深度学习CV岗位面试问题总结(OCR篇)
序言
OCR篇面试知识点总结,问题收集、自问自答,学习、记录、分享和复习。
PaddleOCR的知识宝藏仓库
OCR面试知识点总结
1. 介绍一下CRNN和CTC的原理
CRNN借鉴了语音识别中的LSTM+CTC,不同点是输入进LSTM的特征由语音领域的声学特征,替换为CNN网络提取的图像特征向量。整个CRNN网络可以分为三部分:卷积层、循环层、转录层,卷积层即为普通的卷积神经网络,基于7层CNN(普遍使用VGG16),用于提取输入图像的特征;循环层即循环神经网络,通常用一个深层的双向LSTM,在卷积特征的基础上继续提取文字序列特征,输出序列特征分类,最后转录层由CTC作为训练损失,实现字符位置与类标的软对齐。
CTC主要解决的是输出序列和标签对应不上的问题,RNN进行时序分类时,不可避免地会出现很多冗余信息,比如一个字母被连续识别两次,这时候就需要一个去冗余机制,举个例子,当一个标签为ab的图像输入到CRNN中,经过RNN后得到了长度为5的序列向量,前面三个序列向量都映射为“a”,后面两个映射为“b”,即得到输出为aaabb,如果直接将重复的字符合并去除的话得到的结果就为ab,但是当如果标签之间也存在连续字符时,例如aab,将连续a去除后就得到了ab,这显然是不对的,所以CTC引入了blank机制,以“-”符号代表blank,若标签为aaaaaabb,则结果为ab,若标签为aaa-aaaabb,则结果为aab。
端到端不定长文字识别CRNN算法详解
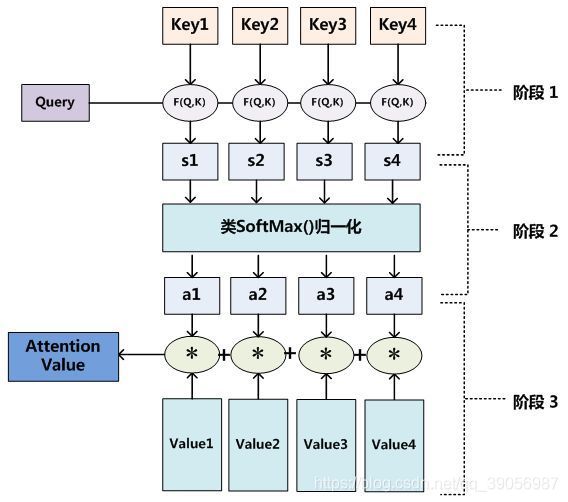
2. 介绍一下Attention机制的原理
Attention机制本质是从人类视觉注意力机制获得的灵感,简单来说就是从大量信息中快速筛选出高价值的东西,主要用来解决LSTM/RNN模型输入序列较长的时候很难获得最终合理的向量表示的问题。做法是保留LSTM的中间结果,用新的模型对其进行学习,并将其与输出进行关联,从而达到信息筛选的目的。总的来说Attention机制就是一系列注意力分配系数,也就是一系列的权重参数,注意力模型就是要从序列中学习到每一个元素的重要程度,然后按重要程度将元素合并。
Attention里有三个重要的参数,Q(查询向量)、K(键向量)、V(值向量),计算主要分为三步:
- 将Q和每个K进行相似度计算得到权重,常用的相似度函数有点积、拼接、感知机等;
- 使用一个softmax函数对这些权重进行归一化;
- 用归一化的权值与V加权求和,最后得出的结果就是注意力值。
对于query Q 、key K 、value V,可以用一个公式来总结:
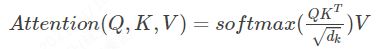
其中的dk作为归一化。
3. 对于中文行文本识别,CTC和Attention哪种更优?
