* DOUBLE,也就是 "10*表达式相加" 的情况:
#include
#define DOUBLE(X) (X)+(X)
int main(void) {
printf("%d\n", 10 * DOUBLE(3+1));
// printf("%d\n", 10 * (4) + (4));
// 我们本意是想得到80,但是结果为44,因为整体没带括号
return 0;
} 运行结果:44(不是预期想得到的结果)
解决方案:整体再加上一个括号!
#define DOUBLE(X) ((X)+(X))
int main(void) {
printf("%d\n", 10 * DOUBLE(3+1));
return 0;
}运行结果:80(达到预期想得到的结果)
结论:所以用于对数值表达式进行求值的宏定义都应该用这种方式加上括号,可以有效避免在使用宏时由于参数中的操作符或邻近操作符之间不可预料地相互作用。
0x02 #define 替换规则
在程序中扩展 #define 定义符号或宏时,需要涉及的步骤如下:
1️⃣ 检查:在调用宏时,首先对参数进行检查,看看是否包含任何由 #define 定义的符号。如果包含,它们首先被替换。
2️⃣ 替换:替换文本随后被插入到程序中原来的文本位置。对于宏,函数名被它们的值替换。
3️⃣ 再次扫描:最后,再次对结果文件进行扫描,看看是否包含任何由 #define 定义的符号。如果包含,就重复上述处理过程。
举个例子:
#include
#define M 100
#define MAX(X, Y) ((X)>(Y) ? (X):(Y));
int main(void) {
int max = MAX(101, M);
return 0;
} 
注意事项:
① 宏参数 和 #define 定义中可以出现 #define 定义的变量。但是对于宏绝对不能出现递归!
② 当预处理器搜索 #define 定义的符号的时候,字符串常量的内容并不被搜索。

0x03 # 和 ##
❓ 我们知道,宏是把参数替换到文本中。那么如何把参数插入到字符串中呢?
❌ 比如这种情况,使用函数是根本做不到的:
void print(int x) {
printf("变量?的值是%d\n", ?) 函数根本做不到
}
int main(void) {
int a = 10;
// 打印内容:变量a的值是10
print(a);
int b = 20;
// 打印内容:变量b的值是20
print(b);
int c = 30;
// 打印内容:变量c的值是30
print(c);
return 0;
}这种情况,就可以用 宏 来实现。

介绍:# 把一个宏参数变成对应的字符串。
使用 # 解决上面的问题:
#include
#define PRINT(X) printf("变量"#X"的值是%d\n", X);
// #X 就会变成 X内容所定义的字符串
int main(void) {
// 打印内容:变量a的值是10
int a = 10;
PRINT(a); // printf("变量""a""的值是%d\n", a);
// 打印内容:变量b的值是20
int b = 20;
PRINT(b); // printf("变量""b"的值是%d\n", b);
// 打印内容:变量c的值是30
int c = 30;
PRINT(c); // printf("变量""c""的值是%d\n", c);
return 0;
}
运行结果如下:
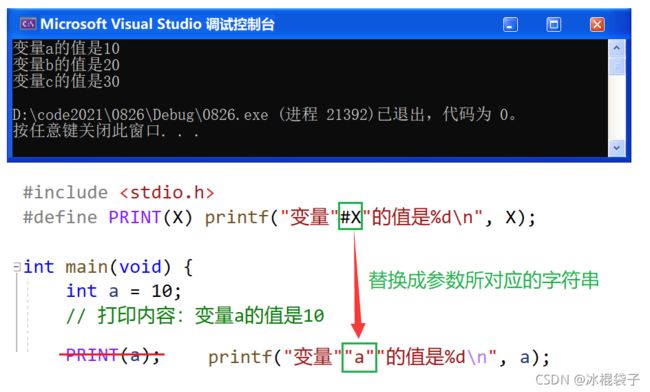
⚡ 改进:让程序不仅仅支持打印整数,还可以打印其他类型的数(比如浮点数):
#include
#define PRINT(X, FORMAT) printf("变量"#X"的值是 "FORMAT"\n", X);
int main(void) {
// 打印内容:变量a的值是10
int a = 10;
PRINT(a, "%d");
// 打印内容:变量f的值是5.5
float f = 5.5f;
PRINT(f, "%.1f"); //printf("变量""f""的值是 ""%.1f""\n", f);
return 0;
} 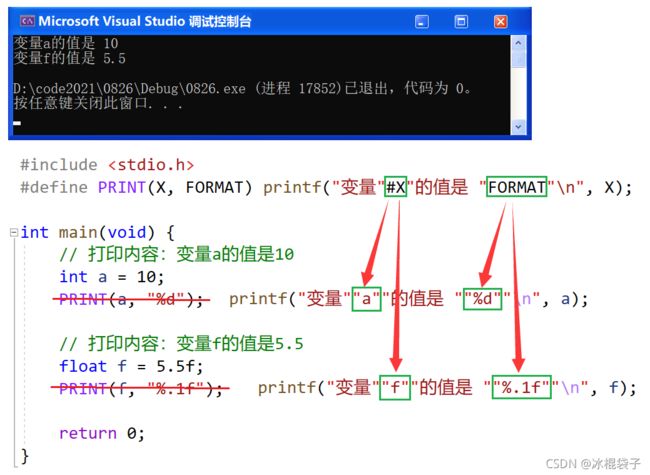
✨ 这操作是不是很奇葩?还有更奇葩的呢,这位更是重量级:


介绍:## 可以把位于它两边的符号融合成一个符号。它允许宏定义从分离的文本片段创建标识符。
使用 ## 将两边的符号缝合成一个符号:
#include
#define CAT(X,Y) X##Y
int main(void) {
int vs2003 = 100;
printf("%d\n", CAT(vs, 2003)); // printf("%d\n", vs2003);
return 0;
} 运行结果如下:
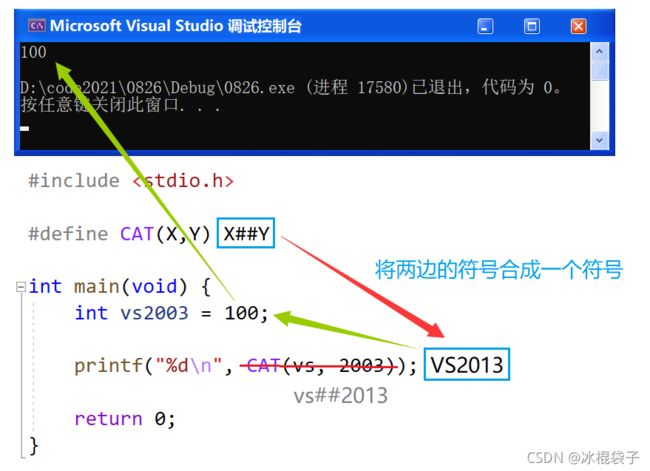
注意事项:## 也可以将多个符号合成一个符号,比如 X##Y##Z
0x04 #undef

