Sketch Your Own GAN
使用绘制的草图,来控制 GAN 生成图像的形状等特征。具体使用的方法很简单,即用真实图像→草图的 GAN 来微调预训练的噪声→真实图像的 GAN 模型,即草图+预训练网络 G→调整后网络 G',最终实现噪声→带有草图外形特征的真实图像,调整后的网络同时保持预训练网络的生成真实性与多样性,以及输入噪声在原模型中代表的颜色、纹理、背景等特征。
Sketch Your Own GAN (peterwang512.github.io)
GitHub - PeterWang512/GANSketching: Sketch Your Own GAN: Customizing a GAN model with hand-drawn sketches.
参考: 用草图控制 GAN 生成的图像特征——朱俊彦 ICCV 论文 Sketch Your Own GAN 解读 - 知乎

Abstract
用户可以通过勾画一个简单的草图来创建深层次的生成模型吗?传统上,创建GAN模型需要收集大规模的样本数据集和深度学习的专业知识。相比之下,草图可能是传达视觉概念的最普遍的方式。在这项工作中,我们提出了一种方法,GAN草图,以重写一个或多个草图的GANs,使新手用户更容易训练GANs。特别地,我们根据用户草图改变原始GAN模型的权值。我们鼓励模型的输出通过跨领域的对抗损失来匹配用户草图。此外,我们探索了不同的正则化方法来保持原始模型的多样性和图像质量。实验表明,我们的方法可以在保持真实感和多样性的同时,匹配草图指定的形状和姿势。最后,我们演示了生成GAN的一些应用,包括潜在空间插值和图像编辑。
1. Introduction
像GANs[20]这样的深层生成模型的潜力和前景在于,它们能够以最小的努力合成无穷无尽的真实、多样和新颖的内容。由于近年来大规模生成模型的质量和分辨率的提高,这些模型的潜在效用不断增长[31,7,53,51]。
尽管如此,高质量生成模型的训练需要高性能的计算平台,这使得大多数用户无法实现这一过程。此外,训练一个高质量的模型需要昂贵的大规模数据收集和仔细的预处理。常用的数据集如ImageNet[13]和LSUN[69]需要人工标注和人工过滤。FFHQ专用人脸数据集[30]需要精细的人脸对齐和超分辨率预处理。此外,技术上的努力也不是微不足道的:开发一个高性能生成模型需要专家团队的领域知识[56,31],这些专家经常在特定数据集的单个模型上投入数月或数年的时间。
这就引出了一个问题:普通用户如何创建他们自己的生成模型?用户在创作带有猫的艺术作品时,可能不想要一个普通的猫模型,而是想要一个定制的特殊猫模型,以特定的期望姿势:靠近、斜倚或都向左看。要获得这样一个定制的模型,用户必须策划成千上万张倾斜的左眼猫的图像,然后找到一个专家,投入几个月的时间在模型训练和参数调整?
在本文中,我们提出的任务,从仅仅几个手绘草图创建一个生成模型。自从Ivan Sutherland的SketchPad[62]以来,计算机科学家已经认识到使用草图引导计算机生成内容的有用性。这一传统在基于草图的图像合成和三维建模领域中得以延续[27,11,28]。但是,与其从草图中创建单个图像或3D形状,我们希望了解是否有可能从手绘草图中创建现实图像的生成模型。与基于草图的内容创建不同,在这里输入和输出都是2D或3D视觉数据,在我们的例子中,输入是一个2D草图,输出是一个包含数百万个不透明参数的网络,这些参数控制算法行为以生成图像。我们问:对于这样一个不同的输出域,我们应该更新哪些参数,如何更新?我们如何知道模型的输出是否与用户草图相似?
在本文中,我们的目标是通过开发一种方法来根据用户提供的少量草图范例定制生成模型来回答上述问题。为了实现这一点,我们利用了在大规模数据上预先训练的现成生成模型,并设计了一种方法来调整模型权重子集以匹配用户草图。我们提出了一种新的跨域模型微调方法,鼓励新模型的创建是类似于用户草图的图像,同时保留原始模型的颜色、纹理和背景上下文。如图1所示,我们的方法只需要四张手绘草图就可以改变物体的姿势并放大猫的脸。
我们使用我们的方法创建了几个新的自定义GAN模型,我们展示了这些修改后的模型可以用于几个应用程序,如生成新的样本,在两个生成的图像之间的插值,以及编辑自然照片。我们的方法需要最少的用户输入。用户无需通过手动过滤和图像对齐来收集新数据集,只需为我们的方法提供一个或几个示例草图即可有效地工作。最后,我们对我们的方法进行基准测试,以充分表征其性能。代码和模型也可以在我们的网页上找到。
3. Methods
两个限制因素使得从用户草图创建GAN模型具有挑战性。首先,因为我们的目标是简化用户对生成模型的创建,所以我们必须只使用非常少量的用户提供的草图数据。要求用户提供成百上千张草图是不合理的;相反,我们的目标是能够用很少的一张草图来创建一个模型。
其次,由于我们的目标是合成逼真的图像,而不要求用户创建逼真的图像,因此用户提供的草图不是从目标域绘制的。这种训练数据(即草图)与模型输出(即图像)的不匹配使得我们的问题设置与传统GAN训练目标(即直接匹配训练数据)有很大的不同。在我们的设置中,目标是创建一个真实的照片模型,其中的形状和姿势是由草图指导的——但输出的是真实的图像,而不是草图。
为了克服上述挑战,我们使用域转换网络并引入了跨域对抗损失(章节3.1)。不幸的是,仅仅使用这种损失就会极大地改变模型的行为并产生不现实的结果。为了保留原始数据集的内容及其多样性,我们在应用图像空间正则化的同时进一步训练模型(章节3.2)。最后,为了缓解模型过拟合,我们将更新限制在特定的层,并在3.3节中使用数据增强。
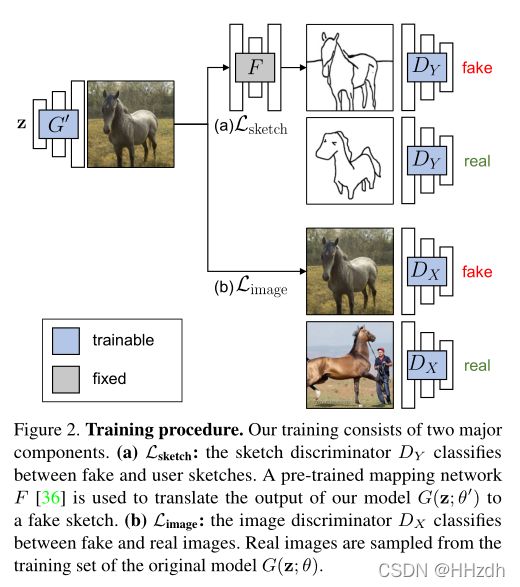
3.1. Cross-Domain Adversarial Learning