首先,从效果上来看,通用OCR场景CTC的识别效果优于Attention,因为带识别的字典中的字符比较多,常用中文汉字三千字以上,如果训练样本不足的情况下,对于这些字符的序列关系挖掘比较困难。中文场景下Attention模型的优势无法体现。而且Attention适合短语句识别,对长句子识别比较差。
其次,从训练和预测速度上,Attention的串行解码结构限制了预测速度,而CTC网络结构更高效,预测速度上更有优势。
4. 介绍一下DBNet文本检测算法,它为什么这么快?
一般基于分割的文本检测网络中,都是先通过网络输出图片的文本分割结果(概率图,每个像素为是否是正样本的概率),然后使用预设的阈值将分割结果图转换为二值图,最后使用一些聚合操作例如连通域将像素级的结果转换为检测结果,并且阈值不同对性能影响较大。在这个过程中,阈值操作是不可微的。DBNet的全称是可微的二值化网络,即引入一个可微的二值化DB模块,对每一个像素点进行自适应二值化,二值化阈值由网络学习得到,将二值化这一步骤加入到网络中一起训练,最终的输出图对于阈值就会非常棒。
DB模块公式:

其实就是一个带系数的sigmoid,和sigmoid的对比如下 :

DBNet阅读笔记
5. 介绍一下DBNet的推理过程
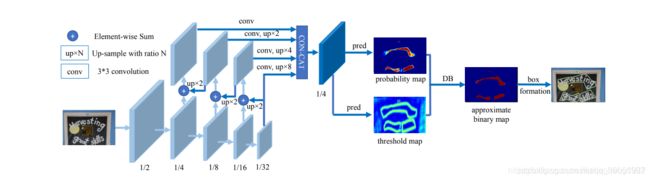
训练过程,训练过程中,将图片输入网络后,经过特征提取和上采样融合并concat操作后得到上图中蓝色的特征图称为F,然后使用F预测出概率图(probability map)称为P和使用F预测出阈值图( threshold map)称为T,最后通过P和T计算出近似二值图B(binary map) 。
推断过程,使用概率图也可以使用近似的二值图来生成文本区域。为了更加的高效,只使用概率图就可以了。在概率图或者近似二值图使用值为0.2的阈值得到二值图,通过得到的二值图获取文本的连通区域,利用偏移量D将连通域放大就得到了文本区域。
偏移量D计算方式:
![]()
A’表示连通区域的面积,L’是连通区域多边形的周长,r’设为1.5。
DBNet论文详解
6. 介绍一下PSENet算法
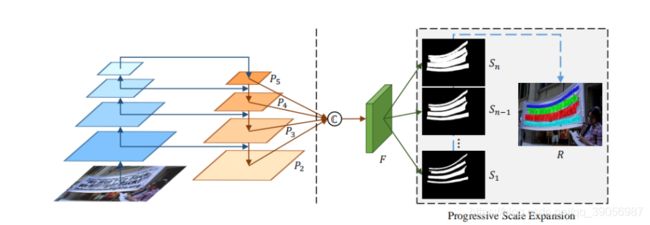
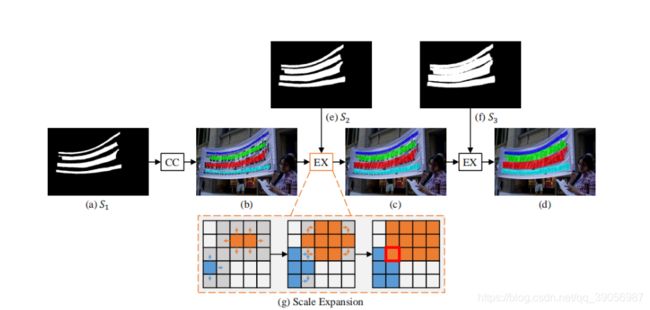
PSENet的核心是提出了渐进式扩展算法解决基于分割的算法不能区分相邻文本的问题。PSE的思想是首先预测每个文本行的不同的kernels(核),这些kernels和原始的文本行具有同样的形状,并且中心和原始的文本行相同,但是在尺度上是逐渐递增的,最大的kernels就是原始文本行大小。
对这些kernels采用渐进式扩展算法,它基于广度优先搜索(BFS), 由三个步骤组成:
- 从具有最小尺度的核S1 开始(在此步骤中可以区分实例,不同实例有不同的连通域);
- 通过逐步在较大的核中加入更多的像素来扩展它们的区域;
- 完成直到发现最大的核。
在逐渐扩展的过程中是收到上一级kernel监督的,因此即使扩增到原始文本行大小也能够将边缘像素区分开来。
PSENet论文详解
PSENet原理介绍
7. 介绍一下CTPN算法的原理