用于移除一个宏定义。
代码演示:用完 M 之后移除该定义
#include
#define M 100
int main(void) {
int a = M;
printf("%d\n", M);
#undef M // 移除宏定义
return 0;
}
0x05 带 "副作用" 的宏参数
❓ 什么是副作用?
后遗症就是表达式求值的时候出现的永久性效果,例如:
// 不带有副作用
x + 1;
// 带有副作用
x++;
int a = 1;
// 不带有副作用
int b = a + 1; // b=2, a=1
// 带有副作用
int b = ++a; // b=2, a=2介绍:当宏参数在宏的定义中出现超过一次的情况下,如果参数带有副作用(后遗症),那么你在使用这个宏的时候就可能出现危险,导致不可预料的后果。这种带有副作用的宏参数如果传到宏体内,这种副作用一直会延续到宏体内。
举个例子:
#include
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main(void) {
int a = 5;
int b = 8;
int m = MAX(a++, b++);
printf("m = %d\n", m);
printf("a=%d, b=%d\n", a, b);
return 0;
} 运行结果如下:
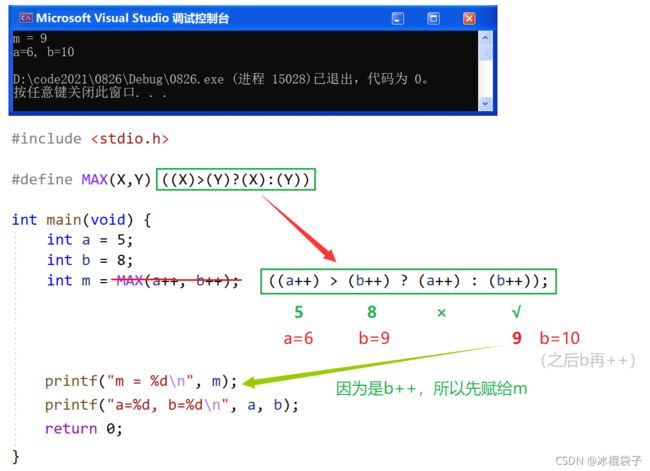
结论:写宏的时候尽量避免使用这种带副作用的参数。
0x06 宏和函数对比
举个例子:在两数中找较大值
① 用宏:
#include
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
int main(void) {
int a = 10;
int b = 20;
int m = MAX(a, b); // int m = ((a)>(b) ? (a):(b))
printf("%d\n", m);
return 0;
} ② 用函数:
#include
int Max(int x, int y) {
return x > y ? x : y;
}
int main(void) {
int a = 10;
int b = 20;
int m = Max(a, b);
printf("%d\n", m);
return 0;
} ❓ 那么问题来了,宏和函数那种更好呢?
用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多,所以宏比函数在程序的规模和速度方面更胜一筹。 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之,宏可以适用于整型、长整型、浮点型等可以用于比较的类型。因为宏是类型无关的。
当然,宏也有劣势的地方:
① 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
② 宏不能调试。
③ 宏由于类型无关,因为没有类型检查,所以不够严谨。
④ 宏可能会带来运算符优先级的问题,导致程容易出现错。
宏有时候可以做函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到:
#include
#include
#define MALLOC(num, type) (type*)malloc(num*sizeof(type))
int main(void) {
// 原本的写法:malloc(10*sizeof(int));
// 但我想这么写:malloc(10, int);
int* p = MALLOC(10, int); // (int*)malloc(10*sizeof(int))
...
return 0;
} 宏和函数的对比表:
| 属性 | #define 定义宏 | 函数 |
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。除了非 常小的宏之外,程序的长度会大幅度增长 | 函数代码只出现于一个地方;每 次使用这个函数时,都调用那个地方的同一份代码 |
| 执行速度 |
更快 | 存在函数的调用和返回的额外开 销,所以相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文环境 里,除非加上括号,否则邻近操作符的优先级可能 会产生不可预料的后果,所以建议宏在书写的时候多些括号 | 函数参数只在函数调用的时候求 值一次,它的结果值传递给函数。表达式的求值结果更容易预测。 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个位置,所以带有副 作用的参数求值可能会产生不可预料的结果 | 函数参数只在传参的时候求值一 次,结果更容易控制。 |
| 参数类型 | 宏的参数与类型无关,只要对参数的操作是合法 的,它就可以使用于任何参数类型 | 函数的参数是与类型有关的,如 果参数的类型不同,就需要不同 的函数,即使他们执行的任务是 不同的 |
| 递归 | 宏是不能递归的 | 函数是可以递归的 |
总结:如果一个运算的逻辑足够简单,建议使用宏。反之,如果一个运算的逻辑足够复杂,建议使用函数。
内联函数(C99)简要介绍:

0x07 命名约定

命名约定,一般来讲函数的宏的使用语法很相似,所以语言本身没法帮我们区分二者。约定俗成的一个习惯是: 宏名全部大写,函数名不要全部大写。
不过这也不是绝对的,比如我有时候就是想把一个宏伪装成函数来使用,那么我就全小写给宏取名。并不强制,但是这个约定是每个C/C++程序员大家的一种 "约定" 。
第十七章 - C语言预处理(下)
前言:
本文为C语言预处理的下篇,本文将进一步讲解预处理的基本知识,对命令行定义进行讲解。对条件编译的语句进行逐个讲解,理解两种文件包含的方式。
传送门:楼下大爷看完直呼简单!C语言预处理(上)
一、命令行编译
❓ 什么是命令行编译?
在编译的时候通过命令行的方式对其进行相关的定义,叫做命令行编译。
介绍:许多C的编译器提供的一种能力,允许在命令行中定义符号。用于启动编译过程。当我们根据同一个源文件要编译出不同的一个程序的不同版本的时,可以用到这种特性,增加灵活性。
例子:假如某个程序中声明了一个某个长度的数组,假如机器甲内存有限,我们需要一个很小的数据,但是机器丙的内存较大,我们需要一个大点的数组。
#include
int main() {
int arr[ARR_SIZE];
int i = 0;
for (i = 0; i < ARR_SIZE; i++) {
arr[i] = i;
}
for (i = 0; i < ARR_SIZE; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
} gcc 环境下测试:(VS 里面不太好演示)
gcc test.c -D ARR_SIZE=5
ls
a.out test.c
./a.out
0 1 2 3 4 5
gcc test.c -D ARR_SIZE=20
./a.out
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
二、条件编译
0x00 介绍
在编译一个程序时,通过条件编译指令将一条语句(一组语句)编译或者放弃是很方便的。
调试用的代码删除了可惜,保留了又碍事。我们就可以使用条件编译来选择性地编译:
#include
#define __DEBUG__ // 就像一个开关一样
int main(void)
{
int arr[10] = {0};
int i = 0;
for (i = 0; i < 10; i++) {
arr[i] = i;
#ifdef __DEBUG__ // 因为__DEBUG__被定义了,所以为真
printf("%d ", arr[i]); // 就打印数组
#endif // 包尾
}
return 0;
}
运行结果:1 2 3 4 5 6 7 8 9 10
❗ 如果不想用了,就把 #define __DEBUG__ 注释掉:
#include
// #define __DEBUG__ // 关
int main(void)
{
int arr[10] = {0};
int i = 0;
for (i = 0; i < 10; i++) {
arr[i] = i;
#ifdef __DEBUG__ // 此时ifdef为假
printf("%d ", arr[i]);
#endif
}
return 0;
}
(代码成功运行)
0x01 条件编译之常量表达式

介绍:如果常量表达式为真,参加编译。反之如果为假,则不参加编译。
代码演示:常量表达式为真
#include
int main(void) {
#if 1
printf("Hello,World!\n");
#endif
return 0;
} 运行结果:Hello,World!
代码演示:常量表达式为假
#include
int main(void) {
#if 0
printf("Hello,World!\n");
#endif
return 0;
}
(代码成功运行)
当然也可以用宏替换,可以表示地更清楚:
#include
#define PRINT 1
#define DONT_PINRT 0
int main(void) {
#if PRINT
printf("Hello,World!\n");
#endif
return 0;
}
0x02 多分支的条件编译

介绍:多分支的条件编译,直到常量表达式为真时才执行。
代码演示:
#include
int main(void) {
#if 1 == 2 // 假
printf("rose\n");
#elif 2 == 2 // 真
printf("you jump\n");
#else
printf("i jump\n")
#endif
return 0;
} 代码运行结果:you jump
0x03 条件编译判断是否被定义

