学习总结——强化学习入门
近期参加了百度飞桨的零基础入门强化学习课程,经过7天的教学+实践的方式入门学习强化学习,从完成小项目的形式加深对强化学习一些概念和算法的理解和消化。在课程的最后,对整个课程做个简单的知识总结。
目录
- 强化学习(RL)
-
- 概念
- 学习方案
- 学习框架
- 基于表格型方法求解RL
-
- Sarsa
- Q-learning
- 区别对比
- 基于神经网络方法求解RL
-
- DQN算法
- 算法流程
- 基于策略梯度方法求解RL
-
- Policy Gradient 算法
- REINFORCE算法
- 连续动作空间上求解RL
-
- DDPG算法
- 优化网络
- 课后实战
-
- 环境描述
- 效果展示
强化学习(RL)
概念
强化学习(Reinforcement Learning),是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。

学习方案
强化学习有两种学习方案:基于价值(value-based)、基于策略(policy-based)

经典算法:Q-learning、Sarsa、DQN、Policy Gradient、A3C、DDPG、PPO
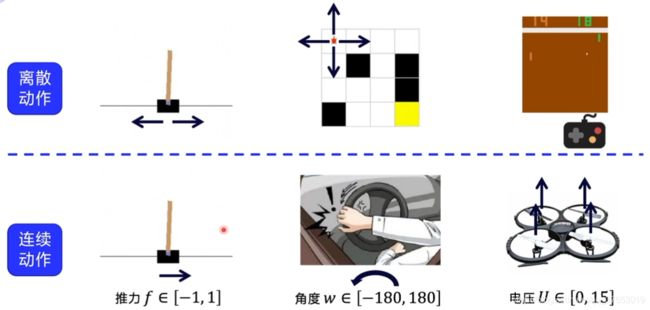
环境分类:离散控制场景(输出动作可数)、连续控制场景(输出动作值不可数)
学习框架
PARL(paddlepaddle Reinfocement Learning)是百度推出的基于PaddlePaddle(飞桨)的深度强化学习框架,具有可复用性强、扩展性好、支持大规模并行计算等优点。百度凭借PARL连续两年(2018、2019)在人工智能顶会NeurIPS的强化学习挑战赛上夺魁,足见其性能的强大。(附PARL的github链接)
基于表格型方法求解RL
Sarsa
Sarsa全称是state-action-reward-state’-action’(state’-action’分别表示下一个状态和行动),目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
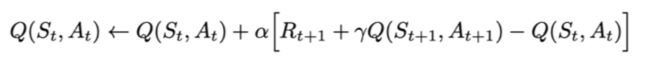
Q-learning
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。
Q-learning跟Sarsa不一样的地方是更新Q表格的方式。
Q-learning的更新公式为:
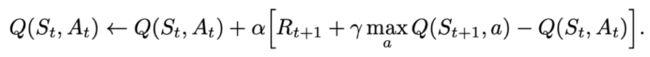
区别对比
Sarsa是on-policy的更新方式,先做出动作再更新。
Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。

On-policy策略:使用策略π学习,使用策略π与环境交互产生经验。(比喻:保守派)
Off-policy策略:行为策略μ和目标策略π分离,目标策略π用于学习最优策略,行为策略μ更具有探险性,与环境交互产生经验轨迹。(比喻:激进派)
基于神经网络方法求解RL
表格型方法存储的状态数量有限,而面对其他如围棋或机器人控制这类有数不清的状态和环境时,表格型方法在存储和查找效率上都受局限,为解决这一局限,利用神经网络来近似替代Q表格,下面以DQN算法为例做介绍。
DQN算法
DQN算法本质上还是一个Q-learning算法,更新方式一致,其使用神经网络的方法来替代Q表格输出。
DQN算法的两个创新点(使得Q网络的更新迭代更稳定):
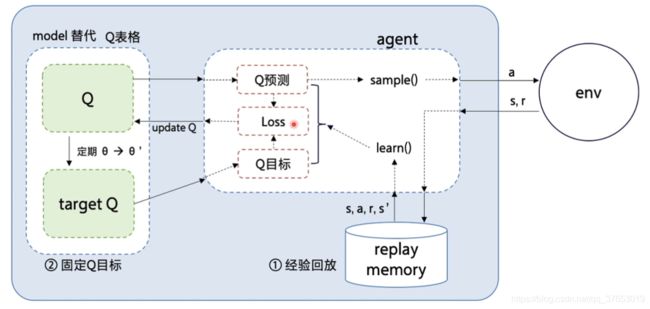
经验回放(Experience Replay):主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s’,再从中随机抽取一批数据送去训练。(战士去攻打城堡积累经验存储起来,军师根据经验选择战术更好地指导战士去攻打城堡)