CTPN是由Faster-RCNN改进而来,结合了CNN和双向LSTM网络,CTPN提出了一个新奇的想法,把文本检测的任务拆分,先检测文本的的小部分,当文本的所有部分都检测出来后,再对齐进行合并,合并之后就得到了一个完整的文本框。为了解决边界预测不准的问题,引入了BiLSTM对连续的小文本框序列进行预测,BiLSTM能够有效的把左右两个方向的序列信息都加入到学习的过程中去,能够使边界的预测准确率大大的提升。
CTPN借鉴了Faster-RCNN的anchor回归机制,但是做了一些创新,只回归两个参数(y,h),y是anchor的纵向偏移,h为文本框的高度。每一个候选框的宽度固定为16像素,只学习y和h这两个参数来完成小候选框的检测。
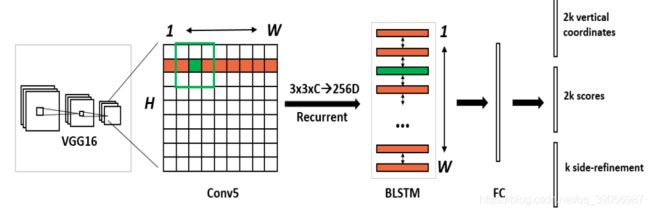
CTPN的基础网络使用了VGG16用于特征提取,在VGG的最后一个卷积层CONV5,CTPN用了3×3的卷积核来对该feature map做卷积,这个CVON5 特征图的尺寸由输入图像来决定,而卷积时的步长却限定为16,感受野被固定为228个像素。卷积后的特征将送入BLSTM继续学习,最后接上一层全连接层FC输出我们要预测的参数:2K个纵向坐标y,2k个分数,k个x的水平偏移量。2k个vertical coordinate,因为一个anchor用的是中心位置的高(y坐标)和矩形框的高度两个值表示的,所以一个用2k个输出。(注意这里输出的是相对anchor的偏移)。2k个score,因为预测了k个text proposal,所以有2k个分数,text和non-text各有一个分数。k个side-refinement,这部分主要是用来精修文本行的两个端点的,表示的是每个proposal的水平平移量。
ctpn详解
【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
8. 你知道哪些文本行纠正方案?
比较常用的纠正方案有几种:
- 基于霍夫变换检测直线角度后进行纠正;
- 在检测文本的同时检测四个顶点,例如车牌等,然后根据四个顶点做仿射变换;
- 如果是一些多边形的检测背景,可以使用关键点回归检测出背景的多个顶点,然后在进行透视变换后再进行文本检测;
9. 基于深度学习的文字检测有哪几种?各有什么特点?
常用的基于深度学习的文字检测方法一般可以分为基于回归的、基于分割的两大类,当然还有一些将两种结合起来的方法。
- 于回归的方法分为box回归和像素值回归。a.采用box回归的方法主要有CTPN、Textbox系列和EAST,这类算法对规则形状文本检测效果较好,但无法准确检测不规则形状文本。
b. 像素值回归的方法主要有CRAFT和SA-Text,这类算法能够检测弯曲文本且对小文本效果优秀但是实时性能不够。 - 基于分割的算法,如PSENet,这类算法不受文本形状的限制,对各种形状的文本都能取得较好的效果,但是往往后处理比较复杂,导致耗时严重。目前也有一些算法专门针对这个问题进行改进,如DB,将二值化进行近似,使其可导,融入训练,从而获取更准确的边界,大大降低了后处理的耗时。
10. 弯曲形变的文字识别时需要怎么处理?