定义:ifdef 和 if defined() ,ifndef 和 if !defined() 效果是一样的,用来判断是否被定义。
代码演示:
#include
#define TEST 0
// #define TEST2 // 不定义
int main(void) {
/* 如果TEST定义了,下面参与编译 */
// 1
#ifdef TEST
printf("1\n");
#endif
// 2
#if defined(TEST)
printf("2\n");
#endif
/* 如果TEST2不定义,下面参与编译 */
// 1
#ifndef TEST2
printf("3\n");
#endif
// 2
#if !defined(TEST2)
printf("4\n");
#endif
return 0;
}
0x04 条件编译的嵌套
和 if 语句一样,是可以嵌套的:
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif三、文件包含
我们已经知道,#include 指令可以使另外一个文件被编译。就像它实际出现于 #include 指令的地方一样。替换方式为,预处理器先删除这条指令,并用包含文件的内容替换。这样一个源文件被包含10次,那就实际被编译10次。
0x00 头文件被包含的方式

< > 和 " " 包含头文件的本质区别:查找的策略的区别
① " " 的查找策略:先在源文件所在的目录下查找。如果该头文件未找到,则在库函数的头文件目录下查找。(如果仍然找不到,就提示编译错误)
Linux环境 标准头文件的路径:
/usr/includeVS环境 标准头文件的路径:
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include② < > 的查找策略:直接去标准路径下去查找。(如果仍然找不到,就提示编译错误)
❓ 既然如此,那么对于库文件是否也可以使用 " " 包含?
当然可以。但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。为了效率不建议这么做。
代码演示:
① add.h
int Add(int x, int y);② add.c
int Add(int x, int y) {
return x + y;
}③ test.c
#include
#include "add.h"
int main(void) {
int a = 10;
int b = 20;
int ret = Add(a, b);
printf("%d\n", ret);
return 0;
} 运行结果:30
0x01 嵌套文件的包含
❗ 头文件重复引入的情况:

comm.h 和 comm.c 是公共模块。
test1.h 和 test1.c 使用了公共模块。
test2.h 和 test2.c 使用了公共模块。
test.h 和 test.c 使用了 test1 模块和 test2 模块。
这样最终程序中就会出现两份 comm.h 的内容,这样就造成了文件内容的重复。
❓ 那么如何避免头文件的重复引入呢?
使用条件编译指令,每个头文件的开头写:
#ifndef __TEST_H__
#define __TEST_H__
// 头文件的内容
#endif⚡ 如果嫌麻烦,还有一种非常简单的方法:
#pragma once // 让头文件即使被包含多次,也只包含一份笔试题:选自《高质量C/C++编程指南》
① 头文件中的 ifnde / define / endif 是干什么用的?
答:防止头文件被重复多次包含。
② #include
答:尖括号是包含库里面的头文件的,双引号是包含自定义头文件的。它们在查找策略上不同,尖括号直接去库目录下查找。而警号双引号是现去自定义的代码路径下查找,如果找不到头文件,则在库函数的头文件目录下查找。
第十八章 - C语言程序环境
我这里有一些好康的!杰哥不要啊~【浅析C语言程序环境】

前言
程序环境是什么?我们都 "经历" 过,但不曾感知到 "他" 的存在。我们其实在不知不觉中早就已经接触到了程序环境…… 第一次创建了一个文件(test.c),敲下那句 "hello world" 随后保存后点击运行后编译出可执行文件(test.exe)时,其实就已经接触到了 "他" 了。
我们只是按下了运行,然后好像所有东西都像变魔术一样直接就产生了,这一切都似乎是理所当然的事。但是你是否思考过他是如何变成 "可执行程序" 的呢?在这一章,我们将简单地探讨一个 "源程序"是如何变成 "可执行程序" 的,作一个大概了解。
一、翻译环境和执行环境
0x00 ANSI C 标准
ANSI C是由美国国家标准协会(ANSI)及国际化标准组织(ISO)推出的关于C语言的标准。ANSI C 主要标准化了现存的实现, 同时增加了一些来自 C++ 的内容 (主要是函数原型) 并支持多国字符集 (包括备受争议的三字符序列)。
ANSI C 几乎被所有广泛使用的编译器所支持,且多数C代码是在ANSI C基础上写的。
【百度百科】ANCI C 标准
0x01 程序的翻译环境和执行环境
ANSI C 的任何一种实现中,存在两种不同的环境:
① 翻译环境:在该环境中,源代码被转换为可执行的机器指令。
② 执行环境:用于实际执行代码。
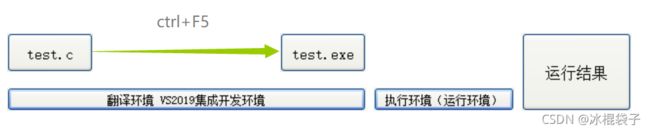
二、详解编译和链接
0x00 翻译环境

组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)
每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
连接器同时也会引入标准C库函数中任何被该程序所用到的函数,且可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。
举个例子:test.c、add.c、minu.c
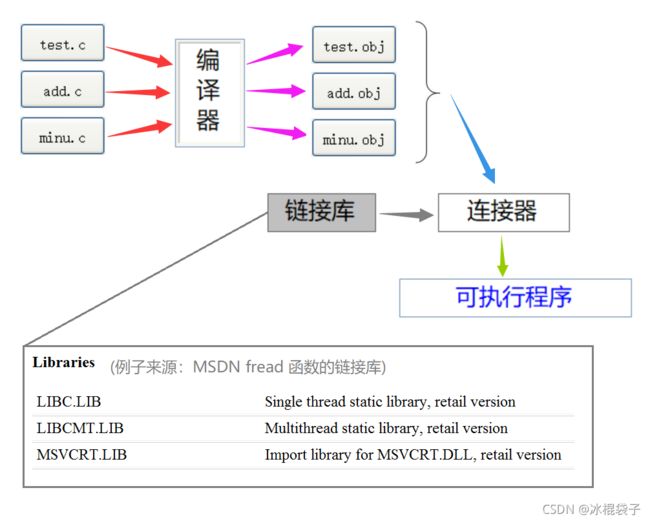
0x01 编译本身的几个阶段
举个例子:
① sum.c
int global_val = 2021;
void print(const char* string) {
printf("%s\n", string);
}② test.c
#include
int main(void) {
extern void print(char* string);
extern int global_val;
printf("%d\n", global_val);
printf("Hello,World!\n");
return 0;
} | test.c sum.c |
预编译截断(*.i) 预处理指令 …… |
编译(*.s) 语法分析 词法分析 语义分析 符号汇总 |
汇编(生成可重定位目标文件 *.O) 形成符号表 汇编指令 → 二进制指令 ----→ test.o ----→ sum.o |
链接 1. 合并段表 2. 符号表的合并和符号表的重定位 |
| 隔离编译,一起链接。 |
||||
main.c
extern int sum(int, int);
int main(void) {
sum(1, 2);
return 0;
}sum.c
int sum(int num1, int num2) {
return( num1 + num2);
}解析图(VS2019):
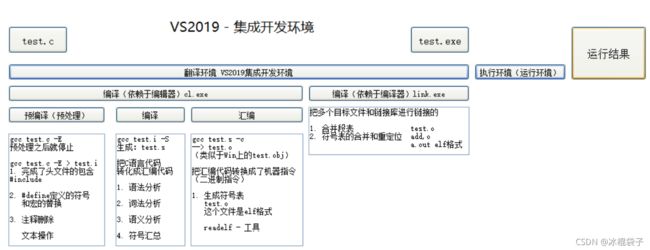
0x02 运行环境
程序执行过程:
① 程序必须载入内存中。在有操作系统的环境中:程序的载入一般由操作系统完成。在独立环境中:程序的载入必须手工安排,也可能是通过可执行代码置入只读内存来完成。
② 程序的执行便开始。接着便调用 main 函数。
③ 开始执行程序代码,这个时候程序将使用一个运行时堆栈(stack),内存函数的局部变量和返回地址。程序同时也可以使用静态(staic)内存,存储与静态内存中的变量在整个执行过程中一直保留他们的值。
④ 终止程序。正常终止 main 函数(也有可能是意外终止)。
举个例子:这段代码的执行过程
int Add(int x, int y) {
return( x + y);
}
int main(void) {
int a = 10;
int b = 20;
int ret = Add(a, b);
return 0;
}
这里还有一个概念:函数栈帧 (目前做简单了解,后续我将专门写一篇函数栈帧的讲解)
【百度百科】C语言中,每个栈帧对应着一个未运行完的函数。栈帧中保存了该函数的返回地址和局部变量。
数组笔试题(附答案+详解)
前言:
本章为数组部分的练习章节,一共八个大题。配备答案+详细画图解析。
如果你还没有学过数组,或者想复习一下再写:
传送门:【维生素C语言】第四章 - 数组
例题:

题目详解展示:

数组笔试题(答案+详解)
8道大题(共63小题),每小题1分,满分63分
说明:
① 建议做题时拿出纸和笔写出你认为的结果;
② 建议先不要看答案,写完后再看答案进行核对;
③ 部分题目前面有对应知识点的传送超链接,可自行选择复习;
④ 对于做错的题,可以看题目答案下面的解析部分,以便深入理解;
⑤ 可以在评论区回复自己做对了几题;
第一大题:
每小题1分,满分7分
复习:【维生素C语言】第五章 - 操作符( 0x05 操作数的类型长度 sizeof )
预测下列代码的运行结果( sizeof )
int main()
{
int a[] = {1, 2, 3, 4}; // 一维数组
/* 1 */ printf("%d\n", sizeof(a));
/* 2 */ printf("%d\n", sizeof(a + 0));
/* 3 */ printf("%d\n", sizeof(*a));
/* 4 */ printf("%d\n", sizeof(a + 1));
/* 5 */ printf("%d\n", sizeof(a[1]));
/* 6 */ printf("%d\n", sizeof(&a));
/* 7 */ printf("%d\n", sizeof(*&a));
/* 8 */ printf("%d\n", sizeof(&a + 1));
/* 9 */ printf("%d\n", sizeof(&a[0]));
/* 10 */ printf("%d\n", sizeof(&a[0] + 1));
return 0;
}答案:
/* 1 */ printf("%d\n", sizeof(a)); // 16
/* 2 */ printf("%d\n", sizeof(a + 0)); // 4/8
/* 3 */ printf("%d\n", sizeof(*a)); // 4
/* 4 */ printf("%d\n", sizeof(a + 1)); // 4/8
/* 5 */ printf("%d\n", sizeof(a[1])); // 4
/* 6 */ printf("%d\n", sizeof(&a)); // 4/8
/* 7 */ printf("%d\n", sizeof(*&a)); // 16
/* 8 */ printf("%d\n", sizeof(&a + 1)); // 4/8
/* 9 */ printf("%d\n", sizeof(&a[0])); // 4/8
/* 10 */ printf("%d\n", sizeof(&a[0] + 1)); // 4/8解析:
1️⃣

2️⃣

3️⃣

4️⃣

5️⃣

6️⃣
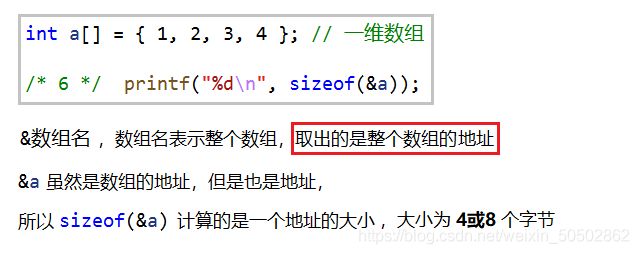
7️⃣

8️⃣

9️⃣


第二大题:
复习:【维生素C语言】第四章 - 数组( 0x02 一维数组的初始化 )
每小题1分,满分7分
预测下列代码的运行结果( sizeof )
int main()
{
char arr[] = {'a','b','c','d','e','f'}; // 字符数组
/* 1 */ printf("%d\n", sizeof(arr));
/* 2 */ printf("%d\n", sizeof(arr+0));
/* 3 */ printf("%d\n", sizeof(*arr));
/* 4 */ printf("%d\n", sizeof(arr[1]));
/* 5 */ printf("%d\n", sizeof(&arr));
/* 6 */ printf("%d\n", sizeof(&arr+1));
/* 7 */ printf("%d\n", sizeof(&arr[0]+1));
return 0;
}答案:
/* 1 */ printf("%d\n", sizeof(arr)); // 6
/* 2 */ printf("%d\n", sizeof(arr+0)); // 4/8
/* 3 */ printf("%d\n", sizeof(*arr)); // 1
/* 4 */ printf("%d\n", sizeof(arr[1])); // 1
/* 5 */ printf("%d\n", sizeof(&arr)); // 4/8
/* 6 */ printf("%d\n", sizeof(&arr+1)); // 4/8
/* 7 */ printf("%d\n", sizeof(&arr[0]+1)); // 4/8 解析:
1️⃣

2️⃣

3️⃣
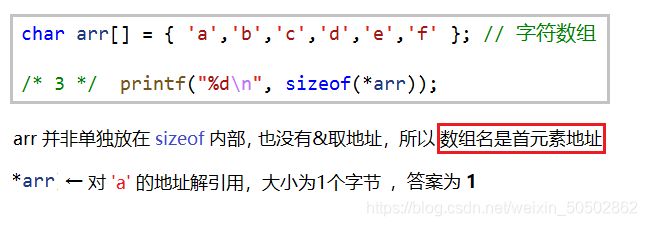
4️⃣

5️⃣
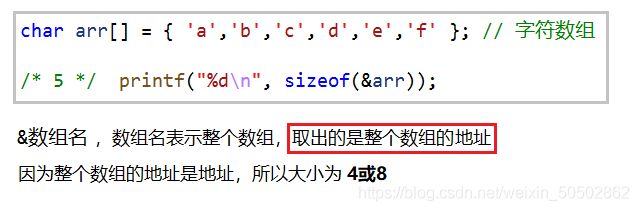
6️⃣
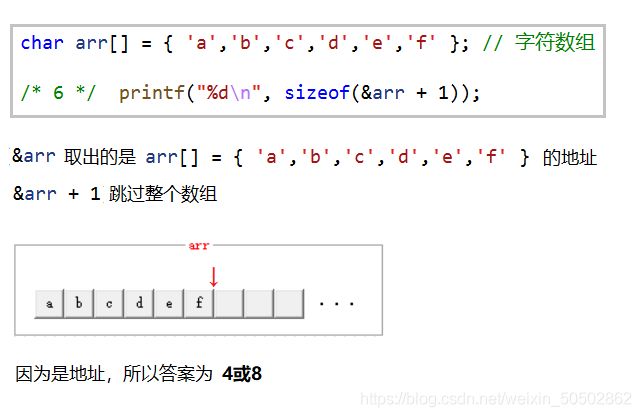
7️⃣

第三大题:
每小题1分,满分7分
预测下列代码的运行结果( strlen )
int main()
{
char arr[] = { 'a','b','c','d','e','f' }; // 字符数组
/* 1 */ printf("%d\n", strlen(arr));
/* 2 */ printf("%d\n", strlen(arr + 0));
/* 3 */ printf("%d\n", strlen(*arr));
/* 4 */ printf("%d\n", strlen(arr[1]));
/* 5 */ printf("%d\n", strlen(&arr));
/* 6 */ printf("%d\n", strlen(&arr + 1));
/* 7 */ printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
答案:
/* 1 */ printf("%d\n", strlen(arr)); // 随机值
/* 2 */ printf("%d\n", strlen(arr + 0)); // 随机值
/* 3 */ printf("%d\n", strlen(*arr)); // error
/* 4 */ printf("%d\n", strlen(arr[1])); // error
/* 5 */ printf("%d\n", strlen(&arr)); // 随机值
/* 6 */ printf("%d\n", strlen(&arr + 1)); // 随机值-6
/* 7 */ printf("%d\n", strlen(&arr[0] + 1)); // 随机值-1解析:
1️⃣

