kubernetes之Pod、控制器介绍
pod介绍
1、pod是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元
2、只要运行pod就会产生名称为pause的容器
3、在同一个pod中多个容器共享pause的协议栈(即同一个pod中的其中一个容器访问另一个容器时,可以通过pause的网络回环访问localhots:端口),
所以在同一个Pod中不能存在端口冲突。
4、pod与pod之间访问,当在同一台机器时,使用Docker0网桥直接转发请求。
5、pod控制器:Deployment、ReplicaSet
Deployment不负责pod创建,Deployment创建完成后就会创建ReplicaSet,RS创建完成后会创建pod
pod的生命周期
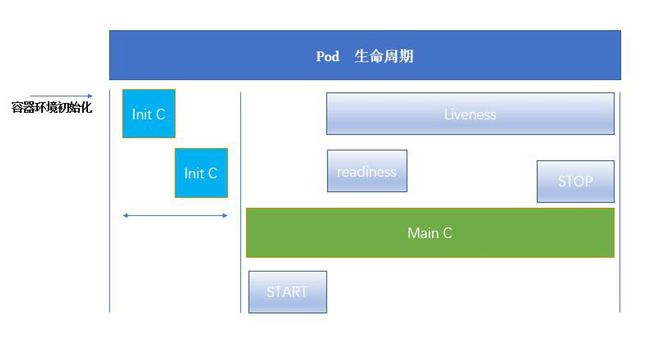
过程:
1、kubectl向apiservice传递指令,apiservice调度kubelet(中间过程由etcd完成持久化),kubelet操作CRI完成容器的初始化。
初始化过程中启动pause的基础容器。
2、只有当yaml文件中存在initContainers配置时,才有initC的过程,如果没有,直接跳过启动MainC。
3、单个或多个InitC的初始化,InitC初始化不能并行,只有当一个InitC初始化完成后,另一个InitC才能开始初始化。
InitC初始化完成后会自动退出,所以在initC中不会出现端口重复的现象,如果不能成功初始化,会删除pause,重新启动整个Pod。
4、只有当InitC的初始化完成后,进入MainC主容器,由于共享pause的网络栈,所以MainC中不能存在两个使用相同端口的容器。
主容器中如果存在readiness(探针)检测,只有当readiness检测完成后,容器的Ready属性直接变为Ready.
如果不存在就绪探测,当initC初始化完成后,容器的Ready属性才会变为Ready.
liveness会伴随MainC的生命周期,当Liveness检测MainC中的进程出现异常时,会执行对应的重启或删除命令。
initC模板
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mycontainer
image: busybox:1.34.1
command: ['sh','-c','echo pod is running! && sleep 3600']
initContainers:
- name: initcontainer
image: busybox:1.34.1
#直到解析到mediaplus-mysql域名后退出
#只要在集群中创建了对应的svc,svc的名称就会默认在dns插件中解析成ip地址
command: ['sh','-c','until nslookup mediaplus-mysql; do echo waiting for mediaplus-mysql; sleep 3; done;']
$ kubectl create -f pod.yaml
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
mypod 0/1 Init:0/1 0 94s
$ kubectl logs mypod -c initcontainer
Server: 241.254.0.10
Address: 241.254.0.10:53
** server can't find mediaplus-mysql.default.svc.cluster.local: NXDOMAIN
*** Can't find mediaplus-mysql.svc.cluster.local: No answer
*** Can't find mediaplus-mysql.cluster.local: No answer
*** Can't find mediaplus-mysql.localdomain: No answer
*** Can't find mediaplus-mysql.default.svc.cluster.local: No answer
*** Can't find mediaplus-mysql.svc.cluster.local: No answer
*** Can't find mediaplus-mysql.cluster.local: No answer
*** Can't find mediaplus-mysql.localdomain: No answer
waiting for mediaplus-mysql
由于没有对应的svc服务,pod的初始化无法完成,对应上述第三点
apiVersion: v1
kind: Service
metadata:
name: mediaplus-mysql
labels:
app: mediaplus-mysql
spec:
type: NodePort
ports:
- port: 3306
nodePort: 30006
$ kubectl create -f service.yaml
service/mediaplus-mysql created
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE
mypod 1/1 Running 0 5m53s
活性探测模板
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mycontainner
image: busybox:1.34.1
command: ['sh','-c','echo pod is running! && sleep 3600']
#就绪探测
readinessProbe :
#容器启动后多久开始探测,单位s
initialDelaySeconds: 10
#多长时间判断为超时,单位s
timeoutSeconds: 3
#探测间隔时间,单位s
periodSeconds: 10
#如果容器之前探测成功,后续连续几次探测失败,则确定容器未就绪
failureThreshold: 2
#如果容器之前探测失败,后续连续几次探测,则确定容器就绪
successThreshold: 2
httpGet:
port: web
path: /login.jsp?inner=1
#存活探测
livenessProbe:
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 10
failureThreshold: 2
httpGet:
port: web
path: /login.jsp?inner=1
$ kubectl create -f pod.yaml
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
mypod 0/1 Running 0 5m48s
由于就绪探测没有完成,所以Pod的Ready一直就无法就绪,对应上述第四点
控制器
无状态服务
通用型:
ReplicationController:确保Pod的副本期望值
ReplicationSet:与rc类似,支持集合式selector
Deployment:支持滚动更新。但是deployment不直接创建pod,它会创建RS,由RS创建pod
特殊场景:
HPA:Pod自动扩容缩,依赖于rs、deployment控制器,不具备pod的创建能力
Job:批处理任务一次或多次成功
Crontab Job:定时执行Job批处理任务一次或多次成功
DaemonSet:在每个node上运行有且只有一个Pod
有状态服务
statefulset

