论文阅读笔记 | 目标检测算法——PP-YOLOv2
如有错误,恳请指出。
文章目录
- 1. Introduction
- 2. Revisit PP-YOLO
-
- 2.1 Pre-Processing
- 2.2 Baseline Model
- 2.3 Training Schedule
- 3. Selection of Refinements
-
- 3.1 Path Aggregation Network
- 3.2 Mish Activation Function
- 3.3 Larger Input Size
- 3.4 IoU Aware Branch
- 4. Other try
-
- 4.1 Cosine Learning Rate Decay
- 4.2 Backbone Parameter Freezing
- 4.3 SiLU Activation Function
- 5. Result
paper:PP-YOLOv2: A Practical Object Detector
code:https://github.com/PaddlePaddle/PaddleDetection

摘要:
在PP-YOLO的基础上再进行了改进,提高精度的同时几乎保持推断时间不变。作者分析了一系列改进,并通过增量消融实验来实证评估它们对最终模型性能的影响。最后PP-YOLOv2取得了更佳的性能(49.5%mAP)-速度(69FPS)均衡,并优于YOLOv4与YOLOv5。
PP-YOLO阅读笔记:目标检测算法——PP-YOLO
1. Introduction
在各种实际应用中,不仅计算资源有限,而且软件支持不足,所以双阶段的目标检测进行的非常缓慢。所以如何在保持推理速度的同时提高YOLOv3的有效性是实际应用中的一个关键问题。为了同时满足这两个问题,作者添加了一些改进,这些改进几乎不会增加推断时间,从而提高PP-YOLO的整体性能。

2. Revisit PP-YOLO
2.1 Pre-Processing
应用从 B e t a ( α , β ) Beta(α, β) Beta(α,β)分布中采样的权重MixUp,其中 α = 1.5 , β = 1.5 α=1.5, β=1.5 α=1.5,β=1.5。
然后RandomColorDistortion、RandomExpand、RandCrop、RandomFlip以0.5的概率依次应用。
然后对RGB通道进行归一化处理。
最后,输入大小从[320,352,384,416,448,480,512,544,576,608]均匀抽取。
2.2 Baseline Model
基准模型是PP-YOLO,其是YOLOv3的改进版本,首先使用ResNet50-vd对YOLOv3的backbone进行替换,随后使用了10个技巧来提升性能。
具体查看:论文阅读笔记 | 目标检测算法——PP-YOLO
2.3 Training Schedule
在COCOtrain2017上,使用随机梯度下降(SGD)对网络进行训练,使用分布在8个gpu上的96张图像的小批量进行500K迭代。学习率在4K迭代时从0线性增加到0.005,在400K和450K迭代时分别除以10。重量衰减设为0.0005,动量设为0.9。采用梯度裁剪来稳定训练过程。
3. Selection of Refinements
PP-YOLOv2大致结构如图所示:
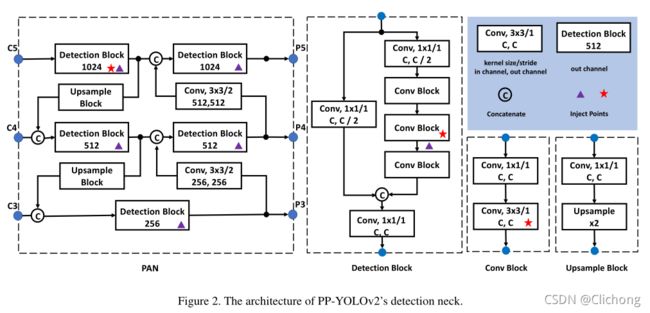
3.1 Path Aggregation Network
使用PAN代替FPN,多了一个自顶向下的信息汇集,之前多次提及,这里不再重复。
3.2 Mish Activation Function
Mish激活函数在YOLOv4、YOLOv5等多种实际的探测器中被证明是有效的。它们在骨干中采用mish激活功能。然而,作者更喜欢使用预先训练的参数,因为有一个强大的模型,在ImageNet上达到82.4%的top-1精度。为了保持主干不变,我们将mish激活函数应用于检测颈部而不是主干。
3.3 Larger Input Size
增加输入尺寸会扩大对象的面积。因此,小范围的目标信息将比以前更容易保存。因此,性能将得到提高。但是,较大的图像输入尺寸会占用更多的内存。要应用这个技巧,我们需要减少Batchsize。更具体地说,我们将Batchsize从每GPU 24张图像减少到每GPU 12张图像,并将最大输入尺寸从608扩大到768。
输入大小从[320、352、384、416、448、480、512、544、576、608、640、672、704、736、768]均匀绘制。
3.4 IoU Aware Branch
在PP-YOLO中,IoU aware loss采用的是软权重格式(soft weight format),与初衷不一致。因此作者采用软标签格式(soft label format)。公式为:
l o s s = − t ∗ log ( σ ( p ) ) − ( 1 − t ) ∗ log ( 1 − σ ( p ) ) loss = -t*\log(σ(p))-(1-t)*\log(1-σ(p)) loss=−t∗log(σ(p))−(1−t)∗log(1−σ(p))
其中t表示锚点和它匹配的ground-truth边界框之间的IoU,p是IoU感知分支的原始输出。ps:仅仅正样本的IoU损失进行了计算
IoU注意力的提出由来:
在YOLOv3中,将分类概率和目标得分相乘作为最终检测置信度,其中这没有考虑到定位精度。为了处理这个问题,论文中引入一个IoU预测分支。在训练过程中,使用感知IoU损失来训练这个分支。在推理阶段,最后的分类置信度由分类概率、目标分数和IoU值乘积得到。最终的检测置信度然后用作后续NMS的输入。
4. Other try
作者其实还尝试了其他的一些消融实验,但是没有效果,所以最后也没有使用这些技巧,这里还是记录一下比较好。
4.1 Cosine Learning Rate Decay
与线性步进学习率衰减不同,余弦学习率衰减是学习率的指数衰减。不过其对初始学习率、热身步数、结束学习率等超参数敏感,所以没有看见其对COCOtrain2017有一个积极影响。(但是对COCOminitrain产生了积极的作用)
4.2 Backbone Parameter Freezing
在对下游任务进行ImageNet预训练参数的微调时,通常会在前两个阶段冻结参数。然后这里同样是对COCOminitrain有效而对COCOtrain2017无效。
不一致现象的一个可能原因是两个训练集的大小不同,COCO minitrain2017是COCOtrain2017的五分之一。在小数据集上训练的参数的泛化能力可能比预先训练的参数差。
4.3 SiLU Activation Function
同样的SiLU,对COCOminitrain有效而对COCOtrain2017无效。所以使用Mish而不是SiLU。
5. Result
- 消融实验,各个在PP-YOLOv2中各个技巧带来的提升:

- 与SOTA的对比:

总结:
本文介绍了PP-YOLO的一些更新,形成了一个高性能的对象检测器PPYOLOv2。PP-YOLOv2比其他著名的探测器(如YOLOv4和YOLOv5)在速度和精度上取得了更好的平衡。在本文中,我们探索了一些技巧,并展示了如何将这些技巧结合到PPYOLO检测器上,并演示了它们的有效性。
总结,其实PP-YOLO系列几乎没有任何创新的,但通过实验结合技巧提升了检测性能。