2️⃣

3️⃣

4️⃣

5️⃣

6️⃣

7️⃣

第四大题:
每小题1分,满分7分
预测下列代码的运行结果( sizeof )
int main()
{
char arr[] = "abcdef";
/* 1 */ printf("%d\n", sizeof(arr));
/* 2 */ printf("%d\n", sizeof(arr+0));
/* 3 */ printf("%d\n", sizeof(*arr));
/* 4 */ printf("%d\n", sizeof(arr[1]));
/* 5 */ printf("%d\n", sizeof(&arr));
/* 6 */ printf("%d\n", sizeof(&arr+1));
/* 7 */ printf("%d\n", sizeof(&arr[0]+1));
return 0;
}
答案:
/* 1 */ printf("%d\n", sizeof(arr)); // 7
/* 2 */ printf("%d\n", sizeof(arr+0)); // 4/8
/* 3 */ printf("%d\n", sizeof(*arr)); // 1
/* 4 */ printf("%d\n", sizeof(arr[1]));// 1
/* 5 */ printf("%d\n", sizeof(&arr)); // 4/8
/* 6 */ printf("%d\n", sizeof(&arr+1)); // 4/8
/* 7 */ printf("%d\n", sizeof(&arr[0]+1)); // 4/8解析:
1️⃣

2️⃣

3️⃣
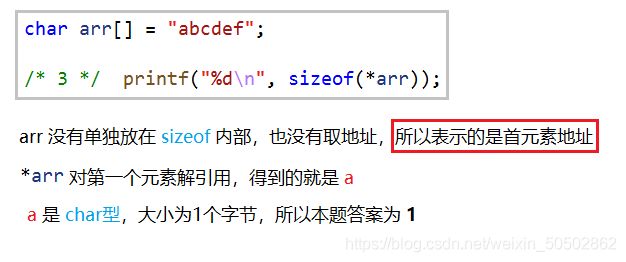
4️⃣

5️⃣
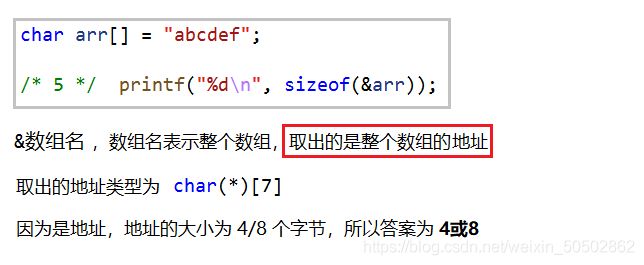
6️⃣

7️⃣

第五大题:
每小题1分,满分7分
预测下列代码的运行结果( strlen )
int main()
{
char arr[] = "abcdef";
/* 1 */ printf("%d\n", strlen(arr));
/* 2 */ printf("%d\n", strlen(arr + 0));
/* 3 */ printf("%d\n", strlen(*arr));
/* 4 */ printf("%d\n", strlen(arr[1]));
/* 5 */ printf("%d\n", strlen(&arr));
/* 6 */ printf("%d\n", strlen(&arr + 1));
/* 7 */ printf("%d\n", strlen(&arr[0] + 1));
return 0;
}答案:
/* 1 */ printf("%d\n", strlen(arr)); // 6
/* 2 */ printf("%d\n", strlen(arr+0)); // 6
/* 3 */ printf("%d\n", strlen(*arr)); // error
/* 4 */ printf("%d\n", strlen(arr[1])); // error
/* 5 */ printf("%d\n", strlen(&arr)); // 6
/* 6 */ printf("%d\n", strlen(&arr+1)); // 随机值
/* 7 */ printf("%d\n", strlen(&arr[0]+1)); // 5解析:
1️⃣
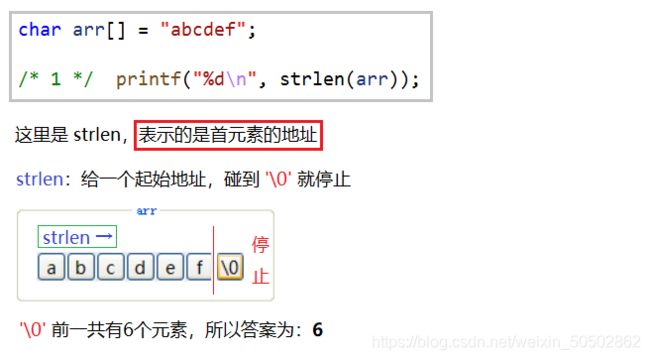
2️⃣

3️⃣

4️⃣

5️⃣

6️⃣
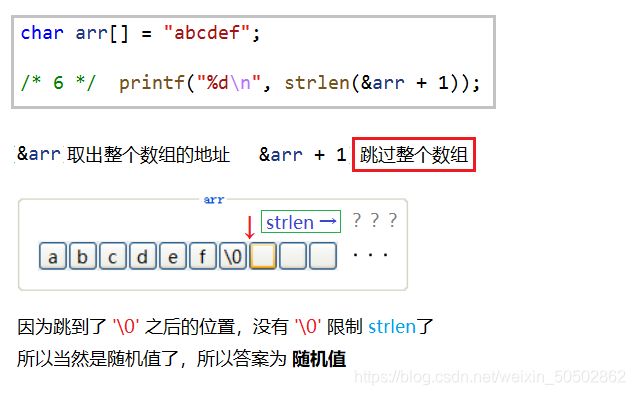
7️⃣

第六大题:
每小题1分,满分7分
复习:【维生素C语言】第十章 - 指针的进阶(上)( 0x00 字符指针的定义 )
预测下列代码的运行结果( sizeof )
int main()
{
char* p = "abcdef";
/* 1 */ printf("%d\n", sizeof(p));
/* 2 */ printf("%d\n", sizeof(p + 1));
/* 3 */ printf("%d\n", sizeof(*p));
/* 4 */ printf("%d\n", sizeof(p[0]));
/* 5 */ printf("%d\n", sizeof(&p));
/* 6 */ printf("%d\n", sizeof(&p + 1));
/* 7 */ printf("%d\n", sizeof(&p[0] + 1));
return 0;
}答案:
/* 1 */ printf("%d\n", sizeof(p)); // 4/8
/* 2 */ printf("%d\n", sizeof(p+1)); // 4/8
/* 3 */ printf("%d\n", sizeof(*p)); // 1
/* 4 */ printf("%d\n", sizeof(p[0])); // 1
/* 5 */ printf("%d\n", sizeof(&p));// 4/8
/* 6 */ printf("%d\n", sizeof(&p+1)); // 4/8
/* 7 */ printf("%d\n", sizeof(&p[0]+1)); // 4/8解析:
1️⃣

2️⃣

3️⃣

4️⃣

5️⃣

6️⃣

7️⃣

第七大题:
每小题1分,满分7分
预测下列代码的运行结果( strlen )
int main()
{
char *p = "abcdef";
/* 1 */ printf("%d\n", strlen(p));
/* 2 */ printf("%d\n", strlen(p+1));
/* 3 */ printf("%d\n", strlen(*p));
/* 4 */ printf("%d\n", strlen(p[0]));
/* 5 */ printf("%d\n", strlen(&p));
/* 6 */ printf("%d\n", strlen(&p+1));
/* 7 */ printf("%d\n", strlen(&p[0]+1));
return 0;
}答案:
/* 1 */ printf("%d\n", strlen(p)); // 6
/* 2 */ printf("%d\n", strlen(p+1)); // 5
/* 3 */ printf("%d\n", strlen(*p)); // error
/* 4 */ printf("%d\n", strlen(p[0])); // error
/* 5 */ printf("%d\n", strlen(&p)); // 随机值
/* 6 */ printf("%d\n", strlen(&p+1)); // 随机值
/* 7 */ printf("%d\n", strlen(&p[0]+1)); // 5解析:
1️⃣
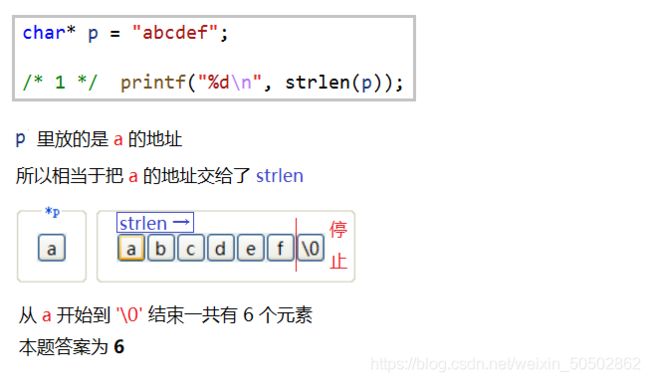
2️⃣

