大数据分析笔记 (6) - 文本分析 (Text Analysis)
大数据分析笔记 - 文本分析
- 总览
- 文本分析步骤
- 挑战
- 第一步:收集原始文本数据(Collecting Raw Text)
- 第二步:表示文本 (Representing Text)
- 第三步:词频-逆文档频率(TFIDF - Term Frequency - Inverse Document Frequency)
-
- 词频 (Term Frequency)
- Term Frequency 问题
- 词语的文档频率 (Document Frequency of a term)
- 逆文档频率 (Inverse Document Frequency)
- TFIDF
- 第四步:主题建模(Topic Modelling)
-
- 流程
- 主题(topic)
- LDA
-
- LDA流程
- 算法
- 注意事项
- 应用
- 情感分析 (Sentiment Analysis)
- 获得结果(gaining insights)
-
- 词云(word cloud)
总览
文本分析指对文本数据进行表示 (representation),处理(processing)和建模(modeling)来获得有用的见解(insight)。
文本分析的一个挑战是高维度(high dimensionality)。
语料库: 指在自然语言处理中用于各种目的的大量文本(文档)集合。
另一个挑战是: 大多数情况下文本是非结构化数据(not structured)。
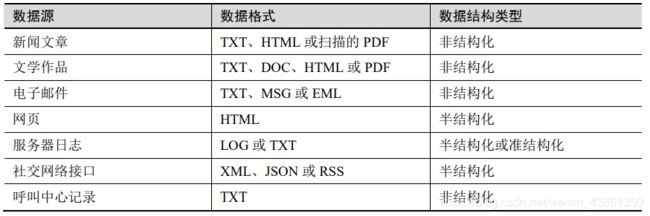
文本分析步骤
- 句法分析(Parsing): 是指处理非结构化文本使其具有一定的结构,供将来分析的过程。句法分析将文本进行解构,然后以一种更为结构化的方式来呈现。(unsturctured -> sturctured)
- 搜索和检索 (Search and retrieval): 在一个语料库中识别包含例如特殊单词,短语,主题或者实体(如人或组织)等搜索项(search items)的文档。这些搜索项通常称为关键术语 (key term)。
- 文本挖掘 (text mining): 指使用前两步产生的术语和索引来发现与感兴趣领域或问题相关的有意义的见解(discover meaningful insights)。
聚类(clustering) 和 分类 (classification) 都可以应用于文本挖掘。比如:将文档聚化成簇 或者 分类文本以进行情感分析(sentiment analysis)。
文本挖掘可以利用来自各个研究领域的方法和技术,如统计分析(statistical analysis),信息检索(information retrieval),数据挖掘(data mining)和自然语言处理(natural language processing)等。
挑战
- 语法(syntax): 涉及句子结构和语法规则。
- 语义(semantics): 是对句子含义的研究。
- 语用(pragmatic): 关注特定上下文中句子的含义。
- 同义词(homonyms): 具有相同拼写但含义不同的单词。
- 缩写词(acronyms): 是单词的缩写形式。
对于计算机来说,文本只是编码和数字的字符序列(sequence of characters)。它不了解语法,语义(semantic meanings)和其实用含义(pragmatic meaning)。
同时,在原始形式中,单词或者文本之间没有自然相似性度量(nature similarity metric)。(因此难以执行聚类或分类)
因此,我们需要以适合用于聚类和分类的形式来表示和处理文本。
第一步:收集原始文本数据(Collecting Raw Text)
对于文本分析来说,进行任何事情之前必须先收集数据。
- 可以在许多网站上对用户生成的内容(user-generated contents)开始积极的监控。(可以使用公开的API, 网页爬虫 web scraper/crawler)
- 准备处理非结构化或者半结构化数据。
第二步:表示文本 (Representing Text)
使用文本规范化的技术(text normalization techniques)对原始文本进行转化。
- 分词 (tokenization): 指从文本正文中分离(也叫做标记)单词 (seperating words)。
- 按空格(spaces)来分词。(可能会把标点符号也给分出来,比如 day. )
- 基于标点符号和空格来分词 (可能会把 we’ll, can’t, state-of-the-art 等直接分开)
- 分词比想象中更困难 (résumé 和 resume)
没有一个分词器适用于每一种情形(no one-size-fits-all)。
-
大小写转换 (case folding): 将所有的字母都变成小写(或者都变成大写)。
- 但是在一些情况下可能会出错: 如专有名词,缩写,公司名等(General Motors; WHO; US;)
- 减少错误的方法是对不进行大小写转换的单词建立一个查找表(lookup table)。
-
停止词(stop word): 在给定语言中,并非所有的单词都需要被考虑。(比如:the, a, of, and, to等这些不太可能有助于语义的理解)
-
词根法(Lemmatization)和词干法(Stemming): 词根法看单词的意义(如: Goose, geese, goose, gander, ganders)。词干法看单词的组成(如:walk, walking, Walk, walks, walked)。最受欢迎的是"Porter stemmer", “WordNet”。
-
词袋法(Bag-of-words representation): 将文档转化成高维向量(high-dimensional vector),向量指示了文档中各个单词的 存在/不存在/出现频率(presence/absence/frequency)。

