目标检测算法——YOLOV5
1、主要贡献
网上对YOLOV5是否称得上V5都有异议,可见其并没有算法上的重大创新,主要是多种trick的集成,并且开源了一套快速训练、部署的方案。
2、主要思路
主体流程和V3类似,三分分支预测,如下:
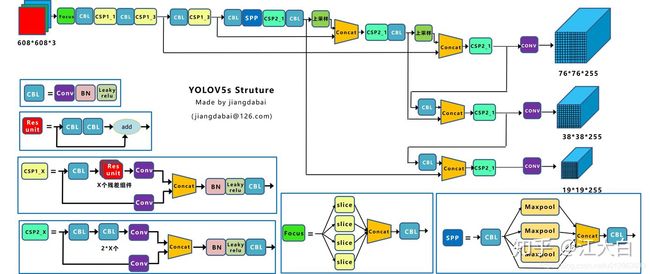
3、具体细节
1)input
主要使用如下trick:Mosaic数据增强、自适应锚框计算、自适应图片缩放。下面分别叙述
a.Mosaic数据增强
Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,如下图:
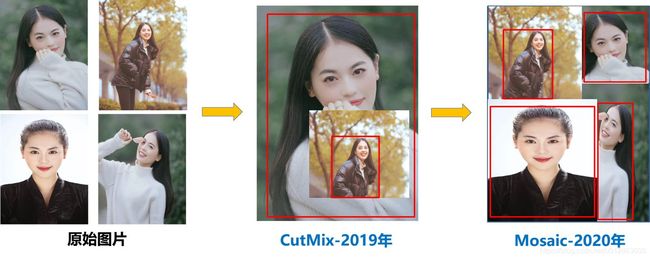
mosaic主要用来解决小目标检测的问题,小目标定义如下(长宽0×0~32×32之间的物体):

但在整体的数据集中,小、中、大目标的占比并不均衡。 如下表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。 但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
主要有几个优点:
*丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
*减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
b.自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。 在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。 在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。 但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。 当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。 控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
具原理:
*考虑到数据有进行随机增强,对dataset的所有bbox进行随机变换,
*利用预设值anchor基于shape规则对bbox计算best possible recall。具体细节是:先利用n个bbox,shape=nx2,和9个anchor计算wh比例值;取wh中的最小值;取9个anchor中最大的比例值;比例值大于阈值,则认为匹配,计算匹配比例即可。由于其计算过程是max(min()),故是最大可能召回率。
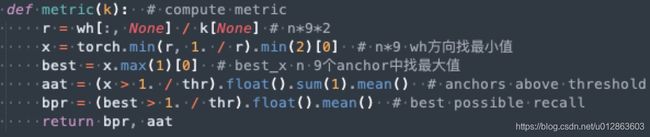
*如果召回率大于0.98,则不用优化了,直接返回;如果小于0.98,则利用遗传算法+kmean重新计算anchor;一直迭代保存召回率最高的anchor即可。
可以看出,由于计算Loss时候匹配规则是shape,而不是iou,所以kmeans算法的聚类结果也是采用shape下召回率作为评估指标。
至于遗传算法+kmean计算anchor,也比较简单,遗传算法是最经典的智能优化算法,主要包括选择、交叉和变异三个步骤,先选择一些种子即初始值,然后经过适应度函数(评估函数)得到评估指标,对不错的解进行交叉和变异操作,进行下一次迭代。采用优胜劣汰准则不断进化,得到最优解。但是本文仅仅是模拟了遗传算法思想,因为其只有变异这一个步骤即对第一次运行得到的anchor进行随机变异操作,然后再次计算适应度函数值,选择最好的。
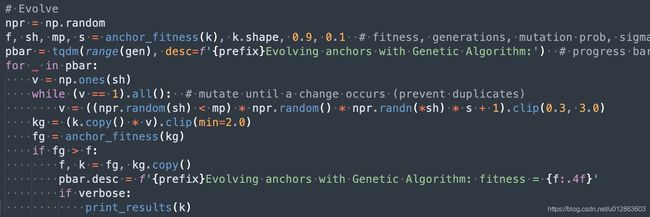
最佳超参查找策略这个就更加简单暴力了,直接设定一组要优化的超参,设定优化范围;然后随机初始化参数,进行train,保存结果;在下一代训练时候,对前述topk最佳超参进行随机选择一组参数,然后进行变异,然后再重新train,重复100遍;最后对搜索结果进行可视化挑选最佳参数。
c.自适应图片缩放
