卷积层,池化层,全连接层,BN层,还有Dropout层
— 卷积层
1.目前值得关注卷积新操作: 参考链接
2.卷积的计算:
上面提到了用1 * 1的卷积的好处,可以减少参数达到同样的效果,首先要先了解卷积的参数计算。首先是我们的卷积层的定义一般有卷积核的大小和输入的深度以及想输出的深度。具体操作呢?就是假设我们用1010256的输入,我们用11的去做处理,假设输出64深度,那我们应该表达成为我们用了64个11256的卷积组去做卷积操作。最后我们得到的就是101064。如果使用33的话,那么应该表达为我们用了64个3*3的卷积组去做卷积。这才能体现出来我们卷积是左右上下的操作联合,其实就是一种局部的全连接,这也是为什么我们可以用全卷积去替代全连接。这一部分的操作会体现在我们OCR部分,所以说OCR的时候我们会在强调一下。
所以我们的卷积的参数计算就是HWinput*output
卷积的大小计算呢?
输出的大小与是否填充,填充数量以及步长有关。

3.卷积层的反向传播 :
可以参考我的另一篇文章,这里不做详细的分析。
4.卷积的python复现
https://zhuanlan.zhihu.com/p/40951745
https://zhuanlan.zhihu.com/p/33802329
—池化层
池化层的操作:最大就是去最大,平均就是取平均,减少计算的参数,一定程度上可以防止过拟合,提高模型的鲁棒性。

池化层如何做反向传播 ,只做梯度的传递,而不做其他的改变 参考链接
全连接层:
https://www.zhihu.com/question/41037974/answer/150522307 全连接层的知乎
一文看懂了全连接
全连接的层的作用:
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
想想将这么多的东西整合到一个点上,想想是不是很实在。这个点对应的前面的卷积层哪些特征会得到保留,哪些特征没有得到保留都是在全连接层这里做到了处理,然后最后输出。比如其中一个类的177512,这个类他会屏蔽哪些卷积层的特征呢?这就看这个177512怎么去操作了。所以从卷积替代全连接的过程,我们可以更加清楚,全连接层的关键作用。
1.为什么说全连接的参数多,卷积如何替代全连接的:
7x7x512的输出,为了的得到4096的全连接点,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程。就是说为了得到4096个全连接点,我们需要将上面的前后左右进行规整,所以就需要4096个77512的卷积组,这样可以得到这么多个点。
以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filtersize = 7, padding = 0, stride = 1, D_in = 512, D_out =4096”
经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1,padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
-用pytorch的简单全连接层实现全连接层
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
-用自适应层实现全连接层:
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
全局平均池化层:通过降低模型的参数数量来最小化过拟合效应。类似最大池化层,GAP层可以用来降低三维张量的空间维度。通过GAP 可以将你的特征图降低到你想要的大小,而这里如果是用作替代全连接的作用的话就是 :一个h × w × d的张量会被降维至1 × 1 × d。GAP层通过取平均值映射每个h × w的特征映射至单个数字。但这样可能会导致信息的损失。
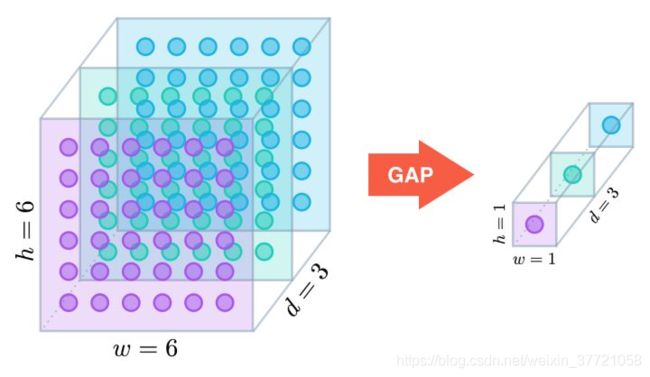
在最早使用GAP的网络结构中,最大池化层的输出传入到了GAP层中,GAP层生成一个向量,这个向量相当于全连接层,起到了前面讲的分类作用。接着应用softmax激活函数生成每个分类的预测概率。好吧,你是全连接没错了。而在我接触的模型中有个resnet50. ResNet-50模型没这么激进;并没有完全移除密集层,而是在GAP层之后加上一个带softmax激活函数的密集层,生成预测分类。即使用了自适应平均池化层,由于没有参数的学习,所以也是会丢失信息的。

注意,和VGG-16模型不同,并非大部分可训练参数都位于网络最顶上的全连接层中。网络最后的Activation、AveragePooling2D、Dense层是我们最感兴趣的(上图高亮部分)。实际上AveragePooling2D层是一个GAP层!我们从Activation层开始。这一层包含2048个7 × 7维的激活映射。让我们用fk表示第k个激活映射,其中k ∈{1,…,2048}。
接下来的AceragePooling2D层,也就是GAP层,通过取每个激活映射的平均值,将前一层的输出大小降至(1,1,2048)。接下来的Flatten层只不过是扁平化输入,没有导致之前GAP层中包含信息的任何变动。
原来计算复杂度高的全连接层替换成global average pooling,运算量大大减少。
全连接的新反思
全连接层与attention层的不同
上面这篇文章是今天看一篇叫做yolonano的文章看到的操作,里面有一个全连接注意力机制的使用,和这篇文章很像的全连接很像,就是让模型去关注自己应该学习的特征。从而提高模型的学习效率
yolonano的文章
归一化层中的BN层
BN层的参考链接1
BN层的参考链接2
Dropout层 —
https://blog.csdn.net/weixin_37721058/article/details/101127960
if dropout_p is not None:
layers.append(nn.Dropout(p=dropout_p))
input_dim = dim