词袋法足够简单(朴素且过分简化问题 naive and over-simplified) 并被广泛应用于文本分析问题中 (是入门的好方法)。其将文档表示为一组词语(单词),而忽略了其他信息(如顺序 order,上下文 context,推论 inferences和语义 semantics)。比如,“a dog bites a man” 和 "a man bites a dog"意思完全不同但是他们在词袋法里是同一种表示。 -
语料库的表示(Representation of a corpus): 语料库可以大到包括一种或者多种语言的所有文档,也可以小到仅限于特定领域(focused on a specific domains)。
大多数语料库都具有元数据,比如语料库的大小以及文本提取的领域。某些语料库包含了文本中出现的每个词的信息内容(Information content, IC)。信息内容是用来表示语料库中词语重要性(importance of a term)的度量。IC值较高的词语的重要性要比IC值较低的词语高。
然而,信息内容无法满足分析动态改变的非结构化数据的需求。问题:传统语料库和IC元数据都无法随着时间改变,因此任何语料库中不存在的词汇和任何新发明的词汇都会自动得到0的IC值。其次,传统语料库限制了用于文本分析算法 (text analysis algorithm) 的全部知识(语料库代表了整个知识库)。
第三步:词频-逆文档频率(TFIDF - Term Frequency - Inverse Document Frequency)
词频 (Term Frequency)
我们需要一个适应文本上下文(context)和性质(nature)的度量标准 metric (不像IC一样)。
TFIDF直接作用于所有获取的文档(fetched documents)。一旦获取的文档发生更改,TFIDF可以被轻松更新。TFIDF是一种广泛用于文本分析的措施。TFIDF对动态内容的处理也是相当强大且有效的,因为文档的变化只需要更新频率计数。
给定一个单词 t 以及一个包含 n 个词的文档 d = {t1, t2, …, tn}。在 d 中 t 最简单的词频形式可以定义为 t 在 d 中出现的次数。

可以对词频函数取对数,以获得更多数据细节。
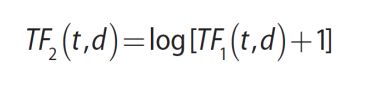
对于长文档,因为其包含的词语数量和种类多,因此往往有更高的词频值。这些因素导致了长文档的词频值的提升,以至于人们对长文档产生了偏见。为了解决这个问题,可以对词频进行规范化。

Zipf’s Law:第 i 个最常见的单词出现在最常见词的 1/i 处。
Term Frequency 问题
词语的重要性仅取决于其在特定文档中的存在。如果该词语频繁出现在每个文档中怎么办?这个词还重要吗?我们需要拓宽我们的视野,不仅要在单个文档中,而是要在整个语料库中考虑一个词语的重要性。
词语的文档频率 (Document Frequency of a term)
文档频率被定义为语料库中包含一个词语的文档的数目。假设语料库D包含N个文档。语料库D={d1, d2, …, dn}中词语 t 的文档频率的定义为:

逆文档频率 (Inverse Document Frequency)
逆文档频率的定义,N代表了语料库的总文档数,DF(t) 代表单词 t 的文档频率。逆文档频率就是他们的商取对数得到。
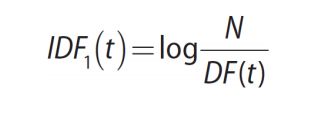
如果词语不在语料库内,会导致分母为零,快速解决的方法是在分母上加个1。