在通常情况下,如果是场景弯曲形变不是太严重,可以检测四个点,然后直接同该国仿射变换、透视变换纠正识别即可;如果弯曲形变得比较厉害,可以尝试使用TPS,即薄板样条插值。还可以结合场景进行分析,例如如果是检测公章文字,可以先将公章用特定算法拉平后在进行检测识别也是可以的。
11. 介绍一下TPS和它的应用场景
TPS(Thin PlateSpline),薄板样条插值,是一种插值算法,经常用于图像变形等,通过少量的控制点久可以驱动图像进行变化。一般用于有弯曲的形变文本识别中,当检测到不规则的文本区域,往往先使用TPS算法对文本区域纠正成矩形再进行识别,如STAR-Net、RARE等识别算法中皆引入了TPS模块。
12. 使用常规的目标检测如YOLO、Faster-RCNN作为文本检测模型有什么局限性?效果和专门的文本检测有什么区别?
其实文本检测也是目标检测的一种,早期的文本检测也使用了yolo、rcnn等目标检测算法,但是由于文本的多样性,要求非高的检测精度,面对类似这些问题:文字之间存在空隙、文字和背景的区分不大、存在众多的弯曲\旋转的不规则文本等,普通的目标检测算法在不经过特殊的改进是无法解决的。所以普通的目标检测算法逐渐被专门的文本检测算法所取代,但是也并不是一无用处。文本检测算法普遍适用于任何复杂的场景文本检测,但是不是所有的项目场景都很复杂,很多场景传统的检测算法是足矣应对的(一些规则的文字场景),并且检测出来的文本框还分好了类,识别后还可以省去了文本段版面分析的繁琐步骤。
13. OCR领域常用的评估指标是什么?
OCR任务通常分为两个阶段,检测和识别:
- 检测阶段:先按照检测框和标注框的IOU评估,IOU大于某个阈值判断为检测准确。这里检测框和标注框不同于一般的通用目标检测框,是采用多边形进行表示。检测准确率:正确的检测框个数在全部检测框的占比,主要是判断检测指标。检测召回率:正确的检测框个数在全部标注框的占比,主要是判断漏检的指标。
- 识别阶段: 字符识别准确率,即正确识别的文本行占标注的文本行数量的比例,只有整行文本识别对才算正确识别。
14. 单张图上多语种并存识别(如单张图印刷和手写文字并存),应该如何处理?
单张图像中存在多种类型文本的情况很常见,典型的以学生的试卷为代表,一张图像同时存在手写体和印刷体两种文本,这类情况下,可以尝试”1个检测模型+1个N分类模型+N个识别模型”的解决方案。
其中不同类型文本共用同一个检测模型,N分类模型指额外训练一个分类器,将检测到的文本进行分类,如手写+印刷的情况就是二分类,N种语言就是N分类,在识别的部分,针对每个类型的文本单独训练一个识别模型,如手写+印刷的场景,就需要训练一个手写体识别模型,一个印刷体识别模型,如果一个文本框的分类结果是手写体,那么就传给手写体识别模型进行识别,其他情况同理。
15. CRNN能否识别两行的文字?
CRNN是一种基于1D-CTC的算法,其原理决定无法识别2行或多行的文字,只能单行识别。
16. 怎么判断文本行图像是否颠倒?
- 原始图像和颠倒图像都进行识别预测,取得分较高的为识别结果。
- 训练一个正常图像和颠倒图像的方向分类器进行判断。
17. 支持空格的模型,标注数据的时候是不是要标注空格?中间几个空格都要标注出来么?
如果需要检测和识别模型,就需要在标注的时候把空格标注出来,而且在字典中增加空格对应的字符。标注过程中,如果中间几个空格标注一个就行。
18. 如果考虑支持竖排文字识别,相关的数据集如何合成?