根据定义,预训练网络 ![]() 应满足可以由低维噪声z生成域
应满足可以由低维噪声z生成域 中符合
中符合![]() 分布的图片,根据先前的 GAN 训练技术可以较容易地达到这个目标。
分布的图片,根据先前的 GAN 训练技术可以较容易地达到这个目标。
而我们想要目标网络 ![]() 满足由低维噪声z生成域中符合
满足由低维噪声z生成域中符合![]() 分布的图片,并且产生的图片需要具有域
分布的图片,并且产生的图片需要具有域  中符合
中符合![]() 分布的一些特征(及形状与姿态)。
分布的一些特征(及形状与姿态)。
为了达到这个目标,我们需要引入另一个预训练网络: ![]() ,即可以将真实图片转化为对应草图的预训练网络。在已有技术下,这个网络无论是在配对样本(如 pixel2pixel),还是无配对样本(如 Cycle-GAN)的情况下都可以实现。在本文中,作者选取了Photosketch作为预训练的 。文章引入的 Cross-Domain Adversarial Learning 鼓励
,即可以将真实图片转化为对应草图的预训练网络。在已有技术下,这个网络无论是在配对样本(如 pixel2pixel),还是无配对样本(如 Cycle-GAN)的情况下都可以实现。在本文中,作者选取了Photosketch作为预训练的 。文章引入的 Cross-Domain Adversarial Learning 鼓励![]() 生成的图片与域中给定的分布
生成的图片与域中给定的分布![]() 相匹配。具体实现如下:
相匹配。具体实现如下:
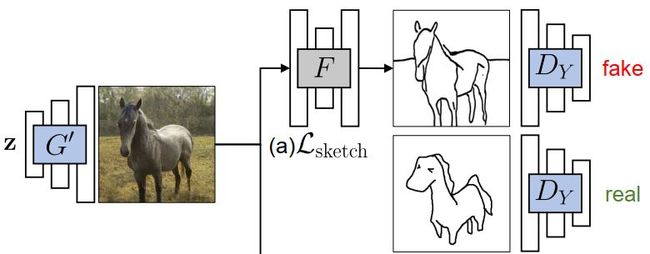
将G'生成的图片丢入F,生成的草图丢入![]() ,损失函数为:
,损失函数为:
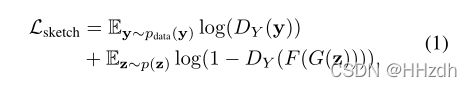
即,使得 ![]() 的分布与
的分布与![]() 尽可能接近。
尽可能接近。
3.2. Image Space Regularization
我们观察到,仅在草图上使用损失会导致图像质量和生成多样性的急剧下降,因为这种损失只会强制生成的图像的形状与草图匹配。(因为只要求生成图片与![]() 中的特征相近)。为了解决这个问题,我们添加了第二个对抗损失,将输出与原始模型的训练集进行比较。
中的特征相近)。为了解决这个问题,我们添加了第二个对抗损失,将输出与原始模型的训练集进行比较。

在匹配用户草图的同时,使用单独的鉴别器![]() 来保持图像质量和模型输出的多样性。
来保持图像质量和模型输出的多样性。
这个 Regularization 的作用就是鼓励![]() 与分布
与分布 ![]() 相匹配,提高生成的图片真实性和多样性。
相匹配,提高生成的图片真实性和多样性。
3.3. Optimization
总损失函数为:
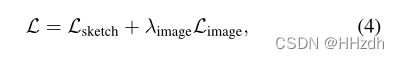
优化目标为:
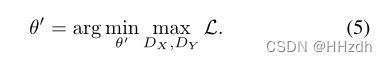
Which layers to edit.为了防止过拟合并加速优化,我们对 Generator 要调整的层进行了限制,具体只调整 StyleGAN2中的 mapping network。
4. Experiments