在常用的目标检测算法中,是将原始图片统一缩放到一个标准尺寸( 比如Yolo算法中常用416*416,608*608等尺寸),再送入检测网络中。 但Yolov5代码中对此进行了改进: 在项目实际使用时,由于不同图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度,因此 对原始图像自适应的添加最少的黑边,推理速度得到了37%的提升。
具体如下:
第一步:计算缩放比例
原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
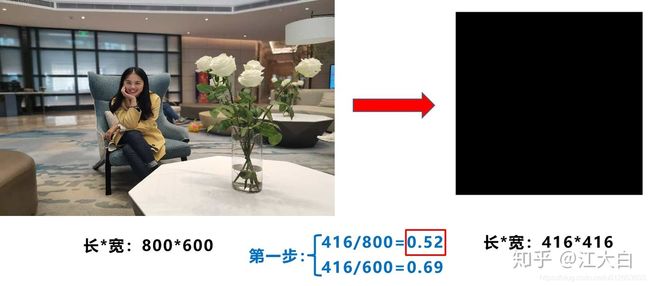
第二步:计算缩放后的尺寸
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。

第三步:计算黑边填充数值
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。

此外,需要注意的是:
a.这里大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
c.为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
2)backbone
主要使用如下提升点:Focus结构,CSP结构
a.focus结构其实就是等同于YOLOV2 passthrough 层的那个ReOrg+Conv操作。
如下右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。 以Yolov5s的结构为例(5m等其他不同),原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
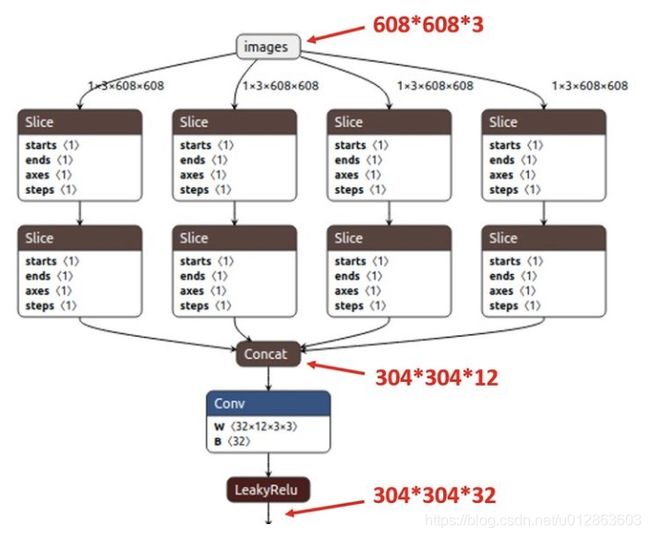
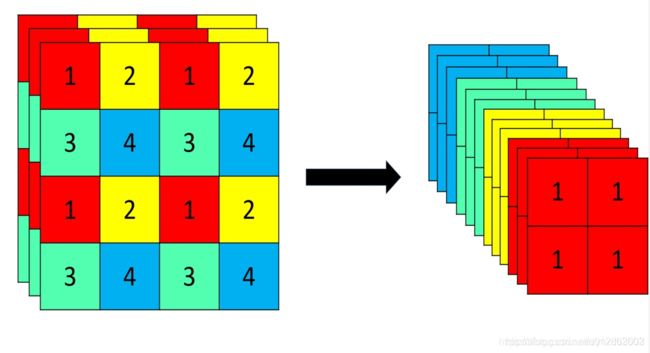
Focus的作用无非是使图片在下采样的过程中,不带来信息丢失的情况下,将W、H的信息集中到通道上, 再使用3 × 3的卷积对其进行特征提取,使得特征提取得更加的充分。虽然增加了一点点的计算量,但是为后续的特征提取保留了更完整的图片下采样信息。
b.csp结构
Cross Stage Partial Network(CSPNet)就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。最朴素的理解可以为跨block的shot cut连接,主要在检测模型上有提升,在分类模型上对比增加和没有增加该模块的resnxt50,top 1和top5几乎不变的情况下,运算量可以降低22%。
Yolov5中设计了两种CSP结构,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。位置见《主要思路》章节中的图。
3)neck & head
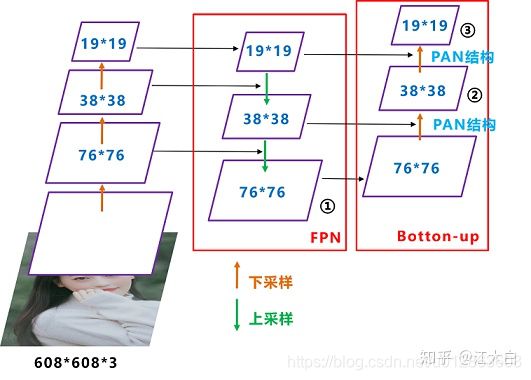
FPN+PAN结构
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,在FPN层的后面还添加了一个自底向上的特征金字塔。FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手。
4)loss function
主要分两点介绍:gt和anchor 的匹配策略;loss函数。
a. gt和anchor 的匹配策略
第一,Yolov5采用的是基于宽高比例的匹配策略。具体而言,对每一个groundtruth框,分别计算它与9种anchor的宽与宽的比值(较大的宽除以较小的宽,比值大于1,下面的高同样操作)、高与高的比值,在宽比值、高比值这2个比值中,取最大的一个比值,作为groundtruth框和anchor的比值,具体实现的伪代码为:max( anchor / groundtruth, groundtruth / anchor )。 得到groundtruth框和anchor的比值后,若这个比值小于设定的比值阈值,那么这个anchor就负责预测groundtruth框,这个anchor的预测框就被称为正样本,所有其它的预测框都是负样本,yolov5中没有忽略样本。