竖排文字与横排文字合成方式相同,只是选择了垂直字体。
19. 训练文字识别模型,真实数据有30w,合成数据有500w,需要做样本均衡吗?
需要,一般需要保证一个batch中真实数据样本和合成数据样本的比例是1:1~1:3左右效果比较理想。如果合成数据过大,会过拟合到合成数据,预测效果往往不佳。
还有一种启发性的尝试是可以先用大量合成数据训练一个base模型,然后再用真实数据微调,在一些简单场景效果也是会有提升的。
20. 竖排文字识别时候,字的特征已经变了,这种情况在数据集和字典标注是新增一个类别还是多个角度的字共享一个类别?
可以根据实际场景做不同的尝试,共享一个类别是可以收敛,效果也还不错。但是如果分开训练,同类样本之间一致性更好,更容易收敛,识别效果会更优。
21. CRNN中如何更换backbone?
CRNN中的backbone替换需要考虑到下采样后的长宽比,需要在backbone中设置,高度一般都会下采样32倍,宽度通常只下采样4倍,所以需要调整backbone中的池化或者卷积的stride宽下降大小。
22. 文本识别训练不加LSTM是否可以收敛?
理论上是可以收敛的,加上LSTM模块主要是为了挖掘文字之间的序列关系,提升识别效果。对于有明显上下文语义的场景效果会比较明显。
23. 文本识别中LSTM和GRU如何选择?
从项目实践经验来看,序列模块采用LSTM的识别效果优于GRU,但是LSTM的计算量比GRU大一些,可以根据自己实际情况选择。
24. 对于CRNN模型,backbone采用DenseNet和ResNet,哪种网络结构更好?
Backbone的识别效果在CRNN模型上的效果,与Imagenet 1000 图像分类任务上识别效果和效率一致。在图像分类任务上ResNet(76%+)的识别精度劣于DenseNet(77%+),在两者精度差不多的情况下,理论上DenseNet的效果要好一些,但是此外对于GPU,Nvidia针对ResNet系列模型做了优化,预测效率更高,所以相对而言,resnet是较好选择。如果是移动端,可以优先考虑MobileNetV3系列。
25. 训练识别时,如何选择合适的网络输入shape?
一般高度采用32,最长宽度的选择,有两种方法:
- 统计训练样本图像的宽高比分布。最大宽高比的选取考虑满足80%的训练样本。
- 统计训练样本文字数目。最长字符数目的选取考虑满足80%的训练样本。然后中文字符长宽比近似认为是1,英文认为3:1,预估一个最长宽度。
26. 如何识别文字比较长的文本?
在中文识别模型训练时,并不是采用直接将训练样本缩放到[3,32,320]进行训练,而是先等比例缩放图像,保证图像高度为32,宽度不足320的部分补0,宽高比大于10的样本直接丢弃。预测时,如果是单张图像预测,则按上述操作直接对图像缩放,不做宽度320的限制。如果是多张图预测,则采用batch方式预测,每个batch的宽度动态变换,采用这个batch中最长宽度。
27. 对于图片中的密集文字,有什么好的处理办法吗?
可以先试用预训练模型测试一下,例如DB+CRNN,判断下密集文字图片中是检测还是识别的问题,然后针对性的改善。还有一种是如果图象中密集文字较小,可以尝试增大图像分辨率,对图像进行一定范围内的拉伸,将文字稀疏化,提高识别效果。
28. 对于一些在识别时稍微模糊的文本,有没有一些图像增强的方式?
在人类肉眼可以识别的前提下,可以考虑图像处理中的均值滤波、中值滤波或者高斯滤波等模糊算子尝试。也可以尝试从数据扩增扰动来强化模型鲁棒性,另外新的思路有对抗性训练和超分SR思路,可以尝试借鉴。但目前业界尚无普遍认可的最优方案,建议优先在数据采集阶段增加一些限制提升图片质量。
29. 对于特定文字检测,例如身份证只检测姓名,检测指定区域文字更好,还是检测全部区域再筛选更好?