3️⃣

4️⃣

5️⃣

6️⃣

7️⃣

第八大题:
每小题1分,满分11分
预测下列代码的运行结果( sizeof )
int main()
{
int a[3][4] = {0}; // 二维数组
/* 1 */ printf("%d\n",sizeof(a));
/* 2 */ printf("%d\n",sizeof(a[0][0]));
/* 3 */ printf("%d\n",sizeof(a[0]));
/* 4 */ printf("%d\n",sizeof(a[0]+1));
/* 5 */ printf("%d\n",sizeof(*(a[0]+1)));
/* 6 */ printf("%d\n",sizeof(a+1));
/* 7 */ printf("%d\n",sizeof(*(a+1)));
/* 8 */ printf("%d\n",sizeof(&a[0]+1));
/* 9 */ printf("%d\n",sizeof(*(&a[0]+1)));
/* 10 */ printf("%d\n",sizeof(*a));
/* 11 */ printf("%d\n",sizeof(a[3]));
return 0;
}
答案:
/* 1 */ printf("%d\n",sizeof(a)); // 48
/* 2 */ printf("%d\n",sizeof(a[0][0])); // 4
/* 3 */ printf("%d\n",sizeof(a[0])); // 16
/* 4 */ printf("%d\n",sizeof(a[0]+1)); // 4/8
/* 5 */ printf("%d\n",sizeof(*(a[0]+1)));// 4
/* 6 */ printf("%d\n",sizeof(a+1)); // 4
/* 7 */ printf("%d\n",sizeof(*(a+1))); // 16
/* 8 */ printf("%d\n",sizeof(&a[0]+1)); // 4/8
/* 9 */ printf("%d\n",sizeof(*(&a[0]+1))); // 16
/* 10 */ printf("%d\n",sizeof(*a)); // 16
/* 11 */ printf("%d\n",sizeof(a[3])); // 16解析:
1️⃣

2️⃣

3️⃣

4️⃣

5️⃣
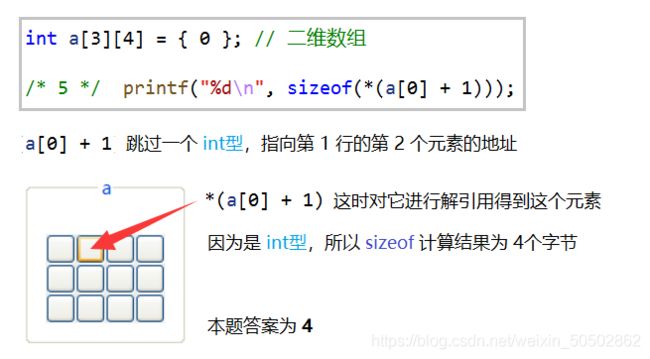
6️⃣

7️⃣

8️⃣

9️⃣


1️⃣1️⃣

总结:
数组名的意义:
① sizeof ( 数组名 ) - 数组名表示整个数组,计算的是整个数组的大小。
② &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
③ 除此之外,所有的数组名都表示首元素的地址。
画图解析C语言指针笔试题
前言:
C语言指针笔试题,建议做完后再看答案。本篇博客有详细的解析部分,对每一道题进行深度的画图解析。如果你想复习下指针再来做,可以进入下面的传送门:
【维生素C语言】第六章 - 指针
【维生素C语言】第十章 - 指针的进阶(上)
【维生素C语言】第十章 - 指针的进阶(下)
指针笔试题(答案+详解)
说明:
① 建议做题时拿出纸和笔写出你认为的结果;
② 建议先把答案遮住(不小心看到也没事),看看你哪里想错了,重要的不是结果;
③ 对于做错的题,可以看题目答案下面的解析部分,以便深入理解;
第一题:
下列程序运行后的结果是什么?
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}本题答案:
2,5详细解析:( 图画错了,是 int a[5] = {1,2,3,4,5} )

第二题:
假设 p 的值为 0x100000,如下表达式的值分别为多少?
(已知结构体 Test 类型的变量大小为 20 个字节)
// 由于还没有学习结构体,这里告知结构体大小是20个字节
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}本题答案:
00000014
00000001
00000004详细解析:

第三题:
下列程序运行后的结果是什么?
int main()
{
int a[4] = { 1,2,3,4 };
int* ptr1 = (int*) (&a + 1);
int* ptr2 = (int*) ((int)a + 1);
printf("%x, %x", ptr1[-1], *ptr2);
return 0;
}本题答案:
4, 2000000详细解析:
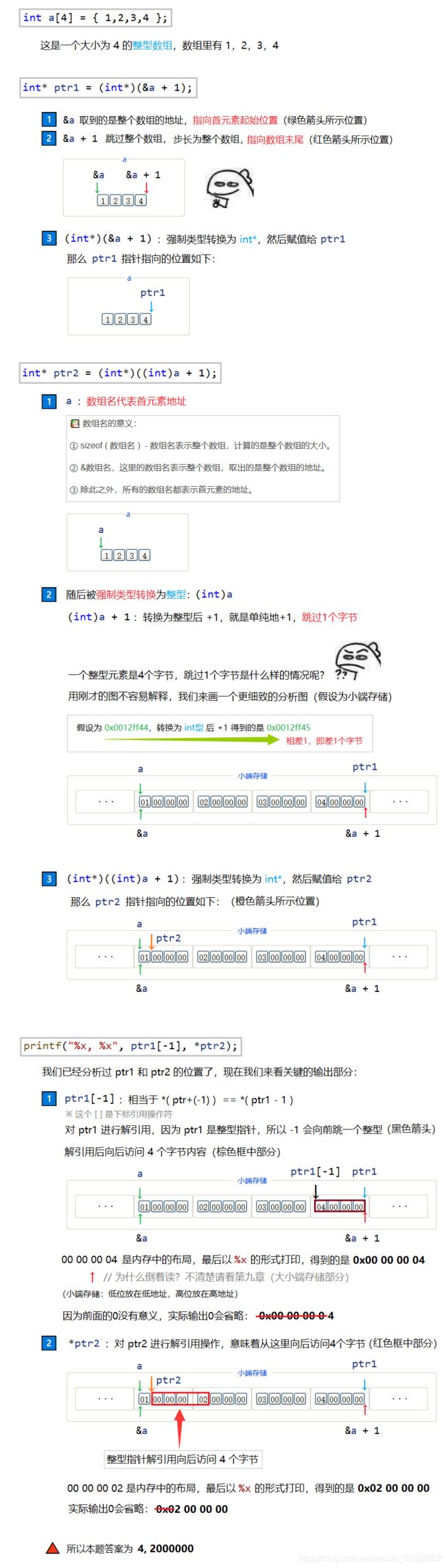
第四题:
下列程序运行后的结果是什么?
int main()
{
int a[3][2] = { (0, 1), (2, 3),(4, 5) };
int* p;
p = a[0];
printf("%d", p[0]);
return 0;
}
本题答案:
1详细解析:

第五题:
下列程序运行后的结果是什么?
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p, %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
本题答案:
FFFFFFFC, -4详细解析:

第六题:
下列程序运行后的结果是什么?
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d, %d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}本题答案:
10, 5详细解析:
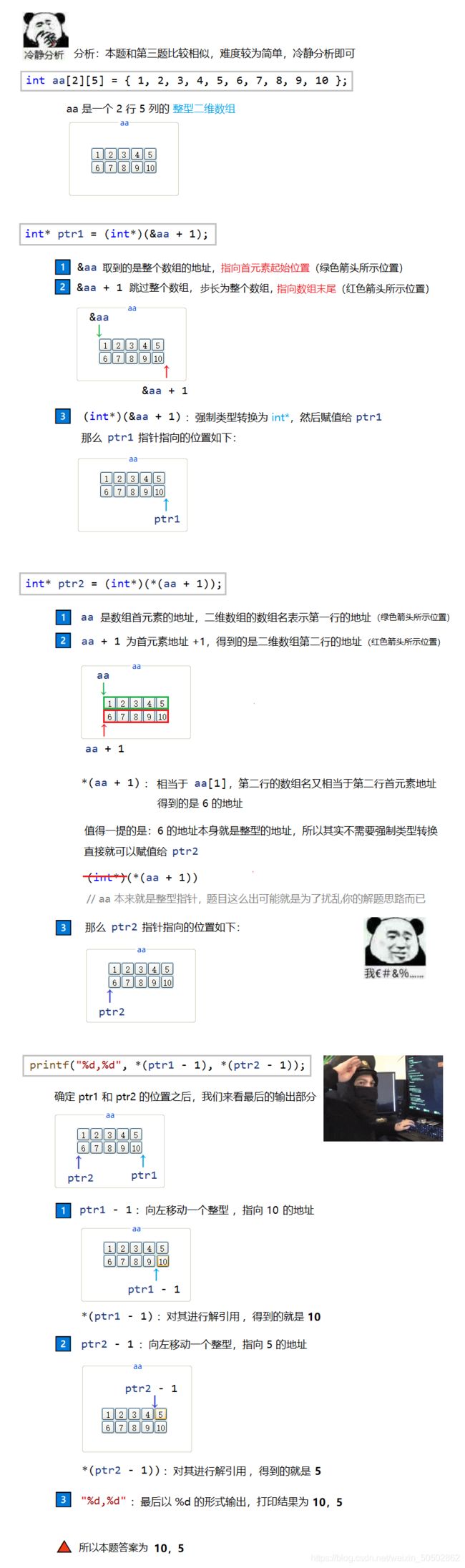
第七题:
下列程序运行后的结果是什么?
int main()
{
char* a[] = { "work", "at", "alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}本题答案:
at详细解析:
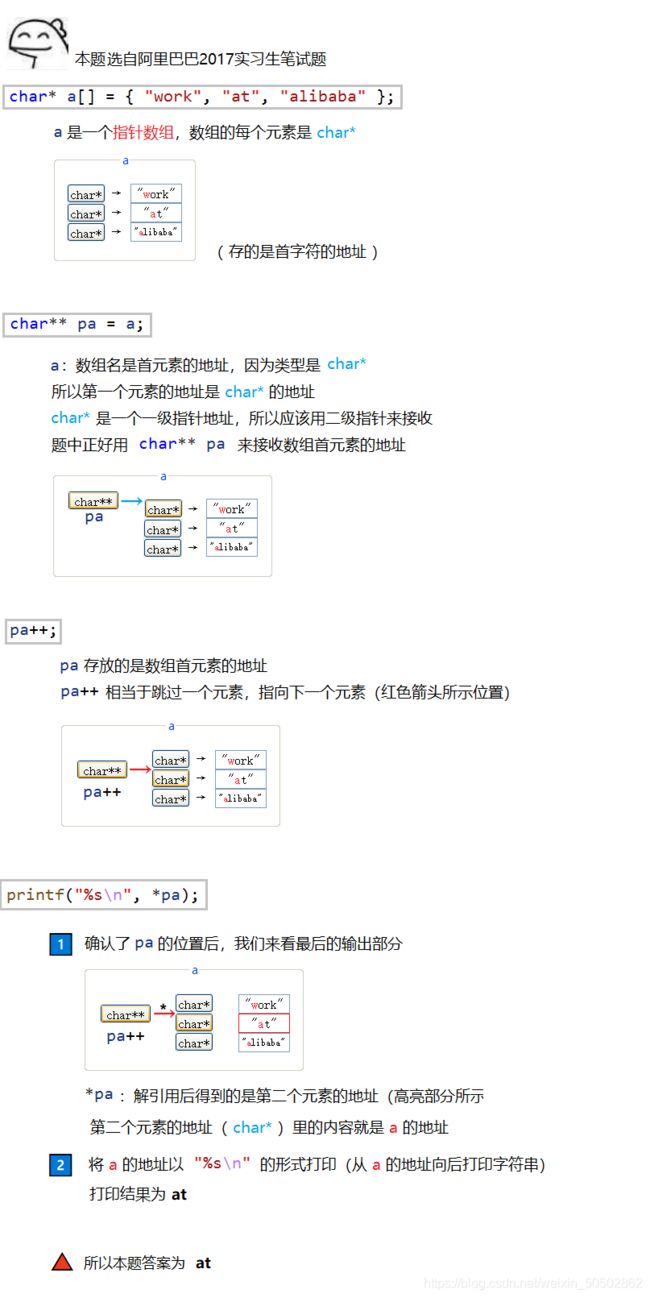
第八题:
下列程序运行后的结果是什么?
int main()
{
char *c[] = {"ENTER", "NEW", "POINT", "FIRST"};
char**cp[] = {c+3, c+2, c+1, c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}本题答案:
POINT
ER
ST
EW解题思路图:

经典动态内存分配笔试题(题目+答案+详解)
前言:
题目选自高质量的C++/C编程指南、Nice2016校招笔试题。
(共4道大题,每题25分。满分100分)
选自高质量的C++/C编程指南、Nice2016校招笔试题
传送门:【维生素C语言】动态内存管理 (相关知识点复习)
第一题:
下列代码存在什么问题?请指出问题并做出相应的修改。
#include
#include
#include
void GetMemory(char *p) {
p = (char*)malloc(100);
}
void Test() {
char *str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
int main() {
Test();
return 0;
}
参考答案:str 传给 GetMemory 函数时为值传递,所以 GetMemory 函数的形参 p 是 str 的一份临时拷贝。在 GetMemory 函数内部动态开辟的内存空间的地址存放在了 p 中,并不会影响 str。所以当 GetMemory 函数返回之后, str 仍然是 NULL,导致 strcpy 拷贝失败。其次,随着 GetMemory 函数的返回,形参 p 随即销毁并且没有及时的使用 free 释放,从而导致动态开辟的100个字节存在内存泄露问题。根据经验,程序会出现卡死的问题。
详细解析:
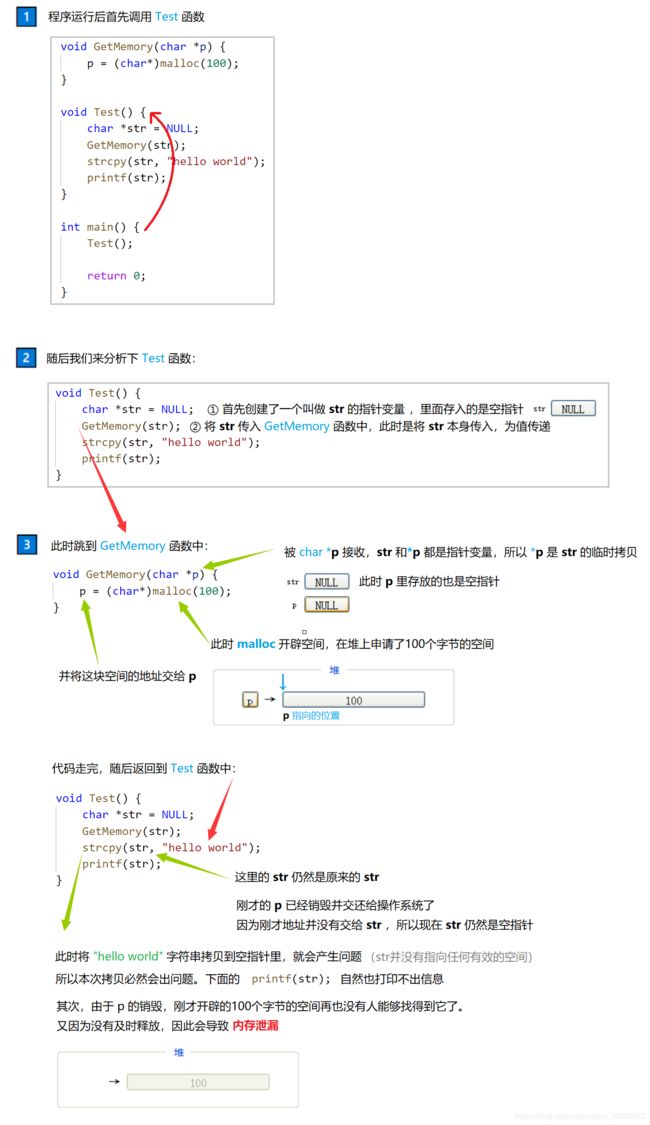
⚡ 代码修改:
① 返回 p ,让 str 接收:
#include
#include
#include
// ↓ 修改返回类型为char*
char* GetMemory(char *p) {
p = (char*)malloc(100);
return p; // 将p带回来
}
void Test() {
char *str = NULL;
str = GetMemory(str); // 用str接收,此时str指向刚才开辟的空间
strcpy(str, "hello world"); // 此时copy就没有问题了
printf(str);
// 用完之后记得free,就可以解决内存泄露问题
free(str);
str = NULL; // 还要将str置为空指针
}
int main() {
Test();
return 0;
} hello world
② 将值传递改为址传递:
#include
#include
#include
// ↓ 用char**接收
void GetMemory(char** p) {
*p = (char*)malloc(100);
}
void Test() {
char *str = NULL;
GetMemory(&str); // 址传递,就可以得到地址
strcpy(str, "hello world");
printf(str);
// 记得free,就可以解决内存泄露问题
free(str);
str = NULL; // 还要将str置为空指针
}
int main() {
Test();
return 0;
}
hello world
第二题:
下列代码存在什么问题?
#include
#include
char* GetMemory(void) {
char p[] = "hello world";
return p;
}
void Test(void) {
char *str = NULL;
str = GetMemory();
printf(str);
}
int main() {
Test();
return 0;
}
参考答案:GetMemory 函数内部创建的数组实在栈区上创建的,出了函数 p 数组的空间就还给了操作系统,返回的地址是没有实际意义的,如果通过返回的地址去访问内存,就会导致非法访问内存问题。
详细解析:
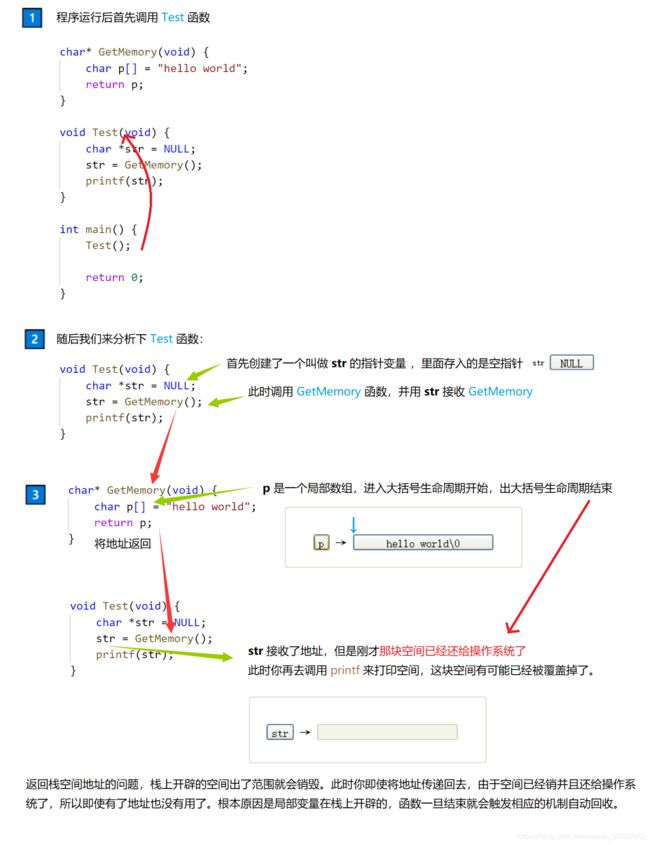
第三题:
下列代码存在什么问题?请指出问题并做出相应的修改。
#include
#include
void GetMemory(char **p, int num) {
*p = (char *)malloc(num);
}
void Test(void) {
char *str = NULL;
GetMemory(&str, 100);
strcpy(str, "hello");
printf(str);
}
int main() {
Test();
return 0;
} 参考答案:没有 free,导致内存泄露。
详细解析:

⚡ 代码修改:
#include
#include
void GetMemory(char **p, int num) {
*p = (char *)malloc(num);
}
void Test(void) {
char *str = NULL;
GetMemory(&str, 100);
strcpy(str, "hello");
printf(str);
// 释放并置空
free(str);
str = NULL;
}
int main() {
Test();
return 0;
} 第四题:
下列代码存在什么问题?请指出问题并做出相应的修改。
#include
#include
#include
void Test(void) {
char *str = (char *) malloc(100);
strcpy(str, "hello");
free(str);
if(str != NULL) {
strcpy(str, "world");
printf(str);
}
}
int main() {
Test();
return 0;
} 本题答案:free 之后没有将 str 置为空指针,导致 if 为真,对已经释放掉的内存进行了访问,引发非法访问的问题。
详细解析:
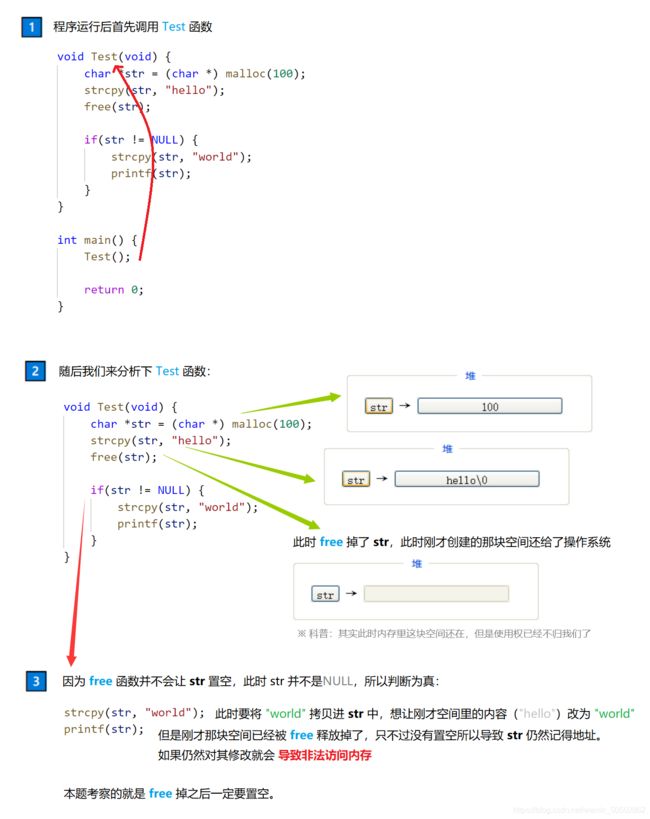
⚡ 代码修改:
#include
#include
#include
void Test(void) {
char *str = (char *) malloc(100);
strcpy(str, "hello");
free(str);
str = NULL; // 置空
if(str != NULL) {
strcpy(str, "world");
printf(str);
}
}
int main() {
Test();
return 0;
}
本系列完。