第二,正样本个数的增加策略,提升收敛速度。
yolov5共有3个预测分支(FPN、PAN结构),共有9种不同大小的anchor,每个预测分支上有3种不同大小的anchor。 Yolov5算法通过以下3种方法大幅增加正样本个数:
(1)跨预测分支预测:假设一个groundtruth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该groundtruth框,即一个groundtruth框可以由多个预测分支来预测。
(2)跨网格预测:假设一个groundtruth框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据groundtruth框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个groundtruth框可以由3个网格来预测;可以发现粗略估计正样本数相比前yolo系列,增加了三倍。
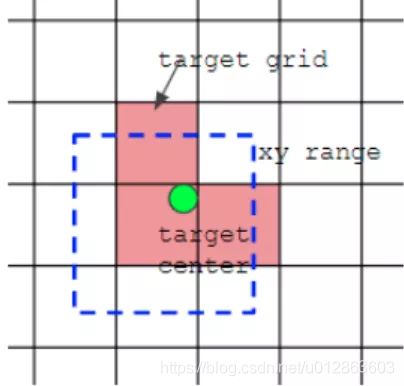
如上图所示,绿点表示该Bbox中心,现在需要额外考虑其2个最近的邻域网格也作为该bbox的正样本anchor。从这里就可以发现bbox的xy回归分支的取值范围不再是0~1,而是-0.5~1.5(0.5是网格中心偏移,请仔细思考为啥是这个范围),因为跨网格预测了。
(3)跨anchor预测:假设一个groundtruth框落在了某个预测分支的某个网格内,该网格具有3种不同大小anchor,若groundtruth可以和这3种anchor中的多种anchor匹配,则这些匹配的anchor都可以来预测该groundtruth框,即一个groundtruth框可以使用多种anchor来预测。
b.loss函数(具体见这篇博客 https://zhuanlan.zhihu.com/p/183838757 结合源码研究)
分为坐标损失(loss_giou)、目标置信度损失(loss_obj)和分类损失(loss_cls)三部分。其中目标置信度损失和分类损失采用BCEWithLogitsLoss(带log的二值交叉熵损失),坐标损失采用CIoU损失。虽然代码里面损失的变量名字写的是giou,但是通过看代码可以发现,其损失的代码实现中写了GIOU/DIOU/CIOU三种方法,默认情况下使用的是CIOU损失。 3个预测分支上的分类损失、坐标损失直接相加,得到总的分类损失和坐标损失,而3个预测分支上的目标置信度损失需要进行加权再相加,得到总的目标置信度损失,权中分别为[4.0, 1.0, 0.4],其中4.0是用在大特征图(预测小目标)上,所以,这里的加权,我认为是旨在提高小目标的检测精度。 最后将分类损失、坐标损失、置信度损失直接相加,得到一个总损失(每张图像的平均总损失),再乘以batch的大小,得到用于更新梯度的损失。
Giou, 由于IoU是 比值 的概念,对目标物体的scale是不敏感的。优化后如下公式:
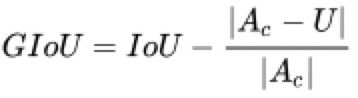
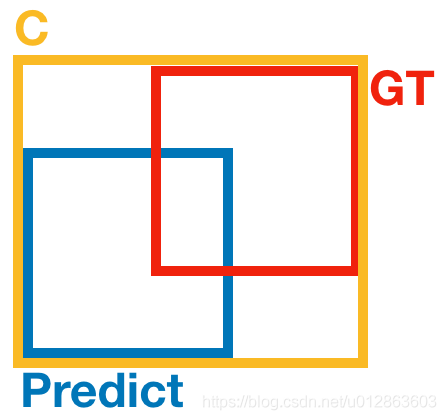
上面公式的意思是:先计算两个框的最小闭包区域面积Ac (通俗理解: 同时包含了预测框和真实框 的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。Ac即下图中的最外层框C。
5)trics
推理阶段,改NMS为加权nms(weighted nms)。
Traditional NMS每次迭代所选出的最大得分框未必是精确定位的,冗余框也有可能是定位良好的。那么与直接剔除机制不同,Weighted NMS顾名思义是对坐标加权平均,加权平均的对象包括 M 自身以及IoU≥NMS阈值的相邻框。

Weighted NMS通常能够获得更高的Precision和Recall,只要NMS阈值选取得当,Weighted NMS均能稳定提高AP与AR,无论是AP50还是AP75,也不论所使用的检测模型是什么。