RS与Deployment
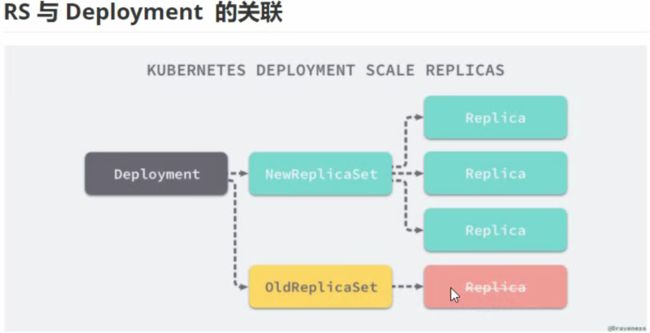
Pod与Deployment关联
两者之间通过标签关联,spec.template.metadata.labels为pod打上名为mediaplus-main的标签。
Deployment的spec.selector.matchLabels需要与spec.template.metadata.labels值一致
apiVersion: apps/v1
kind: Deployment
metadata:
name: mediaplus-main
spec:
replicas: 1
selector:
matchLabels:
app: mediaplus-main
template:
metadata:
labels:
app: mediaplus-main
spec:
containers:
- name: mediaplus-main
....
● 扩容与删除
#创建nginx-deployment --record参数可查看Deployment revision(kubectl rollback history)变化
kubectl apply -f nginx-deployment.yaml --record
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 29h
kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-7bf9547bd6 1 1 1 29h
#nginx-deployment详细信息
kubectl describe deployment nginx-deployment
#扩容
kubectl scale deployment nginx-deployment --replicas 3
#删除
kubectl delete deployment nginx-deployment
● 升级与回滚:当升级pod镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本
#更新nginx镜像
kubectl set image deployment/nginx-deployment(deployment名) nginx(容器名)=nginx:1.19.1
#会创建新的RS,会将旧的RS上的pod删除,在新的RS上创建pod
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-7bf9547bd6 0 0 0 4m45s
nginx-deployment-d4544f9cb 2 2 2 106s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-d4544f9cb-4fxv4 1/1 Running 0 82s
nginx-deployment-d4544f9cb-prr46 1/1 Running 0 84s
#回滚到上一个版本镜像
$ kubectl rollout undo deployment/nginx-deployment
#回滚到指定版本
$ kubectl rollout undo deployment/nginx-deployment --to-revision=3
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-7bf9547bd6 2 2 2 5m56s
nginx-deployment-d4544f9cb 0 0 0 2m57s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-7bf9547bd6-5xh5d 1/1 Running 0 7s
nginx-deployment-7bf9547bd6-nzh5q 1/1 Running 0 9s
● 版本记录: 每一次对Deployment的操作,都能保存下来,给予后续可能的回滚使用
#检查下 Deployment 的 revision:
$ kubectl rollout history deployment/nginx-deployment
deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
2 kubectl apply --filename=nginx-deployment.yaml --record=true nginx:1.19.1
3 kubectl apply --filename=nginx-deployment.yaml --record=true nginx:1.15.9
#有两个版本的更新,因为我创建 Deployment 的时候使用了`--record`参数可以记录命令,我们可以很方便的查看每次 revision 的变化.
#查看单个revision 的详细信息:
$ kubectl rollout history deployment/nginx-deployment --revision=2
deployment.apps/nginx-deployment with revision #2
Pod Template:
Labels: app=nginx
pod-template-hash=d4544f9cb
Annotations: kubernetes.io/change-cause: kubectl apply --filename=nginx-deployment.yaml --record=true
Containers:
nginx:
Image: nginx:1.19.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
● 暂停和启动:对于每一次升级,都能够随时暂停和启动。
#暂停
$ kubectl rollout pause deployment/nginx-deployment
#继续
$ kubectl rollout resume deployment/nginx-deployment


apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: maqing:v1
restartPolicy: Never


apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.34.1
args: ["/bin/sh","-c","date; echo Hello from the Kubernetes cluster"]
restartPolicy: OnFailure
$ kubectl get cronjob,job,pod
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/hello */1 * * * * False 0 47s 4m47s
NAME COMPLETIONS DURATION AGE
job.batch/hello-1649585040 1/1 2s 2m45s
job.batch/hello-1649585100 1/1 2s 105s
job.batch/hello-1649585160 1/1 2s 45s
NAME READY STATUS RESTARTS AGE
pod/hello-1649585040-5qskg 0/1 Completed 0 2m45s
pod/hello-1649585100-g6g6q 0/1 Completed 0 105s
pod/hello-1649585160-npdsh 0/1 Completed 0 45s
$ kubectl logs pod/hello-1649585400-npdsh
Sun Apr 10 10:10:04 UTC 2022
Hello from the Kubernetes cluster