固定Q目标(Fixed-Q-Target):主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值。(兔子活动性大,所以需要定期固定兔子作为没用活动性的靶子,然后以靶子为射击目标)
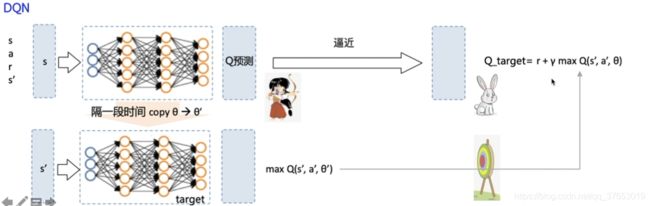
算法流程
基于策略梯度方法求解RL
前面讲到强化学习中有两种学习方案,前面几种都是基于值得方法,而这次是基于策略的方法,本节以Policy Gradient为例介绍基于策略方法去求解RL问题。
Policy Gradient 算法
Policy Gradient 算法是基于策略方法的经典代表,不同于基于值方法,它采用神经网络拟合策略函数,网络输出不是值,而是直接输出action的选择情况。
Policy Gradient优化的目标是在策略π(s,a)的期望回报:所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达。

优化策略网络需要计算策略梯度,优化目标对参数θ求导后得到策略梯度:
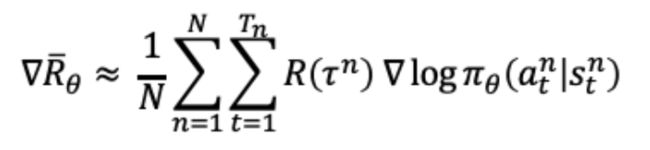
REINFORCE算法
注:1、G为每条state未来的总收益(由state计算得到)
2、算法中的梯度为每个action的梯度(由Loss和action计算)

连续动作空间上求解RL
本节介绍DDPG算法,以该算法为例介绍再连续动作空间上求解RL。
DDPG算法
DDPG的提出动机其实是为了让DQN可以扩展到连续的动作空间。
DDPG使用策略网络直接输出确定性动作。(离散动作输出为离散的数值,连续动作输出为连续的矢量值)
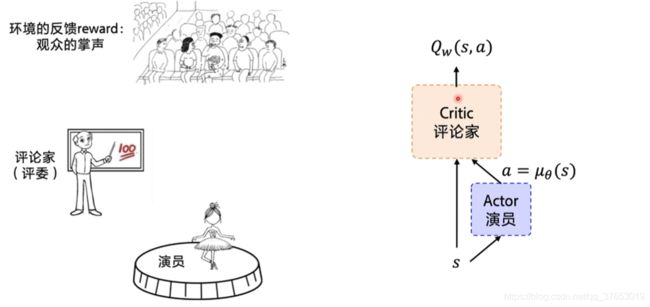
DDPG使用了Actor-Critic的架构(演员-评论家):
Actor网络(演员):演员根据舞台状况(state)作出反应(action)
Critic网络(评论家):评论家根据演员的表演(action)和舞台反应(state/reward)为演员打分
Actor网络优化:根据评论家的打分情况更新网络参数θ(争取下次更好的表现)
Critic网络优化:根据舞台观众的掌声(reward)调整打分的策略更新网络参数w(每一场能获得更多的掌声)
优化网络
DPG借鉴了DQN的两个技巧:经验回放 和 固定Q网络(稳定target)。

课后实战
环境描述
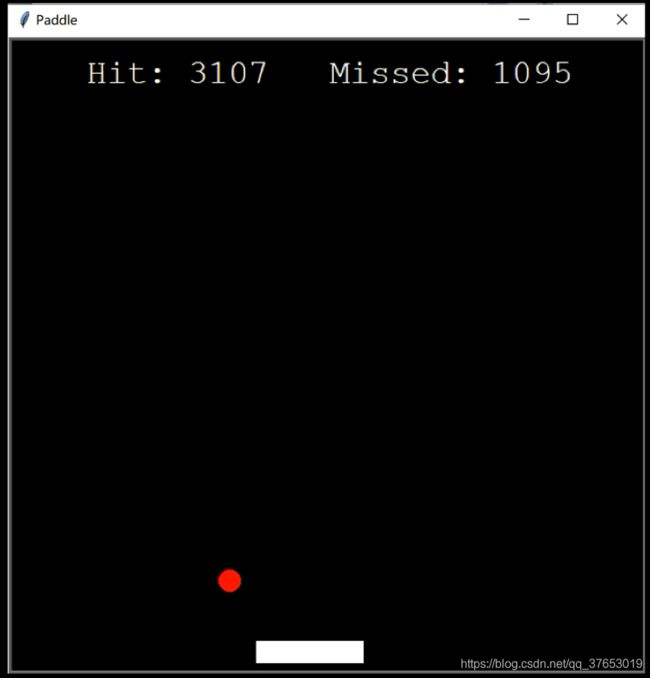
利用强化学习实现Paddle接球小游戏(附github链接)
动作空间(3):
| 动作 | 描述 |
|---|---|
| 0 | 桨向左移动 |
| 1 | 原地不动 |
| 2 | 桨向右移动 |
状态空间(5):
/桨的水平位置x/
/球的位置x和y/
/球在x和y方向上的速度/
奖励方式:
| 奖励 | 行为描述 |
|---|---|
| +3 | 桨成功接到球 |
| -3 | 桨未接到球 |
| -0.1 | 桨的每一次移动 |
效果展示
利用强化学习让桨有根据小球的位置拥有自动接球的能力。
ps:做下简单的实践尝试,本人能力不足,最后成绩不是很理想,各位见笑了。
下图是小球训练过程的效果图():