4、结果
YOLO V5确实在对象检测方面的表现非常出色,尤其是YOLO V5s 模型140FPS的推理速度非常惊艳。
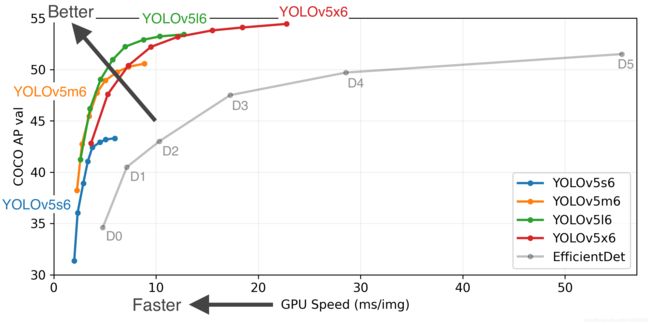
但是要注意,并非V4就真的很差,作者并没有正面的去使用同样的环境对比性能,根据网友的第三方测试,如下:
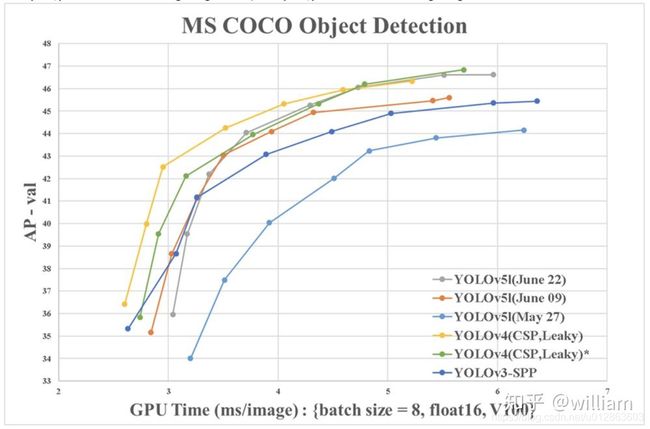
V4和V5的性能很接近,V4从数据上看精度更好,但是可定制化程度更高,并且目前网上多为三方版本,YOLOV5官方开源且持续更新,更适合快速工程部署,但是网友一致反馈,截止2020年底,代码的可读性非常差,在上面二次开发较困难。
V5比V4优点:
1)除了快速的上手,快速部署(内置tensor RT优化demo)。
2)还有一个好处就是训练时间短。对于Roboflow的自定义数据集,YOLO V4达到最大验证评估花了14个小时,而YOLO V5仅仅花了3.5个小时。个人猜测是由于其正样本的采样策略,加速模型收敛。
3)模型尺寸小。 V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB。
5、后续改进点:
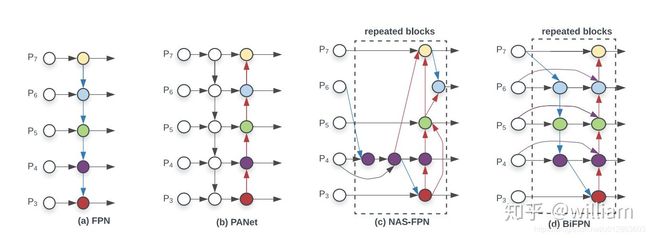
目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。
6、官方数据层面建议:
-
Images per class. ≥1.5k images per class
-
Instances per class. ≥10k instances (labeled objects) per class total
-
Image variety. Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.
-
Label consistency. All instances of all classes in all images must be labelled. Partial labelling will not work.
-
Label accuracy. Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.
-
Background images. Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). Background images added to a dataset do not require labels.
但是对于工业界,很多异常检测(包括工业质检以及审核等业务)很难满足官方说的每类大于1.5K张图片1W个框的样本量,也因此无法像官方那样只需要10%以内的单独背景图,还是需要通过推理具体业务场景图,将误杀的困难样本当做背景图训练。
参考链接:
1、v3 : https://blog.csdn.net/leviopku/article/details/82660381
2、V5的官方tips: https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results
3、 https://zhuanlan.zhihu.com/p/161083602
4、 https://zhuanlan.zhihu.com/p/172121380
5、 https://zhuanlan.zhihu.com/p/143747206
6、 https://zhuanlan.zhihu.com/p/334961642
7、 https://blog.csdn.net/chocv/article/details/117398749
8、 https://bbs.cvmart.net/articles/3462
9、 https://zhuanlan.zhihu.com/p/183838757
10、 https://zhuanlan.zhihu.com/p/151914931