拥有较高IDF的词往往在整个语料库中更重要。罕见单词的IDF会很高。高频单词的IDF会很低。
警告,因为语料库中所有文档数目(N)是保持恒定的,因此IDF仅取决于DF,那些DF值最低的词获得相同的最高IDF。因此,有必要引入更多权重词来对文档中出现次数相同的词进行区分。
TFIDF
是一种既考虑词在单个文档中的普及率 prevalence (TF),也考虑他在整个语料库中的稀缺程度 scarcity (IDF)的评估方法。词语 t 在文档 d 中的TFIDF 定义为 d 中 t 的词频 乘以语料库中 t 的文档频率,如下公式:
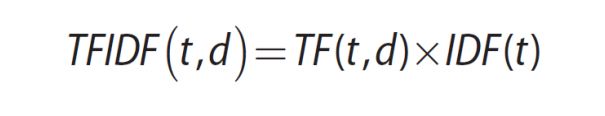
一个词的TFIDF值越高,它在一个文档中出现的就越频繁,但在语料库的所有文档中出现得就越少。
TFIDF在简单和直接的计算中是很有效的,因为它不需要文本含义的相关知识。文档 d 被表示为 TFIDF(t, d)值 的高维向量 (high-dimensional vector)。
TFIDF方法减少描述长度的数量相对较少,同时其很难揭示文档内或文档之间(intra-document or inter-document)的统计结构。
主题建模(Topic Modelling)能够解决这个问题。主题(topic): 经常在一起出现的具有相关含义的单词簇(a cluster of words)。每个词在主题中都有权重。
第四步:主题建模(Topic Modelling)
主题建模提供了文档的简短描述。同时,它也提供了自动组织,搜索,理解并汇总大量信息的工具。主题建模是统计模型,它研究一组文档中的单词,确定文档主题,并发现主题是如何相关(associated)或者如何随时间变化的(change over time)。
流程
- 揭开(uncover)语料库中隐藏的主题模式(hidden topical patterns)。
- 根据这些主题来注释文档(annotate document)。
- 使用注释来组织,搜索,汇总文档(organize, search, summarise)。
主题(topic)
一个主题被正式定义为固定单词词汇分布(a distribution over a fixed vocabulary of words)。不同的主题在相同的词汇上会有不同的分布。词汇中的某个词可以在多个主题中有不同的权重。
一个文档通常由多个主题以不同的比例贯穿文本。
LDA
最简单的主题模型是Latent Dirichlet Allocation(LDA),这是一个语料库的生成概率模型(generative probabilistic model of a corpus)。在生成概率模型中,从概率密度函数 (probability density function) 得出模型观测值 (model observation)。在LDA中,文档被视为生成过程 (generative process) 的结果(带有隐藏变量 hidden variables)。
LDA假设了:
- 有一个固定的词汇表 (fixed vocabulary of words)。
- 潜在主题 (latent topics) 的数目是预定义的。
- 每个潜在主题的特征都是词汇表中单词的分布(Dirichlet distribution)。
- 每个文档表示潜在主题的一个随机混合(random mixture)。
LDA流程
- 选择文档的长度N。
- 每个文档有一个在主题上的分布。
- 为文档中的每个词分配一个主题,并选择相应的主题中的单词。
在现实中,只有文档是可用(available)的。LDA的目标是为每一个文档推断潜在的主题(underlying topic),主题比例 (topic proportion) 以及主题分配 (topic assignment)。
算法
- 选择一个值 k。
- 对于每个文档,将文档中的每个单词随机分配给k个主题之一。
- 对于每个文档 d,遍历每个单词 w,然后计算 d 中分配给主题 t 的单词所占的比例,通常会应用平滑(smoothing)处理:

- 计算从单词w来的所有文档中对主题 t 的分配比例 P(w | t)
- 计算属于主题 t 的单词 w 的概率:
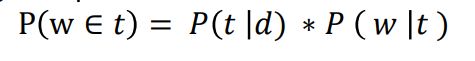
注意事项
LDA将文档视为主题的混合体。
LDA将主题视为单词的混合体。
如果单词 w 很有可能出现在主题 t 中,则所有带有 w 的文档将与主题 t 的关联更为紧密。
如果单词 w 不太可能出现在主题 t 中,则包含 w 的文档出现在 t 中的可能性将会很小。因为文档 d 中剩余的单词将出现在其他主题中,因此 d 有更高的可能性属于那些主题。因此,就算我们将 w 添加到 t 中,也不会将很多该类文档带到 t 。
应用
主题模型可以被用于文档建模(document modelling),文档分类(document classification)与协同过滤(collaborative filtering)。
主题模型不仅可以应用于文本数据,它还可以用于注释图像。
情感分析 (Sentiment Analysis)
情感分析使用统计和自然语言处理来从文本中挖掘观点来识别并抽取主观信息。
应用: 检测产品或者电影的评论的极性(polarity of reviews)。
分析层面包括了文档层面(document),语句层面(sentence),短语层面(phrase),和短文层面(short-text)。
分类方法(朴素贝叶斯,最大熵,或者支持向量机SVM) 经常被用来提取语料库统计以用于情感分析。

分类器仅基于对其进行训练的数据集来确定情感:
- 词义随着领域不同而改变。
- 因此模型无法直接应用于其他领域。
绝对的情感水平无法提供信息,应该建立一条基线,然后将其与观察值比较。比如,一个产品拥有40%正面推文,60%负面推文,貌似是不成功的。但是如果其他类似的成功产品也有类似的正负面百分比,那么不应该认为该产品是不成功的。
如何对大量评论添加标签(积极,消极,中立):
- 使用表情符号 (小心阴阳怪气)
- 使用 Amazon Mechanical Turk 互联网众包市场,将上标签工作外包出去。
获得结果(gaining insights)
词云(word cloud)
五星好评的词云

一星差评的词云:

TFIDF能够用来凸显评论中有信息量的单词。

LDA可以把评论归类为主题。圆盘的大小代表了词的权重。

另一种可视化方式。