两个角度来说明一般检测全部区域再筛选更好。
- 由于特定文字和非特定文字之间的视觉特征并没有很强的区分行,只检测指定区域,容易造成特定文字漏检。
- 产品的需求可能是变化的,不排除后续对于模型需求变化的可能性(比如又需要增加一个字段),相比于训练模型,后处理的逻辑会更容易调整。
30. 如何识别带空格的英文行文本图像?
空格识别可以考虑以下两种方案:
- 优化文本检测算法。检测结果在空格处将文本断开。这种方案在检测数据标注时,需要将含有空格的文本行分成好多段。
- 优化文本识别算法。在识别字典里面引入空格字符,然后在识别的训练数据中,如果用空行,进行标注。此外,合成数据时,通过拼接训练数据,生成含有空格的文本。
31. 低像素文字或者字号比较小的文字有什么超分辨率方法吗?
超分辨率方法分为传统方法和基于深度学习的方法。基于深度学习的方法中,比较经典的有SRCNN,另外CVPR2020也有一篇超分辨率的工作可以参考文章:Unpaired Image Super-Resolution using Pseudo-Supervision,但是没有充分的实践验证过,需要看实际场景下的效果。
32. 识别模型中如何做到横排和竖排同时支持的?
合成了一批竖排文字,逆时针旋转90度后加入训练集与横排一起训练。预测时根据图片长宽比判断是否为竖排,若为竖排则将crop出的文本逆时针旋转90度后送入识别网络。
33. 背景干扰严重的文字(例如印章盖到落款上),需要识别落款或者印章中的文字,该如何识别?
- 在人眼确认可识别的条件下,对于背景有干扰的文字,首先要保证检测框足够准确,如果检测框不准确,需要考虑是否可以通过过滤颜色等方式对图像预处理并且增加更多相关的训练数据;在识别的部分,注意在训练数据中加入背景干扰类的扩增图像。
- 如果MobileNet模型不能满足需求,可以尝试ResNet系列大模型来获得更好的效果 。
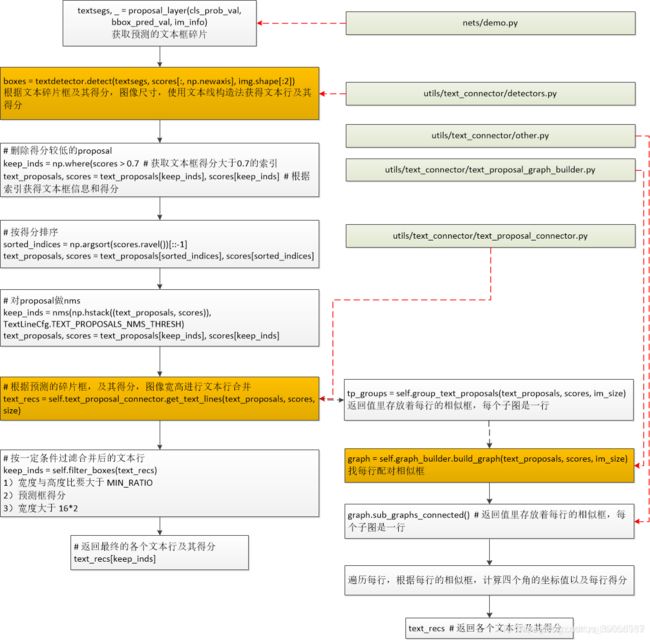
34. 介绍一下文本线构造算法构造文本行
文本线构造法是CTPN中使用,用于对获取的预测碎片框合并成一行文本行的后处理方法,:
在CTPN中根据文本碎片框及其得分,图像尺寸,使用文本线构造法获得文本行及其得分。步骤如下:
- 删除得分较低的proposal
- proposal按得分排序
- 对proposal做nms
- 根据预测的碎片框,及其得分,图像宽高进行文本行合并
- 按一定条件过滤合并后的文本行。
CTPN源码解析5-文本线构造算法构造文本行